
车牌检测与识别算法研究
2021-11-12 02:17王福龙
智能计算机与应用 2021年9期
郑 琳,王福龙
(广东工业大学 应用数学学院,广州 510520)
0 引 言
迄今为止,车牌识别技术已研究多年,虽在计算机视觉领域,车牌识别技术已经做了大量的工作,但还没有真正成熟的运用到高速交通管制、刑事侦查等领域。如何在实际情况中快速准确的识别车牌仍然是一个具有挑战性的课题。
目前,针对车牌定位的方法主要有:基于颜色与纹理的定位方法[1],该方法主要利用车牌颜色信息和车牌区域呈现特定的纹理特征来定位,但对于车牌底色与车身相近或车身包含广告语的车辆定位效果较差;基于数学形态学的定位方法[2-3],该方法主要是利用开、闭运算处理图像来定位车牌,开、闭运算的处理主要依赖于结构元的选取;基于图像视觉特征的定位方法,诸如SURF特征、SIFT特征、HAAR特征等[4-7],这类方法通常需要考虑特征维数以及信息冗余问题;基于多特征融合的定位方法[8-9],相对于利用单一特征定位车牌,多特征融合的定位方法鲁棒性较高;基于神经网络的定位方法[10-11]的计算能力强大,但由于模型的复杂性以及庞大的计算量,需要云端服务器处理数据,计算成本较高。
字符分割的主要方法有:基于连通域的分割[12-14],该方法根据字符的连通性标记目标像素后,与相邻像素的值对比来分割字符,但是归并标记运算量大,易出现像素的重复标记;基于投影法的分割[15-18]方法,主要是统计二值化后车牌字符的波峰、波谷排列信息确定字符左右边界。该方法需要去除车牌螺帽的干扰,对字符区域存在粘连、模糊或遮挡的情况分割效果较差;基于模板匹配的分割[19-20]方法是基于车牌模板特性,寻找字符区域与字符间隙区域像素点的最大差值分割字符,对车牌尺寸规范要求高。字符识别研究的主要方法有:特征提取法[21-24],通过提取待识别字符的特征与字符库中的特征匹配得到识别结果。该方法可提取到字符的显著特征,但提取特征过程中图像变换易导致特征丢失,且提取到的字符特征维数较高,耗时长;模板匹配法[25-27],通过重合度函数度量待识别字符与标准字符的相似度,取相似度最大的样本作为识别结果。该方法应用广泛,但难以区分相似字符;神经网络法[28-32],通过学习大量车牌样本,将得到的样本特征匹配待识别车牌。该方法对数据的计算能力强大,且识别能力依赖收集的大量车牌样本,训练样本消耗的时间较长。
1 车牌识别技术研究方法分类
