
2015年中国PM2.5相关超额死亡数集成评估
2021-10-18 01:33:06王情许怀悦朱欢欢马润美班婕李湉湉
环境监控与预警 2021年5期
王情,许怀悦,朱欢欢,2,马润美,班婕,李湉湉*
(1. 中国疾病预防控制中心环境与人群健康重点实验室,环境与健康相关产品安全所,北京 100021;2. 河北科技大学环境科学与工程学院,河北 石家庄 050027)
空气污染对人类健康的影响已经成为重要的全球环境和公共卫生问题。全球疾病负担研究(Global Burden of Disease Study,GBD)显示,2019年全球死亡相关危险因素中,空气污染位居第4位,其中颗粒物的健康危害最为严重[1]。2019年颗粒物(PM)导致全球近414万人过早死亡,占2019年全球所有死亡人数的8.0%。其中一半以上的死亡(58%)发生在中国和印度。1990—2019年,可归因于PM的死亡人数约增长了50.6%。我国空气污染较为严重,2019年我国大气PM污染造成142.4万例超额死亡,约占全球的34.4%[2-3]。近年来中国采取了大量的防控措施来治理空气污染,空气质量得到了大幅度改善,但与世界平均水平相比,空气污染水平仍较高,随着人口的增长和老龄化,与空气污染相关的疾病负担形势不容乐观。细颗粒物(PM2.5)是我国首要空气污染物,因此,为有效减少空气污染对人群健康的有害影响,需要开展对PM2.5造成的疾病负担的评估,确定高负担的人群和地区,为制定和实施符合实际情况的空气污染治理和健康风险防控措施提供科学的参考依据。
目前,我国已有不少研究开展了PM2.5相关超额死亡的评估,但多基于单一来源的暴露数据或者国外研究的暴露-反应关系(exposure-response,E-R)展开评估,不确定性较高[4-7]。Wang等[8]结合4种不同来源的PM2.5暴露浓度和GBD研究中用到的综合暴露反应评估模型(Integrated exposure-response, IER)评估了2010年我国范围内2 826个县区PM2.5相关死亡风险,结果显示,全国由于PM2.5所致过早死亡人数为127万人。现阶段,基于我国人群队列数据获得的E-R开展的PM2.5慢性疾病负担研究仍较为欠缺。随着环境与健康研究的发展,目前我国已建立起相关人群队列,得到了一些基于本土人群暴露的空气污染对健康定量效应的成果,为我国空气污染相关疾病负担评估研究的开展提供了重要的本土化参数。为了降低评估结果的不确定性,现结合多种来源的PM2.5暴露浓度数据、国内外研究的E-R模型,进行不同情景下的归因于环境PM2.5的超额死亡数评估和分析,为相关的政策制定提供数据基础和科学依据。
1 研究方法
1.1 数据收集与预处理
收集了评估所需的PM2.5暴露浓度、全国区县人口数、基础疾病死亡率、PM2.5长期暴露死亡效应等数据集评估2015年我国不同情景的PM2.5长期暴露所致的超额死亡数。
