
雷达场景识别系统设计
2021-11-01 13:15杨亚宁唐佳璐苟先太
计算机测量与控制 2021年10期
雷 涛,杨亚宁,唐佳璐,杨 玲,苟先太
(1.中国电子科技集团公司 第二十九研究所,成都 614000;2.西南交通大学 电气工程学院,成都 611756)
0 引言
两军对垒的过程中,想要把握战场主动权就必须得掌握敌方的行为意图,而随着信息技术的不断发展与完善,战场上的信息也变得繁杂起来,信息技术成为决胜战场的主导因素之一[1],而面临这些越来越多的复杂的战场信息,如果还是像以往作战,单纯的依靠指战员的经验和临时的判断的话,将会严重影响我方的战斗响应时间,导致贻误战机,严重的甚至会输掉整场战争[2-3]。因此,我们迫切需要研究一种基于深度学习的对于场景行为识别的方法。本系统是通过捕捉敌方雷达的基础电磁信息和外部特征信息[4-5],获取敌方雷达的行为意图从而判断出敌军的意图行为。
对于作战目标的意图识别问题,国外的研究要早于国内,对于信息融合的一些研究,国内直到20世纪80年代才相继展开[6]。而目前的对于作战目标的意图识别的传统方法,已经出现了的有深度信念网络、专家系统、贝叶斯网络、模板匹配等[2]。
模板匹配法是一种最基础的模式识别的方法,这种方法基本上是一种统计识别方法。文献[6-7]引入模板匹配方法,对海战场的作战目标进行了意图识别,并且提高了模型的容错能力和辨识能力。但是由于模板匹配自身的局限性,其识别效果受到先验模型的覆盖面、模板的普适性的约束,因此具有极大的不确定性。
专家系统是人工智能领域中的最重要的的一个应用领域,被用来对人工难以解决的复杂问题进行知识推导和表示。文献[8-9]引入专家系统,通过置信规则库来对群体目标进行了威胁评估,从而提高了识别的计算效率和精度。但是由于专家系统只是单纯的依靠机械式的推理计算,而缺乏知识的共享性和重用性,并不能满足现在战场上的复杂性和多变性。
