
语音识别系统在山西方言中的实现与应用∗
2021-11-08 06:23:02余本国郇晋侠刘晓峰高伟涛
计算机与数字工程 2021年10期
余本国 郇晋侠 刘晓峰 高伟涛
(1.中北大学软件学院 太原 030051)(2.海南医学院医学信息学院 海口 571199)
1 引言
随着计算机科学技术发展,智能产品陆续实现了普通话的或孤立词,或大量连续语音的识别功能并被广泛地应用于各个领域中,例如:教育的同声传译、生活的智能家居以及基层公安的警务等。但是要实现大量的方言语音识别,当前还有很多的挑战目前人机交互已经取得了显著的成功,例如科大讯飞、百度等公司对各地方言库的建立、自媒体中对方言的传播以及藏语等少数民族的方言收录。目前,最为常见的语音识别模型主要有高斯混合模型-隐马尔可夫模型(GMM-HMM)和深度神经网络-隐马尔可夫模型(DNN-HMM),而针对HMM的开发工具有两个,即美国约翰·霍普金斯大学开发的Kaldi和英国剑桥大学开发的HTK[1]。
2 山西方言概括
2.1 山西方言的作用
根据国内方言分布情况将31省划分为九个方言区域[2]。山西地域复杂,虽然,地处华北平原西面的黄土高原上,属于北方方言区,但是,山西方言属于“晋语”,中国北方唯一的“非官话”语言。针对山西各地方言建立一个相应的语音库即研究山西语言的缘起和发展,将这些地方特色语言用库的形式保存下来,从而方便对当地文化和语言做研究以及更好的沟通交流。同时,建立的方言库可以应用于本地的教育以及公安局破案等方面。
2.2 山西方言的特色
在《中国语言地图集》中李荣先生将汉语方言划分为官话区等十个大区,晋语成为独立的方言区。山西方言还在使用的最多的是名词和动词,其次是形容词,涵盖社会各个层面。目前还在使用的部分方言发音如下:
名词:“胰子”(香皂)、“记性”(记忆力)等;动词:“圪蹴”(蹲下)、“抠搜”(吝啬)、“锄倒”(摔倒)等;形容词:“摆到”(不知道)等。
2.3 当前研究方言现状与应用
2.3.1 研究现状
方言有着多杂乱的特点,光语音采集就是一个巨量的工程。文献[3]使用了基于DTW算法的HMM模型,针对于当地孤立词的识别,但是对于大量的连续语音识别效果不理想。文献[4]构建了一个深度神经网络,词错误率下降,但是运算时间和成本较高。
