
利用优化剪枝GoogLeNet的人脸表情识别方法
2021-10-14 06:34张宏丽白翔宇
计算机工程与应用 2021年19期
张宏丽,白翔宇
1.内蒙古师范大学 教育技术系,呼和浩特 010022
2.内蒙古大学 计算机学院,呼和浩特 010021
如今,计算机技术发展迅猛,网络化学习、医疗、交通以及社会安全等领域都广泛应用了自动面部表情识别技术[1-2]。大多数方法都是在用户头部位于正面或近正面状态下进行的表情识别,人脸基本不受遮挡的影响[3]。然而,该限制条件使得表情识别算法的鲁棒性大大降低。除此之外,还有些方法是通过直接约束用户,对用户相关的表情特征进行学习。该特征对用户的身份信息特别敏感,因此,对未知用户的识别鲁棒性有待提升[4]。
目前面部表情识别主要分为两种方式:一种是单帧图像,另一种是视频图像。前者主要是从输入中提取特征图像,后者则能对图像序列的时间信息和每一个静态图像的特征进行提取[4-6]。一些面部表情识别系统在某些图像数据集中可能有很好的性能,但在其他数据集中表现较差,对人脸表情识别的鲁棒性仍有提升的空间[7-8]。
基于上述分析,针对人脸表情识别准确率和数据集通用性等问题,提出了一种基于优化剪枝GoogLeNet的人脸表情识别方法。所提方法的创新点总结如下:
(1)为了提高特征提取的准确性,对GoogLeNet 网络进行改进,去掉最后一个全连接层并保留检测目标的位置信息,添加全局最大池化层,以Sigmoid交叉熵作为训练的目标函数,从而获得更加全面的特征信息。
(2)GoogLeNet 网络中存在参数冗余、计算量较大等问题。因此,所提方法使用剪枝算法来进行网络稀疏化,通过训练网络、修剪低权重连接和再训练网络三步操作,只保留卷积层和完全连接层中的强相关连接,简化了网络结构,减少了参数量,从而提高执行效率。
1 相关工作
面部表情对应人的内心情绪状态、意图或社交信息的脸部变化。文献[9]定义了“愤怒”“厌恶”“恐惧”“快乐”“悲伤”“惊喜”六种人的基本表情,后面又加入了“蔑视”这一表情。人脸表情识别在计算机视觉领域中是个传统问题,也是人工智能技术中的重要部分,逐渐受到越来越多人的关注,学者们提出了大量的新方法[10]。
例如,文献[11]提出了一种融合HOG 特征和改进KC-FDDL(K-means Cluster and Fisher Discrimination Dictionary Learning)字典学习稀疏表示的人脸表情识别算法。对归一化后的表情图像提取HOG特征构成训练集并进行改进的K-均值聚类的Fisher判别字典学习,结合残差加权的稀疏表示进行表情分类,克服了人脸表情识别过程中光照和遮挡等问题带来的影响。然而,该方法不能为遮挡区域恢复充分的表情信息。文献[12]采用稀疏编码和字典学习方法来研究2D 和3D 地标的Kendall 形状空间上的时变形状,研究了固有和非固有解以克服形状空间的非线性对面部表情包括动作轨迹识别的影响。但该方法对数据集的依赖度较高,不同的数据集对于识别结果有较大的影响[13]。
近年来,卷积神经网络(Convolutional Neural Networks,CNN)在图像分类邻域做出了很大的贡献,随之涌现出很多基于CNN 的表情识别方法,弥补了传统方法中鲁棒性较差的问题[14]。如文献[15]提出了一种基于变异特征减少模型与迭代优化分类策略的面部表情识别(Facial Expression Recognition,FER)方法,利用基于加权补丁的局部二进制模式(Weighted Patch-based Local Binary Patterns,WPLBP)进行特征提取,并进行表达分类,提高了表情识别的准确性。但对于特征提取过程的准确性还有进一步提高。