
yolov3模型在图形晶圆表面缺陷检测上的优化与应用
2021-11-02 04:59肖安七李成敏
探索科学(学术版) 2021年9期
肖安七 吕 肃 张 嵩 李成敏
深圳中科飞测科技股份有限公司 广东 深圳 518110
1 引言
近年来,随着GPU等硬件和公开数据集[1]的快速发展与完善,以及越来越多的研究人员加入这个领域,目标检测已然成为计算机视觉领域最热门的方向之一。大量性能优异的目标检测模型被相继提出,并在实际的工程领域中得到验证。
大体来说,近年所提出的目标检测模型还是以基于锚框(anchor based)的模型为主。此类模型主要分为两类:一类是以faster-rcnn[2]为代表的二阶段(two stage)模型,另一类是以yolov3[5]为代表的一阶段(one stage)模型。一般而言,二阶段模型精调后的精度往往比一阶段模型要好,但是模型训练和推理速度远不及一阶段模型,而实际工程领域对算法实时性有较高的要求,所以以yolov3[5]为代表的一阶段模型被广泛采用。但是直接采用这些模型应用于具体的半导体检测项目往往不能得到最佳的检测效果,原因主要有以下两点:一是数据集的差异。以ImageNet[1]为代表的公开数据集以自然图像为基础,在目标特征和图像纹理上与产业界的情况相差较大。二是关注的评价指标不一致。论文中一般考察模型m AP(mean Average Precision)值,而在实际中更加关注缺陷的召回率,且对目标框回归的精度要求明显弱于分类精度。另外,在晶圆缺陷检测场景中,“回拍”操作会使得缺陷优先出现在图像中间区域。此类重要的先验知识可以引入模型设计中,进一步提高模型的性能。
鉴于以上分析,本文选择在yolov3模型的基础上进行针对性修改和优化。主要包含以下三个方面:一是优化真实缺陷(groud truth)的编码过程,二是在骨干网络(backbone network)中加入注意力模块,三是加入新的数据增强方法。
2 相关工作
自2012年Alexnet[7]网络模型被提出后,以卷积神经网络为代表的深度学习便开始了研究热潮,全世界研究者相继提出VGG[8]、Googlenet[9]、Resnet[10]、Densenet[11]等 经 典 分 类 网 络。与此同时,以分类网络为基础的目标检测网络也得到了空前的发展,从2014年提出的二阶段的RCNN模型[12],到以yolov3[5]为代表的一阶段模型,目标检测模型性能越来越好。
发展至今,深度学习技术在工业领域也得到了广泛的应用[21]。在半导体图形晶圆缺陷检测领域也有少量的相关技术研究[24],但是还不够成熟,本文即是一种探索与研究。
3 方法
3.1 优化编码
在yolov3模型中,前景目标的编码过程如下:首先计算缺陷目标与所有锚框(默认为9个)的iou值,把iou值最大的锚框判为正样本,负责预测该目标,然后iou值小于设定阈值T(如0.5)的锚框被判为负样本,最后若一个锚框与所有前景目标的iou值大于T而又不是最大的,则直接忽略,不参与模型最后的损失计算。考虑到实际中缺陷的大小和长宽比变化很大,且大部分缺陷尺寸中等。采用上述编码方法会导致不同特征检测层之间信息冲突问题,这在yolov3-asff[18]中已给出详细说明。
针对这个问题,目前已有一些论文给出了一些解决方法[18][19],但是并没有从源头去处理这个问题。本文认为这个问题的根源在真实缺陷的编码思路上,如果能够把缺陷目标的信息尽可能地保留在所有检测特征层上,就不存在这个信息冲突的问题。但是对于尺寸较大(或较小)的缺陷,位于浅(深)层特征层中的锚框与该目标的iou值过小,硬性进行编码会导致目标框回归困难,所以需要进行一定的选择。改进的编码方法与yolov3基本一致,同样地首先计算真实缺陷与所有锚框的iou值,把iou值最大的锚框判为正样本,同时把其他特征层上与该真实缺陷iou值大于某个阈值T1的也判为正样本,其余部分与yolov3保持一致。阈值参数T1需要通过实验确定。
