
基于自注意力网络的共享账户跨域序列推荐
2021-11-05 12:08:42李秋菊刘方爱王新华
计算机研究与发展 2021年11期
郭 磊 李秋菊 刘方爱 王新华
1(山东师范大学商学院 济南 250358) 2(山东师范大学信息科学与工程学院 济南 250358) (leiguo.cs@gmail.com)
用户行为序列是指按照用户行为所发生的时间进行排序而得到的行为记录,它是很多互联网应用对用户行为进行组织和管理的一种重要方式.比如用户在电子商城点击或购买商品的序列信息,以及用户在视频网站对视频的观看序列等.由于序列信息通常蕴含了丰富的用户行为规律和兴趣偏好信息,如何对序列信息进行建模,并以此预测用户下一次可能会点击或购买的项目,成为近年来研究者关注的热点问题.序列推荐[1-3]同时也是很多网络应用推广产品、进行精准营销的重要方法.目前,序列推荐已经在电商、视频和音乐等领域得到了广泛的应用.
与传统的序列推荐任务相比,共享账户跨域序列推荐(shared-account cross-domain sequential re-commendation, SCSR)是指在特定背景下进行的序列推荐任务,即:为使用共享账户的多个不同用户进行跨领域的序列推荐.其中,共享账户是指多个用户共同使用一个账户(如家庭电视账户);跨域推荐[4-6]是指借助用户在其他领域中的信息来丰富目标域中的用户信息或用户特征,以提高目标域的推荐质量.在共享账户跨域序列推荐任务中:1)本文考虑了共享账户的情景.因为在很多应用中使用共享账户已成为一种普遍现象.例如,一个家庭的成员往往会使用同一个账户观看电影、电视节目,甚至有的家庭会使用同一个账户进行网上购物.在这些情景中,共享账户中的多个用户的行为是混合在一起的,很难直接将它们区分开来,使得推荐任务变得更具有挑战性.2)本文考虑了跨域推荐的情景.主要是因为:一方面,用户的兴趣往往是多样的.例如,用户可能会在同一视频平台上同时观看不同类型、不同题材的视频.比如,她/他既可能会观看一些技能或教育类的产品,也可能会同时观看一些娱乐性的节目(如电视剧、电影等).另一方面,虽然用户在每一个域上使用的产品和服务不一样,但却可以反映出用户的一些共同兴趣和特征.例如,用户对某个作者的喜好可以同时反映到电影和读书领域.捕获用户在这些不同领域中的行为可以帮助我们更进一步了解用户偏好,以实现在目标域进行更加准确地推荐.
目前已有的序列推荐算法大都使用递归神经网络(RNN)和卷积神经网络(convolutional neural network, CNN)[7]对序列信息进行建模,但是RNN和CNN不仅难以并行训练,需要较长模型训练和预测时间,而且RNN和CNN在建模用户的序列行为时都不能够较好地捕捉用户行为之间的长期依赖关系,而长期依赖关系在序列推荐任务中有时会起着比较重要的作用.例如,给定1个购物序列S1={手机,鞋,口红,T恤,巧克力,手机壳},可以看到,手机和手机壳之间存在比较强的依赖关系,但是手机和手机壳的距离又比较远.而这种情况在我们日常生活中是非常常见的,建模用户行为之间的长期依赖关系有利于进一步提高序列推荐的精准度.另外,已有的工作大多数都是针对单个域中的用户行为进行推荐,很少有同时考虑多个用户共享一个账户和跨域这2种情况.例如,虽然π-Net[8]将共享账户跨域序列推荐任务看作一种并行的序列推荐问题,并且提出一个并行的信息共享网络框架来兼顾共享账户和跨域这2种情况,但是该方法仍存在2方面不足:1)π-Net使用多个RNN进行用户行为序列信息建模以及领域信息的捕获,导致方法难以并行训练,具有较高的计算复杂度和需要较长的运行时间.2)由于RNN存在的固有缺陷,使得该方法无法同时建模用户交互序列行为之间的长期依赖关系,只能得到次优的推荐结果.
基于对以上问题的观察,本文将共享账户跨域序列推荐任务作为目标,针对现有方法存在的缺陷,创新性地提出了一种基于自注意力网络的序列推荐算法,并试图同时解决多个用户共享一个账户和跨领域推荐2个问题.具体展开来看,针对共享账户的问题和现有方法不能捕获用户行为之间的长期依赖关系的问题,本文创新性地引入了一种自注意力网络[9]来对用户行为序列进行建模.与现有的使用递归网络或卷积网络的其他模型相比,本文所使用的自注意力网络只使用了注意力机制来对序列信息进行建模,并采用了并行加速的运行方式,使其运行速度比基于RNN和CNN的方法快1个数量级.另外,由于自注意力网络需要计算行为序列中任意2个行为之间的注意力,使得它能够在全局范围内很好地捕捉用户交互行为之间的长期依赖关系.为了能模拟多个用户共享1个账户的混合行为,本文进一步引入了自注意力网络中的多头(multi-head)机制来建模共享账户中的多个用户,即:使用1个头(head)来表示1个用户.针对跨域问题中每个用户会在多个领域上(本文以2个域为例)产生不同行为的现象,本文提出一种带有交叉映射的多层感知网络来解决不同域之间的信息传输问题.并进一步使用能同时考虑2个域信息的混合推荐解码器来进行推荐.最后,采取以端到端的方式在2个域上进行联合训练,并在真实数据集上对提出的算法进行了验证.
本文的主要贡献概括为4个方面:
1) 针对共享账户跨域序列推荐SCSR问题提出了一种基于自注意力的跨域推荐模型(self-attention-based cross-domain recommendation model, SCRM),该模型同时考虑了共享账户和跨域2个特性,并且在2个域中分别进行了推荐.
