
Python在短临气象预报检验中的应用
2021-11-02 01:36何佳惠建忠何险峰王曙东高金兵
气象科技 2021年5期
何佳 惠建忠* 何险峰 王曙东 高金兵
(1 中国气象局公共气象服务中心, 北京 100081; 2 华风气象传媒集团有限责任公司, 北京 100081)
引言
气象服务的核心竞争力是不断提升的预报质量。通过检验评估给出客观结果,一方面便于管理人员进行考核,另一方面便于研发人员对比不同方法带来的预报性能改变,促进产品不断改进完善。
国家气象中心建设开发的基于Web的国家级天气预报检验分析系统[1],实现了涵盖国家级省级智能网格预报、全国城镇天气预报等数十项检验业务产品的检验评估。用户可以通过浏览器查看相应产品的检验反馈信息,为各省以及国家级预报业务考核提供了信息支撑。万夫敬[2]等分析了ECMWF模式气温预报在青岛地区的预报性能,根据模式误差特点,给出主观订正参考值,提高了气温预报正确率。刘丽敏[3]等通过对中央台精细化温度预报在伊春市的检验和误差分析,掌握其预报性能,在实际工作中有针对性加以订正,为本地释用提供依据。赵平伟[4]等开展了GPM IMAGE、ERA5降水数据在云南的适用性评估和对比。蔡晓杰[5]等利用上海沿岸海域19个站点风场资料使用平均误差、预报准确率等指标对风速、风向、大风过程进行检验。吴瑞姣[6]等运用两分类TS评分、邻域法FSS评分方法对安徽省WRF模式短时强降水开展检验。郑琳琳[7]等采用均方误差、TS评分等方法对改进的降水临近外推预报技术方法进行效果检验,得出新方法更具优势的结论。刘凑华[8]等研究了基于目标的降水检验方法并对其改进后进行业务应用。可见检验在业务中发挥着重要作用。目前检验针对的产品在时次、时效上主要是天或小时量级,少有针对分钟级这样高频次发布,高时间分辨率产品的检验。产品在时间维度精细化的提升意味着检验计算时间复杂度的增加。
Python是近几年越来越受到开发人员关注和使用的编程语言。其简洁、易于理解、功能丰富的特点无论是专业编程人员还是普通用户都能够快速上手。在气象领域,推出了很多易用工具包。如标签化多维数组和数据集xarray[9]——在吸收用于实现科学数据自我描述的通用数据模型(Common Data Model)基础上,建立类似pandas的工具,使分析多维数组变得简单、高效、不易出错。国家气象中心预报技术研发室使用Python研发了全流程检验程序库[10],在数据层提供了数据读写、转换等基础函数;在检验算法层提供有无预报、多分类、概率预报等检验算法;在检验产品制作层提供了数值型、表格型、图片型、误差序列分析等函数,成为国内第一款专门用于气象预报检验的python程序库。本文在检验结果可视化阶段使用了该库提供的功能。
基于机器学习方法的短临多要素气象预报系统(Weather Elements Nowcasting based on machine learning, 简称WEN),每10 min滚动更新发布未来2 h多气象要素,覆盖中国区域的短时临近预报,具有高更新频次、高时空分辨率特点。系统在分布式计算环境下,建立72候(1年)×12时辰(1天每2 h为1个时辰)多预报时段复杂预报模型。如何快速获得检验结果是本项工作面临的挑战。
如图1所示,WEN检验子系统主要分为数据准备、检验计算和检验分析3个阶段。第1阶段进行数据读取、合并,目标是设计通用的数据模型。第2阶段进行检验计算,包括连续型数值预报检验、晴雨检验和降水分级检验3类检验方法,全部要素共计10个检验指标。第3阶段分要素、区域对WEN模型进行性能评估。

