
DSC-SSD在政务服务机器人场景理解中的应用①
2021-11-02 14:32:40邓绘梅
佳木斯大学学报(自然科学版) 2021年5期
邓绘梅
(中共安庆市委党校,安徽 安庆246000)
0 引 言
随着我国科技水平的不断提高,机器人已广泛应用于服务业、制造业等各个领域中,而我国电子信息、人机交互等技术也在促进着机器人的不断创新与优化。在机器人工作的过程中,其对工作场景的感知与理解极为重要,唯有充分获取到场景中的视觉信息,机器人才可进行信息的识别处理、打造场景中的事物空间层次等一系列作业,进而提供更为优质的各项服务[1]。DSC-SSD算法是一种优化的基于卷积神经网络的目标检测算法,能够通过深度学习、网络模型训练等方式,在目标检测中展现其较高的检测精度[2]。因此实验中将重点探究DSC-SSD目标检测算法、图像语义分割等相关技术,并将其应用至政务服务机器人的场景理解中,旨在提高服务机器人的场景理解能力。
1 DSC-SSD目标检测算法与图像处理技术
1.1 DSC-SSD算法的网络结构与模型训练
SSD是一种目标检测算法,采用在不同层级中进行图像识别的方式,来检测并获取到相应的图像特征[3]。SSD有效结合了大尺度特征图与小尺度特征图,可有效扩大目标检测的范围,在一定程度上规避漏检、检测效果较差、检测召回率较低等风险[4]。SSD算法的目标检测原理如图1所示。
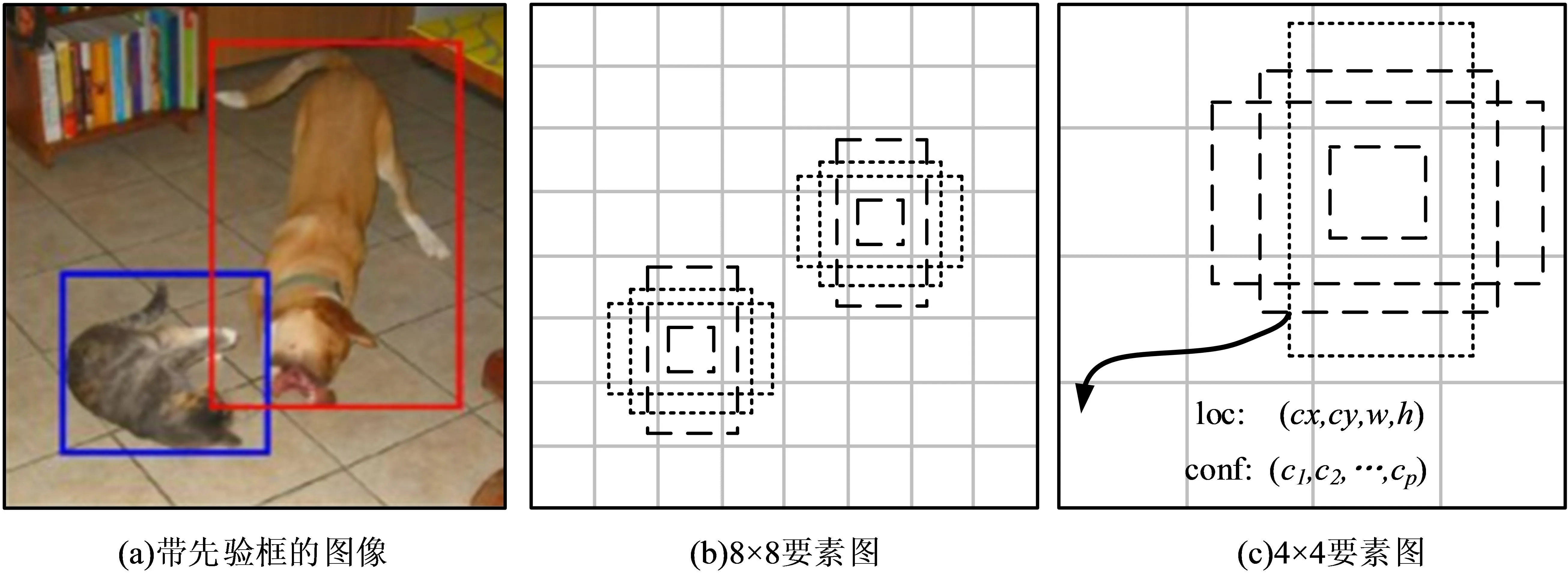
图1 SSD算法的目标检测原理示意图
图1 (a)中表现出在面对狗与猫等不同的目标 检测对象时,SSD会采用根据其形状特征来选择不同的先验框,进而实现后期的模型训练,在数据集制作的过程中,分别代表狗与猫的两个矩形区域将迅速生成。图1(b)所示为8×8大小的特征图,图1(c)中特征图的大小为4×4,其中每个特征图单元均含有k个默认框;任一默认框均会进行不同数量置信度与偏移量的运算;单一默认框的尺寸表示为S k,其计算公式见式(1)。
