
基于用户画像的科技创新知识服务系统构建*
2021-10-14 03:46朱焱王强王涓
数字图书馆论坛 2021年8期
朱焱 王强 王涓
(天津市科学技术信息研究所,天津 300074)
在以全球化、知识化、信息化为主要特征的知识经济时代,科技创新活动面临海量数据分散孤立、知识价值难以判断、资源超载与知识匮乏并存等问题,知识需求和信息供给之间的适当匹配变得越来越重要[1-3]。作为科技创新战略重要实施载体的科技企业和科研院所,尤其需要及时通过准确发现、获取、挖掘、传播和运用知识提高自主创新能力。2015年,国务院印发《促进大数据发展行动纲要》(国发[2015]50号),提出要开展知识服务大数据应用。2016年,国务院印发的《“十三五”国家科技创新规划》(国发[2016]43号)中指出了大数据知识服务的具体发展方向,包括扩大科技文献信息资源采集范围,面向重大科技发展方向搭建语义知识组织体系,深入做好科技资源的语义揭示、开放关联和知识发现能力等。因此,信息服务机构有必要顺应国家政策指引,充分利用资源优势,面向科技企业和科研院所需求,通过技术革新与模式创新开展深度数据加工,从海量数据中挖掘与用户兴趣和用户需求匹配的信息并开展知识服务,为科技企业和科研院所用户创造可持续竞争优势[4-6]。
1 相关研究现状
用户画像(user profile)是建立在一系列真实数据之上的用户模型[7],通过搜集、整理、存储用户的碎片化行为特征、兴趣偏好,抽取与用户信息需求相关的关键指标,给不同的用户按照特征贴标签、建模型[8]。建立用户画像的目的主要是为预测用户行为、发现用户潜在需求提供用于决策的事实支撑,便于对用户进行分析、分类,更好地开展个性化推荐,增强用户对服务的黏度,进行受众挖掘和业务扩展等。
在研发流程上,国内外学者主要基于用户行为、本体特征等,依次按照数据爬取采集、单一用户画像构建与用户行为分析、批量用户画像数据库构建等层次进行架构[9-11],并引入知识图谱技术实现多维信息的检索、抽取、组织、关联、存储、展示、推送[12]。在实现方法上,Godoy等[13]认为满足用户信息需求依赖于获取用户兴趣的方法以及应对用户兴趣变化的策略,需注重研究如何从丰富的语义文本中抽取出关键信息;Ouzif等[14]使用相似性技术找到与目标用户相似的用户及其兴趣,以配置更完整的用户画像,并测试匹配产品推荐、结果过滤、请求扩展等方法的信息服务效果。
在服务产品上,目前很多机构已经利用用户画像数据,针对特定的场景需求和特定领域数据定制、开发知识图谱,开发了成熟的通用型或个性化智能推荐服务产品。