图1 WEN检验业务流程
1 数据模型
1.1 检验数据
多维数组(又称n维,ND ,有时称为张量)是计算科学的一个重要部分,在很多领域都有应用,包括物理、天文学、地球科学、生物信息学、工程、金融和深度学习。在Python中,NumPy为处理原始ND数组提供了基本的数据结构和API。然而,真实的数据集通常不仅仅是原始的数字,它们有标签来编码关于数组值如何映射到空间、时间等位置的信息。Xarray在原始的与Numpy类似的多维数组上引入了维度、坐标和属性形式的标签,使得开发更直观、简洁、更少出错。其核心数据结构Dataset被设计为NetCDF文件格式的数据模型的内存表示。
WEN系统采用网络通用数据格式(Network Common Data Form,NetCDF),使用TDS工具(THREDDS Data Server,TDS)管理文件并提供数据访问服务。预报和观测数据(以下统称检验数据)均为每10 min发布一次。每个时次发布的站点预报数据包括预报时刻、站点、气象要素3个维度,观测数据包括站点和气象要素2个维度。
为避免每次在线获取耗时缺点,同时提高处理和共享能力,采用地球科学科研领域元数据标准CF(Climate and Forecast Metadata Conventions)[11],将检验数据按天合并后保存到本地。数据模型构建分析如下:①检验用的站点数据属于离散采样几何类型(Discrete Sampling Geometries);②一天多个时次更新发布,构成了时间序列(Time Series)。基于此,检验数据采用正交多维数组的时间序列数据表示方法,站点预报数据模型如图2所示。预测数据模型去掉“预报时效”维度即为观测数据模型。在计算机内存中对应Xarray的Dataset。在预测和观测数据匹配时,通过表示位置的“station”和表示时间的“time”两个“标签”即可实现检验数据配对,体现了xarray直观、简洁的优点。

图2 WEN检验数据模型(按天合并的站点预报)
1.2 结果数据
检验方法不同对应指标、要素不同。如晴雨检验和降水分级检验仅针对降水要素,包括TS评分、空报率等指标。连续型预报数值型检验包括平均误差、均方根误差等指标。WEN规定按候输出检验结果。基于此,检验结果按检验方法分类生成,在时间维度包括时效、时辰等。
1.3 站点数据
传统检验方法基于点对点的对比,即在一个时间点上参与检验的样本数为该区域的站点数。WEN系统包括105567个站点。考虑观测数据质量,选取包括国家级气象站(基准站、基本站、一般站)和质控后的部分区域自动站,共计10656个站点。在此基础上将全国分成8个区域,分区范围见图3,各分区站点数见表1。
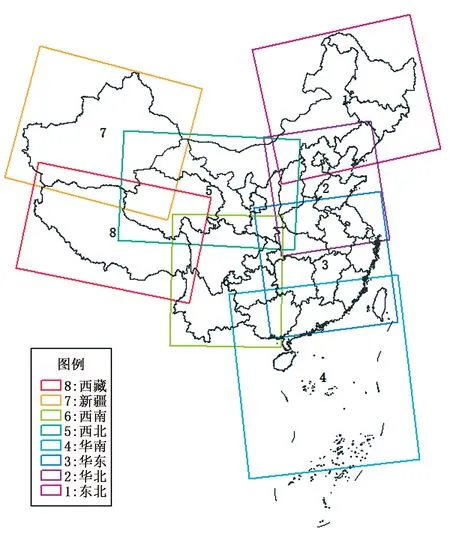
图3 检验分区示意

表1 分区站点数
2 检验计算
WEN采用连续型预报数值检验、有无预报检验(晴雨预报检验)和多分类检验(降雨分级检验)等3类检验算法。后两类属于分类问题,前者是常见的二分类,后者是类别数大于2的分类。在分类算法的实现中应用混淆矩阵获得分类样本统计。针对耗时任务给出了并行解决方案。
2.1 检验方法
连续型预报检验采用平均误差、平均绝对误差、均方根误差、偏差4种统计方法,检验变量包括气压、温度、相对湿度、风速等近地面要素。降水采用技巧评分(TS)、相当技巧评分(ETS)、空报率、漏报率、预报偏差、准确率6种检验方法。上述方法已在业务中广泛应用,在此不做详细介绍。计算公式主要参考由陈昊明等[12]的高分辨率区域数值预报业务检验评估指标及算法。降水分级检验主要参考关于下发中短期天气预报质量检验办法(试行)的通知(气发〔2005〕109号)中中短期天气预报质量检验办法(试行)解释说明(表2)和短时气象服务降雨量等级划分[13](表3)。

