
面向用户偏好建模的个性化对话推荐算法
2021-11-10 07:19尚琛展
信息安全学报 2021年5期
尚琛展, 赵 鑫
1 华中科技大学计算机科学与技术学院 武汉 中国 430074
2 中国人民大学高瓴人工智能学院 北京 中国 100872
1 引言
近年来, 推荐系统在社交[1]、电商[2]、新闻[3]等领域得到了越来越广泛的应用, 充分显示了其商业潜力。在传统推荐系统中[4], 推荐任务的实现高度依赖于用户与物品的历史交互记录, 例如电商网站通过用户的点击记录与购买记录来向用户推送其可能感兴趣的商品。然而, 推荐系统却难以从这种隐式反馈中挖掘用户的真实偏好, 使得系统性能的提升受到限制。针对该问题, 对话推荐系统[5-7]能够通过使用自然语言与用户进行多轮对话, 逐步深入挖掘其个性化偏好, 从而提供高质量的推荐结果。相比于传统推荐系统, 用户在与对话推荐系统进行交互时,提供了及时的、显式的反馈, 这更精确地反映了用户的真实需求, 使推荐系统的性能有更大的提升空间。
在设计上, 对话推荐系统由推荐模块与对话模块组成[8]。一方面, 对话模块能够理解用户意图, 向推荐模块提供有关用户偏好的信息, 并根据其反馈生成对用户的回复。另一方面, 推荐模块根据对话模块提供的信息, 在物品数据库中搜寻匹配项, 从而更高质量地完成推荐任务。表1 所示为电影推荐场景下, 对话推荐系统与用户交互的示例。系统在与用户交流的过程中关注到其喜欢的电影类型, 随后在回复中给用户提供推荐影片, 当用户接受了系统所提供的建议时, 整个工作流程结束。在这个过程中可以发现, 系统需要同时完成对话和推荐两类任务,因此, 做好两个模块的衔接与协同运转对于构建高效的对话推荐系统来说至关重要。

表1 电影推荐场景下的对话推荐系统交互示例Table 1 Example of conversational recommendation in movie recommendation scenario
对话推荐系统近年来受到越来越多的关注, 针对不同的问题设定, 研究者们提出了各种算法来应对不同的需求。例如, ReDial[5]引入情感分析模块, 根据用户表达中体现的情感, 来更精确地获取其对候选物品的偏好; KBRD[6]和KGSF[7]引入外部知识库,来为推荐任务提供充足的信息, 缓解了系统所面临的冷启动问题[9]; CPR[10]将对话推荐任务转化为在图上的路径推理问题, 提升了系统性能, 并增强了推荐结果的可解释性。
上述的这些工作都在一定程度上提升了对话推荐系统的性能表现, 但是它们仍具有局限性。
一方面, 现有的工作[5-7,10]都仅对当前的对话进行建模。为了使用户能够在较短时间内获取系统提供的推荐物品, 保证良好的用户体验, 对话的轮次需要控制在一定的范围内。而这种对交互深入程度的限制, 导致系统对用户的认识是片面的, 难以深入挖掘用户对候选物品的兴趣偏好。如何在控制对话长度的同时加深系统对用户的理解, 这是对话推荐算法需要解决的一个重要问题。
另一方面, 从客观上来讲, 用户的偏好是广泛的、多方面的, 与系统的单次对话仅反映了用户偏好的一方面, 在此基础上得到的推荐结果无法体现用户本身丰富的兴趣偏好, 具有同质化趋势。这种同质化趋势容易造成“信息茧房”等不良现象, 与推荐系统的初衷相违背。
为了解决这两个问题, 可以考虑基于用户的历史对话数据进行建模。一方面, 在不增加当前对话轮次的前提下, 系统可以从用户的历史对话数据中得到更充分的信息, 从而获取对用户更深入的理解。另一方面, 用户的每次对话可能有不同的主题, 丰富的主题展现了用户在不同方面的兴趣偏好, 对这些信息加以利用能够缓解当前对话信息的匮乏, 提升推荐结果的多样性。
