
基于双注意力机制的台风轨迹预测模型
2021-10-20 08:03贺琪刘东旭宋巍黄冬梅杜艳玲
海洋通报 2021年4期
贺琪,刘东旭,宋巍,黄冬梅,杜艳玲
(1.上海海洋大学 信息学院,上海 201306;2.上海电力大学,上海 200090)
台风是一种典型的热带天气系统,是海洋-大气相互作用的重要形式之一(张志伟,2019)。它严重威胁着沿海地区人民的生命财产安全和经济的发展。因此,及时地对台风轨迹进行预测可以为防灾部门提供有效的信息支持,从而减少人员伤亡和经济损失。然而影响台风轨迹的因素众多,如台风热力学、台风动力学和台风期间环境场等(黄小燕等,2013)。并且在台风登陆之后,台风轨迹还会受到陆地地形地貌,以及海岸线水深的影响(余锦华等,2012)。所以,台风轨迹预测是一个十分重要而又充满挑战的研究课题。
早期的台风轨迹预测主要依靠热力学和空气动力学对台风环境场进行分析,结合台风登陆点对沿海地区复杂的海岸线以及陆地地形地貌影响因素的分析,建立台风轨迹预测领域特有的经验法则(王瀚,2020)。然而这种主观经验法,效率低下,并且需要大量人力物力,预测的精度和时效性都难以满足需求。随着台风监测技术和计算机技术的发展,为了解决台风轨迹预测精度不足和时效性滞后的问题,台风领域的专家提出了数值预报方法。袁炳等(2010)提出一种非对称台风Bogus 方法,提升了台风强度预报精度。王康玲等(1996)提出了一套解决台风数值预报初始场的方案,并且已将其应用于中国南海台风预报。钱传海等(2012)讨论了不同初始场和一些边界条件对台风数值预报精度的影响。李泽椿等(2002)回顾了国家气象中心集合数值预报系统的开发过程,概述了国家气象中心现有的中期集合数值预报系统的组成、应用和发展趋势。虽然数值预报在预报性能上要远远优于主观经验法,但是数值预报的精度相较于主观经验法并没有明显提升(陈国民等,2019)。进一步提高数值预报模型的预报精度仍然是一个挑战。
目前,世界各国的气象局基本都建立了气象卫星、海洋观测站,以及地面观测站等台风三维观测系统。从1949 年至今已经积累了大量台风数据(Gao et al,2018)。随着台风数据的收集整理,部分研究者对台风轨迹数据的时空特征进行了分析,认为可以将台风轨迹数据视为时间序列数据,因此提出了将台风轨迹预测和时间序列预测技术相结合的方法,希望获得更好的预测效果。
循环神经网络(Recurrent Neural Networks,RNN) (Tokg觟z et al,2018)是一种适用于处理时间序列数据的神经网络,已经在许多领域被广泛应用,但在迭代后期会出现“梯度消失”的问题。于是,Hochreiter 等(1997)最早提出了长短时记忆网络(Long Short-Term Memory,LSTM),通过增加输入门、遗忘门和输出门,使得网络自循环的权重可以变化,从而避免了“梯度消失”问题,适合处理和预报时间序列中延迟较长的事件。Ranzato等(2014) 提出了一种基于LSTM 的视频解释算法。Sutskever 等(2014)采用了LSTM 算法对时间序列进行预测,得到了很好的效果。研究表明,深度学习算法特别是LSTM 算法,可以很好地应用在天气预报和海洋预报领域中。徐高扬等(2019)将LSTM 网络应用在台风轨迹预测中,与动态时间规整算法(Dynamic Time Warping,DTW) 相结合,在预测6h 台风轨迹中效果很好。
随着神经网络的广泛应用(如金融、医学等),其包含的数据信息成指数增长,数据的长度、影响因子各有不同。传统的LSTM 已经无法完美地解决数据不定长或者数据影响因子较多的分类或预测问题。在此基础上,20 世纪90 年代,Forcada 等(1997)提出了一种编码器-解码器结构用来实现机器翻译。编码器-解码器网络结构无论输入和输出的长度是什么,中间的向量长度都是固定的,根据不同的任务可以选择不同的编码器和解码器。这种灵活性使得编码器-解码器网络迅速发展并且应用在各个领域。Chen 等(2018)提出了一种带可分离卷积的编码器-解码器网络并成功应用在图像分割上。Malhotra 等(2016)将编码器-解码器网络应用在时间序列的异常检测上,并取得很好的效果。Ekambaram 等(2020)利用编码器-解码器网络进行新产品的销售时间序列预测,得到了比较准确的预测结果。然而,随着时间序列的长度和特征数量增加,编码器-解码器网络的中间变量可能存储不了那么多信息,会造成精度下降,于是,一种基于注意力机制的编码器-解码器网络被提出。该注意力机制可以使网络更加集中于重要的特征,同时能够存储更长久的信息,亦有许多学者将其应用于时间序列预测领域,如:查铖等(2020)提出了一种结合注意力机制的区域海表面温度预报算法,明显提升了预报精度。Qin 等(2017)提出了一种双阶段的注意力机制模型,并将其应用在时间序列预测上,取得了很好的预测效果。Du 等(2020)将注意力机制和编码器-解码器网络结合,对空气质量时间序列数据进行预测,取得了很好的效果。Sutskever(2014)等针对注意力机制中的时间关系学习存在的问题,将注意力机制和编码器-解码器网络结合,发现使用注意力机制可以明显提高基于LSTM 的编码器-解码器网络的预测能力。
虽然上述研究方法皆在一定程度上提高了预测精度问题,但目前针对台风轨迹预测还未考虑到台风轨迹数据的特征相关性和深层的时间相关性。为了解决该问题,本文基于长短时记忆网络和注意力机制,提出一种结合双注意力机制的编码器、解码器网络模型(Dual-Attention-Encoder-Decoder,DA-Encoder-Decoder),首先使用台风轨迹数据计算得到台风曲率序列,充分考虑了台风轨迹数据中隐藏的转向和偏折信息。将曲率作为新的特征输入,然后通过特征注意力机制对输入特征分配权重,随后编码器将输入特征编码作为中间变量,而后再通过时间注意力机制对时间步长分配权重,最后通过解码器进行映射输出,得到预测结果。
1 DA-Encoder-Decoder 模型

