
基于大数据技术的区域煤矿监管数据服务平台设计
2021-11-05 11:40孟光伟
工矿自动化 2021年10期
孟光伟
(中煤科工集团重庆研究院有限公司, 重庆 400039)
0 引言
煤矿生产信息化系统的广泛应用及各级煤矿安全风险监测预警系统的建设大大提升了煤矿的安全生产信息化水平,有效提高了安全监管机构对煤矿安全生产的监管能力,促进了煤矿企业安全健康发展[1]。但因各煤矿监测监控系统数据通信协议和数据格式种类繁多,存储方式多样,煤矿安全风险监测预警系统联网数据难以实现数据格式的统一和一体化存储[2]。随着智能化煤矿建设的逐步推进,特别是高频采样传感器的应用和精确定位服务系统的建设,煤矿监测监控系统终端设备数量不断增加,采集的测点数据呈现爆发式增长,数据采集上传和存储的难度进一步增大[3-4]。而目前监管监察平台侧重于煤矿安全生产监测监控数据的过程监测和简单统计分析,缺少对异构系统数据的融合分析和多层次挖掘,难以满足当前煤矿智能化监管监察的应用要求。煤矿安全风险监测预警系统数据上传、存储和分析计算、数据共享面临着一些新的问题和挑战,主要体现在以下方面:
(1) 大多数数据传输协议存在点对点传输、传输数据量小和解析规则复杂的问题,数据完整性难以保证,容错机制繁琐、低效,无法适应当前智能化煤矿建设下大规模数据实时高速上传的要求。目前有些数据联网系统虽然已使用了基于消息队列的传输服务,但仍存在跨平台、可扩展性差、数据传输效率低等问题[2]。
(2) 由于各异构系统数据的结构和存储方式多样,单一的数据存储方式和计算资源已无法满足实际需求,而安全监管机构也普遍缺乏基础存储和数据计算资源,难以对海量多元数据进行长期可靠存储和实时分析处理,数据整合利用和共享难度大,无法满足安全监管机构的数据关联分析、数据挖掘和预测决策等方面的需求。
(3) 各级安全监管机构数据需求的差异性导致监测监控数据层层过滤上传,进而出现各级单位数据不一致、数据可靠性和安全性差、异常数据溯源困难等问题,增加了监管成本[5]。
为解决当前煤矿安全风险监测预警系统面临的问题,满足智能化监管的需求,笔者深入研究了Kafka分布式消息队列,利用Hadoop大数据平台及Spark Structured Streaming流式计算引擎设计了区域煤矿监管数据服务平台,通过统一的数据存储、数据分析计算和共享服务,为各级安全监管机构个性化的数据业务需求提供技术支撑。
1 相关技术
1.1 Kafka分布式消息队列
Kafka是基于Zookeeper协调服务的分布式消息队列系统,其核心功能为高吞吐量的发布-订阅消息服务,主要应用于日志收集和消息队列服务,可在廉价的商用机器上实现数据的高吞吐和高可用[6]。Kafka分布式消息系统主要由消息生产者(Producer)、消息消费者(Consumer)、消息代理者(Broker)及提供分布协调服务的Zookeeper组成。Kafka系统架构如图1所示。
消息生产者将产生的消息推送到Kafka集群, Kafka集群由若干Broker节点构成,用于在物理空间存储接收到的消息数据。Kafka中1组消息抽象归纳为1个主题(Topic),每个主题又被分为1个或多个分区(Partition),单个分区只能位于1个Broker节点中。分区由一系列有序、不可变的消息组成,这些消息被连续追加到分区中,同时Kafka为每条消息分配1个连续的偏移量(Offset),用于标志该消息。