贝叶斯网络是一种图形化网络,通常是基于概率推理的。贝叶斯网络一般用于解决不确定的或者是数据缺失条件下的问题,而对于一些结果发生的可能性该方法还可以给予量化分析。文献[10-11]引入贝叶斯网络,定义了空域作战目标的事件分类,并对后续事件进行了学习更新。但是贝叶斯网络非常依赖于经验知识,很难发现和处理抗性欺骗信息[12-13]。
深度信念网络(DBN)的构成是多层受限玻尔兹曼机(RBM)的堆叠[14-15],是由Hinton等人[14]在2006年提出的一个概念生成模型。在深度信念网络中,这些网络被限制为一个可视层和一个隐层,层间存在连接,但层内的单元间不存在连接。深度信念网络是模式识别领域新兴的概率生成模型[15],可以用来进行深层次的学习和对数据进行深度的挖掘[16-17]。深度信念网络现在主要用于语音[18-19]、情感[20-21]、文本[22-23]和图像[24-25]的分类和识别。但由于这项技术发展时间不长,相比其他方法,这项技术的识别准确率较低,学习过程较为缓慢。
本文概述了基于神经网络与知识图谱的场景识别方法的研究现状,通过了聚类算法、LSTM模型、知识图谱分析以及Web仿真技术的运用,用信息融合方法对得到的原始战场信息进行知识的挖掘,从而得到战场态势信息,分析识别出战场场景。再配合three.js动画库将实时场景进行仿真模拟,实现基本三维场景创建,提高开发效率,降低开发成本[3]。
本文基于神经网络与知识图谱的场景识别方法解决了传统识别方法中存在的识别准确率低、需要训练的数据量大、识别缓慢的的问题,能够更加快速准确,而且需要的数据更少,耗费的资源更少的实现高准确率的识别。通过此种方法可以更好地拟悉敌方作战意图、提高我国电子对抗作战实力、营造更安全的国家周边环境。
1 场景活动的构建
1.1 雷达活动的构建
为了更好地模拟雷达行为的仿真,我们建立了一个场景剧本,通过创建这个场景并实现仿真,通过对仿真数据进行仿真并对数据进行综合处理。