1.1.1 PM2. 5暴露数据
基于本课题组前期开展的全国PM2.5时空模拟研究成果,即中国疾病预防控制中心环境所环境健康风险评估室(简称“环境所风评室”)数据[9],以及来自全球疾病负担评估(GBD 2015)、加拿大Dalhousie大学、美国Emory大学等研究团队[10-12]开展的PM2.5浓度模拟成果,共5套2015年中国PM2.5年均暴露浓度数据。
1.1.2 暴露-反应关系
收集了目前国内外PM2.5健康效应定量研究相关的最新研究成果,包括近年来我国多中心的人群队列研究成果[13-15],即Yin(2016),Li(2018),Yang(2020)3个研究得到的风险比(HR),分别为1.09[13],1.08[15],1.11[14],代表PM2.5暴露浓度每增加10 μg/m3,人群死亡风险分别增加8%,9%和11%;国外2套E-R模型:IER、全球暴露-死亡模型(Global Exposure Mortality Model, GEMM)[16-18],作为本研究的PM2.5慢性死亡效应模型。
1.1.3 人口和基础疾病死亡率数据
评估所需的全国2 826个区县的人口数据主要来源于2010年全国第六次人口普查,包括 0~84岁、85岁及以上的所有以5年为间隔年龄组的人口信息[19]。分疾病、分年龄的死亡率分别来自中国疾病预防控制中心慢性非传染性疾病预防控制中心(疾病终点为全因死亡数)[20]和全球疾病负担评估研究( GBD 2013) (疾病终点为慢性阻塞性肺病、缺血性心脏病、中风、肺癌和下呼吸道感染)[21],使用省级基础死亡率数据代表各区县的值。
1.2 情景设置
采用上述5种不同来源的PM2.5年均暴露数据和5种E-R模型组合成25种参数组合情景,见表1。
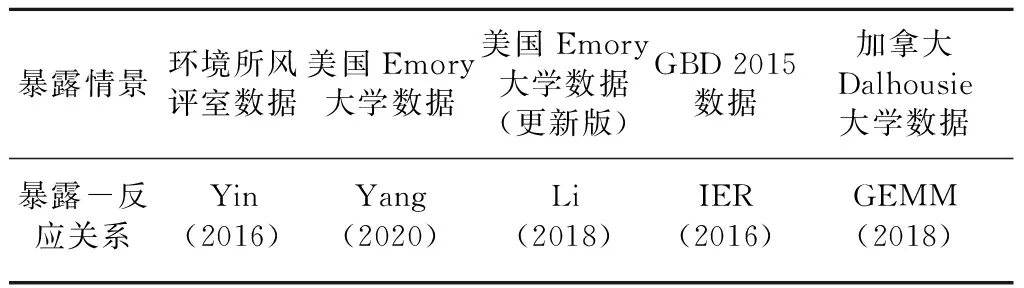
表1 情景设置
1.3 评估超额死亡数
1.3.1 国内暴露-反应关系
基于我国的队列研究得到3套PM2.5长期暴露的E-R[13-15],结合人口和全因死亡率数据,计算得到25岁以上成人与PM2.5相关超额死亡数,见公式(1)。

(1)
式中:M——区县内归因于环境PM2.5暴露的超额死亡人数,例;P——区县内25岁以上人口数,例;I——区县内25岁以上人群死亡率(基于人口普查死亡率),%;RR——主要是3种线性E-R的相对危险度取值(根据国内的3个队列研究得到的HR计算得出)。
1.3.2 国外暴露-反应关系
基于IER和GEMM模型的5种疾病终点的相对风险值来估计PM2.5相关超额死亡数,利用公式(2)估算了每个区县内不同年龄段的超额死亡数。其中每5岁为一个年龄段[16- 17]。
(2)
式中:Mi,j——区县内年龄段为i,疾病终点为j的可归因于PM2.5暴露的超额死亡数,例;Pi——区县内年龄段为i的人口数,例;Ii,j——区县内年龄段为i,疾病终点为j的对应死亡率,%;RRi,j——从IER和GEMM模型获取的对应的PM2.5浓度对应的相对风险值。
