
基于对抗生成网络的复原面貌真实感处理
2021-10-29 06:15王跃进耿国华郭沛瑶拓东成景云鹏朱新懿刘晓宁
西北大学学报(自然科学版) 2021年5期
王跃进,耿国华,郭沛瑶,拓东成,景云鹏,朱新懿,刘晓宁
(1.西北大学 文化遗产数字化国家地方联合工程研究中心,陕西 西安 710127;2.西北大学 信息科学与技术学院,陕西 西安 710127)
在人的遗骸中,颅骨是最容易被长久保存的。作为进行无名尸骨身份识别最有价值的遗骨,近100多年,法医专家们一直尝试通过颅骨来进行身份认证。其中最重要的方法之一就是颅骨面貌复原,也称颅面复原[1-2]。解剖学、人类学等领域国内外学者试图利用颅骨面貌复原技术将本学科知识拓宽,颅骨面貌复原技术的受关注度逐渐升高,但是,复原的面貌还远未完成颅骨的身份识别。计算机辅助完成的复原面貌通常与真实面貌有一定差距[3]。由于目前没有特别有效的方法,为了确认颅骨的身份,国内外刑侦人员通常的做法是将复原面貌向社会公布,由亲属或朋友辨认,进而再与可疑失踪人的照片进行比对,或者由刑侦人员根据发案地周围的失踪人员照片进行比对,该过程漫长且显无力。面对数量庞大的失踪人员,急需利用现有的信息技术提供帮助[4-5]。
本文旨在为计算机辅助复原的面貌与失踪人口的面貌图像之间搭建桥梁,研究复原面貌的真实感处理[6]。目前,复原面貌真实感领域研究者采用的处理方法大多基于纹理映射与物理模拟方法两大类。它们都是在三维模型基础上进行纹理映射或物理模拟从而完成真实感处理。这两类方法需要专业的知识才可以完成,并且复原操作过程繁琐。当前,计算机技术与各个学科之间不再互相独立,复原面貌真实感处理也不再仅仅局限于刑侦与考古领域,医疗美容、电影娱乐与信息安全等领域也都不同程度使用该技术。与该领域研究发展较早且更成熟的国家相比,国内复原面貌真实感处理还处于起步阶段。2008年国家专门立项进行颅骨面貌复原工作,为国内复原面貌真实感处理工作奠定了基石[7-8]。
本文中采用深度学习技术二维空间中完成复原面貌的真实感处理,运用P-net保证身份唯一性的情况下,生成逼真面貌图像,主要工作如图1所示。颅骨面貌复原后只是复原了颅骨生前的外表皮,此时获得面貌模型仅仅具有三维面貌形状信息,缺少真实面貌的纹理细节和五官特征。为了弥补这一问题,早期面貌真实感处理基于纹理贴图的方法来完成[9-14],这样的处理方法仅仅得到了复原面貌纹理的几何信息,而缺少可以更加直观体现出无名颅骨身份的人类学信息。
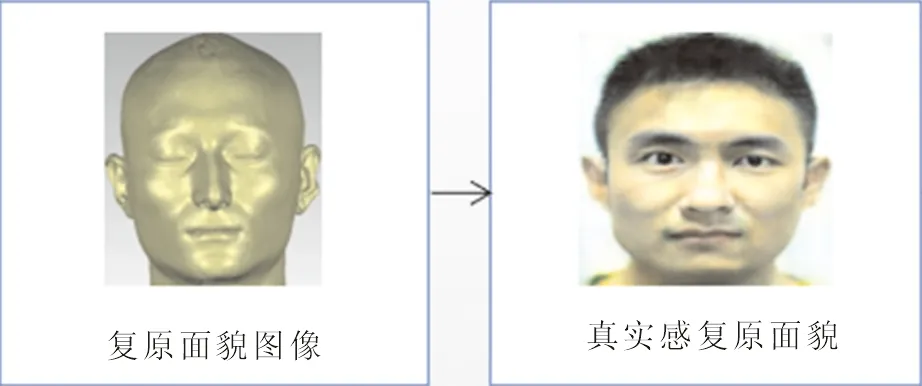
图1 本文主要工作Fig.1 Main contents of this paper
现阶段主流面貌真实感处理方式是基于纹理映射或物理模拟[15-17]。纹理映射真实感主要基于颜色纹理映射进行建模[2,5-6],颜色映射通过改变面貌表面的阴影给出皱纹的视觉印象,而不是通过几何变形。纹理映射真实感处理主要依靠3DMax或OpenGL等软件在复原面貌模型上添加数据库中通用器官纹理数据实现[3,18-21]。使用3DMax等三维建模软件将二维面貌数据的纹理或器官等细节信息提取,将这些特征映射至三维面貌模型以提高真实感[3]。物理的方法主要模拟面貌真实的皮肤形态和功能,典型的方法是质量弹簧、有限元方法和光扩散理论[7,22]。一些研究者提出有限元模型来创建富有表现力和老化的皱纹。
