
基于RFE+CatBoost模型的异常用电检测方法研究
2021-10-21 08:18:48李英娜刘爱莲
电视技术 2021年8期
冉 哲,李英娜*,刘爱莲
(1.昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2.云南省计算机技术应用重点实验室,云南 昆明 650500)
0 引 言
随着社会经济的快速发展,近年来,供电企业数据平台不断发展,用电信息采集系统不断完善,不断累积大量的可供分析的信息。用电信息不仅是企业向用户收取电费的主要依据,而且能提供大量有价值的信息,以供分析人员从中获取信息进行分析,从而对电力系统以及用电企业进行更好的改良和指导。
对于供电企业的用电监察工作来说,利用数据挖掘技术对用电采集信息进行分析,从数据中挖掘用户用电规律,结合机器学习[1]和深度学习等技术,构造异常用电行为识别模型,识别异常用电行为,以便稽查人员及时发现异常用电行为[2],更快地采取应对行动,对于企业降低管理运营成本、提升经济效益、更好地指导电力消费行为以及优化电网的运行具有非常重大的意义。
目前在异常用电行为检测与识别领域,针对电力数据的特性,对于没有明确指明是否存在异常用电的数据,采用无监督学习的方法[3],庄池杰等人在缺乏异常用电数据样本的情况下,分析样本与总体之间的关系,找出离群对象,采用特征提取方法、主成分分析(PCA)、网格处理技术以及计算局部离群因子等模块,只需检测异常度排序靠前的少数用户即可查出大部分异常用户[4]。龚刚军等人针对用电行为最佳聚类数目选择问题,在特征优选策略基础上提出了基于准确度和有效度的聚类优选策略,通过综合考虑准确度评价指标和有效度评价指标确定最佳聚类数目[5],以达到更好的聚类效果[6]。对于明确标明异常用电[7]的数据,采用有监督学习或者半监督学习的方法,程超鹏等人提取用户用电特征后,采用四种相异模型构建Stacking集成模型,提升用电异常识别的准确性,针对单一模型识别率不高的问题做出了改进和提升[8]。