车牌识别工作有其区域性特色,各个国家的车牌特征各有不同。据统计,大部分国家的车牌由阿拉伯数字、英文字母与本国的文字组成,一部分国家或地区的车牌由阿拉伯数字和英文字母组成。现有的车牌识别方法可分为两大类:一类是分割字符的车牌识别,主要由车辆图像预处理、车牌区域定位、车牌字符分割和车牌字符识别4部分组成,其识别流程如图1所示;另一类是免分割的识别,即端到端的识别,其识别流程如图2所示。
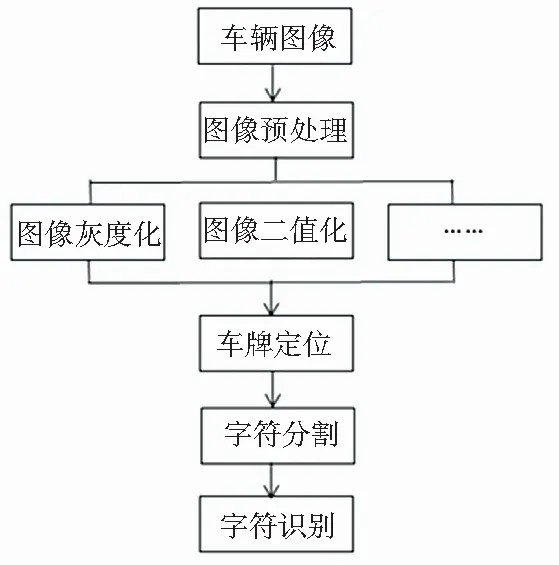
图1 基于分割的识别流程
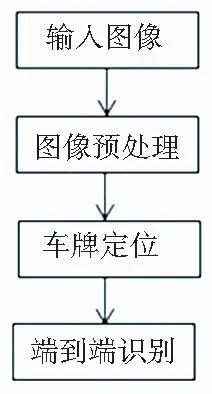
图2 免分割识别流程
车牌识别的难点主要包括以下几个方面:
(1)车牌检测识别算法在移动设备中的部署成本,设备与车辆的距离和相机的变焦系数。
(2)车辆包含广告标语,车身颜色与车牌颜色相近。
(3)车牌倾斜、畸变、模糊;车牌部分被遮挡、字符粘连、缺损或断裂。
(4)字符结构特征难以提取,字符相似性高。
(5)多数车牌识别工作针对特定国家的车牌,限制了实际应用性[33]。
2 图像预处理
获取到车牌图像,由于受天气、光线强度、摄像机与车辆之间的距离、车牌自身磨损等因素影响,图像存在模糊、对比度低、噪声干扰等问题。在对采集的图像进行定位检测之前,需要进行图像的预处理。图像预处理主要包括滤波去噪、图像灰度化、边缘检测、图像二值化和倾斜校正等。
滤波操作主要用于图像去噪,滤波的形式有多种,如均值滤波、中值滤波、双边滤波等,中值滤波对图像中椒盐噪声的抑制效果好,又能保持图像的边缘清晰,一般选用中值滤波对车辆图像去噪。考虑到三通道图像数据的复杂性,要将车辆原图灰度化,图像灰度化操作通过RGB三通道的数值加权计算。灰度化公式如式(1):
Gray=r×0.299+g×0.587+b×0.114
(1)
得到灰度化图像后,用阈值将图像像素点的灰度值设置为0或255,使整个图像呈现明显的黑白效果,区分目标和背景,该过程即图像二值化。其中,选取阈值的主要方法有:OSTU法、迭代阈值法和局部阈值法等,车牌识别技术中常采用OSTU法。为精确提取车牌区域的边缘特征,常用微分算子对图像进行锐化处理,使图像的灰度反差增强,突出边缘部分[34]。一阶微分算子和二阶微分算子得到的图像边缘各不相同,相较于一阶微分算子,二阶微分算子能提取到丰富的纹理信息,得到较细的双边缘,锐化效果更好。
2.1 车牌检测方法分类