然而, 在对用户的历史对话数据进行建模时仍会遇到不小的挑战。首先, 并不是所有的对话记录对于当前的推荐任务都有价值。例如在电影推荐场景下, 某用户的大多数对话中都向系统寻求属于科幻片的推荐影片, 而在当前的对话中他希望寻找喜剧片, 如果系统再根据过去的记录给用户推荐科幻片,就会造成严重失误。如何甄别历史对话数据中对当前任务有用的信息, 是基于多对话进行用户偏好建模的重要挑战。其次, 用户的历史对话数据是丰富的,同时也是冗余的, 如果对其不加以区别地利用, 势必会导致当前对话中的信息淹没在历史对话数据中,使系统得到与当前任务近乎无关的推荐结果。如何权衡历史对话数据和当前对话数据二者的重要性,是需要应对的第二个挑战。
为应对这些挑战, 本文提出了PCR (user preference modeling based Personalized Conversational Recommender) 模型。一方面, 使用注意力机制给历史对话中所有和用户发生过交互的物品赋予一定的权重, 权重越大, 表明它与当前任务的契合程度越高, 从而甄别出历史对话数据中最有价值的信息。另一方面, 本文工作采用“目标对话为主, 历史数据为辅”的原则, 基于自注意力机制[11], 设计了层次化自注意力编码器结构, 先对历史对话数据中与用户发生过交互的物品进行融合, 得到与历史相关的用户向量表示, 再将它与当前对话中出现的实体进行融合得到最终的用户向量表示。这样的层次化编码既考虑到用户在多次对话中所展现出的不同方面的兴趣偏好, 又切实关注了他们在当前的对话中所提出的需求, 从而实现对用户偏好的精细建模。
基于公开数据集[5]的实验表明, 相对于基线模型, PCR 在推荐任务和对话任务上的表现都有所提升, 这表明了本文方法的有效性。
2 相关工作
2.1 推荐系统
推荐系统的目标是从物品数据库中, 选择出与用户兴趣偏好相匹配的子集, 从而缓解用户面临的“信息过载”问题。推荐系统通常以用户和物品的历史交互记录作为信息来源, 获取匹配的推荐结果, 例如用户的点击记录、观看或购买记录, 甚至是评论等文本信息。
经过20 余年的发展, 研究者们提出了许多不同的算法来解决推荐问题。早期所采用的方法主要是协同过滤[12], 但是它难以处理稀疏矩阵, 推荐结果的头部效应较为明显。矩阵分解算法[13]的提出增强了推荐算法模型的泛化能力, 但它无法对用户、物品及其他上下文特征加以利用。逻辑回归在推荐系统中的应用[14]解决了这一问题, 它能够融合多种不同类型的特征, 随后的因子分解机[15]可以对不同特征进行进一步的交叉, 增强了模型的表达能力。
深度学习方法兴起以来, 推荐系统领域也受到这一浪潮的深刻影响, 涌现出众多性能优异的新模型[16-18]。其后, 为了应对冷启动问题和交互数据稀疏性带来的问题, 研究者们提出了许多技术手段来融入外部信息, 比如异质信息网络[19]、知识库[20-21]和社交网络[22]等, 这也进一步增强了推荐结果的可解释性。
2.2 对话推荐系统
传统推荐系统利用历史交互记录来获得关于用户的信息, 在形式上是隐式的, 在时间上是滞后的。对话推荐系统能够通过与用户的多轮对话, 获得显式而及时的反馈, 逐步深入挖掘用户兴趣偏好, 从而提供更高质量的推荐结果。
因此, 对话推荐系统近年来吸引了越来越多研究者的关注。研究者们针对不同的问题设定和形式化方法, 完成了许多有价值的工作。CRM[23]将深度强化学习方法引入对话推荐系统, 构建了一个深度策略网络来决定系统的下一步动作。有研究者提出了SAUR[24](System Ask, User Respond) 范式来描述基于对话的搜索或推荐问题。对话推荐系统框架EAR[25](Estimation-Action-Reflection)统一地解决向用户问什么, 何时进行推荐, 如何适应用户的反馈这三个问题。ReDial[5]是一个端到端的对话推荐算法模型, 该工作同时提出了电影推荐场景下的对话数据集。KBRD[6]在前者数据集的基础上引入外部知识图谱DBpedia[26], 缓解了冷启动问题, 得到更具可解释性的推荐结果。KGSF[7]同时引入实体级和词汇级知识图谱, 通过互信息最大化算法来消解实体、词汇两类向量表示之间的语义鸿沟, 进一步提升了对话推荐系统的表现。
