
基于多变量概率模型的钻井周期预测方法
2021-11-03 11:54:24LUUQuangHungLAUManFaiNGSebastianTINGClementWEEReubenTHENPatrick
石油勘探与开发 2021年4期
LUU Quang Hung,LAU Man Fai,NG Sebastian P.H.,TING Clement P.W.,WEE Reuben,THEN Patrick H.H.
(1.斯威本科技大学科学、工程与技术系,霍桑 3122,澳大利亚;2.斯威本科技大学工程、计算与科学系,砂拉越 93350,马来西亚;3.IDS公司,砂拉越 93100,马来西亚)
0 引言
可靠地预测钻井周期是油气勘探开发规划中的一项重要工作[1]。目前在预测和优化钻井周期时,主要的关注点集中在钻速模拟方面。有研究者对传统的钻速模型[2-8]进行了改进,引入了一些重要的变量来描述钻井过程,将这种改进后的模型称为半经验模型,其中的变量经过多次回归后可得到预测函数。近年来,利用各种钻井数据,结合计算资源,现代钻速模型的应用越来越广泛[9]。这些模型大多数都是数据驱动的,可通过应用各种统计方法和机器学习技术(如人工神经网络(ANN)技术[10-12]、随机森林算法[11,13]、支持向量机方法[13])得到。
虽然钻速模拟是评估钻井效率的重要方法,但总钻井周期不是只由钻速决定。先前的研究[14-15]指出,提高瞬时钻速和平均钻速不一定能降低钻井成本。这是因为钻井施工包括多个过程,从钻机动员、为更换磨损钻头起出井底钻具组合、下套管和固井到解决偶然事件,其中许多过程都不会直接影响钻速。总钻井周期也受到非生产因素的影响,如钻井设备失效、井下落物打捞时间比预期时间长、遭遇恶劣天气等。在整个钻井施工过程中,非生产时间可能会持续多日,与机械钻井所花费的生产时间相当。因此,建立钻井周期预测模型有利于更好地制定钻井计划。
钻井周期预测模型可使用确定性方法或概率法得到。在确定性方法中,根据各钻井要素之间的关系可以确立一个钻井周期预测模型,对总钻井周期[16-18]或某个钻井阶段(如换钻头)的周期[19-20]进行多次回归分析。随着机器学习技术的发展,这种方法取得了一些进展。例如,Ardekani等[19]针对更换钻头的过程开发了人工神经网络模型,比伊朗南部油田取样回归的结果更加准确。概率法则把预测目标按照可能性而不是一个数字来考虑。这是因为实际的钻井过程是不确定的,受到各种非确定因素的影响。概率法不仅可以综合考虑钻井活动不确定性的影响,还可以量化风险,从而优化钻井成本[21-22]。因此,在过去的20多年里,概率法成为了钻井施工设计中的常用方法[23-24]。McIntosh[21]根据样本数据对各个钻井阶段的周期进行了概率分析,并认为对这些概率值进行排序可以找出对总钻井周期影响较大的作业活动。Akins等[22]得到了一套相对综合的采用概率法预测钻井周期的实践方法。Loberg等[23]和 Merlo等[24]开发了商业软件包,有利于钻井工程师量化钻井风险并得到相应的钻井周期和钻井成本。采用北海中部118口井的数据,Adams等[25]对各种影响因素进行分类,描述了钻井周期的概率分布。之后,Adams等[26]又添加了93口井的数据,对概率分布进一步细化。这些概率模型的主要局限性在于,它们仅依据单变量概率密度函数。由于多变量概率密度函数被过度简化为单变量概率密度函数,忽略了一些因素(如垂深和钻深)的影响,结果会出现一定偏差。