图1是整个仿真流程中所仿真的所有雷达行为,是仿真了从探测敌方雷达开始进行搜索活动到失去目标然后再进行小范围的精确搜索活动直到找到目标并确认目标,然后进行制导活动的完整流程。
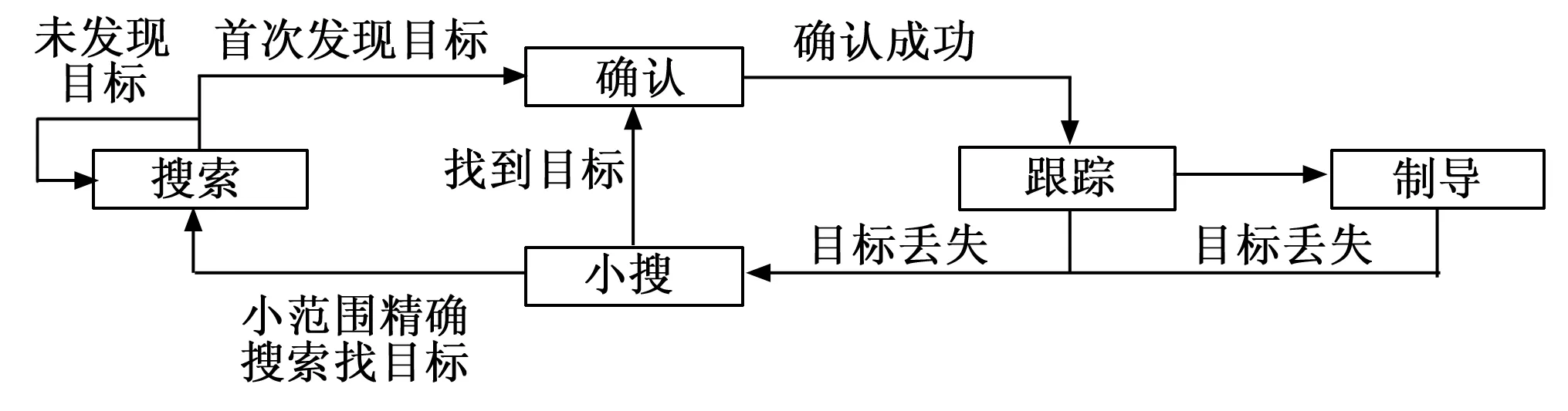
图1 多雷达行为构成的防空反导场景
在实战过程中通过己方的雷达、声纳、红外传感器等获取到的敌方雷达数据,如位置坐标、移动速度、平均功率、峰值功率等参数。本文则对获取到的敌方雷达活动进行仿真构建。本文的仿真系统处理到的雷达数据包括了雷达的坐标位置、速度信息、平均功率等,如表1所示。

表1 雷达相关数据参数
1.2 雷达行为的判别
对于雷达的行为信息的判别,如处于搜索还是跟踪状态,我们本文采用的是通过对于雷达幅度的大小变化来推断出雷达此时的行为特征的,而主要步骤是通过从己方的雷达、声纳、红外传感器等获取到敌方辐射源脉冲序列,然后对这个脉冲序列的峰值、谷值等参数进行提取,将这些信息综合分析后即可得出相关的行为识别结果,步骤如图2所示。
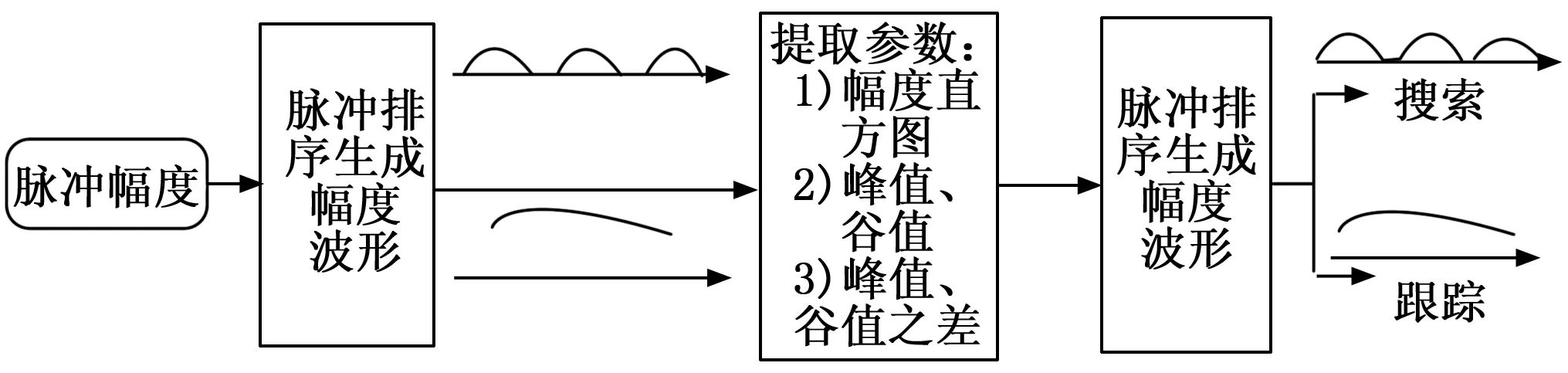
图2 对雷达的行为识别示意图
依据雷达峰值与谷值识别行为状态的具体流程如下所示:
1)首先对雷达的幅度直方图进行计算,在直方图中依次添加脉冲的幅度,将其横轴设置为幅度值,纵轴设置为脉冲的个数,采用统计学中的“百分位数”方法进行幅度峰值(Amax)与谷值(Amin)提取,通过Matlab进行仿真模拟图形,如图3所示。

图3 搜索和跟踪目标的幅度直方图
峰值变化量:dAmax=dAmax(t)-dAmax(t-1)
谷值变化量:dAmin=dAmin(t)-dAmin(t-1)
随后统计固定时间段内的峰值变化量与谷值变化量:若峰值变化量绝对值>ΔA或者谷值变化量绝对值>ΔA,那么则判断为搜索状态;如果峰值变化量绝对值<ΔA且者谷值变化量绝对值<ΔA,则判定为跟踪状态。