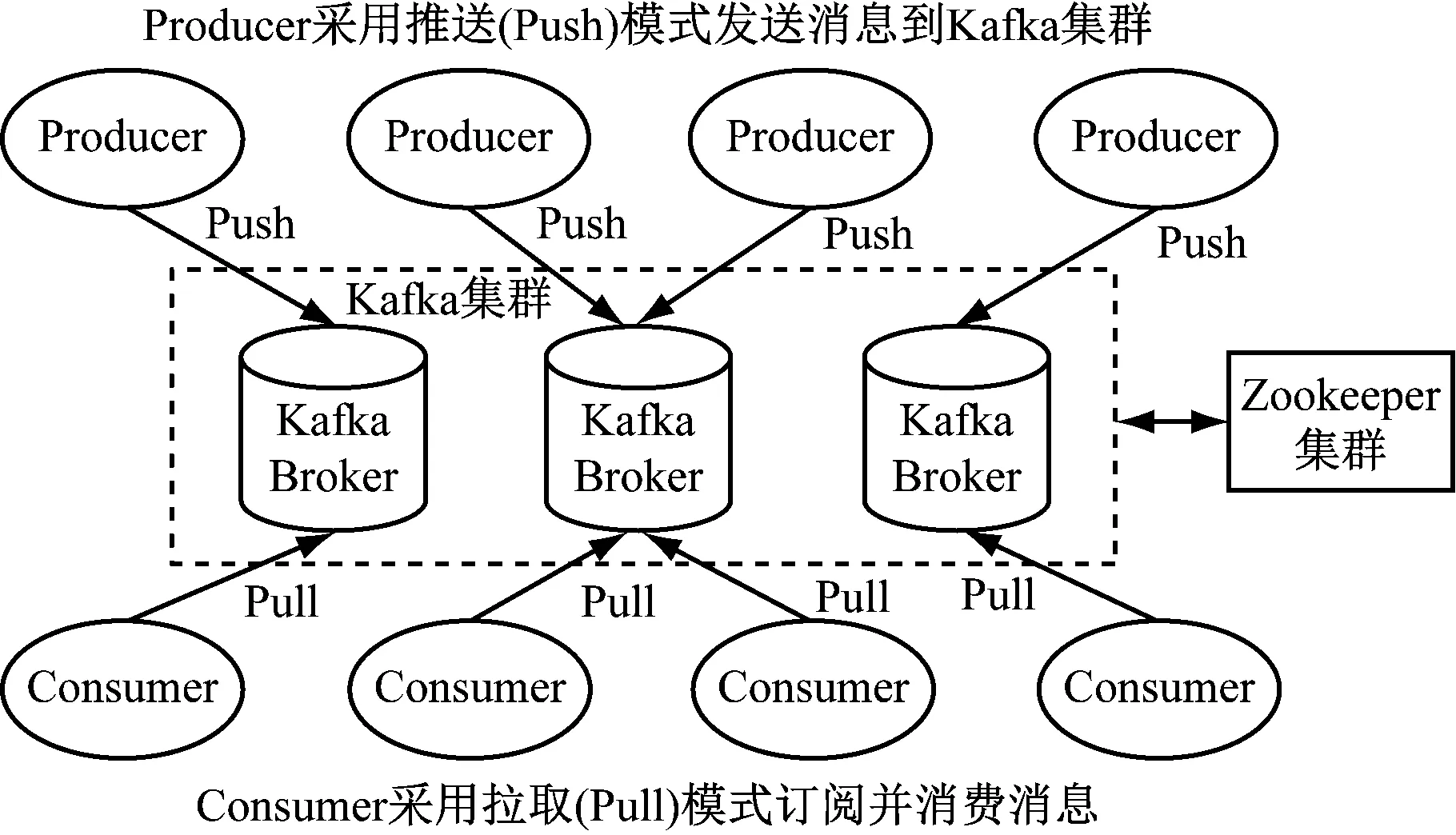
图1 Kafka系统架构Fig.1 System architecture of Kafka
消息消费者订阅消息主题后从Kafka中批量拉取数据并更新分区数据消费偏移量,单个消费者从属于消费者组(Consumer Group),不同消费者组可重复消费主题中的数据。Zookeeper集群负责管理Broker节点动态变化信息,维护Broker和Topic之间的关系,同时为生产者和消费者提供一定的负载均衡服务[6-7]。
1.2 Spark Structured Streaming流式计算框架
Spark Structured Streaming是基于Spark SQL引擎构建的可扩展、高容错的批流一体处理引擎,采用逐步递增的方式处理不断到达的流数据,其关键思想是将持续不断的流数据当作一个不断追加的表,在无界表上不断操作增量数据进行计算,使用类似操作静态表的批处理方式来处理流数据,使得流式计算模型与批处理计算十分相似[8]。
Spark Structured Streaming基于数据流的事件时间(EventTime)来处理数据,使用微批处理(Micro-Batch)将数据流计算任务分为一系列小批处理作业,有效利用Spark SQL引擎中各种数据处理函数,在内存中操作数据表,达到并行高效计算的目的。
2 平台设计
2.1 平台架构设计
基于大数据技术的区域煤矿监管数据服务平台综合利用云平台提供的动态可扩展数据存储计算资源及安全认证管理机制,通过大数据处理技术实现海量数据分布式存储和高效计算服务,为用户提供统一安全权限认证和数据消费服务[9]。平台根据分层设计的思想,依次分为数据采集层、数据传输层、数据计算层、数据存储层、数据服务层,平台架构如图2所示。
(1) 数据采集层按照数据交互标准协议,采集区域内煤矿的安全监控、人员定位、重大设备监控等系统数据,对采集到的数据进行数据去重、数据完整性校验及无效数据去除等初步处理,按传感器编号或设备标志进行统一编码,生成统一规范数据体。

图2 基于大数据技术的区域煤矿监管数据服务平台架构Fig.2 Architecture of regional coal mines supervision data service platform based on big data technology
(2) 数据传输层主要由矿端数据传输服务及Kafka集群构成,负责将处理后的数据体封装为Kafka消息对象,并发送到云平台Kafka集群。为提高传输效率,矿端数据传输服务将一段时间内同一传感器产生的实时数据压缩并封装为数据包。数据传输服务在网络异常和网络拥挤情况下可进行本地缓存,将待上传数据通过文本文件写入本地磁盘,待网络恢复后批量上传。Kafka集群同时接收多个矿端数据传输服务发送的消息数据,持久化到Broker节点磁盘空间,为保证消息数据存储空间的动态扩展,同时避免数据倾斜,数据传输层利用Kafka集群的Broker动态增加和分区再平衡策略,通过脚本实现Broker节点的动态添加和分区数据的定期再均衡[6]。
