
应用于射电天文的高效实时管道数据流传输与处理技术*
2021-10-26 06:13张海龙冶鑫晨王万琼王博群张亚州
天文研究与技术 2021年4期
张 萌,张海龙,3,4,王 杰,4,李 健,冶鑫晨,4,王万琼,李 嘉,王博群,张亚州
(1. 中国科学院新疆天文台,新疆 乌鲁木齐 830011;2. 中国科学院大学,北京 100049;3. 中国科学院射电天文重点实验室,江苏 南京 210008;4. 国家天文科学数据中心,北京 100101)
多波束和相位阵馈源(Phased Array Feed, PAF)接收技术的发展使得天文观测设备获取数据的能力不断提高,射电天文观测数据正在以一种实时、海量、持续的模式增长。终端系统中海量天文信号的高效传输和实时处理,需要异构的分布式计算与存储平台作为支撑。数据传输过程中,系统首先将接收的信号进行数字化,实现通道划分、射频干扰(Radio Frequency Interference, RFI)消减等预处理,这些处理可以在ROACH[1],SNAP[2]或RFSoC[3]等系列开发板卡上执行。硬件板卡与服务器平台通过高速网络连接,将数据打包并通过网络传输至服务器进行复杂算法处理。基于现场可编程门阵列 + 图形处理器的混合架构平台对软件性能提出了更高的要求,高速实时传输天文数据包时需要考虑高输入输出环境下的网络数据包丢失问题。Linux内核在处理宽带网络流量时有很大的开销,由于采用了用户数据报协议(User Datagram Protocol, UDP),系统必须处理丢失、无序和重复的数据包,否则会造成相位信息缺失。对脉冲星数据来说,丢包可对脉冲星的周期预测和折叠等产生严重影响。中央处理器与图形处理器之间数据高速流转时,在图形处理器高效实时数据处理阶段,中央处理器与图形处理器之间通信速率可能会造成的性能瓶颈,也是需要考虑并解决的问题。
射电天文数字终端系统中实现数据包高速率实时传输与预处理的程序称为管道[4]。管道中的数据链式地连接在一起,全部同时在其内部流动。管道包含多个处理单元,每个单元执行特定的任务,最基础和主要的功能是提供缓存模块,暂时存储数据,实现数据的实时流转。应用于射电天文异构终端系统的管道数据传输主要包括3个阶段,数据接收阶段、基于中央处理器/图形处理器的数据处理阶段、数据输出阶段。管道通过缓冲模块实现从数据接收到写入磁盘流程的高效传输,通过调用不同阶段的程序模块实现数据流传输过程的实时处理。
本文研究并分析了可部署在射电望远镜终端系统的数据管道,提出了基于现场可编程门阵列 + 图形处理器的动态、高性能实现海量射电天文数据流实时传输、处理和监控的管道设计思路,为未来新疆110 m射电望远镜(QiTai Radio Telescope, QTT)[5]开发定制多功能实时数据流传输与处理管道软件提供参考。
1 现有射电天文数据流管道软件
针对射电天文数据的实时高速传输,国外已取得了一系列研究成果,提供了开源中央处理器/图形处理器数据流管道软件,包括GUPPI_daq, PSRDADA[6], Hashpipe, Bifrost, Kotekan, Pelican和Cobalt等,国内相关研究正处于起步阶段。