2 结果与分析
2.1 PM2.5质量浓度分布情况
2015年不同数据来源的中国PM2.5年均暴露质量浓度空间分布见图1(a)(b)(c)(d)(e)。由图1可见,不同数据来源的PM2.5浓度空间分布整体较为一致,但也存在一定差异。


图1 2015年不同数据来源的中国PM2.5暴露质量浓度空间分布
浓度较高地区主要分布在我国黄淮海地区和新疆西南部等地,西部、西南、内蒙古等地浓度较低。以本课题组前期研究成果(环境所风评室数据)为例,全国人口加权PM2.5质量浓度为52.30 μg/m3,其中京津冀地区及河南、山东西部等地污染最为严重,部分区县年均质量浓度>95 μg/m3。
2.2 PM2.5相关超额死亡数评估
根据5套2015年中国PM2.5暴露数据和5种E-R模型,对PM2.5相关超额死亡数进行评估,结果见图2。由图2可见,2015年全国(覆盖2 826个区县)归因于PM2.5相关的超额死亡数为75.0万~256.5万例。同一E-R模型,不同PM2.5暴露数据评估得到的PM2.5相关超额死亡数大小排序为:GBD 2015数据 > 环境所风评室数据> 美国Emory大学数据(更新版)> 美国Emory大学数据 > 加拿大Dalhousie大学数据。
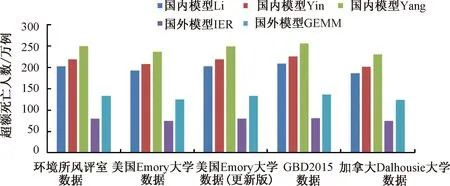
图2 不同情景评估的2015年中国PM2.5相关超额死亡数
基于不同E-R模型,评估2015年中国PM2.5相关的超额死亡数统计结果见图3。由图3可见,不同E-R模型评估得到的PM2.5相关超额死亡数大小顺序为:Yang(2020)>Yin(2016)>Li(2018)>GEMM(2018)>IER(2016)。基于国内E-R模型评估得到的超额死亡数为186.0万~256.5万例,而基于国外E-R模型(IER和GEMM模型)评估得到的超额死亡数为75.0万~133.2万例,基于国外模型评估得到的超额死亡数远小于基于国内的3个模型的评估结果。
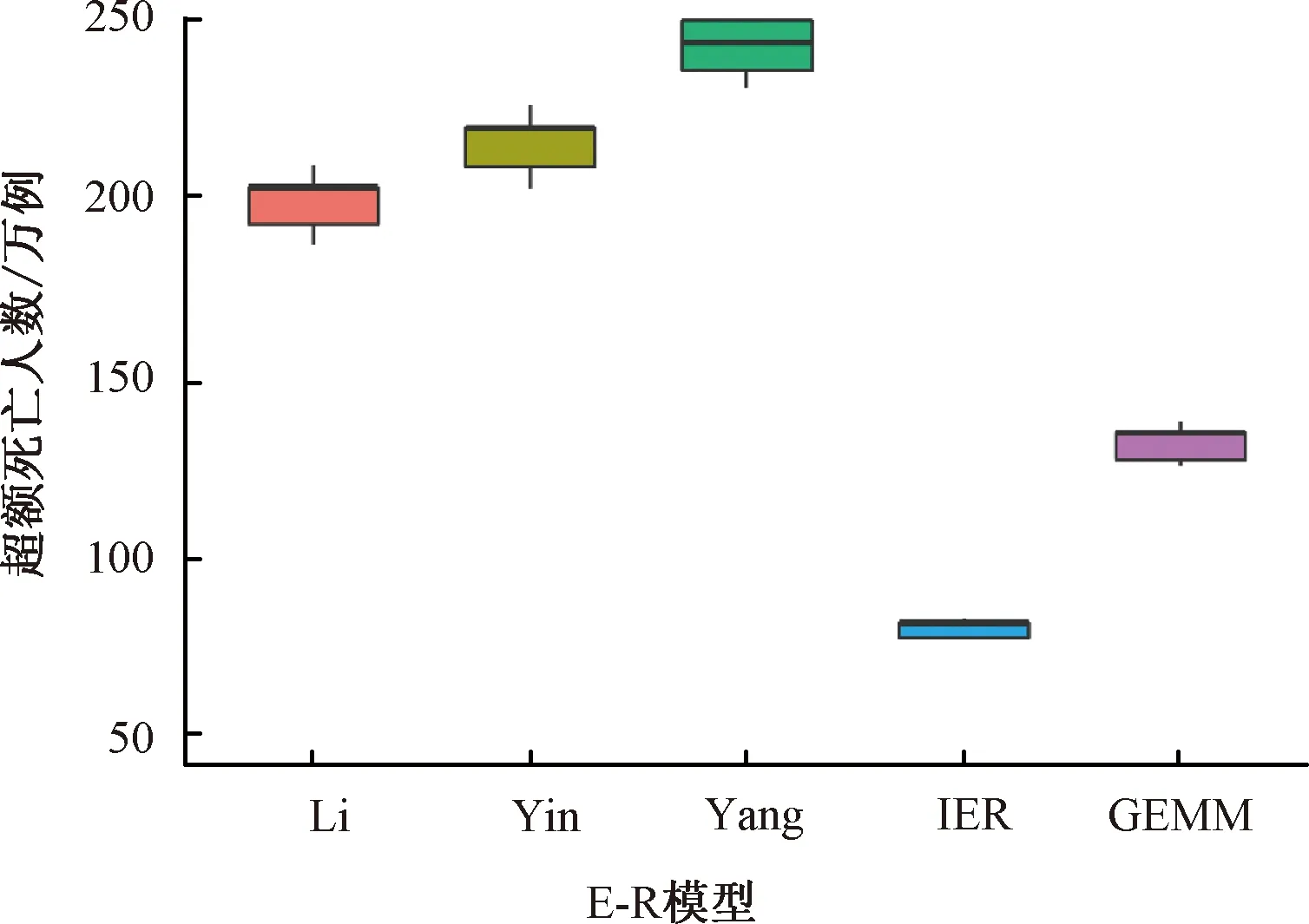
图3 不同E-R模型评估的2015年中国PM2.5相关超额死亡数
2.3 PM2.5相关超额死亡数的空间分布
各情景下PM2.5相关超额死亡数的空间分布格局较相似,污染较重、人口密集的黄淮海地区、四川盆地等具有较高的PM2.5相关超额死亡数。基于本课题组前期研究成果(环境所风评室数据)的PM2.5质量浓度数据,国外、国内不同E-R模型评估的2015年中国PM2.5相关超额死亡数的空间分布见图4(a)(b)和图5(a)(b)(c),其中红色代表PM2.5相关超额死亡较高的区县,绿色代表较低的区县。5种E-R模型评估结果在空间上的分布基本一致,主要为重污染地区的京津冀、山东、河南、新疆、内蒙古西部、西藏北部的超额死亡率较高。整体而言,大部分地区基于GEMM模型评估得到的PM2.5相关超额死亡数高于IER模型的评估结果;国内的3个模型中基于Yang(2020)的评估结果也高于另外2个模型的评估结果。

