
基于ElasticSearch的科技资源检索系统的研究与实现
2021-11-01 08:53:26柳帆
现代计算机 2021年26期
柳帆
(西南交通大学制造业产业链协同与信息化支撑技术四川省重点实验室,成都 611756)
0 引言
近年来,随着科技行业的不断发展与进步,科技资源数据信息量急剧增加,从浩如烟海的、不同结构的科技资源中快速精确地找到用户所需要的信息,传统的数据库检索显得力不从心[1]。ElasticSearch已解决多个行业的海量数据分布式搜索引擎建设方案,但科技资源领域在ElasticSearch分布式搜索方面未涉及到公开的报道。
文献《基于ElasticSearch的气象数据检索技术研究》给出了对气象行业的ElasticSearch分布式搜索引擎建设方案[2],文献《基于ElasticSearch的元数据搜索与共享平台》使用ElasticSearch建立了水利行业的数据搜索与共享平台[3],文献《ElasticSearch分布式搜索引擎在天文大数据检索中的应用研究》对天文大数据的检索进行了应用研究[4]。由此可见,ElasticSearch分布式搜索技术在海量数据的管理与搜索中具有可行性和实践性。因此,为了改善用户搜索体验,提高检索的效率和质量,本文提出了基于ElasticSearch的科技资源分布式搜索引擎的构建方案并对检索系统进行了实现,最终通过实验数据检测,能较好地解决不断增长的科技资源数据检索的需求。
1 相关技术
1.1 Lucene
Lucene[5]是一个开源、稳定、高性能、基于Java开发的全文检索引擎架构,相比较于关系型数据库,Lucene采用倒排索引实现了更加高效的搜索性能。Lucene不是一个完整的搜索引擎,不具备具体的搜索功能模块,开发者需要对Lucene进行二次开发以实现搜索功能和扩展其他各种功能。Lucene是一个出色的全文检索工具库,基本能满足所有场景下的全文检索需求。许多著名的项目都采用Lucene作为搜索工具,例如IBM的WebSphere和Eclipse都利用Lucene作为全文搜索引擎。
1.2 ElasticSearch
ElasticSearch[6-8]是基于Lucene构建的分布式全文检索和分析引擎,具备高性能、高可扩展、实时性等优点。ElasticSearch对Lucene进行了封装,屏蔽了Lucene框架的复杂性,开发者使用简单RESTful API就可以操作全文检索。和传统的数据库相比,ElasticSearch还有如下特点:
(1)使用倒排索引存储结构。把文件ID到关键词的映射转为关键词到文件ID的映射,根据单词出现频率,结合TF-IDF算法计算相关度评分,将评分高的搜索结果优先展示给用户。
(2)分片存储。存储文档时,利用哈希算法计算文档的ID值,接着按照文档的ID值存到对应的主分片上,然后复制主分片的数据到多个复制分片。因此,当有某台服务器宕机时数据不会丢失,保证了ElasticSearch的高可用与高吞吐。
(3)横向可扩展。可以轻松的扩容至数以百计的服务器,支持PB级别的结构化或非结构化数据处理,用于海量数据的分布式存储、搜索和实时分析,能满足大数据时代下的分布式搜索需求。