GUPPI_daq是绿岸终极脉冲星处理仪器(the Green Bank Ultimate Pulsar Processing Instrument, GUPPI)数据采集子系统,通俗灵活,使用简单,已有十多年的历史。PSRDADA和Hashpipe均为用于处理高速数据流,最初分别应用于帕克斯(Parkes)[7]望远镜和绿岸望远镜(Green Bank Telescope, GBT)[8]。Bifrost是快速管道开发的开源软件框架,专门为射电天文实时数据流处理而设计,应用于长波阵列(the Long Wavelength Array, LWA)[9]后端。Kotekan作为加拿大氢强度映射实验(Canadian Hydrogen Intensity Mapping Experiment, CHIME)[10]高度优化的数据流处理框架,更注重效率和吞吐量。Pelican提供了高度抽象的应用程序接口,为静态、准实时处理而设计。Cobalt管理通过网络和图形处理器的数据流,主要应用于低频阵列(the Low Frequency Array, LOFAR)波束合成。
1.1 GUPPI_daq
应用于绿岸望远镜的GUPPI_daq,是脉冲星数字终端GUPPI的数据采集软件。GUPPI_daq实现了数据流实时接收和处理,并以PSRFITS格式记录文件,实时处理选项包括基础模式、折叠模式和子带模式。
GUPPI基于CASPER(Collaboration for Astronomy Signal Processing and Electronics Research)FPGA板卡处理800 MHz带宽、8 bit量化数据,在10 GB以太网环境下封装成数据包发送,由GUPPI_daq负责接收,并将数据保存至磁盘。传输过程中实现与控制子系统交互,提供人机交互的软件界面,并记录监控参数,保存到输出文件。
GUPPI_daq使用多线程工作模式,线程之间通过基于共享内存的环形缓冲区传输数据。在基础模式下,GUPPI_daq只使用两个处理线程和一个数据缓冲区,由网络处理线程负责接收现场可编程门阵列生成的数据包,通过检查自定义的序号判断数据包是否丢失,将接收的数据保存在环形缓冲区,丢弃的数据填充为零,同时从状态缓冲区读取头信息,复制到数据块头中。写盘处理线程读取已写满的缓冲区并解析数据块头信息,以PSRFITS格式保存在磁盘中。
高速率运行时,GUPPI_daq存在磁盘写入速度的限制问题。通过高速以太网接收数据时,800 MB/s接收速率下,GUPPI_daq传输出现少量数据丢包现象[11]。
1.2 Hashpipe
Hashpipe是早期GUPPI_daq的衍生,最初作为美国国家射电天文台通用绿岸天文频谱仪(National Radio Astronomy Observatory Versatile GBT astronomical Spectrometer, NRAO VEGAS)[12]的高效共享管道引擎,由David Macmahon改写,可用于FX相关器、波束合成器、脉冲星观测、快速射电暴(Fast Radio Burst, FRB)、搜寻地外文明(Search for ExtraTerrestrial Intelligence, SETI),也可应用于我国FAST、 “天籁” 项目[13]。
Hashpipe设置共享内存段和信号量机制等功能,在运行时基于命令行参数动态构建管道,整体框架如图1。Hashpipe采用模块化架构设计,蓝色部分表示插件。Hashpipe插件是一个共享库,定义了应用程序特定的线程模块、共享数据缓冲区等功能模块,并且允许用户创建插件,以便在Hashpipe运行时调用。红色部分表示可执行文件,在Hashpipe运行时动态调用已定义的插件。
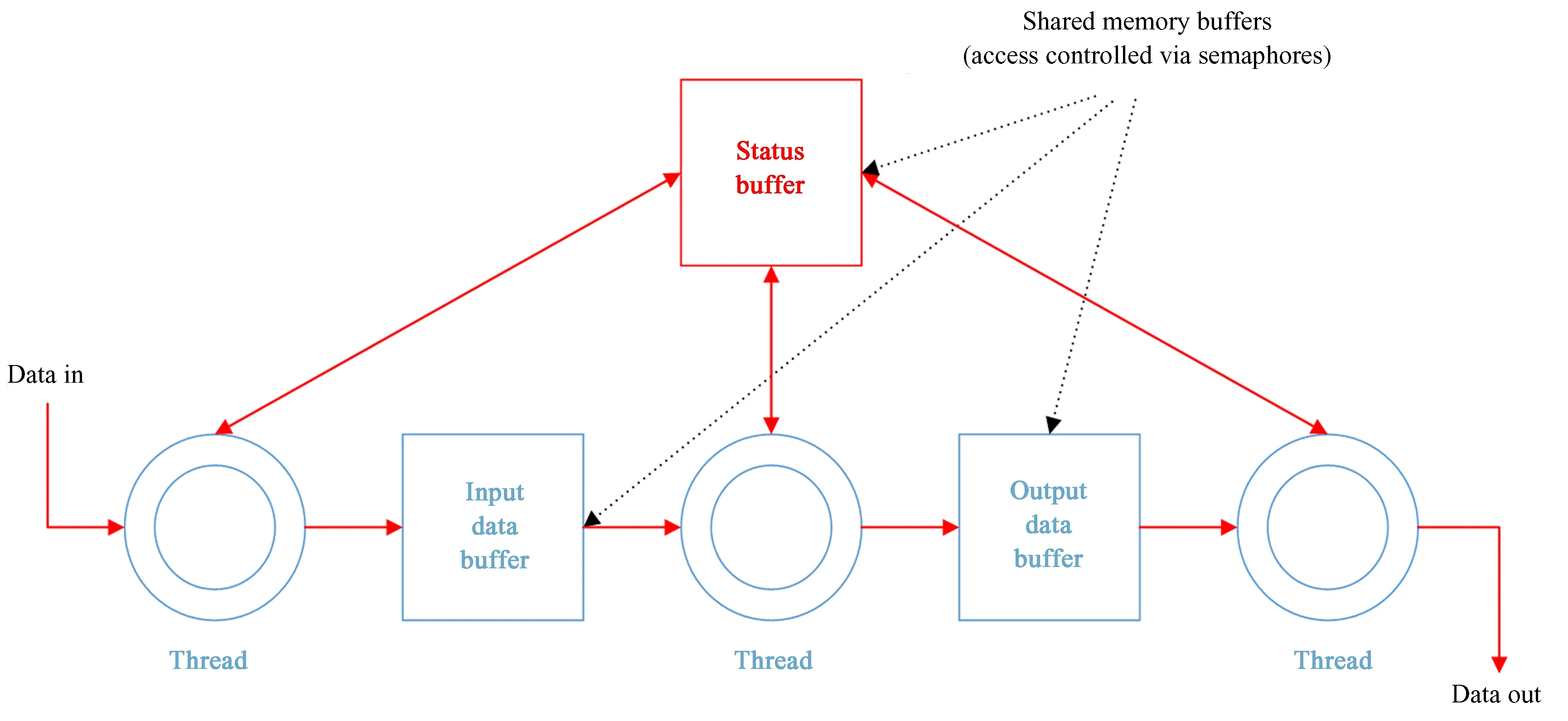
图1 Hashpipe整体框架Fig.1 Hashpipe overall framework