表2 降水分级检验评定简表

表3 短时气象服务降雨量划分 mm
2.2 数据缺失处理
为保证检验结果的正确性及连续性,缺失数据的处理是必不可少的关键步骤。数据缺失有两种表现,一是数据文件缺失,二是数据文件中存在空数据。第1种情况表明某时次没有可用于检验的数据,可将检验结果置为一个约定值,例如-999。第2种情况则需要将空数据去除,从而保证统计样本的有效性。需要注意的是空数据并非一一对应,可应用公共掩码矩阵对检验数据进行剔除。技术实现的关键代码见图4。

图4 缺失值处理关键代码
2.3 混淆矩阵
混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型预测的类别进行判断汇总。其中矩阵的行表示真实值,矩阵的列表示预测值。基于Python语言的机器学习工具scikit-learn的metrics模块的混淆矩阵函数confusion_matrix实现了混淆矩阵的计算。通过传递真实类别和预测类别样本,返回一个n阶矩阵C(n表示类别数,如二分类n=2),Ci,j表示真实类别为i预测类别为j的样本数量。以二分类晴雨检验为例,C0,0表示真反例即命中否的样本数,对应表2中ND;C1,0表示假反例即漏报的样本数,对应表2中NC;C0,1表示假正例即空报的样本数,对应表2中NB;C1,1表示真正例即命中的样本数,对应表2中NA。二分类混淆矩阵与晴雨判定对应关系见表4。通过将气象领域分类检验的判定表与机器学习领域分类模型评估分析表即混淆矩阵建立对应关系,应用混淆矩阵函数实现分类检验计算公式中各参量,再根据公式最终获得检验计算结果。晴雨检验计算实现的关键代码见图5。

