
基于注意力特征金字塔的轻量级目标检测算法
2021-11-04 03:48赵义飞
电子技术应用 2021年10期
赵义飞,王 勇
(北京工业大学 信息学部,北京 100124)
0 引言
目前基于深度学习的目标检测算法可分为单阶段检测算法和两阶段检测算法两类。单阶段目标检测算法以SSD[2]和Yolo[3-5]系列算法为代表,是一种通过在卷积神经网络提取的特征图上设置锚点,并对每个锚点上预设的不同大小和长宽比例的边界框进行检测的方法。两阶段目标检测算法以RCNN[6-8]系列算法为代表,先在特征图上采用额外步骤生成候选区域,再对候选区域进行检测。与单阶段算法相比,两阶段算法一般拥有更高的检测精度,但由于增加了额外的运算量,检测速度也相对较低。
基于深度学习的目标检测算法拥有很好的性能,同时也有着更高的模型复杂度和计算量。实际应用中,由于功耗、成本等限制,这些模型是难以直接部署的。为了使目标检测任务能在移动设备等难以提供高额算力的硬件上更好地完成,本文提出了一种基于轻量级网络的检测算法,并通过引入注意力机制使得原始特征图具有更细粒度的特征表达能力,从而获得更好的检测效果。
1 特征金字塔网络
基于深度学习的目标检测算法中,SSD[2]算法通过多级检测的方式在不同尺度的原始特征图上各自进行预测,而FPN[9]则进一步通过一种自顶向下的简单的特征融合方式从原始特征图中重构出特征金字塔,将网络浅层的强位置信息与深层的强语义信息相结合。PANet[10]在FPN 的基础上添加了自底向上路径聚合的结构,利用网络浅层的位置信息增强了整个特征层次,缩短了浅层与深层特征之间的信息路径。EfficientDet[11]提出了一种新型的BiFPN 结构,在对PANet 进行了简化之后,增加了shortcut 结构并引入了加权策略,通过对原有特征图整体赋予不同权重,更灵活地实现了多尺度特征融合。DetectoRS[12]则通过将原始FPN 融合后的输出作为输入重新返回到模型中再次进行计算的方式实现了一种Recursion-FPN 的结构,并在目标检测、实例分割等多个领域达到了最高精度。
2 本文方法
选择低计算量的神经网络作为特征提取骨架,可以显著提升算法的检测速度,降低算法部署的成本需求。本文以Cream[13]分类模型为基础,采用单阶段的方式进行检测。Cream 模型的主体结构由NAS(Neural Architecture Search)获得,相比人工设计的网络,具有更好的特征提取性能和更少的浮点运算次数。
2.1 注意力特征金字塔网络
文献[9]通过采用最邻近插值法将深层尺寸较小的特征图放大至与相邻的前一层相等的方式将深层特征图融合进浅层达到重建特征图的目的,这种方法简化了计算,但不具备学习能力。文献[11]通过对不同层的特征图整体赋予权重的方式,实现了一种更为灵活的加权特征融合BiFPN。文献[14]对卷积神经网络中特征通道之间的相互依赖关系进行显式建模,采用了一种全新的特征重标定的策略,将注意力机制引入到了计算机视觉分类算法当中。这种注意力机制使得模型能够通过学习的方式自动获取不同特征通道的重要程度,并相应地对来自不同通道的特征进行抑制或者提升,从而将更有效的特征向后传递,达到提升算法精度的目的。