Hashpipe核心是灵活的环形缓冲区,模拟连续内存块,并实现数据在多个线程之间的流转和共享,利用中央处理器控制启动和关闭等操作,通过环形缓冲区暂存并传递数据包,保证数据快速捕获并按正确的顺序分发。
Hashpipe将任务传输到单独的线程中,线程之间共享内存缓冲区,并通过信号量机制控制任务,实现线程间互斥。Hashpipe定义数据接收、处理、输出3个线程,各个线程实现各自的任务。数据接收线程net_thread接收来自计算机万兆网卡的高速网络数据包,根据数据包格式提取文件头和有效数据并解析包头。来自现场可编程门阵列的数据包都有时间戳,如果无序到达,可以重新排列为适当的时间序列,并将数据写入第1个输入数据缓冲区,一旦连续的数据块写满,该块将交由下一个线程处理[14]。处理线程gpu_thread从输入数据缓冲区获取数据,传输至图形处理器执行复杂计算,然后将结果写入输出数据缓冲区。输出线程output_thread从输出数据缓冲区获取数据,写入文件存储在磁盘上。Hashpipe通过定义监控线程监听来自现场可编程门阵列的UDP数据包,通过转置线程重新格式化数据,使时间样本在内存中正确对齐。
后端用C/C++语言编写,头文件中定义多个结构体变量以便调用,定义数据缓冲区hashpipe_databuf,包含需传输的数据类型、缓冲区空间的大小、缓冲区ID、数据存储块数、块ID等基本信息。hashpipe_thread_desc结构用于存储描述Hashpipe线程的元数据;hashpipe_udp_params结构体用于保存网络连接参数,包括端口号、IP、数据包的大小等信息。hashpipe_clean_shmem()函数用于释放状态缓冲区的占用空间;hashpipe_status_unlock_safe()和hashpipe_status_lock_safe()函数用于状态缓冲区的线程安全锁或解锁,确保状态缓冲区处于锁定状态。根据实际需求调用Hashpipe已有函数,可以满足数据传输需求。
界面监控采用David Macmahon编写的ruby程序rb-Hashpipe,作为Hashpipe的可视化前端,可以展示数据包接收、线程状态和缓冲区状态等信息,在更高级别将管道抽象以提供简洁直观的界面监控数据。Hashpipe及rb-Hashpipe均可部署在服务器平台上,环境配置主要步骤如下:
(1)更新GNU系列工具到最新版本,提供Hashpipe编译环境;
(2)安装Ruby管理器rvm;
(3)使用RubyGems更新所需的库文件;
(4)获取Hashpipe版本信息并安装;
(5)配置gnome终端在shell下启动。
数据传输监控界面如图2。
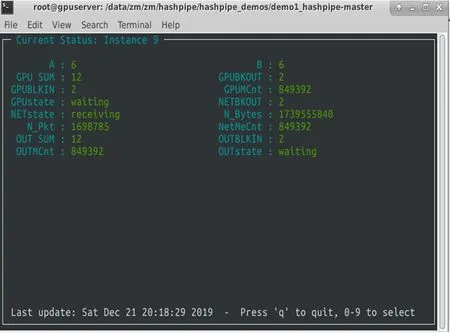
图2 数据传输监控界面Fig.2 Data transmission monitoring interface
1.3 PSRDADA
PSRDADA由澳大利亚斯威本科技大学开发维护,支持脉冲星信号分布式采集和数据分析,主要用于脉冲星基带数据记录和处理,管理从模数转换器采样到图形处理器集群的数据,分析整个过程的数据流。PSRDADA可实现APSR,BPSR和CASPSR基带记录数据分发、管理和监控,现阶段主要应用于澳大利亚帕克斯望远镜的ASPSR,BPSR,CASPSR和HIPSR[15]终端系统。