车牌定位是指从视频流中检测出车牌区域,或直接从移动设备拍摄的车辆图像中提取车牌区域,车牌定位的准确性直接影响车牌的识别结果。颜色和纹理是车牌图像的两个重要特征。颜色特征描述车牌的颜色通道数据信息,纹理特征刻画图像中重复出现的局部模式和排列规则。在车牌定位阶段,通常需要利用车牌的颜色和纹理信息来提取车牌区域,而单一的车牌特征信息不利于精确提取车牌区域。因此,多数定位方法通过多种算法结合定位车牌区域。
2.1.1 数学形态学
数学形态学运算在图像处理中常用于分析物体的几何形状和结构,由形态学的代数运算子组成。基本的形态学运算子有:腐蚀、膨胀、开运算和闭运算[35]。该算法的缺点是不能精确找出车牌左右边界。
开运算:先腐蚀后膨胀,可消除细小物体,平滑较大物体边界时,不明显改变面积大小。
X∘S=(XΘS)⊕S
(2)
闭运算:先膨胀后腐蚀,可去除物体内部的小孔,平滑物体边缘轮廓,填补断裂轮廓线。
X·S=(X⊕S)ΘS
(3)
2.1.2 离散小波变换[26]
图像处理中通过二维离散小波变换将低频和高频信号分离,达到图像增强的目的。图像大小为M×N的离散小波变换如公式(4)。
(4)
其中,j0为任意初始尺度;Wφ(j0,m,n)为j0的近似系数;φj0,m,n(x,y)为尺度函数。
2.1.3 SURF算法
SURF算法是一种局部特征提取算法,具有尺度、旋转不变性。该算法主要分为4部分:
(1)计算积分图像,即计算图像中矩形区域内所有像素点之和。
(2)构造Hessian矩阵,这是SURF算法的核心部分,目的是为了生成图像的突变点,用于特征提取。Hessian矩阵定义如式(5)所示:
(5)
式中,Lxx为高斯二阶偏导Gxx与图像I(x,y)的二维卷积,Lxy,Lyy与Lxx含义类似,g(x,y)为高斯函数[5]。当矩阵判别式取局部极大值时,判定当前点是比周围邻域内其它点更亮或更暗的点,据此定位特征点。
(3)确定特征点主方向。Hessian矩阵初步得到特征点后,统计特征点邻域内60°扇形内HAAR小波响应总和,取响应总和最大时扇形的方向为特征点主方向。
(4)构造SURF特征进行匹配。在特征点周围取一个4*4的矩形区域块,每个子区域统计25个像素水平和垂直方向的HAAR小波特征,得到64维特征描述符,最后通过计算特征点间的欧式距离进行配准。
2.2 字符分割法
字符分割是指在定位出的车牌区域中把每个字符切割出来,车牌中常用的分割算法主要有:基于连通域的分割、基于投影的分割和基于模板匹配的分割。
