
基于双层注意力神经网络的入侵检测方法
2021-10-14 06:34李占斌杨永胜赵龙飞
计算机工程与应用 2021年19期
曹 磊,李占斌,杨永胜,赵龙飞
1.国家海洋信息中心,天津 300171
2.清华大学 公共安全研究院,北京 100084
随着信息技术的不断发展,网络空间安全日益受到关注。恶意的网络活动时刻威胁着人们的信息基础设施、应用和数据安全,并带来许多严重的后果,如服务器宕机、未经授权的非法访问、信息泄露篡改破坏等。因此,实施有效的入侵检测手段来应对这些恶意网络活动已成必然。
网络入侵检测技术是网络安全防护体系重要组成部分,异常流量检测和分析是网络入侵检测领域常用的研究方法[1]。研究人员通常使用机器学习方法来构建网络活动模型,通过评估与正常行为差异性来检测恶意网络活动,较常用的有随机森林[2]、SVM[3]、KNN[4]、GBDT[5]、K-means[6]等浅层学习算法。深度学习是机器学习的一个子集,与浅层学习模型相比,深度学习模型拥有更强的拟合能力,将深度学习技术应用于网络入侵检测已成为许多研究者关注的热点。刘月峰等人[7]借鉴Inception结构,提出了一种9 层网络结构的CNN,并利用多尺度卷积核来提取不同维度的特征,最后在KDDcup99数据集上进行实验仿真。饶绪黎等人[8]构建了一种MLP神经网络模型,实现信息不完全条件下的入侵检测。Devan等人[9]使用深度神经网络(DNN)自动对流量数据进行分类,首先通过XGBoost 算法来减少不必要的特征,然后利用DNN模型对网络入侵行为进行分类训练。在文献[10]中,提出了一种主成分分析法和LSTM 相结合的入侵检测模型,并在UNSW-NB15数据集上进行了仿真实验。汪盼等人[11]通过改进的DBN深度置信网络进行特征降维,并在NSL-KDD数据集上进行了分类实验。
目前,无论是传统机器学习算法,还是深度学习模型,大都采用人工设计的流量特征,这类特征主要包括网络流量包头信息和整个流的统计信息,而对网络流量中的有效载荷数据利用率却不高,无法检测到载荷数据包含的恶意信息,如XSS、SQL注入等。另外,网络流量中的各类信息对入侵检测分析的重要性是不同的,标准的CNN、RNN等神经网络,对重要信息的捕捉能力不足。