从基础层次来看,PSRDADA是一个灵活易管理的环形缓冲区,核心功能是在环形缓冲区之间传递数据流。每个缓冲区划分为描述文件信息的文件头存储块,以及多个存储数据的子块,接收数据时按顺序写入子块,当一个子块填满时,触发标志位,表示子块中的数据可以读取。环形缓冲区可以实现数据集的出队和入队,多个数据集利用多线程并行在多个环形缓冲区排队,主要通过共享内存、信号量机制进行线程之间互斥通信。在高级别配置中,PSRDADA配置可以在集群中各节点启动,通过可视化界面监控相关流程,管理数据的传输和归档。
PSRDADA基于模块化设计实现,包括用于执行特定任务的独立进程,整齐分离数据传输、命令、控制指令和数据分析等不同操作;创建环形缓冲区,实现进程之间的数据传输;配置文件、脚本等,完成分布式工作流程中各种基础配置;基于网络的用户接口,提供基于网络浏览器的监控界面,并通过gridbus发送到远程计算设备,实现远程监控。
PSRDADA基于C语言实现了针对APSR, BPSR, CASPSR和PUMA2不同设备的相应开发,通过多命令行执行:dada_db可以创建或删除一个缓冲区;dada_dbmonitor监控已开辟的缓冲区;dada_dbdisk命令实现数据从缓冲区写入本地磁盘;dada_header获取数据文件头信息;dada_dbcopydb,dada_dbdisk和dada_diskdb实现缓冲区与缓冲区及缓冲区与磁盘间的数据拷贝等。
PSRDADA配置与基本使用步骤如下:
(1)安装或更新PSRDADA需要的GNU工具autoconf(2.59及以上版本),automake(1.9.3及以上版本),libtool(1.5.8及以上版本)和m4(1.4及以上版本);
(2)获取dada格式的数据;
缓冲区创建及数据传输情况如图3,dada_db命令开辟共享内存键为100的缓冲区结构,包括4个大小为524 288 bytes的数据存储缓冲区,总容量为2 MB;8个大小为4 096 bytes的文件头存储缓冲区,总容量为32 KB。dada_dbmonitor命令打开监控界面,实现对文件头和数据缓冲区读写状态的监控。
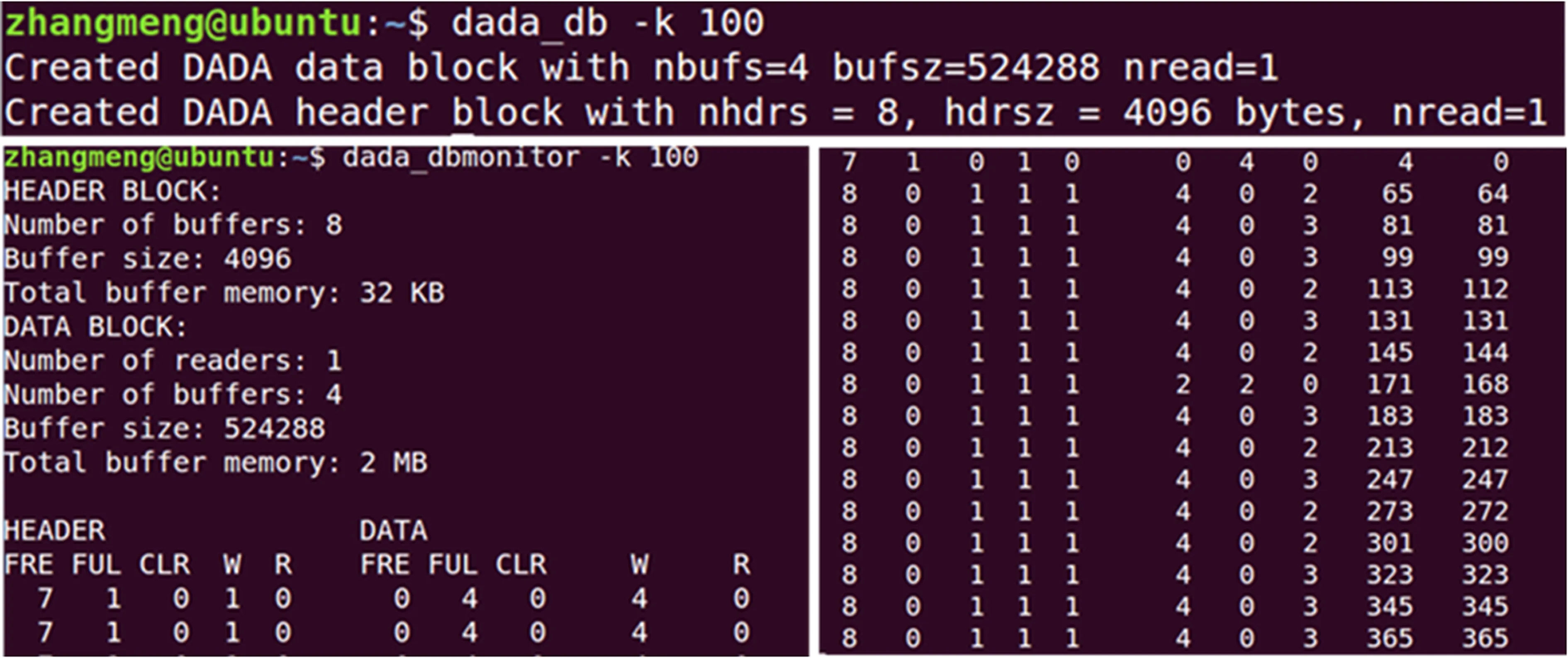
图3 PSRDADA创建数据缓冲区Fig.3 PSRDADA create data buffers
1.4 Bifrost
Bifrost专门用于射电天文数字信号处理,实现流数据处理高性能管道的快速开发,用于中央处理器与图形处理器之间数据的高效传输。现阶段Bifrost用于处理长波阵列的数据,实现在波束合成、相关器上的应用[16]。
Bifrost利用Python实现了高级管道接口,可用于数据传输;利用C++实现支持图形处理器的高性能后端,包括一系列与天文数据处理相关的高性能数据结构和算法,为干涉测量、脉冲星消色散、计时及瞬态信号搜寻等应用而设计的库函数,用于中央处理器和图形处理器上数据计算与处理[17]。其中接口和函数都称为块,通过灵活的环形缓冲区可以同时实现多个块之间的通信,同时执行多线程,使得块可以异步操作。数据块主要有3种类型:(1)tasks从环中读取数据,并实现数据转换,将结果写入输出环形缓冲区;(2)source从文件或以太网数据流的管道外获取数据,将数据写入输出缓冲区;(3)sink可以直接从输入环形缓冲区读取数据并绘制数据的块,或将其写入文件。
Bifrost安装步骤简洁,适合快速部署,安装完成后,通过import bifrost实现模块调用。例如bifrost.pipeline构建管道,创建环形缓冲区;pipeline.run是语句执行管道,为每个块创建一个线程;通过bifrost.blocks加载功能块,调用快速傅里叶变换(Fast Fourier Transform, FFT)、快速色散测量变换(Fast Dispersion Measure Transform, FDMT)、量化、转置等实现数据处理;网络相关模块bifrost.udp用于捕获UDP数据包,可统计并分析包传输信息。如果数据流传输过程中需要一些中间操作,用户可自定义模块。
