
基于层次规则的OSM建筑物面目标冗余清理
2021-10-20 04:10唐忠立张宏奎
北京测绘 2021年8期
唐忠立 张宏奎 汤 鑫 王 倩
(长沙理工大学 交通运输工程学院, 湖南 长沙 410114)
0 引言
用户生成内容(User Generated Content)是Web 2.0时代的显著特征之一[1]。随着智能手机、相机以及平板电脑等支持全球定位系统(Global Positioning System,GPS)芯片设备的普及,大众获取地理信息的能力持续增强,越来越多的用户以高分辨率遥感影像和GPS轨迹为基础,利用Web 2.0创建丰富的矢量地理信息。这一新趋势在“志愿者地理信息”(Volunteered Geographical Information,VGI)[2]或“众包地理数据”(Crowd-sourced Geodata)[3]的普及下日趋流行。由于众源数据具有免费共享、覆盖面积广、准实时更新等特点,弥补了传统地理信息更新迟缓等问题[4-5]。当前,自发地理信息已广泛应用于应急制图、灾后救援、旅游服务等领域[6-10]。
开放街道地图(OpenStreetMap,OSM)被认为是最成功、最受欢迎的志愿者地理信息项目之一[4,6-7],在Web 2.0环境下,群体协作已经成为一种新的模式,利用大众的参与来高效地完成传统上由少数专业人员承担的任务。目前,雅虎地图、Bing Map等均为其提供了影像数据支持。OSM数据由大众自发标报并维护,形成了一种由大众发起的“创建-浏览-更新”数据管理模式,也正是这种自发性不可避免地导致了OSM的数据质量问题,例如,用户基于已有版本新建新版本数据造成数据冗余问题,严重影响其数据的深化应用。因此,相对于专业数据而言,OSM的数据具有质量各异、覆盖不均匀、缺少统一规范、冗余而不完整、隐私和安全难以管控等缺点[2,11-13]。建筑物数据在矢量数据运用中具有极大影响力,OSM建筑物数据的冗余直接影响其应用,因而建筑物面目标冗余清理必不可少。
当前学界对OSM冗余数据清理的研究甚少,李德仁等认为垃圾信息及恶意内容的鉴别与清除、重复内容及数据冗余的检测与清理、涉及隐私与秘密等内容的处理是数据清理的主要对象[14]。QIAN等提出在添加增量数据时通过拓扑一致性筛选出拓扑冲突数据,利用空间聚类算法清理重复数据[15],采用人工交互方式管理数据的属性信息,但并未进一步实现具体的清理算法。NEIS等以维基百科中用户标注的属性信息作为参考基准,根据志愿者在地图上注释的数量对用户信誉进行评估,在此基础上制定多种规则对数据进行检测与筛选,并开发了基于规则的OSM恶意破坏数据自动检测系统[16],但其忽略了空间数据的几何特性。MUMMIDI等提出了从在线用户提供的地图注释中提取、清理兴趣点(Point Of Interest,POI)的方法[17],该方法针对用户贡献的信息内容各异的问题,从志愿者在地图注释的详细信息中鉴别有效的地名,并提取作为兴趣点对空间数据进行清理,但该方法未顾及空间数据的几何因素。此外,Open Watchlist和OSM Mapper两款工具也是对OSM数据管控的有效手段,均使用简易信息聚合 (Really Simple Syndication,RSS)通知志愿者指定区域内的信息变化,但无法进一步识别重复、虚假及低质量等数据。虽然OSM已包含部分质量保证及验证方法,但仅向用户反馈目标重复标报等信息,并无实际处理措施。可见,OSM数据冗余问题已引起学者关注。