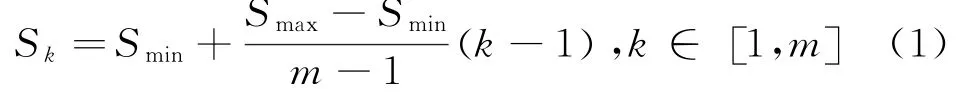
在式(1)中,Smax与Smin的取值分别为0.9与0.2,且任一默认框的纵横比均可由式(2)计算得出。
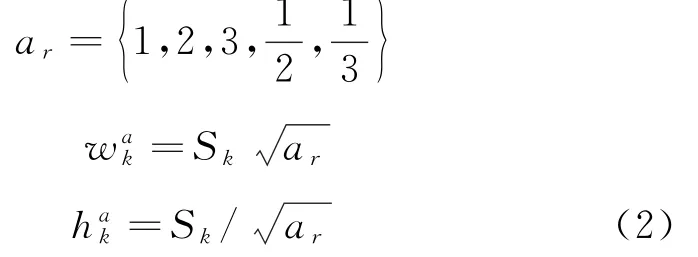
式(2)中,a r表示默认框中所有纵横比的集合分别表示该默认框的长度值与宽度值。若位于同一网络层中,则其将表现出纵横比不同的现象,据此可实现对形状与大小各异的目标检测对象的全面覆盖[5]。DSC是指一种优化的卷积神经网络算法,该算法将卷积运算的过程进行了划分,即深度卷积与逐点卷积两个部分,前者能够对输入的所有通道数据与卷积核进行准确的运算,后者可完成对通道卷积的有序组合与快速输出[6-7]。令图像数据的输入大小与输出大小分别为D F·D F·M与D G·D G·N,其中D F,D G分别为输入数据与输出数据的尺寸,M与N表示相对应的数据通道数量。同理可将卷积核的大小表示为D K·D K·M·N,其中D K表示卷积核的尺寸大小,因此标准卷积的输出如式(3)所示。
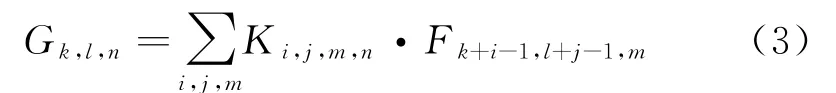
与式(3)相对应的运算量为D K·D K·M·N·D F·D F,在DSC中通道卷积与逐点卷积中的运算量分别为D K·D K·M·D F·D F与1·1·M·N·D F·D F。由此可知DSC运算与标准卷积运算的比值可表示为式(4)。
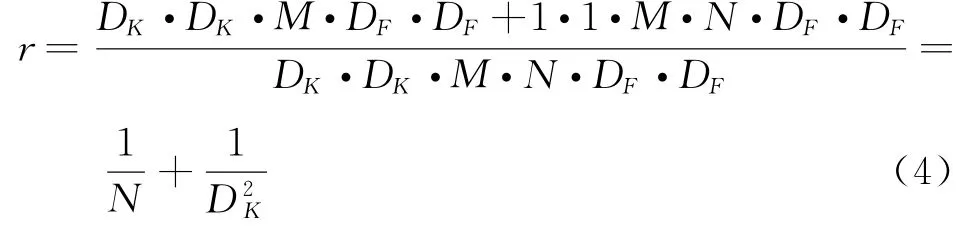
采用DSC对SSD进行改进,即可得到优化后的DSC-SSD网络结构,在DSC-SSD模型训练中,其损失函数主要分为两个部分,即目标分类损失、回归位置损失,如式(5)所示。

式(5)中N表示匹配的默认框数量;α表示其中的权重因子;L conf表示模型训练中的分类置信损失;L loc表示使用SmoothL1损失的目标定位损失,其定义见式(6)。
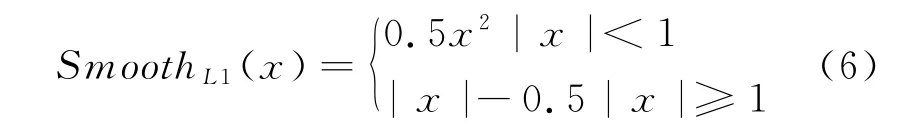
