
基于高光谱技术的鲜食水果玉米含水率无损检测
2021-10-12 01:50廉孟茹张淑娟池江涛穆炳宇孙双双
食品与机械 2021年9期
廉孟茹 张淑娟 任 锐 池江涛 穆炳宇 孙双双
(山西农业大学农业工程学院,山西 太谷 030801)
鲜食玉米含有丰富的蛋白质、脂肪、糖类、钙、胡萝卜素、维生素等营养成分[1],是人们餐桌上的美食。鲜食玉米籽粒含水率为70%左右时食用风味和营养最佳,此时为鲜食玉米的最佳收获期。采收过早,干物质和各种营养成分不足、产量低、效益低;采收过晚会使鲜食玉米风味变差。而人工识别最佳采收期的玉米不仅费时费力,而且还会损伤鲜食玉米。
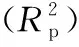
近年来,高新浩等[10]设计了一种基于机器视觉的鲜食玉米品质检测分类器,实现了对不同品种、尺寸以及破损程度的鲜食玉米进行分类。但是还未有高光谱成像技术应用于鲜食玉米含水率无损检测的报道。研究拟采用高光谱技术对鲜食水果玉米进行光谱数据采集并提取,通过比较不同预处理方法和特征波长提取方法,选用决定系数(R2)最大、均方根误差(RMSE)值最小的处理方法作为鲜食水果玉米的最佳建模方法,以此实现对鲜食玉米含水率的预测。
1 试验
1.1 材料
鲜食水果玉米样本于2020年7月17日采摘自山西省榆次区北田镇北田村,于当天运送至实验室,选取尺寸大小均匀、无病虫害的水果玉米144根,其标号,人工剥开玉米苞叶,去除玉米须,采集光谱信息及相关试验。利用Kennard-Stone算法[11]将鲜食水果玉米样本按3∶1的比例划分为校正集和预测集。得到校正集玉米样本108个,预测集玉米样本36个。
1.2 主要仪器
高光谱分选仪:ZOLIX Gaia Sorter型,北京卓立公司;
电热鼓风干燥箱:SY101-2型,天津市三水科学仪器有限公司。
1.3 光谱采集
采集光谱的波长范围为900~1 700 nm。采集玉米的光谱信息,光谱分辨率为9 nm。设置曝光时间为20 ms,平台移动速度为2 cm/s,样本与镜头的距离为22 cm。提取样本感兴趣区域为50个像素点×50个像素点。为了消除光强变化和镜头中暗流对采后数据的影响以及计算扫描物体的相对反射光谱值,在光谱数据采集前先采集黑白板,并对高光谱采集后的数据进行黑白校正,计算公式为:
(1)
式中:
R——校正后的图像;
I——原始图像;
B——黑板校正图像;
W——白板校正图像。
1.4 含水率测定
