
基于物体6D姿态估计算法的增强现实博物馆展示系统
2021-10-29 06:15张少博赵万青彭进业张晓丹胡琪瑶
西北大学学报(自然科学版) 2021年5期
张少博,赵万青,彭进业,张晓丹,胡琪瑶,王 珺
(西北大学 信息科学与技术学院,陕西 西安 710127)
随着数字化技术不断发展,文化遗产展示方式日趋丰富,线上展览、多媒体传播、沉浸式体验等形式为文化遗产展示提供了多元化的渠道,有效扩大了文化遗产的传播范围和文化价值。随着增强现实(augmented reality,AR)技术的成熟,增强现实博物馆开始进入人们的生活,带来了新的体验方式。增强现实借助计算机图形技术和可视化技术,将虚拟信息应用到真实的世界,使真实的环境和虚拟的物体融合在一起,从而增强使用者的体验。虚实融合技术是增强现实系统中的核心技术,该技术的关键是实现虚拟世界的三维坐标系与现实世界的三维坐标系对齐,实现虚实场景的完美融合。用户在体验过程中,会不断变化自己的位置,其观察的角度也会随之发生变化。为了达到逼真的效果,虚拟世界和现实世界坐标系之间的转换关系要不断地根据用户的观察位置和角度做出相应的改变,要解决的核心问题是实现对现实中的物体与增强现实设备之间的相对3D位置和3D方向的准确估计,即对物体进行准确的6D 姿态估计。
近年来,由于机器学习和卷积神经网络(CNN)等新概念的出现,基于深度学习的算法成为研究热点。许多学者已经将基于深度学习的方法应用于6D姿态估计,并取得了良好的效果。这些算法[1-13]通过不同的方式使用CNN建立物体的6D姿态与图像间的对应关系。其中,算法[1-4]使用CNN直接预测物体姿态来建立对应关系。现阶段的主流算法[5-13]是在物体上定义3D关键点,并预测其在图像上的2D 关键点作为姿态估计的中间表示构建对应关系,通过2D-3D对应关系得到物体姿态。其中,BB8[10]使用了3阶段的方式,在前两个阶段实现了由粗到细的分割,获得的结果被送入第三个网络来输出物体边界框的顶点。已知这种2D-3D的联系后,6D姿态可通过PnP[14]算法计算得到。Zhao等人[15]提出,首先使用2D目标检测器[16]从图像中截取物体区域;然后,将截取的区域输入关键点检测网络提取物体关键点;最终,通过PnP[14]算法计算得到物体姿态。但是,上述方法在在检测关键点的过程中都是采用由高到低和由低到高分辨率的框架,将高分辨率特征图下采样至低分辨率,再从低分辨率特征图恢复至高分辨率的思路(单次或重复多次),此过程实现了多尺度特征提取,而在这一过程中会损失特征空间信息,从而影响检测的准确率。并且,这些方法需要大量人工标签,在现实场景往往无法获得,导致在实际应用中的姿态估计精度有限,难以实现无缝的虚实融合。这些方法的另一个缺点是步骤多,需要分别对图像进行目标检测、关键点检测和姿态计算,冗余的特征提取和PnP计算过程导致算法运行速度缓慢。因此,本文提出了一个端到端的6D姿态估计方法,并行的连接高分辨率与低分辨率网络,这样能够保持提取特征的高分辨率,并且将高、低分辨率的特征图融合,提高高分辨率特征图的表示效果,得到的特征在空间上具有更丰富的信息,对关键点的预测更为准确。