为此,本文针对OSM建筑物冗余的问题,在自发地理信息点、线、面数据的检测与合并、筛选与清理等相关研究的基础上,提出了一种基于层次规则的OSM建筑物面目标冗余清理模型:该模型首先采用层次递进的方式对OSM建筑物数据进行冗余识别,并依据拓扑模型进行冗余分类,将分类后的冗余数据通过层次规则进行清理,再将清理后的数据重复2次冗余识别及清理的流程,最后采用OSM长沙市区建筑物冗余数据进行实验分析。
1 OSM冗余数据清理思路
1.1 OSM数据质量问题
由于大众对地理对象的认知与标报目的均不相同,在OSM上的贡献行为很大程度取决于用户习惯与喜好,故贡献者在添加、修改、删除等行为上也不相同。概括而言,OSM数据存在以下问题较为突出:(1)贡献者对地理空间对象认知经验相异,对现存目标进行新建操作;(2)相同用户贡献连续版本;(3)有意的破坏行为。图1所示的“东成大厦”及“体育艺术馆”即为OSM平台志愿者编辑导致的冗余数据。

图1 OSM平台冗余数据示例
1.2 OSM建筑物冗余清理模型
针对OSM建筑物数据的特点及存在的问题,借助OSM错误数据系统筛选规则[16],综合考虑建筑物的几何特征及属性特征,构建了一套由冗余识别、分类及层次规则清理组合而成体系,进而提出基于层次规则的OSM建筑物面目标冗余清理模型。首先该模型根据拓扑关系模型识别存在拓扑冲突的面目标,然后计算拓扑冲突面目标间的面积重叠率,精确识别建筑物冗余,并按拓扑冲突类型将建筑物冗余分类;其次,选取属性信息完整性、均值面积、阈值面积、面积差、规则角比差、不规则角比差、不规则角差、斜率符合值及综合值等9项指标对不同类型的建筑物冗余构建相应的层次规则,并依据层次规则清理建筑物冗余;最后,将首次清理后的数据重复进行2次冗余识别及清理的操作。该模型从冗余识别到分类再到冗余清理的流程如图2所示。

图2 OSM建筑物面目标冗余数据清理流程图
2 OSM建筑物冗余识别
不同个体对现实世界中同一地理实体的认知差异,导致地理实体与数据项之间“一对多”的情况,即常见的重复标报问题,进而导致OSM数据冗余、不一致性、存储空间浪费等一系列问题。因此,冗余目标清理是提升OSM数据质量的必要环节,其前提是冗余识别。冗余目标在拓扑、距离等空间关系以及几何、属性特征等方面表现明显,地理实体与OSM空间目标的一一映射关系使得建筑物目标及其冗余之间呈相交、包含等拓扑关系。为此,引入冗余识别所涉及的拓扑关系模型及重叠率等指标,并采取层次递进的方式进行精确识别。
2.1 冗余识别指标
2.1.1拓扑关系模型
简单面/面目标之间的基本拓扑关系共八种,包括相离(Disjoint)、包含(Contains)、包含于(Inside)、相等(Equal)、相接(Meet)、覆盖于(CoveredBy)、覆盖(Covers)、相交(Overlaps)[18],将基本拓扑关系组合可表达复合的拓扑关系。对OSM建筑物目标及其冗余而言,实际涉及的拓扑类型及组合包括包含于(Inside)、覆盖(Co-vers)、相交(Overlaps)及复合(Complex)共4种,其中,复合型指多种拓扑关系的组合,其组合个数比例可表述为Inside∶Covers∶Overlap=NInside∶NCovers∶NOverlap,其中NInside、NCovers、NOverlap均为大于或者等于1的整数,且NInside+NCovers+NOverlap≥3。OSM建筑物目标冗余识别涉及其中4种拓扑关系,如图3所示。
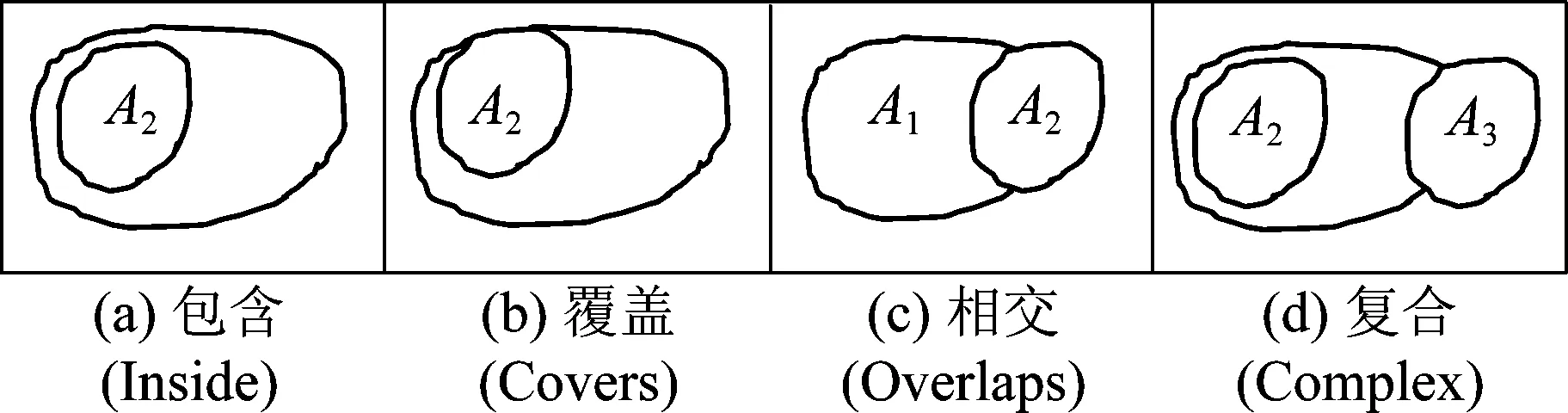
