
基于极化码的分布式信源编解码系统的FPGA 设计与实现*
2021-10-26 06:32:14周峻辉卿粼波吴晓红赵祥伟
网络安全与数据管理 2021年10期
周峻辉,杨 红,卿粼波,吴晓红,赵祥伟
(四川大学 电子信息学院,四川 成都 610065)
0 引言
随着无线传感器网络[1-2]、监控技术[3]、卫星通信[4]等技术的发展,资源受限终端的应用场景日渐普遍。 但这类终端因特定场景对其低功耗、小型化的要求而面临资源限制,所以在对其数据压缩编码的过程中必须要考虑计算的复杂度。传统的信源编码方案采用联合编码的方式对传输数据进行压缩,在编码端进行大量的计算,所以不再适用于这些资源受限的终端设备。 而分布式信源编码(Distributed Source Coding,DSC)方案则是通过各编码端独立编码,在解码端充分考虑信源间相关性来实现联合解码,从而将大量的计算过程从对复杂度敏感的编码端转移到了资源相对丰富的解码端,因此分布式信源编码更适合应用于编码端资源受限的场合。
现在分布式信源编码得到了日渐深入的研究,同时对信道码的研究更是科研人员关注的重点。现在的分布式信源编解码系统一般采用应用广泛的LDPC 码[5]或 Turbo 码[6-7]。 此 外 2009 年 Arikan 教 授提出的极化码[8]作为第一个被严格证明可以达到香农极限的信道编码方法,其具备更优良的检错能力、更好的码率兼容性和更低的编译码计算复杂度,所以有学者开始研究将极化码应用在分布式信源编码中。 文献[9-10]分别实现了一种基于极化码的分布式信源编码系统,但这些系统均按固定码率进行传输,所以不能获得最佳的信源压缩性能。
本文先针对极化码特性进行码率自适应方案设计,并将其应用于分布式信源编解码系统中,通过引入CRC(Cyclic Redundancy Check)校验码的反馈机制,使系统可以在传输最少的校验位时成功译码。目前国内外还鲜有人在FPGA 上实现基于极化码的分布式编解码系统,而且基于极化码的编码器和解码器的研究往往是单独进行硬件实现,并未整合在同一个系统中。 针对这一现状,本文将基于极化码的DSC 系统在 FPGA 平台上完成设计和部署,并进行仿真与结果分析。