表4 混淆矩阵晴雨检验对应关系

图5 晴雨检验计算实现代码
2.4 并行计算
2.4.1 并行计算概念、方式、环境
从计算复杂性的角度来看,一个算法的复杂性可表示为空间复杂性和时间复杂性两个方面。并行计算(Parallel Computing)的基本思想是用多个处理器来协同求解同一个问题,即将被求解的问题分解成若干个部分,各部分均由一个独立的处理器或处理机来并行计算。并行计算的目标就是尽量减少时间复杂性,通常这是通过增加空间复杂性来实现的。并行计算可分为时间上的并行和空间上并行。时间上的并行就是指流水线技术。空间上的并行则是指多个处理器并发的执行计算。并行环境多为MPP(Massively Parallel Processing,大规模并行处理)并行机。不同于普通PC机,通常并行机有特定的系统结构,支持指定的并行环境(常见的有MPI(Message Passing Interface)),硬件价格昂贵,同时并行计算的实现也是一项复杂而艰巨的工作。
曹晓钟等[14]针对大量神经网络训练、预报的需求,在SP2并行机上实现了基于主从计算模式,采用粗粒度任务划分的并行方案。赵军等[15]在多核高性能计算机上使用MPI/OpenMP混合并行计算编程,以增量方式和较小的并行化代价实现了对AREM模式并行化改进,取得了较好的并行计算效果。二者均是在特定并行机环境下实现的并行化。周钦强等[16]采用Java语言基于Eclispes平台开发实现了基于TCP多连接通信实时并发数据处理系统,满足对周期性大批量浪涌数据进行实时快速处理的要求。系统运行于单处理机上。其主要利用线程池化技术和并发管理机制,实现过程不仅需要对不同线程进行详细的程序流程分析,还要处理复杂的线程安全问题,开发成本相对较大。韩帅[17]等利用多节点分块并行与模式并行结合的计算方案,解决了系统文件大小受限、计算资源和计算时效等问题。是一种时间和空间二维并行的方案。
2.4.2 DASK并行计算框架
DASK是一款开源免费、与现有科学计算项目Numpy、Pandas、Scikit-Learn高度协同的基于python语言的并行计算框架[18]。它以一种更方便简洁的方式处理大数据量,能够在普通单机或集群中进行分布式并行计算。DASK由两个部分组成,动态任务调度和“大数据”集合。动态任务调度包括单机调度器和分布式调度器,分布式调度器可以在单机上运行,提供了比单机调度器更丰富的功能,如诊断面板。在单机中通过scheduler参数设置线程或者进程来并行处理,也称为伪分布式。“大数据”集合提供的3种基本数据结构分别是arrays、dataframes、bags。Arrays是对Numpy中的ndarray的部分接口进行了改进,从而方便处理大数据量。Dataframes是基于Pandas DataFrame改进的一个可以并行处理大数据量的数据结构。以上两者通过对大数据量进行分块处理,提供了大于内存数据的解决方案。Bags主要用于半结构化的数据集,比如日志或者博客等。DASK提出的延迟计算是在一个普通的Python函数上面通过dask.delayed函数进行封装,得到一个delayed对象。该对象只是构建一个任务图(Task Graph),并没有进行实际的计算,只有调用cumpute的时候才开始进行计算。延迟计算非常适合当面对的问题是可并行的但是不适合高度抽象如Dask Array或Dask Dataframe的场景。下面给出一段在单机上使用分布式调度器、延迟计算、多进程实现并进行化的代码示例,见图6。

图6 一种DASK并行化示例代码
2.4.3 WEN检验并行化实现
并行计算首先是一种解决计算问题的思想。分析WEN检验,以数据准备环节为例,处理过程分为两个步骤:①读取数据,这个操作对每个文件是相同的;②所有文件读取结束后进行合并操作。读取一个文件是一个独立动作,互相之间无依耐关系,可同时执行。利用dask.delayed将读取文件进行并行化改造。以处理156个观测文件(1 d+2 h)为例,程序分别在两台具备不同核数的普通PC机上运行。考虑网络带宽时间维度不均匀性,为使测试结果更客观,选取2020年9月1—5日,每个日期在不同时间分3次运行,分别记录每次的运行时间,再计算平均用时。并行前后程序执行时间见表5。以平均数衡量,56核处理机效率提升11倍,96核处理机效率提升9倍。进行并行化改造增加的代码不超过10行。
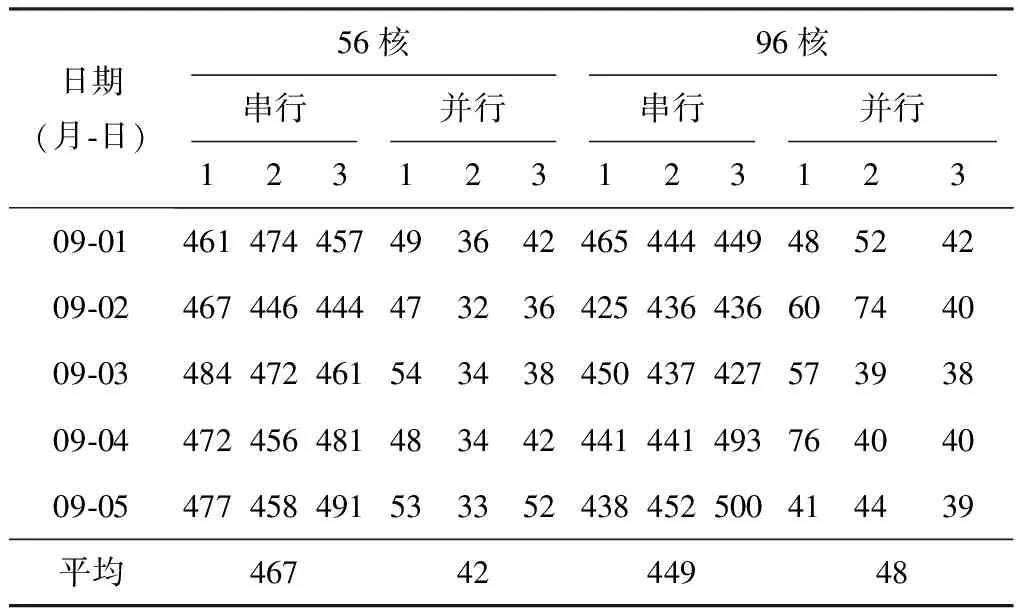
表5 观测数据采集合并运行时间测试结果 s
运用相同思路,对检验计算环节代码进行并行化改造。以计算1天数据每个时次每个时效数值型预报检验为例(仅9月1日数据缺失36个时次,其它日期完整),时次和时效两个维度同时并行,即并行任务有144×12=1728个,测试结果见表6。并行后,56核环境效率提升20倍,96核环境提升51倍。改造后的关键代码见图7。