然而现有的工作仅对当前对话进行建模, 没有充分考虑同一用户在历史对话中所蕴涵的兴趣偏好信息。基于多对话进行用户建模后, 对话推荐系统具备了更大的性能提升空间。
3 问题描述
对话推荐系统的任务是通过多轮对话向用户推荐匹配的物品。对话模块能够分析和理解用户基于自然语言的表达, 并生成相应的回复; 推荐模块能够接收对话模块提供的用户相关信息, 在物品数据库中寻找匹配的推荐结果。多轮对话的过程直到用户接受了推荐结果或者用户离开才会结束。个性化对话推荐任务则更进一步地要求对用户的历史对话数据进行建模, 从而得到更符合用户兴趣偏好的推荐结果。

目标对话 ( t)C 进行到第k 轮时, 系统需要根据目标对话中已经出现的上下文和历史对话序列, 从物品集I 中寻找与用户偏好相匹配的子集 Ik, 并生成回复语句sk1+作为对用户的反馈。这样的推荐过程直到用户接受了推荐结果或者主动离开为止。
已有的对话推荐系统工作仅利用目标对话中的信息得出推荐结果, 而本文工作充分考虑了历史对话中所提供的丰富信息, 来生成更精确地符合用户真实偏好的推荐结果。
4 模型
本文提出了面向用户偏好建模的个性化对话推荐算法框架PCR 来完成个性化对话推荐任务, 该模型首次将用户的历史对话数据作为上下文信息融入到用户建模的过程中。图1 展示了PCR 模型推荐模块的整体结构, 其中右侧为基于KBRD[6]的基线模型,左侧为PCR 基于历史对话进行建模的模块, 其得到的与历史相关的用户向量表示能够增强最终用户向量的表达能力, 从而更精确地与物品数据库中的物品进行匹配。
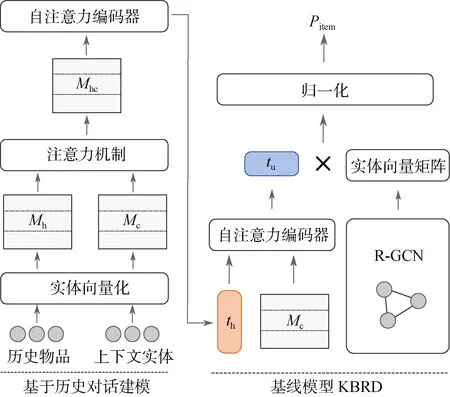
图1 PCR 推荐模块结构图Figure 1 Structure of recommendation module in our proposed model PCR
4.1 构建实体向量
在基于深度学习的推荐系统中, 通常使用向量的形式来表示一个实体。可以将实体表示为一个独热向量 (One-Hot Vector), 也就是除了标识实体序号维度上的值为1, 向量其他维度的值都为0。这种独热表示方法具有不可忽视的缺点: 一方面其数据具有稀疏性, 使得神经网络训练时的收敛速度变慢,提高了计算代价; 另一方面, 无法基于这种向量表示来直接比较实体之间的相似程度, 因为任意两个不同实体向量之间的点积都为0。为了弥补这些缺点,研究者们通常使用嵌入(Embedding), 一类低维稠密向量来表示实体, 这能够在降低计算代价的同时提升向量的表达能力。
本文使用R-GCN[27], 一类图卷积神经网络模型来对知识图谱中的结构信息进行编码, 得到节点的低维稠密向量表示。编码时的图结构来源于DBpedia[26]知识库, 整个图结构G 是三元组( eh, r , et)的集合, 其中 eh,et∊E , 分别表示头节点和尾节点对应的实体, r∊R 表示节点之间的关系, 其中E 和R 分别表示知识图谱中的实体集和关系集。根据图结构的信息, 可以训练实体向量所构成的参数矩阵。
形式化地,初始化一个可训练的参数矩阵N(0)∊R|E|×d(0)作为R-GCN 的输入。随后对第l 层的节点e,使用如下式(1)来更新各节点表示:

4.2 融合多对话信息建模