(3) 数据计算层利用Spark Structured Streaming流式计算框架,实时消费Kafka各主题消息数据。一方面,将解析得到的原始数据持久化到历史数据库HBase;另一方面,为进行数据分析计算,例如报警数据实时统计、设备异常状态关联分析、瓦斯浓度实时预测等,集成Spark MLlib(机器学习算法库)、分布式深度学习算法库Deeplearning4j及自定义算法模型来实现数据挖掘、多维分析、预测决策等相关需求。
(4) 数据存储层由关系型数据库、非关系型数据库及数据仓库组成,通过各类标准化数据驱动对外提供数据读写服务。其中非关系型数据库HBase采用分布式列式存储机制,通过持续写入监控类系统的海量历史数据,为历史数据的批量查询和分析计算提供数据支撑[10-11];数据仓库工具Hive中数据表与HBase中数据表进行映射,利用Spark SQL生成Spark内存计算任务来实现历史数据的高效关联查询、统计分析[12-13];关系型数据库MySQL则保存监控类系统元数据、数据计算层部分计算结果及数据服务应用数据,通过标准化SQL接口实现结构化数据的快速检索。
(5) 数据服务层依托数据存储层和Kafka集群构建数据服务,包括管理实时数据服务接口、历史数据查询接口、各类分析计算配置与数据消费接口,以及满足安全监管机构业务需要的统计报表和数据可视化页面,通过统一安全认证和权限分配为用户提供数据消费和可视化服务。
2.2 数据处理
平台各层数据的处理按流转顺序大致分为数据采集、传输、计算、存储及数据应用,最终将结果数据以服务形式供用户消费。平台下层为上层应用提供数据支撑,同时对上层屏蔽了数据处理的业务逻辑。平台数据处理流程如图3所示。

图3 数据处理流程Fig.3 Data processing process
2.2.1 Kafka消息数据生产与消费
矿端数据采集软件通过文本文件、OPC(OLE for Process Control)等方式采集矿井安全监控、人员定位、重大设备监控等系统的元数据和实时数据并进行处理后上传云端Kafka集群。针对元数据,采用增量采集方式,每次启动时全量采集,此后待数据变化时采集最新变化的数据;针对实时数据,则按定义的采集范围和频率进行持续采集。采集程序根据统一编码规则对采集测点进行编码定义,保证区域内煤矿各传感器和设备的编码唯一,为数据统一存储和共享提供保证。为提高消息数据的吞吐速率,节约存储空间,Kafka集群Topic按数据来源和类型进行划分,如安全监控测点元数据Topic、安全监控分站元数据Topic、安全监控测点实时数据Topic、人员定位实时数据Topic等,各Topic可根据数据的量级和时效性设置不同的分区数量和消息过期时间。
消息数据的消费者为数据计算层的流式内存计算引擎及数据服务层的数据订阅接口。为提高数据消费效率,消费者组设置多个消费者批量拉取Topic各分区数据,将消费者的消费进度Offset信息保存到系统指定Topic中,保证了系统故障恢复后消费者从指定的Offset处继续消费。各级安全监管机构可根据自身业务需要,通过Kafka数据订阅接口,自定义消费规则,获取监测监控实时数据和元数据。
2.2.2 数据计算与存储