因此,本文提出采用多变量概率密度函数对钻井周期进行描述,建立多变量概率模型来预测钻井周期。一方面,在概率模型中引入了更多的钻井变量,可提高预测结果的精确度。另一方面,某些特定事件已经发生后,可以得到条件概率,更好地量化可预测性。本文重点关注主要钻井阶段即导管段、表层套管段、技术套管段、生产套管段的总施工周期,因为总钻井周期就取决于这几个钻井阶段的总施工周期。在多变量分析中,采用目标层深度来模拟钻井阶段,采用垂直深度来模拟下套管和固井阶段。初步分析表明,这些深度与每个钻井阶段所需的周期具有高度的相关性。
本文首先根据自适应核密度估计法建立了每个钻井阶段周期的理论模型,采用蒙特卡洛模拟法建立了整个钻井作业总周期的理论模型,并进行了算例分析。然后建立了无事故钻井周期的概率模型,并对模型进行了验证,讨论了总钻井周期与无事故周期之间的差异以及将模拟数据用于机器学习模型训练的可行性。
1 多变量概率模型
首先,采用自适应核密度估计法得到各钻井阶段的多变量概率密度函数,预测考虑钻井深度和其他参数的钻井周期概率分布。然后,结合不同钻井阶段的概率密度值,采用蒙特卡洛模拟法得到整个钻井作业总周期的预测模型。
1.1 多变量概率密度函数求取
有两个或两个以上变量即为多变量概率密度函数。本文采用Bernacchia和Pigolotti提出的自适应核密度估计法[27]得到了多变量概率密度函数。这种方法的优点是可以得到具有高收敛性的最优化的核函数和带宽(bin)。采用 O’Brien等[28]的研究方法(名为fastKDE),在大量数据的基础上快速高效地得到概率密度函数的预测值。
给出一组数据,具有n个数据点p1,p2,…,pn,设多变量概率密度函数为f。其中,核密度估计模型是二元的,设钻井周期为t,深度为d,深度是与每个钻井周期有关的参数。数据集pj(j=1,2,…,n)里的每个数据可以用坐标(tj,dj)来表示。也可以在核密度估计模型中加入更多变量来代表更多元的分布。本文求取的概率密度函数是光滑变量p的函数,它与离散数据点p1,p2,…,pn之间的关系可通过引入核函数K来得到:
显然,为了通过一组离散数据来得到概率密度函数,必须确定核函数K。Bernacchia和Pigolotti提出的自适应核密度估计法[27]采用了傅里叶变换,可将数据坐标(t,d)有效地转化为可描述分布的频域 u,反之亦然。其中,傅里叶变换的逆变换定义为:
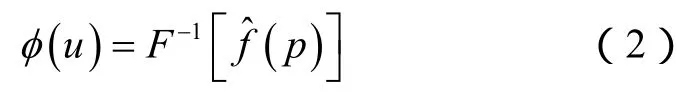
核函数的傅里叶变换为:
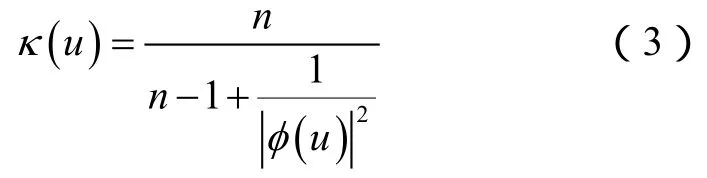