本文选择传统的GMM-HMM模型,从方言的语音特征入手,收集山西朔州语音语料,建立和训练模型,实现朔州的方言语音识别。实验数据表明,对于小区域差别小的方言地区,GMM-HMM模型识别率较好且方便快捷。
2.3.2 应用
目前,公安的安全领域系统都配备了普通话的语音识别系统,用于平常的警务工作,例如:对犯罪嫌疑人和外来人口的身份以及归属地的确认。但是日常交流使用方言,普通话的语音识别对方言识别率较低,人机交互低,对工作的效率影响较大,因此本文研究方言识别用于地方,加快办案效率和提高人机交互。
3 山西方言语音识别概括
3.1 语音识别原理
普通话的识别系统主要涵盖如下几个部分。首先,将原始的信号转换成为离散信号。其次,预处理离散的信号并提取特征向量。然后,依靠大量的语音语料、标注文件和词典(Lexicon),训练各个模型参数,结合特定的模型算法,求得每个模型的参数。最后,在识别阶段,使用模式匹配算法,以得到的概率大小判断语音对应的文本[5]。图1是普通话语音识别图。

图1 普通话语音识别图
山西方言语音识别,于方言有自身独特的属性,在连续的语音识别中,需要做大量的标注工作。本文处理方法是建立一个自适应词典,将声韵母与汉字一一对应以达到一个标注的过程。图2是本系统方言语音识别图。
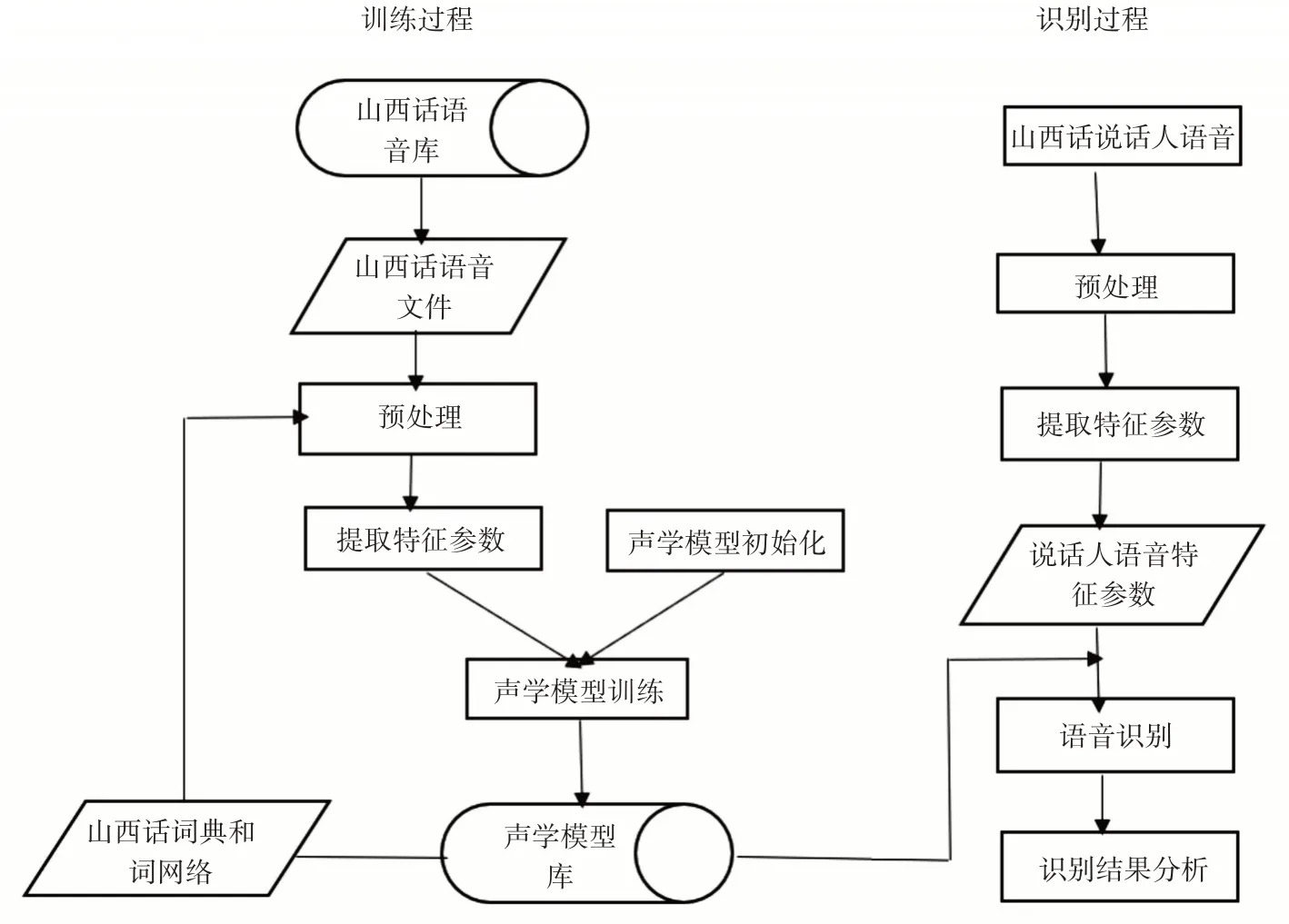
图2 方言语音识别图
3.2 预处理
由于所录制的语音环境不佳等因素,往往伴随着一些杂音,这些因素对语音识别单位效果产生了很大的影响。因此要对输入的语音信号首先要进行预处理来消除无用语音的干扰;然后进行数字化,将模拟信号转化为数字信号以便用计算机来处理[6],最后进行预加重、分帧加窗等操作。
1)预加重。在低频到高频的一段范围内,高频部分会随影响跌落。因此,使用信噪比计算和分析频谱时,升高高频部分,使信号的平铺变得平整。其公式为
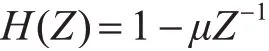
2)分帧加窗。语音信号具有短时平稳性,为得到短时的语音信号,先将语音信号采样点量化成一个观测单位,再乘以汉明窗,以增加帧的左右端连续性。为防止相邻帧变动过大,让邻帧之间有一段堆叠区域,此堆叠区域包含N个取样点,通常N的值约为采样点个数的1/3或1/2[7]。