数据计算层中,Spark Structured Streaming读取Kafka集群中消息数据进行解析,将得到的测点数据根据其事件时间生成数据集(DataSet),利用Spark SQL对数据进行预处理。除常用的Spark SQL函数外,可根据业务需求自定义Spark SQL函数,实现测点原始数据的数据去重和错误数据标记,并将预处理后的测点实时数据写入历史数据库HBase中,将变化的测点元数据更新到MySQL。
Spark Structured Streaming为进行分析计算服务,根据消费者提交的计算任务配置信息,生成批/流处理任务。读取HBase中测点历史数据或Kafka中有效期限内的测点实时数据,依据计算规则选择Spark MLlib中机器学习算法或者Deeplearning4j中深度学习算法,也可根据需要集成自定义数据分析算法模型[14]。以某矿井10 min瓦斯浓度预测为例,首先Spark Structured Streaming根据提交的计算请求初始化流处理任务,获取当前微批任务时间窗口Kafka中对应瓦斯传感器前2 h历史监测值,对生成的DataSet去除错误数据后排序,利用k最近邻填补法进行缺失值填充,形成瓦斯测点前2 h的30 s均值数据;之后使用Holt-Winters三次指数平滑函数预测未来10 min 该测点的30 s均值,并将预测结果写入Kafka中。
对于历史数据的统计分析,例如井下人员出勤统计、瓦斯数据趋势变化、监控数据异常报警分析,利用Spark Structured Streaming批处理模式读取Hive中主题数据表,使用Spark SQL对各类型数据进行多维度统计、规律挖掘和关联分析,将结果输出到Hive中。
2.2.3 数据订阅服务
为安全可靠地对外提供各类数据消费服务,设计了数据订阅服务应用,对数据服务接口和数据消费者进行统一管理和安全权限认证,主要由以下模块构成。
(1) 权限认证管理模块。用于管理外部数据消费者,为其分配数据服务消费权限。数据消费者根据系统返回的数据消费凭证和访问方式,在时间期限内实现对指定数据和数据可视化服务的消费。
(2) 服务管理模块。用于动态注册和发布各类数据服务接口和数据可视化页面的访问路径,包括Kafka数据订阅接口、分析计算任务配置和结果数据消费接口、历史数据查询接口、元数据查询接口、统计分析结果的图表、报表页面的URL路径。对Kafka、MySQL、Hive及HBase等工具对应的API或连接驱动进行集成和封装,在应用层形成标准化数据操作接口,以SDK(软件开发工具集)形式对外提供,为外部消费者提供简单、可靠的安全认证和数据订阅、消费服务。
(3) 基础信息管理模块。管理矿端数据采集基础信息并监控数据传输链路状态,方便管理人员掌握区域煤矿监控类系统联网数据采集传输情况。
(4) 数据展示模块。对煤矿监控类系统基础数据、实时数据和报警信息、统计分析和预测预警结果通过多种图表方式进行综合展示,提供多种业务数据统计报表,具有权限的消费用户可方便进行集成,减少自身业务系统开发工作量。
3 平台分析及应用
基于大数据技术的区域煤矿监管数据服务平台具有以下特点:
(1) 利用分布式大数据集群统一存储区域内煤矿安全生产监测监控数据,降低了各级安全监管机构资源投入和维护成本,避免了传统存储平台单点故障带来的数据丢失风险。同时基于云平台的存储和计算资源可按需求动态扩展,满足了海量数据长期可靠存储和高效计算的要求,为智能化监管监察所需的数据融合、数据关联分析、深度挖掘以及智能决策支持提供了数据基础[15-16]。
(2) 利用Kafka消息队列的数据高吞吐性能,实现了大规模数据的高速上传和高效处理。 采用Kafka发布-订阅模式,实现了数据的按需消费,减轻了网络传输开销,也避免了联网数据多级上传和过滤带来的不利影响。
(3) 通过Spark Structured Streaming流式处理框架,满足实时数据的流式计算要求和历史数据统计分析的批处理要求,提高了海量数据的处理效率。各类数据分析算法、机器学习算法和深度学习算法的集成,为数据挖掘、推理分析和预警决策提供了支持。
(4) 利用HBase分布式列存储数据库,满足了各类型监测数据的高效读写要求。通过与之关联的Hive数据仓库,方便建立各类专题数据模型库,提高了数据多维度关联分析和数据挖掘能力。
(5) 平台具有统一的SDK,便于数据消费者进行安全权限认证、配置分析计算任务、获取各类数据消费服务和集成可视化页面,降低了用户业务系统实现的复杂度。
(6) 将后台数据服务中心与前端监管监察业务系统解耦,通过数据服务为各级监管机构提供数据定制和消费服务,提高了数据利用效率。
区域煤矿监管数据服务平台中数据存储和分析计算服务已在青海省煤矿事故风险分析平台项目中得到应用,基于开源大数据监控工具Ambari及HDP(Hortonworks Data Platform)大数据平台构建在青海联通云上的数据存储和计算平台,为青海省煤矿监管监察提供数据存储和分析计算支撑。青海煤矿事故风险分析平台中安全监控、人员定位和重大设备的实时数据查询、历史数据统计分析,提高了监管人员对监管范围内煤矿安全态势的感知;瓦斯特征分析、瓦斯浓度预测所得出的瓦斯历史变化特征及发展趋势,为瓦斯风险预测预警提供了支持。煤矿瓦斯特征分析及浓度预测界面如图4所示。
4 结语
结合煤矿安全风险监测预警系统建设中海量数据传输、存储、分析计算及数据共享方面的业务需求,利用大数据技术设计了构建在云平台上的区域煤矿监管数据服务平台,满足了煤矿监测监控数据的高速传输、可靠存储、高效分析计算和挖掘预警的需求,通过数据订阅消费为安全监管机构提供了个性化的数据业务服务。现场应用表明,区域煤矿监管数据服务平台能够可靠地为监管监察业务系统提供数据存储和分析计算服务,提高了安全监管机构的监管效率,对于智能化监管监察所需的数据关联分析、数据挖掘及预测预警也具有一定参考价值。

(a) 瓦斯特征分析界面
猜你喜欢
机械设计与制造(2023年2期)2023-02-27
房地产导刊(2022年10期)2022-10-18
汽车实用技术(2021年10期)2021-06-04
通信产业报(2020年43期)2020-01-15
中国环保产业(2019年10期)2019-11-21
中国商论(2016年34期)2017-01-15
电子科技大学学报(2016年2期)2016-08-31
中国卫生(2014年12期)2014-11-12
中国卫生(2014年8期)2014-11-12
中国卫生(2014年7期)2014-11-10