2) 采用多头自注意力网络建模共享账户中多个用户的偏好,不仅具有并行运行的良好特性,而且能够很好地捕捉用户行为间的长期依赖关系和建模共享同一账户中多个用户的混合行为.
3) 提出一种带有交叉映射的多层感知网络来实现不同域之间的信息传递.在深度迁移学习方法中,探讨了建模用户序列行为之间交互关系的方法.
4) 在真实数据集上进行了实验,实验结果表明,本文提出的方法更加有效地对共享账户的行为进行建模,并且在共享账户跨域序列推荐任务上取得了更好的结果.
1 相关工作
本节将从跨域推荐、共享账户推荐和基于注意力网络的推荐3个方面来介绍相关工作.
1.1 跨域推荐
由于跨域推荐[10-11]主要是考虑了来自多个域的信息,所以它有助于解决推荐系统中经常面临的冷启动[12]问题和数据稀疏[13-14]问题.在现有的跨域推荐研究中,主要有2种方法来解决跨域问题.
一种方法是将不同域之间的信息直接聚合起来.例如,文献[15]采用了一种基于语义网络的描述框架.它们整合了多个相关辅助领域的信息,将辅助域的有用信息与目标域的信息进行整合,实现跨域的项目推荐.文献[16]介绍了一种跨域主题学习(cross-domain topic learning, CTL)模型,它采用了通过主题层的方式(而不是作者层)来加强跨域协作.文献[17]描述了一种跨域三元分解(cross domain triadic factorization, CDTF)方法,该方法将用户域和项目域结合,可以更有效地挖掘用户与项目之间存在的交互关系.文献[18]采用星型结构的混合图对社会网络进行建模,实现了项目之间的连接.该方法的主要优点是能够确定影响项目进行跨域传输的因素.
另一种方法是将辅助域中的信息传输到目标域中.基于深度学习的方法[19]非常适合迁移学习,因为深度学习方法可以学习到不同域的高级抽象表示.例如,文献[20]在LDA(latent Dirichlet allocation)模型上采用贝叶斯方法,将用户的偏好在域之间进行传输,使用一个公共空间来模拟多个域的用户偏好和项目受欢迎程度.文献[21]提出了一个新的框架,该框架充分利用了个体和群体的信息,同时实现了多领域的训练.文献[6]将捕获到的用户与项目之间交互的关系与带有用户社交关系的拉普拉斯图的优势结合起来,其核心思想就是向来自社交关系图域的用户推荐来自信息域的项目.
但是,上述提及到方法大部分只适用于静态评分数据,而不能直接应用到序列推荐任务中.
1.2 共享账户推荐
共享账户推荐是对多个用户在同一个账户内产生的混合交互行为进行建模,然后向账户里的每一个用户进行推荐,这通常被认为是2个独立的过程,即首先识别用户,然后再进行推荐[22-23].例如,文献[24]将由多个用户交互行为组成的共享账户看作线性子空间的并集,这使得线性子空间聚类算法在共享账户推荐问题中得到了很好地应用.文献[25]以一个新的研究视角研究用户识别,它利用用户偏好和消费时间来表示用户身份.以不同用户在不同时间段进行消费和消费行为具有一定周期性为理论基础,提出了不同的用户偏好可以在不同时间段内体现出来.文献[26]在鉴定共享账户里的不同用户时同样利用了时间因素,按照分析的用户偏好对时间进行划分以生成一个自适应的时间模型.文献[23]提出一种无监督框架来鉴定同一账户内的用户,然后学习每一个用户的偏好.在他们的方法中,利用一个异构图来学习项目和元数据之间的关系.在每个账户中利用投影的无监督方法判断用户的偏好,然后提供个性化推荐[27].文献[8]认为可以通过端到端的方式解决共享账户的问题,并且同时考虑了跨域信息以提高每个域的推荐质量.但是该模型由于是以RNN为基础建立的,所以其训练时间比较长,并且无法很好地捕捉用户行为间的长期依赖关系.
1.3 基于注意力网络的推荐
注意力网络[28-29]目前已经被广泛应用于图像处理、机器翻译、自然语言处理等领域.例如,文献[30]提出一个模型,该模型通过平滑用户的历史行为来改进注意力网络,通过发现项目之间存在的连接性探索项目之间更多的相似性.该模型主要是利用了用户偏好具有不同优先性的特点.文献[31]介绍了一种优先考虑用户最近交互行为的机制.即该模型在优先考虑了用户最近交互行为生成的当前偏好的基础上,又结合了用户在该域中由所有行为分析生成的长期偏好,其实现过程采取了一种新的注意力网络.为了克服RNN固有的一些问题,文献[9]提出了一种新的仅基于自注意力机制(self-attention,SA)的网络结构,完全不需要借助循环机制或卷积机制.最近的相关研究[32-34]表明,自注意力网络在多种推荐任务上可以取得更好的推荐结果.例如,文献[32]提出了一种基于自注意力和度量嵌入的方法,该方法在解决序列推荐问题时同时考虑了用户的短期偏好和长期偏好.文献[35]将用户行为分为异构行为和其他行为.它们将不同的异构行为投射到不同的潜在空间中,这些行为在一个公共空间中可以相互作用.在考虑其他影响因素的情况下,采用自注意力网络对所有用户行为进行建模.
但是,目前的研究大都是针对传统的序列推荐任务,而对于更为复杂的SCSR任务探讨较少.特别是如何解决SCSR任务中用户行为的长期依赖关系,所以共享账户问题还存在很多研究空白.
2 本文提出的SCRM方法
本节首先给出了SCSR任务的定义和所提出的SCRM方法的总体架构,然后分别详细描述了SCRM的组成模块,最后给出了相应的目标函数.表1列出了本文后续内容会使用到的符号定义:

Table 1 Definition and Description of Common Symbols
2.1 SCSR任务定义
在本文中,使用SA={A1,A2,…,Ai,…,A|SA|}和SB={B1,B2,…,Bj,…,B|SB|}分别表示域A和域B的共享账户中用户交互行为序列.其中,Ai∈(1≤i≤n)表示在域A中消费项目的索引,表示域A中所有项目的集合;Bj∈(1≤j≤m)表示在域B中消费项目的索引,表示域B中所有项目的集合.SCSR任务的目标是在给定序列SA和序列SB的情况下,给共享账户中的某个用户推荐即将消费的下一个项目.域A和域B中所有候选项目会被推荐的概率分别被定义为P(Ai+1|SA,SB)和P(Bj+1|SB,SA),分别表示在域A和域B中,给定序列SA和SB情况下,推荐项目Ai+1和项目Bj+1的概率.
2.2 SCRM的总体架构
SCRM的主要任务是:1)对共享账户中多个用户的行为信息进行建模;2)将用户在不同域上的兴趣信息进行跨域传输;3)将跨域传输得到的辅助域信息与目标域的原始信息进行整合以提高在目标域的推荐结果.

Fig.1 System architecture of SCRM图1 SCRM的系统架构
SCRM的系统架构如图1所示.SCRM主要由4部分组成,即嵌入层(embedding)、自注意力模块(self-attention block, SAB)、跨域传输网络(cross-domain transfer network, CTN)和混合推荐解码器(hybrid recommendation decoder).其中,嵌入层的功能是将原始的输入序列进行预处理.具体操作是依据输入序列对目标域中所有项目的嵌入矩阵进行检索,以得到输入序列中每个项目的初始嵌入表示(即输入序列的初始表示).自注意力模块主要是在不同域中建模用户的序列信息,以及模拟共享同一个账户的多个用户特征.在这一模块中,引入自注意力模型的多头(multi-head)机制,使用每一个头(head)表示共享账户里的每一个用户,从而达到从多个维度建模用户兴趣的目的.跨域传输网络的任务是将从辅助域中提取到的用户兴趣信息传输到目标域中,以提高目标域的推荐质量.在本模块中,通过采用多层交叉映射感知网络来实现知识的跨域传输.每一个跨域传输模块由2层隐藏层构成,其中第1层与第2层之间通过共享传输矩阵的方式,实现辅助域与目标域的信息共享.混合推荐解码器的主要任务则是进一步混合了跨域信息和目标域中原有的序列信息,以进一步提高目标域的推荐结果.通过使用拼接操作,将目标域内自注意力网络模块的输出与跨域传输模块最后的输出进行拼接,从而达到综合考虑2个域信息的目的.
2.3 嵌入层
本文提出的嵌入层主要包括初始项目表示和位置嵌入表示2部分.初始项目表示是将目标域中的所有项目映射为低维空间中的实数向量,构成目标域的嵌入矩阵,实现目标域中每个项目的向量化表示;然后模型的输入序列(即SA,SB)根据嵌入矩阵中的索引得到输入序列的向量化表示.在本文中,将输入序列的长度n固定为30.令M∈|I|×d表示域A或域B中所有项目的嵌入矩阵,其中I表示域A或域B中的所有项目集合(I=A或I=B),d是项目表示的潜在维度.输入序列中的每一个项目都对矩阵M进行检索可以得到输入序列SA(以域A为例)的初始嵌入EA∈n×d,其中n表示输入序列的最大长度,d表示序列中每个项目的潜在维度.
由于自注意力网络(如2.4节所示)并不包括任何的循环机制或卷积机制,所以使用自注意力网络直接对序列信息进行建模得到的编码并不包括序列的顺序信息.为了使模型能够捕获到用户行为序列间的时序关系,在初始嵌入E的基础上增加了一个位置编码P∈n×d[36]:

(1)
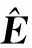
2.4 自注意力模块(SAB)
为了克服基于RNN方法不能很好地捕获序列行为间长期依赖关系的固有缺陷,本文采用了自注意力网络(SA)作为基础序列编码器.与传统的注意力网络相比,SA不仅能够建模序列中用户行为的上下文信息,而且还通过计算序列中任意2个行为之间的相关程度捕获行为的长期依赖关系和序列的全局信息.
在本文中,使用的SA方法是采用点积运算的方式计算行为之间的注意力:

(2)
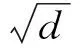


(3)
其中,WQ,WK,WV∈d×d是3个不同的投影矩阵,使用3个不同的投影矩阵与采用相同的投影矩阵相比,不同的投影矩阵会使得模型灵活性更好一些.S是自注意力网络的输出,1个S表示共享账户里1个用户的项目特征表示.因为自注意力网络计算的是序列中任意2个元素之间的相似度,所以不管元素之间距离有多远,都可以捕获到元素之间的关系.因此,自注意力网络的输出S不仅学习了序列的上下文关系,也学习了项目的长期依赖关系.
2) 多头自注意力网络(multi-head self-attention, MSA).由于共享账户通常是由多个用户共同使用,所以假设账户里的交互行为仅是由1个虚拟账户生成是不合理的.为了从多用户视角对共享账户中的混合交互行为进行建模(假设每一个账户里有H个用户),进一步在SA里引入了多头机制,用1个头(head)表示共享账户中的1个用户.
为了达到从多个维度(即多用户视角)进行建模的目的,MSA通过H个不同的权重值WQ,WK,WV对嵌入值进行H次变换,进而得到H组并行的Q,K,V,1组Q,K,V看作共享账户中1个用户的初始输入.然后,这H组数据以并行的方式通过自注意力网络进行投影,得到H个d维的输出S.最后,将这H个S进行拼接处理,并将其投影到d维空间上,得到MSA的最终输出,如图2所示.与以往方法相比,我们创新地提出了使用MSA网络联合建模共享账户里多个用户的信息.每个域中的多头机制可以表示为
D=MultiHead(Q,K,V)=
Concat(head1,head2,…,headH)WO=
Concat(S1,S2,…,SH)WO,
(4)

(5)
其中,WO∈Hd×d是投影矩阵;headi=Si∈n×d表示一个自注意力网络的输出;D∈n×d是某个域(A或B)中MSA的最终输出,它表示在考虑共享账户里H个用户混合行为信息后所学习出的共享账户的项目表示;H是MSA网络中自注意力头(或用户)的数量.

Fig.2 Architecture of the multi-head self-attention network in SCRM图2 SCRM模型中多头自注意力网络的体系结构
3) 点式前馈神经网络(point-wise feed-forward network, PFFN).在本文中,点式前馈神经网络指的是作用于每一个位置的2层全连接网络.PFFN将MSA的输出D作为输入,其计算方式可形式化为
N=PFFN(D)=
ReLU(DW(1)+b(1))W(2)+b(2),
(6)
其中,矩阵W(1),W(2)∈d×d,b(1)和b(2)都是神经网络的参数.本文使用ReLU作为激活函数.
4) 层规范化(layer norm).为了使模型稳定,并且能够加速神经网络训练,本文采用层规范化对点式前馈神经网络输出的序列特征进行规范化处理.层规范化不同于批规范化的是,我们在计算均值和方差统计数据时,同一批内的样本数据是独立的.其定义为
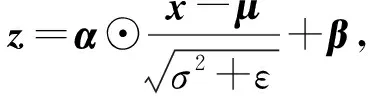
(7)
其中,x表示MSA或PFFN的输出,因为本文在MSA网络和PFFN网络中都使用了层规范化.μ表示由数据计算而来的均值组成的向量,σ2表示方差,α和β是可学习到的参数.⊙表示向量元素积运算.
到目前为止,得到了共享账户中所有用户序列中每一个项目的表示.为了学习整个共享账户中用户序列的表示,进一步将序列中n个物品的表示通过聚合函数将其进行聚合,并将其作为自注意力模块SAB的最后输出.其中,聚合函数可以使用求和函数、均值函数、最大值函数和最小值函数等方法来完成.本文采用了最小值聚合函数的计算方法,并在实验中对这4种方法的有效性进行了对比(具体实验参见表6).基于最小值的聚合函数可以表示为

(8)

2.5 跨域传输网络CTN
MSA的输出仍然只对用户在域A(或域B)中的序列行为进行了建模.为了能够利用用户在其他相关域的信息,实现跨域推荐,还需要将在域A(或域B)中学习到的用户兴趣传输到域B(或域A),然后将其与用户在目标域B(或域A)的兴趣信息相结合,以提高在目标域B(或域A)的推荐结果.在本节中,提出了一种基于多层交叉映射感知网络的跨域传输网络来实现域跟域之间的信息传输[5].它的主要任务是在2个域之间通过在同一层网络中共享同一个矩阵来实现域和域之间的双向信息传递,从而达到使用辅助域来提升目标域推荐效果的目的.
CTN的架构如图1所示,从图1中可以看CTN是一个多层交叉映射感知网络,它以来自2个域的基本的序列表示作为输入(SAB的输出),对于其中的任意2层(q层和q+1层):

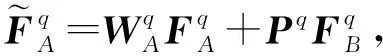
(9)

(10)
其中,WA和WB分别表示域A和域B的权重矩阵,矩阵P的作用是控制域A与域B之间的信息流的传输.跨域传输的信息会同时从域A中传向域B和从域B中传向域A中.所以,CTN可以实现知识的双向传输,以保证模型在每个域都可以接收到用户在其他辅助域的相关信息.当域A中数据较为稀疏时,SCRM在学习域A中用户兴趣的基础之上,也可以通过跨域传输网络学习到域B中的用户偏好表示,反之亦然.因此,SCRM在域A中对用户偏好有一个更好的学习,并且解决了数据稀疏的问题.
通过使用矩阵P而不是标量来控制域跟域之间的信息传输,主要是基于2个原因:1)矩阵P是从数据集中学习得到的,所以组成矩阵P的每一行数值都不是相同的,这也意味着其可以建模跨域传输信息不同位置的不同重要性即赋予用户序列不同项目不同权重.2)由于多层神经网络一般都会采取塔型的结构,低层网络的神经元数量要多一些,高层次网络的神经元数量要少一些.通过改变矩阵P的维度,可以实现不同维度的隐藏层之间的连接.
第q+1层.跨域传输模块通过一个多层交叉映射感知网络(以2层为例)来实现域和域之间的信息传输.域A和域B通过交叉连接进行耦合:
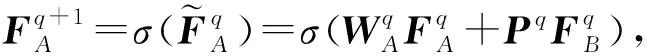
(11)
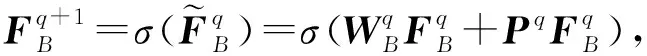
(12)
2.6 混合推荐解码器