在国外,Desarkar等[15]从医学咨询网站用户发表的言论中提取关键语义信息,以用户关注的疾病为主题构建知识图谱;纽约医疗中心Montefiore与Franz Inc和英特尔公司合作部署了PALM“以患者为中心的分析学习机”,同步大量原始数据以进行深入分析,辅助临床医生快速高效地确认高风险患者的个性化治疗方案[16];Microsoft Research公司开发的微软学术图谱能够提供2.1亿位作者、4.7万种期刊和4 000余种会议实体及其学术关联[18];Kensho公司开发的金融知识图谱能够协助证券行业交易员、投资人或分析师预警、识别金融风险[16];Taylor集团开发的wizdom.AI能够挖掘论文数据并建立学者、研究主题、基金、引用趋势等不同概念间关联服务[17];Uber eats平台构建的食物知识图谱能够用图形关联餐厅、菜单、美食的对应关系,方便食客实现快捷查询[16]。在国内,徐芳等[19]基于用户标签和资源标签聚类图书馆用户画像并实现内容推荐服务;Li等[20]和Han等[21]采用聚类方法分析用户浏览过的网页痕迹,对用户和社会化标签进行共现分析和主题聚类,依据用户兴趣主题构建画像模型提高个性化搜索性能;杨群等[22]和朱会华等[23]通过对用户意图进行挖掘和内容推荐构建了移动图书馆情境化服务;刘海鸥等[24]进一步探索如何利用用户画像模型提升改善图书馆行业面向用户市场的信息服务竞争优势。总体而言,国外开展的知识服务主要应用于证券、食品和医疗保健等领域[14],国内知识服务主要结合科研知识图谱应用于高校的学术发现和图书馆服务。此外,国内尚未构建面向产业领域的科技创新用户画像体系,未能支持科技企业、科研院所获取以解决问题为目标的深度知识。本研究重点探索如何利用用户画像技术为产业领域内科技创新主体提供精准的知识服务,并尝试面向大中型科研院所和科技企业开展应用实践,为推动企业科技创新、支撑产业转型升级、提高区域创新效率提供智力支撑。
2 基于用户画像的知识服务系统设计
本研究利用知识图谱作为知识发现和获取的基础,利用用户画像技术来提高知识服务的精准度。首先构建以科技文献资源为主的科技大数据知识图谱,然后根据创新主体的科技创新活动属性构建用户个性化画像,基于画像为其提供精准的知识服务,实现文献、学者、机构、期刊、基金/项目、领域和主题7类知识的快速搜索、全景分析和精准推荐。
2.1 知识服务系统的整体架构
基于前期调研,将知识服务系统的整体架构(见图1)设计为5个模块,分别是数据存储与计算、数据收集与整理、知识图谱、用户画像、知识服务。
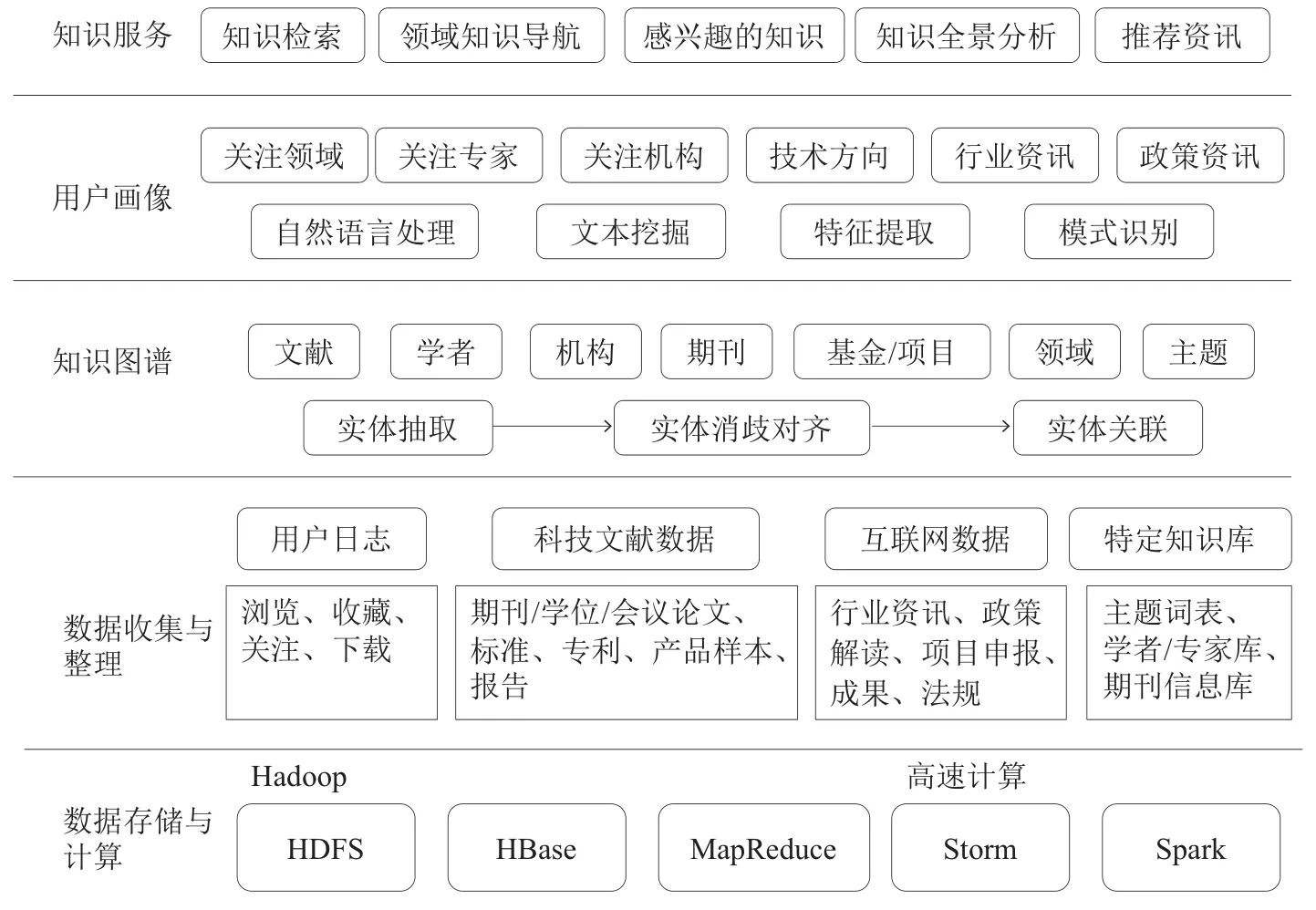
图1 知识服务系统的整体架构
(1)数据存储与计算模块。该模块以Hadoop分布式存储架构对不同来源的数据进行分别存储,为异构数据提供海量存储和高速计算。模块底层分布式文件系统为HDFS,采用HBase作为分布式存储数据库,MapReduce作为分布式计算框架,利用Storm与Spark两种高性能的并行计算方式快速处理数据。
(2)数据收集与整理模块。该模块的主要功能是对不同来源、结构不同的数据进行收集与整理,并实施数据标准化、数据去重和数据补全等预处理。
(3)知识图谱模块。利用自然语言处理技术,使用机器学习或者神经网络学习方法,从清洗好的数据中抽取出文献、学者、机构、期刊、基金/项目、领域和主题7类知识实体,然后进行实体消歧对齐和实体关联处理,建立科技大数据知识图谱。
