
基于注意力机制和图卷积的小样本分类网络
2021-10-14 06:34王晓茹
计算机工程与应用 2021年19期
王晓茹,张 珩
1.北京邮电大学 计算机学院,北京 100876
2.北京市网络系统与网络文化重点实验室,北京 100876
在过去的几年,利用深度神经网络,在很多图像识别数据集上的准确率已经取得了很大地提高。这些模型[1-4]往往都基于卷积神经网络,而且需要大量有标签的数据来训练。为了提高识别的准确率,网络向着更深和更复杂的方向发展,这无疑增加了网络参数,同时需要更多有标签的数据来训练。另一方面,基于传统深度神经网络的图像识别算法训练的模型往往只能识别训练数据中出现的类别,进一步限制了算法的应用和发展。不同于机器,人类通过几次甚至一次观察就能够识别图像的特征,当再次看到相同类别的图像时就能够准确地识别出来。希望机器也能够拥有这样的能力,所以在机器学习的领域中,一个新的方向逐渐受到大家的关注——小样本学习[5-6]。
小样本学习的目的是通过少数几张甚至一张有标签图像学习图像的类别信息。可以通过对传统的神经网络进行精细的调参来解决小样本学习问题。但是由于有标签的训练数据不足,很容易导致网络出现过拟合的现象。尽管能够通过数据增强和正则化的技巧减轻过拟合现象,但是并不能从根本上解决这个问题。
通过元学习[7]能够很好地解决小样本学习问题,目前已经有很多基于元学习思想的模型被提出。在元学习的训练阶段,会将训练集分为一个个元任务,然后用这一个个元任务去训练网络,即是指导网络如何去解决一个个元任务,而不是训练网络识别所有类别的图像。这样,在测试的时候,即使测试数据集中有新的类别的图像,网络仍然有足够的泛化能力识别出图像的类别。基于元学习思想的小样本学习算法主要包括基于度量的算法[8-14]、基于数据增强的算法[15-17]和基于模型优化的算法[18-21]。其中基于度量的算法被认为是一种最简单而有效的方法。
基于度量的小样本学习算法一般包含两步:(1)通过一个特征提取器提取支撑集图像和查询集图像的特征。(2)在一个统一的空间中比较特征的距离或者相似度,从而得到图像所属的类别。尽管有很多基于度量的小样本学习算法被提出来,但是这些算法仍然很难达到很高的准确率。认为现有的基于度量的小样本学习算法主要有两个方面的不足:(1)特征提取网络不能关注那些对分类起决定性作用的特征。(2)简单的将图像映射到同一个特征空间进行比较,不能充分利用支撑集中不同类别图像之间特征的差异。
基于上面的分析,主要关注两个方面的问题:(1)如何更好地提取特征来指导后面的分类?(2)如何充分利用提取的特征以及特征之间的关系?因此,提出了基于注意力机制和图卷积网络的小样本目标识别算法。这篇文章的主要贡献有:
(1)提出了添加了空间和通道注意力机制的特征提取网络,使得特征提取网络能够更好提取对分类有帮助的特征。
(2)提出了基于图卷积网络的关系网络,能够在比较特征相似度的同时利用不同类别图像特征之间的关系,从而提高分类的准确率。
(3)在Omniglot数据集和miniImageNet数据集上进行了大量的实验,相较于其他的基于度量的小样本学习算法,本文模型达到了更高的准确率。
1 相关工作
在这部分,将主要介绍基于度量的小样本学习算法、注意力机制以及图卷积网络。
1.1 小样本学习
小样本或者单样本分类任务是一个很有应用前景的研究方向。传统的深度学习方法并不能很好的解决小样本学习问题。最近,使用深度神经网络的方法已经取得很好的效果。但是与传统的分类任务相比,小样本分类任务在分类的准确率上还远远达不到同样的水平。