尽管PnP算法被广泛用于姿态估计,但是仍有以下不足:首先,由于网络的损失函数是针对关键点,因此并不能反映姿态估计任务;而且,关键点误差与姿态准确率并不完全正相关,使用PnP算法会产生一定的误差。为了解决这一问题,本文使用的神经网络接受关键点3D到2D的对应关系并返回6D姿态,实现整体网络端到端的训练,提升检测精度与速度。另外,为了减少网络对手工标注的依赖及提升泛化能力,本文利用物体3D模型合成训练数据。
博物馆在相关AR应用[17-19]上主要是三维文物模型展示互动,其实现方式是基于识别二维图像中特定标识物,即用户通过手机等设备扫描制作好的三维物体或二维平面图片来呈现文物模型等内容。与此同时,博物馆努力推进文化遗产走入公众日常生活,如运用AR识别人体姿态[20-21]进行虚拟换装,识别面部特征虚拟佩戴头饰[22],吸引用户与文物合影并分享。在博物馆AR显示设备的选择方面,智能手机等移动设备处于主导地位。然而,运行复杂的计算机视觉算法需要很强的运算能力,直接将其部署在移动设备上会产生很长的处理延迟,无法满足AR应用的及时性需求,影响用户的体验。针对这一问题,本文在物体6D姿态估计算法的基础上,设计了一个基于云计算的分布式增强现实框架来实现高精度、低延迟的移动增强现实应用,在该框架的基础上开发了虚实结合的增强现实博物馆平台展示,用于文物增强展示与交互。
1 方法描述
1.1 端到端的物体6D姿态估计算法
本文提出了一个基于RGB图像的端到端的6D姿态估计方法End 2End-Pose。受OK-POSE[15]的启发,本文的方法基于目标检测(object detection)网络结构,在此基础上扩展了网络模型,实现对物体的检测及姿态估计。为了减少网络对手工标注的依赖,利用物体3D模型合成训练数据,用计算机自动生成标签,使用合成图像进行训练。本文的方法和现有方法相比具备多项优势:①网络并行地连接分辨率高到低的网络提取模块,保持了高分辨率的表示,并通过重复融合不同分辨率的特征生成可靠的高分辨率特征图用于后续检测。②是一个端到端的网络架构,减少了冗余的特征提取和PnP计算过程,提升了检测的速度。③无需真实的姿态标注作为训练数据,泛化能力强,可以在实际场景中应用。
1)数据准备
首先,使用最远点采样(farthest point sampling,FPS)算法[23]在三维物体表面采样若干个三维点,并将其定义为物体的关键点;之后,使用blender软件,在不同的视点,从各个角度来渲染模型,并且将三维关键点投影到对应的视点下。如图1所示,在物体的上半部分均匀的采样了40 000个相机视点,为了增强模型的泛化能力,避免过拟合,随机在PCASOL VOC数据集中抽取图像作为合成图像的背景。除此之外,为了增加合成图像的多样性,在合成图像的过程中添加了随机的光照和图像噪声,并且对物体进行高斯滤波,使其能更好地与背景图像融合。
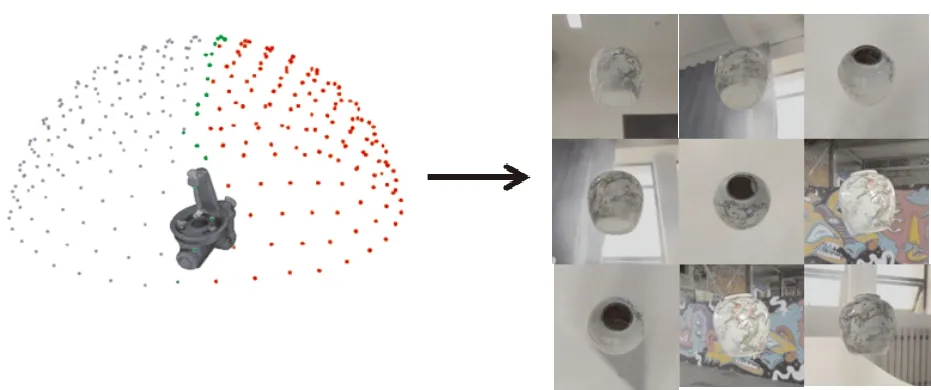