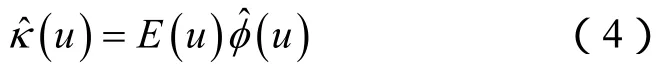
其中,E(u)是经验特征函数,定义为:
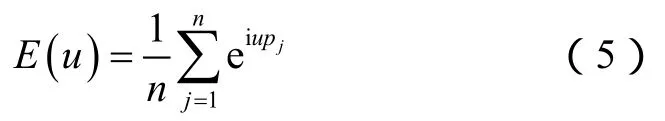
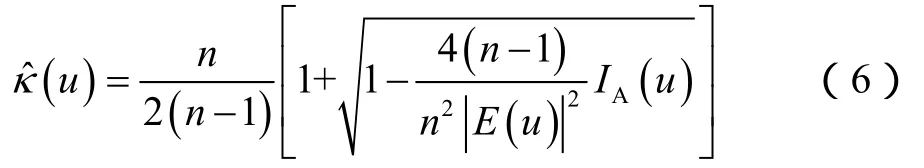
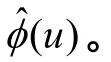

1.2 马尔科夫链蒙特卡洛模拟
每个钻井阶段都可以根据概率密度函数来预测。然而,在大量数据缺失的情况下,很难对整个钻井作业进行有效的预测。假设想要估计包含所有主要钻井阶段的一个完整的钻井作业的总钻井周期,如果只有5%的施工作业包含所有钻井阶段,那就意味着必须忽略其他 95%的施工作业里的数据信息。当完整的施工作业数量不足时,由于仅采用了少量的样本,预测结果就会有所偏差。
采用马尔科夫链蒙特卡洛法(MCMC),可以利用每个钻井阶段的概率密度函数来得到采样数据,因此可以有效便捷地评估与整个施工作业有关的风险。利用马尔科夫链蒙特卡洛法来评估钻井作业的不确定性的方法并不是新提出的[29]。Peterson等[30]模拟了开支授权(AFE)的风险,然而仅采用了少量数据(27口井)且假设输入数据符合大量的特殊分布:正态分布、伽马分布、对数正态分布和指数分布,因此结果并不是很可靠。
本文采用吉布斯采样法,根据马尔科夫链蒙特卡洛法由多变量概率密度函数得到一系列数据。吉布斯采样法是众所周知的 Metropolis-Hastings采样法的一种特殊情况,由于Metropolis-Hastings采样法对跳跃函数的选取很敏感,对于多变量的情况吉布斯采样法更实用。采用吉布斯采样法得到m个钻井阶段的r个模拟结果的过程如下。
③从 1到 m,对所有的钻井阶段重复第②步,就得到包含m个阶段的一个蒙特卡洛模拟结果。
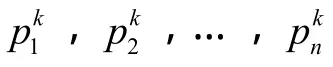
对于变量超过两个的情况,上述过程同样适用。需要注意的是,在这种情况下,对于每一步从条件概率中得到样本的过程,第②步中变量的顺序是随机选取的。
2 算例描述
笔者的行业合作伙伴是一个马来西亚公司,该公司为很多钻井公司提供数据管理服务。本文采用了该公司数据库(见表1)中192次钻井作业的数据集。每次钻井作业的数据集中都包括每次钻井作业中各阶段的顺序、每个钻井阶段的周期、深度等。典型钻井施工井身结构示意图如图1所示,由于本文重点对8个主要钻井阶段进行分析,其他钻井阶段的数据就从数据集里剔除了。将这8个钻井阶段分成了4组,详见下文。
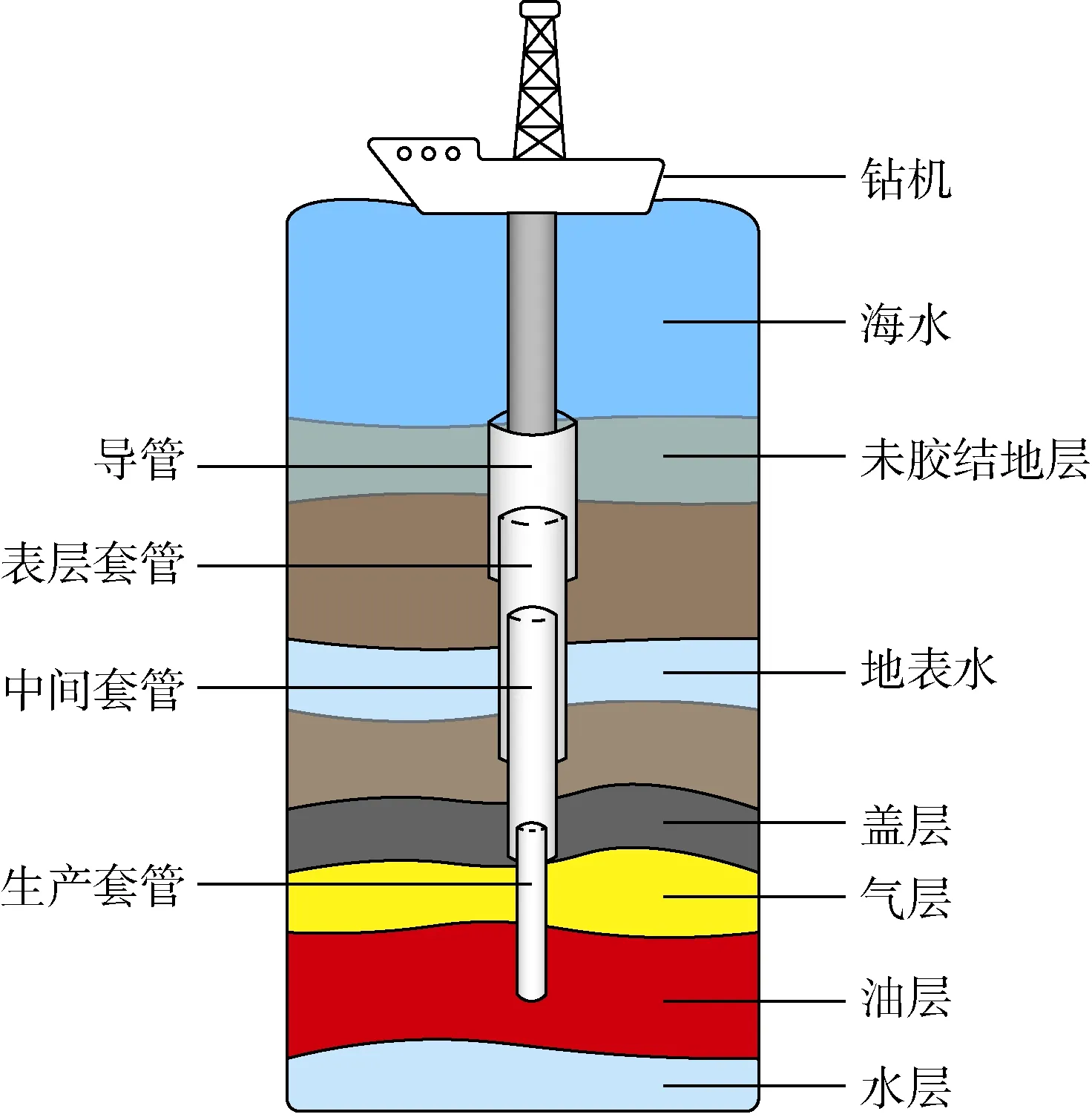
图1 典型钻井施工井身结构示意图
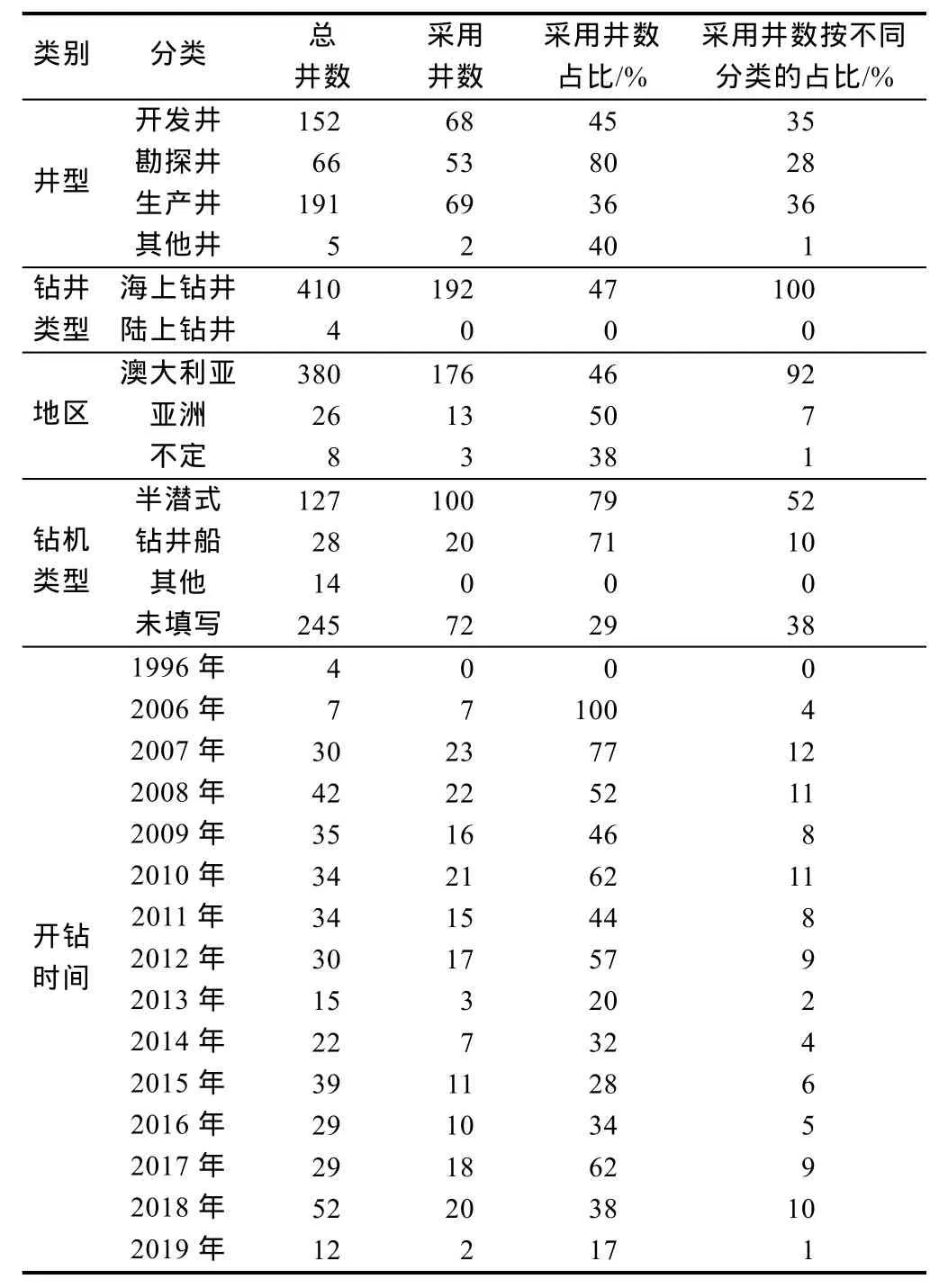
表1 按照不同分类对414次钻井作业的钻井数据汇总
2.1 导眼钻进(CH)和下导管(CC)