赵文清等人利用深度学习框架,基于长短期记忆特征提取网络,构建异常用电识别模型[9]。徐瑶等人提出一种GNN-GSSVM的用户异常用电识别模型,采用卷积神经网络提取用户特征,然后通过SVM检测异常用电行为[10]。上述方法多没有考虑到异常用电样本中特征选取对模型识别准确度影响的问题,样本差异对于最后构建的模型的识别效果有着很大的影响,大部分模型构建趋于复杂化,所提取的特征与实际用户用电行为习惯不一定具有相关性。最后虽能达到较好的识别准确率,但在识别时间和识别难度上较为复杂。
鉴于此,本文提出一种基于递归特征消除(Recursive Feature Elimination,RFE)和CatBoost相结合的异常识别模型。首先根据用电采集系统采集的数据,从中提取电能特征,其次构建特征矩阵,采用递归特征消除方法选取有利于模型的最佳特征,利用CatBoost模型进行异常用电的识别[11],最后利用所得模型对云南某地真实用电数据集进行验证,证明所提模型的有效性。
1 算法理论介绍
1.1 Boosting算法
Boosting算法是集成算法的代表,它通过将一些基分类器组合起来得到分类性能较强、针对特定问题能够有很好解决效果的模型。首先用初始权重训练出一个基分类器,以基分类器的学习误差率作为更新训练样本的权重的依据,调高学习误差表现率高的训练样本点的权重,使这些误差表现率高的点在之后的基分类器的学习中得到更多的重视。其次,基于调整权重后的训练集来训练下一个基分类器。重复进行上述步骤,直到基分类器数目达到指定的数目。最后将这些基分类器通过集合策略进行整合,得到最终的强分类器。Boosting算法的原理如图1所示。
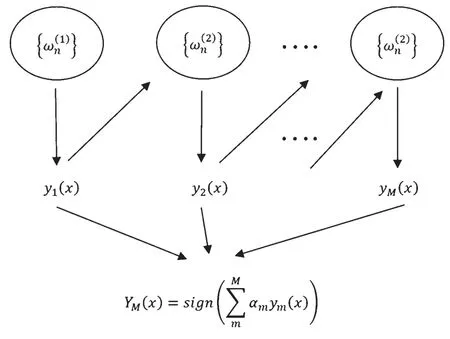
图1 Boosting原理图
在图1中,n个训练样本在初始状态下为每一个训练样本赋上权重ωn(i)(1≤i≤n),在训练迭代的过程中,每次训练得到的结果会根据上一次基学习器ym(1≤m≤M)的情况进行调整,重复训练之后直到基学习器的数量达到M,最后每个基学习器结合之后得到Boosting的数学模型:
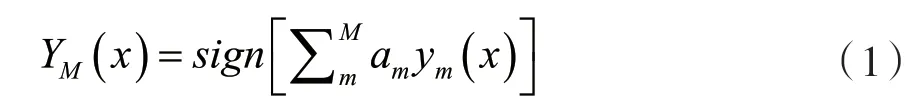
1.2 梯度提升算法
梯度提升算法(Gradient descend boosting)是一种基于Boosting算法的代表性算法之一,它通过对弱预测模型的集成产生预测模型,组合为一个强学习器。在梯度提升的每个阶段m,(1≤m≤M),假设已经有一个不太完美的模型Fm,通过在模型Fm上增加一个新的估计量h得到一个更好的模型:
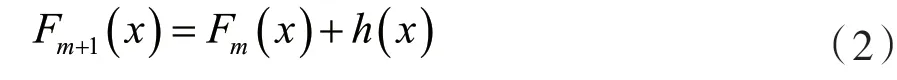
为了求得h的值,梯度提升算法基于以下作为观察:一个完美的h可以预测当前此模型的残差,满足:
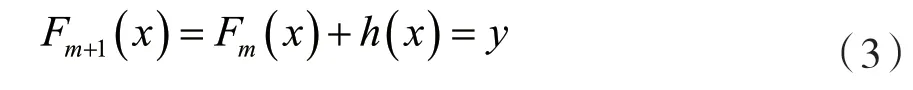
等效的式子有:

梯度提升通过拟合残差y-Fm(x)得到h。与其他提升方法的改进方法一样,Fm+1通过纠正Fm的误差逐渐达到想要的效果。模型的残差y-Fm(x)就是损失函数关于F(x)的负梯度。所以梯度提升思想在算法上的表现可以代入除了均方损失之外的不同的损失函数,以得到不同的梯度。在有监督学习问题中,一个输出变量y和一个输入变量x通过联合概率分布P(x, y)描述。给定训练集{(x1, y1),(x2, y2),…,(xn, yn)},旨在在所有具有给定形式的函数F(x)中找到一个F^(x)使得损失函数L[y,F(x)]的期望值最小:
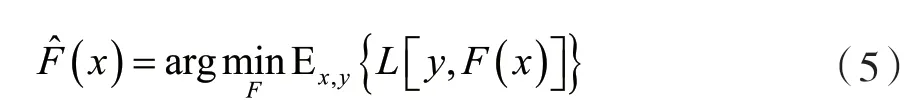
梯度提升方法通过某一类H中基学习器hi(x)带权重和的形式来表示对实值变量y做出估计的F^(x):
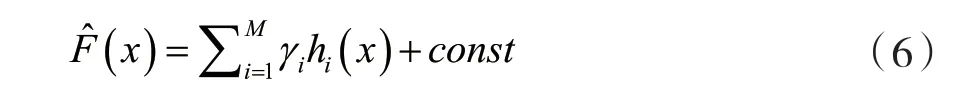
根据经验风险最小化原理,此方法的目的是找到一个近似F^(x)可以最大程度减少训练集上损失函数的平均值,从一个由常数函数组成的模型F0(x)开始,以贪心的方式逐步扩展:
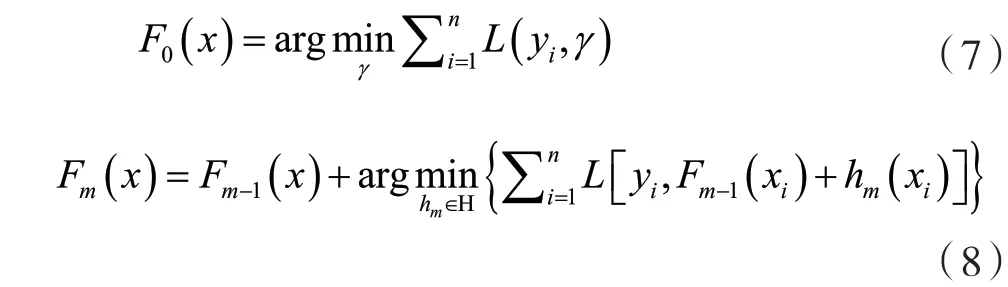
式中:hm∈H是基学习器。