(4)用户画像模块。依托自然语言处理、文本挖掘、特征提取、模式识别等技术,分别从关注领域、关注专家、关注机构、技术方向、行业资讯和政策资讯6个方面构建用户画像,构建完成的画像能够基于用户反馈实现持续动态更新。
(5)知识服务模块。该模块具备知识检索、领域知识导航、知识全景分析和知识推荐四大功能。知识检索为用户提供精准知识发现服务;领域知识导航为用户提供关注领域内的知识导航服务;知识全景分析帮助用户从全方位的视角观察分析相关知识框架;知识推荐为用户推荐感兴趣的科技文献知识和互联网资讯。
2.2 基于知识图谱的知识库构建
目前知识图谱技术逐渐与信息检索、语义抽取、知识表示、机器学习、数据挖掘、自然语言处理以及语义网等技术方向融合发展[25-26],能否充分挖掘、揭示、展现出某个研究主题内部载体元素之间的关系是知识图谱的建立关键[27]。本研究基于海量的科技文献数据,依次开展实体抽取、实体消歧对齐、实体关联技术,构建一个包含7类实体及其关联关系的科技大数据知识图谱。
(1)实体抽取。图谱中涉及的实体及概念主要有文献、学者、机构、期刊、基金/项目、领域和主题7类。除主题实体外,其他实体都可以从科技文献的相关信息中直接抽取。如从文献的完成作者中抽取学者,从作者的发文单位中抽取机构,从文献出版单位中抽取期刊,从文献获得的资助抽取基金/项目,从文献中图分类号抽取领域。主题的抽取涉及自然语言处理中文本分词等相关技术。首先采用隐马尔可夫模型对科技文献分词,然后利用停用词表过滤分词结果,剔除无用词,最后以主题词表为基础,考虑上位词、下位词、同义词、反义词等关系,结合学术概念词表和行业领域通用词表对分词进行规范,形成最终研究主题。
(2)实体消歧对齐。科技文献中存在大量的重名学者,文献发表的期刊和机构也会有各种曾用名和简称,因此必须对实体进行消歧和对齐。假定学者没有曾用名,首先根据学者姓名确定身份,当姓名相同时,再根据单位确定身份。当姓名和单位都相同时,需要按照研究主题来进行消歧。把姓名和单位都相同的学者所有文献进行主题聚类,根据聚类结果确定学者身份。即有x个同名同单位学者,若所有文献聚类出y个主题,则标识对x个学者进行消歧处理得到y个学者。对重名期刊,根据其ISSN来确定身份。对机构建立(机构名称,曾用名1,曾用名2,…,曾用名n)映射关系,通过映射关系进行机构消歧。
(3)实体关联。实体之间的关联关系是知识图谱的核心内容,也是知识服务的关键。基于各实体之间的关联关系,可以发现无法直接检索到的、隐藏在关联背后的知识。分析文献与其他实体之间的关系,根据这些关系设定基本的关联规则,可以建立其他实体之间的关联关系。从文献中获得的信息可以呈现如下关系:作者体现的是文献与学者/专家的关系;发文单位体现的是文献与机构的关系;研究方向体现的是文献与主题的关系;出版单位体现的是文献与期刊的关系;中图分类号体现的是文献与领域的关系;所获资助体现的是文献与基金/项目的关系。以文献为纽带,主要建立学者之间、机构之间的合作关系,学者、机构与期刊之间的发文关系,学者与机构之间的任职关系,学者、机构与主题、领域之间的研究关系,学者、领域与基金/项目之间的承担关系,主题之间的共现关系,领域与主题之间的包含关系。基于上述的关联关系建立以学者为中心的知识图谱(见图2)。
