
危重症指标相关性分析模型
2021-10-14 06:34:20张力戈陈芋文秦小林李雨捷
计算机工程与应用 2021年19期
张力戈,陈芋文,秦小林,易 斌,李雨捷
1.中国科学院 成都计算机应用研究所,成都 610041
2.中国科学院大学,北京 100049
3.中国科学院 重庆绿色智能技术研究院,重庆 400714
4.陆军军医大学 第一附属医院,重庆 400038
围术期患者出现危重症,不仅会增加患者的医疗费用,影响患者的康复结果[1-2],甚至会导致患者死亡。Khuri等[3]研究表明术后30天内发生严重不良事件的患者中位生存时间减少69%。短期手术并发症的长期后果对患者生命健康和生活质量有深远的影响[4]。有效预测危重症风险有助于医生及时诊断和治疗患者,避免药物过度使用,有利于医院资源的合理配置,同时降低患者的痛苦和死亡率。患者的各种监测指标在危重症预测中起着重要作用,结合这些指标对患者围术期危重症的预测更具有实用性和针对性。
目前,机器学习在医学领域得到了广泛的应用。Ramana等[5]利用支持向量机、C4.5决策树、BP神经网络等完成基于肝脏文本数据集的诊断分类。Patricio 等[6]使用Logistic 回归、支持向量机和随机森林分类算法基于血液样本数据预测乳腺癌。Aljaaf等[7]提出了一种基于C4.5决策树的心力衰竭多层次风险评估方法。Otoom等[8]提出了分析监测冠状动脉的系统,他们的数据集有76 个特征,只有13 个特征被使用。Demsar 等[9]证明少量的特征可以携带足够的信息来建立合理准确的预测模型。Sharma 等[10]使用改进的灰狼算法进行特征选择和预测患者帕金森风险,估计准确率达到94.83%。Lucini等[11]使用数据挖掘方法结合机器学习算法来预测患者未来的住院和出院情况。由于单一分类器不能对所有疾病进行诊断,Nallur等[12]基于三种进化算法、支持向量机和多层感知器,提出了混合分类参数优化诊断系统,实现了对混合疾病的诊断。以上研究表明,在不降低预测精度的前提下,可以减少用于预测的特征数量。然而,上述选择特征的方法多为针对特定疾病设计或者依赖医生经验直接选择,通用性较低。对于一系列危重症,仍然需要一种通用的方法来分析它们与患者术前和术中检测指标的潜在关联。
针对上述问题,本文提出基于机器学习的危重症指标分析模型。模型采用统计方法与斯皮尔曼等级相关系数去除冗余指标,基于XGBoost[13]分析指标与危重症之间的相关性,并提取危重症对应的核心指标。
1 相关工作
用于危重症指标选择的方法可以分为嵌入法与过滤法两类。嵌入法依赖特定的机器学习模型,使用不同的指标子集训练模型,选择预测性能较高的子集作为最优指标子集。过滤法通过预定义的性能度量来选择指标,这些方法独立于后续的分类器。过滤法具有较少的计算量,使用更为广泛。Yu等[14]提出了一种基于条件互信息的特征选择方法,为后续的支持向量机分类器选择最有效的心率变化特征。采用该方法选取15个特征的准确率比全部50个特征的准确率高1.21%。Lee等[15]提出了一种基于支持向量机误差界准则的特征选择方法提高充血性心力衰竭的识别效率,采用该方法选取17个特征的准确率高于遗传算法所选特征。Wang等[16]提出了一种改进的信息增益方法来选择肝硬化特征,该方法结合信息增益和典型分类器来生成最优特征子集。
以上研究重点在最优指标子集的选择上。Sanchez-Pinto 等[17]分析了目前临床诊断中使用的8 种不同特征选择方法。他们的研究结果表明,基于回归的特征选择方法在较小的数据集上可以得到更好的临床预测,而基于树的方法在较大的数据集上表现更好。Sanchez-Pinto等[17]分析了两类特征提取算法在临床预测中的有效性,其工作具有指导意义。与上述研究不同,本文着重分析患者术前术中检测指标与危重症的相关性。指标与危重症的相关性揭示了指标对危重症预测的影响,本文模型利用指标对危重症预测的贡献来衡量二者之间的相关性,并选取贡献较大的指标作为危重症对应的关键指标。
2 核心指标分析模型
本文模型由数据预处理、指标相关性分析、指标重要性分析与核心指标选择四部分组成,整体流程如图1所示。