导眼或导眼孔的主要目的是在最初的钻井过程中提供一个可靠的结构基础来保证井、井口和作业设备的稳定性。钻井开始后,导眼将钻井液从井筒返排到钻机。导眼钻进的过程一般需要0.35 d(见表2),约8.4 h。下一个作业就是下导管,即采用打桩机将套管用水泥固定在海床上。导管非常厚(厚度大于3 cm),非常短,在61~66 cm的井眼中,导管直径可达47~51 cm[31]。下导管作业平均需要 0.78 d(见表 2),约18.7 h。下导管周期与深度之间的相关系数很小,为0.18,可能是由于到目前为止一直还没有直井钻井。
2.2 表层套管段钻进(SH)和下表层套管(SC)
下导管后就是表层套管段钻进,主要是钻井钻到表土层后向更深层钻井时需要进行的操作,通常会受到松软地层和地下水渗入井眼的影响。钻一个直径约45 cm的表层套管段井眼,平均花费1.9 d(见表2),有时要花14 d左右。下一个阶段就是下表层套管,目的是将井筒中的设备和流体与周围环境隔离开。考虑到固井,标准的套管直径较小(约34 cm)。下表层套管平均需要1.55 d(见表2)。表层套管段钻井周期与深度之间的皮尔森相关系数高达 0.80,说明本文方法可以预测出钻至目标深度所需的时间。
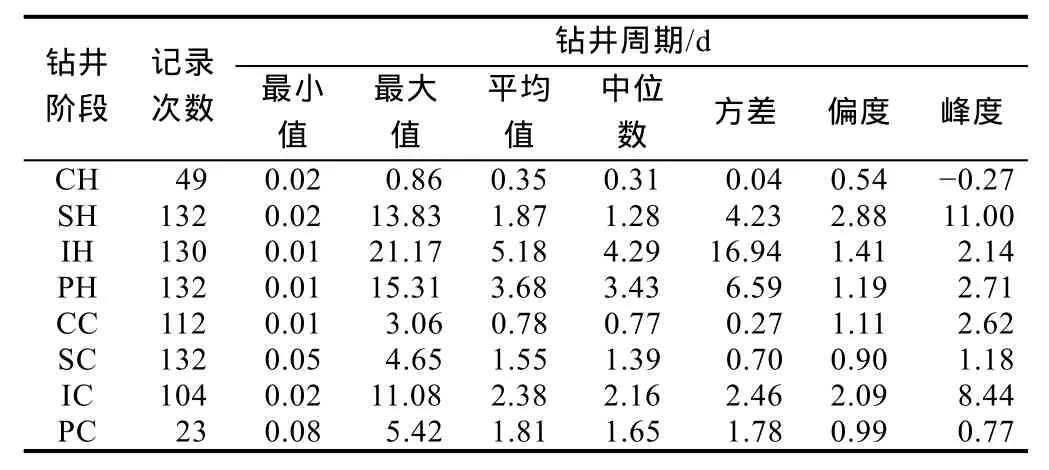
表2 数据集中选出的192次钻井作业的统计数据
2.3 技术套管段钻进(IH)和下技术套管(IC)
在钻井作业中用时最长的就是技术套管段钻进,平均要花5.2 d(见表2)。由于受到各种复杂因素的影响,如海床的地质特征、井筒性质、设备类型和操作以及各种意料之外的技术和非技术事故都会对钻井周期造成影响,精细地模拟技术套管段钻进时间是非常困难的。表2所示的数据集中的数据也证明了这一点,钻井周期的方差很大。一旦钻井完成,下技术套管阶段平均只需要2.4 d就可以完成(见表2)。一般技术套管段井眼和套管直径分别为31,24 cm[31]。
2.4 生产套管段钻进(PH)和下生产套管(PC)
为了到达目标油层,需要进行生产套管段钻进,平均需要3.7 d(见表2)。在生产套管段钻进中会出现更多的技术问题,最长可能需要 2个星期。目标层下生产套管可以封闭产层,为下一步采油提供基础。一般生产套管段井眼和套管直径分别为22,18 cm。下套管平均用时1.8 d(见表2)。由于成本和技术问题,深井中生产套管也可能偶尔换成生产尾管。
3 无事故钻井周期的概率模型系统
为了建立无事故建井周期的概率模型系统,在重建概率密度函数和进行马尔科夫链蒙特卡洛模拟时,提出了行业中常用的两个假设:①假设实测数据点数量足以准确完整地代表某个钻井阶段的实际分布;②假设每个钻井阶段周期的预测是一个随机的过程,包括输入数据和输出数据的固有随机性,而且每个钻井阶段都是独立的随机过程,与其他钻井阶段之间没有相关性。
3.1 各钻井阶段的深度相关概率模型