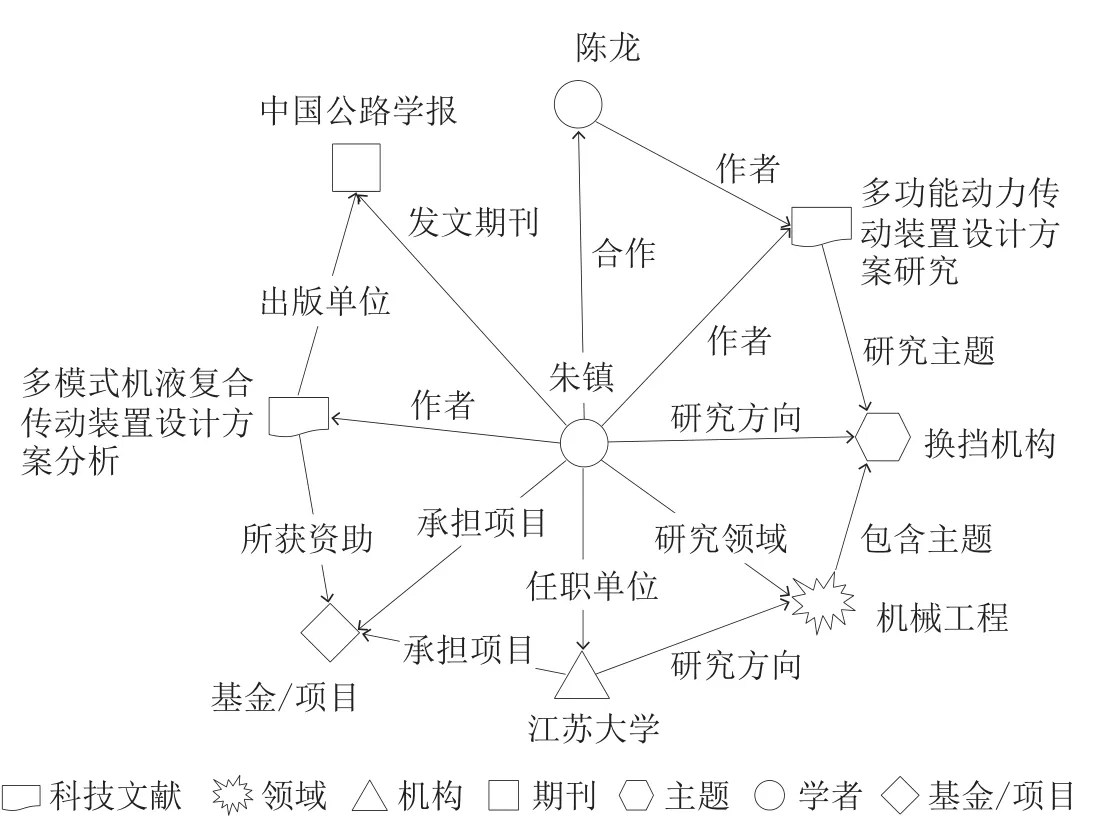
图2 以学者为中心构建的知识图谱示意图
2.3 用户画像构建
本研究以科研创新活动用户为对象,构建的用户画像具备科研标签、技术标签和资讯标签,具体构建流程如图3所示。①数据采集。主要任务是采集构建用户画像模型所需基础数据,包括科研需求数据、科研行为数据和互联网资讯数据。其中,科研需求数据包括用户经常关注的领域、专家和机构,主要利用调查问卷和访谈法与用户深入沟通获得;科研行为数据是用户在查找科技文献活动中产生的数据,包括浏览、下载、关注和收藏记录等,主要通过用户活动日志获得;互联网资讯数据是用户经常浏览的行业信息和政策信息,主要通过专业数据抓取工具获得。②数据组织与整理。该步骤主要通过数据规范、数据分类、数据清洗、数据去重等技术对基础数据进行标准化和整理加工,建立用科研需求画像数据库、科研行为画像数据库和互联网资讯画像数据库。③标签抽取与用户画像。该步骤是构建用户画像模型的核心,利用自然语言处理、数据挖掘、模式识别、特征提取等技术,建立用户标签数据库,完成用户画像建模。
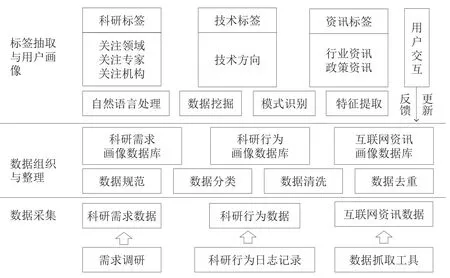
图3 用户画像模型构建流程
3 基于用户画像的知识服务功能实现
基于用户画像的科技创新知识服务系统的构建,要结合企业与科研院所开展科学研究、技术创新过程所需领域知识的特点,以及检索、下载、订阅等科研行为的情况,其服务功能应包括知识精准检索、知识全景分析、领域知识导航、知识推荐4类。
3.1 知识精准检索功能
传统的文献检索无法揭示蕴藏在科技文献中的知识,而基于用户画像的科技创新知识服务系统通过碎片化挖掘、语义化关联,深度抽取资源内容特征构建的科技数据知识图谱,针对文献、学者、机构、期刊、基金/项目、领域和主题建立交叉和关联检索。输入关键词后不仅可以直接检索到相关主题知识,还可以直接获取上述各种关联知识。如通过研究领域、研究主题、所在单位、发文期刊、所获资助都可以检索到相关研究学者;根据姓名可以直接检索到其所在研究机构,同时也可以获得与该研究机构对应的研究领域、研究主题、发文期刊、所获资助等,通过这些又能检索相关的其他研究机构;根据研究领域可以检索到相关主题,不仅可以查询到相关主题知识目录,还可以同时获得与主题相关的专家学者姓名、主要机构、发文期刊、相关主题下的基金/项目信息等。
3.2 知识全景分析功能