图3 OSM建筑物面目标冗余中的四种拓扑类型
2.1.2面积重叠率
引入面积重叠率主要是定量化精确识别相交冗余,并为识别包含、覆盖及复合冗余提供定量化依据。其计算如式(1):
(1)
式中,FA、FB和FA∩B分别表示建筑物面目标A、B以及A∩B的面积。函数Fmin取两个建筑物面目标A和B中较小的面积值。此外,取S(A,B)最小阈值为20%[19]。
2.2 冗余识别流程及分类
冗余识别是进行冗余清理的前提,拓扑空间表达模型是拓扑冲突检测的基础,面积重叠率指标是精确识别的定量化依据。故选取以上两个指标形成一套由浅入深的层次递进的冗余识别方法,并将其冗余数据按拓扑类型进行分类。其冗余识别流程及分类情况如下:
(1) 首先通过拓扑关系模型识别发生拓扑冲突的面目标。
(2) 然后根据式(1)计算面目标间的重叠率,精确识别冗余面目标。
(3) 最后根据图3所示拓扑关系类型将建筑物冗余分成包含型、相交型及复合型,如图4所示。

图4 OSM建筑物面目标冗余类型示例
3 OSM建筑物冗余清理
3.1 层次规则构建
层次规则的构建是保障冗余清理的有力支撑,指标的选取是规则构建的关键因素。传统文献在定义数据清理指标方面不全,文中提出了8项约束指标构建层次规则,具体定义如下:
(1) 属性信息完整性
(2)
式中,F表示属性信息完整值,i表示第i个属性因素(1≤i≤n,n表示属性因素的数量),Si表示i个属性信息的值,Si的取值为{0,1},0代表第i个属性因素为空,1代表第i个属性因素存在。
(2) 均值面积
(3)
式中,A为区域内建筑物平均面积,Si为第i个面目标面积,N为清理发生拓扑冲突的面目标总个数。
(3) 面积差ΔS:即包含建筑物面积S包含与被包含建筑物面积S被包含(S被包含=∑Si)。
(4) 阈值面积T:即包含建筑物面积S1与被包含面目标个数I之比。
(5) 规则角比差ΔXab及不规则角比差ΔYab:即ΔXab=Ra-Rb,ΔYab=Ia-Ib,分别设定阈值为δ及ϑ。其中R及I计算式如下:
(4)
(5)
式中,R为规则角比值,I为不规则角比值,其中将小于78.6°设定为不规则角,将87°~93°设定为规则角,Sθ为满足规则角的值(Sθ∈{0,1}),Sω为满足不规则角的值(Sω∈{0,1}),L为闭合多边形边的数目。
(6) 不规则角差Δθ:即Δθ=∑θA-∑θB,θA和θB为面目标A和B的不规则角。
(7) 斜率符合值SCv:
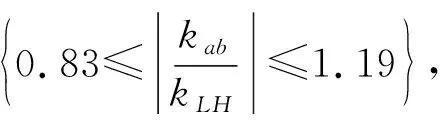
(6)
(7)
式中,Sv为斜率符合值;kab为多边形临近道路的边的斜率值;kLH为道路临近多边形的线段的斜率值;S为斜率比值;n为多边形中参与计算的总线段数。如图5所示,图中M、H、L表示道路折点,a~f表示多边形折点。

图5 斜率比值示例图
(8) 综合值c:根据清理需求对前7类指标按需组合,即包含型c=∑[Fi+Ri-Ii+(Sv)i]/n;相交型c=A+Sv。
根据以上8项指标构建包含型及相交型层次规则,其中包含型层次规则中以包含面目标及被包含面目标为例说明,相交型规则中以面目标A、B为例说明。规则1、规则2及规则3为包含型冗余清理的规则,层次关系为:规则1为父级规则,规则2为规则1的子级规则,规则3为规则2的子级规则;规则4、规则5及规则6为相交型冗余清理规则,层次关系为:规则4及规则5为父级规则,规则6为规则5的子级规则。各类型层次规则如下。
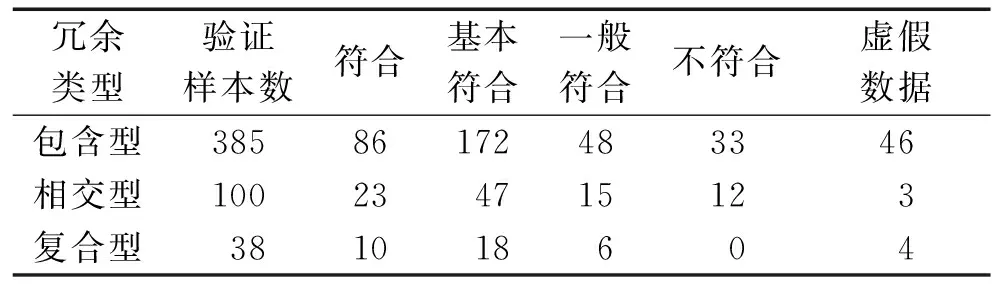