图4 国外E-R模型评估的2015年中国PM2.5相关超额死亡数的空间分布

图5 国内E-R模型评估的2015年中国PM2.5相关超额死亡数的空间分布
3 讨论
根据2015年中国生态环境状况公报[22]报道,2015年中国 PM2.5年均质量浓度为55 μg/m3,与本研究中几套PM2.5质量浓度数据的均值较为接近。由于中国地面监测站大多集中在中国中东部人口稠密地区,农村地区和欠发达省份(例如西藏、青海和内蒙古)较少,使用地面监测站获得的暴露数据通常会高估实际的全国PM2.5浓度均值[8, 23]。相反,使用卫星反演的数据在空间上能覆盖广大农村地区,因此,应用多套暴露数据进行评估能够更科学地表达人群暴露分布和造成的健康风险[8]。
研究发现,基于国内E-R模型评估的PM2.5相关超额死亡数远大于国外E-R模型的评估结果,这与疾病终点和死亡效应值有关。国外2个模型的疾病终点为5种主要病种,总死亡数远小于国内模型的全死因死亡数。同时,国内暴露反应关系模型的死亡数与浓度呈现正相关的线性关系[13-15],而国外为非线性关系,死亡数与浓度呈非正相关关系,超过一定的阈值后E-R曲线出现平稳状态[18]。虽然国内模型是基于我国人群的队列研究所得,暴露浓度与死亡数更能够准确表达我国的真实情况,但国内的线性模型可能高估了我国PM2.5死亡效应,国外的非线性模型更加符合人群死亡效应,因此,未来应该结合2类模型的优势,并结合更多的人群队列数据积累,获取更准确的E-R关系进而获得更可靠的PM2.5相关疾病负担评估结果。
目前,已有几项研究报告了我国部分地区或全国长期暴露于PM2.5导致的死亡负担[6-7, 24-25]。Liang等[23]基于1 530个地面监测站的数据和GEMM模型评估了2000—2016年全国PM2.5相关的超额死亡数,其中2015年成人超额死亡数约为160多万例,略高于在本研究的基于环境所风评室和GEMM模型在相同的疾病终点下评估全国的超额死亡数(133万例)。这可能是由于其使用的监测站数据对于暴露的评估高于本研究中基于模型模拟得到的暴露数据。因为现有空气质量监测站点大多分布在PM2.5浓度相对较高的城区和近郊,而空气质量较好的远郊和农村地区的监测站点则分布较少。Wang等[8]基于IER模型评估了2010年我国2 826个县区PM2.5相关的超额死亡数为127万例,其中针对成人主要包括慢性阻塞性肺病、肺癌、缺血性心脏病、脑卒中等;而5岁以下儿童则多死于急性下呼吸道感染。从空间差异来看,由于较高的空气污染及人口密度,京津冀地区和华北平原风险较高。Liu等[4]评估了全国PM2.5相关的超额死亡数从 2004 年的80万例增加至 2012 年的120万例,其中疾病终点针对成人的肺癌、缺血性心脏病和中风。空间上超额死亡数较高为京津冀、长三角、珠三角、四川盆地、山东、河南等空气污染较重的地区或人口密度高的地区。本研究的PM2.5相关超额死亡数的空间分布与以上2项研究结果相似。