对于不同的钻井阶段,即导眼钻进、表层套管段钻进、技术套管段钻进、生产套管段钻进、下导管、下表层套管、下技术套管和下生产套管,采用Bernacchia和 Pigolotti提出的自适应核密度估计法[27]可以得到钻井周期与深度的联合概率分布,如图 2所示。图 2中这些阶段的特征总结如下:①所有钻井阶段的施工周期都是多个椭圆区域的叠加,在每个椭圆区域中数据分布都是从边缘向中心越来越密集;②几乎所有的钻井阶段主要椭圆的主轴都在水平方向上被不均匀或不平行地拉长;③CH、SH、PH、SC和 PC阶段的椭圆向对角线方向倾斜(见图2a、图2b、图2d、图2f和图2h中的黄色和绿色部分),这几个阶段钻井周期与深度的皮尔森相关系数较高(0.35~0.80)。按照图 2中的分布,可以根据已知深度预测得到钻井周期的条件概率,反之也可以根据钻井周期预测得到深度的条件概率。

图2 8个钻井阶段无事故钻井周期与深度的联合概率分布
本文主要关注对钻井周期(时间)的预测,图 3是随深度变化的无事故钻井周期条件概率的空间分布。图3中水平线表示采样深度,针对这一深度(将在图4中使用)计算建井周期的一维条件概率。图3表征了在不同深度下钻井周期不同的可能性,但实际上钻井周期随着深度的变化成比例地变化。这与直观感觉一致,即井越深,钻井、下套管和固井所需的时间就越长。
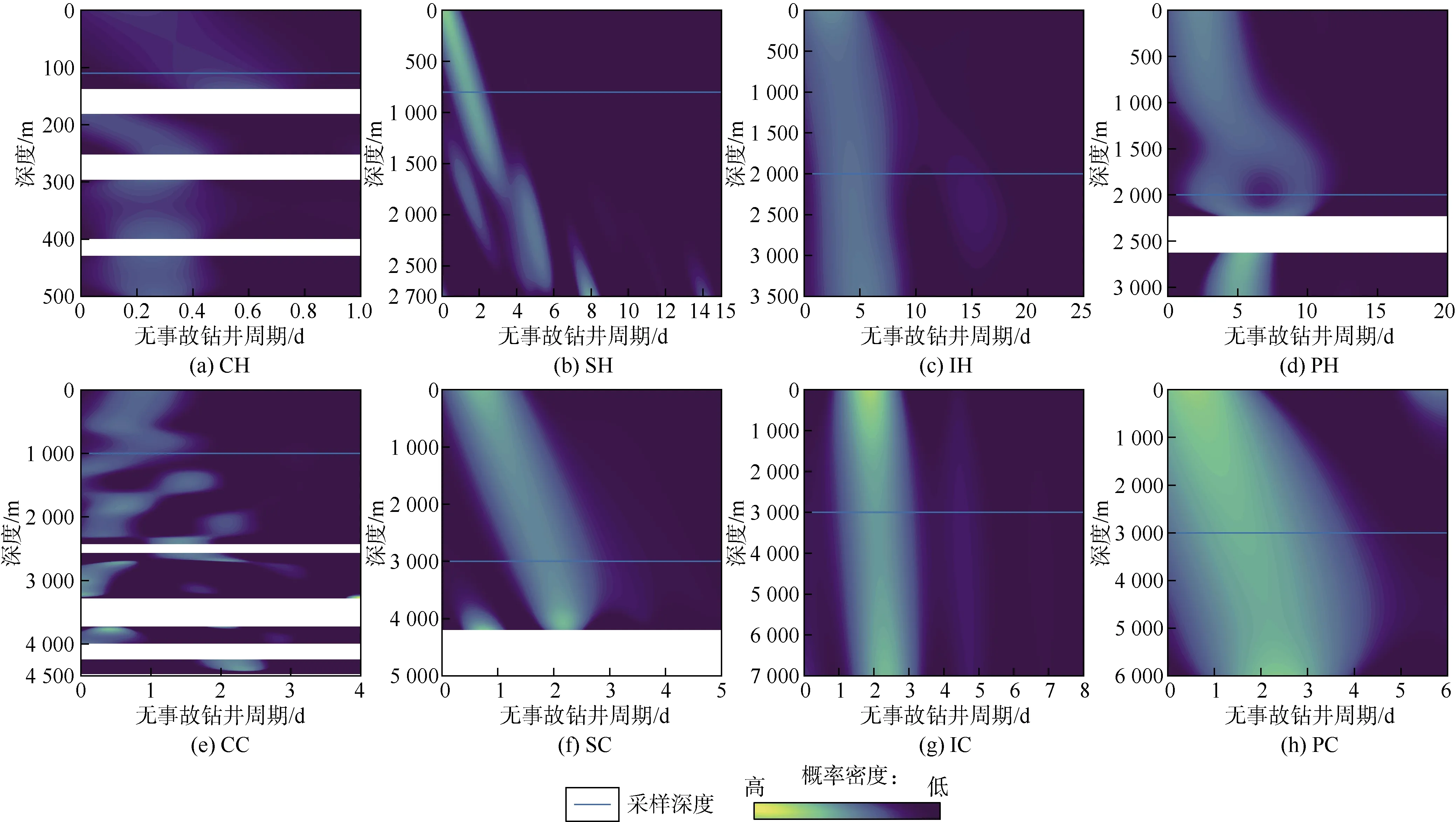
图3 8个钻井阶段随深度变化的无事故钻井周期条件概率的空间分布(水平的白色条状区表示从傅里叶变换中剔除的低概率区)
给定条件概率,就可以对已知深度的各个钻井阶段的周期进行预测。图 4为在给定深度下无事故钻井周期的条件概率分布。例如,图4c描述了在技术套管段钻进阶段钻进垂深2 000 m的钻井周期条件概率。图4中,纵坐标的值越大表示钻井周期的概率越大,根据主要概率分布曲线得出多个众数,主要概率分布曲线及其贡献量(用百分比表示)在图中展示,但贡献量占比小于 1%或者超出绘图窗的概率曲线不在图中展示。以下技术套管阶段(见图4g)为例,第1个概率分布曲线(贡献量占比97%)众数为2.1 d,第2个概率分布曲线(贡献量占比1%)众数为6.7 d,表示概率最大的无事故钻井周期为2.1 d,其次为6.7 d。图4中棕色区域代表每个众数的 P10~P90范围,仍以下技术套管阶段(见图4g)为例,第1个概率分布曲线中,在P10~P90范围内,无事故钻井周期在1.1~3.8 d。

图4 8个钻井阶段在给定深度下无事故钻井周期的条件概率分布
根据各钻井阶段的深度相关概率模型,可以针对已知垂深预测出完成某个钻井阶段所需的周期。本文对主要概率分布进行了评估,给出了值域内的最高发生概率。预测结果以概率范围对应的钻井周期最小值到最大值的形式给出,而不是给出一个确定的值(不能反映实际钻井中的不可预见性),作业者可以据此定量评估钻井计划的风险。
3.2 不考虑事故时间的1次完整作业的蒙特卡洛模拟
进行钻井周期预测时的主要难题之一就是数据不全。在本文采用的数据集中,只有2%的钻井施工作业包含所有8个阶段,大多数钻井作业仅包括3~5个阶段。此外,所有阶段的数据不是呈尖峰态分布(峰度大于3),就是呈低峰态分布(峰度小于3)(见表2),在使用常规的基于数据的统计模型时就有一定难度。由于数据直方图肯定会偏离正态分布,导致难度更大。由于不是所有钻井作业都包含这 8个阶段的数据,很难在一个模型中同时考虑所有阶段。