最近的研究发现,在RNN或CNN神经网络上添加注意力机制,可以在大量自然语言处理任务中取得更好的效果,如神经机器翻译[12]、文本分类[13]、情绪分析[14]等。注意力机制使用权重隐藏层来计算输入序列的权重分布,根据权重分布就能反映输入序列重要元素的位置信息。与RNN和CNN不同的是,注意力机制可以忽视输入序列中元素的距离,直接捕获对任务有重要贡献的依赖关系,从而为RNN或CNN提取的特征补充重要性信息。虽然注意力机制在自然语言处理等领域应用效果良好,但目前尚未应用到网络入侵检测的问题中。
本文提出了一种双层注意力神经网络模型L2-AMNN,无需复杂的特征工程,直接提取原始网络流量的有效载荷数据作为样本,经数据处理形成字节数据-数据包-网络流层次结构的文本序列表达。借鉴自然语言处理方法,在双向LSTM 模型基础上,引入双层注意力机制,分别关注重要的字节和数据包。利用字节注意力机制,计算字节信息权重分布,提取关键字节信息特征;利用数据包注意力机制,计算数据包信息权重分布,提取关键数据包信息特征,最后生成更加准确的入侵检测特征向量,提高网络入侵检测能力。
1 基于双层注意力机制的神经网络构建
1.1 整体架构
如图1 为本文提出的L2-AMNN 模型整体构建流程,首先对PCAP格式的原始网络通信数据进行数据预处理,包括流量切分、数据清洗等操作,并提取网络流量的有效载荷数据作为输入数据,然后构建、训练层次网络模型L2-AMNN,最后得到模型分类结果。
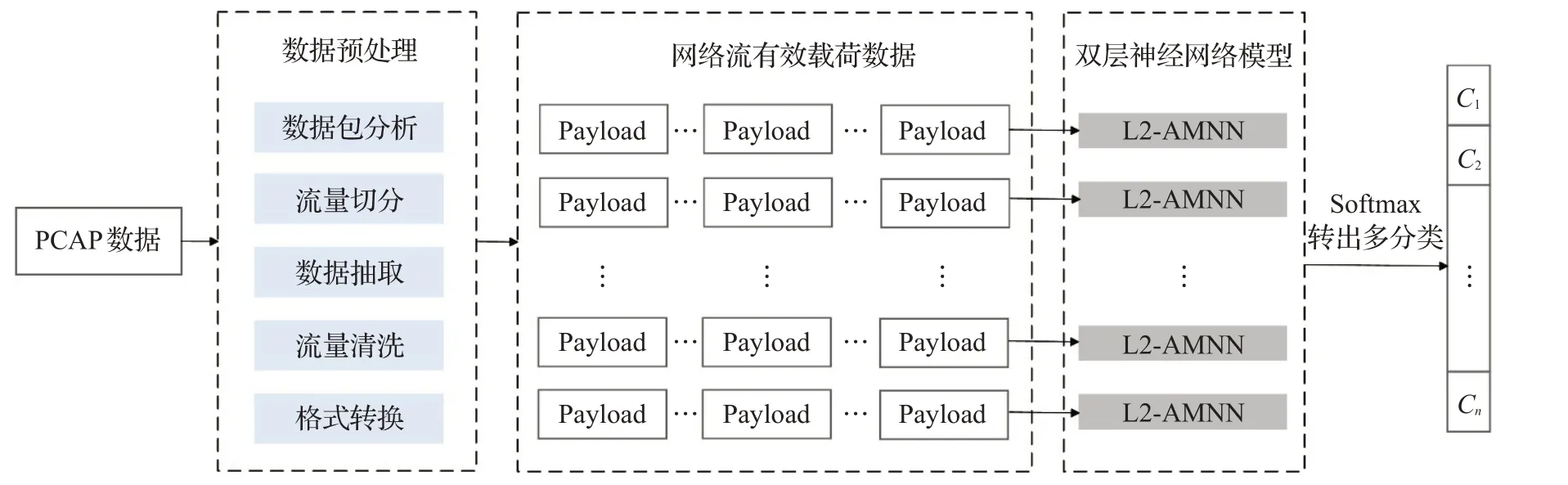
图1 L2-AMNN模型构建流程Fig.1 Overview of L2-AMNN construction
从整体上看,L2-AMNN 是一个端到端的深度学习模型,可以自动学习输入数据的特征信息,通过构建层次网络结构模型,实现对有效载荷攻击信息的深入挖掘,创新性地融合层次注意力机制,进一步提高了字节和数据包重要特征的提取能力。模型整体具有对多协议、多类别、长时间序列攻击的高精度检测优势。