2 雷达场景识别
在雷达对抗领域采用人工智能技术作为新兴技术,将长短时记忆循环神经网络或知识图谱应用于雷达场景识别技术,无疑能够牢牢抓住电磁作战领域的主动权,拉开与对手的技术差距。而对敌场景识别包括了:从敌信息源获取的信息进行相关的特征提取,再通过识别推理,即可推理识别得到场景,场景识别的一般过程如图4所示,下面将介绍本文中采用到的知识图谱方法。

图4 场景识别的一般过程
2.1 基于知识图谱的雷达场景识别
知识图谱的构建是为了描述场景中与目标相关的各种实体与概念之间的关系。知识图谱是一种基于图的数据结构,由节点和边组成,如图5所示。知识图谱最常用的语义关系为“实体-关系-实体”与“实体-属性-属性值”。通俗地讲,知识图谱就是把所有不同种类的信息连接在一起而得到的一个关系网络,它提供了从“关系”的角度去分析问题的能力。

图5 知识图谱结构图
依据雷达信号特征、雷达事件及时空信息与雷达场景之间的因果关系构建知识图谱根据专家在大量雷达场景数据中提取到的知识生成三元组,如在场景可能为防空反导场景识别(A)、场景B、场景C的前提下,根据雷达时空信息,可以推断出场景可能为防空反导场景识别(A)、场景C对应三元组为{(1,1,1), 航线在特定区域外行驶方向由我方至敌方,(1,0,1)},进而挖掘雷达的特征信号、事件信息、时空信息与场景识别之间存在的关联,完成知识提取,如图6所示。

图6 知识提取
三元组G=(E,R,S)建立起两个节点之间的联系,无数个三元组建立起概念层之间的联系。概念层建立在数据层之上,是知识图谱的核心,丰富实体之间、边之间的关系和属性值。以场景识别过程建立知识库,按照识别规则出现的先后顺序,在初始数据至最终识别结果之间,必然存在实体和边之间的上下层关系及同层关系,同一层实体之间label相同,为一种概念,上下层两个实体之间由关系连接,建立起概念之间的上下位关系。结合实体和边之间关系及其内属性等语义描述,即可建立起包含概念层和数据层的结构化的可逻辑推理的知识库,实现雷达场景识别过程信息的存储。如图7所示。