通常,在每个步骤中为任意的损失函数L选择最佳函数h在计算上不可行,有以下优化方法。
对这个最小化问题,应用梯度下降步骤,如果考虑连续情况,即H是任意微分函数的集合',根据以下方程更新模型:
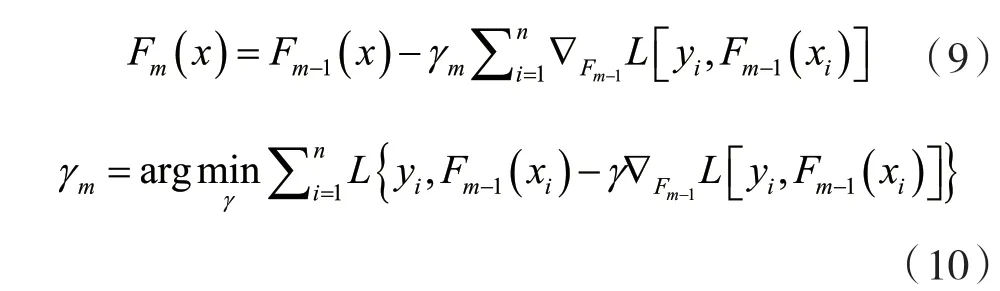
式中,对于i∈(1,…,m)是关于函数Fi求导,γm是步长。但是在离散情况下,即如果H是有限的,就选择最接近L梯度的候选函数h,然后根据上述等式通过线搜索来计算系数γ。
1.3 梯度增强树算法
梯度增强通常与固定大小的决策树(一般是CART树)一起作用于基学习器。对于这种特殊情况,Friedman提出了对梯度增强方法的改进,以提高每个基础学习者的适应质量。
第m步的通用梯度提升将适合决策树hm(x)拟合近似残差,Jm是叶子节点数。则模型树将空间分为Jm个不相交的区域R1m,…,Rjmm并预测每个区域的恒定值。利用指标函数I,对于输入x,输出hm(x)可以有以下和的形式:
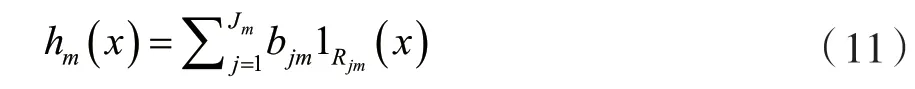
式中:bjm是区域Rjm的预测值。
系数bjm乘上某一值γm,通过线性搜索最小化损失函数得到该值,模型更新为:
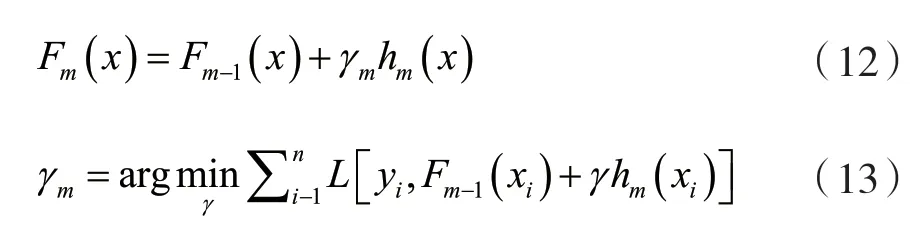
Friedman建议修改此算法,以便为每棵树的区域选择单独的最优值γmj,而不是单个γm。他称修改后的算法为“TreeBoost”。修改后,可以简单地舍弃来自树拟合过程的系数bjm,模型更新规则变为:
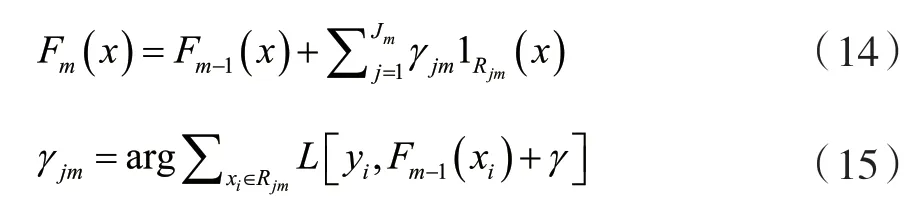
1.4 CatBoost算法
CatBoost由Categorical和Boosting组成,针对分类问题主要解决的重点是高效合理地处理类别型特征。此外,CatBoost着重解决预测偏差以及梯度偏差的问题,对减少过拟合的发生有很好的效果,准确性和泛化能力能得到较大提升[12]。传统Boosting算法计算的是平均数,而CatBoost在这方面采用其他算法做了改进优化,这些改进能更好地防止模型过拟合。