1 DSC 理论与极化码基础
1.1 DSC 理论
分布式信源编码以Slepian-Wolf 理论[11]和Wyner-Ziv 理论[12]为理论基础,通过尽可能地利用各信源彼此之间的相关性信息,在编码端通过独立编码的方式将各信源数据送入编码器中,在解码端通过联合解码的方式解码各信源数据,如图1 所示。
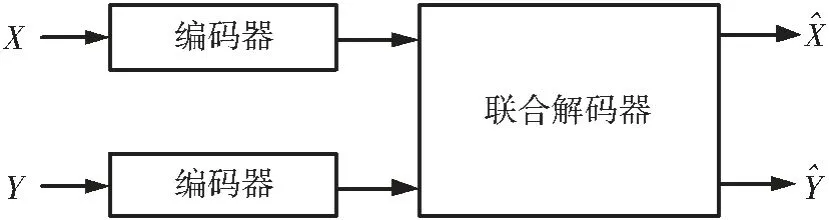
图1 独立编码、联合解码示意图
由于 X 和 Y 是相关信源,可以把 Y 当做 X 经过一个虚拟信道后产生的边信息。 在解码端根据X 通过编码器后产生的校验位序列,和 X 通过虚拟信道后产生的边信息序列Y 来进行解码,如图2所示。
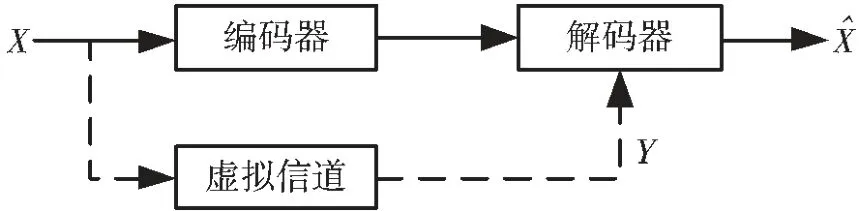
图2 分布式信源编码示意图
1.2 信道极化
信道极化是极化码编码过程中最核心的思想,它保证了极化码传输的可靠性。 其原理是先将原始信道通过信道合并得到一个组合信道,再通过信道分裂,得到信道容量趋于0 或趋于1 的极化信道WN。随着码长的增加,极化信道的信道容量越趋近于0或者1。 信道容量趋近于1 的信道其抗干扰性好,适合用来传输信息;信道容量趋近于0 的信道容易受到干扰,所以一般用来传输收发双方定好的冻结比特。
1.3 极化码编码原理
记极化码码长为 N=2n,信源序列 u=(u1,u2,…,uN),其中信息比特的集合为 uA,A 代表通过极化码构造得到的信息比特的索引集合; 冻结比特集合为uAC,AC为冻结比特的索引集合。 极化码的编码过程还需要生成矩阵 GN,GN是一个大小为 N×N的矩阵,它通过 G2的克罗内克积(Kronecker product)得到。

在编码过程中,可设冻结比特为全0,则编码过程可表达为式(3),其中 GA表示 G 中行号位于 A 中的行构成的子矩阵:
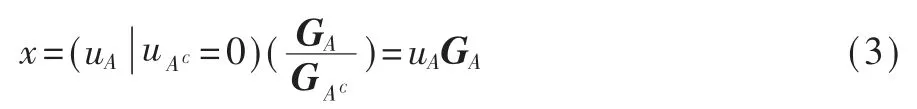
1.4 极化码译码原理
Arikan 教授最初提出极化码构造原理的同时,也提出了最经典的极化码译码算法即SC(Successive Cancellation)连续消除译码算法。 随后陆续有学者提出各种改进算法,如SCL(Successive Cancellation List)译码算法[13]和 CA-SCL(CRC Aided Successive Cancellation List)译码算法[14],这两种算法都是在 SC 译码算法的基础上发展而来的。 SC 译码算法先通过对接收信号的似然比进行计算得到比特估计值:
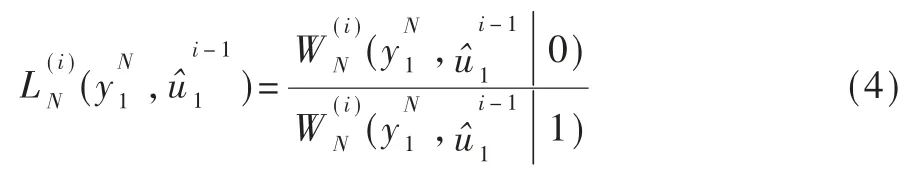
如果 ui对应冻结比特,可直接令如果 ui对应信息比特,则需要进行下式判决:
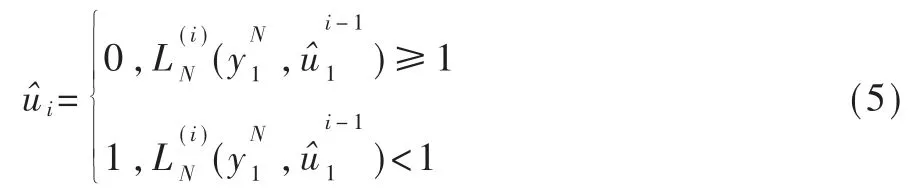
似然比通过式(6)、(7)递归计算:
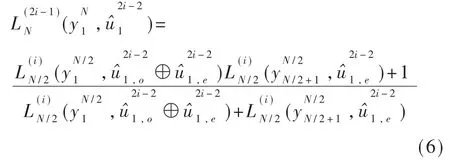
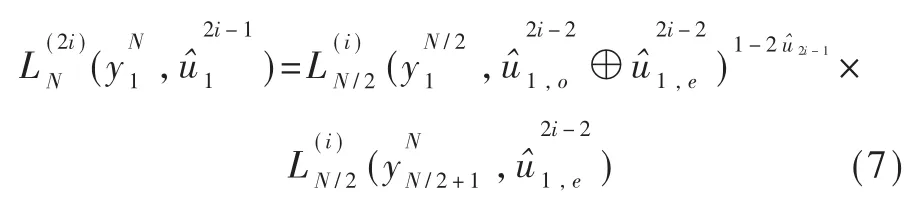
2 基于系统极化码的DSC 模型设计
2.1 系统极化码设计
1.3 节和 1.4 节是关于一般的非系统的极化码编译码流程, 即码字序列中不直接包含信源比特。为了采用极化码作为本文设计的系统信道码来实现分布式信源编解码模型,需要直接从码字序列中分别提取出信息比特和冻结比特,故本文采用系统极化码[15]的编解码形式进行设计。 记 GAA为GA中列号位于A 中的列构成的子矩阵:

根据式(9),可以通过两步编码的方法实现系统极化码的编码过程。 具体过程如下:
(1)将信息比特置于uA,冻结比特可全部置零,计算 m=uG。
(2)将mAC置零,计算根据冻结比特索引即可得出冻结比特xAC。
2.2 DSC 模型的码率自适应方案设计