目前,ElasticSearch是企业级大数据解决方案的首选工具之一,并且已经有许多成功的使用案例,Github、维基百科、百度、阿里巴巴等企业都已大规模部署及应用,如图1展示了ElasticSearch总体架构。
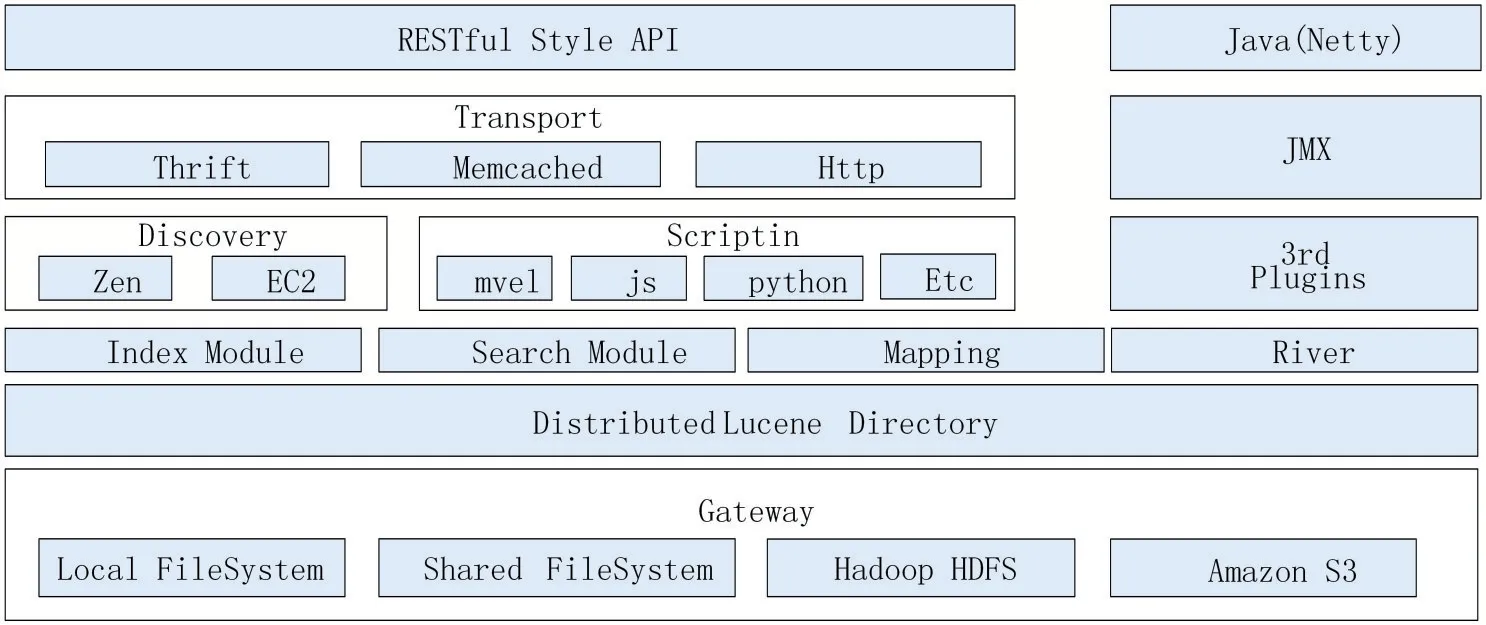
图1 ElasticSearch的总体架构
(1)GateWay是ElasticSearch的文件系统,用于存储索引。它支持不同的存储方式,本地文件系统、分布式文件系统以及AmazonS3云平台等都可以用于索引的存储。
(2)Distributed Lucene Directory是分布式的Lucene框架,它在GateWay的上一层,是ElasticSearch的核心实现层,ElasticSearch集群的每个节点都有一个Lucene-core的支持。
(3)Function layer是ElasticSearch的功能层,提供了索引创建、数据搜索和映射三大核心功能。
(4)Discovery是ElasticSearch的发现模块,主要用于在集群内选取主节点,然后完成节点间的信息传输。Scripting用于支持JavaScript、Python等语言对ElasticSearch的操作;同时ElasticSearch也支持第三方插件3rdPlugins,比如中文分词插件以及可视化操作插件。
(5)Transport是传输层,借助HTTP进行传输;JVM主要用于管理ElasticSearch集群的应用。
(6)RESTful Style API是用户接口层,主要用于支持用户与ElasticSearch集群的交互。
1.3 中文分词
在自然语言中,词是最小的、不可分割的数据,中文继承自古代汉语的传统,词语之间没有明显区分标记,不能以单个汉字分词,不像英文以空格作为天然的分隔,因此必须引入中文分词。中文分词是中文信息处理的首要前提,是搜索引擎的精确性的根本保障,中文分词的精确与否,将对搜索结果的相关性排序产生直接影响。目前在中文分词领域,主要采用三种分词方法:字符串匹配分词法、理解分词法和统计分词法[9]。
(1)字符串匹配分词法。根据特定的策略将要分词的字符串与词典中的词匹配,如果能在词典找到说明匹配成功。匹配方式分为正向匹配、逆向匹配、最长匹配、最短匹配、单纯分词、分词与标注相结合这六种,前两种是通过扫描方向划分,中间两种是通过长度划分,后两种是通过是否与词性标注相结合划分。
(2)理解分词法。模拟人对句子的理解过程,在分词的过程中实现对句法以及语义的分析,再通过句法信息以及语义信息对分词定界。
(3)统计分词法。计算相连的字在不同的文本中出现的频率,按照频率判断是不是一个词。目前,研究分词技术的前沿团队在技术实现细节方面都非常保密。要开发一个分词准确率高、分词速度快的中文分词系统,依靠个体是一个漫长的过程。因此,在具体的实现过程中,一般采用开源的中文分词器来完成分词工作。
1.4 Logstash
Logstash[10]作为一个开源的数据搜索引擎,拥有实时管道功能和强大的数据处理能力。Logstash可以动态整合分散的数据源,并根据选择标准化数据到指定位置,实现数据的收集、转换与输出,其数据处理流程分为三个模块。