CatBoost算法的目标是在处理GBDT特征中的Categorical features[13]时能达到更好的效果。在决策树算法中,标签的平均值作为节点分裂的标准,此方法被称为Greedy Target-based Statistics,用公式表达为:
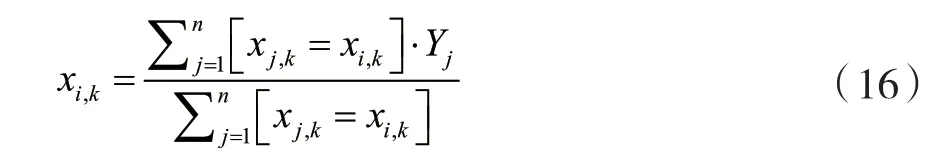
在式(16)的基础上添加先验分布项进行改进,可以减少低频数据以及噪声在数据分布上面的 影响:
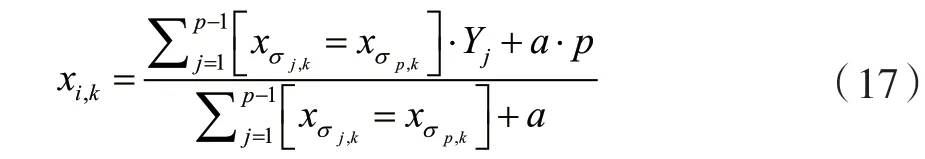
式中:p是添加的先验项,a通常是大于0的权重系数。
2 算例分析
2.1 数据来源
本文数据是采集自云南某地用户5个月用电在线监测数据集,在线监测数据每60 min采集一次,采集信息主要包括正向有功总电能、无功总电能,反向有功总电能、无功总电能,三相电压,三相电流(电表、表前、一次),三相有功功率,三相功率因数以及总功率因数等电参量。
2.2 数据处理与特征提取
在实际用电和采集用电信息的过程中,由于计量系统故障、人为干扰等因素,导致采集到的数据有很多缺失值、异常值。需要对这些数据进行剔除和筛选。对于缺失值达到30%的用户进行标记,经过筛查如果数据缺失值达到50%以上、没有特别进行标明的数据,按照计量系统异常处理进行剔除。数据经过筛选剔除处理后,最终剩余正常数据2 593条,异常数据537条。
针对数据中所提取的特征做相关性分析,得到的矩阵如图2所示。
由图2可以直观地看出所提各项特征之间存在的线性相关关系,可以得知部分特征的相关程度较高,表明这些特征包含了较多的重叠信息。通过递归特征消除可以进行特征筛选,消除原始变量之间的信息重叠。
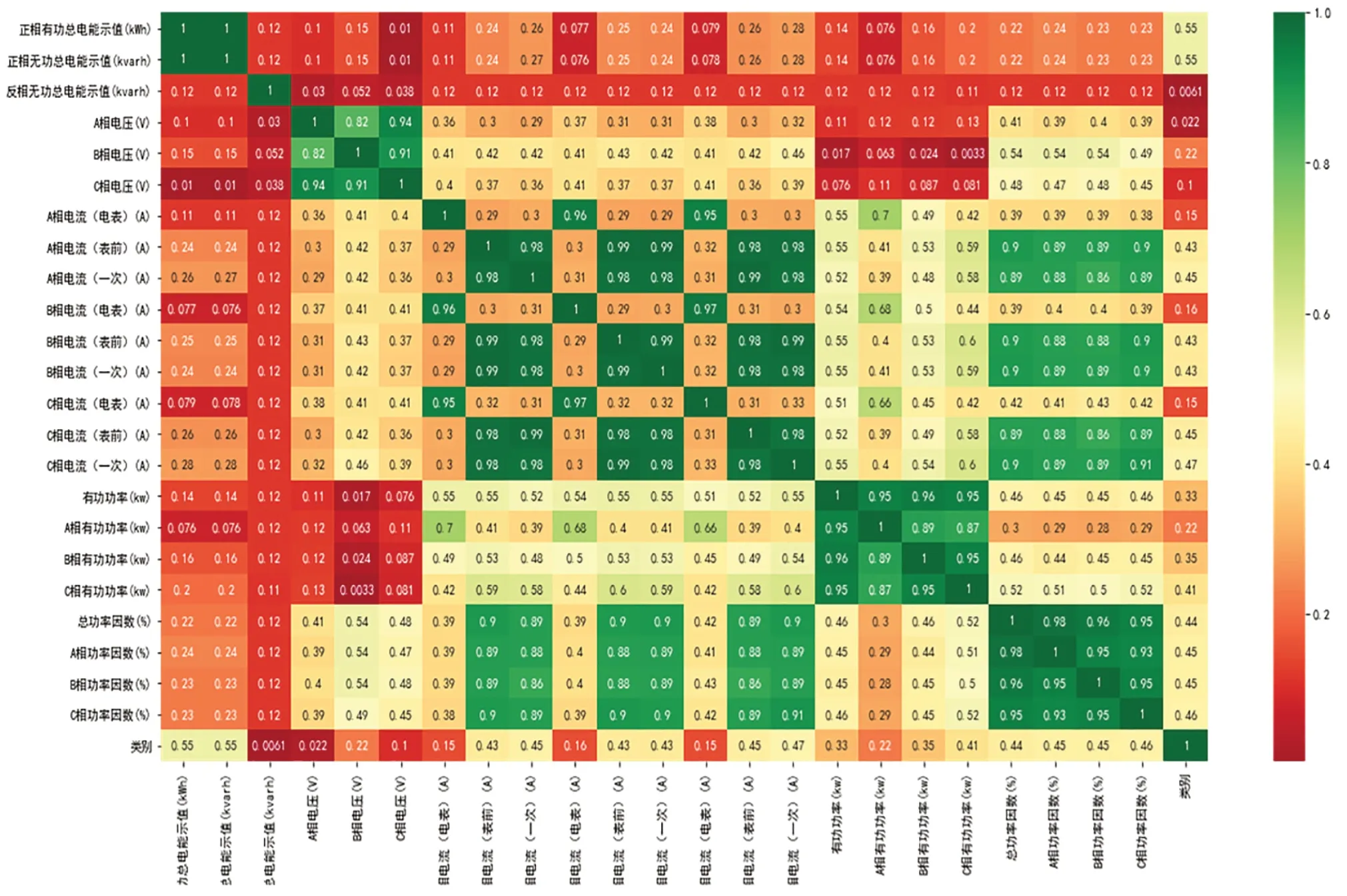
图2 特征集的相关矩阵
2.3 特征递归消除
特征递归消除[14]是一种基于wrapper包裹的型模式下的后向搜索算法,常用在特征选择[15]上面。特征递归消除方法使用一个机器学习模型来进行多轮训练,每一次训练结束后,就会消除若干权值系数所对应的特征,之后在新的特征集上面进行下一轮训练。重复该过程直至产生最优的特征子集。基本步骤如下:
(1)使用所有特征变量训练模型;
(2)计算每个特征变量的重要性并进行排序;
(3)对每一个变量子集s_{i},i=1,…,s,提取前 s_{i}个最重要的特征变量,基于新数据集训练模型,重新计算每个特征变量的重要性并进行排序;
(4)计算比较每个子集获得的模型的效果;(5)决定最优的特征变量子集;(6)选择最优变量集合集合的模型为最终模型。经特征递归消除后筛选出来的特征为正向有功总电能、三相电流(电表)、三相电压、有功功率以及总功率因数。特征指标如表1所示。这些特征从用电角度考虑也能全面反映用户用电情况,将上述特征数据作为模型的输入。
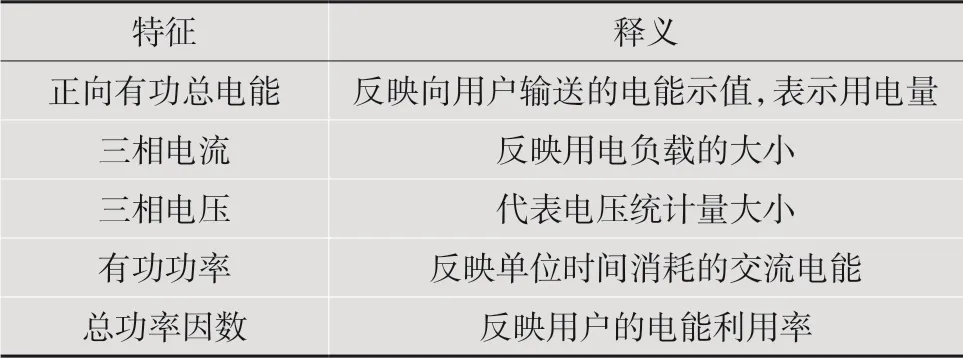
表1 用户用电特征指标
2.4 实验结果分析
将数据以7∶3的比例划分训练集和测试集。在本实验中,采用CatBoost算法的优势降低了对于超参数的依赖,无需进行过多的参数设置。为了验证本文提出的RFE+CatBoost模型的分类性能,将模型识别结果与随机森林(Random Forest)模型、逻辑回归(Logistic Regression)模型、XGBoost模型、LightGBM模型、SVM模型进行对比,针对用电特征属性,5种模型的调参结果如下:随机森林模型设置max_depth为15,max_leaf_nodes设置为2;LightGBM模型reg_lamba设置为0.9,max_depth设置为3,max_bin设置为3;XGBoost模型设置max_depth为3,reg_lamba设置为0.9;逻辑回归(Logic Regression)模型超参数设置max_iter为3;SVM模型则采用默认的超参数设置。
将所提取的用户特征集作为模型的输入,通过混淆矩阵(confusion matrix)、准确率(Accuracy)[16]、AUC(Area Under Curve)指数3个指标来评判不同检测模型的好坏,ROC曲线下的面积占比就是AUC值。AUC值越大,说明模型检测效果越好。AUC对比结果如图3~图8所示。