图1 模型流程图Fig.1 Flow chart of model
2.1 数据预处理
2.1.1 数据提取与合并
为同时分析患者术前术中指标,本文模型将患者术前检测指标与检测指标进行提取与合并。对于患者术前检测指标数据,由于不同患者每次进行术前检查的指标不同,因此术前检测指标数据集中存在一定的缺失值。模型以14天为阈值,通过公式(1)填充每个患者的指标缺失值,式中ei,j、ek,j表示第i和k时刻指标j的检测值,阈值设定为14 天是与医生讨论后的结果。然后,根据患者的病历号与手术时间,合并患者各类术前检测指标。患者术中检测指标数据为时序类型,为将这些指标与术前检测指标合并,模型计算患者术中各类监测指标的均值(mean)、方差(variance,var)、标准差(standard deviation,std)、最大值(max)、最小值(min)、峰度(kurtosis,kurt)、偏度(skewness,skew),统计各类指标术中异常时间,并以这些统计值代表术中各类监测指标。

提取术前和术中检测指标数据后,模型结合病历号和患者手术时间,将两种指标数据合并生成术前术中指标数据集。
2.1.2 指标缺失值与单一值处理
虽然模型在提取指标数据集时已填充了术前检验指标的缺失值,但是由于指标记录不完整以及患者之间的检测指标存在差异,数据集中仍存在大量缺失值,含缺失值较多的指标在危重症预测中无实际作用,属于冗余指标。本文模型首先通过公式(2)计算每个指标所含缺失值比例,式中li表示指标i所含缺失值比例,ui为指标i中缺失值的数量,n表示指标i整体维度,即所提数据集的样本量,图2 展示了肝衰样本缺失值统计结果。然后设置阈值MT,将缺失值比例高于MT的指标作为冗余指标并移除。

图2 指标缺失值统计结果Fig.2 Statistical results for missing values of indicators

除缺失值外,指标数据集中存在单一值现象,即数据集中某些指标仅包含一种值。造成这一问题的原因是数据集中所有患者的一些指标检测值相同,例如数据集中所有患者均没有使用过某种药物。无论患者是发生危重症,这些指标的检测值都相同。因此,这些指标对危重症预测无实际意义,属于冗余指标。本文模型通过统计数据集中各类指标不同检测值的数量确定单一值指标,并将这些指标移除。
2.2 指标相关性分析
由于数据集中指标种类繁多,不同指标之间可能存在一定的相关性。同时,具有高共线性的指标在危重症预测中的作用相同。为进一步提升危重症的预测效率,本文模型通过斯皮尔曼等级相关系数分析患者检测指标间的相关性,并移除相关性高的指标。
首先将选中的两个指标a、b的检测值分别排序,记a、b中检测值的排名向量为ra、rb,根据公式(3)计算ra、rb的插值da,b,式中rai、rbi为ra、rb在位置i处的值,n表示指标维度,即指标数据集的样本量。然后,通过公式(4)得到a、b间的相关性ρa,b。