获得实体的向量表示之后, 下一步是从用户的自然语言表达中提取必要的物品和非物品实体, 并融合历史对话数据与目标对话数据, 供后续对用户进行建模。
实体可以根据其性质分为两类, 一类称为物品,即直接推荐给用户的实体, 例如在电影推荐场景中,电影本身就是物品。另一类实体为非物品实体, 例如表1 中的粗体字词汇“科幻片”、“克里斯托弗·诺兰”就是非物品实体。在用户表达中出现的这两类实体都能够为推荐任务带来有价值的信息。
目标对话( t)C 中出现的所有实体构成上下文实体集 Ec⊂E ,历史对话序列H 中出现的所有物品实体构成历史物品集 Eh⊂E。进一步地,依据这些实体可以从N 中取出相应的实体向量,构成上下文实体矩阵Mc∊R|Ec|×d和历史物品矩阵Mh∊R|Eh|×d。前者反映了用户在目标对话中展现的兴趣偏好,后者则体现了用户在历史对话过程中体现出来的长期偏好。
为避免历史信息的冗余对结果造成负面影响,本文使用注意力机制来甄别历史对话数据中对当前任务有价值的信息。根据历史物品与上下文实体的相关性,对历史物品矩阵Mh进行重组。首先根据如下式(2)来计算Mh对Mc的注意力分布矩阵:

满足Ahc∊R|Ec|×|Eh|。这里使用了双线性模型注意力打分函数[28]来判定两个实体向量之间的相关性,式中Wa∊Rd×d为双线性模型的权重矩阵。获得注意力分布矩阵之后,可以得到重组后的历史物品矩阵:
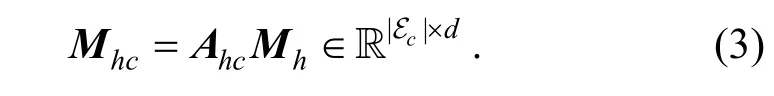
Mc和Mhc分别包含了用户在目标与历史对话中所展现出的偏好信息,它们能够用来对用户进行更精细的个性化建模,从而在物品数据库中寻找到与用户最为匹配的推荐结果。
4.3 用户偏好建模与推荐
通过将用户表示成与实体向量相同维度的、处于同一语义空间的用户向量, 能够直接使用向量点积比较用户与物品实体的相似性, 从而向用户提供更加匹配的推荐结果。
这启示我们可以将Mc和Mhc从两个矩阵线性地压缩为一个d 维的向量来代表用户,由于这两个矩阵中的向量原本就来源于表示实体向量的语义空间,那么经过线性压缩后得到的用户向量,也自然而然地与该语义空间相匹配。
这种具有线性特征的压缩手段可以是直接对矩阵中的各向量取平均值,但是本文采用了更复杂的自注意力机制[11]来完成这一步操作。
定义一个自注意力编码器 S : R*×d→Rd,这是一个从矩阵到向量的映射,其中的矩阵可以由任意多个d 维向量堆叠而成。编码器的具体形式为:
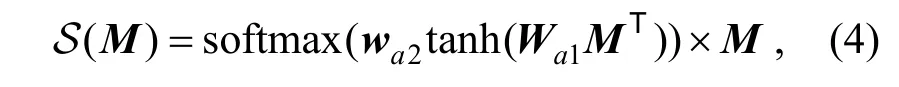
其中, Wa1∊Rda×d是可训练的权重矩阵,wa2∊Rda是可训练的权重向量。由此得到的自注意力编码器能够将任意多个实体向量,按照一定的自注意力权重比例线性组合成具备相当表达能力的用户向量。
为了权衡历史对话数据与目标对话数据之间的重要程度,避免目标对话中的信息被丰富的历史对话数据所淹没,本文依据“目标对话为主,历史数据为辅”的原则,采用层次化自注意力编码结构对两类信息进行编码。
首先对修正后的历史物品矩阵Mhc进行编码,得到与历史有关的用户向量表示 th= S( Mhc) ∊Rd,再将其与上下文实体矩阵堆叠进一步得到用户矩阵Mu= [ th; Mc] ∊R(|Ec|+1)×d。对Mu使用自注意力编码器编码得到最终的用户向量表示 tu= S( Mu) ∊Rd。层次化自注意力编码结构的设计体现了对两类数据重要性的权衡,相当于先验知识的输入,限制了历史信息发挥作用的空间。
最后通过对比用户与实体的相似性来进行推荐。具体来说,通过向量的内积操作来得到各实体与用户的相关性打分,并使用归一化函数softmax 来获得物品实体最终出现的概率:
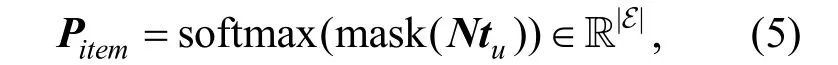
其中的mask 操作将所有非物品实体的打分置为-∞,避免向用户推荐非物品实体。