3.3 特征参数
特征参数提取方法主要有以下的三种类型,基于线性预测的倒谱系数(LPCC)分析法,基于Mel系数的Mel频率倒谱系数(MFCC)分析法和基于现代处理技术的小波变换系数分析法[8]。由于人耳的特殊性,特征参数的选择取决于是否接近人耳的感知特性[9]。因此,人们提出Mel频率[10]来反映人耳对语音的感知状况。又由于MFCC有较强的稳健性,可以在嘈杂的环境下提取到稳定的数据,所以本文选择使用MFCC提取特征参数。图3是Mel频率和线性频率的关系,从图中可以看出,它可以将不统一的频率转化为统一的频率,也就是统一的滤波器组。Mel频率计算公式:
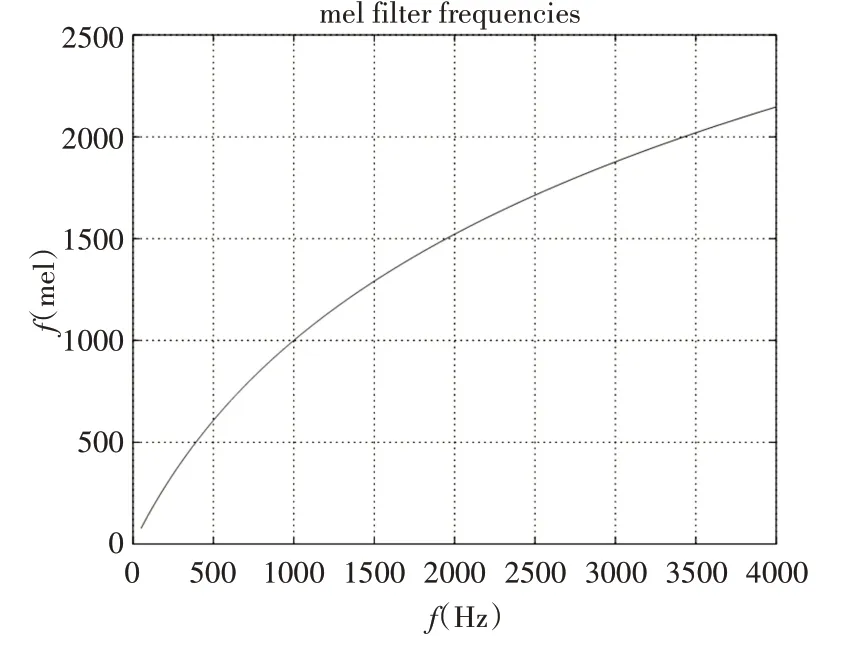
图3 Mel频率和线性频率关系图
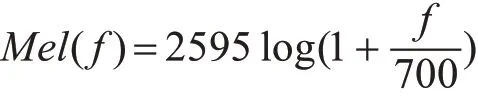
注:f为原始语音信号的频率。
3.4 声学模型
在语音识别过程中,声学模型是语音识别系统的重要组成部分,它占据着语音识别大部分的计算开销,决定着语音识别系统的性能[10]。诸如隐马尔科夫模型(Hidden Markov Model,HMM)、人工神经网络(Artificial Neural Network,ANN)等各种方法生成的声学模型效果不一。HMM已经在传统的ASR(Automatic Speech Recognition)中使用[11]。根据山西方言情况选择GMM-HMM作为模型。
HMM是在马尔可夫链上发展形成的,但是实际问题更为复杂,观察到的事件并不是与状态一一对应,而是由一组概率分布联系在一起[12]。
GMM-HMM是一个统计模型,描述了两个相互依赖的随机过程,一个可观察的过程,另一个隐藏的马尔可夫过程。观察序列被假设是由每一个隐藏状态根据混合高斯分布所生成的[13]。一个GMM-HMM模型的参数集合由状态先验概率、状态转移概率以及状态相关的混合高斯模型参数三部分组成。
3.5 语言模型
语言模型(language model,LM)广泛用于机器翻译、方言识别、语音合成中的自然语言处理。n元语法模型(n-gram)最为常见。在方言语音识别中,可以选择的基元包括词(word)、声韵母(ini⁃tialfinal)和音素(phone)等。