以wav格式的声音文件为例,Bifrost执行步骤一般为
(1)读取.wav格式的文件;
(2)将原始数据拷贝到图形处理器;
(3)将时间轴分割成小块,对新生成的小块执行快速傅里叶变换;
(4)取这些FFT模的平方;
(5)将数据转置为sigproc兼容的格式,进行标准化;
(6)将数据拷贝到中央处理器;
(7)将数据转换为整数型,并以filterbank格式存储。
1.5 Kotekan
Kotekan是Andre Recnik使用C/C++组合开发的软件框架,主要用于射电天文望远镜数据传输,最早为CHIME后端应用开发,旨在实现更高的效率和吞吐量[18]。
Kotekan管道是模块化的,由一系列对数据执行不同操作的单元组成,实现了实时管理X引擎的数据流,包括接收来自F引擎的UDP数据包,图形处理器节点内数据流实时处理及结果存储。核心结构是先进先出(First In First Out, FIFO)环形缓冲区,通过系统内存的环形缓冲区实现中央处理器与AMD GPU之间通信,及传输到图形处理器进行处理之前数据检查和暂存[19]。
Kotekan创建网络线程、GPU线程、GPU回调线程、GPU后处理线程和输出线程。每个线程与一个或多个环形缓冲区对象的接口关联,接收的数据均通过环形缓冲区暂存,实现边读边写。这些线程和缓冲区形成了如图4的数据路径,管道可以多线程并行地产生多个结果数据集[20]。

图4 Kotekan中数据流Fig.4 Data flow in Kotekan
缓冲数据由Kotekan::stage处理模块写入和读取,从网络或外部设备获取数据,通过数据处理算法实现数据操作,最后将处理后的数据通过网络传输或存储在本地。
1.6 Pelican
Pelican[21]是由牛津电子中心开发的实时数据流处理框架,具有高效、模块化、轻量级、可校准的特点,主要应用于LOFAR和BEST-II,通过图形处理器对数据进行并行处理。Pelican提供了高度抽象的应用程序接口(Application Programming Interface, API),适合用于静态、准实时处理。
Pelican用C++实现了可重用的模块化组件,将数据获取和处理分离,具有灵活性和通用性,具备读取UDP数据的机制,将数据流传递给各计算服务器,完成数据缓冲、处理和文件写入。Pelican可对望远镜接收数据进行实时处理,也可用于任何需要处理传入数据流的应用程序。
Pelican可用于脉冲星搜寻的数据预处理。平方公里阵列(Square Kilometre Array, SKA)早期计划使用Pelican处理非成图的基于图形处理器实时射电脉冲检测,流程如图5。首先通过软件服务器读取UDP数据,去除窄带频谱干扰的峰值,实现图形处理器中进一步窄带划分,完成复杂数据到功率数据的转换,将数据传输至图形处理器模块执行分散搜索算法。
短时间内成像导致相关器输出速率非常大,为了提高数据传输速率并产生更新的校准系数,系统需对输出数据流进行实时处理。Pelican可用于射电望远镜数据转换成科学图像之前的数据校准和成像方程求解。Pelican实现科学成像的框架如图6。系统接收来自ROACH2的子带数据,通过实时更新相关器的相位和振幅系数,提供初始校准,然后基于图形处理器的2D-FFT生成脏图,洁化后执行基于特定步长的图像差分比较,阈值检测器用来发现瞬态事件,最后用堆叠模块形成一个高动态范围的图像[22]。