(1)Input输入模块。从数据源获取数据;
(2)Filter过滤模块。对数据进行处理,比如格式转换、数据派生以及增强等;
(3)Output输出模块。将数据输出到指定到位置进行存储。
2 设计与实现
2.1 分词器的选择与比较
目前主要的中文分词器包括:Standard-Analyzer、CJKAnalyzer、MMSeg4j、Smartcn、IKAnalyzer[11-12],下面从分词准确性和分词速率两个方面对上述中文分词器进行分析。
(1)使用测试用例“2017年7月1日,庆祝香港回归祖国20周年大会暨香港特别行政区第五届政府就职典礼在香港会展中心隆重举行”来测试分词的准确性,并进行分析和比较,如表1所示。

表1 中文分词比较
从表1可以看出,采用一元分词的StandardAnalyzer和采用二元分词的CJKAnalyzer,其分词结果都不够准确,并且会产生过多索引碎片,从而降低检索的准确率。Smartcn分词器、MMSeg4j分词器和IKAnalyzer分词器采用词库分词,分词准确率更高,其中IKAnalyzer分词效果最为理想。
(2)利用分词速率比较中文分词器的性能。为了避免开发环境对实验结果的影响,本文在相同的实验环境比较相对值,使用上述中文分词器对SIGHANBakeoff 2005 PKU数据集(510KB),以及10M文本数据进行分词,评测结果如表2所示。
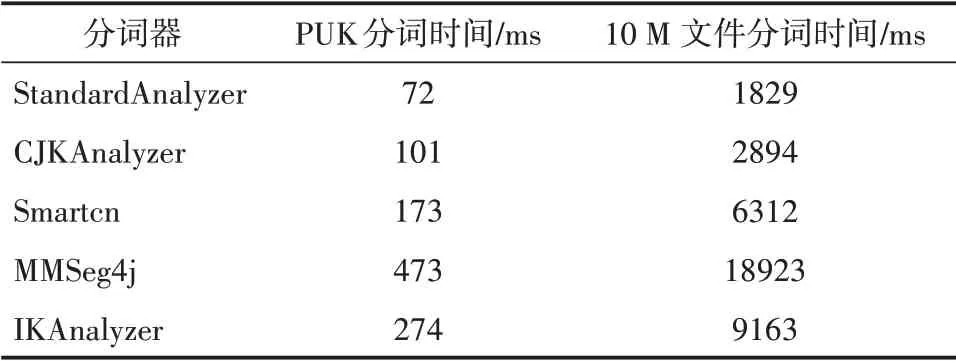
表2 中文分词时间比较
尽管StandardAnalyzer、CJKAnalyzer、Smartcn的分词速率比较快,但是分词可靠性不高,而IKAnalyzer的分词速率比MMSeg4j快。结合多种因素,可以得出:IKAnalyzer是本文首选的中文分词器。
2.2 系统总体架构
结合数据规模、性能和功能需求,基于ElasticSearch的科技资源检索系统分为数据导入、数据索引、数据检索、缓存四个模块。首先用Logstash将MySQL中的标准化数据导入到ElasticSearch,当用户发送搜索请求时,SpringBoot通过ElasticSearch官方提供的JavaAPI调用Elasticsearch实现数据的检索,最后用VUE框架对搜索结果进行前端展示。此外,对于用户信息、用户热搜资源和平台热搜资源等信息通过SpringBoot存放到Redis数据库中,以便进一步提高系统的性能,系统的总体架构如图2所示。

图2 系统总体架构
2.3 数据导入
本系统中科技资源数据经过汇聚、清洗、筛选和标准化之后,会存入MySQL数据库中,然后利用Logstash工具将资源数据从MySQL数据库同步到ElasticSearch中,Logstash详细配置如下:
input{
stdin{}
jdbc{
jdbc_connection_string => “jdbc: mysql://192.168.2.116.3306/gl3?serverTimezone=CTT”
jdbc_user=>“root”
