
基于虚拟蜜罐技术的互联网攻击特征提取与安全防御
2021-11-09 11:40苏延平
重庆科技学院学报(自然科学版) 2021年5期
苏 延 平
(闽南理工学院, 福建 泉州 362000)
在开放的网络环境下,本地服务器遭受互联网攻击的风险显著增加[1]。尽管防火墙系统[2]和IDS系统(入侵检测系统)[3]能够在一定程度上抵御蠕虫[4]、网络病毒[5]及其他恶意代码的攻击[6],但随着入侵数据规模的不断扩大和病毒种类的不断变异与增多,本地系统安全防御依然会面临严峻的挑战。由于传统防火墙防御技术和IDS入侵数据检测技术,依赖于与病毒特征库中的已有特征码的一一比对[7],这种以后验检测为基础的检测和特征提取方法耗时长、效率低、准确率低,无法做到实时在线监控和防御,恶意网络攻击的风险因素依然存在。针对网络病毒和恶意攻击数据更新迭代快的事实,提出了一种基于优化虚拟蜜罐技术的网络攻击特征提取方法,该方法能够主动捕获进入局域网服务器系统的病毒恶意数据特征码,并提升网络安全防御的整体性能。
1 虚拟蜜罐技术及结构优化
虚拟蜜罐被布置于本地网络系统中,任何针对蜜罐系统的访问都可以被怀疑为攻击,蜜罐防御的价值在于引诱病毒和恶意数据进入系统[8],使系统被病毒和恶意数据攻击,在被攻击的过程中监视、检测并提取攻击者的数据特征码。蜜罐首先可以识别出进入本地服务器网络的攻击对象,获取有价值的信息[9-10],并通过系统防火墙和IDS系统的互动和信息传递,清除恶意数据和网络病毒,保护本地网络和服务器的安全。虚拟蜜罐也是一种虚拟化的技术,蜜罐被布置于网络虚拟机上,主要用于迷惑网络攻击者入侵本地网络,伺机掌握攻击者的特征。虚拟蜜罐通常被布置于防火墙之前,采集与入侵者相关的特征信息,为防火墙和IDS系统捕获病毒和恶意数据提供足够的证据,虚拟蜜罐在网络中的布置见图1。