已经有很多研究表明使用元学习的方法能够很好的解决小样本分类任务,其中基于度量的小样本学习方法是一种简单而又有效的方式。双生网络[8(]Siamese Network)是一种通过共享网络权值实现的网络。双生网络有两个输入,通过两个共享权重的神经网络将输入映射到新的空间,从而可以在这个新的空间计算两个样本的相似程度,最终达到分类的目的。匹配网络[9](Matching Network)先使用一个卷积神经网络获得支持集和测试集的浅层表示,然后将它们放入一个双向LSTM 网络,最后通过计算输出特征的余弦相似度来表示查询集图像与支撑集图像的相似度。不需要对一个训练好的匹配网络做任何改变,网络就能够识别训练过程中没有遇见的类别。原型网络[11(]Prototypical Network)是将输入图像映射到一个潜在空间。其中,一个类别的原形是对支撑集中的所有相同类别图像的向量化样例数据取均值得到的。然后再通过计算查询集图像的向量化值与类别原型之间的欧氏距离就能得到查询集图像的类别。即原型网络认为在映射后的空间中距离越近的样例属于同一类别的可能性越大。前面的提到的双生网络和原型网络都是通过一个神经网络得到样例的向量化表示,然后计算向量化表示之间的相似度或者距离来判断样例是不是同一类别。而关系网络[12(]Relation Network)则是通过一个神经网络来计算不同样例之间的距离。
1.2 注意力机制
注意力机制[22]最初在机器翻译中被使用。随后,注意力机制开始在计算机视觉任务中被使用。注意力机制和人类的视觉机制相似,由于人眼看到的图像往往包含了大量的信息,但是大脑处理图像的时候往往只会关注某些重要的部分,忽略那些不重要的信息,这样能够加快大脑处理图像信息的速度。所以在计算机视觉中使用注意力机制可以让神经网络关注与任务相关的信息。注意力机制可以简单的理解为对某个时刻的输出y,在输入x上各部分施加不同的注意力的一种机制,而这里注意力就是权重。注意力机制可以分为软注意力机制和强注意力机制[23]。软注意力是可学习的,通常可以嵌入模型中直接训练,而强注意力是一个随机预测的过程。目前,神经网络中使用较多的是软注意力机制。
1.3 图卷积网络
在过去的几年中,神经网络的兴起与应用成功推动了模式识别和数据挖掘的研究。很多曾经机器并不能很好的解决的问题,现在已经能通过各种各样的深度学习模型解决了。但是传统的深度学习方法只能够被应用到提取欧式空间数据的特征上,许多从非欧式空间产生的数据,传统深度学习在上面的表现却仍不尽如人意。因而人们开始设计能够处理非欧式结构数据的神经网络,即图神经网络。在传统深度学习中,数据样本之间往往被认为是独立的,但是在图神经网络中,每个样本结点都会通过边与其他数据样本建立联系,这些信息能够用来捕获不同实例之间的相互依赖关系。图神经网络包含了很多类别[24],在这篇论文中,使用了图卷积网络[25-26],图卷积网络是对图结构的数据进行操作的卷积神经网络。
2 模型和方法
在这部分,首先将定义小样本学习中的专业术语和相关的符号,然后介绍使用的数据集,最后将提出基于注意力机制和图卷积网络的小样本目标识别算法,并且介绍模型设计的细节。
2.1 问题描述
对于人来说,初识一个新的物品,人类可以通过探索很快地了解并熟悉它,而这种学习能力,是目前机器所没有的。如果机器也能拥有这种学习能力,面对样本量较少的问题时,便可以快速地学习,这便是元学习。已经有很多研究发现,通过元学习可以很好的解决小样本分类问题。
基于元学习的小样本分类方法将分类任务分为一个一个的元任务。通常,元学习将训练集分为训练任务集和测试任务集。在训练的过程中,随机的从训练集中抽取C×K个样本作为支撑集(support set),其中C表示类别数,K表示每一类的图像数。然后再从训练集中剩下的类别为C中某一类的图像中抽取一定数量的图像作为查询集(query set),即那个由查询集和支撑集图像构成的一组数据成为一个episode。小样本分类任务的目是要得到查询集中的图像分别属于C类中的哪一类。当每次抽取的类别数为C,每类图像的数量为K时,把这样的任务称为C-way K-shot问题。式(1)和式(2)给出了支撑集和查询集的定义。