3.2 注意力模块
在卷积神经网络结构设计中,注意力机制也是一个重要的组成部分。考虑到在半导体图形晶圆缺陷检测中有一步“回拍”操作,会使得缺陷优先出现在图像中间区域,同时半导体图形晶圆缺陷对颜色敏感,而CBAM[20]注意力机制中正好同时包含有空间注意力和通道注意力,所以可以尝试在yolov3模型中引入CBAM注意力模块。但是该注意力模块插入的位置需要通过实验确定。
3.3 数据增强
目前常见的增强策略有镜像、旋转、剪切、颜色变换等[5]。yolov4[6]模型中提出mosaic数据增强,该方法把四张图缩放后拼接为一张图,如图1左图所示,可以很好地提升模型的检测性能,尤其是对于小目标的检测。但是在实际项目中,晶圆缺陷是尺度敏感的,直接采用mosaic数据增强会破坏这种缺陷判别特征。改进的措施如下:首先从训练集中随机选取四张图,然后随机从每张图中截取一个一定大小的缺陷块(patch)并把这四个缺陷块不做任何缩放地拼接起来,拼接后的图像如图1右图所示。此种数据增强方法命名为patch-mosaic4。

图1 mosaic数据增强(左)与
考虑到半导体晶圆缺陷会优先出现在图像中间区域,而patch-mosaic4数据增强会使得缺陷分布在图像四周,从而在一定程度上破坏了这一先验规则。另外,由于晶圆图像背景复杂,在实际应用时模型时常会对一些无缺陷图像有较多过检,但是这些背景下的缺陷图像收集工作一般比较麻烦,所以也需要通过数据增强的方式予以缓解。针对这个问题,本文提出patchmosaic5数据增强方式。基本思路与patch-mosaic4一致,都是拼接多张图,不同点有两个:一是patch-mosaic5在patch-mosaic4的基础上在图像中间再添加一个缺陷块,如图2左图所示;二是此时用于四周拼接的四张图像是随机从有缺陷训练集和无缺陷数据集(当前模型过检较多的无缺陷图像组合成的数据集,需要在训练前收集完毕,且数据集是动态变化的)中随机挑选的,即这四个拼接块中有些块可能没有缺陷,如图2右图所示,第二象限和第四象限的两个图像块中没有缺陷。这样的设计完美地符合了本项目缺陷的特征,同时充分利用了mosaic数据增强方法的优势。

图2 patch-mosaic5数据增强示例
4 实验
4.1 实验说明
本文实验数据集是我们在现场采集并标注好的数据,共约三万张,大致均分为七个类别,随机选取百分之十的数据作为验证集,也做测试集使用。其他训练参数,如优化器、学习率调整方法等基本遵循yolov3[7]的设置。实验平台是基于ubuntu20.04,2080ti显卡。
4.2 对比实验
在本节中,我们将以累加的方式展示每个策略的有效性,结果如表1所示。需要说明的是,在实际应用中最受关注的是两个指标:模型检测精度和推理速度。前者以m AP50衡量,而不是常用的m AP,因为实际项目中更加关注缺陷分类准确度,而不是定位准确度。后者以单张图的推理速度衡量,其中推理时间和FPS(Frames Per Second)包含最后的非极大值抑制(Non-Maximum Suppression,NMS),且推理时间和FPS使用单块2080ti显卡以batch size等于1测试得到。
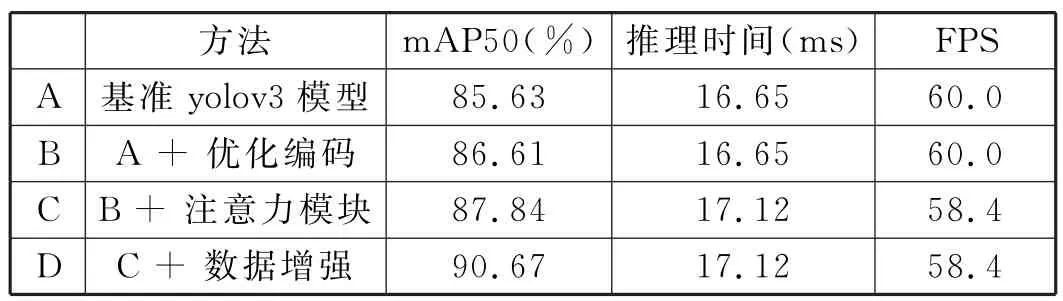
表1 验证集上的对比实验结果统计表
可以看到采用预训练权重训练后得到的基准yolov3模型最后精度可以达到85.63%,单张图的推理时间约为16ms。