文献[16]提出了一种无监督域自适应字典学习(Unsupervised Domain Adaptive Dictionary Learning,UDADL)模型,通过学习共享字典来桥接源域和目标域,并借用分析词典来寻找近似解决方案作为潜在变量以简化识别步骤。文献[17]提出了一个共同学习FER 的空间特征和时间动态的框架。使用深度网络从每个帧中提取空间特征,同时通过卷积网络对时间动态建模,并通过BiLSTM网络从融合的功能中收集线索完成面部表情识别,然而实际当中的用户身份是难以限定的。文献[18]提出一种利用生成对抗网络(Generative Adversarial Network,GAN)识别面部表情的方法,重点针对真实环境面部表情识别过程中的类内差距较大的表情进行识别,使其更好地适应类内差异较大的任务。
如今,GoogLeNet 和ResNet 等CNN 模型成为了人们常用的模型,表情识别算法通过使用数据驱动的方式将用户无关的表情特征从表观信息中提取出来。文献[19]将CNN、AlexNet 和GoogLeNet 模型应用于水果识别,以区分不同情形下的水果种类,因此结合适当的数据集,可以将其应用于人脸表情识别。然而,通过直接采用CNN提取表情图像数据的特征会受到类内差异的限制,想要得到预期的性能难度较大。文献[20]提出了一种基于GoogLeNet 的ILGNet 网络模型,结合了初始模块和具有局部和全局特征的连接层,使用经过预训练的GoogLeNet来解决大规模图像分类问题。然而,用户身份以及图像采集条件的表观差异造成了表情的类内差异,因此,常常会导致表情特征可辨别性的鲁棒性较差。
2 GoogLeNet
GoogLeNet采用多个分类器结构,并且将多个来源相结合进行反向传播,采用了一种新颖的多尺度方法。在达到开始层之前后向传播衰退时可能会存在一些问题,该类架构能尽可能地消除这些问题,且减少维度的附加层允许GoogLeNet 在宽度和深度上无显著损失。该体系结构包含多个初始层,其中每层都类似于大型网络中的微型网络,能够允许架构进行更为复杂的决策。该架构整合了多种尺度的卷积核以及池化层,最终形成一个Inception 模块,如图1 所示,显著减少了模型的参数数量。

图1 Inception模块结构Fig.1 Structure of Inception module
典型的Inception 模块主要由三个尺寸各不相同的卷积核和一个最大池化单元构成,它们共同对前一层的输入图像进行接收,且能并行地处理输入的图像,再将输出结果根据通道进行拼接。1×1 卷积的作用主要是进行降维,由于卷积操作中接收到的输入图像大小相同,且卷积还进行了padding操作,因此输出图像的大小也相同,从而能够根据通道进行拼接。
学者们采用了多种不同的方式对Inception 架构进行改进。在Inception-v2中,对所有mini-batch数据的内部执行批量标准化处理,从而让每层的输出都能规范化到一个N(0,1) 的高斯核,再将两个连续的3×3 卷积层组合来替代Inception 模块中的5×5 卷积层,既能保持感受野范围,又能减少参数量,加快计算速度。在Inception-v3 中加入了分解思想,即对较大的二维卷积进行拆分,使其变为两个较小的一维卷积,例如对7×7的卷积进行分解,将其分解为两个一维的卷积(1×7,7×1),以此增加网络的非线性。Inception-v4 比v3 版增加了Inception模块的数量,对整个网络进行了加深。
3 提出的面部表情识别方法
面部表情识别系统中,人脸图像数据集作为输入,利用GoogLeNet 网络结合支持向量机(SVM)等传统分类器对采集到的图像进行分析。系统的总体结构如图2所示。
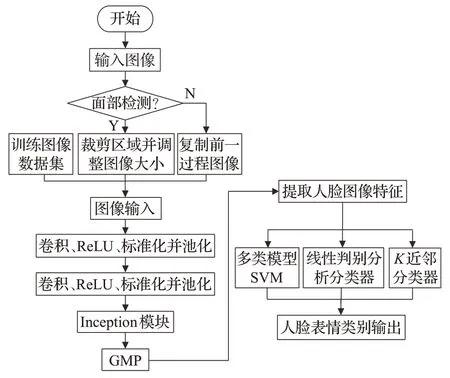
图2 系统的总体结构Fig.2 Overall structure of the system