在DSC-SSD进行目标检测时,通过多尺度特征层的相关信息在回归层中生成数量较多的检测框,随后再利用非极大值抑制的方式,剔除其中冗余的、不符合要求的检测框,最终实现对目标的精准定位。
1.2 基于图像语义分割的图像处理技术
图像分割技术的本质在于将目标图像进行有效分割,使其成为多个具有独特性质的子区域。各子区域互不重叠,具有一定的区域相关性与差异性[8]。令输入图像区域为R,则其划分后的子区域为R1,R2,…,R n,且满足是R中的一个连通区域,i=1,2,…,n;由于每个子区域之间均互不重叠,因此R i∩R j=∅,i≠j;P为一种逻辑关系,则有P(R i)=TRUE,i=1,2,…,n;对R中任意相邻的两个子区域R i与R j,均满足作为一种集深度卷积神经网络、带孔卷积于一体的图像语义分割算法,Deep Lab能够在带孔卷积的作用下,实现对目标图像分辨率的有效控制,并扩大其卷积核的感受野。全连接条件随机场可在其高细节捕获能力的作用下,与深度卷积神经网络进行有机的结合,共同进行图像分割作业,取得较为优质的分割效果,其能量函数表示为式(7)。
式(7)中x表示子区域中像素点的语义标签;θ(x i)表示其中的一元势函数,满足θ(x i)=-表示任一像素点分配到相应语义标签的概率。
1.3 场景理解与DSC-SSD算法的融合设计
要实现政务服务机器人的场景理解功能,实验中将DSC-SSD目标检测算法与图像处理算法进行融合,获取到了当前场景的内容理解信息图,其中囊括了目标图像的特征位置、类别、深度表征等。图像深度估计方法能够使得二维图像得到完全的分离,避免场景前置与后置内容出现重叠的问题;DSC-SSD目标检测算法与图像语义分割算法共同作用,完成对特征图像的准确定位与高效分割。融合设计算法的场景理解流程如图2所示。
2 DSC-SSD在政务服务机器人场景理解中的应用效果分析
2.1 DSC-SSD算法与其他目标检测算法的比较