受文献[11]和[14]启发,本文提出了注意力特征金字塔网络(Attention-Feature Pyramid Network,AFPN),通过在通道维度进行重新标定的方式对原始特征图对特征金字塔的贡献进行更为细粒度的建模。以Cream604 为例,本文将Cream604 中下采样倍数为8 倍、16 倍、32 倍的特征图分别记为P8、P16 和P32,并额外添加一个64 倍的下采样层,特征图记为P64。模型的整体结构如图1 所示。
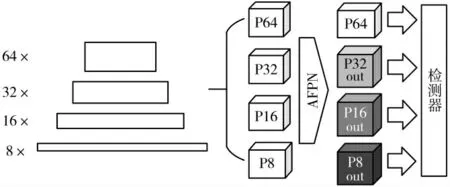
图1 目标检测模型整体结构
由于不同层的特征图在分辨率和通道数上都不一致,在进行特征融合时,要对参与构建特征金字塔的特征图进行调整。文献[11]指出不同的输入特征图对特征金字塔的贡献是不均等的,并通过添加权重系数来表示原始特征图对其所参与构建的特征金字塔层的贡献,通过分别将与原始特征图相邻的下一层和上一层特征图按照先后次序融入的方式构建新的特征图。AFPN 同样考虑了输入特征图对特征金字塔的贡献不同,采取了一种更为细化的特征融合的方式。AFPN 以低层的特征图为主体,采用自顶向下的方式将深层的特征图向浅层融合,将深层富含的语义信息与浅层的位置信息相结合,以求得到更好的检测效果。为了简化计算,AFPN 采取最邻近插值的方式对深层特征图进行上采样。由于通过插值进行上采样的方式不需要进行计算,因而没有可供进行学习的参数。AFPN 首先在上采样特征图后面添加了额外的卷积模块,增加了上采样特征图的特征表达能力。随后,AFPN 采用注意力机制对低层的特征图和经过上采样的高层特征图进行建模,让网络通过学习的方式自动获取原始特征图在通道维度对新特征的重要程度。如图2 所示,以大小为96×20×20 的特征图P16 为例,经AFPN 中的特征融合得到P16 out 的过程可以用如下公式描述:
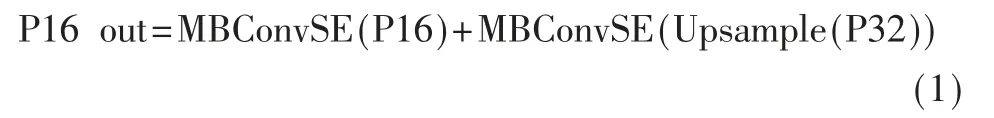
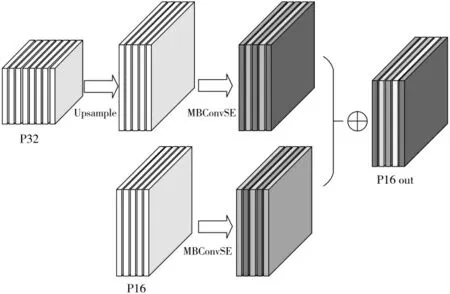
图2 注意力特征金字塔网络结构
其中,Upsample 表示最邻近插值上采样操作,这部分没有参数,不具备学习能力;P32 的大小为320×10×10,经过上采样后变为320×20×20。MBConvSE 表示融合通道注意力机制的转置瓶颈[15]结构,具体如图3 所示。其中Conv 代表卷积运算(Convolution),BN 代表批量归一化操作(Batch Normalization),SE 代表基于通道的注意力模块(Squeeze-and-Excitation block),而SE 模块中的Global Pooling 则仍然采用全局平均池化(Global Average Pooling)的方式进行运算。文献[15]指出,通过将特征图扩展至高维再降回低维的方式可以减少ReLU 激活函数对特征图中所包含信息的损耗。