(1)连通域分割法。基于连通域的算法主要分为两大类:一类是从局部到整体检查连通域,确定“起点”,再标记周围邻域;另一类是从整体到局部,先确定不同的连通域成分,再用区域填充的方法标记连通域[12]。车牌字符中的阿拉伯数字和英文字母都有较好的连通性。扫描车牌的二值图像,提取值为“1”的像素点,用不同的数值标记不同的连通域,与相邻像素点的值对比后切割字符[14]。这种分割方法在字符破损、粘连或存在噪声等情况时无法有效分割字符,且难以解决汉字的分割问题。
(2)投影分割法。投影分割法分为水平投影分割和垂直投影分割。这种方法主要根据车牌字符固定规格的间隙来分割字符。其基本思想是:对二值化车牌的白色像素进行水平和垂直方向上的统计,根据字符区域白色像素点多,字符间隙区域白色像素点少的特点,检测字符间白色像素点个数的波谷分割字符[36]。这种分割方法对变形程度较轻的车牌分割效果好,但对模糊、损坏的字符分割效果较差。
(3)模板匹配分割法。模板匹配分割法的基本思想:确定车牌模板后,在字符图像上从左至右滑动,确定字符上下边界的车牌图像,以模板字符宽、高为标准,求得字符区域与间隙区域白色像素的最大差值分割字符。该算法是基于车牌模板特征的算法,能有效解决汉字不连通问题。
2.3 字符识别方法分类
车牌字符识别算法可分为两大类:一类是识别分割好的车牌字符;另一类是直接识别定位好的车牌,即端到端的识别。车牌识别算法主要分为以下3类。
(1)模板匹配法。这是一种经典的模式识别算法,需要先根据车牌字符类型建立完整的字符模板库,然后通过重合度函数度量车牌字符与样本字符的相似度,取最大相似样本作为识别结果,重合度函数如式(6)所示[25]。该算法实现简单,具有一定的容错性,但识别效果易受光照影响,对相似字符的区分能力差。
(6)
式中,f为模板二值图;g为车牌二值图;两者二值图尺寸相同,均为M×N;Tf和Tg分别为模板字符二值图像和车牌字符二值图像中数值为1的像素个数;符号Λ为与运算。
(2)特征提取法。车牌字符的结构特征分类效果显著,从被切割和归一化处理后的字符中能提取到体现字符特性的特征向量。特征提取法提取字符的统计特征,再通过判决函数对车牌字符进行识别。特征提取方法包括:逐像素特征提取法、骨架特征提取法、垂直方向数据统计特征提取法、弧度梯度特征提取法等。其中,逐像素特征提取法是指对图像进行逐行逐列的扫描,取黑色像素特征值为1,白色像素特征值为0,最终形成维数与图像中像素点的个数相同的特征向量矩阵。这种方法可提取到分类显著的特征,但提取特征耗时较长。