4.4 用户信息增强的对话生成
本文使用Transformer[29]来完成系统的对话生成任务。这是一类能够对序列信息进行建模的编码器-解码器模型框架,其中编码器能够对输入的词向量序列进行编码得到序列的高维表示,然后将其输入解码器解码得到输出的词向量序列。输出的词向量再经过一层仿射变换分类器得到单词表上的概率分布。具体来说,令o ∊Rdw表示输出的词向量, dw为词向量维度,最终得到的句子中词汇概率分布为softmax(W o + b ) ∊R|V|,其中| V |为词表大小,W ∊R|V|×dw和b ∊R|V|分别为权重矩阵和向量。
为了使生成的对话与当前推荐任务和用户偏好更为契合,本文采用与KBRD[6]相一致的做法,将用户向量转化为词汇偏置,再叠加到词概率分布的计算公式中。形式化地讲,定义映射 F:Rdw→R|V|,它能够将用户向量tu转化为词偏置 bu=F(tu),最终的词汇概率分布如下所示:
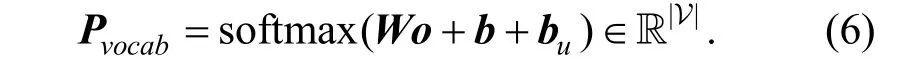
至此,一个端到端的个性化对话推荐算法框架PCR 构建完成。推荐模块能够综合利用用户的历史对话数据和目标对话数据,通过注意力机制和层次化的编码权衡和利用两类信息,完成对用户偏好的精细建模;对话模块能够利用推荐模块构建的用户向量表示来生成更加符合用户偏好的回复信息。
5 实验
这一部分将详细介绍与实验相关的细节, 包括数据集的选用、不同任务评测指标的确定、系统实现的具体设定、所采用的基线模型类别, 以及对比实验的结果。
5.1 数据集
本文使用数据集ReDial[5]来对模型进行训练和评测, 这是一个电影推荐场景下的对话推荐数据集,标注者们在一定的指导下进行以电影推荐为主题的对话, 从而生成相应的数据。经过预处理后, 数据集总共有10347 个对话, 每个对话都有相应的电影寻求者和推荐者, 这些对话分别属于738 位电影寻求者, 其中90%以上的寻求者都有5个及以上的对话记录, 为完成个性化对话推荐任务提供了数据基础。
为了缓解推荐中可能遇到的冷启动问题, 并为模型构建可靠的实体向量表示, 本文使用外部知识库DBpedia[26]来构建模型所需的图结构。在完成对话数据集到知识库的实体链接任务后, 共计得到64362个实体, 其中的电影实体有6924 个。
5.2 评测指标
本文采用不同的指标来分别对推荐任务和对话任务进行评测。对于推荐任务, 使用 Hit@K、MRR@K、NDCG@K 来评价系统的表现, 分别反映了推荐结果的命中准确度和排序准确度。对于对话任务, 使用BLEU[30]指标来评价生成的对话文本与目标的相似性, 使用Distinct[31]指标来衡量生成结果的多样性, 以避免生成信息量不大、各处适用的文本。
5.3 实验设定
本文使用CRSLab[8]框架来实现模型, 这是一个基于PyTorch 实现的, 用于构建对话推荐系统的开源工具包, 其提供了易于使用的数据接口和大规模的标准评测机制, 便于对模型进行全方位的评测。
在推荐模块, 将实体向量和用户向量的维度设置为128 维, R-GCN 模块的层数设置为1, 归一化因子Ze,r设定为|r|eE 。训练时的批处理大小设置为2048, 使用Adam[30]优化器进行优化, 学习率定为0.003。
在对话模块, 将词向量的维度定为300 维, 其Transformer 模块编码器、解码器设置为2 头自注意力, 层数为2。从用户向量转化为词偏置的映射F 定义为一个两层的前馈神经网络, 其中间层的大小为512 维。训练时的批处理大小为32, 同样使用Adam优化器进行优化, 学习率设定为0.001。
5.4 对比实验结果
由于本文主要关注对话推荐系统中的推荐模块,故选用如下四个模型作为基线模型进行比较, 来验证PCR 模型在推荐任务上的高效性。