在系统中,首先进行图像预处理,去除不必要的图像部分,如图像的背景,并需要裁剪的区域。使用类别激活映射图(Category Activation Mapping,CAM)来定位图像中人脸的位置,且从图像中裁剪出合适的面部部分。然后,将图像输入优化剪枝CoogLeNet网络以提取深层特征,其中采用Inception 模块加深网络学习深度,同时利用剪枝算法训练CoogLeNet网络,以降低模型的数据冗余。最后,结合优化剪枝CoogLeNet网络的学习结果,利用分类器实现人脸表情的识别,分别是中性、高兴、悲伤、生气、惊讶、厌恶和害怕。
3.1 网络结构
面向人脸表情特征提取与定位GoogLeNet网络结构的设计参考了全局最大池化(Global Maximum Pooling,GMP)网络的设计,使用CAM 设计思想来加强特征图中的位置信息。因此,GoogLeNet-GMP 的网络结构如图3所示。

图3 GoogLeNet-GMP模型结构Fig.3 Structure of GoogLeNet-GMP moudle
所提网络结构中采用GoogLeNet Inception v3 作为基础网络,将GMP 层加在最末位的Inception 模块之后,再将原网络的稀疏全连接层替换为Sigmoid 全连接层,最后一个卷积层的第k个特征图由fk(x,y)表示,经过GMP后,类别i的得分Si计算如下:
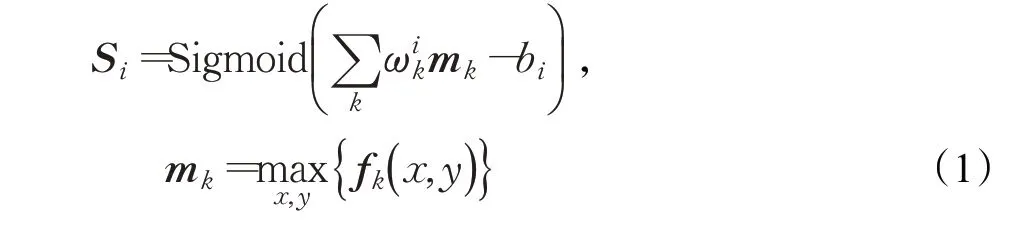
以Sigmoid 交叉熵函数为目标函数训练,逼近多类标签的概率分布,生成类别激活热图ψi的表达式为:

CoogLeNet-GMP 网络结构参数如表1 所示,其中Inception 模块按结构差异分为5 类。特征图通过GMP后,输出大小为1×1×2 048。

表1 CoogLeNet-CMP网络的结构参数Table 1 Structural parameters of CoogLeNet-CMP network
GoogLeNet网络最后使用sofmax函数进行分类,在人脸表情识别过程中,需要对多个目标进行检测,因此使用Sigmoid 交叉熵函数进行替换,使用所有样本的平均Sigmoid 交叉熵函数值作为目标函数,对网络进行训练,实现多分类预测。
3.2 特征提取
在所提的人脸识别方法中,GoogLeNet作为一个深层特征提取器来提取图像特征,然后,利用这些特征训练传统的分类器。所得到的识别精度略有提高,且特征提取快速简单[21]。另外,由于特征提取只需要对数据进行一次处理,CPU也能完成这项工作。与训练一个新的网络相比,使用预先训练的GoogLeNet网络来提取深层特征的优点在于:(1)所需的计算能力更小;(2)实现高识别精度所需的数据更少。
为了论证GoogLeNet网络的特征提取能力,需要将网络提取的深层特征可视化。所提方法中使用T-SNE(随机邻居嵌入)方法将GoogLeNet 提取的特征进行可视化。T-SNE函数将高维数据转换为低维数据,是一种降维算法,能够可视化人脸图像的高维数据[22-23]。一般情况下,高维空间中的远点将转换为远处的嵌入低维点,而高维空间中的邻近点将转换为邻近的嵌入低维点。因此,可以将低维点可视化,从而在原始高维数据中找到簇。由GoogLeNet 从数据集中学到的人脸图像所提取的特征如图4 所示。由图4,GoogLeNet 网络能够准确提取出生气、厌恶、害怕、高兴、悲伤、惊讶、中性等表情,将其用于人脸别情特征的提取是可行的。

图4 利用T-SNE可视化GoogLeNet提取的特征Fig.4 Visualization of features extracted by GoogLeNet using T-SNE
3.3 剪枝