基于上述步骤,根据公式(5)构造数据集中所有指标的相关性矩阵T并提取其上三角矩阵U,式中ρi,j表示第i个指标与第j个指标间的相关性,ti,j与ui,j分别为T与U在位置(i,j)处的值。图3展示了肝衰样本指标相关性矩阵部分结果,图中色彩深度代表了相关性高低。最后设置相关性阈值CT并逐列与U中元素比较,若U中第i列存在大于CT的元素,则将第i个指标作为冗余指标并移除。
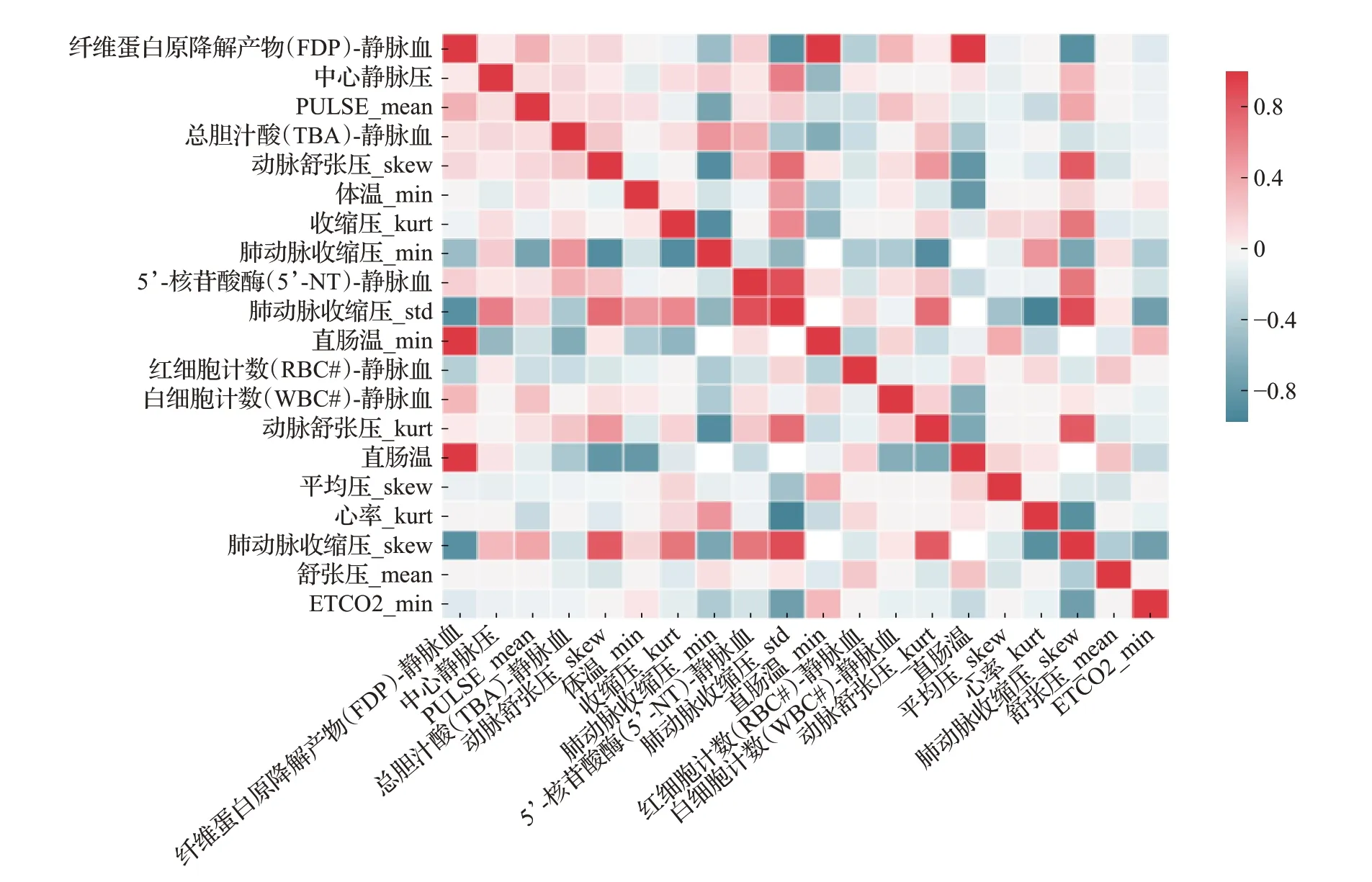
图3 指标相关性分析部分结果Fig.3 Collinear processing results of indicators