图7 WEN数值型检验方法并行化实现关键代码

表6 连续型数值型预报检验(每时次每时效)运行时间 s
从测试结果来看,效率提升并非与CPU核数成线性递增。首先,该测试结果采用单机多进程并行方案,且并行任务数大于核数,即并行任务与CPU并非一次分配到位,而是进行了多次分配。其次,当进程间传输数据较大时,会产生性能损失。从表5和表6并行方案测试结果来看,96核环境耗时均高于56核环境。但总体上计算效率并行方案都远高于串行方案。
对于串行方案,表5测试结果显示,56核环境略高于96核,但相差不大。主要原因是表5对应的业务属于IO密集型,主要受实时网络流量影响,受CPU型号差异带来的性能影响较小。表6测试结果,96核环境耗时是56核环境的3倍左右。表6对应的业务属于计算密集型,主要受CPU性能影响。56核环境CPU型号高于96核环境。两者的型号分别是56 Intel(R) Xeon(R) Gold 5120 CPU @ 2.20 GHz和96 Intel(R) Xeon(R) CPU E7-8850 v2 @ 2.30 GHz。
3 检验分析
图8是2021年3月1~6候模型的全国区域气温要素检验结果(篇幅有限仅以气温要素均方根误差指标为例进行说明)。图中横轴表示一个候的预报模型,每个刻度代表一个模型(即每天12个时辰之一,世界时)。从图中可以看出,①3月WEN模型气温均方根误差最大4.77 ℃(第1候第11时辰),最小1.13 ℃(第4候第5时辰);②每候总的趋势表现为:后5个时辰较前7个时辰大,即夜间(北京时晚10:00至次日早08:00)误差较白天大。对比了21年3—5月的检验结果,发现不同月份表现差的模型均集中在夜间。

图8 2021年3月第1~6候WEN模型全国气温均方根误差
4 结论
本文在分析业务需求的基础上,设定快速计算为目标,重点围绕气象领域检验分类问题和应用并行计算改善时效性两个方面,设计并实现了针对高频次、高时间分辨率短临气象预报产品的检验系统。今后将围绕检验报告自动生成、容器化部署等开展工作,推动公共气象服务中心产品检验业务常态运行,为实现气象服务高质量发展贡献力量。
猜你喜欢
现代信息科技(2021年21期)2021-05-07
舰船科学技术(2020年2期)2020-04-17
电子制作(2019年14期)2019-08-20
读与写·教育教学版(2017年10期)2017-11-10
党的生活·党员电教与远程教育(2017年9期)2017-10-17
故事会(2016年21期)2016-11-10
党政干部学刊(2015年7期)2015-12-24
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