其中S表示支撑集,xi和yi表示支撑集中的第i张图像以及其对应的标签。

其中Q表示查询集,N表示查询集中的图像数量,xi和yi分别表示查询集中的第i张图像以及其对应的标签。特别的,当支撑集中每类图像的数量K=1 时,称这类任务为单样本学习;当K>1 时,称为小样本学习。
2.2 模型简介
本文提出了一种基于注意力机制和图卷积网络的端到端的模型来解决小样本分类问题。模型的框架如图1所示。
从图1 可以看到,本文模型包含两个网络:基于注意力机制的特征提取网络(FN)和基于图卷积网络的关系网络(RN)。特征提取网络用于提取输入图像的高维特征表示,而关系网络根则根据两张图像的特征表示判断两张图像是不是同一类,从而得到查询集图像的所属的类别。

图1 网络结构Fig.1 Network architecture
以5-way1-shot问题为例,从数据集中随机抽取5 张类别不同的图像{x1,x2,x3,x4,x5}组成支撑集,然后从数据集剩余的类别与支撑集类别相同的图像中随机抽取一张图像作为查询集。这里目标是判断图像xˉ和支撑集{x1,x2,x3,x4,x5}中哪一张图像属于同一类别。
首先,将所有图像都输入到特征提取网络,得到每张图像的特征然后,将支撑集图像特征和查询集图像特征拼接在一起,得到其中C(·,·) 是特征的拼接操作。将拼接后的特征送入关系网络,最后关系网络的输出一个5 维的向量,表示两个特征对应图像属于同一类别的概率。
2.3 模型细节
2.3.1 特征提取网络
特征提取网络使用了一个包含四层卷积的CNN网络。为了更好地提取任务相关的特征,在特征提取网络中添加了注意力模块。比较了一些注意力模块,如Nonlocal[27]等,但是Non-local 的计算量较大,而且特征提取网络的深度很小,所以选择了即插即用的卷积注意力模块[28(]Convolutional Block Attention Module,CBAM)。CBAM 包含了两个维度的注意力——空间注意力和通道注意力。
特征的每一个通道都表示一个专门的检测器,可以认为每一个通道代表着一种不同的特征。因此使用通道注意力可以使得网络知道关注什么特征针对目前的任务是有意义的。如图2(a)所示,先在每一个通道的特征图上进行全局平均池化和全局最大池化,得到两个1×1×C的通道描述。然后将这两个通道描述送入一个多层感知机中,这个多层感知机由两个共享权重的全连接层组成,即将全局平均池化和全局最大池化的结果都通过这个全连接层得到相应的输出,这两层全连接层的神经元个数分别为和C,在实验中,取r=2。然后将输出的特征经过逐元素相加后经过Sigmoid激活函数得到最终的通道注意力。最后,将得到的通道注意力与原来的特征图相乘。
而空间注意力能够关注哪里来的特征是有意义的。如图2(b)所示,与通道注意力相似,在通道维度上进行最大池化和平局池化,得到两个H×W×1 的空间描述。然后,将这两个特征在通道维度拼接,经过一个卷积层后得到空间注意力。最后将经过了通道注意力的特征图与空间注意力相乘,最终得到了经过调整的特征图。

图2 卷积注意力模块Fig.2 Convolutional block attention module
2.3.2 基于图卷积的关系网络
关系网络的目的是比较支撑集图像特征和查询集图像特征,从而得到查询集图像属于支撑集图像类别中的哪一类。基于传统神经网络的关系网络仅仅将查询集图像特征和一类支撑集图像特作为输入,所以不能充分利用支撑集中不同类别图像之间的差别和相似性作出更准确的判断。所以,针对小样本学习的训练特点,将不同的图像特征抽象成图卷积中的节点特征,同时将节点的距离作为边的权重。这样关系网络就能够利用图卷积里面的消息传递的特性获得整个支撑集的信息,从而作出更准确的判断。
在前面的特征提取网路中,得到了支撑集图像特征和查询集图像特征,并把它们拼接在一起得到了在特征提取网络中,在C-way Kshot,K>0 的时候,将同一类别图像特征的平均值作为该类的特征,即拼接后特征先经过一个全连接层,得到融合后的特征。然后,将这些特征作为图的结点,支撑集图像的特征之间的距离作为边的权重,组成一个完全图。距离的计算方式如下:

这个完全图经过图卷积网络后,每个节点输出一个特征。将输出的特征经过Softmax激活函数得到查询集图像属于每一类的概率。
2.3.3 损失函数
在模型的训练过程中,使用了交叉熵损失函数,即:

φ、θ分别为特征提取网络和关系网络的参数,ri,j表示第i组数据中查询集图像与第j张支撑集图像为同一类的概率。
3 实验
在这部分,将介绍实验环境设置和使用的数据集,然后将介绍网络的具体结构。最后,进行了大量的实验,验证了本文模型在小样本分类问题中能够取得的效果。同时,进行了消融实验验证模型中相关模块的有效性。
3.1 数据集
在Omniglot 数据集和miniImageNet 数据集上进行了实验。Omniglot数据集包含来自50个不同字母表的1 623 个不同手写字符,每个字符包含20 张28×28 图片。使用了与文献[9,11-12]类似的处理方式,将图像分别旋转90°、180°和270°作为新的类别。然后将1 200个字符以及它们旋转之后的字符作为训练集,剩下的423个字符以及它们旋转之后的字符作为测试集。与文献[9-12,18]类似,在Omniglot 数据集上进行了20-way1-shot和20-way5-shot的实验。
miniImageNet 数据集是ImageNet 数据集的子集。miniImageNet 数据集包含了100 类图像,每一类由600张图像组成,将图像统一处理成84×84 的大小。和文献[12]中一样,将100 类中的64 类作为训练集,16 类作为验证集,20 类作为测试集。与文献[9-12,18]类似,在miniImageNet 数据集上进行了5-way1-shot和5-way5-shot的实验。两个数据集的实验设置如表1所示。

表1 在Omniglot和miniImageNet数据集上的试验设置Table 1 Experiment settings on Omniglot and miniimageNet dataset
3.2 模型具体实现
本文的模型一共包含了两个部分:特征提取网络和基于图卷积的关系网络。
特征提取网络由4个卷积层组成,在特征提取网络里面使用的通道注意力和空间注意力。特征提取网络的具体结构如图3。在每一个卷积操作之后添加了一个注意力模块。
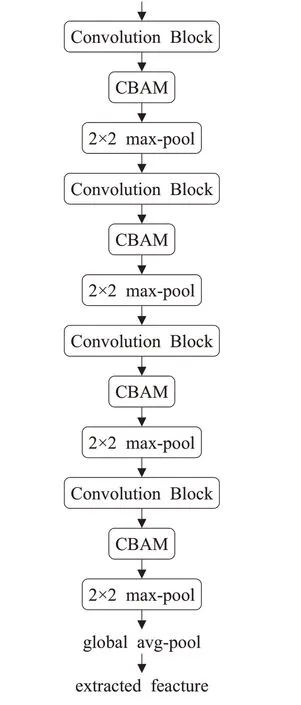
图3 特征提取网络的结构Fig.3 Architecture of feature extraction network
在关系网络中,首先将查询集图像特征和支撑集图像特征经过一个全连接层进行融合,然后将融合后的特征作为图的结点特征,由这些结点构成一个完全图,然后将这个完全图进行3 层图卷积,最后输出一个5 维的向量,经过Softmax 后得到查询集图像属于每一类的概率。特征提取网络结构如图4所示。

图4 关系网络的结构Fig.4 Architecture of relation network
3.3 实验结果和分析
3.3.1 对比实验
将本文模型与多个小样本分类模型进行了比较,实验结果见表2和表3。