(13)
其中,⊕表示拼接运算,W和b是神经网络的参数,softmax表示进行归一化的操作.
2.7 目标函数
本文使用负对数似然损失函数作为目标函数,对各个域的SCRM进行训练:
LA(θ)=

(14)
LB(θ)=

(15)
其中,θ表示SCRM模型中的所有参数,表示域A和域B的训练序列(SA和SB).
为了能够进一步充分利用用户在不同域中的共同兴趣,将2个域中预测函数同时进行训练,将LA和LB线性联合起来,模型的损失函数进行一步转化为
L(θ)=LA(θ)+LB(θ).
(16)
注意,SCRM中所有的参数都是以端到端的方式进行学习的.
3 实 验
3.1 研究问题
本文实验围绕5个研究问题展开:
1) 基于平均排序倒数(MRR)和召回率(Recall)这2种评价指标而言,本文提出的SCRM在不同域中的表现如何;SCRM是否同时提高了在2个域的推荐性能;SCRM方法与其他最新方法相比表现如何.
2) SCRM中的2个模块MSA和CTN在推荐中分别起到的作用是什么.
3) 超参数H如何影响SCRM模型的性能.
4) MSA中的聚合函数的选择对于实验效果的影响.
5) SCRM的训练效率如何.
3.2 数据集和评价指标
本文使用真实数据集HVIDEO[8]作为实验的数据源.由于没有其他公开可用的数据集,所以,这里我们只采用了1个数据集来评估本文提出的方法.HVIDEO是一个智能电视数据集,包含2016-10-12—2017-06-30期间26万个家庭的观看日志.这些观看日志是从知名智能电视服务提供商的2个平台(域V和域E)收集的.域V包括电视连续剧、电影、动画片、才艺表演和其他节目的视频.域E包括基于教科书的在线教育视频以及体育、食品、医疗等方面的教学视频.HVIDEO数据集的统计如表2所示:

Table 2 Statistics of HVIDEO Dataset表2 HVIDEO数据集的统计数据
实验中,随机选择75%的序列作为训练数据,15%的数据作为验证集,其余10%作为测试集.对于实验评估,本文使用每个序列中最后1个观察到的项目作为真实值.本文采用常用度量标准MRR@5,Recall@5,MRR@10,Recall@10,MRR@20,Recall@20来衡量不同推荐算法的性能表现.关于MRR和Recall的定义如下.
1)MRR.MRR是根据用户实际观看的某个视频所在的排名位置,进行取倒数并做均值运算得到的.本文之所以选择MRR作为评价指标之一,主要原因是本文使用的模型在每次推荐时只有1个真实值.如果视频的排名位置过低,则对我们的推荐系统起不到具体的实际作用.所以本文使用MRR@5,MRR@10,MRR@20作为评价指标.
2)Recall.Recall的功能是衡量检索到的相关项目数与文档中所有相关项目数的比例,也就是衡量检索系统的召回情况.
3.3 对比方法
在实验中,本文与4种类型的9种基准方法进行了对比.
1) 传统推荐方法
① pop[37].此方法根据项目的流行程度进行推荐,并始终推荐最流行的项目.
② item-KNN[38].该方法用于计算项目之间的相似性,这是通过2个项目之间的共现次数实现的.
③ BPR-MF[39].该方法是一种常用的基于矩阵分解的推荐方法.本文通过使用到目前为止,出现在这个序列中的所有项目的平均潜在因素来表示一个新句子的方式将BPR-MF应用到序列推荐任务中.
2) 共享账户推荐方法
此类中只有1种基准方法——VUI[25].该方法假设共享账户里的不同用户会有不同的偏好,并且会在不同的时间段进行消费.所以将账户的日志记录按照在不同时间段的不同偏好对共享账户里的用户进行分解.该算法将1天划分为不同的时间段,共享账户里的日志都划分到相应的时间段内,并且假设每个时间段内的日志记录是由一个虚拟用户生成的,使用一个3维向量来表示这个虚拟用户,借助余弦相似度来计算这些虚拟用户之间的相似性,相似度高的会进行合并.VUI使用user-KNN的方法为这些生成的潜在用户进行推荐.
3) 跨域推荐方法
① NCF-MLP++[37].该方法使用基于深度学习网络,利用多层感知机(MLP)计算传统协同过滤方法中的内积.
② Conet[5].该模型将十字绣网络的思想应用于跨域推荐,利用神经协同过滤模型在不同域之间共享信息.
4) 序列推荐方法
① GRU4REC[39].它使用GRU层编码用户的序列行为,并通过基于排名的损失函数学习模型.
② HGRU4REC[40].该方法通过考虑用户信息改进了GRU4REC,提出了一种层次递归神经网络(RNN).
③π-Net[8].这是通过并行信息共享网络研究SCSR问题的最新方法.但是,由于该方法是基于RNN的,因此非常耗时,而且无法捕获共享账户内交互行为的长期依赖关系.
3.4 参数设置
在本文中,SCRM是在TensorFlow框架上实现的,并通过NVidia RTX 2080 Ti GPU进行加速.本文使用Xavier方法[41]随机初始化模型参数,将Adam作为优化算法.模型的参数配置为:dropout值为0.4,超参数学习率为0.000 1,嵌入尺寸为80,迭代次数为50,批量大小为128.所有这些参数都在验证集上进行了调整.
3.5 实验结果(问题1)
为了验证本文提出SCRM方法的有效性,本节将SCRM与现有的9种方法做了对比实验,表3具体显示了SCRM与其他对比方法的比较结果.从表3中可以观察到:
1) 从表3中可以看出,与其他方法相比,本文提出的SCRM模型在域V的各个评价指标均优于其他方法;在域E上也取得了较好的结果,在绝大多数评价指标上的表现也优于其他方法.这说明本文针对SCSR问题提出的SCRM方法是有效的.与同为解决SCSR问题的基于RNN的π-Net方法相比较,在MRR指标上最高提升了4.15%,在Recall指标上最高提升了4.52%.与序列推荐方法GRU4REC相比,SCRM在MRR指标上最高提升了6.68%,在指标Recall上SCRM最高提升了9.94%.明显的提升幅度不仅说明了考虑共享账户和跨域的特性对于序列推荐是有帮助的,而且可以看出基于自注意力的SCRM模型要比基于RNN的模型更具有一定的优势.