由于极化码自身的特性,可以在只传输部分校验位的情况下准确译出码字,故本文在此基础之上设计校验位的码率自适应方案以动态调整码率,具体实现的DSC 模型如图 3 所示。
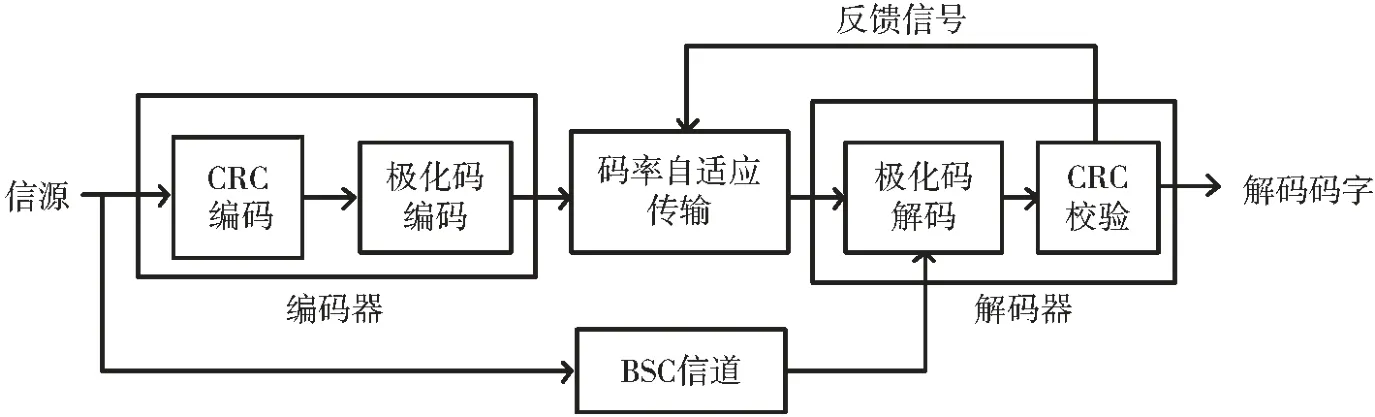
图3 基于极化码的码率自适应分布式信源编解码系统
信源的系统位通过BSC 信道产生系统位的边信息,经过编码后的校验位逐个发送给解码器。 解码器根据带噪的边信息和当前获得的校验位的对数似然比进行译码,若极化码译码码字进行CRC 校验失败,则将更多的校验位传至解码器,解码器进行重新解码,直至解码成功为止。
3 基于 FPGA 的 DSC 系统设计
3.1 系统总体设计框架
本系统主要由四个模块构成,如图 4 所示。 二进制信源source 输入给编码模块和边信息处理模块。 在边信息处理模块中对source 进行加噪后送入到解码模块。 编码模块对 source 进行极化码编码后,将校验位全部送至删余模块进行缓存。 删余模块逐个发送校验位至解码模块。 解码模块根据收到的校验位和通过边信息处理模块传来的全部系统位进行尝试解码,未收到的校验位则相当于被打孔删余,对应的对数似然比为零。 若解码失败,则反馈一个信号给缓存了全部校验位的删余模块,使其按顺序输出下一位校验位,解码模块有了更多的校验位数据后再次尝试解码,当解码成功时输出译码码字。
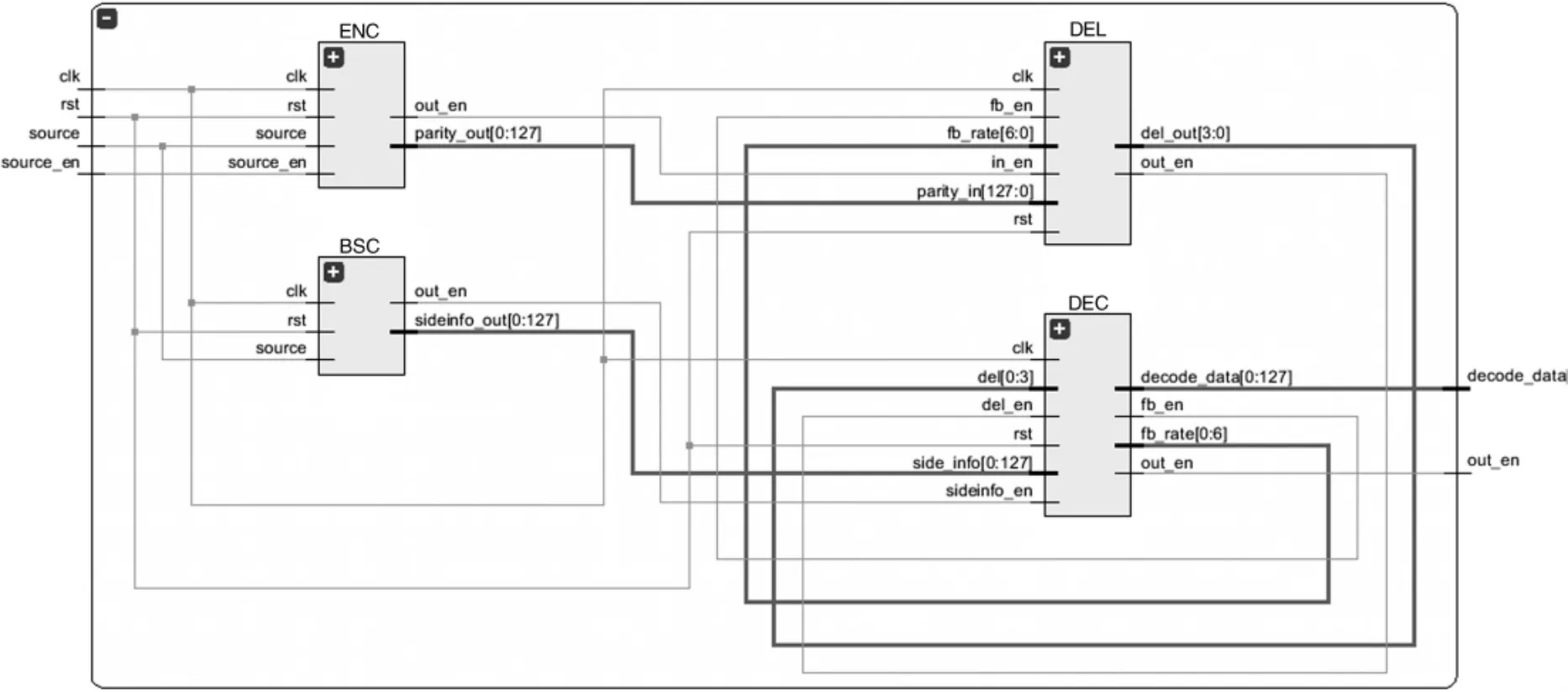
图4 基于极化码的分布式信源编解码系统RTL 电路图
3.2 编码(ENC)模块的设计
编码模块将输入的信源序列通过系统极化码编码过程产生出相应的校验序列。 根据式(3),编码过程需要提前准备G 矩阵、信息位索引的数据,本设计先在数值计算软件中产生相关数据,再将相关数据导入到Vivado 中设计成 ROM 实现对数据的调用。 系统极化码编码过程分为三步,首先将 ROM 中的数据和输入的信源序列缓存在寄存器中以方便进行计算;其次通过非系统极化码编码得到非系统码字;最后通过系统极化码编码将非系统码字转换为系统码字,即2.1 节中提到的两步编码,最后使输出有效信号拉高。