(1) Popularity: 将物品在数据集中出现的次数视为其受欢迎程度, 根据物品的受欢迎程度向用户进行推荐。
(2) AutoRec[31]: 基于自编码器的协同过滤方法。
(3) TextCNN[32]: 使用基于CNN 的模型抽取文本特征来构建用户向量表示。
(4) KBRD[6]: 一个端到端的对话推荐算法模型,其推荐模块结构如图1 右侧所示, 它在构建用户向量时只使用了上下文实体进行预测。而本文的方法则考虑了历史对话中与用户发生交互的物品。
其中Popularity、AutoRec 和TextCNN 为推荐模型, 而KBRD 同时具备处理推荐和对话任务的能力。
下面将列出实验结果, 包括在推荐任务和对话任务中, 本文的方法与基线模型效果的比较。
在推荐任务上的实验结果如表2 所示, 本文使用Hit@50、MRR@50、NDCG@50 三个指标来评价模型的推荐结果, 第一个指标反映推荐结果的命中程度, 后两个指标反映推荐结果的排序精度。可见在三个指标上, 本文的方法相对于基线模型均有所提升, 且显著性统计检验(t-test)结果表明, 本文工作相对于最佳基线模型KBRD 提升效果明显(p-value <0.05)。
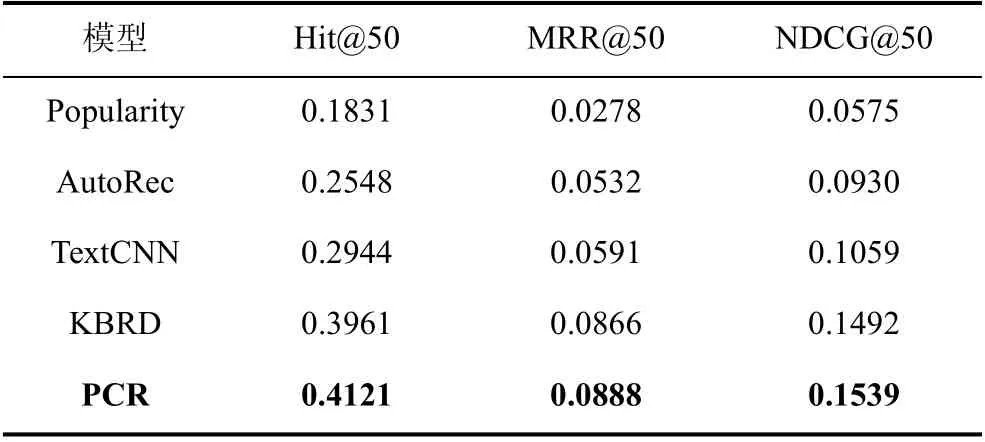
表2 推荐任务评测Table 2 Results on recommendation task
6 讨论
本节将对模型结构的设计、数据集的可靠性和超参数的选取进行讨论。
6.1 模型结构设计
模型的结构实现中有两处最为关键的设计, 一是如何衡量历史对话数据与当前任务的关联程度,也就是说应该采用什么样的注意力打分函数来评估历史物品的权重; 二是如何权衡历史对话数据与目标对话数据的重要性, 本文采用的方法是进行层次化编码。
在注意力机制中,通过注意力打分函数对向量之间的匹配程度进行打分,从而得到注意力分布权重。表3 展示了常见的注意力打分函数,其中x 为输入向量,q 为查询向量,D 为向量的维度,W 为双线性模型打分函数中的可训练权重矩阵。

表3 常见的注意力打分函数Table 3 Common attention scoring functions
本文工作中注意力打分函数的选择并不是一个由经验支配的决定, 而是由实验结果所指引的。为了判断选择何种表达式能够更高效地提取历史对话数据中有用的信息, 仅使用历史物品进行推荐结果的预测。图2 展示了采用不同的注意力打分函数完成这一任务时所取得的评测结果。可以发现, 使用双线性模型时所取得的结果最好。

图2 不同注意力打分函数的表现Figure 2 Performances against different attention scoring functions
在权衡历史和目标对话数据的重要程度时, 本文采取的原则是“目标对话为主, 历史数据为辅”,并设计了层次化自注意力编码结构对各类信息进行整合, 这种设计也来源于实验结果的指引。表4 展示了使用层次化结构和非层次化结构(也就是历史物品和上下文实体直接进行整合)两种方法时, 模型在推荐任务上的表现。

表4 不同编码结构的表现Table 4 Performances against different encoding structure
可见在使用层次化编码结构时, 模型能够更精确地权衡各类信息之间的重要性, 从而得到更准确的推荐结果。
6.2 数据集的可靠性
事实上, 已有的对话推荐系统[5-7]假设数据集中的对话数据是独立同分布的, 而个性化对话推荐任务则要求对话数据是对于用户的条件分布。只有满足后一条件的数据集才能够证实本文工作的有效性,否则本文实验结果中的效果提升可能只是一种假阳性效应。