针对每个知识对象,都能从相关文献、研究专家、合作机构、研究主题、研究领域、发表期刊、所获基金/项目7个方面对其进行深度揭示。就研究主题而言,可揭示研究内容与其相关的所有科技文献、研究该主题的学者与机构、经常与其共现的主题、发表该主题文献的期刊、该主题隶属的研究领域、该主题被哪些基金项目资助等,还可以呈现历年的文献发表量、被引量和H指数等研究概况,方便用户快速全面了解和分析整个研究主题及其发展脉络;就专家/机构而言,可以查看其最新的研究成果,展示其主要研究方向,发现与其从事产业、行业或开发方向相似的专家/机构,方便用户开展产学研合作或产品开发咨询。
3.3 领域知识导航功能
基于用户画像建立的关注领域标签,结合知识图谱中的领域实体,可以建立用户关注领域知识目录,并以此为基础为用户提供关注领域内的知识导航服务,包括领域内的研究主题、相关的科技文献、相关的研究学者和研究机构等。知识目录树的建立是知识导航的基础,根据领域概念的上下级或隶属关系,把用户画像模型中的关注领域进行重新组织和规范表达,形成领域知识目录。利用文本相似度技术从知识图谱中找到与叶子节点最相似的领域实体,为用户推送该领域实体对应的研究主题,以及与该研究主题相关的文献、学者、机构。
3.4 知识推荐功能
该功能主要基于用户画像中的关注专家、机构和技术标签,采用内容推荐算法和协同过滤算法为用户推荐感兴趣的知识,具体包括订阅推荐和科研行为推荐。其中,订阅推荐基于用户主动关注的专家和机构信息,利用基于内容的协同过滤算法,找出与用户关注的专家和机构研究方向相似的专家和机构,推荐给用户;科研行为推荐主要基于用户的技术方向信息,采用内容推荐算法为用户推荐与其技术方向相似的科技文献、研究主题、专家和机构。
4 应用成效
系统建成后,选择天津市内重点产业领域的科研院所和科技企业开展应用实践。在双向沟通交流中厘清各类型用户的科技创新特点与科研生产主题,先后建立画像库和知识服务平台,并依托科技成果转化推广体系深入开展知识服务,力求通过实践将基于用户画像的科技创新知识服务系统从科技成果切实转化为社会生产力。
4.1 知识图谱的应用成效
以天津科技文献共享服务平台总量超过5亿条的科技文献资源为基础数据,利用前面所述的知识图谱构建方法,经过实体抽取、实体消歧对齐、实体关联3个步骤,挖掘整理了近1 000万个学者、20万个机构、200万个主题、5万个基金项目、5万种期刊传媒、500个研究领域,其中对200万个学者和机构进行了消歧处理,同时建立了10亿条知识对象之间的关联关系,最终构建了一个包含科技文献、学者、机构、期刊、基金/项目、领域和主题7类实体及其关联关系的科技大数据知识图谱。
4.2 基于用户画像的知识服务系统应用成效
面向天津市轨道交通、海水淡化、新能源、新材料等重点领域10余家领军企业、科研院所,梳理用户关注的领域、专家和机构,收集和分析用户科研行为,包括浏览和下载的科技文献、互联网信息、科技项目信息等数据,为每家企业和科研院所构建了个性化的用户画像模型,搭建了定制化知识服务系统,为其获取已有知识、发现潜在知识及知识之间的关联关系提供了全面支撑。搭建的轨道交通和海水淡化知识服务平台,梳理了铁路轨道交通和海水淡化领域的5 125个研究主题、91个期刊、107个专家、77个机构、125个标准,帮助用户全面了解和跟踪该领域的研究主题、行业专家和行业机构,以及最新的技术热点,根据其个人画像模型为其推荐该领域的重点文献、热门专家和机构,提高了用户在该领域的技术创新能力。