通过马尔科夫链蒙特卡洛模拟可以对一次包含所有 8个阶段的完整钻井作业的无事故钻井周期进行预测,如图5所示。图5展示了不同模拟次数下的模拟结果,1条蓝色线表示1次模拟的结果。图中黑色实线表示实测数据,通过对每个钻井阶段的原始数据进行算术平均得到。可以看出,当模拟次数为1 000或更多时,蒙特卡洛模拟的众数大概为20 d(见图5c或图5d中红色实线),这与实际钻井阶段的平均时间19 d(由图5c或图5d中所有蓝色实线所示数据求平均值得到)基本吻合。这说明通过马尔科夫链蒙特卡洛模拟能够有效地获得实测数据的平均值。经过1 000次模拟后,P10~P90范围对应的钻井周期范围是稳定的,预计在15~29 d。在某些情况下,一次完整的钻井过程可能会持续长达 43 d,这种风险是不可排除的。需要注意的是,虽然图 5是针对每个钻井阶段的已知深度范围对各阶段的所有值随机运行的结果,但是对于一个确定的深度,仍然可以确定蒙特卡洛模拟结果。

图5 不同模拟次数下无事故钻井周期的马尔科夫链蒙特卡洛模拟结果
综上,可以通过较多次数的蒙特卡洛模拟来预测钻井周期。这种方法的好处是,不需要同时掌握一次完整钻井作业中的所有阶段的所有数据,而是可以将缺失数据的钻井阶段联合起来,进行完整的风险评估。模拟次数越多,对整个钻井作业风险的定量评价结果越可靠。
4 讨论
4.1 模型验证
通常认为,在很多情况下根据已知数据集建立的统计或概率模型足以在实际中应用,而无需进行更多评估[32-34]。然而,本文基于两个方面的考虑进行了更多的分析来验证模型。一方面,有必要对比和验证模型中得到的参数的最优性。另一方面,将模拟参数与实际钻井参数匹配,有助于了解是否可以根据模型获得数据的主要特点。在数据不全的情况下建立模型时,验证就显得更加重要。
重建概率密度函数的难题之一是在选取最优参数时的主观性,包括函数和带宽的优先形式。而核密度估计法受核带宽和核形状选择的影响。通过对经验特征函数进行傅里叶变换,Bernacchia和 Pigolotti[27]发现,低通滤波器有助于获得自适应核密度估计值,可将模拟概率密度函数与实际数据之间的差异降到最低。当样本数量很大时,自适应核密度估计法可以完全收敛,而不受核带宽和核形状选择的影响。
截止频率是建立自适应核密度估计函数时所需的唯一参数,Bernacchia和Pigolotti[27]认为,一半的经验特征函数值在特定经验阈值之上。O’Brien等[28]通过引入快速傅里叶变换对核密度估计法进行了扩展,得到了与超体积相关的替代经验阈值。Bernacchia和Pigolotti[27]证明了这个替代经验阈值在人工数据计算时是有效的,同时,O’Brien等[28]发现,他们的参数对于人工模拟数据和实际数据都是有效且稳定的。O’Brien等[28]也证明了选择的最优参数与其他自动带宽选择法选择的参数的表现同样优异。因此,本文采用了O’Brien等[28]的方法和经验阈值。