网络剪枝实质是一种网络稀疏化技术,其优势在于能有效地避免过拟合,使网络规模的扩大和训练速度的提高成为可能。其主要思路是在对某个较大的神经网络进行训练时,对其中无用的连接进行移除。通过去除某个单元来删除其本身及其所有的输入输出连接。网络架构的尺寸越大,则对初始条件越敏感,网络剪枝效果越好。
3.3.1 正则化与弃置层
正则化方式的选用将会对剪枝以及再训练造成一定的影响。通过使用L1 正则化对非零参数进行惩罚,能让更多的参数趋近于0,使得修剪后再训练之前的准确性更高。
弃置层常用于防止过拟合,若能调整弃置率来适应网络架构的变化,则弃置层也可用于再训练。利用Hinton构建的弃置算法中的参数不会被全部丢弃,而是以一定的概率丢弃,因此,可视其为“软弃置”。修剪则是“硬弃置”,无法对修剪后置零的参数进行恢复。由于矩阵稀疏化,分类器会选择最多的信息预测因子,所以具有更少的预测方差,这缓解了过拟合问题。由于剪枝对模型的泛化能力进行了有效提升,因此,在再训练阶段的弃置率会更小。

其中ϑi表示第i层中的连接数,ϑi0为原始网络,ϑir代表再训练网络,Ni表示第i层中神经元的数量;原始弃置率由κ0表示,再训练时的弃置率记为κr(受弃置层的影响),且ϑi与Ni有着平方关系。
3.3.2 局部剪枝和参数协同适应
进行再训练时,不应将剪枝网络的参数再进行初始化,剪枝后剩余连接的权重应是再训练阶段所得的权重。卷积神经网络脆弱的协同适应特征:在原始训练权重下,网络模型使用梯度下降能持续进行优化,并使精度得到恢复。然而,当对部分层级参数执行重新初始化操作后,重新训练无法得到预期的效果[24-25]。因此,若需对剪枝网络重新进行初始化,必须进行重新整理。若在剪枝网络上进行再训练,则需对剩余连接的原始参数进行保留。
从保留权重开始对已修剪的层进行重新训练,只需要少量计算,无需经过全网传播。除此之外,网络深度的增加,会使神经网络易受消失梯度的影响,从而难以对深层网络中的修剪错误进行恢复。针对该问题,通过对网络中部分参数进行修复,重新使用幸存参数对浅层网络进行训练,这些参数在初始训练阶段就与未修剪层进行了共同适配。
3.3.3 修剪神经元
经过对连接的修剪后,便可以对有零输入或零输出连接的神经元进行安全的修剪,用去除或对神经元进行修剪的方式来进行修剪。在进行再训练时,处于再训练阶段时,由于梯度下降和正则化,当到达零输入以及零输出连接的死神经元时,系统会自动地进行赋值,死神经元不会对最终的损耗有贡献,导致其输入和输出连接的梯度均为零。只有正则化能将权重置为零,因此在该阶段会自动对死神经元进行剪除。
4 实验结果与分析
本次实验是基于MATLAB 仿真平台进行的,硬件环境为:Microsoft Windows 10 操作系统,CPU 型号为E5-1620 v4,时钟频率为3.5 GHz,采用的显卡为NVIDIA Quadro M2000,显存大小为2 GB,本次实验使用的是基于Caffe的深度学习平台。
在本次实验中,GoogLeNet 网络模型训练250 个周期,最小批次是64,其初始学习率和学习率变化因子分别为0.01和0.96,每一个步长在进行迭代之后,降低学习速率,最大迭代次数、动量以及权重衰减分别为2 000、0.9和0.000 2。在1 600次迭代后,已经形成了GoogLeNet网络之间的连接关系,后面的迭代训练是为了增强相关性和消除噪声,因此,选择第1 600 次训练的模型作为剪枝模型,利用最终剪枝后的模型来进行人脸表情识别。
4.1 JAFFE数据集实验
JAFFE 是一个只有213 个静态图像的面部表情数据库。利用JAFFE数据集,通过不同的训练方法测试少量图像对系统训练的影响。从JAFFE数据集中,选择了202幅图像,这些图像都是使用图像预处理技术处理后的(JAFFE 数据集包含一些错误标记的面部表情,后期进行删除)。在这个数据集中有7 种不同的面部表情:生气、高兴、中性、惊讶、悲伤、害怕和厌恶。JAFFE数据集的部分图像示例如图5所示。