图1 合成图像采集过程Fig.1 The generation of synthetic image
本文提出的网络结构如图2所示,主要包括2个网络模块,一个是物体检测网络,用于检测物体的类别、边界框和2维关键点。另一个是姿态推理网络,该网络利用预测出的物体2维关键点和预定义的物体上的3维关键点之间的对应关系推理出物体的姿态。
网络的输入图像尺寸为640*480像素,为了解决高分辨率到低分辨率的子网串联造成的特征图空间信息丢失的问题,检测网络的主干结构使用了平行框架,高分辨率特征图提取主网络,逐渐并行加入低分辨率特征图提取子网络,在不同网络间进行特征多尺度融合。物体检测网络的主框架包含4个阶段和4个并行的卷积分支,每一阶段的分支数逐级递增,每一分支特征图的分辨率下降为上一分支的1/2,分别为输入图像分辨率的1/4、1/8、1/16和1/32,并且每一个分支都会将其他分支产生的多分辨率特征进行融合。第一阶段包含4个残差单元,然后跟随一个3×3卷积核。第二、第三、第四阶段分别包含 1、4、3个模块化块。模块化块的多分辨率并行卷积中的每个分支包含4个残差单元。每个单元包含2个3×3的卷积核,其中,每个卷积之后是批量归一化和非线性激活函数ReLU。第四阶段共有4个分支,将4个分支提取的特征以分辨率最高的尺寸融合,融合的具体方式为:同分辨率的层直接复制,通过双线性插值法提升特征图的分辨率,并使用1×1的卷积核将通道数统一。使用3×3的卷积核对特征图下采样来降低分辨率,通过直接将特征图对应位置相加的方式实现特征融合。融合后的特征具有更丰富的空间语义信息。把融合后的特征输入到区域提取网络(region proposal network,RPN)识别物体可能出现的感兴趣区域(region of interest,ROI),并将它们用于物体类别分类、边界框回归,以及关键点检测任务。分类与边界框回归任务参考Faster-RCNN[16]分类任务,利用已经获得的ROI特征,通过全连接层与softmax函数计算每个ROI具体属于特定类别的概率。边界框回归任务直接通过ROI特征预测边界框左上角与右下角的坐标。关键点检测任务对ROI特征进行连续2个1×1的卷积生成关键点热力图,并使用softmax函数将热力图转换为关键点的概率分布图,分布图中的每一个单位代表关键点出现在对应像素的概率,第i个关键点的坐标xi,yi可由式(1)计算得出
(1)
其中,Pi(u,v)是第i个关键点在概率分布图上坐标为(u,v)的概率值。
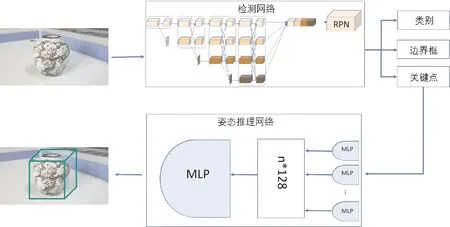
图2 模型结构图Fig.2 Model structure