2.3 指标重要性分析
分析指标与危重症相关性的关键部分是估计各指标在危重症预测中的重要性,指标的重要性代表了该指标对危重症预测的贡献程度。
尽管模型已经在前期预处理中填充了部分空值并移除了含有大量空值的指标,但指标数据集中仍存在缺失值。为更好地处理缺失值,本文模型采用基于分类与回归树(Classification and Regression Trees,CART)结构的XGBoost算法作为危重症预测分类器,分析各类指标对危重症预测的贡献度。XGBoost 是梯度提升决策树(Gradient Boosting Decision Tree,GBDT)的一种改进算法,通过结合二阶导数并加入正则项来优化目标函数,同时在训练过程中加入样本抽样与特征抽样来降低算法过拟合风险,提升算法的泛化能力。模型通过公式(6)进行危重症预测,式中xi为患者i的检测指标向量,表示患者i危重症预测值,F为针对患者危重症风险预测的CART决策树空间,fk为第k次迭代的CART决策树,k表示模型最终迭代次数。模型针对危重症预测的目标函数如公式(7)所示,yi为患者i的真实标签,L()为损失函数,∑kΩ(fk)为正则化项。
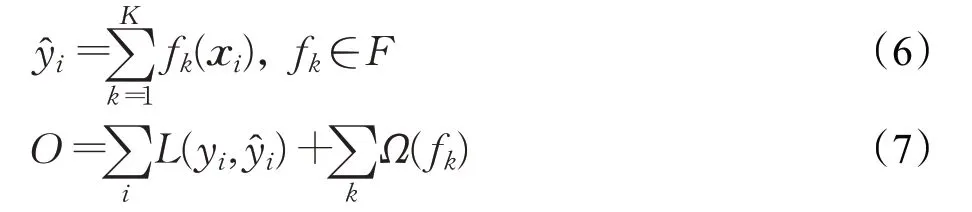
完成训练后,本文模型采用指标在XGBoost 分类器中的平均信息增益表示指标对危重症预测的贡献程度,即指标的重要性。通过公式(8)进行计算,式中vj为指标j的平均信息增益,Gj、Tj分别表示指标j在XGBoost 分类器所有CART 决策树中的信息增益和以及作为分裂节点出现的总次数。为提升分析稳定性,本文模型以10次随机采样分析结果均值作为最终指标与危重症的相关性。

2.4 核心指标选择
核心指标的选择基于上一步得到的各指标对危重症预测的重要性。首先对指标重要性进行降序排列。其次,通过公式(9)对指标重要性进行归一化,式中sj为第j个指标的归一化重要性,m为数据集中指标数量。然后通过公式(10)计算指标重要性累加和,式中cj表示第j个指标的重要性累加和。最后设置阈值KT,选择重要性累加和低于KT的指标作为核心指标。

3 实验结果与分析
3.1 实验数据与环境
为验证本文模型有效性,实验部分采用肝衰与肾衰患者数据进行分析,数据均采集自合作单位真实患者检测数据。肝衰与肾衰样本量与原始检验指标量如表1所示,两种危重症阳性样本数量明显少于阴性样本数量。针对此问题,为保证患者数据的真实有效性,本文模型采用降采样方法将阴性样本数量减少至与阳性样本量一致。