规则1:若S1≥2A,则清理包含面目标;若0 规则2:若{ΔS>T},则清理被包含面目标;若{ΔS≤T},则输出至子规则3。 规则3:若{c包含>c被包含},则清理被包含面目标;反之,则清理包含面目标。 规则4:当L1=L2=4 时,若Δθ≥0,则保留A清理B;反之,则保留B清理A。 规则5:当L1,L2至少有一个不等于4时,若{δmin≤ΔXab≤δmax,-ϑmin≤ΔYab≤-ϑmax}或{-δmin≤ΔXab≤-δmax,ϑmin≤ΔYab≤ϑmax},则保留A清理B;反之,则保留B清理A;若{-δmax<ΔXab<δmin,-ϑmax<ΔYab<ϑmin},则输出至子规则6。 规则6:若{-7°≤Δθ≤7°且cA>cB},则保留A清理B;若{-7°≤Δθ≤7°且cA 对于包含型冗余数据,将包含及被包含面目标作为两类清理对象,该冗余类型运用其层次规则清理冗余面目标的流程如图6所示。 图6 包含型冗余清理流程 对于相交型冗余数据,以面目标A和B为例,若发生三个以上面目标冗余,则两两进行清理,该冗余类型运用其层次规则清理冗余面目标的流程如图7所示。 图7 相交型冗余清理流程图 对于复合型冗余数据,可将其视为“包含型”和“相交型”冗余的组合,因此,其清理过程可按照先清理包含型冗余再清理相交型冗余顺序依次进行。 为了评价冗余清理的效果,此处采用精确率P(Precision)、r召回率(Recall)及调和平均值F1对结果进行分析,各指标定义如下: (1) 精确率 (8) 式中,PT是被正确清理且已清理冗余数据的实例数;PF是被错误清理且已清理冗余数据的实例数。 (2) 召回率 (9) 式中,FN是数据冗余且未清理冗余数据的实例数。 (3) 调和平均值F1 (10) 式中,F1值为精确率和召回率的调和平均值。F1分数在1处达到最佳值(精确率和召回率均为1),在0处达到最差值。 为了验证本文所提出的基于层次规则的OSM建筑物冗余清理模型的合理性,选取了OSM真实的历史数据进行实验。实验采用开源免费数据库(POSTGRES)存储下载的OSM建筑物历史数据,文件格式为XML,由于OSM的总数量大且数据的完整性及完善度受贡献者活跃程度的影响较大,因此新一线城市或二线城市中建筑物冗余数量相对较多,故选取长沙市建筑物数据进行分析,如图8所示。实验区域内建筑物面目标数共为30 505个,发生拓扑冲突的面目标为780个,符合冗余数据样本为722个。本文利用ArcMap 10.2及C#程序处理数据,将冗余清理实验结果通过ArcMap 10.2显示,由于实验区域较大且冗余数据比较分散,故展示局部区域清理实验结果,如图9所示。 图8 实验区域示意图 图9 局部区域建筑物冗余清理前后对比图 依据层次规则对三种类型的OSM建筑物冗余进行清理,实验结果见表1。然后将清理后的目标级与天地图上相对应目标在形状及大小方面进行比对,将比对的结果分为符合、基本符合、一般符合、不符合及虚假数据5个等级,实验结果见表2。最后,基于表1清理后数据统计,计算P、r及F1值,并评价清理效果,其结果如表3。 由表1可知,整体冗余样本数满足实验要求,其中包含型及相交型样本数更是充足。故在此基础上,其实验结果具有较高的可信度。PT值及PF值分别反映冗余清理的正确率及错误率,从表1中可看出三种类型冗余清理的正确率均达到了85%以上,且清理的错误率在10%左右,其中包含型及相交型的PF值更是低于10%,表明该模型清理建筑物冗余不仅能达到其数据清理的要求而且其清理的准确性高。