1.2 数据预处理
原始网络流量数据由一个个数据包组成,能提供完整真实的通信信息描述,通常以网络信息五元组[15(]源IP地址、源端口、目的IP地址、目的端口、协议)的标准组合而成。PCAP 格式是常见的网络流量存储格式,其方向分为单向流和双向流,为全面准确地分析流量特征,本文主要提取双向网络流量。
本文对原始网络通信数据进行预处理,主要有以下几方面原因:一是为表示通信行为的时序特征,需按照五元组属性逐条提取流数据;二是要对流数据进行清洗过滤操作,尽量减少脏数据量;三是流数据格式不符合神经网络模型输入要求,需要进行格式转换。如图2所示,数据预处理主要包含数据包分析、流量切分、数据抽取、流量清洗、格式转换等步骤。
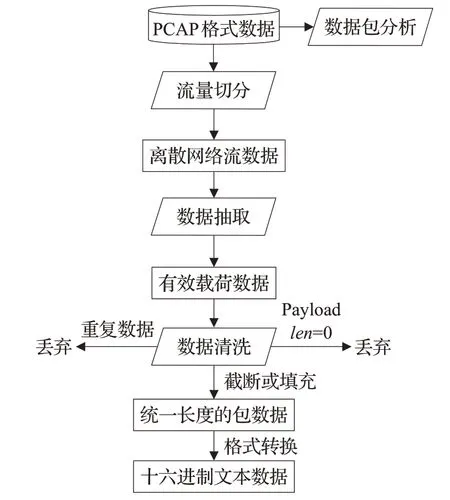
图2 数据预处理流程Fig.2 Data preprocess procedure
数据包分析:在数据处理前,进行数据人工分析是非常重要的一个步骤。首先对原始网络通信数据进行包分析,基于时间戳、IP地址、端口号等过滤网络恶意行为数据包,然后进行协议分析,识别数据包采用的协议,明确能够提取的载荷数据结构及特征,最后,要了解PCAP文件结构,为后续的数据抽取清洗作好准备。
流量切分:流量切分步骤是将连续的原始流量数据切分成多个离散的网络流数据。利用Wireshark 的editcap 工具,根据网络攻击的时间戳进行数据提取,按照五元组格式,切分成多个离散的网络流数据,输出数据仍是PCAP格式。
数据抽取:流量切分后生成的一个网络流PCAP文件包含多个数据包,数据抽取步骤需要抽取每个数据包的传输层以上的有效载荷数据,为了降低对结果的影响程度,认为IP报头等数据是无用数据,应该丢弃。
流量清洗:流量清洗主要去除载荷数据长度为零的数据包,删除重复数据,并将每个流中的数据包固定为一定长度,大于该长度进行截取,反之进行填充。