我国作为一个人口众多、幅员辽阔的发展中国家,空气污染水平、人口密度、年龄结构和经济发展在空间上存在巨大差异,因此空气污染防治和健康风险防控政策措施也应根据各地特征,因地制宜地制定。在本研究中,京津冀地区、山东、河南等重污染地区,以及空气相对清洁但人口密度较高的广东的超额死亡数较高。因此,污染严重的地区需重点关注,加强空气污染防控和减排;同时对于人口稠密的地区需要制定更严格的空气质量标准和政策,降低其健康危害和疾病负担。
本研究采用了最新的暴露数据集和E-R模型进行参数组情景设置,以了解中国PM2.5相关超额死亡数的空间分布差异。与之前的研究相比,具有一定的创新性。首先,本研究使用了5套不同数据来源的PM2.5暴露浓度数据,覆盖了全国范围内的区县,可以有效地减少评估疾病负担时与暴露估计相关的不确定性。其次,之前的评估研究大多运用国外研究的IER 和GEMM的E-R模型,而本研究基于我国本土人群队列数据获得的E-R开展PM2.5慢性疾病负担研究,同时运用多种E-R模型评估,得到疾病负担的区间范围,有利于减少评估的不确定性。
本研究存在一定的局限性,如疾病的基础死亡率是省级尺度的,区县级基础死亡率对于评估区县级的超额死亡数及其空间分布更为科学,但目前区县级分病种的基础死亡率数据无法获取,因此采用了省级基线死亡率数据。为了使未来研究结果表达更加科学,中国应系统地收集和提供县级疾病特定基线死亡率的统计数据[8]。
4 结语
应用多种来源的 PM2.5暴露浓度数据和E-R模型评估了2015年中国PM2.5相关超额死亡数,观察到不同E-R模型得到的疾病负担差异较大,运用国内研究的E-R模型评估的疾病负担结果较国外模型的评估结果更大。未来应加强我国PM2.5与人群健康的队列研究,基于中国国内的E-R模型和考虑人口结构变化的影响开展PM2.5相关疾病负担的评估与预估研究,为PM2.5健康风险的精细化定量化探索提供线索。
猜你喜欢
环球时报(2022-06-11)2022-06-11 17:17:47
环球时报(2022-06-10)2022-06-10 21:16:07
中老年保健(2021年4期)2021-08-22 07:07:02
今日农业(2021年5期)2021-05-22 01:32:38
科学之谜(2020年6期)2020-08-11 07:37:21
当代水产(2019年8期)2019-10-12 08:57:56
意林(绘英语)(2018年1期)2018-04-28 01:21:42
新闻传播(2016年20期)2016-07-10 09:33:31
中国猪业(2016年1期)2016-04-21 03:50:52
中国水利(2015年13期)2015-02-28 15:14:04