jdbc_password=>“root”
jdbc_driver_library => “/es/logstash/mysqlconnet/mysql-connector-java-8.0.11.jar”
jdbc_driver_class=>“cool.mysql.cj.jdbc.Driver”
jdbc_paging_enabled=>“true”
jdbc_page_size=>“5000”
schedule=>”1”
type=>“synthetical”
}
}
filter{
json{
source=>“message”
target=>“msg_json”
}
grok{
match=>{"message"=>"%{COMBINEDAPACHE-LOG}"}
}
}
output{
if[type]==“synthetical”{
elasticsearch{
hosts=>“192.168.2.247:9201”
index=>”synthetical”
document_id=>“%{id}”
template_overwrite=>true
manage_template=>true
template=>“/es/logstash/template/logstah
ik.json”
template_name=>“synthetical-ik”
}
}s
tdout{
codec=>json_lines
}
}
2.4 分布式索引子系统
2.4.1 中文分词的实现
IKAnalyzer是一个开源、基于Java实现的轻量级中文分词工具包,支持多种分析处理模式,采用了“正向迭代最细粒度切分”算法[13],具有高速的数据处理能力。本文采用IKAnalyzer中文分词系统作为中文分词模块的主要组件,在ElasticSearch中配置IKAnalyzer中文分词插件的过程如下:
(1)下载IKAnalyzer源码,接着执行命令mvncleanpackage,打包得到jar包文件。
(2)将IKAnalyzer依赖包复制到elasticsearch/plugin/analysis-ik目录下。
(3)在Elasticsearch的config目 录 下 对IKAnalyzer进行相关配置,配置文件elasticsearch.yml添加的内容如下:
index:
a
nalysis:
analyzer:
ik_syno:
alias:[ik_max_word]
type:custom
tokenizer:ik
use_smart:false
filter:[synonym]
ik_smart_syno:
type:custom
tokenizer:ik_smart_tok
user_smart:true
filter:[synonym]
ik:
type:ik
use_smart:true
ik_smart:
type:ik
use_smart:true
filter:
synonym:
type:synonym
ignore_case:true
synonyms_path:ik/custom/synon-ym.