AFPN 中的转置瓶颈模块选用了更适合低算力设备的hswish 激活函数,对于P32,首先通过1×1 卷积将特征图扩张至640×20×20,再通过3×3卷积提取特征,最后通过1×1 卷积降维至与P16 相同的96×20×20 以便进行特征融合;对于P16,则先扩张为320×20×20 再调整回96×20×20。对于调整后的两组特征图,采用element-wise add 而不是concatenate 的方式以避免计算量的进一步增加。AFPN 中注意力机制的实现也针对计算量进行了优化,具体为将文献[14]中的SE module 中的两个全连接层替换为1×1 卷积并保持通道数不变,并将最后的sigmoid 函数替换为hsigmoid 激活函数。此外注意力机制的实现被直接融合进了转置瓶颈结构之中,与文献[14]中的标准SE module 相比,这种方式可以在保持相似性能的同时进一步降低运算量。
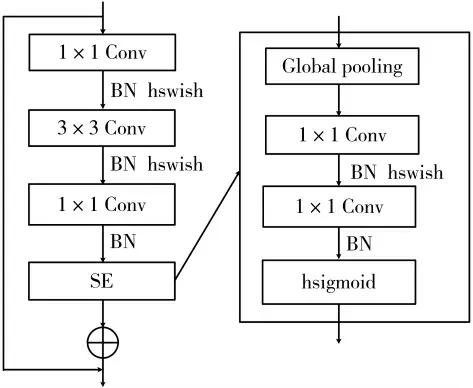
图3 MBConvSE 模块
2.2 AFPN 损失函数计算
AFPN 采用传统的单阶段目标检测算法的检测模式,即对特征图上产生的每个预测框进行检测。由于目标检测模型的训练一般是在包含多个类的数据集上进行的,因此损失函数的计算要在所有类上进行。记用于表示第i 个先验框与数据集中物体所处的真正位置在类别p 上的匹配程度,当两者的交并比大于预设值时,认为该预测框为正样本,即i∈Positive,此时否则计为负样本即i∈Negative。文献[16]指出,正负样本比例失衡是导致单阶段目标检测算法精度较低的重要原因之一。采用难例挖掘的方式对整幅样本比例进行控制,通过将负样本的数量控制在正样本3 倍左右,可以简单而有效地提高训练的稳定性。最终得到的AFPN 的损失函数Loss 由定位损失Ll和类别置信度损失Lc共同组成:
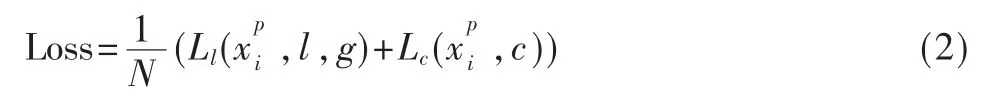
当复杂句子中包含很多的分句而且这些分句的句法和逻辑结构,语序都与中文一致时,采用顺译的方法,即按照英语句子的语序就能直接进行翻译。
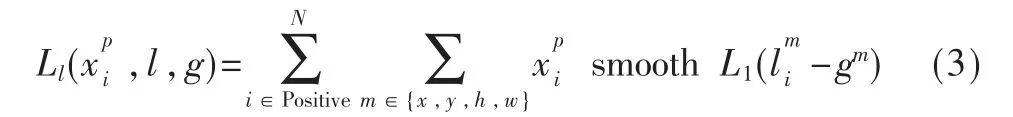

3 实验
3.1 数据集及评价指标
Pascal VOC 数据集是计算机视觉领域的经典数据集,共包含了人、猫、公共汽车等在内的20 类物体。其中VOC07 数据集共有9 963 张图片,共包含了24 640 个带标注的物体;VOC12 数据集中训练集和验证集共有11 540张图片,共包含了27 450 个带标注的物体。将VOC07 和VOC12 数据集中的训练集和验证集作为总训练集,VOC07 数据集中的测试集作为总测试集,已成为目标检测算法经典的训练和评估方法。
由于目标检测问题本质上仍然是二分类问题,因此可将样例按所数据集中所标注的真实类别与模型所预测类别的组合划分为真正例(True Positive,TP)、假正例(False Positive,FP)、真反例(True Negative,TN)和假反例(False Negative,FN)4 种情况,所有情况组成的混淆矩阵如表1 所示。

表1 预测结果混淆矩阵