(3)神经网络法。神经网络算法发展至今,已经从传统的人工神经网络(Artificial Neural Network, ANN)发展到如今的卷积神经网络(Convolutional Neural Network, CNN)、生成对抗网络(Generative Adversarial Network, GAN)等。使用神经网络算法识别车牌最大的难点在于:神经网络需要大量样本进行训练,由于各个国家的车牌规格存在差异,车牌通用性不高,车牌样本不足[31];神经网络模型复杂的网络结构保证了强大的计算能力,同时也不可避免的导致了数据过拟合、梯度消失等问题,且庞大的网络模型限制了在车牌识别所需移动设备中的部署。
3 车牌检测与识别算法的分类
3.1 基于车牌检测的算法
文献[1]中提出,首先利用车牌颜色信息得到候选区域,再利用车牌底色与字符间的搭配特性去除伪车牌,最后根据车牌字符的先验知识,验证得到的区域是否为车牌。该算法可在交通视频截取的图像中定位多个车牌,白天和夜晚平均定位准确率为95.01%,平均定位时间为763.49 ms。文献[9]中则先将整幅图像划分为小单元,计算小单元的边缘密度,根据其边缘密度分布和车牌尺寸大小过滤背景区域;再用形态学操作算子(高帽与低帽运算)提取候选区域,利用霍夫变换确定精确位置;最后通过模板匹配法,判断得到的车牌区域是否为数字与字母来去除误检区域。该算法的定位准确率为97.9%,平均定位时间163 ms。文献[8]在小波变换的基础上,用Sobel垂直检测算子边缘检测,根据车牌结构的先验知识连接边缘检测中的水平跃变点提取车牌候选区域;最后用纵向条带滑动窗口和句法评判函数去除伪区域,句法评判函数如式(7)。该算法在夜晚和大雾天气的定位率分别为96%和97%,定位耗时分别为79 ms和65 ms。文献[5]中先将车辆RGB图像转换到HSL颜色空间,再对二值化后的图像做形态学腐蚀和膨胀操作,连通相邻的非连通区域,然后结合车牌的先验知识筛选出候选车牌区域,最后利用SURF算法实现图像配准,实现车牌的精确定位。文中利用车牌的多种特征提取候选区域,可以减少后续步骤中SURF算法特征匹配的次数,降低匹配时间,提高算法的实时性。该算法定位准确率达到了96.5%,平均定位时间为740 ms。表1为近3年来车牌定位算法常用方法分类。
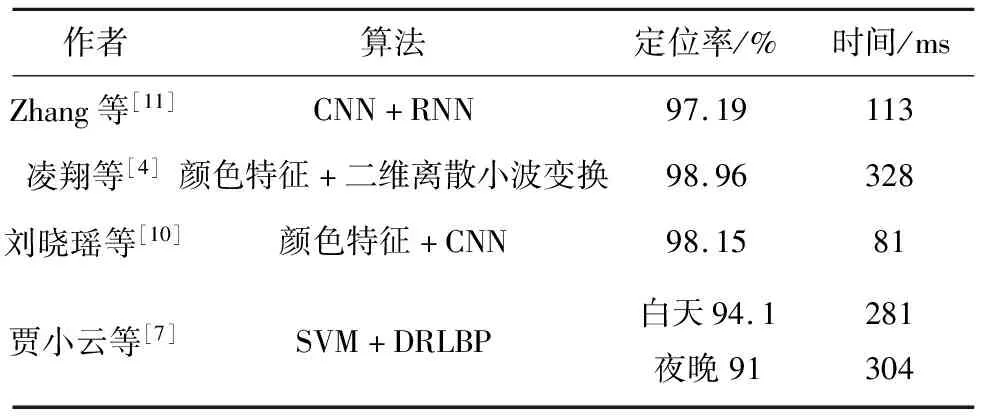
表1 车牌定位算法对比
(7)
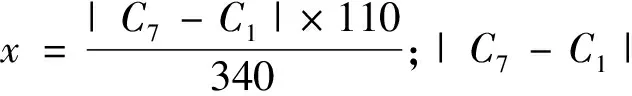