FN值反映的是该模型冗余清理无效的实例数,从表中可看出三种冗余类型的FN值均低于6%,表明本文提出的基于层次规则的建筑物冗余清理模型能够清理出绝大部分冗余数据,是控制管理OSM建筑物冗余数据的一种有效方法。 表1 实验区冗余数据清理实验结果 从表2可知,清理后三种类型目标级的比对满足符合及基本符合的等级所占比例均在65%以上,其不符合数据及虚假数据均在10%左右,根据定性推理[20]思想,可反映出本文实验所用的OSM建筑物数据质量较好。故此,表明该模型对于OSM建筑物冗余数据的清理有较高的可靠性。 表2 目标级冗余数据清理实验结果 单位:个 从表3可知,三种冗余类型均有较高的P值及r值,表明该模型清理效果较好。结合式(8)及式(9)可看出,其精确率与召回率为此消彼长的关系,在提升一个指标的同时必然会使另一个指标下降。在精确率与召回率合格条件下,ΔPr(P与r之差的绝对值)越小其清理效果越佳,其中包含型及相交型的ΔPr均较小,表明该模型对包含型及相交型的清理效果较好。其复合型的ΔPr稍大,这意味着该模型对此类冗余清理效果比其他两类冗余清理效果稍低一些,由于其实验样本数较少,对此类冗余清理效果评价可能会存在一定的偏差。但是,从整体上看,三类冗余的ΔPr值与F1值均处于一个较好的水平,亦表明该模型的有效性,同时,也为OSM建筑物数据的管控提供了一个新的视角。 表3 冗余清理统计分析 单位:% 本文针对OSM平台上建筑物数据冗余问题,基于层次化、规则化的理论方法,结合建筑物要素的几何、属性、拓扑三类信息,构建了一套从冗余识别到冗余分类再到冗余清理的体系,进而提出一种基于层次规则的OSM建筑物目标冗余的清理模型。本模型对于众源地理信息准实时的特点来说,能够很好地解决不活跃地区建筑物冗余更新迟缓的问题,并且可以高效地清理出冗余数据,提高数据的实用性。相对于一些现有的数据清理方法,本文所提模型既考虑了专业建筑物数据管理中存在的问题,又顾及了众源建筑物数据冗余的问题,其清理模式更加符合OSM建筑物数据管理的要求。试验结果表明,该模型能够准确地清理出绝大部分的冗余数据,亦证明其模型的有效性,为OSM建筑物数据清理提供了一个新的视角。 本文所提出建筑物冗余清理模型主要是针对规则建筑物冗余,尚未过多顾及不规则建筑物的几何、属性及拓扑等信息,且建筑物的几何特征及拓扑特征在该模型中占比较重,若对于相应的不规则建筑物冗余的清理,该模型的清理效果相对较差,此外,贡献者信誉度、版本号及编辑时间等因素对冗余清理也会产生一定的影响。如何实现将其他多方面的影响因素纳入建筑物冗余清理模型,进一步优化冗余清理模型,以便更加精确地清理建筑物冗余是后续工作中需要继续探究的问题。3.2 冗余清理


3.3 冗余清理评价

4 试验与分析

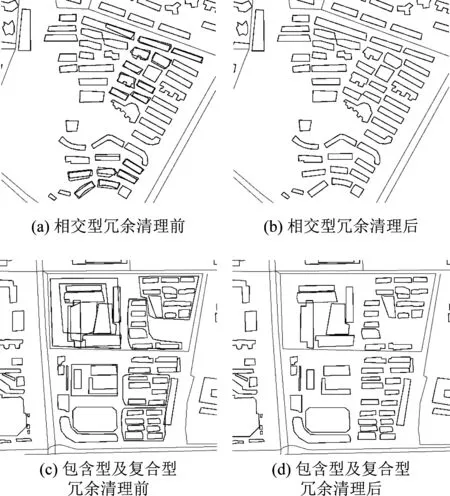


5 结束语
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-29铁道建筑技术(2021年4期)2021-07-21数学小灵通(1-2年级)(2021年4期)2021-06-09小学生学习指导(低年级)(2019年9期)2019-09-25Coco薇(2017年11期)2018-01-03暨南学报(哲学社会科学版)(2016年9期)2017-01-15小天使·二年级语数英综合(2015年12期)2015-12-04河南科技(2014年24期)2014-02-27中学英语之友·上(2008年2期)2008-04-01中学英语之友·上(2008年2期)2008-04-01