图1 给出了DA-Encoder-Decoder 模型的流程图,两个灰色矩阵从上到下分别表示台风轨迹时间序列矩阵和台风轨迹曲率矩阵,绿色矩阵表示融合台风轨迹矩阵和曲率矩阵的输入矩阵。蓝色矩阵表示经过特征注意力加权的特征矩阵,橙色矩阵表示经过时间注意力加权的特征矩阵。D,D1,D2表示矩阵宽度,即台风序列数据的特征个数,H 表示矩阵高度。DA-Encoder-Decoder 模型的具体步骤如下:

图1 DA-Encoder-Decoder 模型流程图
步骤淤:将西北太平洋台风数据库处理成台风轨迹矩阵和曲率矩阵。
步骤于:将台风轨迹矩阵和台风曲率矩阵合并,依次按照台风轨迹时间先后进行排列,构成矩阵序列,作为DA-Encoder-Decoder 模型的输入。
步骤盂:利用注意力机制为获得的输入矩阵特征分配注意力权重,然后将注意力权重乘上对应的特征,得到加权的特征矩阵。
步骤榆:将特征矩阵输入编码器,得到隐藏状态特征,保存特征信息。
步骤虞:利用时间注意力对隐藏状态特征按照时间步长进行权重分配,然后将注意力权重乘上对应的特征,得到加权的隐藏状态特征。
步骤愚:对获得的隐藏状态进行解码,通过映射,最终获得预测结果。
1.1 曲率特征的构建
本文中每一条台风序列可表示为Si= [x1,x2,x3,…,xn],每一个xt沂Si表示台风序列的一个时间步长的输入[a,b],其中a 表示纬度坐标,b 表示经度坐标。然后将台风轨迹抽象到二维坐标系中,可以看作是一系列坐标点,通过二维坐标系中三点定圆原理,可以求得台风轨迹对应的曲率变化序列,求解步骤如下:
步骤1:首先设所求圆的半径为R,圆心坐标为(x,y),则可由圆公式得:

根据上述步骤求得每条台风轨迹的曲率序列,加入输入轨迹序列中作为第三个特征。得到新的输入序列Si= [x1,x2,x3,…,xn],每一个xt沂Si表示台风序列的一个时间步长的输入[a,b,c],其中a 表示纬度坐标,b 表示经度坐标,c 表示当前坐标点对应的曲率。
1.2 编码器-解码器模型
1.2.1 编码器
编码器在本质上是一种循环神经网络,它将我们的输入序列编码转化为一种特征。对于时间序列来说,给定输入序列X=(x1,x2,x3,…,x栽),编码器可以利用下面公式学习从x 到隐藏状态的映射。

其中ht沂Rm,Rm是t 时刻编码器的隐藏状态,m 是隐藏状态的大小,f1是一个非线性激活函数,在本文中我们使用LSTM(长短时记忆网络)。每一个LSTM 单元都有一个记忆细胞来记录t 时刻的状态St。对于这个记忆细胞将会通过三个门:遗忘门ft,输入门it以及输出门ot。LSTM 三个门的更新机制如下:

上式中[ht-1;xt] 表示当前输入和之前的隐藏层的连接。Wf、Wi、Wo、bf、bi、bo、bs是需要学习的参数。滓和已分别表示逻辑sigmoid 函数和对应元素的相乘。
相较于传统的循环神经网络,LSTM 的细胞状态可以对一段时间内的活动进行求和,可以克服梯度消失、梯度爆炸等问题,并且能够更好地捕获时间序列的时序依赖问题。
1.2.2 解码器
为了预测输出经纬度,本文使用了另外一个基于LSTM 的循环神经网络去解码已编码的输入信息。然而Cho 等(2014)提出,随着输入时间序列长度的增加,编码器-解码器结构网络的性能会下降。因此本文在解码之前结合了一个时间注意力机制,针对时间步长去训练相应的注意力权重。简单地说,就是根据前一个时间步的解码器隐藏状态计算当前编码器隐藏状态的权重。最终计算出我们期望的目标预测值。
1.3 注意力机制
注意力机制(Attention mechanism)是一种模仿人们视觉神经的方法,当人们观看某个东西时,会将视线主要集中在重点关注的部分周围,获取这个部分更多的相关信息,减少对无用信息的获取。所以,注意力机制最早应用在图像分析领域,且表现出色。随后慢慢地应用到了自然语言处理领域,与深度学习相结合,显著地提升了模型的效果。目前,注意力机制经常会和Encoder-Decoder 一起应用。注意力机制可以应用在多个领域,它们所作用的对象不同,对模型的性能提升也不尽相同,本文利用特征注意力机制和时间注意力机制来为输入特征和时间步长分配权重。
1.3.1 特征注意力机制
在使用编码器之前,使用特征注意力主要是为了获得输入特征对预测结果的影响大小的关联关系,以获得更好的预测结果。本文特征注意力的学习流程如图2,对t 时刻的第n(1臆n臆k,n沂Z)个特征向量的隐藏状态的特征注意力权重表示方法如下:


1.3.2 时间注意力机制
输入数据经过编码器编码后,将会得到一系列隐藏状态,为了得到预测结果,需要对隐藏状态进行解码。本文使用LSTM 网络作为编码器和解码器。然而,编码器中输入序列长度过长的时候,解码器的性能会下降。所以,本文在解码器之前利用时间注意力机制来尽量提升解码器的性能。对编码器生成的隐藏状态来说,其对时间依赖性的关注不足,需要利用时间注意力机制来对编码器的隐藏状态进行权重分配,以提升网络整体性能。简单地说,时间序列的长期依赖性可以通过加权编码器中目标值最相关的隐含状态来学习(Sagheer et al,2019)。本文时间注意力的学习流程如图2,对t时刻的第i(1臆i臆T,i沂Z)个隐藏状态的时间注意力权重表示方法如下:
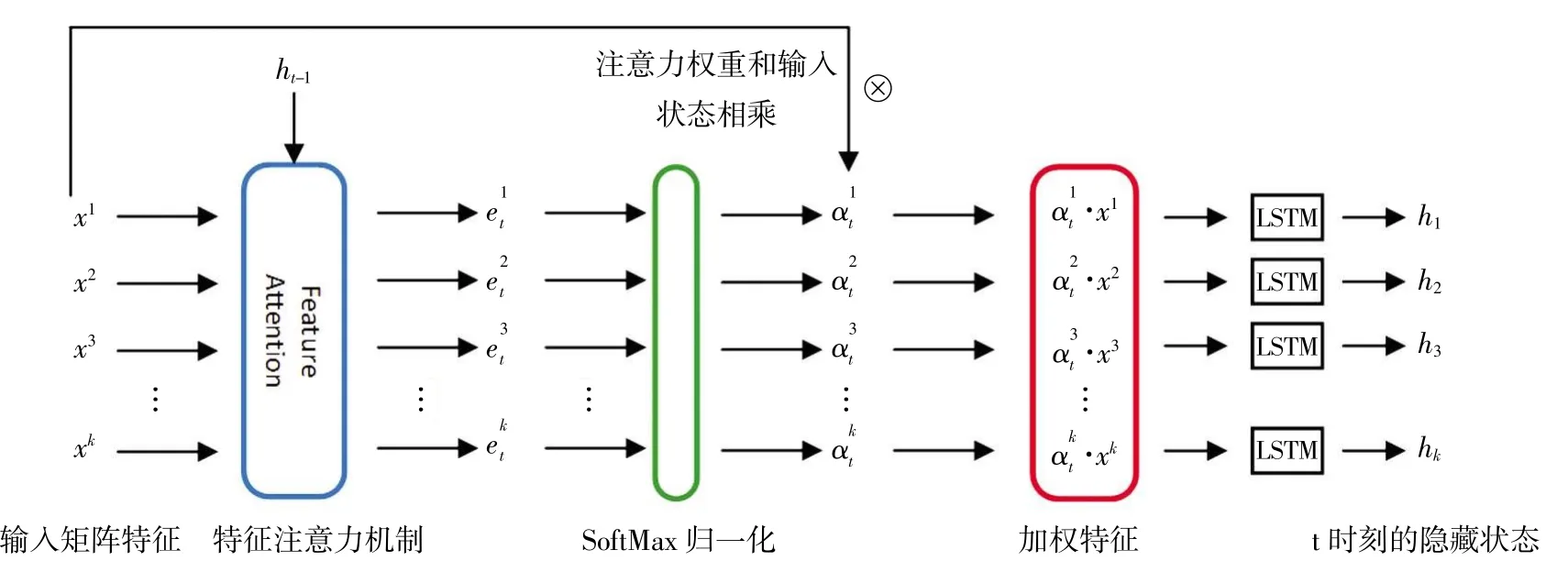
图2 特征注意力机制流程图