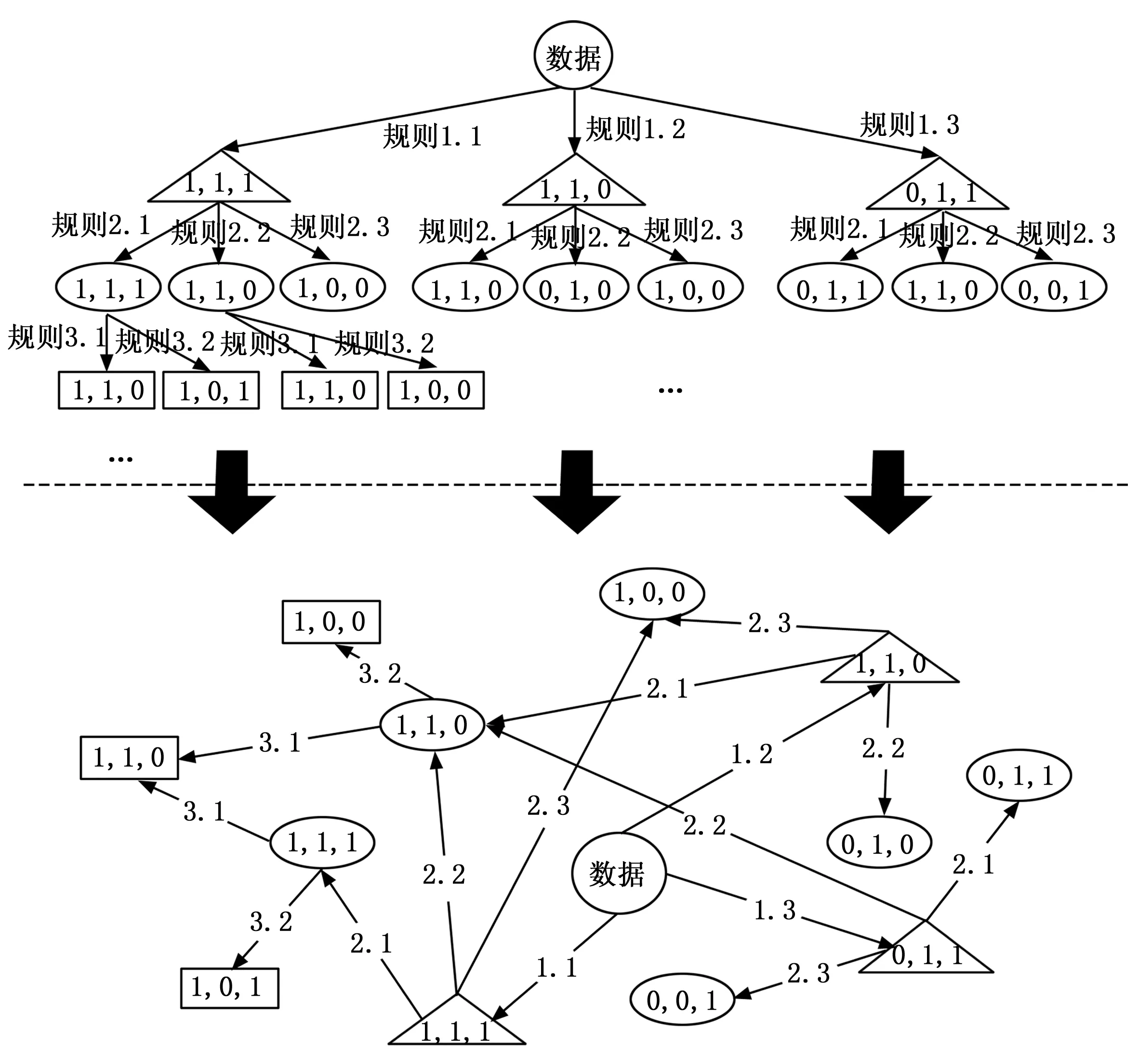
图7 结合语义建立知识图谱
2.2 基于神经网络的雷达场景识别
将处理雷达数据进行整合后,并将数据传入Web端就行仿真,再通过聚类算法和LSTM综合处理得到场景识别的仿真结果。
长短时神经网络(LSTM,long short-term memory)是一种时间循环神经网络,它的诞生最开始是用于解决RNN循环神经网络中存在的长期依赖问题。LSTM的优点是在较长的序列中,它的计算处理能力要强于普通的循环神经网络,另外LSTM也能同时解决掉普通的循环神经网络中存在的梯度的爆炸和梯度的消失问题。而LSTM的主要组成是由3个门结构构成,分别是遗忘门、输入门、输出门,具体组成如图8所示。
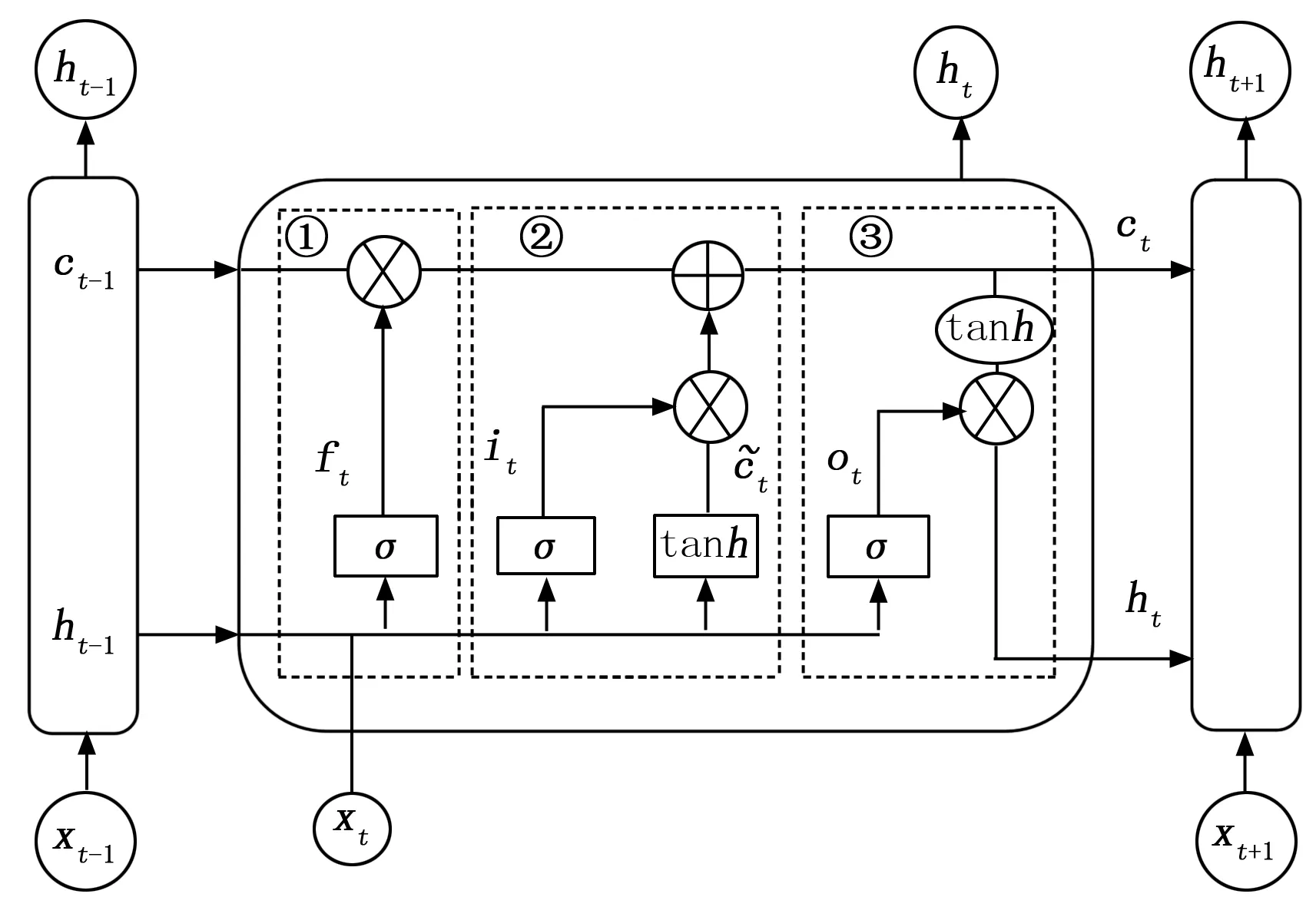
图8 LSTM神经网络结构图
本系统用到LSTM的流程如下:


ft=σ(wf·[ht-1,xt]+bf)
(1)
it=σ(wi·[ht-1,xt]+bi)
(2)
(3)
(4)
ot=σ(wo[ht-1,xt]+bo)
(5)
ht=ot·tanh(ct)
(6)
通过LSTM对雷达的数据的训练与分析,最后得出部分行为识别结果如图9所示。

图9 部分数据的 A 雷达行为模式占比时序分布图
由图9可以看出A 雷达跟踪在占比和雷达工作脉宽在攻击、侦查和防御3个意图的特征据中都出现了重合部分,并且图中3种特征数据之间混叠严重,但是其中A 雷达的搜索模式占比中攻击意图和侦查意图的特征数据重复部分较大,防御意图与其他两种意图之间的重复程度较小,可以分析得出在这段时序内的雷达意图。
3 场景识别仿真
3.1 仿真系统架构与原理