鲜食玉米籽粒称重后,置于105 ℃电热鼓风干燥箱内干燥至恒重(6 h左右),测定玉米籽粒烘干后的质量[12],按式(2)计算玉米籽粒含水率。
(2)
式中:
W——鲜食玉米的含水率;
W1——烘干前玉米的质量,g;
W2——烘干后玉米的质量,g。
1.5 原始光谱
水果玉米的原始光谱图如图1所示。
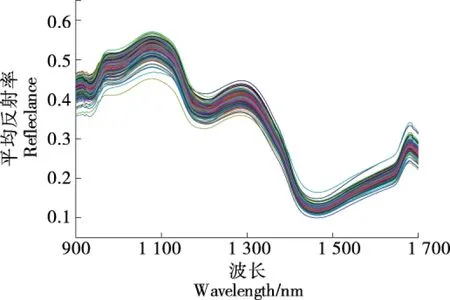
图1 水果玉米的原始光谱图Figure 1 The original spectrum of fruit corn
从图1可以看出,样本集玉米光谱平均反射率曲线整体趋势一致。玉米光谱900~1 700 nm的光谱范围内时光谱反射率范围大约为0.12~0.53,在波数为970,1 200,1 450 nm附近处有3处明显的特征峰。970,1 450 nm附近的特征峰来源于O—H键的伸缩振动,与水分子的结构有关[13-14];1 200 nm附近的特征峰为液态水的组合频吸收带[15];1 450 nm是O—H键一级倍频峰[16]。
1.6 鲜食玉米含水率的描述统计
通过使用直接干燥法测定的含水率频率直方图如图2 所示。
从图2和表1可以看出,鲜食水果玉米样本的含水率分布在0.68~0.81。含水率的均值、中值和众数都在0.75 附近,含水率分布大致符合正态分布。
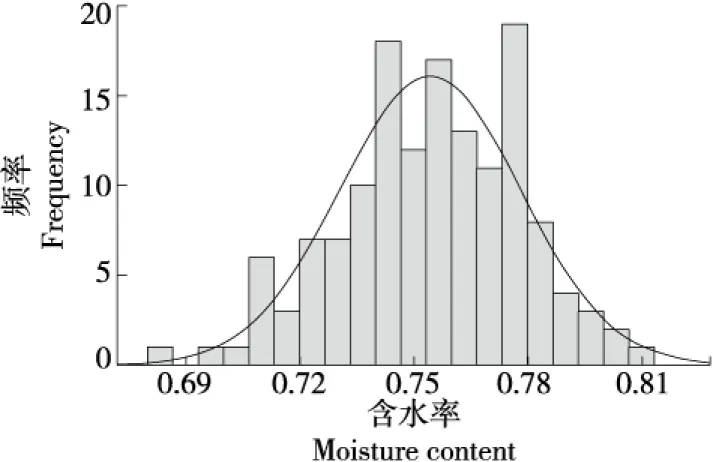
图2 水果玉米含水率频率直方图Figure 2 Frequency histogram of moisture contentof fruit corn
2 数据处理
2.1 光谱预处理
光谱数据预处理可以消除光谱数据采集过程中试验仪器产生的噪声、背景干扰、周围杂散光干扰等因素对数据的影响[17],消除光谱数据中的冗余信息,提高模型的准确率。试验采用变量标准化算法(SNV)、附加散射校正算法(MSC)、卷积平滑(SG)、去趋势法(De-trending)、移动平均法(MA)和归一法(Normalize)6种方法对玉米光谱数据进行预处理,并与原始光谱数据(RW)建模效果作对比,预处理后的光谱图如图3所示。
图3 预处理后的光谱图Figure 3 Spectrum after pretreatment
测定的玉米样本含水率的描述性统计数据如表1所示。

表1 玉米样本含水率描述性统计数据
对处理后的光谱数据建立偏最小二乘回归(PLS)模型比较建模效果如表2所示。
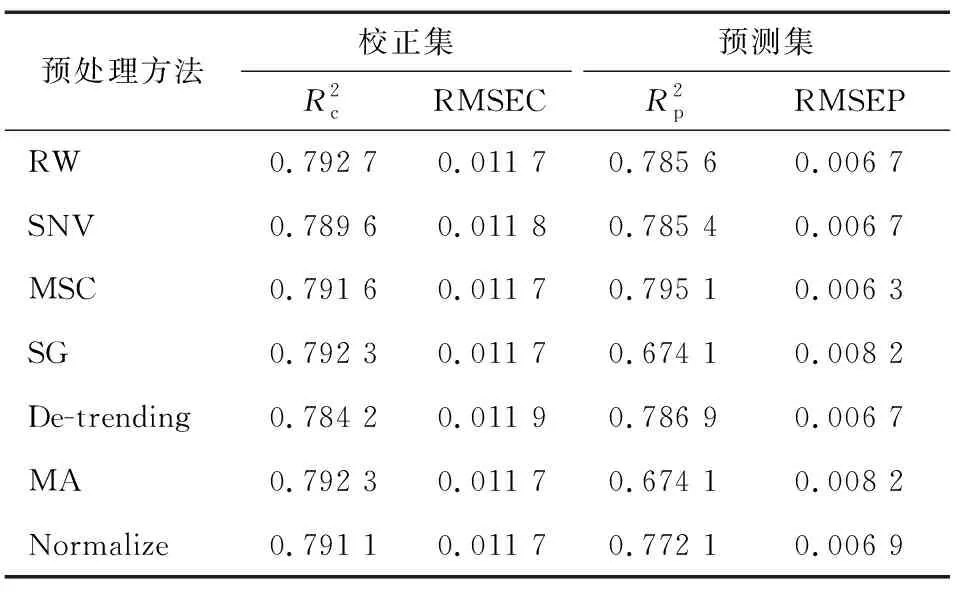