图 6是不同钻井阶段的实测数据与多变量概率模型得到的模拟结果之间的统计对比。对于实测数据,统计了每个钻井阶段现有的所有数据。对于模拟结果,采用了每个钻井阶段的概率模型得出的10 000个数据点,剔除了异常值。结果发现,模拟结果与实测数据的统计分析结果具有高度相似性。例如,技术套管段钻进阶段(见图6c)的模拟结果的中位数是4.9 d(见图6c),与实测数据的中位数4.3 d(见表2)非常接近。
为了全面检验模型的性能,总结了图 6中所有统计箱线图的中位数和须值。图7a是无事故钻井周期的统计结果,可以看出各阶段模拟结果的中位数和须值与实测数据的中位数和须值之间高度相关,皮尔森相关系数均高达0.989。图7b是总钻井周期的统计结果,皮尔森相关系数分别高达0.990和0.959。值得注意的是,每个阶段的实测数据点不超过132个。尽管数据不多,模拟结果与实测数据之间仍有较高的匹配度。
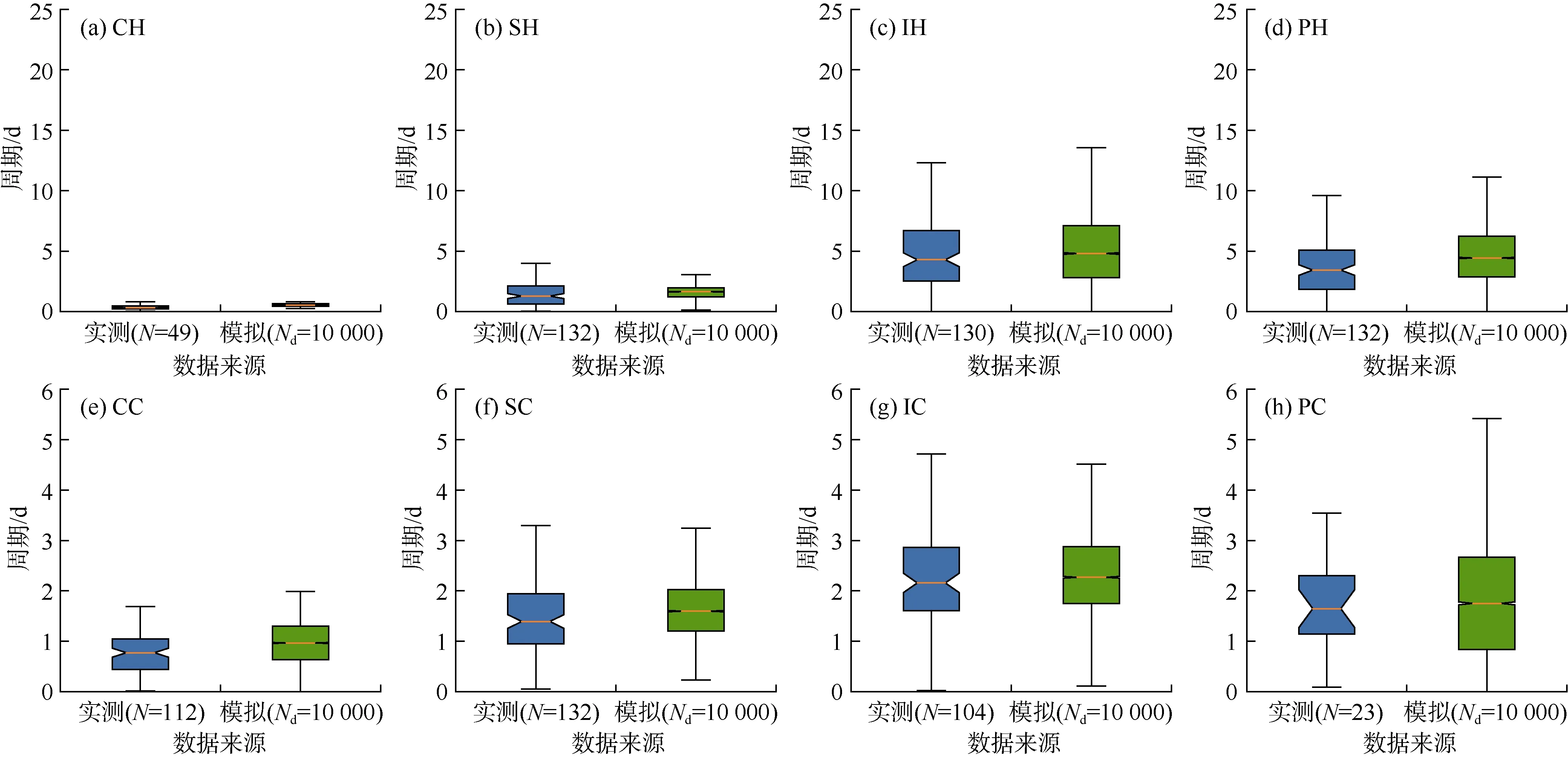
图6 8个钻井阶段实测数据与多变量概率模型模拟结果的统计分析结果对比
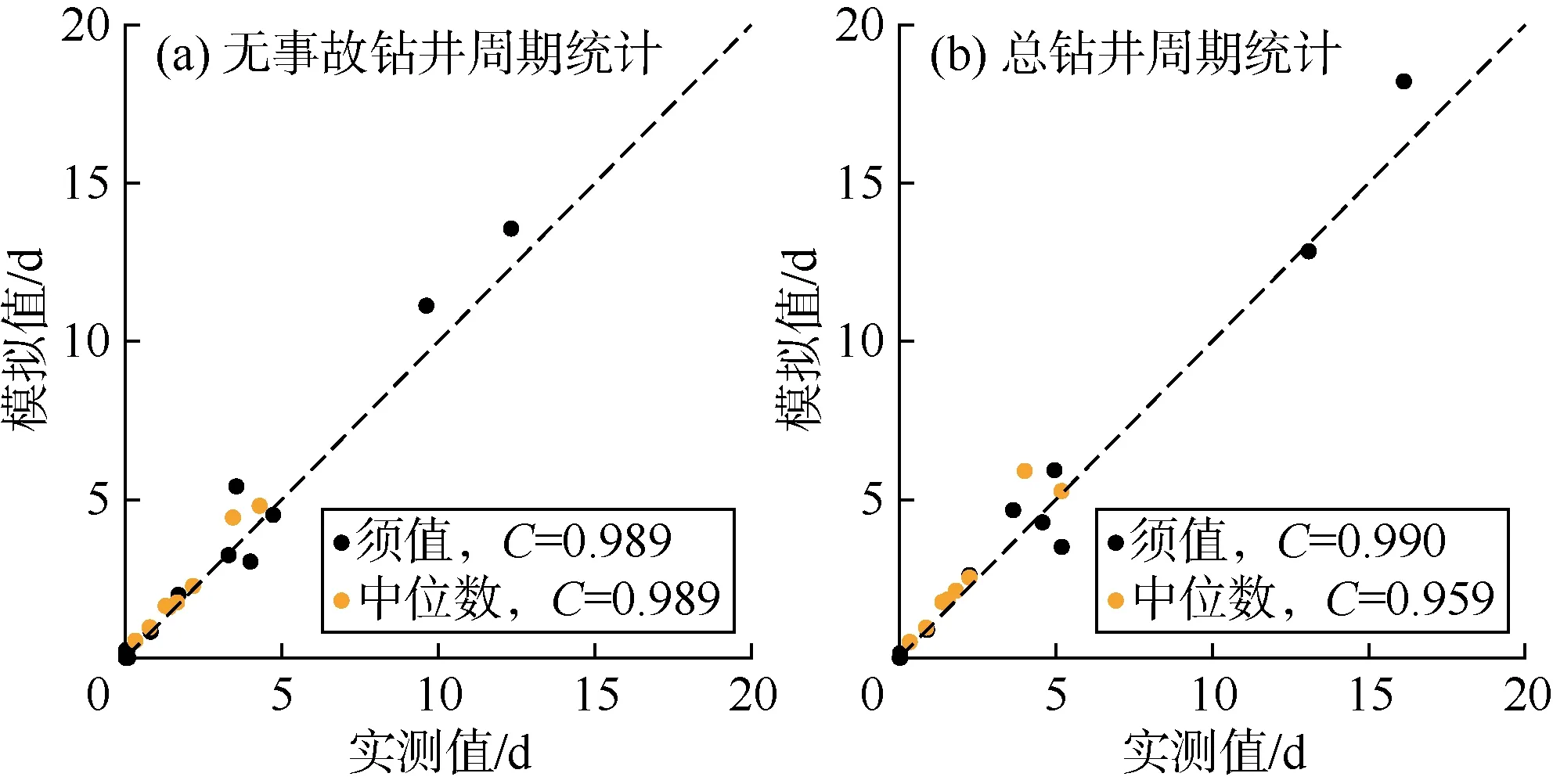
图7 无事故钻井周期和总钻井周期的实测数据与模拟结果的统计参数对比
4.2 无事故钻井周期与总钻井周期之间的差异
无事故钻井周期与总钻井周期之间总是存在着显著的差异。为了对这个差异进行量化,重新推导了每个阶段的深度相关概率模型。然后,对数据集中的所有钻井作业的总钻井周期进行了新的马尔科夫链蒙特卡洛模拟。图 8为模拟得到的无事故钻井周期和总钻井周期的概率分布。对于无事故钻井周期,P10和 P90的对应值分别为10 d和26 d,也就是说,对于一次完整的钻井作业,无事故钻井周期有80%的概率在10~26 d。相比之下,对于总钻井周期,P10和 P90的对应值分别为14 d和38 d。可见,如果钻井过程中出现事故,钻井周期可能延长至少4 d,至多12 d。此外,总钻井周期的概率分布曲线沿着横轴被拉长,尾部更长,表示不仅钻井周期延长,不确定性范围也扩大。
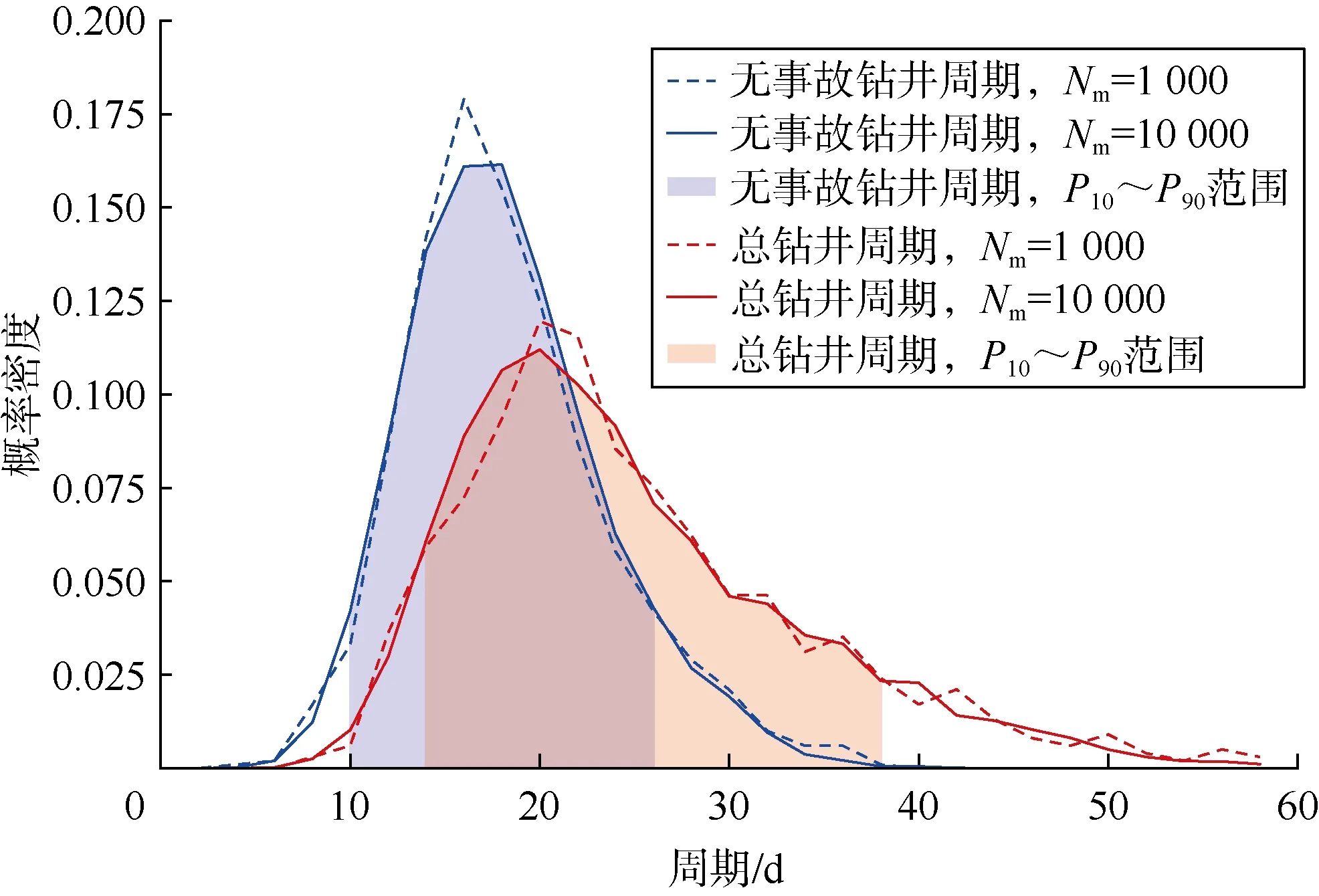
图8 通过马尔科夫链蒙特卡洛模拟得到的一次完整的钻井作业的无事故钻井周期和总钻井周期的概率分布
图9为经过10 000次马尔科夫链蒙特卡洛模拟后得出的各阶段无事故钻井周期和总钻井周期的累计概率分布。可以看出,生产套管段钻进阶段无事故钻井周期与总钻井周期之间的差异最大,最大相差超过10 d(累计概率 95%);表层套管段钻进和技术套管段钻进阶段的总钻井周期会比无事故钻井周期大约多出 2 d(累计概率95%)。

图9 经过10 000次马尔科夫链蒙特卡洛模拟后得出的各阶段无事故钻井周期和总钻井周期的累计概率分布
4.3 由概率模型得出的钻井数据的具体应用
概率法之所以受到关注是因为它可以利用概率分布函数获取更多数据。由于机器学习模型依赖数据的可用性,数据不全会导致机器学习模型表现变差,因此概率法的应用就显得非常重要。为了进一步检验概率法提高机器学习模型预测能力的作用,对不同数量的输入数据进行了随机森林(RF)模型的性能测试。