常规的物体6D姿态估计方法在得到3D物体关键点和2D图像位置之间的对应关系后,使用基于RANSAC的PnP算法计算物体姿态。但是,此两阶段过程不是最优的:首先,它不是端到端可训练的;另外,关键点的准确率不会直接反映最终的6D姿态估计任务。为了解决这一问题,本文使用了姿态推理网络来代替PnP算法直接预测物体6D姿态。姿态推理网络包括3个主要模块:具有共享网络参数的局部特征提取模块、关键点的特征聚合模块,以及由3个全连接层组成的全局推理模块。使用3层的多层感知机(MLP)提取每个对应的局部特征,在各个关键点之间共享权重,之后使用最大池化(maxpooling)操作对提取的关键点局部特征进行聚合,得到n个多维向量,n为关键点的个数,最终聚合后的特征输入全局推理模块输出预测的姿态,其中,旋转用四元组表示,平移用向量表示。相较于使用PnP算法通过关键点2维3维关系计算物体姿态,直接通过网络可以直接对姿态预测建立损失函数,减少关键点预测误差对姿态估计的影响。在使用PnP算法时,需要对2D-3D关键点进行过滤匹配,当关键点数目增多时,计算耗时会增加。直接使用网络预测的速度不会因为关键点数目的增加而降低。
3)模型训练
本文设计了1个多任务学习机制,结合目标检测和姿态估计2个任务,定义了1个多任务损失函数,同时去训练图像分类、边框回归和姿态估计。损失函数定义如下,
L=Lpose+μLclass+νLbbox。
(2)
其中,Lpose、Lclass、Lbbox分别是姿态估计、类别分类和边界框回归的损失函数。姿态估计损失如式(3)所示。
江西铜业集团的德兴铜矿对含硫废石采用微生物浸出—溶剂萃取—电积方法,每年回收硫精矿1 000 t,铜9.2 t,金33.4 kg,产值达1 300多万元,铜、金和银的回收率分别为86.60%、62.32%和65.09%[26];大冶有色公司丰山铜矿对尾矿采用重选—浮选—磁选—重选联合工艺再选,得到铜精矿、铁精矿、硫精矿,其品位分别为Cu 20.5%、TFe 55.61%和S 43.61% [27]。
(3)
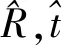
1.2 增强现实博物馆平台
本文提出一个混合框架来实现虚实融合的增强现实博物馆平台。技术路线图如图3所示。框架由3个模块组成:图像捕捉模块、文物跟踪模块和渲染模块。图像捕捉块和渲染块部署在增强现实设备中,文物跟踪块部署在云服务器中。此外,云服务器上还部署了存储虚拟内容的云数据库。在图像捕捉块中,相机获取原始视频并将这些视频剪辑成具有特定图像格式的帧,例如JPEG和PNG。由于视频中相邻的帧非常相似,只需要跟踪关键帧中的文物,以减少文物跟踪块中的计算量。为此,使用图像预处理程序,在每3张输入图像去除2张来过滤相似的图像,以减少冗余数据并挑选剩余的1张图像作为关键帧。关键帧输入到文物跟踪块。在文物跟踪模块中,使用1.1节中提出的物体6D姿态估计算法追踪得到关键帧中文物的类别和姿态,并将文物的类别输入到云数据库中以找到相应的虚拟内容。渲染模块根据追踪模块中得到的文物姿态将虚拟内容渲染到图像中的对应位置,实现增强现实的效果。使用WebGL(web graphics library)来实现渲染功能,WebGL是一个用于渲染的JavaScript脚本文件,用于渲染交互式2D和3D图形。模型渲染是一个投影变换过程,通过投影矩阵,映射虚拟物体从局部空间坐标系到世界坐标系系统,然后到相机坐标系,最后到图像坐标系。使用WebGL通过透视投影的方式将虚拟物体渲染到真实世界,使物体随着相机的移动呈现出近大远小的视觉效果,令3D虚拟内容在2D图像上看起来更逼真。通过式(4)将 3D 虚拟内容投影到图像上