系统通过了聚类算法、LSTM模型、知识图谱分析对上传的数据进行了分析和处理,在Matlab中计算出识别结果,然后通过服务器传到Web客户端,Web客户端three.js动画库将实时场景进行仿真模拟,其架构如图10所示。
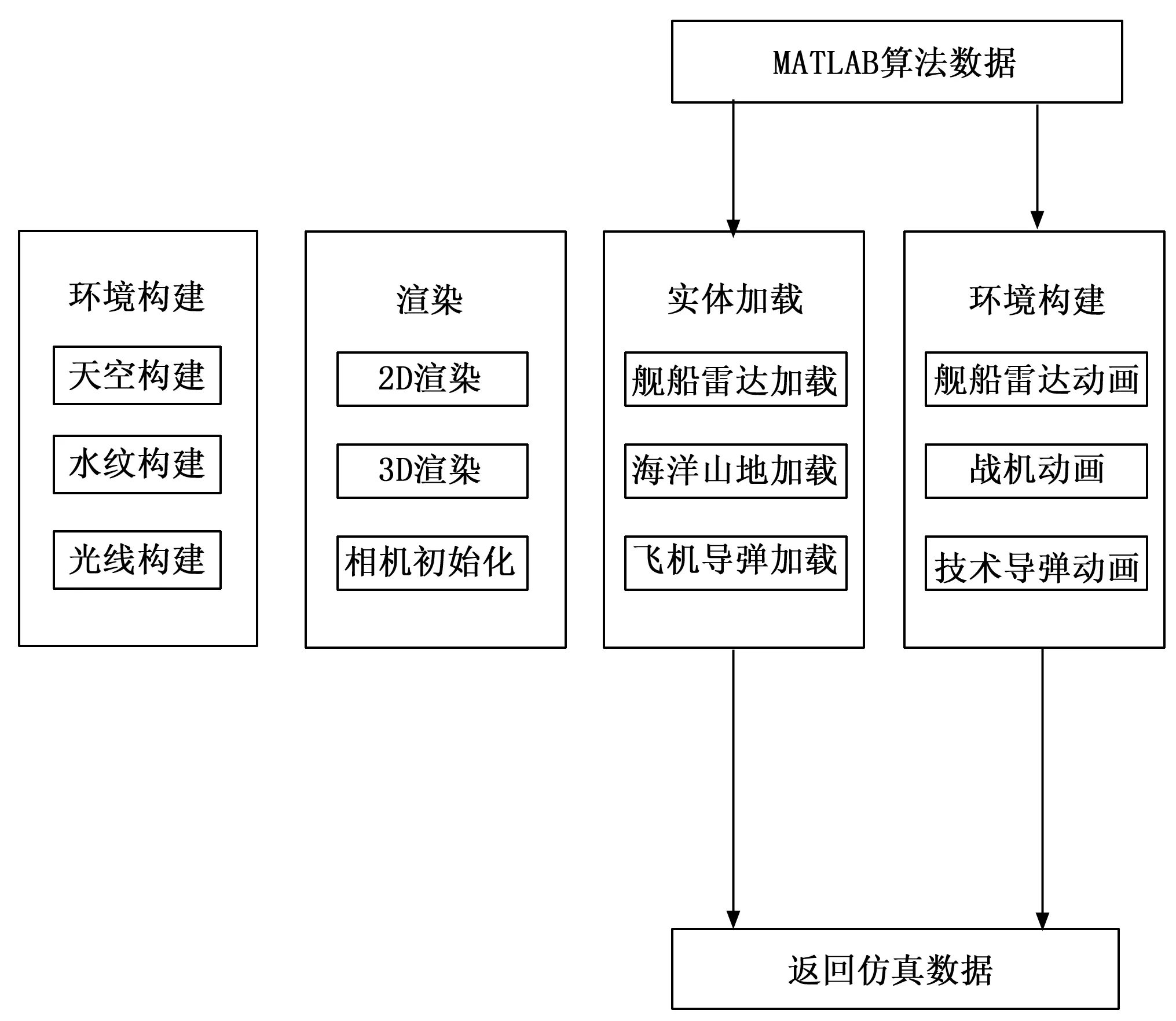
图10 仿真系统框架设计
系统通过使用Three.js中内置的对象对仿真场景进行初始化仿真,仿真的流程如下:首先在场景中创建一个盒子模型,之后的所有仿真皆在此盒模型中进行,随后再对背景元素进行构建,如相机、渲染器的创建等,由此创造出一个最基础的仿真场景;然后再到场景中添加仿真的环境元素,如海洋、天空、日光等,添加完毕后再用这些环境元素的纹理对盒子模型的内部进行纹理映射,至此,整个场景的环境效果即可呈现;再创建完场景和背景元素后就可以往盒子模型中加入仿真模型了,如雷达、预警机、驱逐舰等。本仿真系统的数据支持是进行了LSTM运算的Matlab算法端,通过这些数据,系统不断加载渲染出模型以及通过内置动画展现出模型的空间信息。本系统中采用的是这6步:1)创建三维场景;2)设置摄像机;3)设置光源;4)设置渲染;5)加载 OBJ 文件;6)模型的平移、旋转、缩放等。
三维模型的加载流程如图11所示。

图11 三维模型加载流程
3.2 场景识别结果
雷达在搜索、小搜、跟踪等行为转变过程中,其相对于侦察设备的功率会发生变化。同时雷达的位置坐标、移动速度、频段、峰值数量、脉宽也会发生变化,因此测量观测雷达的各项参数变化特征,可快速确定威胁目标当前的行为方式、意图从而推导识别出现在的场景。记录的部分数据如表2所示。
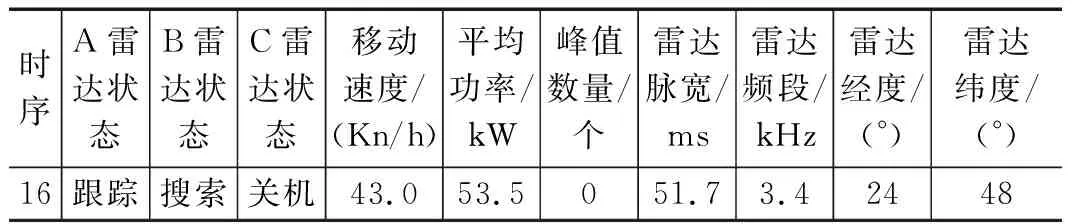
表2 雷达部分数据截取表
在对9 000组样本进行了训练与测试之后,得出了网络模型LSTM和知识图谱方法的识别准确率,如表3所示,在选取的部分实验中可得出LSTM的识别准确率大致在82.3%左右,而知识图谱的识别准确率在86.1%左右,经过