分析目前复原面貌真实感处理与年龄编辑的国内外研究现状[23-27],本文基于Pix2Pix对抗生成网络,引入身份约束P-net,提出进行复原面貌真实感处理的方法,技术路线如图2所示。传统的Pix2Pix网络是一种可以完成像素到像素的成对转换的通用框架[28-31],使用VGG16来提取面貌特征,VGG16通过卷积和全连接的方式进行面貌的特征提取,通过增加深度和宽度有效地提升了性能,同时只使用了3×3卷积与2×2池化,十分简洁[32-33]。但是,使用复原面貌作为输入时,常常识别不到面貌。为了确保生成真实感面貌的身份准确性,本文预训练了一个人脸面貌目标约束网络P-net,同时使用SE-Block(将SE-Block添加到先前的网络中,它会根据特征通道之间的相关性进行建模,强化重要特征)学习各通道间关系。
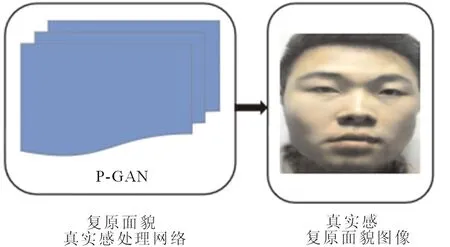
图2 技术路线图Fig.2 Technology roadmap
P-net具有三类数据,第一类数据“锚示例”和第二类数据“正示例”分别对应真实感处理前面貌数据和其对应真实面貌数据,为了保证真实感后面貌图像身份信息不变,第三类数据“反示例”样本需要选取与第一类数据身份不同但相似度最高的前3样本。本文使用Triplet loss和Contrastive loss,Triplet loss一般用于差别不明显的样本,通过Triplet Loss使得网络对于第一、三类数据分辨能力加强,Triplet loss使用平方距离来表示三类数据之间的距离。另外引入了Contrastive loss,这个损失函数主要是用在降维中,即本来相似的样本,经过降维(特征提取)后,在特征空间中,两个样本仍旧相似。而原本不相似的样本,在经过降维后,在特征空间中,两个样本仍旧不相似。
本文的训练目的是身份相同的第一、二类数据的距离越来越近,而身份不同的第一、三类数据的距离越来越远。通过这样来约束面貌生成的方向,保证生成面貌的身份保存率。
2014年Isola等提出一种全新的网络结构,如图3所示使用两个不断竞争学习的模块[34-35]。这个网络即对抗生成网络(generative adversarial network,GAN),它使用生成器模块(generator)与判别器模块(discriminator)不断竞争博弈,最终使得生成器达到要求。生成与判别模块内部结构可以是神经网络或其他结构。生成器接收为一个随机的噪声(random noise),通过学习真实样本的数据分布,使得生成器产生的伪造数据尽可能逼近真实数据分布。判别器任务则是判别数据的分布是否符合真实分布。对抗生成网络的思想本质就是一场零和游戏(zero-sum game),生成器与判别器竞争过程中一方损失则另一方一定受益。在图像领域,判别器通过分析输入数据分布判断其真假,通过判别器的判断生成器生成真实分布图像的能力进一步增强。两者在不断的竞争中提高自身能力,最终达到一个稳定状态。
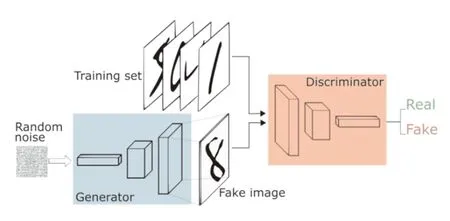
图3 对抗生成网络结构Fig.3 Adversarial generation network structure
针对生成器与判别器各自的目标,GAN网络的损失函数如公式(1)。