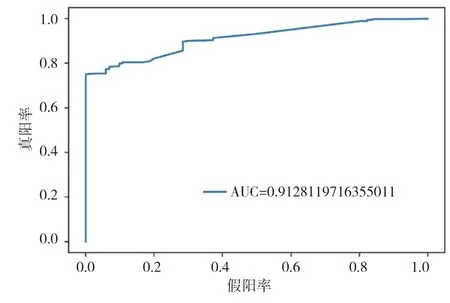
图3 Random Forest模型ROC曲线图
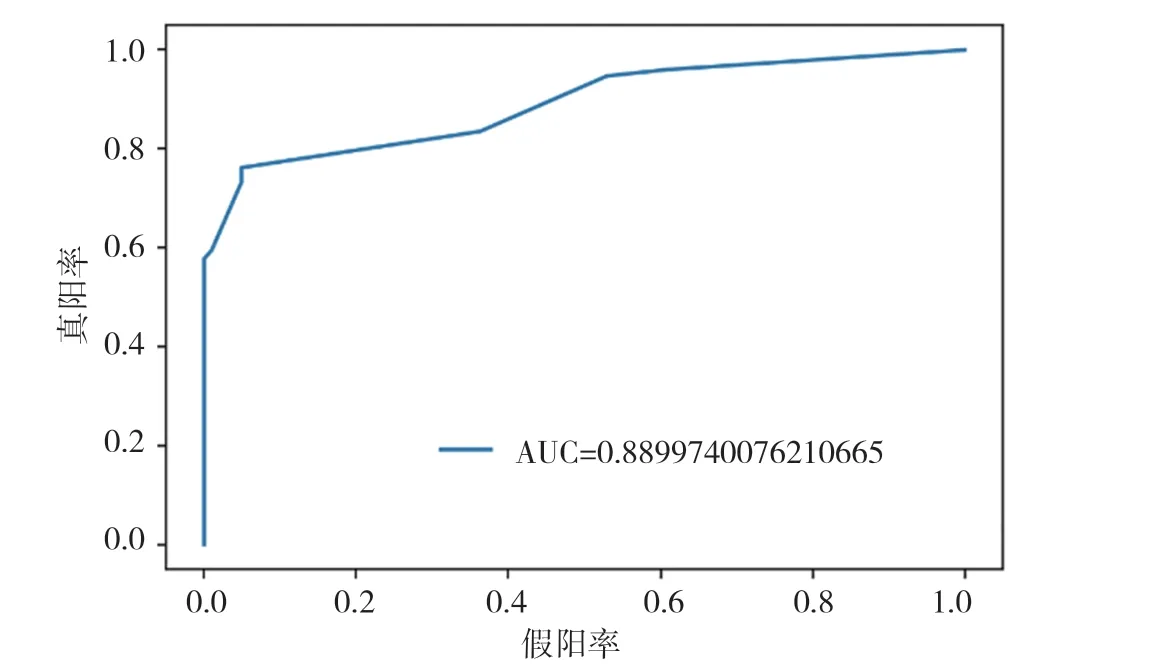
图4 LightGBM模型ROC曲线图
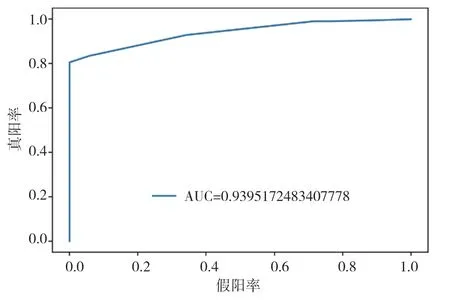
图5 XGBoost模型ROC曲线图
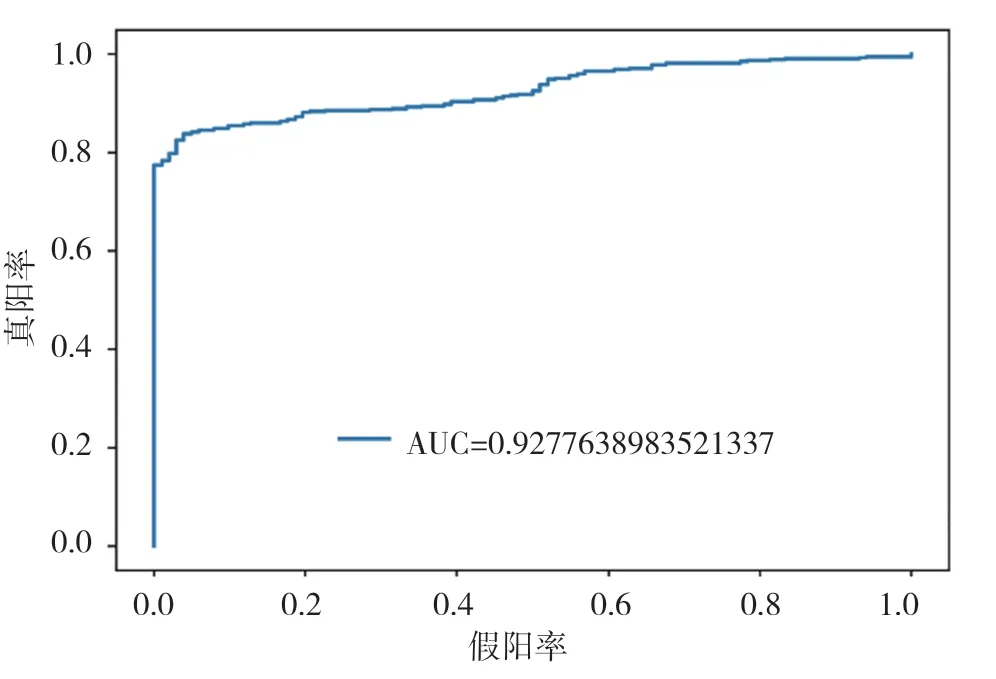
图6 SVM模型ROC曲线图
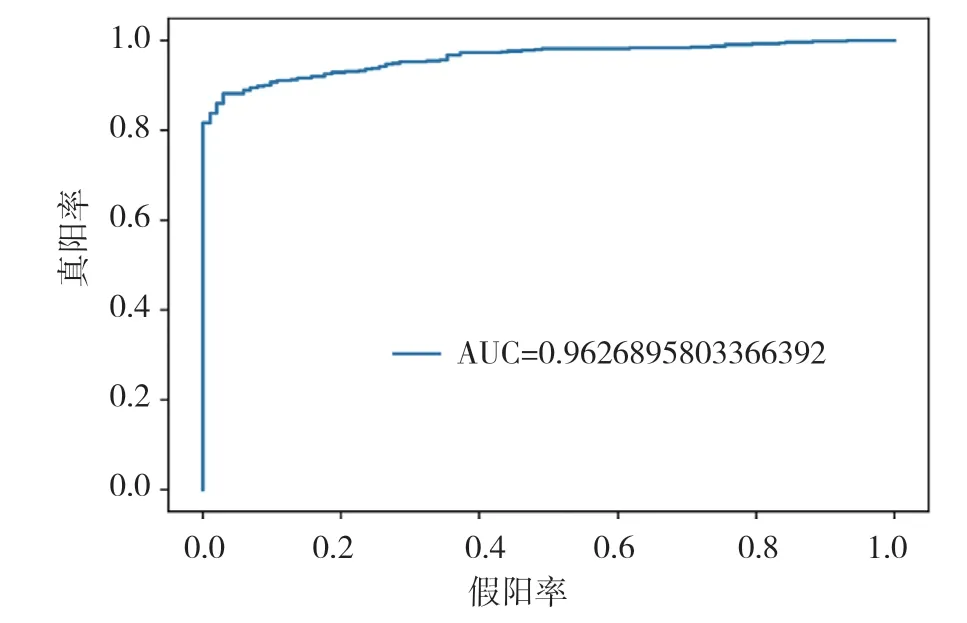
图8 CatBoost模型ROC曲线图
通过以上模型对比AUC值可知,识别效果最好的是CatBoost模型,AUC的值为96.3%,SVM算法、XGBoost算法、随机森林(Random Forest)算法也有较好的识别效果,AUC的值分别为92.8%,94.0%,91.3%。各个模型对比可知,CatBoost模型的AUC值要高于其他模型。
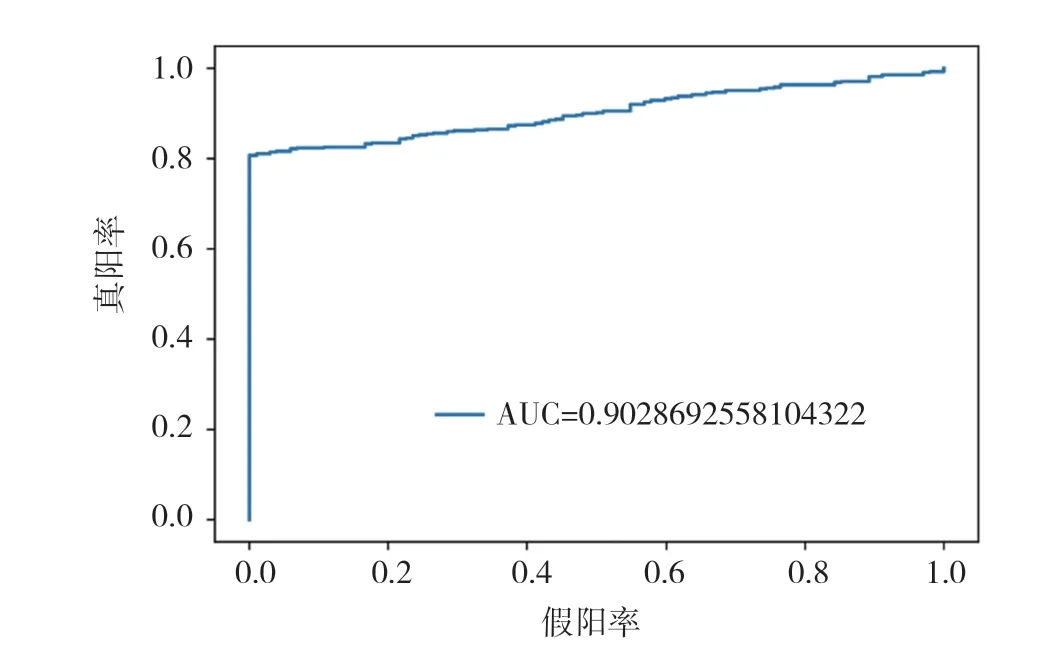
图7 Logistic Regression模型ROC曲线图
6种模型在用电特征集上的实验结果如表2 所示。
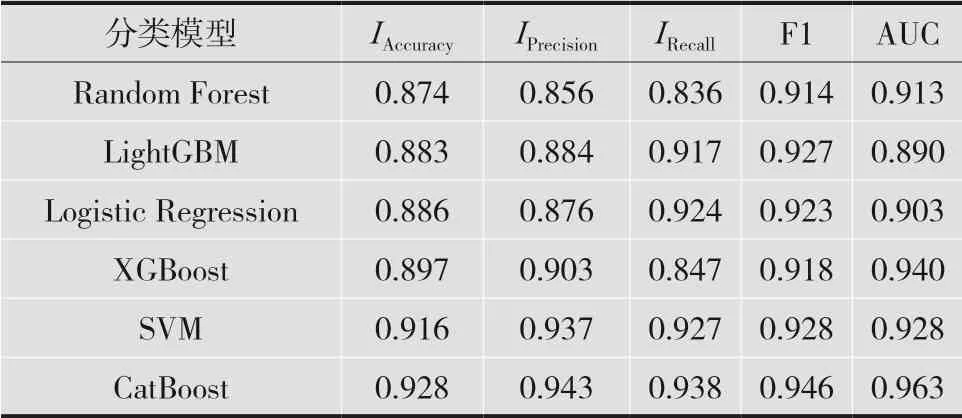
表2 各分类模型结果对比
由表2可知,相比于其他检测模型,特征优选后的CatBoost模型对于异常用电行为的识别率高达93%,在准确率、召回率、F1值上面的效果都要优于其他模型。LightGBM在F1值上面则要比逻辑回归模型和XGBoost模型要好。3种模型的召回率中,XGBoost最低,所以综合F1值来看,这3种模型中XGBoost的识别效果要更好,在分类方面有较强的数据挖掘能力。SVM模型的识别效果仅次于本文所提模型,与XGBoost模型相比也能有很好的识别效果。在准确率上SVM模型效果更好。XGBoost模型在AUC值上要好于SVM模型,也有很好的识别效果。总体来说,从各项评价指标来看,RFE+CatBoost模型对于异常用电具有很好的识别效果。
