
基于ResNet18的图像分类在农作物病虫害诊断中的应用
2021-10-20 12:24:28赵春霞
农业与技术 2021年19期
赵春霞
(青岛职业技术学院,山东 青岛 266555)
引言
本文基于卷积神经网络的农作物番茄叶片多种类病虫害识别和诊断,提出一种对病害种类准确识别的卷积神经网络模型,用于对于不同的番茄叶片病害分类,实现番茄叶片病害自动诊断和识别。
1 基于深度学习的图像分类方法
深度学习是研究和解决在深度神经网络中表达数据特征的一种机器学习方法,其被广泛应用于图像分类和识别中,尤其在海量图像的高级抽象特征自动提取方面效果很好,分类的精度和准确度都有所提升。
1.1 深度神经网络
深度神经网络的内部网络结构如图1所示,Input layout表示输入层、Hidden layout表示隐藏层、Out layout表示输出层,其中小圆圈表示神经元,每条直线代表上下层之间2个神经元之间的连接,并且上一层与下一层之间是全部连接的,即数据从上一层的每个神经元经过加权运算后都输出到下一层神经元,上一层数据作为下一层的输入。对于图像而言,每个像素点就是输入,每张图像的宽度和高度的乘积,就是输入的神经元的个数,这种全连接的方法在图像分类上表现的数据量非常的大,训练的速度慢,成本高,效率很低,并且图像在计算过程中很难保留原有的特征,导致图像分类和识别的准确率不高[1]。

图1 DNN的基本结构
1.2 卷积神经网络
一个典型的卷积神经网络结构如图2所示,主要包括输入层、执行卷积运算的卷积层、执行池化采样运算的池化层、全连接层和输出结果层5部分。图像分类中关注的是图片中各个部分的边缘和轮廓,而边缘和轮廓只与相临近的像素有关。卷积神经网络CNN通过卷积计算可以将复杂问题简化,可以提取图片的边缘和轮廓,把大量参数降维成少量参数,即使当图像做旋转,翻转或者变形,截取部分图片时,也能准确地识别出来是类似的图像[2]。