3.3 边信息处理(BSC)模块的设计
边信息处理模块模拟了一个虚拟信道,它将信源序列以一定的交叉概率生成一个边信息给解码模块。交叉概率越大,边信息序列和信源序列的差异越大,解码所需要的校验位也越多。该模块的状态机只有两步,先将信源序列等数据存入寄存器中;再以一个随机序列为索引,将信源序列进行随机比特翻转生成边信息输出,同时使输出有效信号拉高。
3.4 删余(DEL)模块的设计
删余模块为本设计中码率自适应方案的核心模块。 它将编码模块输出的校验序列进行缓存,在第一次校验比特发送过程中,根据交叉概率的大小发送一定数量的校验比特,然后让解码器进行尝试解码。 若解码器解码失败,则发送反馈信号给删余模块。 删余模块每次收到反馈信号后则按顺序发送一位校验比特给解码器使其重新解码并记录发送校验比特的总数。
3.5 解码(DEC)模块的设计
本文根据FPGA 平台和硬件描述语言的特性,在充分考虑资源消耗及系统吞吐率的情况下,采用了改进的SC 译码算法的硬件实现方式,从而使其更适合在FPGA 平台上进行实现。 通过在解码模块中增加CRC 校验环节,使解码模块带有一个反馈输出,从而实现码率自适应方案。
3.5.1 译码算法的优化设计及实现
由于在极化码译码过程中对数似然比的计算涉及了大量的乘法和除法运算,这极不易于在FPGA中进行实现,因此需要对对数似然比的迭代计算进行等价替代,于是采用最小和译码算法,可将对数似然比的递归算法简化为如式(10)、(11)所示:
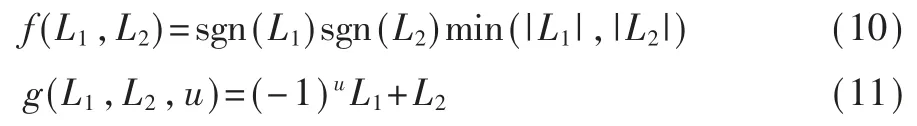
由于对数似然比在运算过程中始终是以浮点数的形式参与计算,而在FPGA 中直接对浮点数进行操作较为复杂,FPGA 直接操作的是一定位数的reg 类型数据,因此要将浮点数形式的对数似然比定点量化为一定比特数的定点数。 若量化比特数越多,则译码过程需要占用越多的资源;若量化比特数过小,则会降低译码性能。 最终本文采用4 比特定点量化的方案,即所有的对数似然比用4 比特表示,又由于对数似然比有正有负,且最小和译码算法需要对数似然比的正负符号值直接参与运算,因此采用补码的形式,即 1000~0111 对应于-8~7。