图5 JAFFE数据集的部分图像示例Fig.5 Some image examples of JAFFE dataset
在每次测试中,随机选取70%的图像作为训练图像,其余图像作为测试图像。在JAFFE数据集上对所提方法的识别效果进行实验论证,7种表情的混淆矩阵如图6所示。

图6 JAFFE数据集的表情识别混淆矩阵Fig.6 Expression recognition confusion matrix based on JAFFE dataset
从图6 中可以看出,本文方法在7 类人脸表情的识别准确率均高于60%,其中高兴、悲伤和惊讶表情的识别准确率均高于85%,高兴表情最易于识别,准确率为89%。由于生气和厌恶的表情在某些情况下彼此相似,导致它们在像素空间中并没有区别,因此经常会引起混淆。此外,JAFFE 数据集图像数量较少,对于剪枝后的GoogLeNet 网络较为适用,因此整体的识别效果较为理想。
为了论证本文方法在JAFFE 数据集中人脸表情的识别性能,将其与文献[15]、[17]、[18]中方法进行对比,5倍交叉验证的错误率如表2所示。

表2 JAFFE数据集中不同方法交叉验证的错误率对比Table 2 Error rate comparison of different cross validation methods in JAFFE dataset %
从表2 中可以看出,本文方法的错误率最低,为8.91%。由于JAFFE 数据库中的图像数量非常少,深层GoogLeNet尚未展示最佳的性能,因此GoogLeNet网络的性能与文献[18]中采用GAN 的识别效果较为接近。但本文方法采用优化剪枝算法GoogLeNet网络模型,并且采用Inception模块加深学习的深度,因此表情识别的效果更佳。
此外,在JAFFE 数据集中,本文方法与其他对比方法(文献[15]、[17]、[18]方法)获得的每种情绪识别准确率和总体识别准确率,如表3所示。
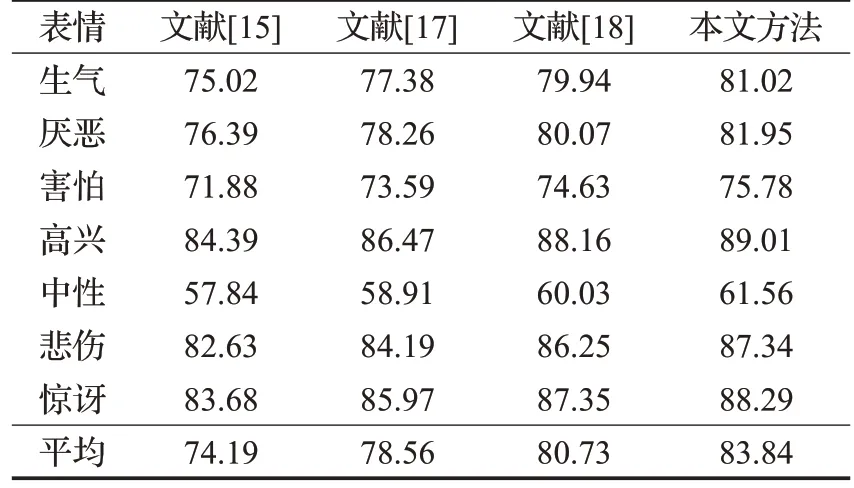
表3 不同方法在JAFFE数据集的表情识别准确率Table 3 Expression recognition accuracy obtained by different methods in JAFFE dataset %
从表3 可以看出,无论是每种情感识别准确率还是总体识别准确率,本文方法获得的结果均高于其他对比方法,其总体识别准确率为83.84%。由于本文方法采用优化剪枝GoogLeNet网络,其中采用Inception模块较深学习的深度,以获得表情的深度特征,同时利用剪枝算法简化模型,整体上提高人脸表情识别的性能。文献[15]利用WPLBP 提取表情特征,以迭代优化分类策略实现表情识别,但该方法受提取精度的影响较大,因此分类准确率较低,总体识别准确率为74.19%。文献[17]使用深度网络从每个视频帧中提取空间特征,同时通过BiLSTM 网络完成面部表情识别,从时间和空间两个角度完成人脸的识别,约束条件较多,识别准确率受到了一定的限制,其总体识别准确率为78.56%。文献[18]中采用GAN 实现面部表情识别,该方法主要用于识别具有较大类内差距的表情,因此,对于类内差距较小的表情,识别效果并不显著,如中性与害怕表情。
4.2 CK+数据集实验
CK+数据集包含593个面部表情序列,每个视频序列可以看作是几个连续的视频帧,其中有来自123个模特的大约10 000 张面部表情图像。由于这些图像序列是连续的,因此有很多相似的图像。实验中,在去除相似图像后,选取693 幅图像,并使用图像预处理技术进行处理。数据集中选取了具有生气、高兴、中性、惊讶、悲伤、害怕以及厌恶这7种表情的图像。CK+数据集的部分图像示例如图7所示。

图7 CK+数据集的部分图像示例Fig.7 Some image examples of CK+dataset