格式转换:神经网络对输入数据格式有一定要求,所以要对PCAP 格式的流数据进行格式转换。将流数据以十六进制进行读取,表示为[A~F,0~9]组成的字节序列,将其转换为字符数据,每条流数据为一行文本,并标记其标签类别。
1.3 网络模型结构
L2-AMNN模型为双向LSTM网络融合双层注意力的网络结构,根据网络流量的字节数据-数据包-网络流的组成特点,模型首先使用了一个双向LSTM神经网络和字节注意力层,编码了带有权重信息的字节词向量数据,形成数据包特征表示,然后通过双向LSTM 神经网络和数据包注意力机制,编码形成网络流的整体权重特征向量,最后使用softmax 函数进行分类。网络结构如图3所示。

图3 L2-AMNN神经网络模型结构Fig.3 Neural network structure of L2-AMNN
1.3.1 字节特征提取
词嵌入层:输入数据由数据包的字节序列组成,与自然语言处理中的单词处理类似,需要使用词嵌入层进行输入编码,由于字节数据取值范围有限,本文选用one-hot编码方式,定义一个d维词向量,则一个数据包的字节信息词向量表示为:

式中xit∈Rd,bit表示第i个数据包的第t个字节数据,e∈Rv×d是词向量矩阵,v表示数据包中字节数量,d表示词向量维度。
字节双向LSTM网络层:L2-AMNN使用双向LSTM[16]神经网络对字节数据的词向量进行编码,学习字节数据的特征信息,生成正向和反向的特征向量,将连接后生成数据包的特征向量hit。

字节注意力编码层:标准的双向LSTM网络模型对输入字节词向量进行统一编码,每个词向量对生成的中间编码向量贡献基本相同,但却忽略了某些关键字节信息会对分类结果产生影响,为了解决这一问题,引入字节注意力机制,计算字节数据的权重分布,将有重要贡献的字节信息突出表达。为此,首先要计算字节数据的权重信息,权重信息矩阵的计算公式如下:
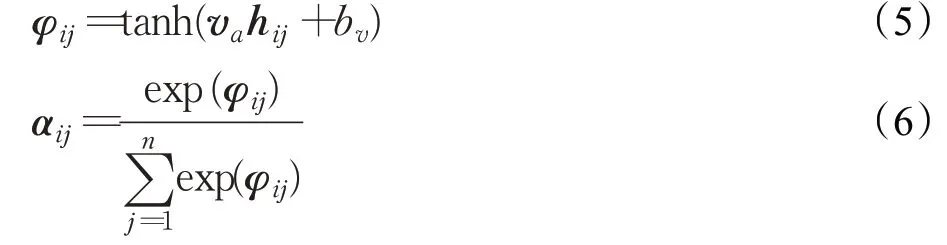
式(5)(6)中,为了度量某个字节数据的权重,使用hij和随机初始化向量va的相似度来表示,然后经过函数softmax 获得了一个归一化的注意力权重矩阵αij,αij代表数据包i中第j个字节信息的权重。