E(x)~Pdata(x)[logD(x)]+
E(x)~Pz(x)[log(1-D(G(x)))]。
(1)
其中,x为输入图像;Pdata、Pz分别为给定数据集和随机信号的概率分布。
GAN网络的生成器与判别器的目标相反,如此一来生成器与判别器形成一个min-max游戏,两者交替优化自身,最后到达平滑的状态。
1 Pix2Pix生成网络
Pix2Pix网络基于GAN网络进行改进,实现了图像到图像的翻译工作。GAN网络使用条件约束控制数据生成方向,Pix2Pix网络利用图像作为约束条件,网络学习输入与输出之间的关系,最终生成想要的图像。
图4左侧输入为非真实图像x(如草图)结合随机噪声z(未画出),通过生成器产生伪造图片G(x),x与G(x)进行合并通道作为判别器的输入。判别器给输入为一对真实图片的概率。图4右侧表示真实图像y与x进行通道合并,作为判别器的输入。那么判别器的目标就是,在输入是一对真实图片时,输出最大概率;在输入不是一对真实图片时,输出最小概率。生成器的目标则是提高自身生成能力,希望在G(x)和x为一对输入时,试图欺骗判别器,让判别器输出最大概率。
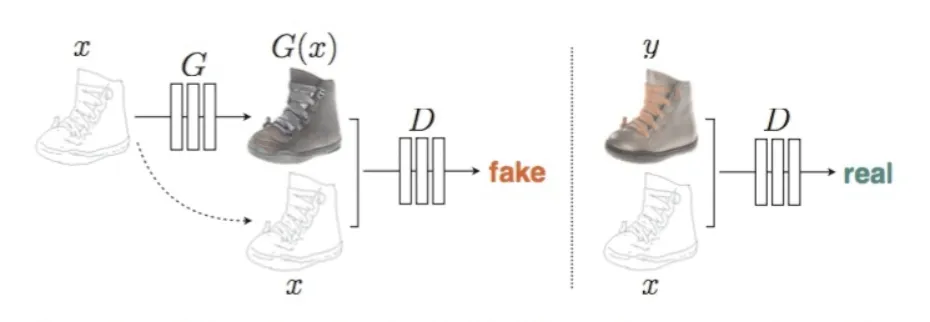
图4 Pix2Pix对抗生成网络结构[35]Fig.4 Adversarial generation network structure
Pix2Pix的损失函数是基于条件GAN网络的损失函数,L1为像录级别的损失,参考TP-GAN网络结构[35],如式(2)所示。使用L1的目的是计算输入图像与约束图像之间的距离,
(2)
其中,min和max的含义可以理解为,判别器D的训练目标是使得式(3)的值越大越好,而生成器G的训练目标是使得式(3)的值越小越好。但是这里需要将生成器G的损失函数从最小化log(1-D(x,G(x,z))修改为最大化log(D(x,G(x,z)))。这是由于对抗生成网络使用公式(3)进行训练的时候,极易发生饱和的状态,导致生成器与判别器的能力悬殊。
lcGAN(G,D)=E(x,y)[logD(x,y)]+
E(x,z)[log(1-D(x,G(x,z)))。
(3)
Pix2Pix网络的生成器采用U-Net结构,如图5所示,U-Net结构可以将各个层次的特征充分融合,所以在图像识别与分割领域广泛使用。U-Net相对传统的Encoder-decoder结构,添加了跳跃链接。跳跃连接的作用是可以将下采样与上采样的各阶段特征进行充分融合。U-Net使用上采样获取图像的细节信息,使用下采样获取图像轮廓信息,那么跳跃连接可以将各个部分的特征信保留并融合,避免出现因为随着网络传递导致丢失大量细节信息的问题。

图5 U-Net网络结构Fig.5 U-net network structure
Pix2Pix网络的判别器采用马尔科夫判别器(PatchGAN)[36]。PatchGAN不是直接对输入图像整体做出判别,而是对图像进行划分Patch,针对N×N大小的Patch进行判别。理论上不同的Patch可以认为是没有关联的,判别器结果取所有Patch判别结果平均值。通过Patch分批进行判别,降低了参数量,提高运算速度。