图2 典型的卷积神经网络基本结构
1.2.1 基本概念
1.2.1.1 卷积核(Kernel)
又称滤波器,在对图像数据进行卷积运算时,需要对图像数据某个局部矩形区域进行加权求和,以获取图像的边缘核轮廓特征,其中的权值就是卷积核。
1.2.1.2 卷积核大小(Kernel Size)
卷积核的矩形区域大小称为卷积的大小,卷积核大小一般为奇数。如,一般使用二维卷积核3×3。
1.2.1.3 步长(Stride)
当进行卷积运算时,卷积核每次向右或向下移动的像素称为步长,一般用Stride表示。如,Stride=2,表示进行卷积运算时,卷积核每次移动2个像素。
1.2.1.4 填充(Padding)
为了防止边缘信息丢失,在卷积运算之前,在原图像或图像特征数据四周边缘上填充一层或多层0像素。
1.2.1.5 卷积过程
卷积过程是把卷积核中的k×k个元素依次和图像中相同区域对应的像素进行相乘求和运算后作为对应位置新的特征值,然后把该卷积核沿着图像向右或向下平移步长Stride个像素,继续计算新的特征值,直至完成整个图像的计算[3]。
1.2.2 图像的卷积运算
对于有颜色的RGB图像,包含R、G、B 3个大小相同的图层(通道),若卷积核为k×k,则卷积核的大小可表示为3×k×k,其中3表示3个通道。RGB图像卷积运算方法是在图像的R、G、B 3个通道上分别使用对应的k×k的加权相加得到结果再相加,得到一个二维卷积输出结果。若有多个卷积核,可得到多个二维卷积输出结果。2个通道的卷积运算过程如图3所示。如,输出56=(1×1+2×2+4×3+5×4)+(0×0+1×1+3×2+4×3)。
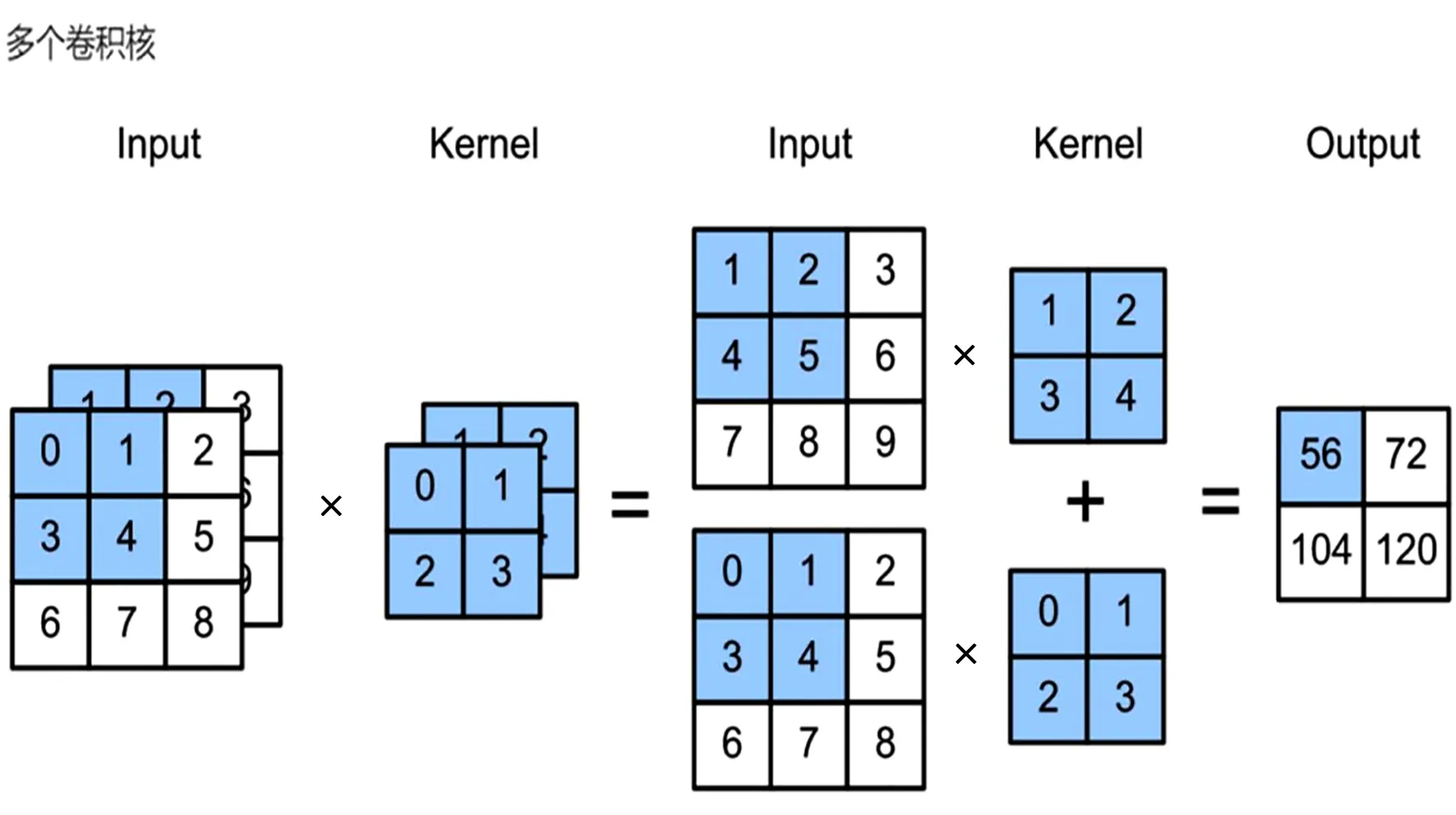
图3 2个通道的卷积运算过程
1.3 模型选择
目前卷积神经网络的典型架构有LeNet-5、AlexNet-8、VGG16-19、ResNet等。本文采用ResNet模型结构使用Pytorch框架构建ResNet18模型,并对农作物番茄叶病虫害类型数据集进行训练,实现农作物病虫害自动诊断。
2 实施步骤和流程
2.1 数据清洗
数据清洗是整个项目实施过程中第一个环节,也是非常重要和不可缺少的环节,模型训练的效果和数据清洗的结果质量密切相关。数据清洗包括将命名不规范的图像名,重构规范成统一的格式,如随机字符串__类别名__图像号.图像格式;删除尺寸不匹配的图像;筛选噪声图像,将图像像素全为0的噪声图像删除;将同类别的图像整理到同一文件夹下。

图4 数据集清洗后的部分数据
2.2 图像数据预处理
对训练集和测试集分别进行图像预处理,主要包括图片大小调整,将图片的大小统一调整到ResNet模型架构的要求的尺寸,224×224;图像增强例技术,如缩放、拉伸、翻转、平移、对比对调整、加入噪点等,主要目的是让图像数据更适合AI模型进行处理,并扩充数据集,可以使用Pytorch中有一系列的数据增强函数来实现;图像归一化处理,将图像变化为模型能够接受的数据类型及格式,实现归一化,并且归一化至[0.0,1.0]之间的值,只对训练集进行归一化处理;图像标准化处理,对训练集的图像数据使用均值MEAN=[0.485,0.456,0.406]、标准差STD=[0.229,0.224,0.225],先减去均值再除以标准差进行标准化运算,通过标准化后,使数据更符合数据中心化分布规律,能增加模型的泛化能力[4]。
2.3 数据加载
利用Pytorch中的ImageFolder方法加载数据集,加载训练集将训练集路径和预处理及增强的方法作参数输入,加载测试集并将测试集路径和预处理方法作为参数输入。
利用Pytorch中的DataLoader方法将加载好的训练和测试数据集转变成便于模型计算的数据类型Pytorch DataLoader。
2.4 模型设计与搭建
2.4.1 ResNet18模型结构
具体见图5,其中,“3×3conv,64”表示3×3大小的卷积核,深度为64。