在深度学习框架进行网络模型训练的过程中,在实验中将网络层、各项超参数进行定义,用以检测DSC-SSD算法的训练效果。将最大迭代次数设置为80k次,迭代步长为1,学习率的初始值及其衰减系数分别为0.00001与0.5,权重衰减率的值与学习率初始值相等,网络模型训练结果详见图3。
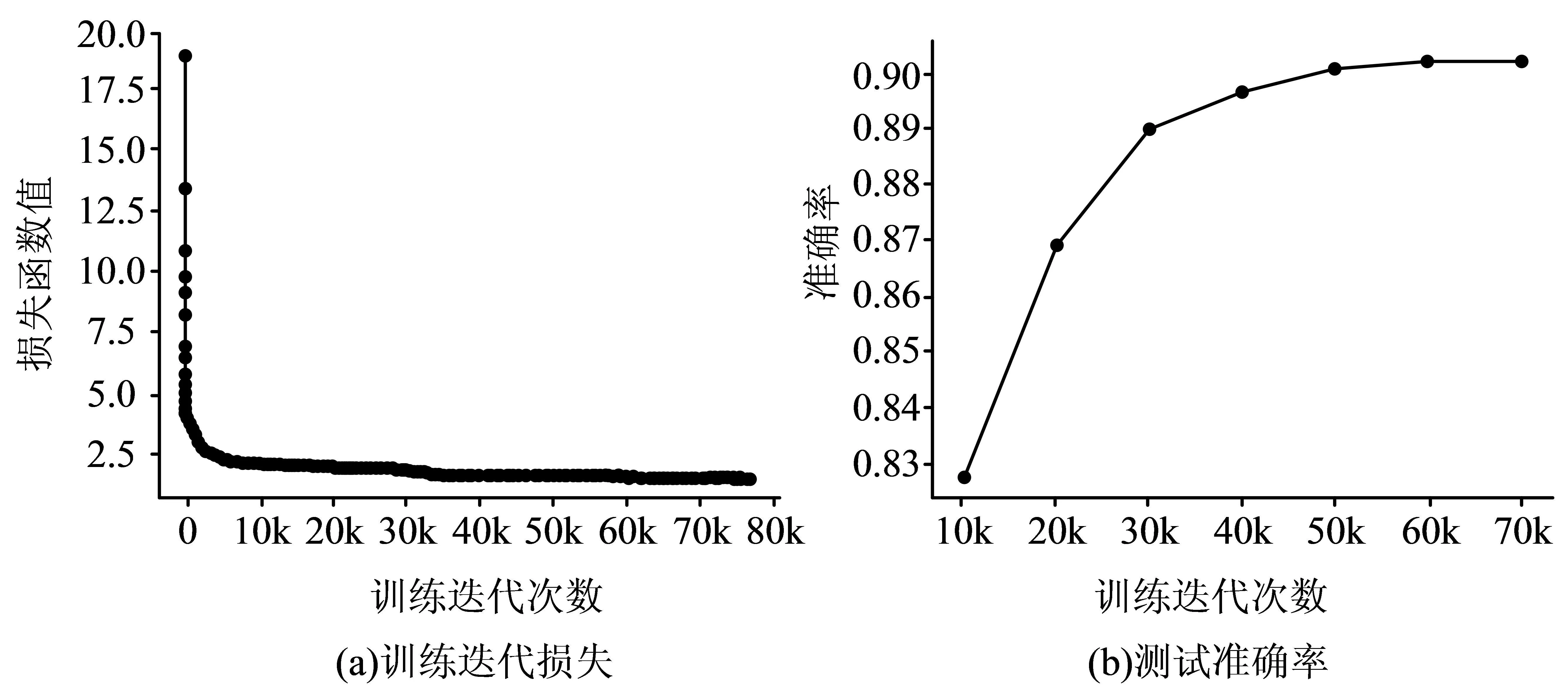
图3 DSC-SSD算法的模型训练结果
从图3(a)可以看出随着迭代次数的持续增加,损失函数的值整体呈现出下降的趋势,训练迭代次数达到约5000时,损失函数值降至2.5左右,随后随着训练迭代次数的增加,损失函数值下降幅度较小,几乎维持稳定状态。图3(b)显示随着训练迭代次数的增加而不断提高,训练迭代次数少于30000时,测试准确率上升幅度较大,随后增幅较小,逐渐维持平稳状态。这表明DSC-SSD算法随着训练迭代次数的增加,在测试集上的表现愈来愈佳。将当前常用的目标检测算法与DSC-SSD算法同时用于政务服务机器人场景理解中,其目标检测结果见图4。
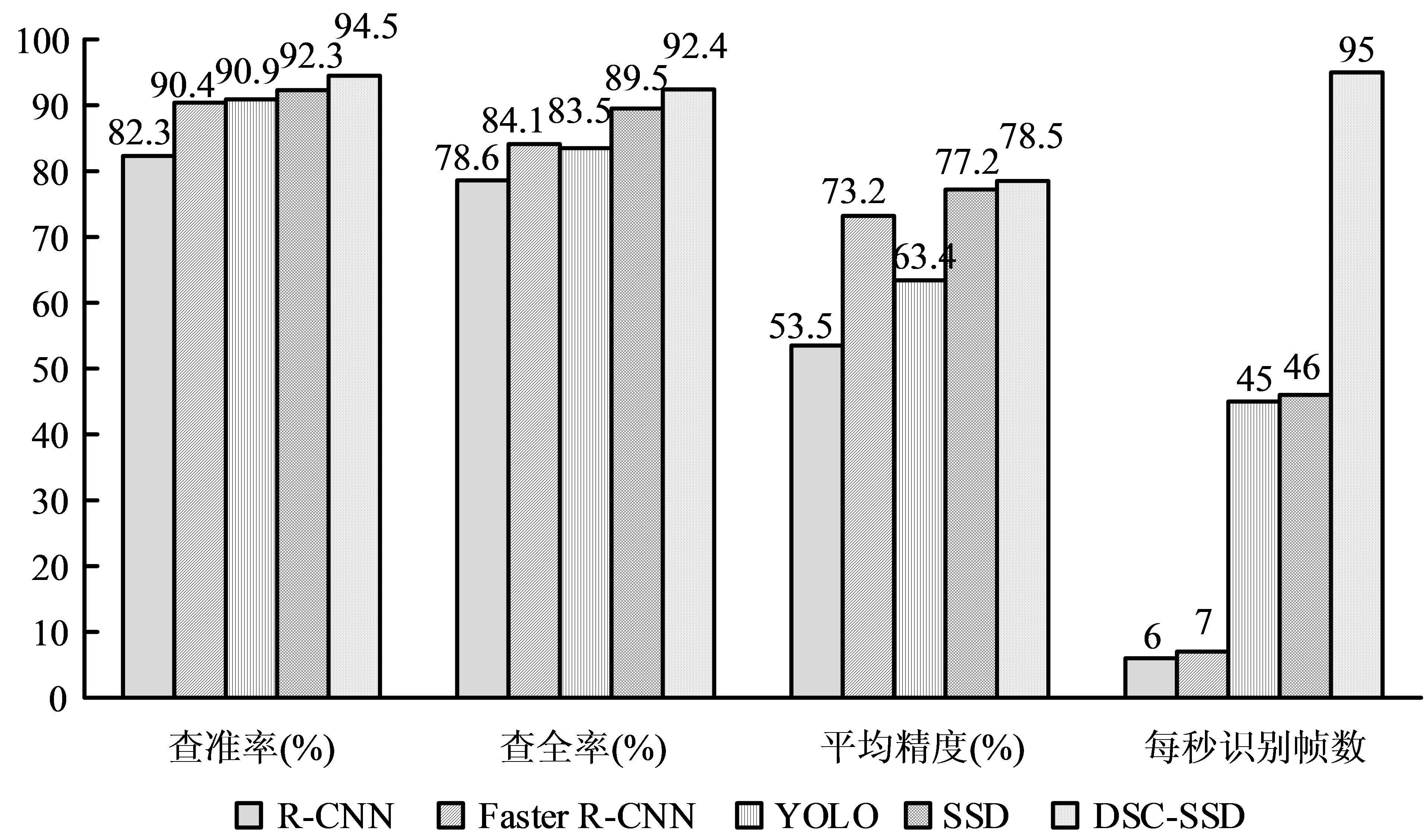
图4 DSC-SSD与不同算法的实验结果对比
据图4可知,相较于R-CNN,Faster RCNN,YOLO,SSD算法而言,DSC-SSD算法在查准率、查全率、平均精度、每秒识别帧数上均表现出较为优越的性能,其结果分别为94.5%,92.4%,78.5%,95fps。在每秒识别帧数的比较中,R-CNN,Faster R-CNN,YOLO,SSD算法的实验结果分别为6fps,7fps,45fps,46fps,而DSCSSD算法的实时检测速度达到了95fps,约为YOLO算法与SSD算法检测速度的2倍。这显示出DSC-SSD算法具有更高的检测精度与更强的目标检测能力,能够以其较强的目标检测有效性广泛应用于场景理解中。
2.2 场景理解算法融合的效果研究
选择政务服务机器人场景理解采集到的四张图像,采用DSC-SSD目标检测算法与常规算法进行对比实验,进而获取到相应的定位准确度,即目标检测对象的候选框与目标检测对象真实位置的交并比,对比结果见图5可知。