由于本文所采用的ReDial[5]数据集是由数据标注平台的工人生成的数据, 而非普通用户在不受干预的日常生活环境下生成的数据, 因此, 对话中的信息是否真实地反映了用户内在的兴趣偏好是值得怀疑的。本文设计了一个实验来验证ReDial 数据集中的数据满足对于用户的条件分布。
实验中, 仅使用历史对话数据来预测用户可能喜欢的影片。在对照组中, 保持历史对话数据不变,完全打乱它们对应的目标对话, 再进行预测。如果对话数据符合独立同分布的假设, 则对照组相对于实验组的结果不会有明显的差别; 如果对话数据符合对用户的条件分布, 则对照组的结果相对于实验组应该有明显的下降, 这是因为历史对话数据与目标对话数据所属的用户不一致。
验证实验的结果如表5 所示。对照组的结果相对于实验组发生了明显的下降, 因此数据集可以用于个性化对话推荐任务。实验也间接地验证了本文方法在基于多对话进行用户建模时的有效性。

表5 数据集可靠性验证结果Table 5 Verification results of dataset reliability
6.3 历史对话数量选取
在实际应用场景中, 由于用户的历史对话数量可能非常多, 无法将所有的数据都加以利用。因此,只能选取一定数量以内的历史对话进行利用。
历史对话数量太少可能导致相关信息匮乏, 数量过多会增加系统的计算负担, 甚至可能带来一定的噪音影响。为了确定实验所选用的历史对话数量,需要将其作为变量对系统进行测试, 寻找合适的拐点值作为本文实验所采用的值。
图3 展示了ReDial 数据集中用户的对话数量分布, 展现出明显的长尾效应, 大多数用户的对话数量都在50 以内, 个别用户的对话数量超过了100 个。基于该统计结果, 设置历史对话数量从5~100, 间隔为5, 实验测试不同历史对话数对系统推荐结果的影响。为了避免目标对话信息造成影响, 仅使用历史对话数据进行预测, 结果如图4 所示。

图3 用户的对话数量分布Figure 3 Distribution of user conversation numbers

图4 历史对话数对推荐结果的影响Figure 4 Performances against different historical conversation numbers
历史对话数小于40 时, 推荐任务评测指标与历史对话数呈现正相关关系; 在历史对话数超过40 之后, 推荐任务评测指标呈现不稳定的波动状态。前半部分的结果是符合直觉的, 当历史对话数量越多,能够被利用的历史信息越充足, 对推荐结果的提升作用也越明显。继续增加历史对话数, 信息在变得充足的同时也变得冗余, 甚至引入噪音, 导致推荐结果的准确度在一定范围内波动。据此, 本文的实验选取历史对话数量为40。
7 总结
本文提出了一个面向用户偏好建模的个性化对话推荐算法框架PCR, 它能够甄别用户历史对话数据中有价值的信息, 通过层次化的自注意力编码结构得到用户向量表示, 从而完成对候选物品的排序与推荐。实验结果表明, 本文方法得到的结果在推荐任务和对话任务上相对于基线模型均有所提升。
接下来的工作中, 可以进一步从历史对话数据中挖掘与用户偏好相关的信息, 例如利用更普遍和丰富的文本信息对用户进行建模; 同时引入更丰富的外部信息, 缓解冷启动问题, 并为用户提供更具多样性的推荐结果。
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
疯狂英语·初中天地(2021年11期)2021-02-16
中国外汇(2019年18期)2019-11-25
少年漫画(艺术创想)(2019年2期)2019-06-06
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
高中生学习·高三版(2016年9期)2016-05-14