图6 Pelican实现成像框架Fig.6 Pelican realized imaging framework
1.7 Cobalt
Cobalt是基于图形处理器设计开发的LOFAR望远镜软件相关器和波束形成器[23]。软件部分实现了数据管道,用于管理通过网络和中央处理器、图形处理器的数据流,并完成数据存储。
图7为从外部系统到Cobalt内部数据流示意图。接收的数据存入输入缓冲区,完成子带处理后进行存储,模块间以all-to-all模式通信。

图7 Cobalt数据流示意图Fig.7 Cobalt data flow
Cobalt由几个交互子系统组成,管理来自网络的数据流,实现高速率、可持续数据传输,持久性存储数据,并进行控制、监控、记录日志和元数据。图8显示了Cobalt的组件依赖关系和数据流。Cobalt处理大量独立的数据流,每个AntennaFieldInput接收10 GbE端口的UDP数据包,并将有效数据转发到TransposeSender,通过环形缓冲区移动整数倍,执行延迟补偿。这些数据流在没有相互依赖的情况下结合信息传递接口(Message Passing Interface, MPI)实现并行处理,图形处理器上的信号处理管道GPUpipeline包含TransposeReceiver组件,传输子带数据,与MPI_Isend和MPI_Irecv非阻塞发送和接收相结合,传输相关或波束数据。输出组件接收图形处理器子带数据,最终使用casacore以MeasurementSet或HDF5格式存储[24]。
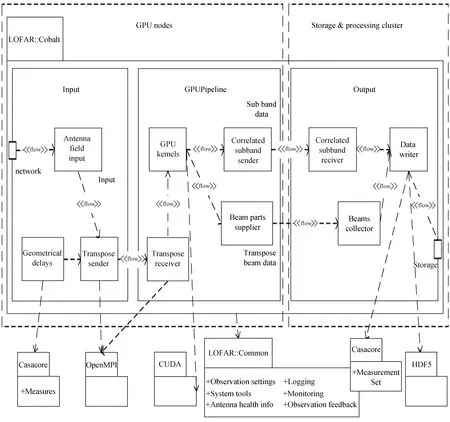
图8 Cobalt组件依赖关系和数据流Fig.8 Cobalt component dependencies and data flow
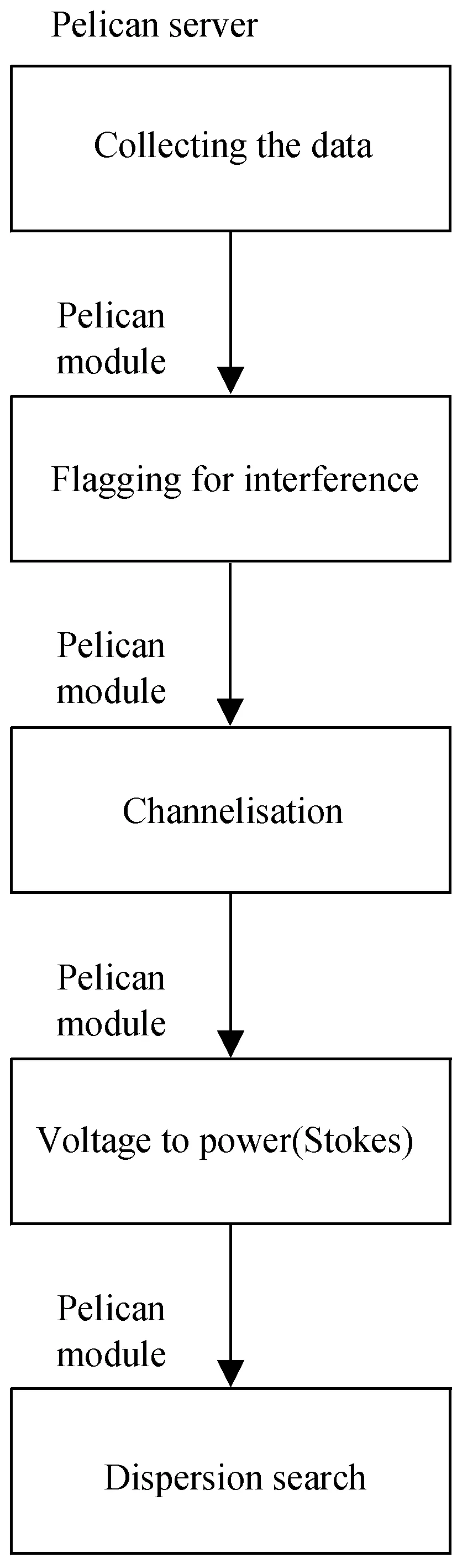
图5 平方公里阵列计划利用Pelican实现数据处理流程
Cobalt可以处理离线任务,包括自动标记、校准、平均、脉冲星数据相干消色散和动态光谱产生以及脉冲星数据在线折叠和搜索。Cobalt具备可扩展性,如子阵列并行观测、中断响应以及其他的观测模式。在网络带宽和计算能力方面,Cobalt提供了额外容量,效率显著提高,例如低波段天线和高波段天线的并行观测。一般来说,相关器只能处理单个项目的数据,Cobalt因拥有巨大的计算和吞吐能力,可以同时处理多个项目数据。
目前已有更新版本Cobalt 2.0,具备更好的灵活性和吞吐量,接收数据量速率超过1 TB/s,更大限度地利用图形处理器的优势,实现高性能计算和数据实时处理。
2 面临的问题
现阶段数据流管道软件面临的重点与难点:
(1)现有射电天文数据流管道软件均为特定观测设备设计,为满足特定需求开发,并不适用于所有类型的观测设备及观测模式。针对具体观测设备,应根据各观测设备的接收系统需求来实现相应的软件功能。部分软件系统虽然可移植到不同的观测设备终端,使用时并不需要其全部功能,需要深入研究底层代码,完成二次开发及调试,开发成本高、难度大。
(2)已有大型射电望远镜终端系统多采用基于Xilinx FPGA的ROACH系列、SNAP系列硬件板卡,近几年推出了集成度更高的RFSoC,可提供高速以太网数据传输接口,对服务器端数据流实时接收能力提出了更高的要求。部署在服务器端的管道需要满足基于RFSoC平台更高带宽的数据接收需求,提高数据的传输效率。