3.5.2 CRC 校验
加入了CRC 校验码的解码模块的示意图如图5所示。
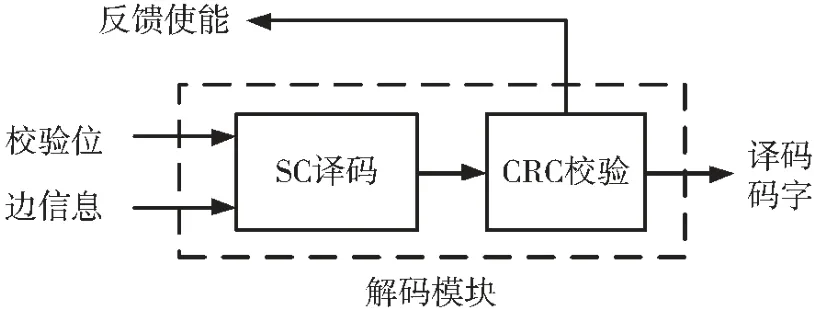
图5 解码模块示意图
解码模块将已获得的全部边信息和部分校验位一同送至SC 译码器进行译码,得到译码码字后开始CRC 校验判定。 若此刻解码模块获得的校验位位数较少,则经过SC 译码后得到的码字极易有错,不能通过CRC 校验,于是解码模块将反馈使能信号拉高,指导删余模块进一步传输校验位信息。若解码模块已获得了解码所需的足够的校验位位数,则能成功译出码字,即能通过 CRC 校验,于是解码模块输出译码码字。
4 实验结果及性能分析
4.1 系统仿真结果
为验证系统功能正确性,本文采用Xilinx 公司的Virtex-7 VC707 开发板,在Vivado 软件中利用硬件描述语言进行设计,并使用Vivado 自带的仿真工具,通过编写testbench 进行系统功能正确性的仿真验证。仿真参数进行如下配置:极化码码长N=256,信源序列长度 K=128,交叉概率 p=0.03。
从图6 中可以看到,第一次进行译码时,删余模块先向解码模块发送了73 位校验比特。 每次译码失败后,解码模块通过输出反馈信号,使删余模块按顺序发送下一位校验比特。 经过两次反馈过程之后,即当发送了75 位校验比特后,解码模块成功通过解码和 CRC 校验译出了正确的码字, 然后输出译码码字并使输出有效信号out_en 拉高。
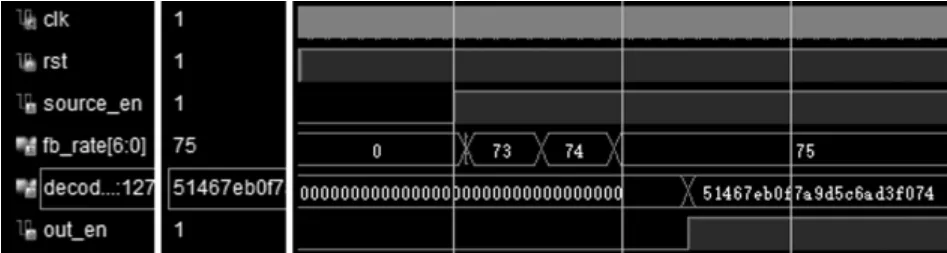
图6 系统仿真结果
4.2 压缩码率测试结果
本文中极化码压缩码率的计算公式可表示为:

式中NA表示信源序列长度,NAC表示需传输的校验比特数。 通过改变交叉概率的大小,可得到不同的极化码压缩码率,极化码与 LDPC 码[16]压缩码率对比如图 7 所示。