在车牌检测定位的诸多算法中,大部分定位车牌的算法都表现出了良好的性能。文献[7]和文献[11]中提出的算法不受车牌颜色以及先验知识的限制,可对不同国家、不同地区的车牌进行定位。文献[1]和文献[4]中提出的算法能在拥挤的交通道路中实现多车牌定位。其中,文献[4]对车牌的定位率达到了98.96%,但由于采用算法受车牌颜色以及先验知识的限制,只能对中国的蓝色车牌进行多车牌定位,且在交通道路视频中截取的图像中车辆过多、车牌尺寸过小、车牌污损、车牌老化等情况,会导致该算法产生车牌漏检。文献[1]能够在夜晚光线较差的情况下实现多车牌的定位,且定位率达到了93.78%,但由于该算法处理的图像像素为2 592*2 096,所以该算法的定位时间较其它算法耗时较长。该算法一个大的优点就是不需要手动设置阈值范围,而是通过自动确定亮度条件来决定使用全局阈值法还是自适应阈值法来设置阈值。同样,该算法也因为颜色以及先验知识的限制,只能对中国地区蓝色和黄色的车辆牌照实现多车牌定位,也不适用于因污损或彩色光而改变颜色的车牌的定位。
3.2 基于字符分割的算法
文献[18]主要基于车牌字符粘连、断裂和被遮挡的条件下分割车牌字符。其先采用投影法粗分割字符,根据车牌字符的先验知识将粗分割得到的字符块分成3类:非合并块、合并块和不确定字符块。合并块按既定准则合并,不确定字符块和粘连字符块根据模板匹配法二次分割。该算法可分割部分人眼难以分辨的遮挡字符,分割时间只需10 ms左右。文献[13]主要采用连通域方法来分割字符。先对车牌二值图像做4邻域连通区域标记,通过宽、高筛选和同高筛选方式得到字符特征区域。大量的特征筛选会导致车牌字符出现信息缺漏,文中根据车牌模板特点设计了填补方案补全缺漏字符,同时利用投影法界定字符边界。字符分割算法的文献对比情况见表2。
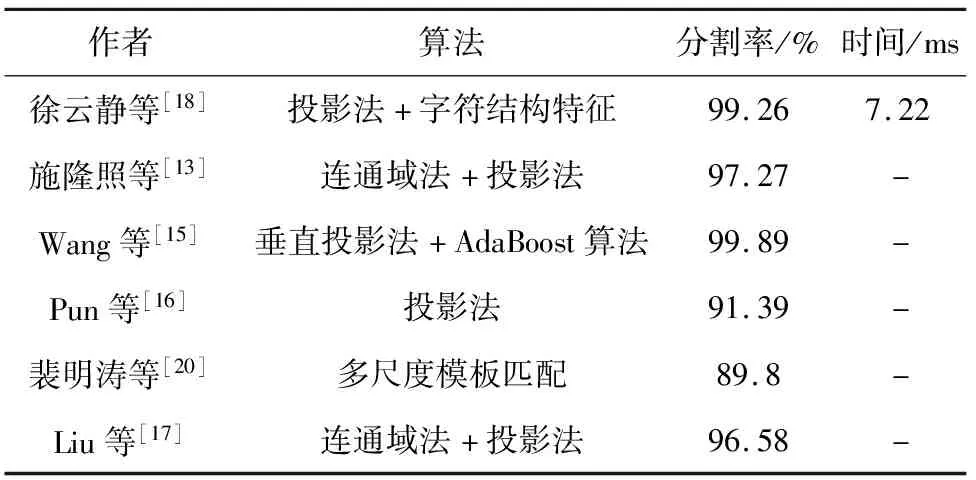
表2 字符分割算法对比
3.3 基于字符识别的算法
文献[23]通过提取车牌二值字符图像上的外轮廓特征(ET1特征)与内部结构信息(DT12特征),经主成分分析法(PCA),将特征向量降至50维后,再进行识别。该算法对数字和字母字符的识别精度分别为99.37%、99.35%,平均耗时分别为2.1 ms、1.52 ms,适用于数字和字母组成的车牌。文献[24]中的算法,提取原始字符的4个尺度不变特征,在级联的特征向量上选用F-score法降维后,送入支持向量机分类器中识别,该算法在高速公路图像中对车牌的识别率为97.6%。文献[26]提出了一种顶帽重构的方法,解决车牌图像中不均匀照度的问题。顶帽重构是数学形态学中的一种变换,是形态学中原图像与开运算的结果图之差。