4.3 面向区域、行业、企业的知识服务系统应用成效
在国内重点区域、行业、企业与科研院所的探索实践中,不断调整融合系统功能、用户需求、资源内容,最终形成个性化业务搭建流程,能够在短期完成一站式检索、知识目录推荐、项目申报与科技政策、标准规范、行业动态等13个知识服务功能模块的高效部署。
(1)区域知识门户。面向天津市某重点区县搭建了区域知识门户,除具有通用知识服务功能外,还针对用户个性化文献资源管理与服务平台快速、自定义搭建需求,开发了文献资源个性化选择部署、门户布局个性化定制、用户分级管理以及动态信息自主发布模块,为区域内企业和科研院所科技创新提供强有力的知识服务支撑。
(2)行业知识门户。搭建完成科技情报、科技咨询等重点行业领域知识门户,针对行业特点和行业内企业需求,构建了重点行业领域主题词表和专业知识图谱,并根据特色行业企业创新需求开发互动功能,为本地特色行业企业提供广覆盖式的知识服务。
(3)企业与科研院所知识门户。面向轨道交通、海水淡化、新能源、新材料等重点领域10余家领军企业、科研院所,建成定制化知识服务门户,为每家企业院所构建了用户画像模型和关注主题知识图谱,充分调用知识服务系统全功能,帮助企业与科研院所实现知识的有效管理和应用,为其开展轨道设计、海水淡化与利用等方面的关键技术研究提供了有效知识服务支撑。
5 结语
该项研究对国内开展区域、行业、科技企业、科研院所科技创新知识服务具有重要意义。一方面,针对科技企业、科研院所开展了基于科研项目主题或产业链上下游主题的用户画像工作,并对科技文献资源中蕴藏的知识对象进行了深度知识挖掘,构建了一个包含科技文献、学者、机构、期刊、基金/项目、领域和主题7类实体及其关联关系的科技大数据知识图谱;另一方面,通过开展推广应用,成功发挥了该系统的社会效益与经济效益,高效解决产业、行业、企业领域科技创新用户的知识检索、获取和发现问题,并开拓面向科技管理决策的应用领域,充分体现人工智能对传统科技信息服务生态的全面升级,积极助力大数据技术与产业实体经济融合创新和长远发展。需要指出的是,由于已经在应用研究中建立了良好的用户基础和应用推广体系,今后有望在更大范围、更深层次、更高水平上获得可持续发展。
猜你喜欢
小哥白尼(神奇星球)(2022年3期)2022-06-06
管子学刊(2022年2期)2022-05-10
中北大学学报(自然科学版)(2022年2期)2022-05-05
管子学刊(2022年1期)2022-02-17
少先队活动(2020年12期)2021-01-14
新世纪智能(高一语文)(2020年9期)2021-01-04
非公有制企业党建(2020年10期)2020-10-27
中成药(2017年3期)2017-05-17
影视与戏剧评论(2016年0期)2016-11-23
领导科学论坛(2016年9期)2016-06-05