表1 危重症样本量Table 1 Number of samples for critical illnesses
本文实验在Python 3.5环境下完成,实验平台CPU为Inter Core i5 2.9 GHz,16 GB RAM。实验中XGBoost分类器与LightGBM[18]分类器参数如表2、表3所示,训练时以每个患者的术前术中检验指标作为样本的特征。实验中采用准确率(Accuracy)、F1 值(F1_score)、AUC(Area Under Curve)、敏感性(Sensitivity)与特异性(Specificity)评价分类结果。
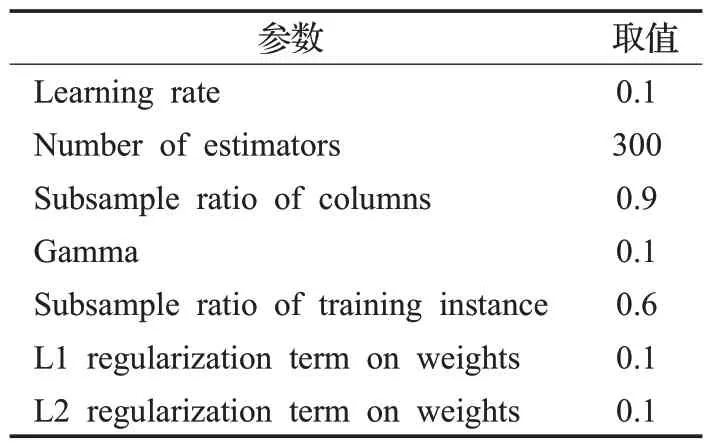
表2 XGBoost参数Table 2 Parameters of XGBoost
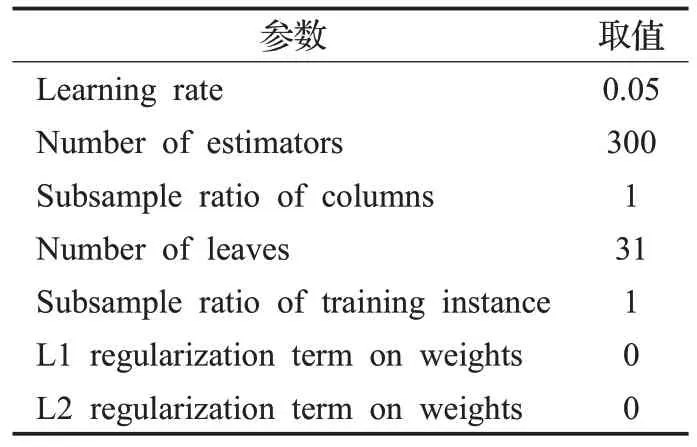
表3 LightGBM参数Table 3 Parameters of LightGBM
3.2 实验结果与分析
模型在缺失值处理与指标相关性分析中,采用的阈值MT与CT分别为0.90与0.98。肝衰与肾衰样本初始指标数量为192 与193,经过模型数据预处理以及指标相关性分析,剩余指标数量为119与73。
图4 为肝衰与肾衰样本前20 指标的归一化重要性。从中可看出,肝衰每个指标的重要性略低于肾衰指标。肝衰与肾衰前20 指标归一化重要性累加和分别为0.450 与0.498,表明肾衰指标重要性累加和增长快于肝衰,即按照同样的阈值进行核心指标选择时,肾衰样本核心指标数量明显少于肝衰样本。因此,实验中设置肾衰样本核心指标选择阈值高于肝衰样本核心指标选择阈值,确保肾衰样本与肝衰样本选择的核心指标数量相差不大,分别设置为0.70 与0.55,实际应用中可根据需要设置与

图4 指标归一化重要性Fig.4 Normalized importance of indicators
图5 为肝衰与肾衰样本的归一化重要性累加和结果,图中竖线以为界限,将指标分为两部分,左边部分即所选的核心指标。从图5可看出,肝衰与肾衰样本所选的核心指标数量分别为31 与36,所选核心指标如表4所示。

表4 两种危重症核心指标Table 4 Key indicators of two critical illnesses

图5 指标重要性累加和Fig.5 Cumsum for the importance of indicators
目前基于支持向量机、Logistic 回归、随机森林、XGBoost与LightGBM等机器学习算法的预测模型已经应用在各类疾病的风险预测中[5-6,19-21]。相对于上述预测模型,本文模型的重点在于分析患者各类检测指标与危重症之间的相关性,并提取相关性高的指标辅助医师诊疗患者。为验证模型指标分析结果有效性,本文基于上述预测模型,对比了全部指标与核心指标在肝衰与肾衰预测中的效果,预测模型采用XGBoost 与LightGBM 分类器。预测结果ROC曲线与P-R如图6、7所示,其中虚线表示使用核心指标的结果,实线表示使用全部指标的结果,红色表示XGBoost分类器结果,绿色表示LightGBM分类器结果。从图6、7 可看出,XGBoost 与LightGBM使用肾衰核心指标的ROC 曲线与P-R 曲线与使用全部指标的ROC 曲线与P-R 曲线基本一致,XGBoost 与LightGBM 使用肝衰核心指标的ROC 曲线与P-R 曲线线下面积略大于与使用全部指标的线下面积,即本文所提核心指标的肾衰预测效果与使用全部指标相近,肝衰预测效果略高于全部指标。