图1 虚拟蜜罐在网络中的布置图
为了进一步提升防御系统的性能,并有效应对网络攻击病毒的变异,在传统蜜罐防御的基础上,加大了虚拟蜜罐在本地网络中的密度,形成一种防御性更强的密网结构,以提升各虚拟蜜罐之间的信息交互性能。在密网连接模式下,利用VMware软件模拟虚拟网络交换机,再通过主机模拟的方式将所有访问者的IP模拟成公网IP,实现与互联网数据的交互。多台蜜罐主机共同构成密网,密网在对病毒和恶意数据的防御性能上,显著优于传统单一的虚拟蜜罐,密网的网关接口与外网和日志服务器连接,在数据特征共享、传递及同步性能上更强,也具有强大的主动防御性能。基于多个虚拟蜜罐经过优化组合后所形成的密网结构见图2(本文设计系统以3个虚拟蜜罐和2个内部服务器构成的密网系统为例)。
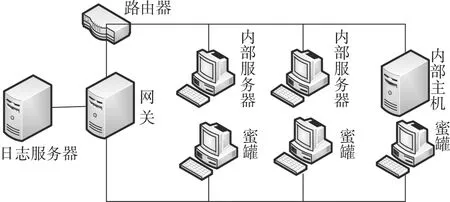
图2 密网防御体系结构优化
密网结构相比于单独虚拟蜜罐更加复杂和高效,能够改善和提升虚拟蜜罐在数据捕获、特征提取及数据分析的能力,尤其在应对不断变种的蠕虫、病毒或恶意代码时具有更高的识别效率和检测效率。
2 基于改进虚拟蜜罐技术的网络攻击特征提取
互联网攻击发生时,密网系统会对攻击者的特征进行内容匹配,由于病毒、蠕虫或恶意代码等攻击者特征都采用二进制序列构成方式,一旦特征匹配成功,该入侵文件即被确定为网络攻击者。攻击特征提取过程分为2个步骤:第1步由密网捕获可疑数据,并提取监测对象的样本;第2步选择合适的特征提取算法实时提取特征,特征提取算法的选择至关重要,会对最终的数据分析和入侵检测结果构成重要影响。密网防御系统的价值在于可以捕获进入本地系统内的全部入侵者,在入侵数据的采集方面借助SEBEK工具,监视进入密网的全部数据,SEBEK工具的一个重要优点是具有良好的隐匿性。服务器端通过内部网络与虚拟蜜罐、防火墙和IDS系统连接,及时清除已被确定的恶意代码或病毒入侵数据。
密网系统在获取攻击数据样本后,需比对和计算出攻击数据序列的特征码,样本特征码作为识别入侵数据的唯一依据,是一组虚拟的二进制序列。假设密网系统捕获了一组数据序列S1、S2、…、Sm:
S1={s11,s12,…,s1n}
S2={s21,s22,…,s2n}
…
Sm={sm1,sm2,…,smn}
(1)
如果在上述数据流中,每个单一的数据序列都包括连续的子序列H={h1,h2,…,hk},则可以定义H是这组包含攻击的数据流的一个特征片段。数据序列的特征片段仅仅是特征码的一个组成部分,无法利用单一的一个特征片段识别入侵数据的特征码,因此特征识别的过程是要提取出包含在改组数据流中的全部特征片段。为保证序列特征码匹配的过程更加完整,采用了一种数据全局联配的算法,提取入侵数据的全部特征片段。全局联配算法模拟了生物信息学中碱基排列规则,从动态视角分析网络攻击者的特征。对于子序列中的任意两个字符x和y,存在一个对应的函数g(x,y)能够表示字符x和y匹配程度的得分,且g(x,y)满足如下条件:
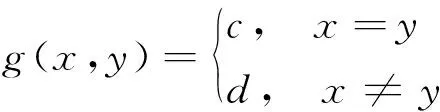
(2)
(3)
在任意选取2组序列的匹配过程中,还有可能会出现这2组序列长度不等的情况,此时需要借助相似度矩阵R完成不等长序列的匹配,如果序列Si和Sj的长度分别为p和q,则相似度矩阵的大小设定为(p+1)×(q+1)。对相似度矩阵R进行初始化处理,初始化的过程描述如下:
R(0,0)=0
R(i,0)=R(i-1,0)+g(Si,0)
R(0,j)=R(0,j-1)+g(0,Sj)
(4)
对相似度矩阵进行填充,以满足不等长序列的全匹配:
(5)