A→B:如上所述,优化编码过程中涉及到一个重要的超参数T1需要通过实验确定,且不难分析T1值过大或过小都不好。实验中,当T1取不同值时对应的m AP50值如表2所示,最佳精度以黑体标出。可以看到T1取0.2时效果最佳,相对于基准模型精度可以提升0.98%。

表2 不同T1值对应m AP50
本文在yolov3模型的基础上提出Sky-yolov3模型,主要是针对半导体图形晶圆缺陷检测场景尝试了三个新的策略,包括优化缺陷目标的编码过程,较好地缓解了不同检测层之间的矛盾,然后根据项目特点在骨干网络中引入CBAM模块,并且对该注意力模块插入的位置进行了实验分析,最后在mosaic数据增强的基础上提出了新的数据增强方法。通过使用这些改进策略,模型精度可以有效提升5.05%,同时推理速度几乎不受影响。需要说明的是本文更多的是为了验证以上策略的有效性,而不是追求最优性能,所以对于上述多个重要超参数并没有进行详细测试与优化。希望本文能够为研究人员和工程人员提供一个模型优化的思路。下一步工作将继续探索更多更好的策略,并用到实际项目中以获得更好的检测性能。
B→C:这一步考虑模型在B的基础上引入注意力机制,重点考察注意力机制插入的位置。实验中发现,在骨干网络的每一个残差块末尾插入CBAM模块后模型表现出一定的过拟合现象,验证集精度降低到85.57%,考虑是因为模型中添加太多CBAM模块而引入太多模型参数。鉴于此,实验中尝试在骨干网络最后一个stage的每个残差块中插入CBAM模块,结果发现依然有轻微的过拟合。受[23]启发,本文将CBAM模块接在骨干网络最后的输出特征层上。进一步地,本文在原始CBAM模块处理的基础上添加一个跨层连接,如图3所示,进一步提升模型性能。实验发现,使用图3所示插入方式模型精度可以提升1.23%,且推理速度几乎不受影响。
图3 改进的CBAM模块图
C→D:考虑在模型C的基础上添加上述数据增强方法。新的数据增强方法包含原始数据增强方法和patch-mosaic5。模型训练时,训练数据集先经过原始数据增强方法进行图像变换,然后按一定概率执行patch-mosaic5。需要注意的是原始的数据增强方法中不包含大尺度的缩放变换和较大的色度变换,因为晶圆缺陷对缩放和颜色敏感。采用上述数据增强方法能带来较大的性能提升,约2.83%。
5 结论
本文在yolov3模型的基础上提出Sky-yolov3模型,主要是针对半导体图形晶圆缺陷检测场景尝试了三个新的策略,包括优化缺陷目标的编码过程,较好地缓解了不同检测层之间的矛盾,然后根据项目特点在骨干网络中引入CBAM模块,并且对该注意力模块插入的位置进行了实验分析,最后在mosaic数据增强的基础上提出了新的数据增强方法。通过使用这些改进策略,模型精度可以有效提升5.05%,同时推理速度几乎不受影响。需要说明的是本文更多的是为了验证以上策略的有效性,而不是追求最优性能,所以对于上述多个重要超参数并没有进行详细测试与优化。希望本文能够为研究人员和工程人员提供一个模型优化的思路。下一步工作将继续探索更多更好的策略,并用到实际项目中以获得更好的检测性能。
猜你喜欢
计算机与生活(2022年11期)2022-11-15
中南民族大学学报(自然科学版)(2022年3期)2022-05-08
小雪花·成长指南(2022年1期)2022-04-09
一重技术(2021年5期)2022-01-18
北京航空航天大学学报(2020年8期)2020-09-10
甘肃教育(2020年22期)2020-04-13
计算机系统应用(2020年3期)2020-03-18
电子制作(2018年11期)2018-08-04
第二课堂(课外活动版)(2016年2期)2016-10-21
华人时刊(2016年16期)2016-04-05