4 HTK工具基本介绍
为了研究和使用隐马尔可夫模型(HMM)的相关实验,英国剑桥大学特定开发了HTK(Hidden Morkov Model Toolkit)工具。它广泛应用于语音合成、方言识别和DNA排序等领域。不过HTK主要用以构造基于HMM的语音识别工具。语音识别技术主要有语音识别单元的选取、模式匹配准则、特征提取技术以及模型训练这四个方面。语音识别系统主要包含语音特征参数的数据准备模块、模型训练模块、模型分析模块和语音识别模块[14]这四个模块。如图5所示,它主要有两个处理阶段。第一阶段,HTK训练工具使用训练语音语料和对应的标注文件来训练HMM模型集的参数;第二阶段,通过使用HTK识别工具来识别未知的语音语料[15]。

图5 参数内容
5 方言语音识别的设计与实现
本文中的语音识别系统是在Windows10平台上使用HTK v3.4工具包开发的。以山西朔州为例,使用1000条方言词句用于模型的训练。
5.1 语音库建立
“一切后续相关ASR的研究,都必须严格筛选有序的语音语料入库”[16]。建立一个语音语料库必须要做好如下的工作:科学的划分方言区域、确定录音人和相关设备、设计发音语料、对录音进行保真处理、对语音语料进行标注。
5.1.1 科学的划分区域
朔州方言的语言特性逐渐从历史、社会以及地理等因素演变而来的。根据《朔州方言志》,朔州分为六区县。在已知的地域方言中,平鲁区话和朔城区话大致相同,将平鲁区和朔城区的的统一处理,使得口音划分更加合理。在对朔州不同口音进行地区录取,结合所划区域,录音人大体分布在朔城区、怀仁县、右玉县、山阴县、应县这五个区域。由于普通话受到城镇化的影响,一些重要的方言特殊词难以听到,所以录音人大多选择口音浓重村乡的成年人或者青年人。
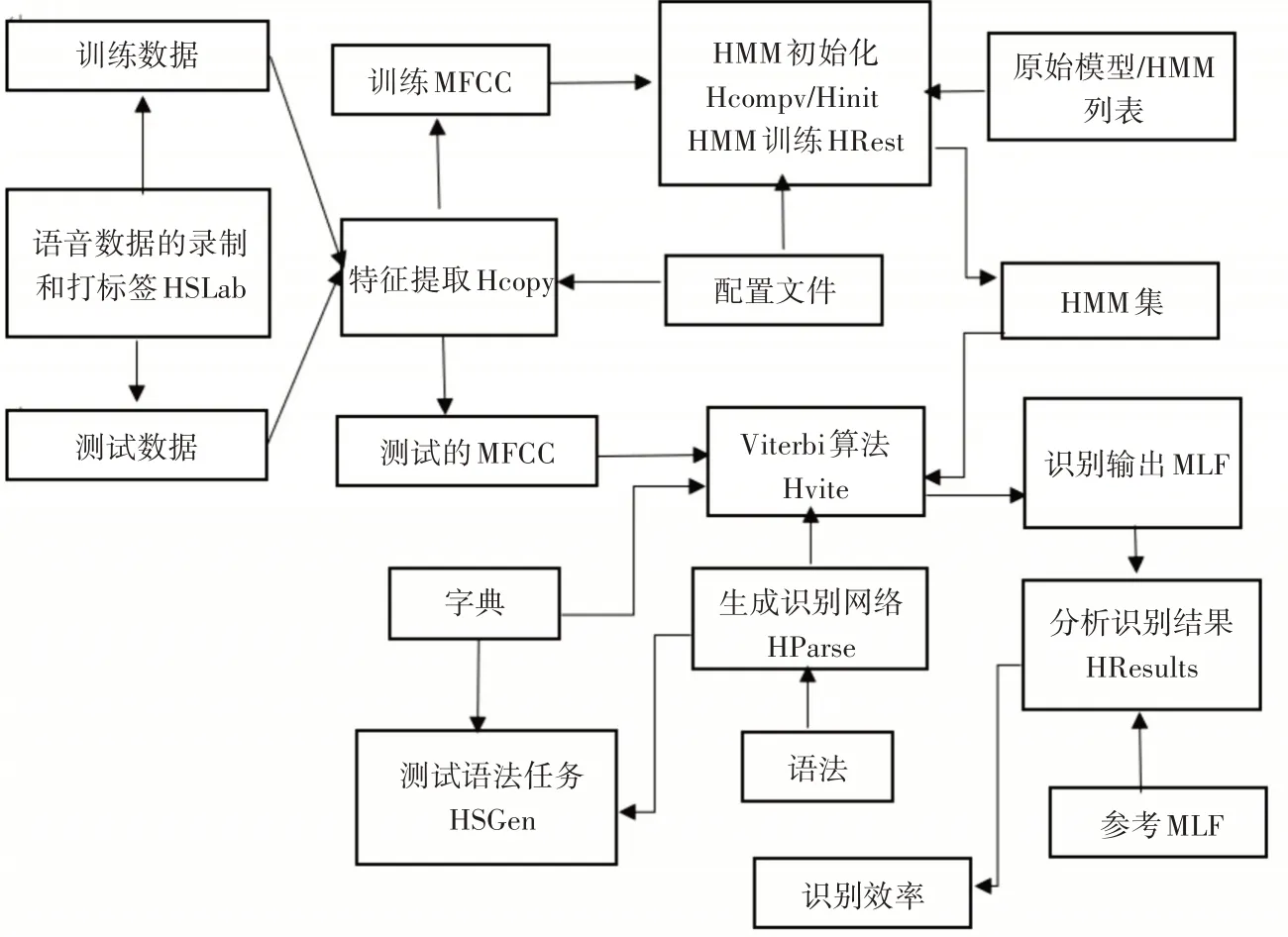
图4 HTK处理阶段
5.1.2 音语料的设计
在各地方志中,记录了很多具有地方特色的方言,并给出了一些语言现象的解读。为了对比研究方言与普通话发音的出入,进一步研究系统的方言,通过查阅《朔州方言志》,发现方言大体有二十个声母,包括零声母在内;有三十八个韵母,根据《朔州方言志》中的声韵母表,将不同发音人的录音进行筛选和微调,语音语料尽可能多地囊括词汇,达到数据库的完整性。