Pix2Pix基于对抗生成网络结构为图像翻译一类问题提供了通用框架。生成器使用U-Net结构,融合了网络各层的特征信息,保证生成图像的质量。判别使用PatchGAN,解决了直接输入一张图片运算速度慢的问题,同时因为是使用Patch判别,所以输入图片的大小不受限制。
2 面貌约束网络P-net
为了确保生成的真实感面貌的准确性,本文预训练了一个用于目标约束的面貌网络P-net,这个网络与之前的面貌相似度度量网络不同,因为当数据为复原面貌图像时,面貌检测网络通常会检测不到目标。本文针对这个问题重新来训练一个网络P-net,使用VGG16来进行人脸特征提取,结合SE-Block来学习各个特征通道之间的关系,为了让网络更好的收敛,引入了BN层,损失函数使用Triplet loss和Contrastive loss相结合。P-net网络结构如图6所示。
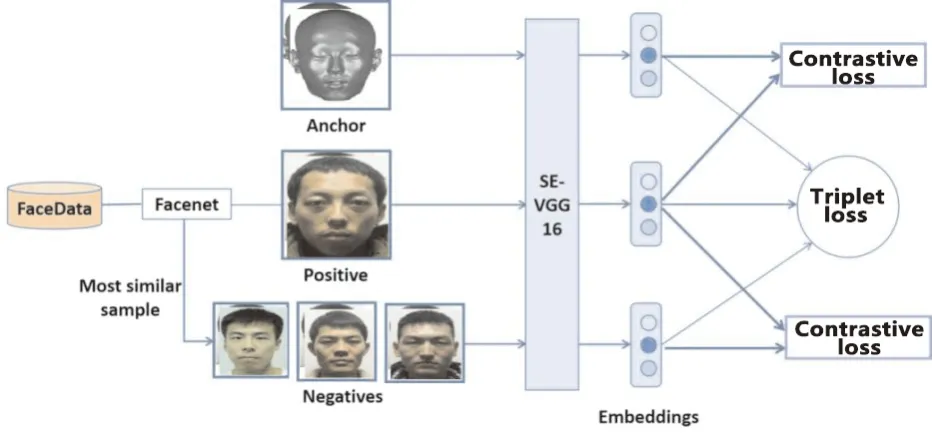
图6 P-net网络结构Fig.6 P-net network structure
P-net网络中主要具有3类数据,Anchor代表复原面貌图像,Positive代表Anchor的真实面貌图片,Negative代表与Anchor不同身份的真实面貌图像。本文将Anchor、Positive和Negative称为图像三元组。P-net网络目标是使得相同身份的Anchor和Positive距离变近,而不同身份的Anchor和Negative距离变远。
为了提高判别网络的能力,Negative样本数据选取与Anchor身份不同但与其对应的面貌图像相似度最高的样本,这些样本被称为Hard Negative。P-net使用Face++将Anchor面貌数据与数据集中的面貌进行相似度度量,选择相似度最高的前3个面貌数据作为Hard Negative样本。Triplet loss可以将差别很小的数据进行区分。输入图片三元组,通过使用Triplet loss,将复原面貌图像Anchor与Positive和Negative之间的距离使用平方距离表示。那么Triplet loss的损失函数计算公式可表示为公式(4)。
(4)
在数据量较小的情况下,Triplet loss让Anchor样本和Positive样本的距离小于Anchor样本和Negative样本的距离。此外,Anchor样本和Positive样本的距离尽可能小,所以另外引入了Contrastive loss,Contrastive loss将数据进行降维,降维之后的数据之间的相似性不会改变。本文所采用的Contrastive loss损失函数为
(1-y)max(margin-d,0)2。
(5)
其中,d为两个图像之间的欧氏距离;margin为预设置的阈值。损失函数将Triplet loss和Contrastive loss相结合,得到P-net网络的损失函数为
(1-y)max(margin-d,0)2。
(6)
3 面貌真实感网络P-GAN
Pix2Pix将网络中生成器的随机输入信号z换做一张图像x和随机信号z的组合向量{z,x},输出为G(z,x)。判别器要判断{x,G(z,x)}和{x,y},其中y为本文实验想要得到真实数据Real。网络中的生成器采用U-Net结构,U-Net使用拼接的方式将不同通道的特征融合,形成更厚的特征,这样采用多尺度特征融合保留了更多的信息,得到的图像更加精细。判别器采用了PatchGAN,提高了网络的运行速度。