Table 3 Comparison Results on HVIDEO Dataset表3 HVIDEO数据集的比较结果 %
另外,为了公平起见,本文对原有的GRU4REC与HGRU4REC做了一定的处理,使其与针对SCSR任务的模型具有相似的结构,并且使用了相同的TensorFlow框架来运行程序.
2) 从表3中还可以观察到,就Recall值来讲,SCRM在域V的表现要比在域E上好的多.由其他方法的数据对比也可看出,域V上的Recall值普遍要高于域E的对应值.这主要是因为用户在域V上有更多的观看视频记录,所以域V的数据集要更加密集.也正因为此,模型可以更好地学习到用户在域V的偏好.另外,与同为研究SCSR问题的π-Net方法相比,本文提出的SCRM方法在域E上的提升幅度要比域V上的提升幅度多.在MRR@5指标上,域V提升幅度为4.15%,而在域E上的提升幅度为1.91%;在Recall@5指标上,在域V的提升幅度为1.89%,而在域E的提升幅度为4.52%.由此可以看出,基于自注意力的SCRM模型,对于稀疏数据集的学习具有更为积极的作用.
3) 从表3还可以看出,本文提出的基于自注意力网络的SCRM方法在各个评价指标上均优于传统的模型.与解决SR问题的GRU4REC方法比,基于自注意力的SCRM模型在域V的指标Recall@20上提升了5.44%,在MRR@20指标上提升了4.48%;在域E上Recall@10指标提升了9.94%,MRR@10指标提升了6.68%.与表现较好的HGRU4REC方法相比,本文提出的SCRM在域V指标MRR@20上提升了2.13%,在Recall@20指标上提升了4.05%;在域E指标MRR@5上提升幅度为4.31%,在Recall@5指标上提升幅度为5.14%.由较大的提升幅度可以看出本文提出的SCRM方法对于推荐系统的有效性.另外,在SCRM方法与π-Net方法比较过程中,发现2个域中的MRR@5和Recall@5提升幅度最大.对于个性化推荐系统来讲,一般推荐项目所处位置越靠前越会吸引用户的注意力,所以MRR@5和Recall@5效果的提升,对于推荐系统提升用户体验性具有重要意义.
4) 单独观察表3的Recall和MRR的增长情况可以得出,Recall增长得更快一些.Recall在域V上从Recall@5指标到Recall@20指标提升了3.37%,在域E上从Recall@5指标到Recall@20指标提升了17.04%;MRR在域V上从MRR@5指标到MRR@20指标仅增加了0.33%,在域E上从MRR@5指标到MRR@20指标增加了1.53%.这主要是因为Recall测量的是top-k列表中相关项目所占的比例;而MRR测量的是相关项目的排名.随着列表中项目数量的增加,其相关项目自然而然会随其增加,所以Recall的值就会增大.然而,MRR计算的是每个正向项目排名的倒数,所以随着项目的增加对于MRR的影响有一定的限制.
3.6 实验分析
本节主要是围绕回答3.1节中的研究问题2~5进行展开.分别做了关于SCRM的分解实验,设置超参数H的不同值来观察H对于SCRM模型影响效果的实验和不同聚合函数对SCRM的作用对比实验,并进行了实验分析.
3.6.1 SCRM的分解实验(研究问题2)
为了证明SCRM的不同组成部分对其运行效果的影响,本文在HVIDEO数据集上对SCRM进行了分解研究.我们将SCRM分别与2种方法进行了对比:SCRM(无MSA)表示将自注意力网络进行了移除,即将嵌入层得到的用户序列编码直接作为CTN模块的输入;SCRM(无CTN)表示将多层交叉映射感知网络进行移除,即将自注意力网络的输出直接作为混合推荐解码器模块的输入,根据单个域的信息进行推荐.
实验结果如表4所示,由表4观察可得:
1) SCRM在2个域上绝大多数指标表现都要优于SCRM(无 MSA),这主要是因为SCRM中包含的对用户序列行为进行编码的自注意力网络有助于提高模型性能.也说明借助MSA网络建模共享账户里多个潜在用户的特征有助于提高2个域的推荐质量.在域E上,MRR指标最少提高了0.98%.在域V上,MRR指标最少提高了0.79%,指标Recall