5.1.3 注
在识别过程中,就是使用Viterbi算法在所有搜索树路径中找出权值最高的候选路径[17]。但是方言与普通话在个别字词会产生音节的混乱,这时候要用标注语音达到搜索目的。
在文献[18]中,介绍了COCOA((Oxford Con⁃cordance Program)模式,但COCOA只能用来标注有限的语篇信息;在文献[19]中,标注闽南话,所以选则了台湾注音TLPA;清华大学数据集thchs30中标注情况,是采用国际音标(IPA)+声调标注方法,其中声调采用数字1、2、3、4、5,代替《汉语拼音方案》中声调阴平(ˉ),阳平(ˊ),上声(ˇ),去声(ˋ),轻声(不标调)这几个标调符号。
山西朔州六区县,同闽南情况差别大,由于山西朔州方言的多样性,产生了多发音映射关系,参照清华大学数据集标注情况,采取采用拼音+声调变化相结合的方法进行研究。通过整理发音规律,将标准普通话中的发音音节与方言的音节进行替换,在标准的词典中加入自适应的朔州方言音节,构成朔州方言的自适应词典(Lexicon)。表1是普通话和带有山西朔州方言音节的部分替代关系。
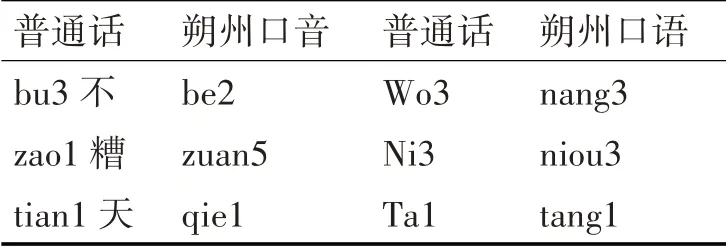
表1 普通话和带有山西朔州的部分替代关系
5.2 特征参数提取
在本系统中,采用的特征参数为MFCC(Mel Frequency Cepstral Coefficient),MFCC是Mel倒谱系数。在HTK中,使用HCopy工具,通过把每一个语音文件转换成MFCC文件的方式将语音特征参数提取出来。在本系统中,各种参数内容如图6所示。
5.3 模型训练
在模型开始训练前,初始化模型的参数并不重要。必须在训练之前根据训练数据正确初始化HMM模型参数[20]。通过使用HTK提供的训练工具:HInit/HRest或HCompv,初始化和迭训练模型,直到收敛。训练的样本与迭代次数成正比,样本越多,迭代次数越多,训练的模型也就越稳定。
5.4 模式识别与分析
在已有的gram、自适应Lexicon和HMM模型的基础上,调用HVite识别器进行识别,然后可以将识别后的结果放在MLF文件中。然后,调用HTK提供的HResults,将所有测试语料正确音节标注的参考MLF文件和识别器输出的MLF文件进行比较,计算出相关参数以及识别率[21]。