针对Pix2Pix网络生成复原面貌图像真实感低的问题,本文在此基础上引入预训练网络P-net,它专门针对面貌真实感的处理,P-GAN网络的整体输入为成对的面貌图像和人脸数据,将P-net中输入部分替换为二元组,特征提取部分为SE-VGG16,去除Triplet loss部分,将提取到N维的特征映射到超球面,最后使用余弦距离(记为P-cos)来度量相似度。P-net主要用来约束生成人脸图的唯一性,P-GAN网络框架如图7所示。
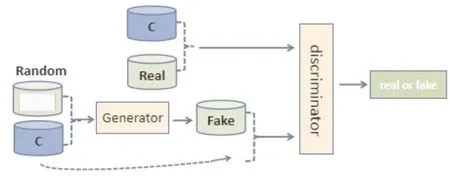
图7 P-GAN网络结构Fig.7 P-GAN network structure
本文将P-net作用于生成器部分,将P-net产生的损失引入生成器的损失函数中,来提高生成器的准确度,修改后的损失函数见式(7),
P-GAN loss=
E(y,x)~Pdata[logD(y,x)]+
E(z,x)~Pz[log(1-D(G(z,x)))+
P-net loss]。
(7)
4 实验结果与分析
4.1 实验数据与参数设置
本文在面貌数据集上评估了P-GAN真实感处理的效果。数据集中含复原面貌图像和与其对应真实面貌图片200对,对于P-net的预训练网络,本文使用计算量较小的VGG16网络来进行特征提取,将网络的输入改为三输入,引入BN层和SE-Block来加速网络训练以及获取特征通道之间的关系。将最后一层的全连接替换为128,用于得到128维特征向量,损失函数采用Triplet loss和Contrastive loss相结合的方法,它们分别作用于(Anchor、Positive、Negative)和((Anchor、Positive),(Positive、Negative)),采用梯度下降法进行优化。网络的参数初始化分为2部分,①网络的卷积部分的参数直接采用VGG16论文中的参数;②全连接层参数采用截断为0.01的高斯分布。本文网络使用Fine-tuning训练。
对于P-net网络,本文通过Face++来筛选Hard negative样本,选取相似度最高的前k个样本与所对应的m个Anchor和Positive组成m×k三元组,用于P-net网络的训练。
4.2 实验结果评价标准
通过提取人脸的特征,计算两张面貌图像的欧式距离与余弦距离,从而判断两者身份相同的概率,并给出相似度评分,百度API(https:∥ai.baidu.com/tech/face/detect)人脸识别准确率已经达到99.9%。对于一般的人脸相似度判断,使用欧氏距离结合余弦距离进行计算。欧式距离比较简单,用来计算两个点间的距离,公式为
(8)
通过计算空间目标向量的夹角余弦值(cosθ),判别两者之间的相似程度,cosθ值越小说明夹角越小,也就代表两者相似程度越高。
(9)
在百度人脸相似度平台会看到人脸相似度是一个百分比,其使用Sigmoid函数,这个函数y的范围是(0,1),对应的百分比范围0~100%,同样可以通过Sigmoid函数的变形来实现从欧氏距离到人脸相似百分比的映射。
(10)
4.3 实验结果分析