在每次测试中,随机选取70%的图像作为训练图像,其余图像作为测试图像。在CK+数据集上对所提方法的识别效果进行实验论证,7种表情的混淆矩阵如图8所示。
从图8 中可以看出,所提方法在7 类人脸表情的识别准确率均高于60%,其中高兴、悲伤表情的识别准确率分别为94%、93%,惊讶、害怕和厌恶的表情识别率均超过80%。因为生气和厌恶的表情在某些情况下彼此相似,导致它们在像素空间中并没有区别,因此容易引起混淆。此外,CK+数据集图像数量多,有利于模型训练,因此整体的识别准确率较高。
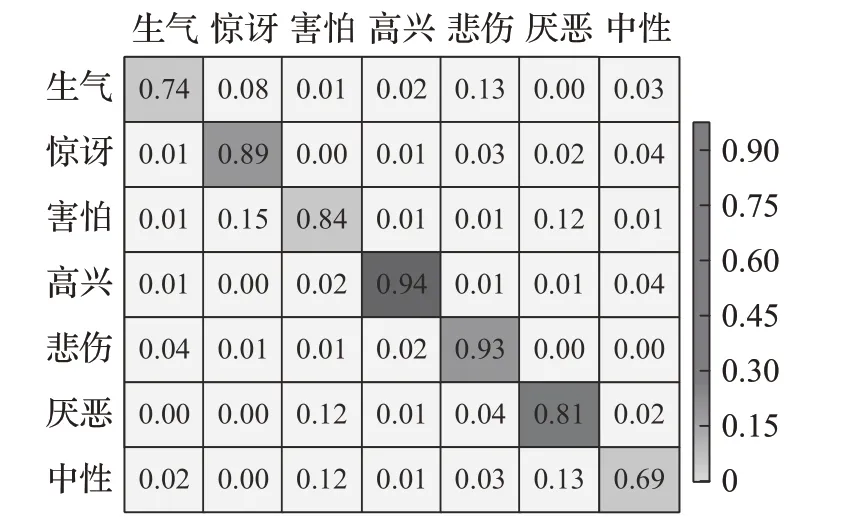
图8 CK+数据集的表情识别混淆矩阵Fig.8 Expression recognition confusion matrix of CK+dataset
为了论证本文方法在CK+数据集中人脸表情的识别性能,将其与文献[15]、[17]、[18]中方法进行对比,5倍交叉验证的错误率如表4所示。

表4 CK+数据集中不同方法交叉验证的错误率对比Table 4 Error rate comparison of different cross validation methods in CK+dataset %
从图4中可以看出,本文方法仍然获得最低的错误率。一般来说,在CK+数据集中,为每个受试者的每个表情选择两个图像,其中一个图像是情绪开始表达时的帧,而另一个图像是情绪达到其表情峰值时图像序列中的帧。通过两个图像的结合共同进行分类,能够减少错误率,因此本文方法的错误率相比于JAFFE数据集均有了一定的下降。本文方法采用GoogLeNet网络,其中利用Inception模块较深学习深度以及利用GMP保留位置信息,能够降低错误识别的可能性。
此外,在CK+数据集中,本文方法与其他对比方法(文献[15]、[17]、[18]方法)获得的每种情绪识别准确率和总体识别准确率,如表5所示。
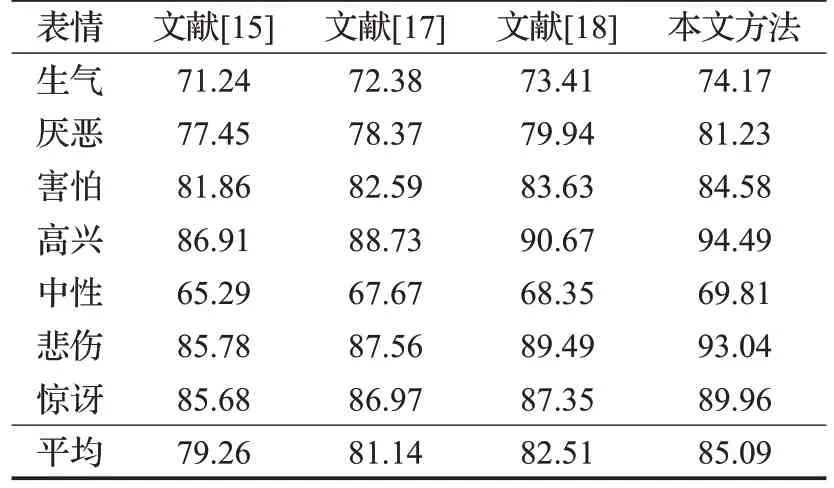
表5 不同方法在CK+数据集的表情识别准确率Table 5 Expression recognition accuracy obtained by different methods in CK+dataset %
从表5中可以看出,无论是每种情感识别准确率还是总体识别准确率,本文方法获得的结果均高于其他方法,其总体识别准确率为85.09%。由于本文方法采用优化剪枝GoogLeNet网络,其中采用Inception模块较深学习的深度,以获得表情的深度特征,同时利用剪枝算法简化模型,整体上提高人脸表情识别的性能。文献[15]利用WPLBP 提取表情特征,并且迭代优化分类策略实现表情识别;文献[17]利用BiLSTM 网络结合深度网络提取的提取空间特征以及时间特征完成人脸的识别;文献[18]利用GAN 实现面部表情的识别。相比于其他3种方法,本文方法的总体识别准确率分别提高了7.32%、4.87%和3.12%,其人脸表情识别性能的优越性得以论证。
4.3 Cohn-Kanada数据集实验
Cohn-Kanade 人脸表情数据库建于2000 年,是由CMU机器人研究所和心理系共同创建的。该数据集中由100 位女性成年人的约500 张多种表情序列组成,包括非裔美洲人、拉丁美洲人、亚洲人等。实验需要对图像进行归一化处理,得到大小均为64×64的图像,其中,部分图像如图9所示。

图9 Cohn-Kanade数据集的部分图像示例Fig.9 Some image examples of Cohn-Kanade dataset
在Cohn-Kanade 数据集上对本文方法的识别效果进行实验验证,随机选取20个研究对象,每个对象包含6 张不同表情的图像,随机选取10 个对象用于训练,剩下的10个对象用于测试,进行30次实验取平均值,6种表情的混淆矩阵如图10所示。