dic
index.analysis.analyzer.default.type:ik
2.4.2 索引的实现
Elasticsearch是基于Lucene实现的,采用倒排索引的方式存储数据[14]。首先从存放标准数据的MySQL数据库中获取数据,然后通过分词器解析生成多个字段(field),接着构建文档(document),最后用IndexWrite建立索引并将信息放入索引库中。索引库包含文档号、词频、位置和偏移量等信息,其实现流程如图3所示。
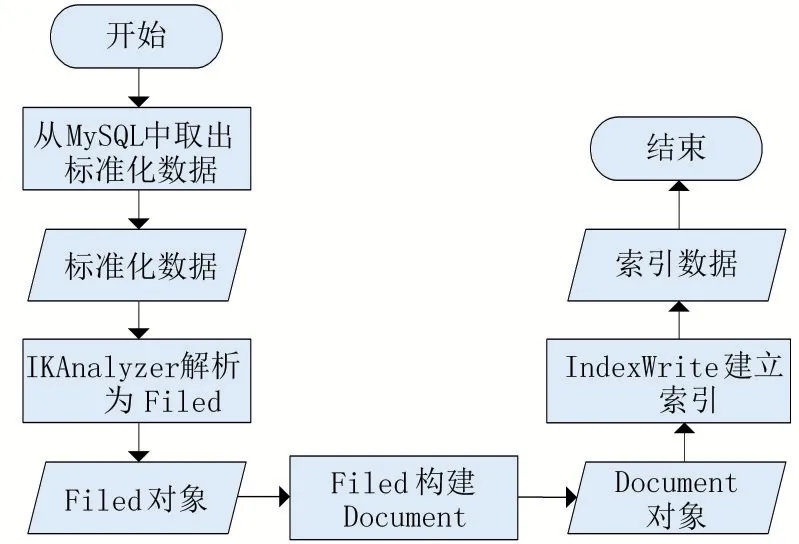
图3 索引的实现流程图
2.5 分布式检索子系统
2.5.1 检索的实现
用户输入查询关键字,系统将关键字与ElasticSearch索引库中的索引进行匹配,经过基于TF-IDF算法的相关性计算之后,得到搜索排序结果,提供接口给检索模块调用,最终返回给用户使用,检索模块的详细实现流程如图4所示。
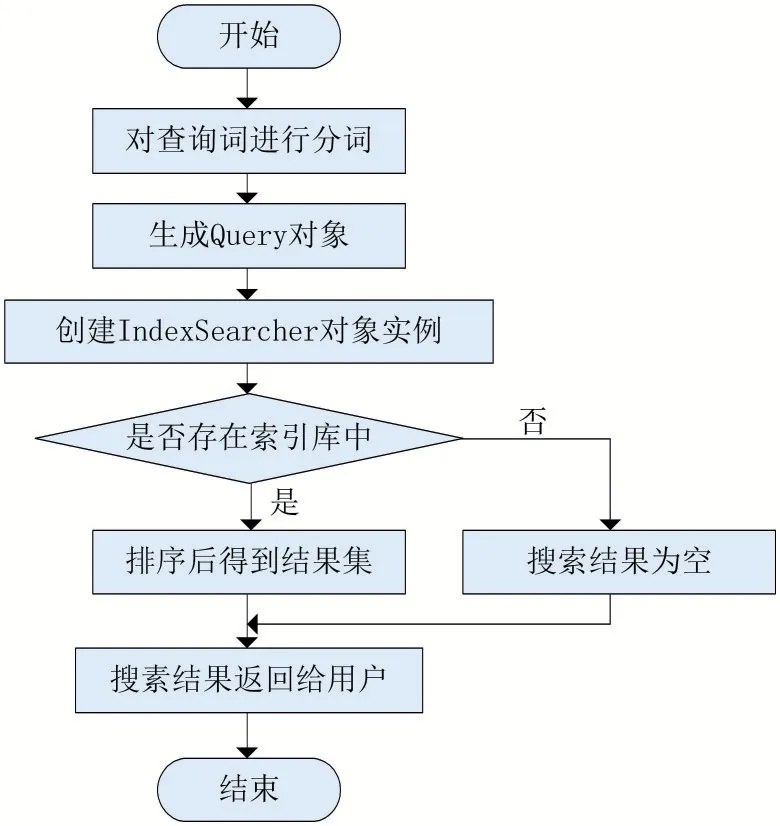
图4 检索的实现流程图
(1)分词器对查询关键字进行分词。
(2)通过MultiFiledQueryParse生成Query对象,然后在不同的索引列上进行多个关键词的搜索。
(3)创建IndexSearcher对象实例,对ElasticSearch集群各节点进行索引检索,将符合条件的搜索结果合并,然后经过相关性排序之后,放到结果集中并返回给用户。
2.5.2 联想搜索的实现
搜索联想是指用户在搜索框输入检索词的过程中对每一个字进行响应提示,帮助用户更快地得到自己先要检索的内容。这个过程主要通过客户端的动态网页技术Ajax来完成,服务端需要统计用户历史检索词的频率,将频率较高的检索词按照前缀匹配结果返回给前端页面,搜索联想的实现流程如图5所示。

图5 搜索联想的实现流程图
(1)用户输入检索词,前端会实时获取输入的内容,然后利用Ajax异步地向服务端发送联想词搜索的请求;
(2)服务端将请求到的数据在ElasticSearch中进行前缀匹配,利用ElasticSearch搜索对应前缀的索引,然后通过ElasticSearch的bool quer将多个前缀查询结果组合起来返回给前端;
(3)前端利用Ajax组件库中的jQuery完成提示词显示,搜索联想功能的实现结果如图6所示。

图6 搜索联想的效果图
2.6 Redis缓存
Redis[15]是一个开源的高性能数据库,数据保存在内存中,数据读写效率比传统数据库高一个量级,能够显著提升系统的性能。
在本系统中,为了减少数据库运行压力,提高系统响应速度和并发量,需要引入Redis数据库,把经常被访问的数据放入Redis数据库中,对用户信息、用户热搜资源和平台热搜资源进行缓存。同时,为了提升搜索联想词的性能,也要借助缓存机制将高频的前缀匹配结果存放在内存,从而不用每一次都访问数据库。