3 结 语
针对包含复杂统计量的用户侧历史用电数据,本文提出了一种经RFE特征优化后的CatBoost模型的异常用电识别,选取用户5个月的用电监测数据用于异常用电行为的识别,将预测结果与其他传统分类模型进行对比,通过实验验证所提方法的有效性,可得出如下结论。
将CatBoost算法应用于电力数据针对用户侧的异常检测领域,能够减少模型对于超参数的依赖,有效降低模型过拟合的几率,增强了算法的鲁棒性,针对于异常检测进行合理的特征筛选再经模型识别能够得到很好的准确率。
采用的样本数据为异常用电的小样本数据,所提模型能够胜任小样本异常用电数据,在样本数据不够多的情况下也能够有很好的识别效果。所提方法适用于复杂统计量的用电数据,有助于对各种类型异常用电数据进行很好的识别,以供电力企业稽查人员或分析人员识别检测异常用电。
在下一阶段的工作中,将针对异常用电行为的检测进行进一步的细分,通过划定阈值或者箱型图判定等方法,结合数据类型进一步精确识别异常用电,进而为电网电力监察工作提供更加可 靠的支持。
猜你喜欢
经营者(2023年10期)2023-11-02 13:24:48
数学物理学报(2021年6期)2021-12-21 06:24:38
中国化肥信息(2021年12期)2021-04-19 12:25:22
中学生数理化·中考版(2020年12期)2021-01-18 06:59:44
应用数学(2020年2期)2020-06-24 06:02:50
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:52
小学生必读(中年级版)(2018年10期)2019-01-04 05:11:10
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