图5 DSC-SSD与常规算法对目标检测对象的定位准确性对比
从图5可知,相较于常规检测算法而言,DSC-SSD算法在对目标图像进行识别检测时,具有较为明显的优势。对比分析两种算法定位准确度的平均值,发现前者为0.927,后者为0.934。这表示采用DSC-SSD目标检测算法能够在一定程度上,保证目标定位的精确性。
3 结 语
在我国经济发展水平与科技水平不断提高的过程中,机器人在各大领域中需求量的提升与其应用环境的日渐复杂化,对其工作性能提出了更高的要求。为了探究DSC-SSD在政务服务机器人场景理解中的应用成效,并有效提高机器人的场景理解能力,实验中对DSC-SSD目标检测算法进行深入研究,通过对图像目标检测、图像语义分割等相关技术进行优化与结合,设计场景理解与DSC-SSD的融合算法来进行实验。结果显示DSCSSD算法的目标定位准确度平均值可达到0.934,其查准率、查全率、平均精度、每秒识别帧数分别为94.5%,92.4%,78.5%,95fps,显著优于其他算法。这表明DSC-SSD算法能够在政务服务中发挥出其优越的工作性能,可大量投入到政务服务机器人的场景理解中。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
开放教育研究(2020年2期)2020-03-31 01:54:14
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
广东饲料(2016年5期)2016-12-01 03:43:19
广东饲料(2016年3期)2016-12-01 03:43:09
广东饲料(2016年2期)2016-12-01 03:43:04
广东饲料(2016年1期)2016-12-01 03:42:58
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