获得字节信息的权重矩阵后,计算权重矩阵αij与字节信息特征向量hij的加权和,更新每个字节的特征表示,得到数据包向量pi,计算公式如(7)所示:

1.3.2 数据包特征提取
数据包双向LSTM 网络层。获得带字节权重的数据包向量后,通过双向LSTM神经网络对数据包向量pi进行编码,学习数据包的特征信息,生成正向和反向的特征向量,将连接后生成网络流的特征向量hi。

数据包注意力编码层:与字节信息特征编码类似,标准的双向LSTM 网络模型对同样会忽略某些关键数据包信息对分类结果有重要影响,通过引入数据包注意力机制,计算数据包的权重分布,将有重要贡献的数据包信息突出表达。数据包权重信息矩阵αi表示如下式所示,其中vb仍是一个随机初始化向量并可进行自动学习,N为数据包个数。

网络流f向量为权重矩阵αi与数据包信息特征向量hi的加权和,可表示为:

1.3.3 网络流分类
将网络流向量f输入softmax 分类器中,并将其线性化为一个长度等于类标签数量的向量p,利用交叉熵损失函数Loss,使损失函数最小化,当标签值为c时,fc和pc分别为真实值和预测值的概率。

2 实验设计
2.1 实验数据集
本文数据集来源于加拿大网络安全研究所的入侵检测数据集CICIDS2017[17]。该数据集在连续5 天时间内,基于HTTP、HTTPS、FTP、SSH等多种协议,采集原始网络通信流量共51.1 GB。攻击类型包括Brute Force、DoS、Heartbleed、Web 攻击、Infiltration 和僵尸网络等6大类。数据集提供了PCAP、CSV两种格式。本实验采用PCAP 格式数据,训练数据集、验证数据集和测试数据集的比例为6∶2∶2。
如表1 所示,在6 大类攻击类型下,实验数据集又细分了13种网络攻击小类作为数据标签。原始数据集是按照网络流五元组切分后统计的双向流数据量,考虑数据的不平衡性会对分类结果产生影响,进一步对部分数据进行了采样处理,如Heartbleed 数据量过小,采取二次切分流数据的方式进行数据过采样,对于DDoS 数据量过大的样本,采取随机欠采样方式处理。对CICIDS2017 数据集进行预处理后,共生成42 144 条双向流数据。