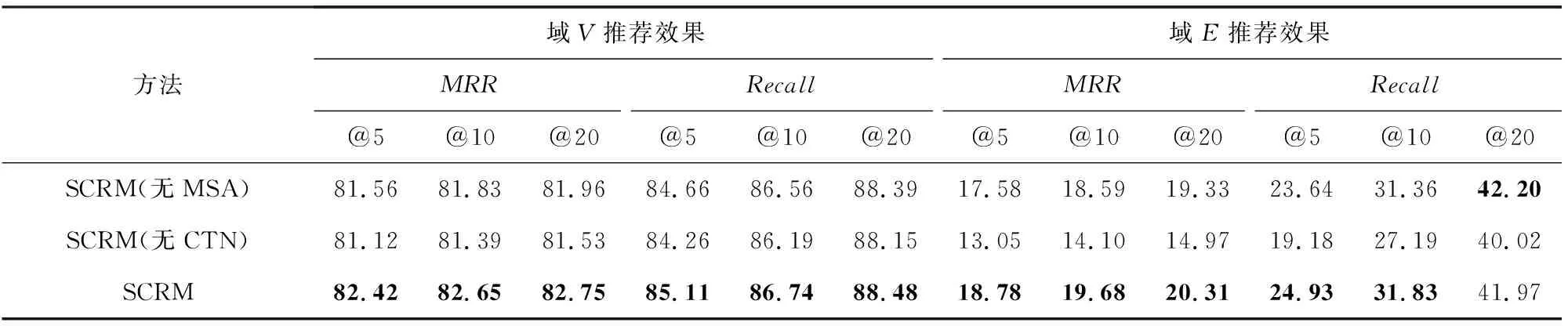
Table 4 Ablation Experiments of SCRM表4 SCRM的分解实验 %
最多提升了0.45%.当然也可以看到,SCRM(无MSA)在指标Recall@20上是略高于SCRM,这说明本文将自注意力网络应用于序列推荐时,根据用户的所有序列信息并给予每一个项目一定的权重去判断用户即将点击的下一个项目时,也会带来一定的噪音信息.
2) SCRM在所有指标上,表现要均优于SCRM(无CTN),这主要是因为SCRM借助CTN的多层交叉映射感知网络在每个域上进行推荐时综合考虑了2个域的信息.在域V的推荐上,MRR提升幅度最小的是MRR@20指标为1.14%,Recall提升幅度最大的是Recall@5指标为0.85%.在域E上,MRR指标中提升幅度最大的是MRR@5为5.73%,Recall指标中提升幅度最大的是指标Recall@5为5.75%.由此可以看出,本文提出的通过多层交叉映射感知网络实现跨域信息传输对于SCRM模型的有效性.
3) 在2个域中的各项评价指标上,SCRM与SCRM(无CTN)之间的提升幅度要比SCRM与SCRM(无MSA)之间的提升幅度大一些.这表明在SCRM中CTN模块要比MSA模块更加有效一些.除此之外,还有一部分数据集的原因.因为绝大多数成员都在域V上有观看记录,域E的用户数量相对较少,因为域E上是教育类的视频,所以受众大部分都是儿童,这部分观众本身比较固定并且可能观看的类型特别局限.所以大多数情况下,通过MSA模块从域V里提取出来的用户偏好,可能就对域E的用户的帮助不大,进而难以提高域E的推荐质量.
4) SCRM(无CTN)是3种模型中表现最差的,但是SCRM(无CTN)要比表3中大多数比较方法的绝大多数指标表现都要好,这证明了本文提出的借助MSA网络对多用户建模的有效性.同时可以看到,SCRM(无MSA)要比所有比较方法的绝大多数指标表现都要好,这表明本文提出的CTN模块的有效性.
3.6.2 超参数H的影响(研究问题3)
在HVIDEO数据集上,家庭成员共享一个账户.因此本文提出了多头SA网络来模拟多个用户共享一个账户的情况,其中超参数H表示账户中用户的数量也是MSA模型中头的数量.为了探讨建立共享账户模型的重要性,本文进一步进行了实验,以表明超参数H对于SCRM的影响.本文根据现实生活中的真实情况,在{1,2,3,4,5}数值空间上对H的取值进行搜索.在调整过程中,模型中的其他参数保持不变.
实验结果如表5所示,其中H=1表示1个账户只有1个虚拟用户.通过结果可以看出当H=1时,SCRM模型取得了最差的结果;当H=3,4,5时,SCRM在MRR和Recall指标上的数值差距较小,取得了较好的结果,这也符合我们现实生活中家庭成员数量的实际情况,这表明了将共享账户建模为H个潜在用户的重要性.
另外,由表5看出:SCRM在H=4时表现最好,并且与H=1的情况进行对比,在域V上,MRR提升幅度最大为8.52%,Recall提升幅度最大为6.29%;在域E上,指标MRR最多提升了7.85%,最少也提高了7.41%;指标Recall的提升幅度最小为3.28%,最大为7.64%.较大的数据提升幅度表明本文提出的使用多头的MSA网络建模共享账户里的多个用户的有效性.
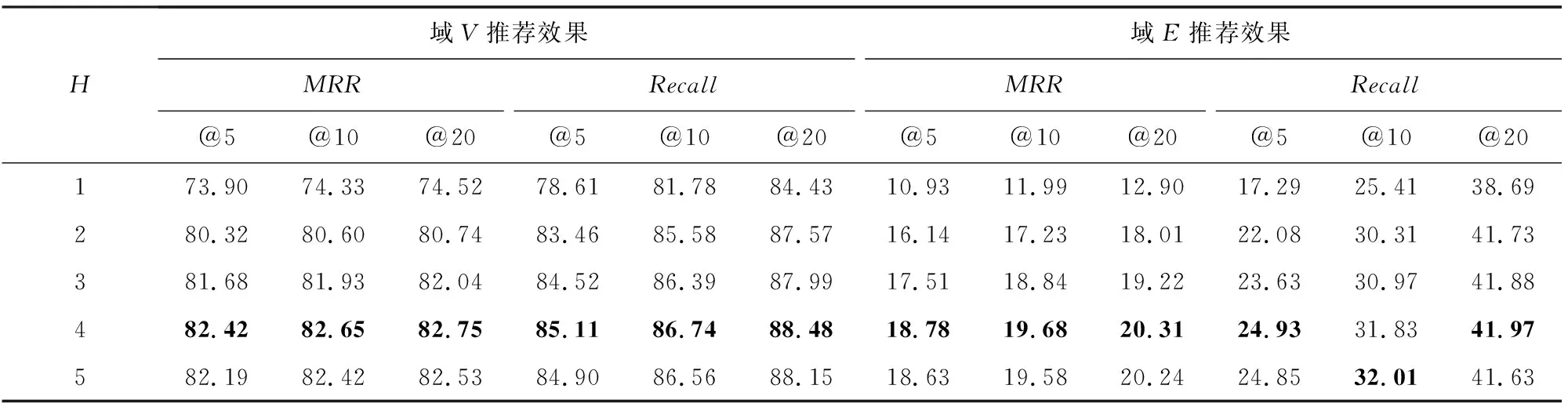
Table 5 Impact of the Hyperparameter H表5 超参数H的影响 %
3.6.3 聚合方法的影响(研究问题4)
在2.4节中,在得到一个序列中所有项目的表示后,需要使用聚合函数将所有项目进行聚合,以得到整个序列的表示.本节中,我们对常用的4种聚合函数——最小值函数min、最大值函数max、均值函数mean、求和函数sum——进行了实验验证.表6给出了使用不同聚合函数所得到的实验结果.由表6可以观察到,最小值函数在域V与域E中的各个评价指标上均优于其他3种聚合函数.这表明对于SCRM模型,使用最小值聚合函数,可以更多地获得共享账户里的用户信息.