查准率(Precision)和查全率(Recall)可由表中的混淆矩阵计算得出,二者分别定义为:其中,all detections 表示所有预测框的数量,all ground truths 表示数据集中所有标注物体的数量。对于VOC 数据集,首先计算所有不同的Recall 值,然后将每个Recall值对应的大于等于该Recall 的最大Precision 值进行求和平均,即得到了AP(Average Precision)值。对数据集中包含的所有类的AP 值取平均数即得到了 mAP(mean Average Precision)。mAP 作为最常用的检测指标之一,被广泛应用于图像分类、目标检测等计算机视觉领域。
3.2 数据预处理
文献[2]指出,通过数据增强的方式对数据集中的图像进行预处理,可以有效提升模型的检测性能。本文采取了随机裁剪、镜像翻转、图像扩张、随机添加噪声、随机调整亮度等方式对VOC 数据集中的图像进行了增强处理,以提高模型的鲁棒性。将经过数据增强处理的图像缩放到320×320 像素,并将图像对应的标注信息进行相应调整,即得到了模型输入值。
3.3 模型超参数设置
本文采用mini-batch 梯度下降法,设置batch size 为32,并使用momentum 优化器对梯度下降过程进行优化,momentum 系数设置为0.9,L2 正则化系数设置为5×10-4。模型共在VOC 数据集上进行120 000 次迭代,初始学习率设置为1×10-3,并采用动态调整学习率的方式,具体为在迭代进行到80 000 次和100 000 次时将学习率调整为1×10-4和1×10-5,从而更助于找到模型最优解。
3.4 实验结果
表2 比较了本文所设计的模型与目前部分主流算法在VOC 数据集上的表现。
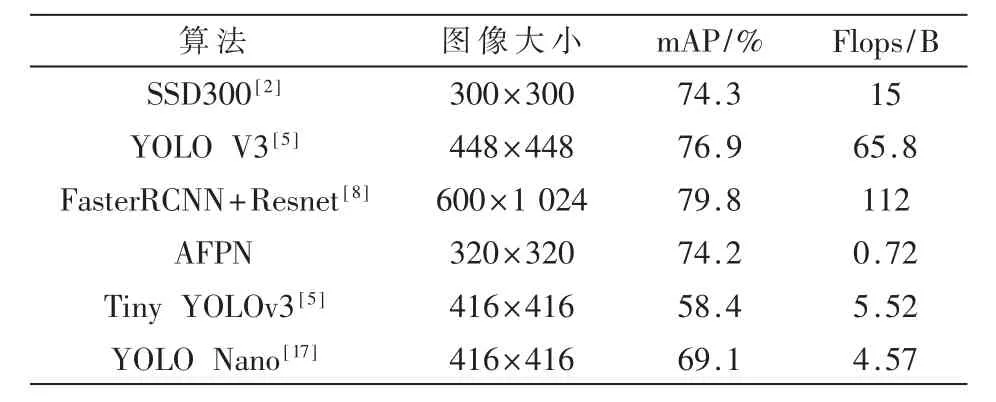
表2 不同算法在VOC 数据集上的表现
可以看出,对于复杂检测模型,以SSD300 为例,本文设计的算法在保持了与其相似输入图像尺寸和精度的同时,将浮点运算量降低到了1/20 以下,部分图像的检测结果对比如图4 所示。对于其他小型检测模型,以YOLO Nano 为例,本文的算法依然占有精度和运算量的优势。

图4 AFPN(左)和SSD300(右)检测结果对比
4 结论
本文针对传统目标检测算法模型复杂度高、计算量大的问题,通过对特征融合方式进行研究,提出了一种基于注意力特征融合的轻量级检测算法。实验结果证明了本文的算法的有效性,对于移动端等低算力平台,本文的算法具有更强的适用性。
猜你喜欢
环球时报(2022-09-19)2022-09-19
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
考试与评价·七年级版(2020年4期)2020-10-23
电子制作(2019年11期)2019-07-04
少儿美术(快乐历史地理)(2019年2期)2019-06-12
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
童话世界(2017年11期)2017-05-17
第二课堂(课外活动版)(2016年2期)2016-10-21