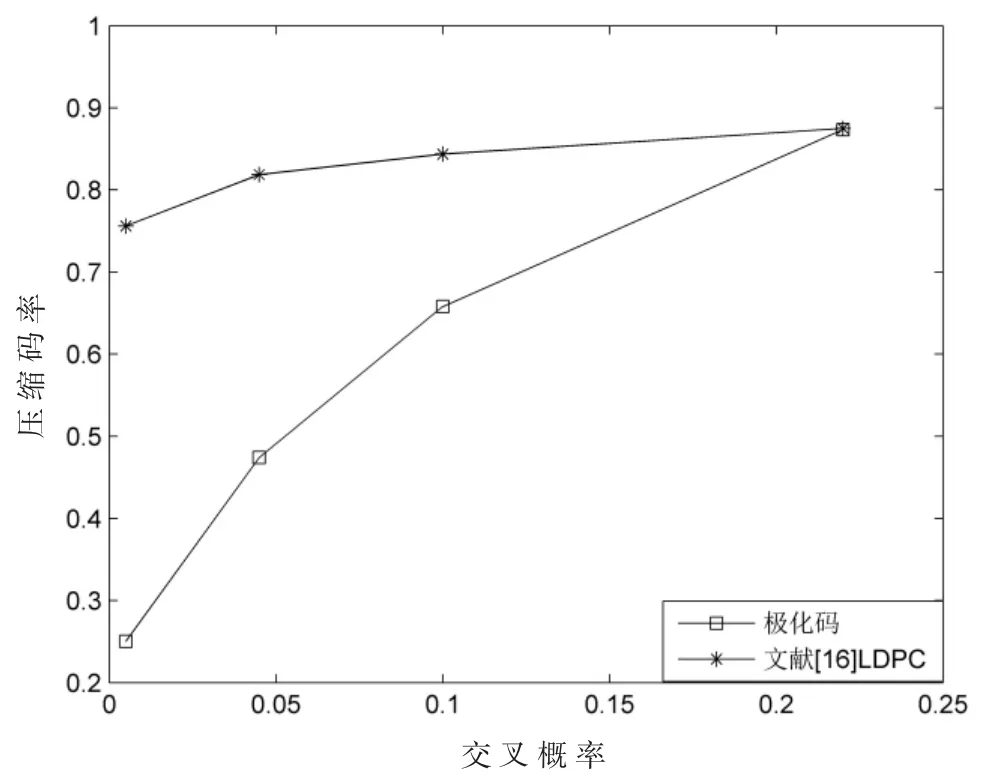
图7 极化码与LDPC 码压缩码率比较图
4.3 系统性能测试
将设计完成的系统进行综合后,可以在工程总结窗口查看系统的资源占用情况,如表1 所示。
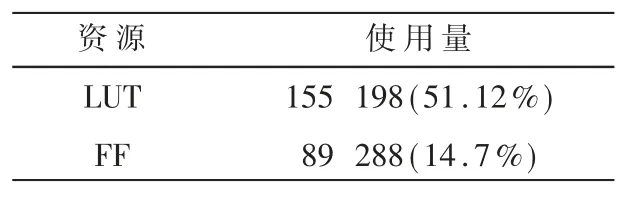
表1 系统资源消耗情况
系统的吞吐率可以通过式(14)计算得出:

式中,f 为时钟频率,N 为有效码长,t 为所消耗的时钟周期。 由于在本文中,有效码长为 128,时钟频率为 200 MHz,共消耗了 27 843 个时钟周期,由此计算出吞吐率为 919 kb/s。 表 2 是本文所设计系统的吞吐率与其他方案的比较。

表2 吞吐率比较
5 结论
本文针对极化码的特性,设计了一种码率自适应的基于极化码的分布式信源编解码系统模型,并在 Xilinx 公司的 Virtex-7 VC707 开发板上完成了实现,可应用于多种数据传输平台,具有一定的应用价值。 本系统的吞吐率目前主要受限于极化码译码器的硬件实现方式,下一步可通过优化译码器结构,并引入流水线的思想进一步提高系统性能。
猜你喜欢
中国石油石化(2022年12期)2022-07-16 08:28:28
无线电工程(2022年4期)2022-04-21 07:19:44
现代计算机(2021年36期)2021-03-14 00:50:38
中国外汇(2019年19期)2019-11-26 00:57:32
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年11期)2019-01-21 02:20:48
电子世界(2017年16期)2017-09-03 10:57:36
新闻传播(2016年3期)2016-07-12 12:55:27
西部广播电视(2015年4期)2016-01-15 02:05:50
遥测遥控(2015年2期)2015-04-23 08:15:19