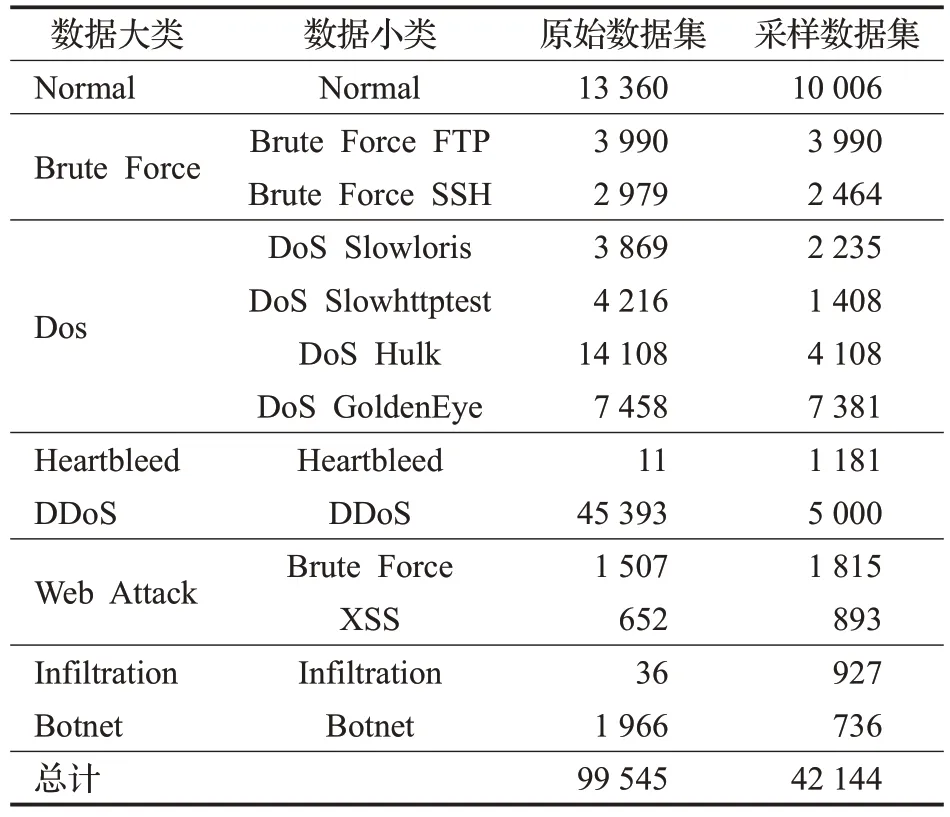
表1 实验数据集Table 1 Experimental data sets
2.2 模型训练
本实验在Ubuntu 操作系统中,基于开源的Tensorflow 深度学习框架,利用GeForce GTX 1060 显卡进行GPU 加速计算,极大提升了模型训练效率。如表2 所示,模型训练过程中,输入数据取512字节,输入序列长度1 024,词向量one-hot编码长度17,设置4层LSTM隐藏层,每层神经元数量为200。为避免训练过拟合,分别对初始学习率、学习率衰减指数、衰减速度及dropout进行配置,并当损失函数值1 000次不下降时,提前结束整个训练周期。
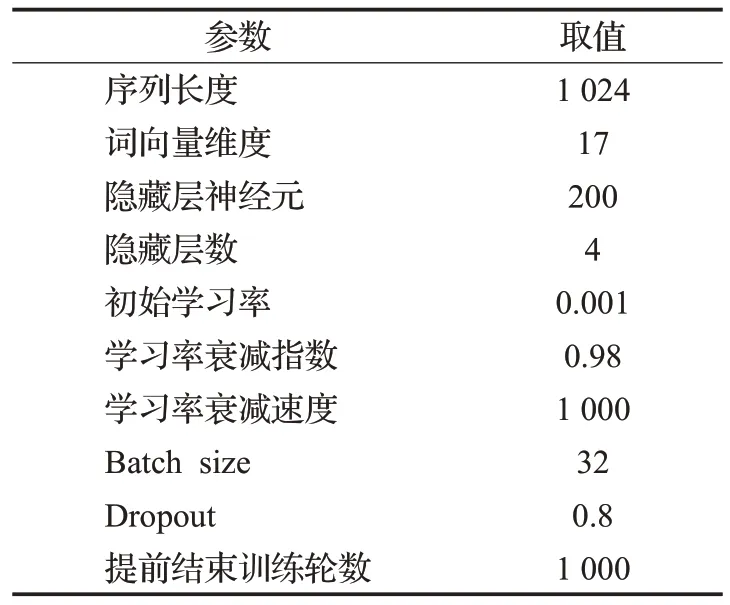
表2 模型训练超参数设置Table 2 Hyperparameters of training model
2.3 评估指标
本实验为多分类模型,使用表3的多分类混淆矩阵进行具体分类结果评估。
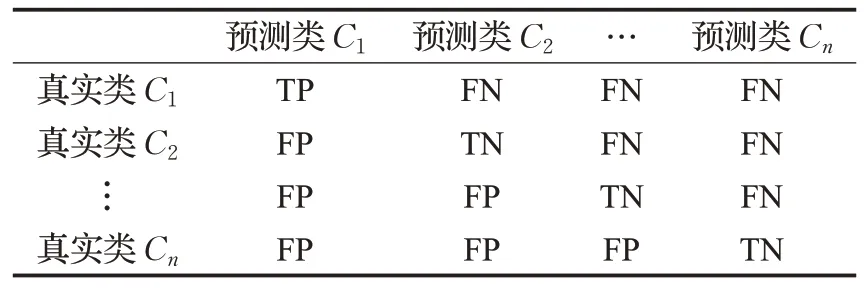
表3 多分类混淆矩阵Table 3 Confusion matrix of multi-class
除上述混淆矩阵外,还将使用两类评估指标对实验结果进行评估,一类为分类模型通用的评估指标准确率(Accuracy)、精度(Precision)、检出率(Recall)和F1-score,另一类为网络安全入侵检测领域的评估指标漏报率(MAR)和误报率(FAR)。
准确率(Accuracy),衡量模型对数据集中样本预测正确的比例:
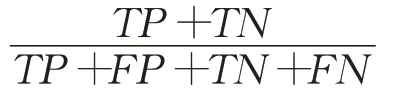
精度(Precision),衡量预测为正例的样本中真正为正例的比例:

检出率(Recall),评估是否把样本中所有真的正例全部找出来:
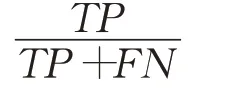
F1-score,精度和检出率的平衡点,其中P表示精度,R表示检出率:

漏报率(MAR),预测为正常流量样本中攻击流量样本的比率:
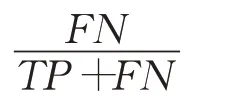
误报率(FAR),所有为正常流量的样本中预测为攻击流量的样本比率:
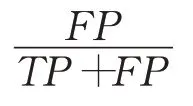
2.4 实验结果及分析
(1)训练结果对比
为了评估注意力机制带来的影响,训练了两组模型:一组为结合双层注意力机制和双向LSTM 网络的L2-AMNN 模型;另一组仅为双向LSTM 网络模型。图4(a)和(b)为L2-AMNN 和双向LSTM 两个模型训练过程中,在验证数据集上的损失函数值loss和准确率accuracy的变化曲线。从图中可看出,两个模型在训练数据集上都显示出良好的收敛性,获得了模型最优参数,后续实验将在测试数据集上科学评估模型性能。
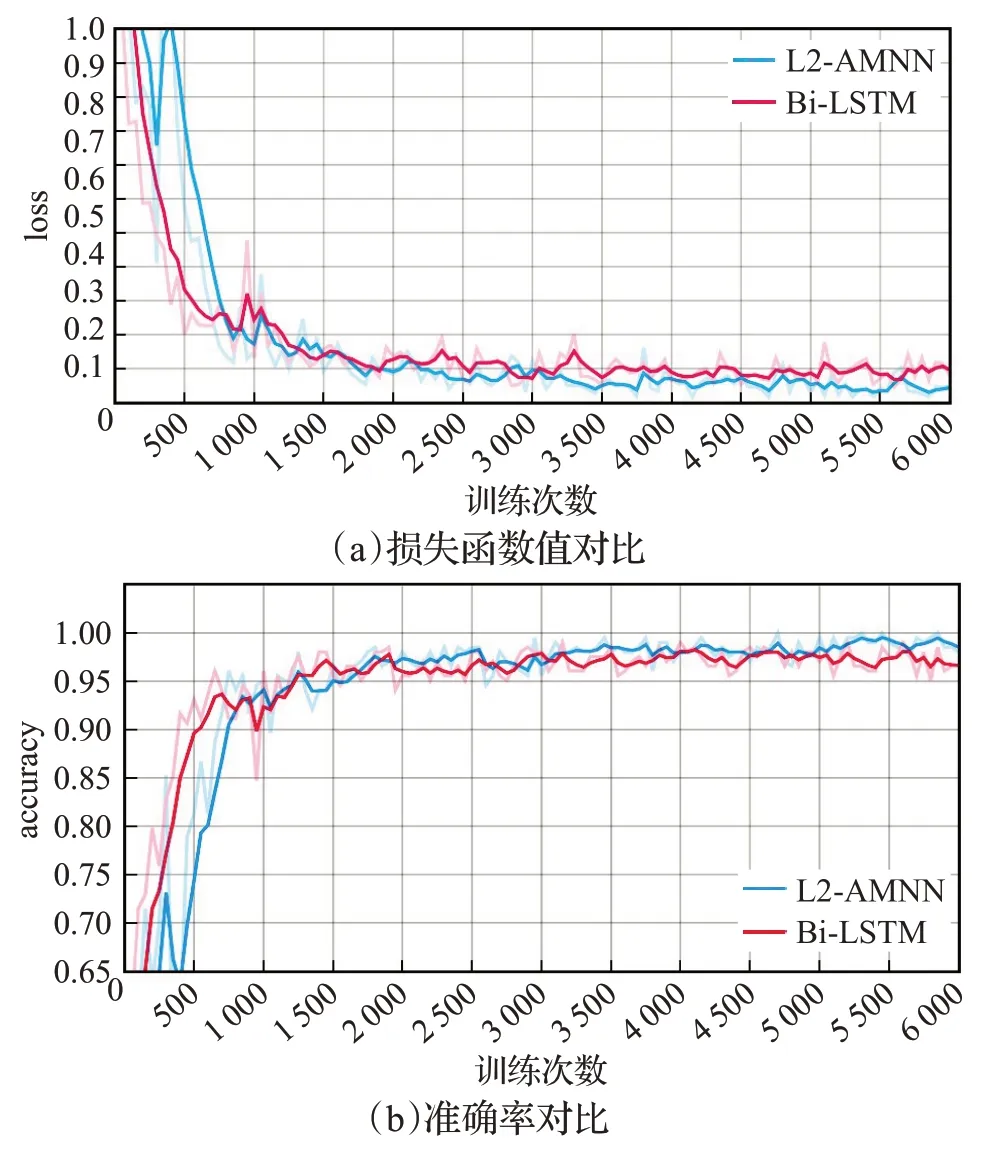
图4 模型训练的准确率和损失值Fig.4 Accuracy and loss of training model
(2)测试数据集分类结果
为了更直观地说明情况,利用混淆矩阵,列出了测试数据集上的详细分类结果。图5 混淆矩阵提供了一种可视化的方式,矩阵的每一列代表预测值,每一行代表真实值,对角线上给出了准确的分类结果,L2-AMNN分类准确率为99.05%,Bi-LSTM分类准确率为97.33%,L2-AMNN 的分类准确率比Bi-LSTM 高了1.72 个百分点,验证了双层注意力机制有助于提高分类准确率。
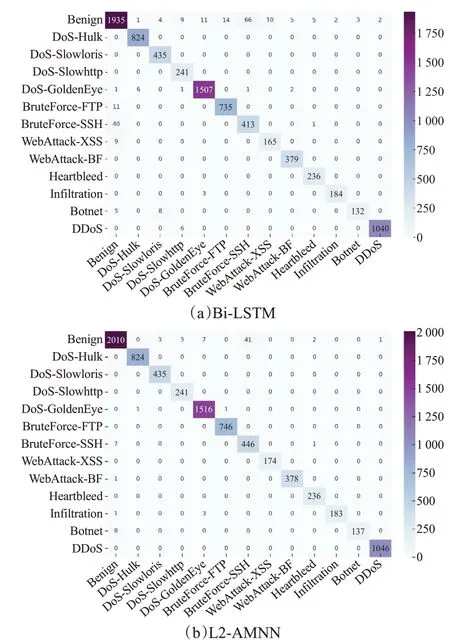
图5 测试数据集分类结果Fig.5 Classification results of testing data sets