表3 雷达部分数据截取表
实验验证识别准确率达到了实战的要求,相比较这知识图谱与LSTM,知识图谱的识别准确率要更高一些,但并不意味着知识图谱要更有优势,因为相对于知识图谱来说,LSTM作为单向通道时的准确率是可以通过拓展双向通道提升准确率的,即为双向LSTM(Bi-LSTM)。
4 结束语
针对判断实战环境中进行场景识别过程时受到的硬件设备和环境的限制。通过了聚类算法、LSTM模型、知识图谱分析以及Web仿真技术的运用,用信息融合方法对得到的原始战场信息进行知识的挖掘,从而得到战场态势信息,分析识别出战场场景。系统运行流畅,仿真效果良好,可视化程度高,两种方法的识别准确率都达到了80%以上,经过测试达到了实验要求,可以对数据进行快速仿真,对场景进行快速识别,对于三维场景在浏览器端的模拟实现和对海上模拟电子对抗具有一定的实际实用价值,但系统也还存在一些问题:
1)由于所研究问题的特殊性,无论是真实战场的敌军航舰外部信息、战场雷达信号还是敌军战术意图数据集合,都是无法获取与准确仿真的,因此在仿真数据以及选取特征数据都需要进一步的考证和实践。
2)现代军事发展日新月异,雷达型号更新换代较快,系统选取根据目前雷达型号得出的相关结论并不具有一定的时效性,因此需要在构建模型的进行算法计算的时候要充分考虑到雷达数据的更新换代。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
军事文摘(2022年16期)2022-08-24
小哥白尼(军事科学)(2022年1期)2022-04-26
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
意林(2020年20期)2020-11-06
新城乡(2018年6期)2018-07-09
电影(2015年7期)2015-12-24