从图10 中可以看出,本文方法每个表情的识别准确度均高于75%。由于该数据集中没有中性表情,因此害怕、厌恶等表情不会与中性表情出现混淆,因此准确率均有了一定的提高。同样,高兴、悲伤表情易于识别,其识别准确率分别为92%和91%,均高于90%。
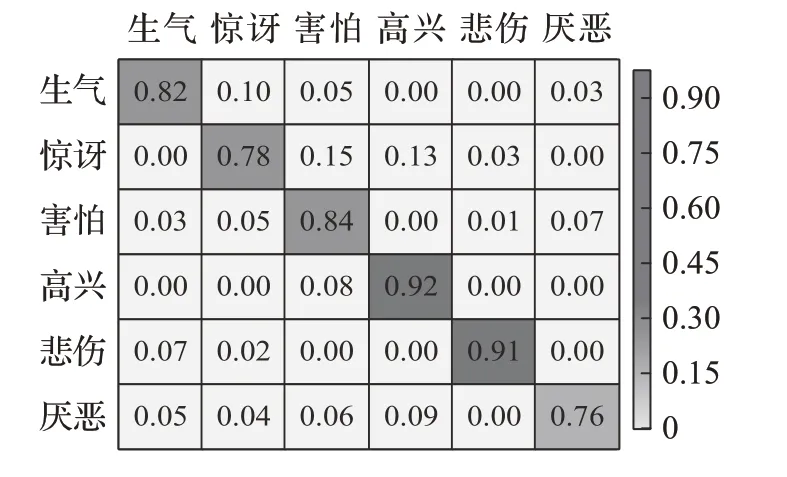
图10 Cohn-Kanade数据集的表情识别混淆矩阵Fig.10 Expression recognition confusion matrix of Cohn-Kanade dataset
为了论证本文方法在Cohn-Kanade 数据集中人脸表情的识别性能,将其与文献[15]、[17]、[18]中方法进行对比,5倍交叉验证的错误率如表6所示。

表6 Cohn-Kanade数据集中不同方法的错误率Table 6 Error rate of different methods in Cohn-Kanade dataset %
从图6 中可以看出,本文方法获得了最低的错误率,为6.92%。由于该数据集的图像数量有限,网络学习受限,因此错误率高于CK+数据集,但由于其中缺少中性表情,避免了表情混淆的发生,因此错误率低于JAFFE数据集。
此外,在Cohn-Kanade 数据集中,本文方法与其他对比方法(文献[15]、[17]、[18]方法)获得的每种情绪识别准确率和总体识别准确率,如表7所示。

表7 不同方法在Cohn-Kanade数据集的表情识别准确率Table 7 Expression recognition accuracy obtained by different methods in Cohn-Kanade dataset %
从表7 中可以看出,与JAFFE、CK+数据集的识别结构一致,本文方法在每种表情和总体识别准确率均均高于其他对比方法,其总体识别准确率为84.87%。由于所提方法采用优化剪枝GoogLeNet 网络,其中采用Inception 模块较深学习的深度,以获得表情的深度特征,同时利用剪枝算法简化模型,整体上提高人脸表情识别的性能。文献[15]的识别准确率受WPLBP方法特征提取精度的影响较大,因此分类准确率不高,总体识别准确率为78.85%。文献[17]结合了表情的时空特征,通过卷积网络对时间动态建模,特征提取的难度较大。文献[18]针对面部表情识别过程中的类内差距较大的表情利用GAN 实现面部表情的识别,应用场景相对单一,识别效果有待提高。
4.4 影响平均识别率的其他因素
为了进一步评估本文方法的性能,将其与文献[15]、[17]、[18]中方法从训练网络的运行时间、人脸表情识别准确度两个方面进行评估。不同方法在JAFFE、CK+和Cohn-Kanade数据集上的识别精度和运行时间,如图11所示。
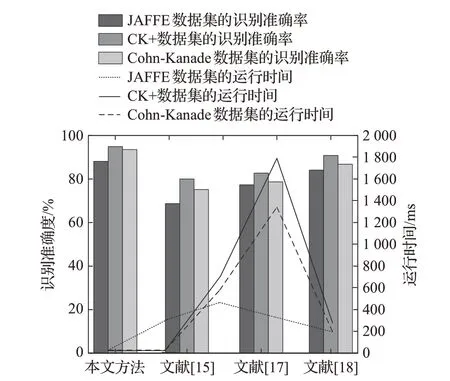
图11 运行时间与识别精度的对比Fig.11 Comparison of running time and recognition accuracy
从图11中可以看出,在在JAFFE、CK+和Cohn-Kanade数据集上,与其他方法相比,本文方法均具有较高的识别准确率,并且运行时间也较短。因为本文方法采用的GoogLeNet网络具备Inception模块,且融合GMP 模块,能够加深学习深度,获得较高的识别准确率。同时,本文方法利用剪枝算法对GoogLeNet网络进行稀疏化,能够减少训练的时间。而文献[17]中利用BiLSTM网络结合深度网络提取的空间特征以及时间特征完成人脸的识别,识别系统数据量,因此运行时间最长,在CK+数据集上的运行时间接近1 800 ms。文献[15]中的WPLBP方法以及文献[18]的GAN模型系统构成简单,因此在运行时间上,较文献[17]有所减少,但识别精度低于所提方法。