图3 时间注意力机制流程图

2 实验
2.1 实验数据

本文实验使用Keras 框架搭建,Keras 是一个高度模块化的神经网络库,可以基于Theano 或者tensorflow 搭建,并且支持扩展开发。实验硬件环境平台是Windows10,Intel Corei7,3.0 Hz,8GBRAM。
2.2 精度评价指标
在使用模型进行预报时,由于误差的计算是根据预测坐标和实际坐标的差值,均方根误差(Root Mean Square Error,RMSE)能够很好地反应坐标点的偏移,也是一种常用的精度评价指标。实际误差距离(ErrDis)(km)则是根据预测坐标点和实际坐标点来计算两点之间地理上的实际误差距离。能够更加明确清晰地体现预测误差,对实际业务应用也有一定的作用。
因此,为验证DA-Encoder-Decoder 模型的有效性,本实验使用RMSE 和ErrDis 来评估不同预报方法的性能,RMSE 和ErrDis 的公式如下表示:


对于RMSE 和ErrDis 来说,它们的值越小越好。当模型训练使得RMSE 和ErrDis 最小的时候,就是最优模型。训练时,通过观察RMSE 和ErrDis的变化来确定合适的模型结构和模型参数。
2.3 实验结果分析
由于台风预测需要时效性,实验选取训练时间步长为一天(24 h)的数据。然后将全部的台风轨迹数据进行划分,将75%的数据作为训练集,用于训练DA-Encoder-Decoder 预测模型的参数,剩下的25%的数据作为验证集,用于验证模型的学习效果。
确定输入特征:前文中提到利用台风轨迹计算出曲率序列。增加曲率的特征主要是为了模拟出台风的轨迹的曲线运动趋势,包含了台风的转折角度和未来方向等信息。为了确定曲率特征对预测性能的提升能力,使用台风轨迹原始数据和增加曲率特征的数据集分别预报24 h、48 h、72 h 的轨迹坐标。对比了曲率在编码器-解码器(Encoder-Decoder)和基于双注意力机制的编码器解码器模型(DAEncoder-Decoder)预测模型的作用。根据表1 预测结果,可以看到在Encoder-Decoder 模型和DAEncoder-Decoder 模型上,增加了曲率特征之后对RMSE 和ErrDis 都有一定的降低作用,有利于提高台风轨迹预测的精度。因此,本文在输入特征中增加曲率特征。

表1 增加曲率特征性能对比
确定注意力机制:针对Encoder-Decoder 模型,增加不同的注意力机制,来记录性能变化。从表2 可以看到,增加了注意力机制的模型预测精度要优于未增加的注意力机制的模型。增加了时间注意力的TA-Encoder-Decoder(Temporal-Attention-Encoder-Decoder)模型要优于增加了特征注意力的FA-Encoder-Decoder (Feature-Attention-Encoder-Decoder)模型。而本文提出的基于双注意力机制的DA-Encoder-Decoder 模型效果明显优于其他注意力机制。因为利用特征注意力机制去计算输入特征的注意力权重会在更大程度上修正输入特征对预测结果的影响。第二部分的时间注意力机制会针对每次输入的样本计算时间步长的注意力权重,尽管LSTM 也具备这种能力,但是在编码器解码器结构下,长序列会大大降低模型预测精度,而时间注意力机制能够解决这个问题,可以对输入数据进行长时期的权重计算,将之前的信息存储在隐藏层中。
表2 是针对不同的注意力机制与预测模型结合的预测结果。预测模型分别对24 h、48 h、72 h 台风轨迹进行预测。可以看出,增加了时间注意力的模型(TA-Encoder-Decoder)精度比单纯的Encoder-Decoder 模型高,证明了在时间维度上的注意力权重训练能够提高模型的预测精度。同理,在特征维度上的注意力权重训练也能够提高模型预测精度。因此,特征相关性和时间相关性对台风轨迹预测的精度均有影响。本文的DA-Encoder-Decoder模型既考虑了特征相关性,又考虑了时间相关性,从表2 可以看出,DA-Encoder-Decoder 模型的精度要明显优于其他同类模型的预测精度。