表1 部分字符串联配结果显示
字符串全局联配方法是基于一种动态化的数据分配理念,通过一组数据流中全部字符序列的两两比对,得到最优的全局联配效果,即基于相似度矩阵计算出最高的匹配度得分。由于进入蜜罐系统的一组数据流中序列长度随机,长度可能相等也可能不等,为了便于比对和实现全局范围内的序列匹配,通常以插入空格的方式使序列对齐,每当插入一个空位时,应扣除全局联配的对应分值,以保证相似度匹配的准确性。
由于较短的数据序列的报文在全局比对中并不具有唯一性,当被检测出的攻击特征与子序列一致时蜜罐系统会出现误报,影响到最终的攻击数据诊断。如果在全局比对时序列包含较多的短序列,应采用空位补缺的方式将对比序列的长度调整到一致再进行比对,以降低系统干扰数据和无效数据的产生。此外,数据流中的有效数据序列包含有较多的语义片段,这些零散的片段信息也可表征出入侵数据的部分特征,蜜罐系统能够根据提取到的字节和片段特征对入侵数据的类别作出判断。考虑到当入侵数据集规模较大时,需要降低算法的复杂度以保证特征码提取的效率,此次研究提出在字符串全局联配方法的基础上引入分层比对的方法,提升特征提取的效率。当序列集合被初始化之后,根据既定的序列匹配规则对序列作分类处理,以序列的相似度值来构造一种具有层级性的序列关系,并令经过层层对比后序列相似度集合为U,首次迭代设定n=1,基于层级之间关联性确定比对关系的算法如下:
while |U|>0 do
else
再根据序列之间的相似度值生成最终的比对结果,当迭代次数满足条件n+1>1时,则:
n=n+1;
else
层级式序列比对的优势在于避免了传统字符串全局联配方法下,多次反复比对导致检测效率过低的问题,保留了特征码提取的准确性;此外,层级式比对的迭代过程简单,每一层迭代中产生的冗余数据不会被传递到下一层,解决了入侵数据及规模较大时系统运算时间过长和生成序列码效率过低的问题。由多个蜜罐组成的密网系统,可以采用节点并行计算的方式同时处理进入系统的原始数据,在考虑到确保全部特征码具有唯一性的同时,设置更合理的过滤条件和比对条件,按照重新组合序列匹配程度得分,识别新序列的特征码是否为恶意数据。针对网络攻击者的类别不同,提取样本的间隔、序列长度等各不相同,如面对网络蠕虫使用更简单的空指令,或多态技术即可以准确地提取出攻击者的序列特征码,而针对其他的病毒类别计算方法就相对复杂。在基于多蜜罐的密网防御模式下,利用全局联配和层级序列比对的方法,重新组合并提取数据流中的特征码,进而判断出网络攻击者的特征,保护本地服务器的安全。
3 实验分析
3.1 实验环境搭建
在实验室环境下,以图2的密网拓扑结构为基础搭建实验环境,硬件及配置如下:
攻击端主机配置:Intel Core i 9,主频3.6 GHz,1 TB固态硬盘,16 G内存。
密网主机配置:Intel Core i 9,主频3.6 GHz,1 TB固态硬盘,16 G内存。
蜜罐客户机配置:Intel Core i 5,主频3.0 GHz,500 GB固态硬盘,8 G内存。
实验软件环境设置见表2。

表2 实验软件环境
在设定好的密网拓扑结构下模拟互联网攻击行为,向地址为192.168.54.0的主机网址发送大量的攻击包,密网系统捕获到的网络攻击包括3种:DoS攻击,样本数量为3 215条;Script攻击,样本数量为1 524条;Backdoor攻击,样本数量为985条。正常样本normal的数量为24 276条。
3.2 结果分析
设计的基于多个虚拟蜜罐的密网结构,在应对大规模入侵数据时,具有更强的数据处理性能。从捕获到的样本集合中,随机选择70组数据序列,观测和对比本文设计的密网技术与传统单一蜜罐技术,在3种互联网攻击下入侵数据序列特征的匹配度得分情况见图3 — 图5。

图3 DoS攻击下入侵数据序列特征匹配得分

图4 Script攻击下入侵数据序列特征匹配得分

图5 Backdoor攻击下入侵数据序列特征匹配得分
对3种互联网攻击病毒数据序列的匹配情况分析可知,密网的序列匹配分值可以保证在90分以上,且未出现较为剧烈的波动;而传统单一蜜罐技术的匹配得分在75分左右,在处理DoS攻击时随着样本总量的增加,匹配分值出现了下降的趋势,而在处理Script攻击和Backdoor攻击时,匹配分值都出现了不同程度的波动。3种互联网攻击特征提取算法耗时情况见表3。