形态学的开运算操作是先腐蚀再膨胀,这种运算放大了裂缝或局部最低亮度的区域,可去除图像中较小的亮点。但开运算的膨胀过程会导致字符变形,因此文中使用重构代替膨胀作开运算。作者在车牌字符识别阶段采用全局相似度函数进行模板匹配,但由于模板匹配法对相似字符的识别能力较差,文中未提取字符的特征信息,车牌的识别率为77.86%,识别时间为15.35 ms。文献[30]中设计了一个改进的6层CNN模型,用来提取图像中的特征信息。根据提取的特征信息,采用双向递归神经网络(Bidirectional Recursive Neural Network, BRNN)识别特征,最后利用连接时序分类(Connectionist Temporal Classification, CTC)对BRNN的输出解码翻译,得到识别结果。文中提出的6层CNN模型融合了第4层和第6层卷积层,在融合时使用了平均池进行池化运算。改进后的模型提取的特征更大程度的保留了车牌字符的信息,提高了识别性能。以平均17.53 ms的速度识别220*70像素的车辆图像,识别率为96.62%。文献[31]的核心思想就是使用Wasserstein 距离损失,衡量卷积生成对抗网络中的损失函数,结合深度可分离循环卷积神经网络,识别免分割的车牌图像。文中使用 Wasserstein 距离作为一种新的标准,衡量卷积生成对抗网络中生成器和判别器两种分布的距离,在判别器的最后一层添加一个全连接层来实现操作,图3为文中生成对抗网络示意图。文中采用深度可分离卷积得到车牌的特征信息,深度可分离卷积将标准卷积分成深度卷积和逐点卷积。其中,深度卷积在每个通道上起到滤波作用,逐点卷积负责通道的转换,作用在深度卷积的输出特征映射上,图4为深度可分离卷积示意图。文献中采用的算法解决了实际情况中车牌训练样本不足的问题,降低了网络参数的计算量,压缩了网络模型大小。表3为模式识别算法的文献对比情况,表4所列为近4年神经网络识别算法的对比情况。
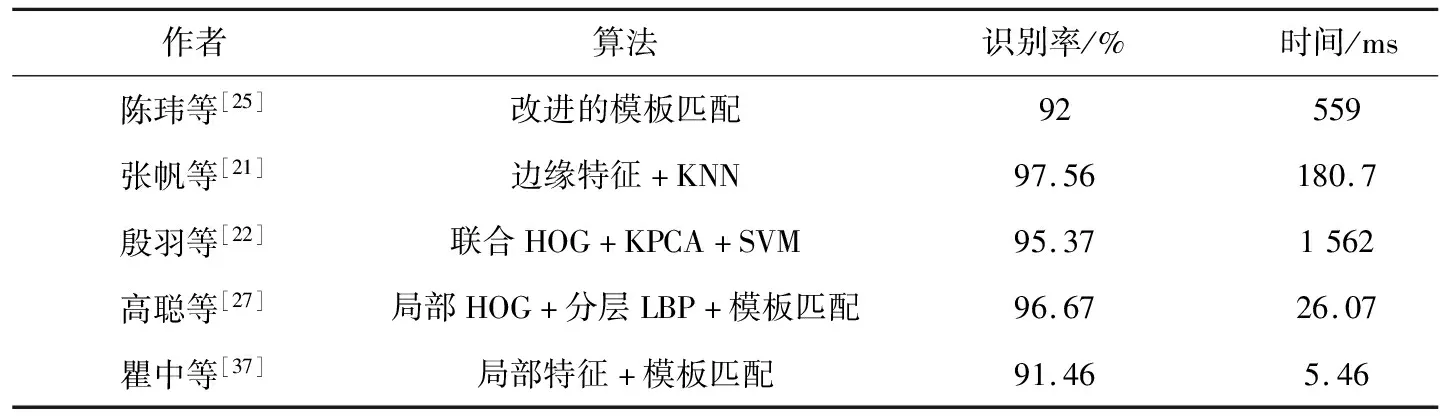
表3 模式识别算法的对比
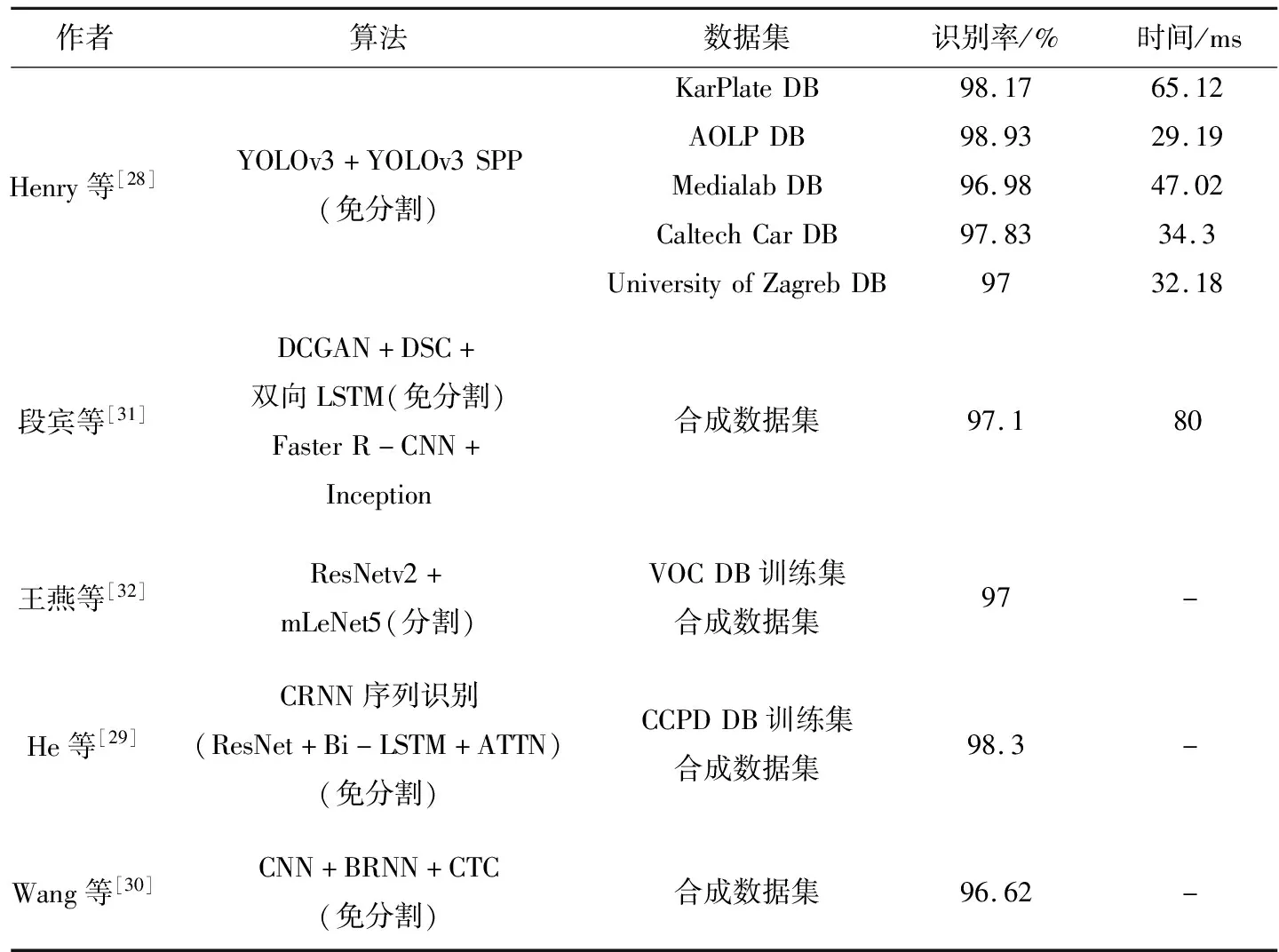
表4 神经网络识别算法对比
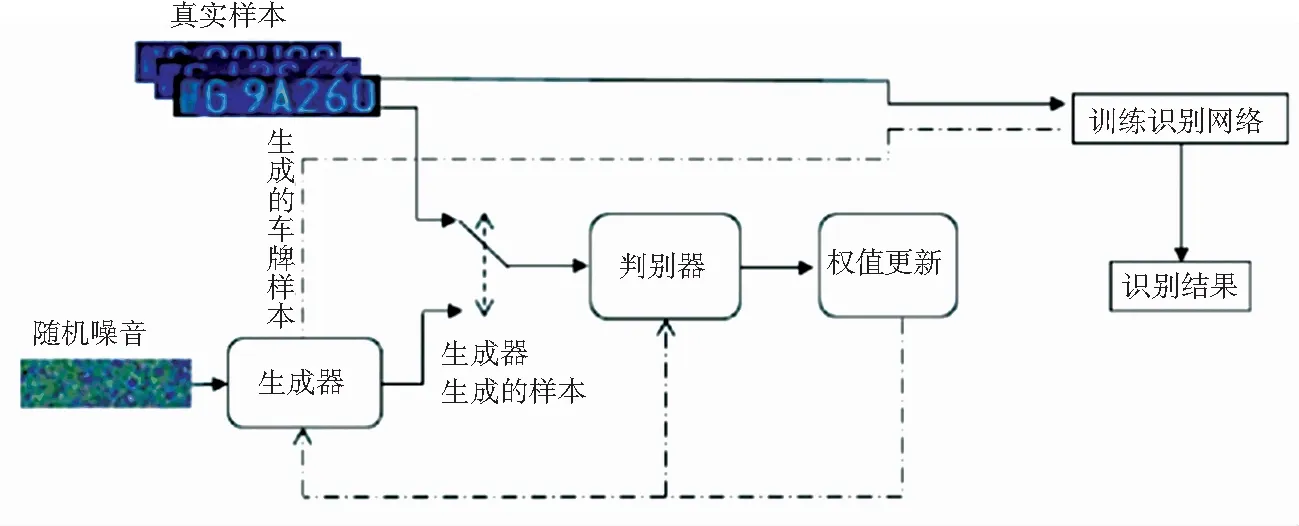
图3 生成对抗网络示意图[31]

(a)标准的3D卷积核 (b)深度卷积核 (c)逐点卷积
在车牌识别技术的诸多研究中,对于质量较好的车辆图像,大部分识别算法都有着较高的识别性能。总结以往的研究工作,仍存在一些问题需要解决:
(1)对于被遮挡和断裂的车牌字符仍未找到好的解决方式。
(2)对于模式识别算法,应寻求识别模糊程度更高的车牌。
(3)神经网络算法中的网络模型相当于一个“黑盒”,把图像输入网络模型,得到识别的车牌。在这个过程中,无法对模型进行“解释”,灵活性不足,得到车牌信息时极大的依赖于大量的训练试错。此类算法依旧需要考虑的是如何解决训练样本、模型部署、梯度消失,对系统性能的影响问题。
(4)对于可达到较好性能且相对简单的网络结构,较好的解决了训练样本的生成问题,但对于车牌纹理丰富的图像,生成的样本质量有待提高。
4 结束语
本文对车牌检测与识别算法进行了全面回顾,重点关注了车牌定位与字符识别算法的研究。给出了图像预处理、车牌定位、字符分割和字符识别步骤的介绍,并对各个步骤的方法和优缺点进行了阐述。研究表明,大部分定位与识别算法表现出良好的性能。在实际的交通道路应用中,常出现交通拥挤,车流量过大、车速过快等情况。因此,对于算法在移动设备中的部署、识别率以及实时性有着极高的要求。模式识别算法较神经网络算法在设备部署上有着明显的优点,考虑如何利用模式识别算法结合其它方法提高低质量图像下车牌的识别率与识别速度,得到低成本与高识别率的车牌识别算法是一个重要的研究方向。神经网络算法有着强大的并行计算能力,避免了人工提取特征,但需要大量的学习样本,存在着收集样本成本较大、网络模型复杂、泛化部署代价过高的问题。如何降低深度学习神经网络模型的大小,权衡车牌识别率与识别成本是利用神经网络算法识别车牌的重要研究方向。本文提出一个新的方法:将文献[38]中利用多纹理特征提取字符特征的方法运用到文献[26]中,可解决车牌字符的不均匀照度问题,在保证识别速度的同时,识别率有较大的提高。在车牌识别技术真正应用到高速交通管制、刑事追踪等领域之前,仍有许多问题需要解决。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
电脑报(2021年41期)2021-11-04
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
动漫界·幼教365(中班)(2021年4期)2021-05-23
电脑知识与技术(2019年29期)2019-12-16
电脑爱好者(2019年8期)2019-10-30
小猕猴智力画刊(2017年5期)2017-05-25
科技创新导报(2016年32期)2017-04-22