表2 增加不同注意力机制性能对比(输入包含曲率特征)
预报方法对比:确定了预测模型的输入特征、注意力机制,预报模型基本上已经确定,为了验证本文提出的DA-Encoder-Decoder 模型的有效性,分别与传统预测方法以及神经网络方法进行了对比。对比方法包括:BP、SVR、LSTM、ELM。对于SVR 网络使用的是径向基核函数(Radial Basis Function,RBF),该核函数能够实现非线性映射并且需要学习的参数较少。以上对比试验均采用Keras 库函数进行搭建。训练数据使用数据集的75%,验证数据使用25%。通过预测24 h、48 h、72 h 的台风轨迹,对比模型的RMSE 和ErrDis 指标来比较模型之间的预测性能的差异。
表3 是所有对比模型和本文模型的预测结果。可以看出,在预测24 h 台风轨迹时,BP、SVR、LSTM、ELM、DA-Encoder-Decoder 模型的RMSE指标分别为3.48、2.96、2.81、5.62、1.82,ErrDis指标分别为330.6 km、279.24 km、263.14 km、539.55 km 和172.03 km。在24 h、48 h、72 h 上的预测中,与其他机器学习、深度学习预测模型相比DA-Encoder-Decoder 模型降低了预测误差,具备最好的预测性能。

表3 不同模型性能对比(输入包含曲率特征)
3 结束语
本文提出的DA-Encoder-Decoder 模型在台风轨迹预测上的应用具有一定的研究意义,它充分挖掘了台风轨迹数据的特征和时间信息,在输入上结合了台风轨迹的曲率序列,包含台风轨迹的转向、偏折等隐藏信息,与同类台风轨迹预测模型相比,提高了预测准确性。
本文主要的结论有三点:
(1)之前的台风轨迹预测都是只单纯考虑台风时间序列经纬度之间的关系,而本文将包含转向、偏折信息的曲率特征作为预测特征,考虑了台风转向等隐藏因素对台风轨迹的影响。
(2)利用了特征注意力机制为特征分配权重,得到不同的特征对要预测的轨迹点在特征维度上的影响。特征与权重相乘得到加权特征,突出了关键特征,提升了预测精度。
(3)利用了时间注意力机制为特征分配权重,反映出历史台风轨迹数据对要预测的轨迹点在时间维度上的影响,历史台风轨迹数据距离预测的轨迹点的时间远近不同,对其的影响也不相同;特征与权重相乘可得到加权特征,使得关键信息被突出,加权特征包含的信息越明显,预报精度便越高。
对比不同方法在同一数据集下的预测结果,DA-Encoder-Decoder 分别预测24 h、48 h、72 h台风轨迹,误差分别为172.03 km、245.14 km、403.6 km,实验结果表明DA-Encoder-Decoder 模型在台风轨迹预测方面获得了一定的精度提升,从而验证了本文方法的有效性,该模型值得更深入地研究和应用。由于台风轨迹所受到的影响因子众多,如风速、压强、降雨量等,这些因子对台风轨迹的变化具有一定的影响,因此在后续的研究中也应该充分考虑其他相关要素对台风轨迹的影响。在下一步工作中,利用要素相关性或关联规则去筛选对台风轨迹影响较大的要素,利用这些要素建立多要素预测模型,从而进一步提高台风轨迹预测精度。
猜你喜欢
环球时报(2022-09-07)2022-09-07
网络安全与数据管理(2022年1期)2022-08-29
小学生必读(低年级版)(2021年10期)2022-01-18
科学技术创新(2021年5期)2021-03-17
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
——编码器
演艺科技(2020年7期)2020-08-13
小读者(2020年4期)2020-06-16
家庭影院技术(2019年8期)2019-12-04
探测与控制学报(2015年4期)2015-12-15