图6 两种危重症预测ROC曲线Fig.6 ROC curves of two critical illnesses
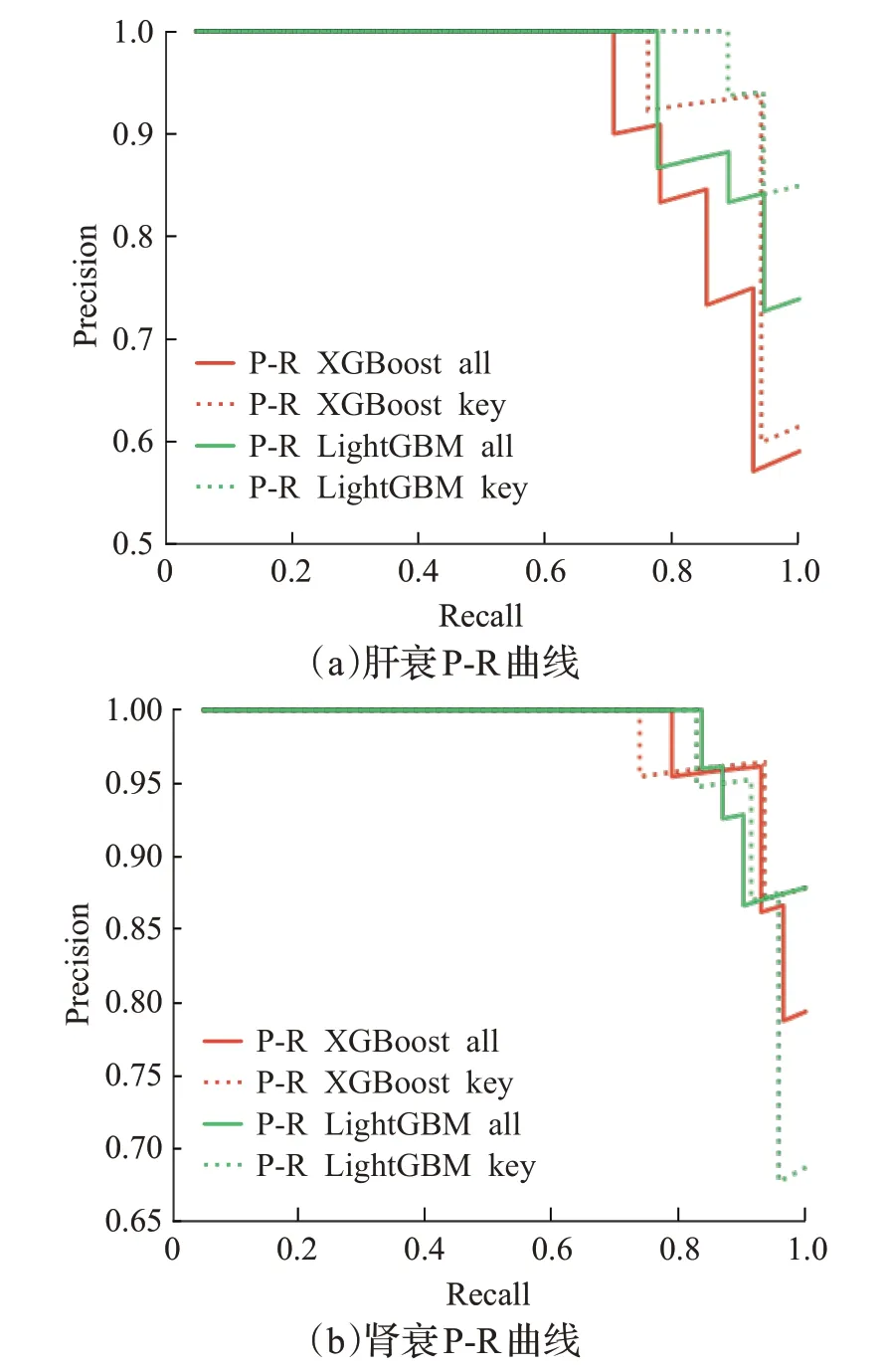
图7 两种危重症预测P-R曲线Fig.7 P-R curves of two critical illnesses
进一步验证模型有效性,本文采用10 折交叉验证对比了全部指标与核心指标在肝衰与肾衰预测中的效果。将肝衰数据集与肾衰数据集分成10 个不同的子集,子集的样本量分别为(35,35,34,34,34,34,34,34,34,34)与(51,51,51,51,51,51,50,50,50,50),每次使用其中1 个子集作为测试集,剩余9 个子集作为训练集,交叉验证重复10 次。表5 与表6 中预测结果均为10 折交叉验证均值,采用的分类器分别为XGBoost 与LightGBM。从表5 可看出,肝衰核心指标在XGBoost分类器上的准确率、AUC、F1 值与特异性,较所有指标分别提高了0.011、0.013、0.009 与0.030,敏感性略低于所有指标。肾衰核心指标在XGBoost 分类器上的准确率、F1 值、敏感性与特异性,较所有指标分别提高了0.012、0.012、0.003 与0.019,AUC 略低于所有指标。从表6 可看出,肝衰核心指标在LightGBM 分类器上的准确率、AUC、F1值、敏感性与特异性,较所有指标分别提高了0.021、0.022、0.019、0.001 与0.038。肾衰核心指标在LightGBM 分类器上的准确率、F1 值与敏感性,较所有指标分别提高了0.018、0.022与0.039,AUC与所有指标相等,特异性略低于所有指标。由表5 与表6 结果可知,本文所提核心指标在肾衰与肝衰中的预测效果略高于所有指标,即本文模型提取的核心指标有效。
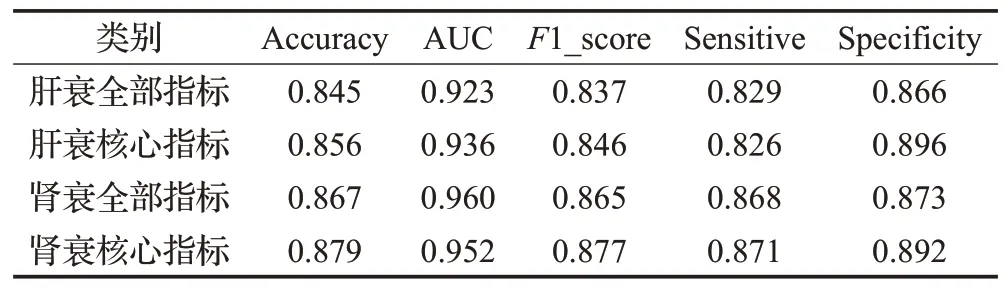
表5 XGBoost预测结果Table 5 Predictive results of XGBoost