3 实验结果与分析
对搜索引擎而言,衡量系统性能的关键指标是系统的响应时间。本实验采用某机构约5万份科技资源文本数据作为实验对象,测试检索词选择生物医疗、机器学习、物联网、发明4个词,分别记录在本搜索引擎和关系型数据库MySQL中进行搜索时第1次查询与第n次(n=10)查询的平均速度。实验结果如表3所示。通过实验结果表可以得出:基于ElasticSearch的科技资源检索系统的检索效率远远高于传统的基于数据库的检索系统。
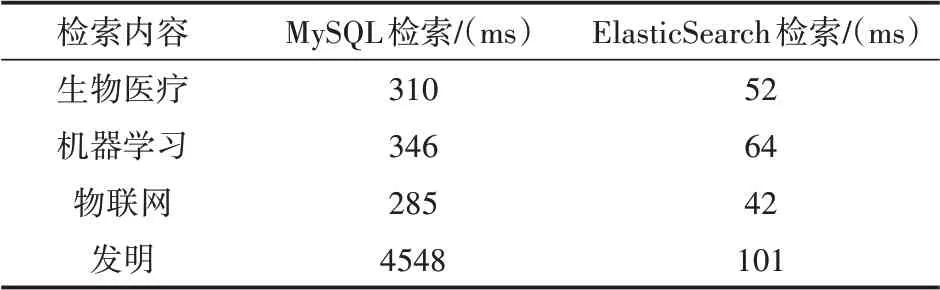
表3 检索时间对比
4 结语
本文在深入研究分布式检索原理、ElasticSearch相关技术的基础上,实现了基于ElasticSearch的科技资源检索系统,进行了检索速率的测试,而且和传统的MySQL数据库检索速率进行比较,获得了较好的测试效果。本系统可以实现对检索内容的分词,提高了检索的准确率,系统通过Redis数据库来缓存热搜信息以及用户信息,提高了系统响应速度。系统使用Ajax技术,实现了服务器端和客户端的异步通信,达到了搜索提示和相关搜索的功能,使用户界面更加友好。但系统也有一些不足之处:
(1)在比较了多种分词器的基础上,本系统采用了IKAnalyzer进行中文分词。但由于科技资源领域的专业词汇较多,导致ElasticSearch中未记录的词汇增多,会在一定程度上降低查询的准确性。因此,在后续的研究中可以针对科技资源领域建立专业词汇表,提高中文分词的准确性。
(2)本系统使用了相对比较简单的相关性排序算法对搜索结果排序。在后续的研究中,将通过改进评分策略和排序算法,构造出性能更完美且检索效率更高的分布式搜索引擎。
猜你喜欢
智富时代(2019年6期)2019-07-24 10:33:16
能源(2017年10期)2017-12-20 05:54:07
能源(2017年5期)2017-07-06 09:25:54
高中生·天天向上(2016年9期)2016-11-22 09:10:34
雷达与对抗(2015年3期)2015-12-09 02:38:50
中国卫生(2015年12期)2015-11-10 05:13:38
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06 07:49:12
技术经济与管理研究(2014年11期)2014-03-11 17:02:44
自动化博览(2014年12期)2014-02-28 22:34:27
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