(3)数据实时高效传输与处理能力是管道软件性能提高的方向。数据处理平台多采用图形处理器集群实现大规模数据处理,然而数据分发与收集并没有得到有效的处理,高效实现数据流在多图形处理器上的分发与汇总,将大大提高传输与计算效率。
(4)为满足多功能数字终端系统的数据处理要求,应形成一套配置灵活的系统软件,构建的管道软件应实现数据处理与分析所需算法,针对不同观测模式提供可调用的类库,满足多观测课题的需求。
3 大口径射电望远镜数据流管道软件设计思路
应用于大口径射电望远镜数据流传输与处理的管道软件,作为多功能终端系统软件中重要的组成部分,将完成数据流获取、传输、管理与监控;高效捕获并暂存来自现场可编程门阵列的网络数据包,实现数据在中央处理器与图形处理器之间高速流转及相关处理;提供图形处理器内部数据处理算法调用,实现原始数据格式到标准文件格式的转换及数据类型的匹配,最终将数据高效写入磁盘存储。
3.1 基于零拷贝和环形缓冲区的数据传输
110 m射电望远镜多功能数字终端采用现场可编程门阵列+图形处理器集群架构模式,如图9[25]。RFSoC实现数据采样和预处理,单块RFSoC芯片可实现8通道,每通道最大采样速率为4.096 GSPS,12 bit采样,采样后每通道的数据量约为48 Gbps。经过RFSoC预处理将采样数据划分成多个子带,利用RFSoC提供100 GB的数据传输接口,通过高速以太网传输至图形处理器集群,实现数据相关并进行数据预处理。

图9 110 m射电望远镜终端系统框架Fig.9 The block diagram of QTT backend system
网络数据传输使用UDP协议,网卡缓冲区的数据通过Linux内核协议栈传输至用户应用程序,数据包在内核态与用户态之间拷贝,系统消耗大且存在传输瓶颈。为了有效降低系统资源占用,实现图形处理器服务器端传输的低丢包率和低延迟需求,图形处理器服务器端可基于零拷贝技术实现高输入输出环境下的高性能数据获取。标准数据传输与零拷贝数据传输对比如图10。管道软件实现基于零拷贝的数据传输模块,创建并行网络输入线程,在用户态以轮询方式读取网卡缓冲区中的数据包,实时写入动态创建的环形缓冲区,避免以标准内核协议栈方式处理,减少网卡到管道软件过程中的数据拷贝次数,以提高数据访问效率。

图10 标准数据传输与零拷贝数据传输Fig.10 Standard data transfer and zero-copy data transfer
3.2 基于图形处理器集群的数据实时处理
基于混合架构的110 m射电望远镜多功能终端系统计划实现脉冲星、暂现源、分子谱线、总功率、甚长基线干涉测量(Very Long Baseline Interferometry, VLBI)、基带数据等多种观测模式。图形处理器集群内部数据流如图11,现场可编程门阵列预处理后的数据传输至图形处理器集群,实现数据处理。数据流经解码、射频干扰消减后,针对不同观测模式完成相应处理,并最终以VDIF,PSRDada或PSRFITS等格式存储。
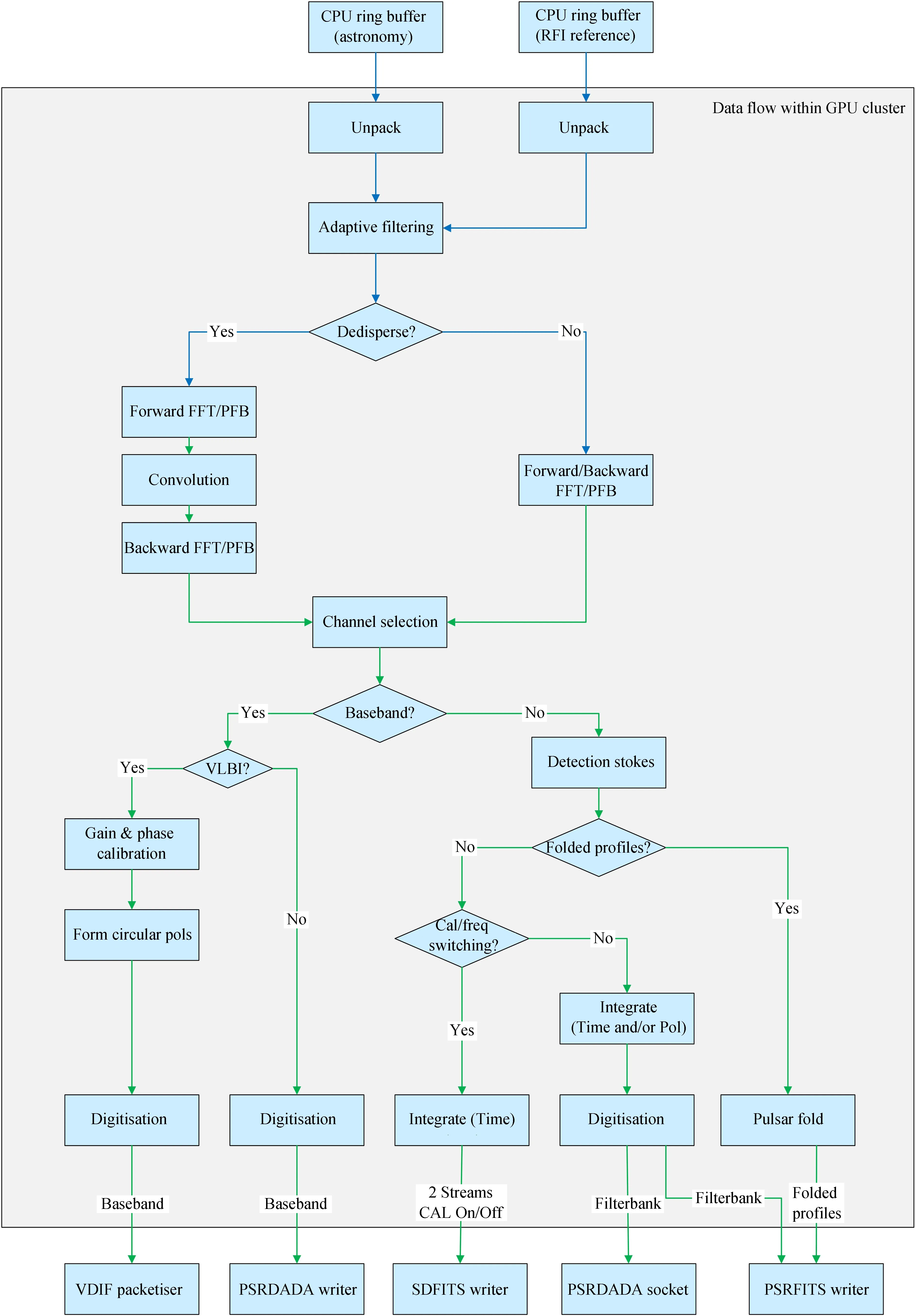
图11 110 m射电望远镜多功能数字终端图形处理器集群内部数据流Fig.11 QTT multifunctional digital backend GPU cluster internal data flow