Puv=K[R|T]Pw。
(4)
其中:Puv是模型3维坐标在图像上的2维投影坐标;K是相机的内参;[R|T]是追踪模块预测出的文物的姿态;Pw是模型上每一个点原始的3维坐标。通过公式(4),虚拟内容被渲染到真实世界并显示在移动设备上,实现增强现实效果。使用5G通信来连接云服务器和移动设备,因为与4G相比,5G 的数据传输速率要高10到100倍,可以解决传输大型虚拟内容带来的额外传播延迟。
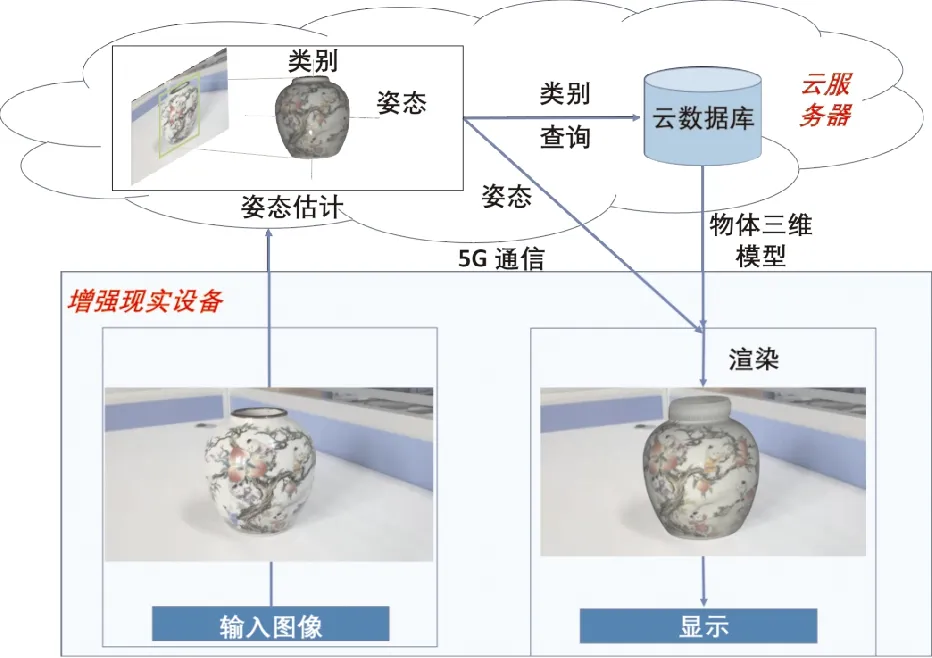
图3 系统结构图Fig.3 System structure
2 实验
2.1 算法性能测试
将本文提出的方法与2种常用的增强现实识别算法OK-POSE[15]与BB8[10]在公开测试集LINEMOD[11]数据集上作比较。LINEMOD数据集包含了13个物体类别。每一个类别有接近1 200张RGB图像,以及姿态的标注信息。使用2D Projection作为评价三维姿态估计准确度的指标,该指标是指若预测出的物体姿态与实际物体姿态在图像上的投影平均每个点距离误差小于5像素,则认为姿态估计准确。该指标适合评估增强现实相关算法,实验结果如表1所示。
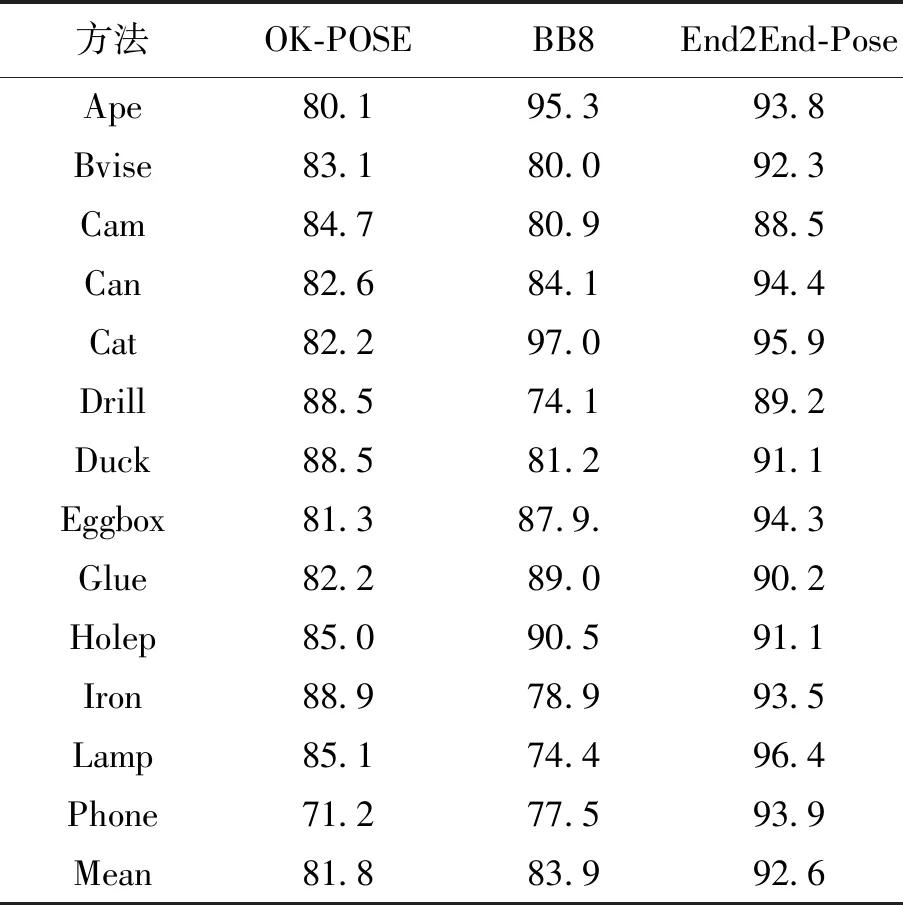
表1 在LINEMOD数据集上与准确率对比Tab.1 The accuracies on LINEMOD dataset
由表1可知,本文提出方法的准确率比OK-POSE高10.8%,比BB8高8.7%。这是由于本文使用的网络始终保持特征的高分辨率表达,并且使得每一个高分辨率到低分辨率的表征都从其他并行特征中反复接收信息,从而得到丰富的高分辨率表征。因此,预测的关键点在空间上更精确。表2展示了3种方法的运行速度,结果显示,本文提出的方法速度达到30 帧/s,快于BB8(8 帧/s)与OK-POSE(18 帧/s),满足增强现实应用对及时性的需求。这是由于本文提出的方法使用了端到端的网络结构,减少了冗余的PnP计算过程,提升了检测的速度。

表2 运行速度对比Tab.2 Comparison of the runtime
图4展示了可视化结果,对物体在不同场景下的姿态进行测试,上半部分为在背景杂乱的环境中测试,下半部分为在背景简单的环境中测试,其中,绿色的边框为ground-truth,蓝色边框为预测出的姿态。实验结果表明,当图像中包含完整物体,或物体处于简单场景中时,网络可以准确估计物体的姿态。

图4 可视化结果图Fig.4 The visualization results
实验结果表明,本文提出的方法可以准确地检测出场景中物体的6D姿态,准确率达到92.6%,并且运行速度达到30 帧/s,实现实时检测。因此,本文提出的方法满足实际应用需求,可以在增强现实博物馆系统中用于识别文物的姿态,并对其添加虚拟内容,实现文物的增强展示。