表3 提取互联网攻击特征的耗时
最后,验证文中提出的基于多个虚拟蜜罐构建的密网的安全防御性能,评价指标选择recall(召回率)、precision(准确率)和FAR(误报率)这3个指标,指标的定义如下:
recall=TP/P×100%
(6)
precision=TP/(TP+FP)×100%
(7)
FAR=FP/T×100%
(8)
式中:T为待检测数据中全部为真实数据的数量;P为待检测数据中全部为攻击数据的数量;TP为检测出为正确数据的数量;FP为被系统错误判定为攻击数据的数量。
将包括正常数据在内的全部捕获到的30 000个数据样本随机分成10个组,检验基于密网技术的网络防御性能,统计分析结果见表4 — 表6(为使指标统计结果更为直观和客观,引入了同等条件下,传统防火墙和IDS模式下的3种指标数据值)。
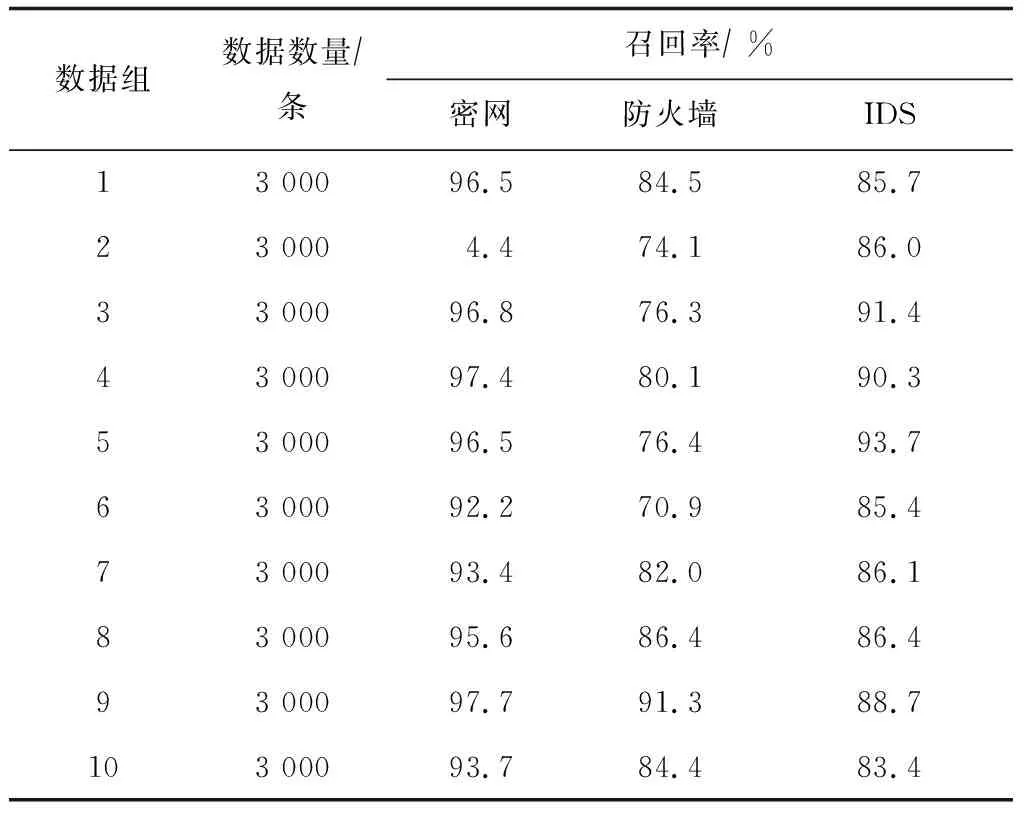
表4 recall指标统计结果

表5 FAR指标统计结果

表6 precision指标统计结果
实验统计数据的结果显示,无论是传统的防火墙防御还是IDS防御,recall和precision都偏低,均值未超过0.9,相反,FAR过高表明传统算法在应对大规模入侵数据时的防御能力偏弱。而密网防御系统在应对网络攻击时,3种指标数据明显增加,证明基于虚拟蜜罐技术的网络安全防御系统具有更高的安全性。
4 结 语
随着互联网开放程度的不断提高,各种网络攻击方式也在变异和更新迭代,给传统基于被动防御方式的网络安全防御系统带来新的挑战。探讨了在现有虚拟蜜罐技术的基础上,在本地服务器网络中引入多个蜜罐,实施同步防御策略,形成较为完善的防御网络。基于优化的全局联配的算法提取入侵数据流中的特征码进行比对,以便准确地识别出攻击者的特征。实验分析结果证明,虚拟密网技术具有更高的特征提取效率和防御性能。
猜你喜欢
现代电子技术(2022年11期)2022-06-14
计算机与网络(2020年21期)2020-04-01
中学时代(2019年9期)2019-11-13
中外文摘(2019年20期)2019-11-13
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
知识窗(2019年6期)2019-06-26
爱你·心灵读本(2018年6期)2018-09-10
爱你(2018年16期)2018-06-21