管道软件应提供图形处理器内部数据处理模块,用甚长基线干涉测量技术充分整合天文学算法,实现解码、射频干扰识别、校准、折叠、标准格式输出等常用功能,实现标准文件格式的转换及数据类型的匹配。基于网络提供友好的访问界面,以模块化的方式实现更好的灵活性并支持扩展,提供用户自定义模块功能,允许用户根据实际需求调用模块或编写自定义模块。
针对110 m射电望远镜多功能数字终端数据流,数据传输流程如图12。网络线程捕获来自RFSoC的数据并存储至输入数据环形缓冲区,管道软件运行在多台图形处理器服务器上,每台甚长基线干涉测量服务器接收一个频率通道子带。为实现图形处理器集群上多线程并行和分布式执行,高效及时运行和数据块转发,集群节点中结合MPI实现数据的分发和获取,采用MPI提供的非阻塞消息接收与发送调用接口MPI_Isend和MPI_Irecv,实现计算和通信重叠进行,提高数据处理效率。图形处理器集群处理后的数据暂存于输出数据缓冲区,并通过并行输出线程传输至存储系统。

图12 数据传输流程图Fig.12 Data transmission flowchart
3.3 基于BeeGFS的数据存储
随着数据量的迅速增加,高性能计算系统需要更复杂、更高效的方法管理和存储大量数据。分布式文件系统将数据分布到众多存储设备上,对数据进行分布式存储和管理,实现分布式读写。借助并行分布式文件系统BeeGFS[26]构建更高效的数据存储后端,提高输入输出性能,实现数据存储后端的高性能和可扩展性。
基于BeeGFS的数据存储系统整体框架如图13。图形处理器集群处理过的数据整合后封装成特定的格式,通过构建并行输出管理线程同时传输一个或者多个数据流,相同格式的数据写入同一环形缓冲区,传输至文件存储系统,通过BeeGFS提供的Client读写数据,利用多个独立I/O实现高并发读写。基于BeeGFS分布式文件系统实现元数据分离,MDS和OSS的本地文件系统分别承载元数据和数据的存储,其中文件头中包含的日期时间、观测环境参数等观测信息,作为元数据信息的主要组成部分,存储于元数据服务器。MDS,OSS以及Client的扩展性使得基于BeeGFS的数据存储系统能够满足大规模数据存储扩展的需求。

图13 基于BeeGFS的数据存储系统Fig.13 Data storage system based on BeeGFS
4 结 语
射电天文望远镜数字终端系统越来越依赖实时处理来克服数据存储和分析的瓶颈,天文领域已经开发并研究了数据流处理管道,用于提高数据传输和处理的效率,简化数据处理代码开发难度。本文综述了现有射电天文数据传输管道软件,介绍了射电天文数据传输管道软件的结构、功能,并在图形处理器服务器上进行了测试。在总结现有管道软件的基础上,本文给出了未来大口径射电望远镜多功能终端系统应根据实际观测需求设计数据传输管道的一般思路。未来多功能数字终端系统基于现场可编程门阵列+图形处理器实现,应该向易升级、改造、灵活、可扩展的方向发展。
致谢:本文得到中国虚拟天文台、国家天文科学数据中心、中国科学院科学数据中心体系提供的数据资源和技术支持。
猜你喜欢
航空学报(2022年7期)2022-09-05
军事文摘(2022年12期)2022-07-13
儿童故事画报·自然探秘(2022年6期)2022-07-05
军事文摘(2021年22期)2022-01-18
汽车维修与保养(2020年10期)2021-01-22
汽车维修与保养(2020年11期)2020-06-09
计算机技术与发展(2020年5期)2020-05-22
中国新通信(2017年3期)2017-03-11
太空探索(2016年9期)2016-07-12
时代人物(2014年10期)2015-01-28