采用泰勒图描述了不同数量输入数据情况下随机森林模型的性能,如图10所示。采用泰勒图可以在一个图中对 3个主要的统计参数,即皮尔森相关系数、均方根误差和标准差进行评价。从图10中可以看出,模拟数据与实测数据具有相近的标准差,均在2.5~3.3 d这一范围内;均方根误差也相近,均在2.2~2.6 d这一范围内;所有情况下随机森林模型都表现良好,皮尔森相关系数较高(均大于 0.8)。这说明模型模拟得到的数据与实测数据具有相似的特征。也就是说,可以采用概率模型来估计钻井数据,将模拟数据用于机器学习模型的训练。

图10 不同数量输入数据下随机森林模型性能的对比
5 结论
本文提出了一种用多变量概率模型来预测钻井周期的方法。这种方法采用自适应核密度估计法来建立与深度相关的钻井周期概率模型,并结合马尔科夫链蒙特卡洛法模拟一次完整钻井作业周期的概率分布。
利用行业伙伴提供的数据集对模型进行了测试,数据集中的数据都是在实际钻井施工中采集的。研究表明,根据本文建立的模型,当钻井深度一定时,可以预测出各个主要钻井阶段可能的施工周期,将这些施工周期结合起来就可以得到整个钻井阶段的总施工周期。此外还发现,如果在钻井过程中发生事故,在10%~90%的置信区间内,钻井周期延长至少4 d,至多 12 d。采用概率法获取的模拟数据可用于机器学习模型的训练。
符号注释:
C——皮尔森相关系数;d——深度,m;E(u)——经验特征函数;f——多变量概率密度函数;ˆf——f的最优值;F——傅里叶变换;F-1——逆傅里叶变换;i——样本序号;j——数据点序号;k——钻井阶段序号;K——核函数;m——钻井阶段个数;n——数据点个数;N——有相关数据记录的钻井作业次数,简称记录次数;Nd——对模拟结果进行统计分析时采用的数据点个数;Nm——蒙特卡洛模拟次数;p——光滑变量;p1,p2,…,pn——离散数据点;P10,P90——目标值可信度10%和90%对应的概率,%;r——包含所有钻井阶段的蒙特卡洛模拟结果的个数;t——钻井周期,d;u——频域;κ(u) ——核函数的傅里叶变换;κˆ(u)——κ(u)的最优值;φ(u) ——傅里叶变换的逆变换;φˆ(u)——最优逆变换。
猜你喜欢
广西民族大学学报(自然科学版)(2022年1期)2022-05-18 05:18:06
中学生数理化·高一版(2021年3期)2021-06-09 06:10:16
小哥白尼(趣味科学)(2020年6期)2020-05-22 06:43:14
电子测试(2018年10期)2018-06-26 05:53:50
当代旅游(2018年8期)2018-02-19 08:04:22
统计与决策(2017年2期)2017-03-20 15:25:27
通信电源技术(2016年1期)2016-04-16 04:57:39
深圳职业技术学院学报(2015年5期)2015-11-30 06:22:24
中学生数理化·中考版(2015年10期)2015-09-10 07:22:44
化工自动化及仪表(2014年2期)2014-08-02 01:43:26