2.2 平台应用测试
本文提出的增强现实博物馆平台主要通过移动智能设备,比如手机、平板电脑,在真实环境中识别目标物体(文物、遗址),根据识别到的内容渲染出对应的虚拟信息,使参观者在游览过程中不仅能看到遗迹中残存的展品,并且可以在展品的基础上进行内容扩展,以数字化的方式对展品进行增强展示,参观者不论在任何角度观察文物都能全方位看到,打破了空间的局限性。用户通过移动设备扫描特定的文物,在设备上则会显示出复原文物的三维模型,用户可以与其进行交互,比如移动、缩放等操作。系统效果图如图5,6所示。

图5 文物复原展示Fig.5 Cultural relic restoration display
图5显示了增强现实平台利用物体6D姿态估计技术,准确地将兵马俑破损部分的3D模型渲染回兵马俑上实现无缝融合展示。图5A是移动设备采集到的兵马俑原始图像,图5B是使用OK-POSE进行姿态估计的增强展示效果图,图5C是使用本文提出的6D姿态估计方法的效果图。图5的结果表明6D姿态估计方法在增强现实博物馆展示系统中起到了连接虚拟与现实的作用,只有准确估计图像中物体的姿态,才能将虚拟内容准确叠加在图像中。

图6 交互可视化展示Fig.6 Interactive visual display
图6展示了增强现实平台可以识别图像中目标文物的姿态,并在对应位置渲染3D模型,并且模型可以移动、旋转、缩放等交互操作,方便用户多角度的观察。
3 结语
本文提出一种端到端的物体6D姿态估计算法,使用并联网络结构提取高分辨率特征,保留更多的空间信息,提升预测物体关键点的精度,使用一个姿态推理网络替代PnP算法,从关键点中得到物体姿态,提升姿态估计的精度与速度,并且使用计算机合成的图像作为训练数据,减少了对数据标注的工作量。本文还提出了一个基于云计算、深度学习、5G通信的增强现实框架,在此基础上,开发了增强现实博物馆虚实展示系统。通过一系列实验,验证了本文所提出的姿态估计算法具有高精度,相较于常规的2种增强现实识别算法,准确率提高了10.8%与8.7%,运行速度达到30 帧/s,且对于不同的场景都具有很强的泛化能力。所开发的增强现实博物馆展示系统可以实现对文物的增强展示与交互。未来的工作将致力于实现更加丰富的交互功能,更有效地传播文化遗产资源。
猜你喜欢
作物学报(2022年9期)2022-07-18
中国典型病例大全(2022年12期)2022-05-13
建材发展导向(2022年3期)2022-04-19
今日农业(2021年8期)2021-11-28
健康体检与管理(2021年10期)2021-01-03
学生天地(2020年3期)2020-08-25
广东教育·高中(2017年10期)2017-11-07
计算机应用(2016年10期)2017-05-12
诗选刊(2015年4期)2015-10-26
新高考·高一物理(2015年5期)2015-08-18