此外,训练图像与测试评估中使用的图像的比例能够评估不同方法的训练图像比例对所选数据集的影响。在实验中,将数据集中70%的图像作为训练集,剩下的作为测试集。以JAFFE数据库为例,使用不同方法的训练图像的不同比例以及由此产生的识别准确率如图12所示。
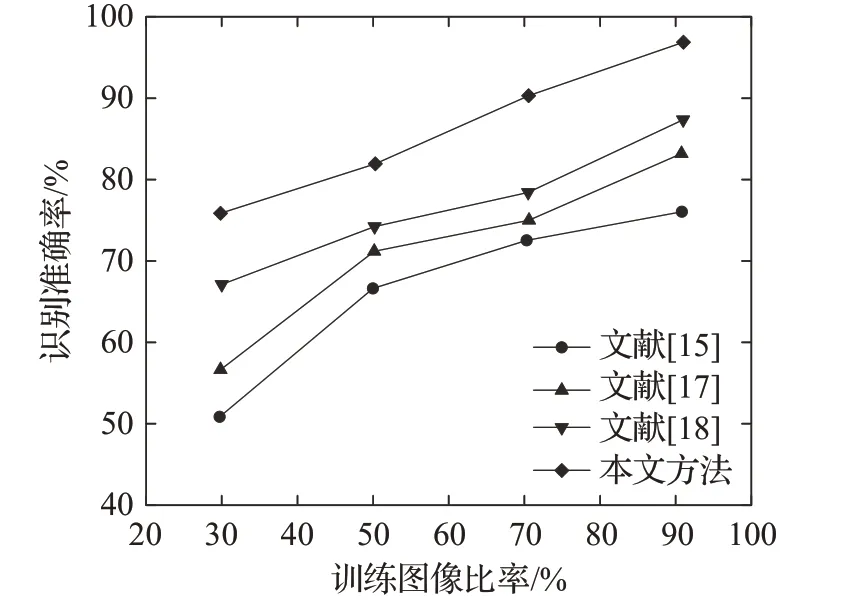
图12 训练图像比例对不同方法识别准确率的影响Fig.12 Influence of training image proportion on recognition accuracy of different methods
从图12中可以看出,当训练图像比率增加时,所有方法的识别精度都会提高,并且无论所测试的训练图像比例如何,本文方法都表现出最佳的性能。事实上,当从JAFFE数据库中随机抽取90%的图像作为训练图像,并将剩余图像作为测试数据集时,该方法的识别准确率达到96.0%。
4.5 消融实验
为了明确各个网络部件对分类性能和运行效率的影响,以JAFFE 数据集为例进行消融实验,测试高兴、悲伤、生气、惊讶、害怕和厌恶的6 种表情的平均准确率。
本文方法包括4个主要部分:特征提取模块、Inception模块、GMP 模块和分类模块,分类模块由3 个常用的分类器组成。由于分类模块对于本文网络中进行分类是必要的,因此保留分类模块,并分别删除特征提取模块,Inception模块和GMP模块,然后进行不同实验,结果如表8 所示。可以看出,当删除其中一个模块时,与完整网络相比,平均识别率均有一定程度的下降。特别是在没有特征提取模块的情况下,识别率下降最多,只有51.72%。一般,获得的初始特征过于粗糙,直接进入后续处理会严重影响后续结果。因此,特征提取模块在网络中是必需的。Inception模块是本文方法的核心模块,缺少该模块也导致识别率严重下降,这证明了Inception模块的重要性。由表8还可以看出,没有GMP模块,平均识别率为75.12%,GMP 层加在Inception 模块之后,将原网络的稀疏全连接层替换为Sigmoid 全连接层,其作用是加强特征图的位置信息,依然具有一定增益效果。因此,每个模块在最终输出结果上都有一定的促进作用。

表8 JAFFE数据集消融实验结果Table 8 Ablation experimental results in JAFFE dataset %
5 结束语
本文提出了一种基于优化剪枝GoogLeNet 的人脸表情识别方法。利用改进GoogLeNet 网络提取面部特征,添加GMP 以获得更全面的特征信息及特征图位置信息。同时,通过剪枝算法对GoogLeNet 网络进行训练、修剪低权重连接和再训练网络等操作,以简化网络结构和参数量,提高运行效率。在JAFFE、CK+和Cohn-Kanade数据集上对所提方法进行实验论证,结果表明,与其他方法相比,本文方法具有较高的识别准确率和较短的运行时间,以JAFFE 为例,本文方法的准确率为83.84%,运行时间低于100ms,具有明显的识别优势。此外,当训练图像比例增加时,获得的识别准确率也会随之提高。
由于本文方法针对公开图像集中的表情进行识别,未来会增加现实生活中的视频数据集、微表情数据集,从而提高方法的适用性。
猜你喜欢
保健医苑(2022年5期)2022-06-10
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
计算机工程与设计(2021年4期)2021-04-22
农业科技与信息(2021年2期)2021-03-27
成都信息工程大学学报(2021年6期)2021-02-12
动漫星空(2018年9期)2018-10-26
中国交通信息化(2018年5期)2018-08-21