表2 光谱预处理方法对PLS建模结果的影响
2.2 光谱数据建模
高光谱数据中包含了大量化学和物理信息,具有高维度和共线性问题,其中一些相关性不强的光谱信息会影响建模效果,不仅使建模时间增加,还会降低模型相关性[18-19]。为了更加高效准确地预测模型效果,需要对光谱数据进行特征波长的提取。选用连续投影法(SPA)、竞争性自适应加权重算法(CARS)和随机蛙跳法(RF)3种方法来优选特征波长,并利用优选出的特征波长建立PLS回归模型来比较建模效果。
2.2.1 SPA特征波长提取 采用SPA建模优选过程及所筛选出的最优波长如图4和图5所示。
由图4和图5可知,优选的变量数目从1到6变化时其对应的均方根误差(RMSE)值在减小;变量数目超过6时,RMSE值开始增加;当变量数目为6时,RMSE值最小,为0.012 375,所以采用SPA建模方法优选出6个特征波长,分别为1 074,1 141,1 182,1 278,1 685,1 700 nm。
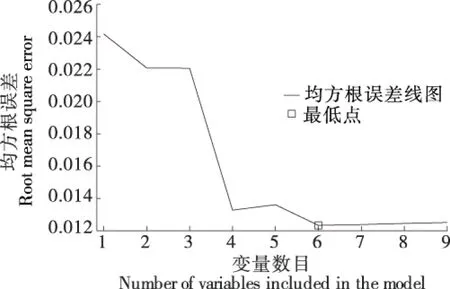
图4 特征波长优选过程Figure 4 Feature wavelength optimization process
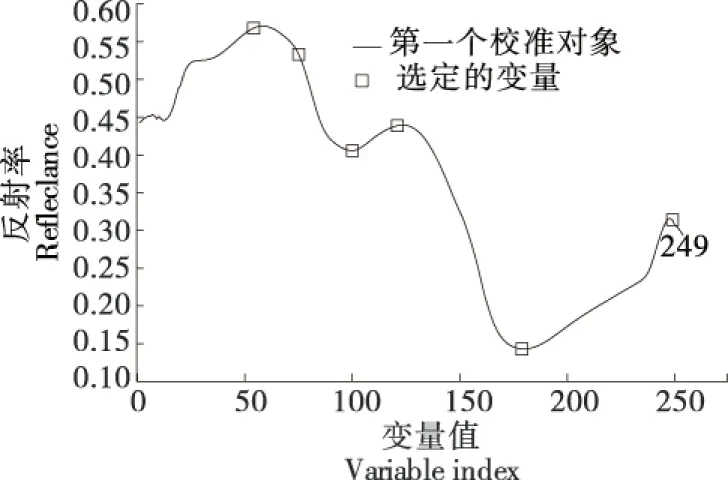
图5 SPA提取的特征波长Figure 5 Feature wavelength extracted by SPA
2.2.2 CARS特征波长提取 采用CARS建模,设置蒙特卡罗采样次数为50次,优选过程及所筛选出的最优波长如图6所示。
从图6(a)可以看出,随着蒙特卡罗采样次数从1次增加到50次,所采集的变量由254个减小到2个;从图6(b)可以看出,交叉验证均方根误差(RMSE)的值呈由大变小再变大的趋势,在第35次采样时均方根误差最小,最小值为0.011 3;图6(c)为波长变量优选过程中各波长变量回归系数的变化趋势,第35次采样时均方根误差最小。由CARS模型运行结果提取出16个特征波长,分别为902,918,953,1 064,1 128,1 131,1 195,1 198,1 310,1 380,1 421,1 424,1 488,1 491,1 535,1 545 nm。
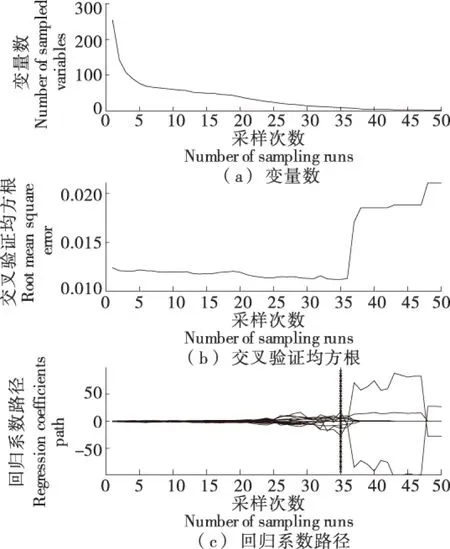
图6 CARS提取的特征波长Figure 6 Feature wavelength extracted by CARS