Table 6 Effects of Different Aggregation Methods for SCRM表6 SCRM中不同聚合方法的对比效果 %
3.6.4 模型的训练效率(研究问题5)
为了证明SCRM模型的训练效率,本文在图3中绘制了SCRM和π-Net的训练时间.从图3的折线图中可以看出SCRM模型每一步的训练时间都远少于π-Net的训练时间,这个结果表明SCRM具有更短的训练时间和更高的训练效率.与基于RNN的方法相比,由于SCRM可以在并行模式下进行训练,所以总的训练要远快于基于RNN的方法.

Fig.3 Training time of π-Net and SCRM图3 π-Net和SCRM的训练时间
4 结论与展望
本文研究了共享账户跨域序列推荐SCSR问题,提出了一种新的基于自注意力的跨域推荐模型SCRM,以克服共享账户跨域序列推荐任务中的挑战.具体来讲,为了减少训练时间和建立长期依赖关系,本文引入了自注意力网络作为SCRM的基本序列编码器.为了模拟共享账户的特征,假设共享账户由多个用户组成,并进一步探索了多头自注意力网络MSA.为了将用户信息从辅助域传输到目标域,提出了跨域传输模块,借助多层交叉映射感知网络实现域和域之间的信息传输.最后,将传输的信息与目标域中的原始信息相结合,得到一个混合推荐解码器.为了评价SCRM的性能,在真实数据集HVIDEO上进行了大量的实验.
本文提出的SCRM方法虽然取得了较好的结果,但仍具有一定的局限性.例如,SCRM在数据互补性高的数据集上,性能比较好,但如果域和域之间共享信息少,模型性能就会表现稍差.下一步我们将从2个方面入手:1)对于自注意力网络应用于序列推荐问题上,在给序列中每一个项目分配权重信息时,可以考虑舍弃部分项目.2)对于共享账户里用户数量的设置,本文设定为一个固定值,未来可以考虑用户的数量采取具体账户具体分析的方式,根据共享账户已有的历史信息自适应地选择用户数量.
作者贡献声明:郭磊负责模型总体设计及论文写作与修改;李秋菊负责算法实现及论文写作;刘方爱负责模型设计及论文修改;王新华负责模型设计及论文修改.
猜你喜欢
系统仿真技术(2022年4期)2023-01-17 13:01:44
北京航空航天大学学报(2022年8期)2022-08-31 08:59:18
读报参考(2022年1期)2022-04-25 00:01:16
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
科学家(2021年24期)2021-04-25 13:25:34
中国外汇(2019年17期)2019-11-16 09:31:14
中国外汇(2019年10期)2019-08-27 01:58:28
特别健康(2018年4期)2018-07-03 00:38:20
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