(3)分类评估指标分析
为了进一步比较两个模型性能,本文还计算了Precision、Recall 和F1-score 等分类评估指标。表4 显示了两个模型评估指标计算结果,可以看出L2-AMNN模型在各个数据类别中都取得了更好的分类效果。两组实验对比说明,WebAttack、Dos、BruteForce 的分类性能提升最为明显,在WebAttack 数据类别中,由于注意力机制的引入,L2-AMNN模型能够更好地挖掘XSS、Web暴力破解网络流量中的关键攻击信息;对Dos、BruteForce数据类别分析表明,注意力机制能够让模型提取到关键数据包的持续攻击特征,有效提升了模型捕获较长序列重要特征的能力。实验结果也可看出,Botnet 和Brute-Force-SSH的分类效果相对较差。经分析,CICIDS20117中的僵尸网络发起大量非法HTTP请求,但有部分请求与正常流量无异,如POST/api/report HTTP/1.1,造成部分攻击流量未检出,所以检出率较低。另外SSH暴力破解攻击的协议为SSHv2加密协议,表明两个模型对加密协议的检测性能相对较低。
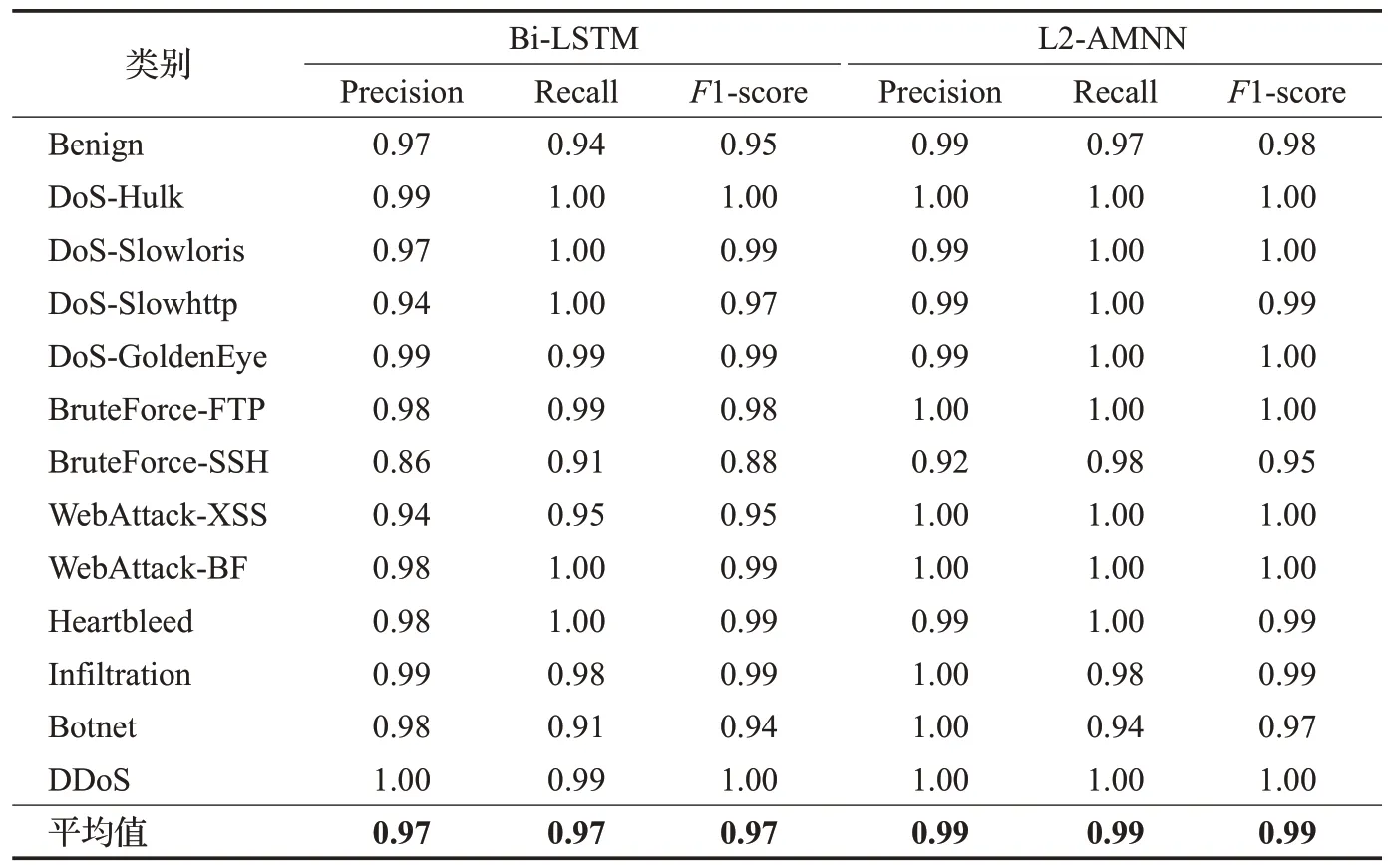
表4 Precision、Recall和F1-score对比结果Table 4 Comparison results of Precision,Recall and F1-score
(4)注意力机制可视化分析
为了更好地理解本文提出的双层注意力机制,分析载荷数据中的字节信息、数据包信息对特定网络攻击类别的影响程度,选取了XSS攻击和FTP暴力破解攻击进行分析,可视化了不同字节和数据包的注意力权重。图6展示了注意力机制可视化结果,每一行为一个数据包部分字节数据,黄色代表字节注意力权重,绿色代表数据包注意力权重,颜色值由权重归一化得到,颜色越深表明权重值越大,对最终的检测分类影响越大。图6(a)展示的是XSS 攻击可视化结果,其中一条数据包为GET 请求“GET/dv/vulnerabilities/xss_r?Name=