本文人脸相似度评价采用百度人脸相似度API,首先API对生成的图像进行人脸检测,P-GAN所有生成的样本均被检测为正常人脸,通过计算真实面貌与生成面貌图像之间的欧式距离与余弦距离,得到面貌相似度得分。该得分在0~100之间,分数越高表明人脸的相似度越高,评价结果如表1所示。图8展示了Pix2Pix网络和P-GAN网络的真实感处理结果。
本文对数据进行增强操作(对称反转和加入高斯噪声等)后,与原始Pix2Pix网络进行结果比较。发现添加P-net约束后,可以直观地看出本文网络P-GAN在进行面貌真实感处理时对于身份的保存率更高,同时在发型和情感上也与真实面貌图像有着更优的保存率。但是,仍然存在生成出错的样本,很大一部分原因是由于数据量少,网络过拟合导致。P-GAN网络生成的真实化面貌图像全部可以被识别成功,同时与真实面貌相似度最高可达93.06%,与视觉上的感受相同。本文P-GAN网络真实感处理后的面貌图像对于身份信息保存率全部高于传统的Pix2Pix网络。身份信息保存率高,主要是由于P-net中损失函数的创新功能。
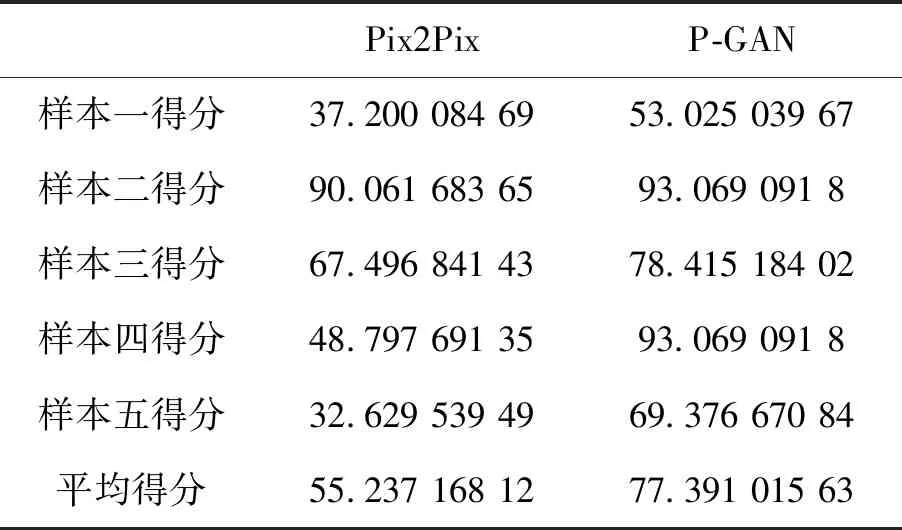
表1 Pix2Pix与P-GAN结果评价Tab.1 Pix2Pix and P-GAN results evaluation

图8 面貌真实感结果Fig.8 Face realistic result
P-net的损失函数由Triplet loss与Contrastive loss结合而成,Triplet loss的目标是使得相同身份的数据距离尽可能近,同时使得不同身份数据的距离尽可能远(至少大于设定值margin)。针对成对数据P-net的损失函数引入Contrastive loss,使得网络可以有效地处理这类数据,
(11)
其中,d表示两个图像之间的欧氏距离;s为两者的相似系数;margin为预设设置的阈值。当样本相似s的值为1,式(11)只剩下前一项,如果两个相似的样本欧式距离大,那么通过的平方加大损失进行优化模型;当样本不匹配时,式(11)只剩下后一项,而不同身份样本的欧氏距离反而很小的话,通过margin进行加大损失。总之,当不同样本出现欧氏距离与其身份不同的情况,本文P-net损失通过s值的变化,对其加大损失。通过Triplet loss与Contrastive loss结合的损失函数,可以保证真实感处理后人脸图片的身份信息得以保存。
5 结语
本文所提出的P-net用来生成更加准确的面貌图像,通过引入Face++来选择 Negative样本,采用VGG16来提取特征,Triplet loss作为损失函数来进行训练得到一个特征提取器,对P-net产生的特征进行相似度度量,并且将损失引入到生成器当中,用来约束生成器的生成规则。它不仅可以应用于复原面貌真实感处理,也可以应用于其他的生成机制中(人脸老化、表情变化、人脸识别数据集等)。
猜你喜欢
疯狂英语·新悦读(2022年8期)2022-09-20
小天使·二年级语数英综合(2021年4期)2021-06-15
现代装饰(2021年1期)2021-03-29
科技知识动漫(2017年11期)2018-03-07
Coco薇(2017年11期)2018-01-03
小天使·二年级语数英综合(2017年10期)2017-10-31
戏剧之家(2016年20期)2016-11-09
电脑知识与技术(2015年30期)2016-01-09
雕塑(1999年4期)1999-06-28