表2 在Omniglot数据集上的效果Table 2 Results on Omniglot dataset %
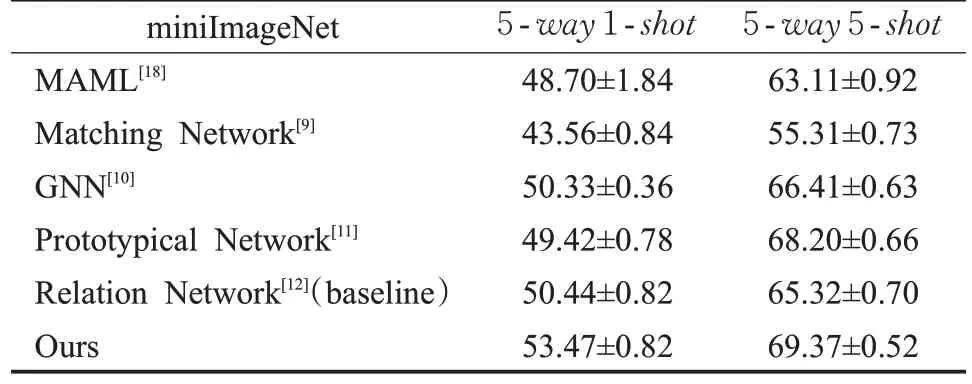
表3 在miniImageNet数据集上的效果Table 3 Results on miniImageNet dataset %
从实验数据可以看到,在两个基准数据集上面,本文模型都取得超过基准模型的效果,虽然在5-way5-shot任务中的准确率不及原型网络,但是已经达到了相近的水平。在特征提取网络中添加了注意力机制,使得特征提取网络能够关注那些对分类更有帮助的特征。同时,基于图卷积的关系网络改进了传统关系网络不能利用支撑集图像特征之间关系的问题,使得关系网络不仅能够比较支撑集图像特征和查询集图像特征,而且能够利用图卷积的信息传递得到支撑集中其他图像的相关信息。因此,本文模型能够取得比基准模型更高的准确率。
3.3.2 消融实验
为了能够分析清楚网络中各个部分的影响,使用控制变量法对模型进行了消融实验,分别验证了注意力机制和图卷积的有效性。消融实验的结果见表4。

表4 在miniImageNet数据集上的消融实验Table 4 Ablation experiment on miniImageNet dataset %
如表4所示,进行了3组实验:(A)只在特征提取网中使用注意力机制;(B)只在关系网络中使用图卷积;(A+B)同时使用注意力机制和图卷积。从实验结果可以看出针对关系网络提出的两个改进点都能提高分类的准确率。在与原型网络对比中可以看到,虽然单独的使用注意模块和图卷积并不能获得更好的效果,但是,注意力模块和图卷积的组合却能够明显提高分类的准确率。使用注意模块CBAM能够加强网络对关键特征的提取。通过调整不同特征的权重,CBAM能够使得特征提取网络提取到对分类更有效的特征。但是由于特征提取网络并不复杂,只能在空间和通道维度上调整不同特征的权重,所以使用CBAM 对最终结果的提升效果不及使用图卷积的效果。使用图卷积不仅能够让关系网络使用当前图像和查询集图像特征,而且能够让关系网络综合支撑集中各个图像特征之间的差异,利用这些差异,关系网络能够做出更准确的判断。同时,发现两种方式一起能够明显提高传统关系网络分类的准确率。
4 结束语
本文提出了基于注意力机制和图卷积的解决小样本分类问题的网络。本文模型主要由特征提取网络和关系网络组成。在特征提取网络中,使用了通道和空间注意力来指导神经网络提取更重要的特征。在关系网络中,使用了图卷积让网络在比较查询集图像特征和对应的支撑集图像特征的同时利用图卷积的消息传递获取支撑集中其他图像的特征信息。对比实验表明,在Omnislot 数据集和miniImageNet 数据集上均取得了比基准模型更好的效果。消融实验结果说明,注意力模块和图卷积的使用确实提高了模型分类的准确率。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
电子制作(2018年19期)2018-11-14
传媒评论(2017年3期)2017-06-13
自动化学报(2017年11期)2017-04-04
第二课堂(课外活动版)(2016年2期)2016-10-21
新校长(2016年8期)2016-01-10
噪声与振动控制(2015年4期)2015-01-01
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
食品科学(2013年8期)2013-03-11