图5 ResNet18模型结构
2.4.2 模型设计结构说明

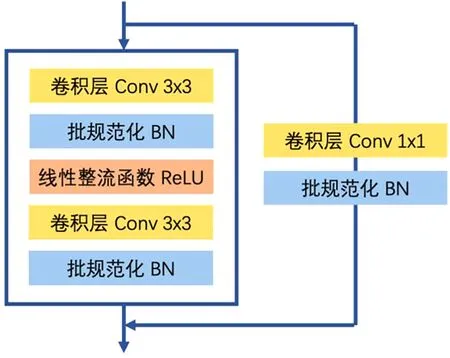
图6 Basic Block残差网络结构
2.4.3 创建模型,保存参数
根据ResNet模型架构,使用Pytorch框架创建模型,并保存训练模型的参数。
2.5 模型训练和测试
本文使用10000条训练数据和10000条测试数据进行训练和测试,进行10种分类。
2.5.1 模型训练
整个模型的训练过程包括2个阶段。向前传播阶段。数据从模型的输入层开始,从低层次向高层次依次计算的过程;在前向传播过程中,输入的图形数据经过模型处理后得出分类的结果,并通过损失函数计算输出的结果与真实值之间的损失值。反向传播阶段。当模型的输出结果与实际的预期值误差较大时,则进行向后反向传播。
具体流程:加载训练数据集;遍历数据集获取图像数据和对应的标签;梯度归零;前向传播,使用模型计算输出;计算损失率;反向传播:将误差从高层次向低层次依次返回,识别每个参数对误差的影响程度,然后进行参数更新;更新参数;保存损失值,便于统计每一个周期的损失值。
2.5.2 模型测试
训练完训练集后,用生成的模型Model参数来测试样本。在测试之前,需要调用Model.eval()的方法,不改变网络参数的权值,并且梯度不归零,不进行反向传播,使用生成的模型进行前向传播计算出输出值和预期值的损失值,根据损失值的变化来验证模型的有效性,同时计算测试集中测试结果的准确率。
2.5.3 模型评估
用训练数据集训练神经网络,并使用测试集进行测试,并完成不同的多周期训练,通过绘制训练和测试的损失值变化曲线观察模型训练的效果,通过计算准确率来验证模型。
分别设置训练周期EPOCHS的值为5、10、20对模型进行训练,得到的损失值变化曲线如图7~9所示,可见训练的损失值和测试的损失值随着训练周期EPOCHS的增加,都在变小,不存在过拟合的现象。在EPOCHS=10左右时,两者的损失值变化已不大,但EPOCHS=20时的测试的准确率比EPOCHS=10时测试的准确率高3%。

图7 EPOCHS=5 图8 EPOCHS=10 图9 EPOCHS=20
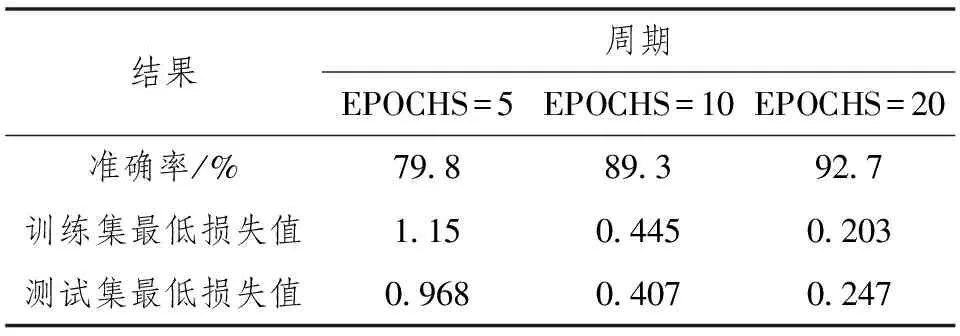
表1 不同训练周期的训练结果
2.6 应用模型
搭建网络应用,利用训练好模型和模型权重,完成指定图片的预测根据返回预测结果,进行实际的应用。
3 结语
本文使用Pytorch搭建ResNet18模型,优化了网络结构和参数,提高了模型的图像分类性能,对病害种类准确识别的卷积神经网络模型进行多次测试,在农作物番茄叶病虫害数据集上训练时取得了较小的误差,在海量图像的高级抽象特征自动提取测试时准确率较高,用于预测时分类效果较好,模型结构稳定,该模型以及模型参数可用于实际的农作物病虫害种类的诊断。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26 14:09:30
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
数学小灵通(1-2年级)(2020年6期)2020-06-24 05:57:54
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中学生数理化·八年级数学人教版(2017年2期)2017-03-25 16:12:51
中学生数理化·七年级数学人教版(2016年9期)2016-12-07 08:18:09
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