5.6 实验结果分析
为判断训练的模型是否具有好得鲁棒性和识别率,进行如下测试:分为两组,一组是理想环境下(实验室内),一组为噪音环境(实验室外),14人(7男7女),在朔州方言的语音数据库中,随机挑选100条具有地方方言特色的词句放入模型中,识别率只有53.6%。随着加大方言的词句和标注信息放入本方言模型中训练,实验结果逐渐上升;HMM模型识别率具有很好的稳定性,但噪音环境与理想环境识别率存在差别。测试结果如表2~表3。
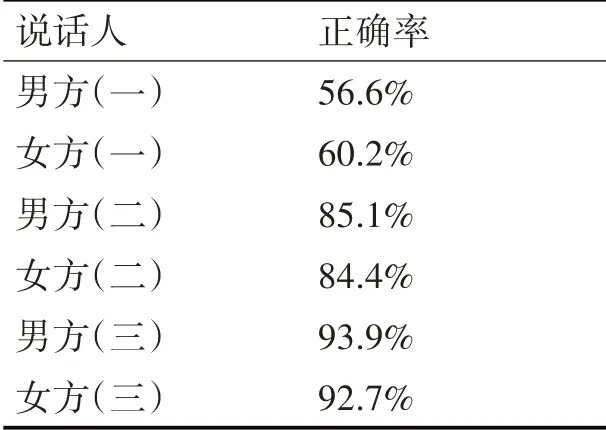
表2 理想环境下测试结果
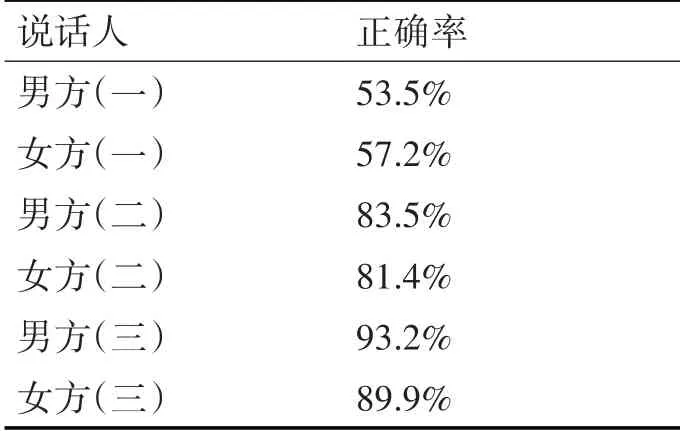
表3 噪音环境下测试结果
6 结语
本文将朔州方言语音进行预处理、特征参数提取后,建立了方言词汇的自适应词典(Lexicon)和HMM模型,采用HTK对山西当地方言的语音识别进行系统设计与实现。实验数据表明,男女发音的识别率会有不同,识别的效果也随数据量的增加而逐渐提高。但是,各地方言口音不同导致训练的模型识别率不同;HTK中语法gram需要穷举,更适应于小范围识别。在未来的工作中,应建立完善的山西方言语言语料库和完整的训练模型库,以实现整个山西方言的语音识别。
猜你喜欢
中国特种设备安全(2021年5期)2021-11-06 05:09:00
今日农业(2021年14期)2021-10-14 08:35:50
装备制造技术(2021年4期)2021-08-05 07:39:54
计算机工程(2020年3期)2020-03-19 12:24:50
今日农业(2019年11期)2019-08-15 00:56:32
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
中国交通信息化(2018年3期)2018-06-13 03:27:58
制造技术与机床(2017年11期)2017-12-18 06:46:39
中国交通信息化(2016年2期)2016-06-06 07:28:02
化工矿产地质(2015年3期)2015-12-04 02:09:40