表6 LightGBM预测结果Table 6 Predictive results of LightGBM
4 讨论
由于患者术前术中检测指标数据存在缺失值情况,实验中采用了XGBoost 分类器与LightGBM 分类器对所提模型进行验证。从上述实验结果可看出,本文模型所提关键指标在危重症预测中可以替代所有指标。对比其他预测模型,周杰斌等[20]使用Logistic 回归模型预测药物性肝衰的AUC 与准确率分别为0.917 与0.867,略低于本文模型提取的核心指标在LightGBM 模型中的肝衰预测效果;Vijayarani等[22]使用人工神经网络预测包括肾衰在内的肾脏疾病的准确率为0.877,与本文模型提取的核心指标在XGBoost 模型中的肾衰预测结果相似。这些结果表明本文模型有效地移除了冗余指标,避免了这些冗余指标对危重症预测的影响,提取的核心指标能够有效地用于危重症风险的预测,即模型能有效分析指标与危重症之间的相关性。
然而,本文模型仍存在一些不足:为了保证患者样本的有效性,模型没有填充患者检验指标的缺失值。虽然模型分析了指标缺失值并设置阈值移除了部分缺失值比例较高的指标,但数据集中仍然存在部分缺失值。由于数据缺失等因素影响,一些根据医生经验对危重症应具有重要意义的指标在模型中可能没有得到应有的重要性。因此,本文模型仍需结合医生经验等因素进一步改进,使分析结果更接近指标与危重症之间的真实相关性。
5 结束语
本文提出了基于XGboost 的危重症指标分析模型。该模型包括数据预处理、相关性分析、重要性分析和关键指标选择四部分,对指标的缺失值、单值、相关性以及与危重症之间重要性进行统计与分析,并根据重要性结果选取危重症对应的核心指标。实验采用肝衰与肾衰两种危重症样本对模型进行验证,结果表明本文模型能够有效地分析患者检测指标与危重症之间的相关性。
猜你喜欢
现代临床医学(2022年1期)2022-02-12 02:04:56
中国食物与营养(2021年11期)2021-12-21 06:35:02
首都医科大学学报(2021年6期)2021-12-20 11:00:42
中成药(2018年5期)2018-06-06 03:11:46
电子测试(2018年1期)2018-04-18 11:52:35
中国医药指南(2017年3期)2017-11-13 02:57:02
中国医药指南(2017年3期)2017-11-13 02:55:46
中成药(2017年3期)2017-05-17 06:09:10
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