2.2.3 RF特征波长提取 采用RF建模,为了减小随机蛙跳法所产生的不稳定性,蒙特卡罗采样次数应尽可能多,设置蒙特卡罗采样次数为2 000次,优选过程及所筛选出的最优波长如图7所示。
概率越大的变量对建模的贡献率越大,从图7可以看出,波段的选择概率范围为0.0~0.6,大部分变量的选择概率值都很小,只有少数变量的选择概率峰值比较突出,可被确定为特征波长,选择概率大的数据坐标点有(3,0.224 0)、(57,0.242 5)、(73,0.300 0)、(75,0.273 0)、(76,0.245 0)、(93,0.232 5)、(98,0.215 0)、(132,0.211 5)、(167,0.213 5)、(186,0.537 0)共计10个,其对应的特征波长分别为902,1 074,1 125,1 131,1 135,1 189,1 205,1 313,1 424,1 485 nm。
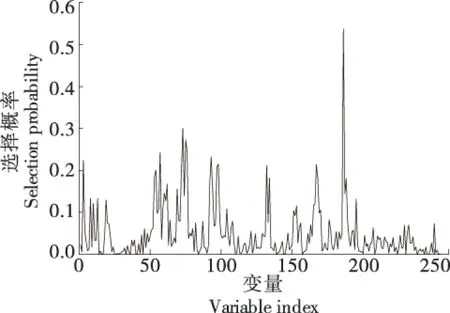
图7 RF提取的特征波长Figure 7 Feature wavelength extracted by RF
3 建模结果与分析
比较基于MSC预处理的3种特征波长的PLS建模结果与原始光谱的PLS建模效果如表3和图8所示。
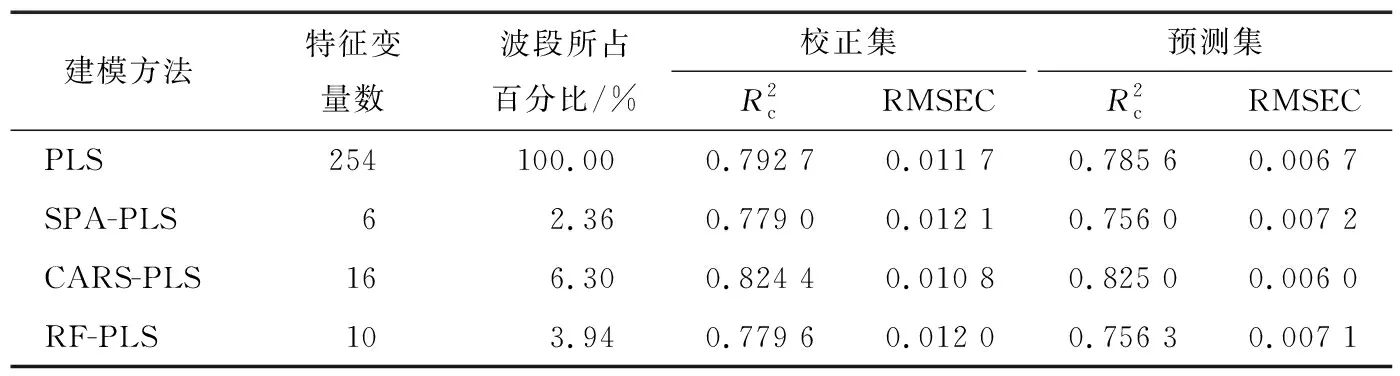
表3 不同特征波长提取方法对PLS建模效果的影响
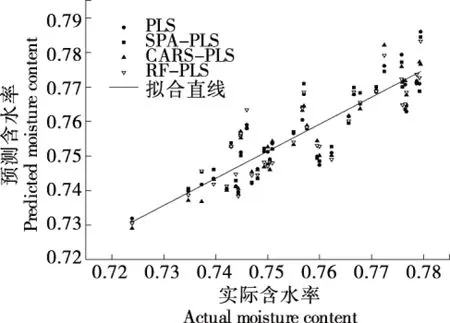
图8 3种特征波长的PLS建模与原始光谱的PLS建模预测效果
4 结论
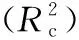
研究基于去除苞叶的鲜食玉米进行光谱信息采集并建立含水率模型,该模型预测效果较好。但是针对田间未去除苞叶的鲜食玉米含水率的无损检测模型还需进一步研究。
猜你喜欢
今日农业(2022年3期)2022-11-16
今日农业(2022年1期)2022-06-01
温州大学学报(自然科学版)(2022年2期)2022-05-30
今日农业(2021年3期)2021-12-05
阅读(科学探秘)(2021年8期)2021-09-01
潍坊学院学报(2020年2期)2021-01-18
照明工程学报(2020年1期)2020-06-16
照明工程学报(2020年1期)2020-06-16
今日农业(2019年15期)2019-09-03
制导与引信(2017年3期)2017-11-02
