
创建民族团结进步示范州载体研究
——以红河州哈尼、彝、汉三种文字标牌翻译软件开发为例
2021-10-12 11:05常亚昕龙云飞
红河学院学报 2021年5期
常亚昕,龙云飞
(红河州民族研究所,云南蒙自 661199)
一 问题的提出
红河哈尼族彝族自治州境内居住着哈尼、彝、苗、傣、壮、瑶、回、布依、拉祜、布朗(莽人)等10个少数民族,少数民族人口占全州总人口的61.5%(2020年),其中哈尼族人口最多。我国宪法规定:各民族都有使用和发展自己的语言文字的自由。为认真贯彻落实《中华人民共和国民族区域自治法》《红河哈尼族彝族自治州自治条例》,2011年7月,红河州委州政府下发文件《关于规范使用哈尼之、彝之、汉之三种文字标牌的通知》(红办发〔2011〕87号),红河州正式使用哈尼文、彝文、汉文三种文字(以下简称“三种文字”)标牌。
2019年,红河州成功创建为全国民族团结进步示范州,“三种文字”标牌作为创建示范州宣传工作的载体之一,以视觉文字的形式展现了红河哈尼族彝族自治州民族文化特色,结合开展民族团结进步创建工作。截止2019年底,“三种文字”标牌已覆盖范围包括:州、县(市)、乡(镇、办事处)党和国家机关、人民团体的名称标牌;州党代会、州人代会、州政协会及州委、州人大常委会、州政府、州政协召开的重要会议、重大活动的会标;州、县(市)人民政府所在地事业单位的名称标牌;州、县(市)人民政府所在地城区主要道路、街道、公共设施的名称标牌;州内主要旅游景点名称标牌;州、县(市)人民政府所在地的部分宾馆、酒店;国有、私营企业;主要街道的商号、店铺等等,以及各种重大节庆活动、民族团结宣传月、宣传周、民族团结进步创建活动等宣传标语。“三种文字”标牌自2011年启动以来,粗略统计已翻译6万余条。
二 开发“三种文字”标牌翻译软件的必要性
(一)解决人员不足,提高工作效率
目前承担全州翻译工作的任务主要集中在红河州民族研究所,且翻译人员不足。因为翻译任务是根据需要安排,不定时也不定量,所以在翻译任务比较集中的时候不免出现翻译人员无法按时完成任务的情况。笔者从2011年从事“三种文字”标牌翻译工作至今,在多年的翻译实践中通过分析工作中遇到的问题,提出此开发“三种文字”翻译软件的设想,希望通过软件的开发运用,提高工作效率,促进红河州“三种文字”标牌翻译工作长期有效地发展。
2019年7月州委州政府颁布了《关于贯彻全面深入持久开展民族团结进步创建工作 铸牢中华民族共同体意识的实施意见》(红办发〔2019〕50号),意见提出的主要任务之一就是深化民族团结进步宣传教育。同年12月,国家民委命名红河哈尼族彝族自治州为“全国民族团结进步示范州”。“三种文字”标牌作为我州创建全国民族团结进步示范州宣传工作的载体之一,为进一步巩固提升全国民族团结进步示范州创建成果,推进新时代红河州民族团结进步创建工作由“创建型”向“示范型”转变,不断铸牢中华民族共同体意识,开发一款适用于红河州翻译哈尼文、彝文、汉文“三种文字”标牌的翻译工具,并将翻译软件推广到各县市民宗局,达到各县市可以独立运用翻译软件翻译“三种文字”标牌的目的。这也是践行国家相关民族语言文字政策的体现,同时有利于本民族人民增强文化自信,有利于树立自觉学习、保护和发展民族语言文字的意识[1]。并且符合少数民族语言文字信息化、办公自动化趋势。
(二)创建哈尼文、彝文数据库,提高标牌翻译的规范化
1.“三种文字”标牌翻译软件的开发研究属于少数民族语言文字机器翻译技术的研究。机器翻译(Machine Translation)是指利用计算机完成一种自然语言到另一种自然语言的转换,它涉及多门学科,包括语言学、数学、计算机科学等,是一种多领域交叉学科[2]。而少数民族语言文字机器翻译技术的研究更是一项复杂的工作,因为少数民族语言的句子结构与汉语存在巨大差异。受到市场规模、语料库规模、研究人员数量、经费支持力度等多种因素的制约,目前我国少数民族语言文字机器翻译技术整体上还处在初级阶段[3]。此涉及的哈尼文、彝文两种少数民族语言文字中,目前面世的彝语言文字计算机信息处理系统比较多,而哈尼语言文字计算机信息处理系统尚无。
2.大多数少数民族语言一般有小型词典,但没有完备的语料库,在句法分析方面的研究也基本处于空白[4]。目前我们“三种文字”标牌翻译的对象主要是名词性的新词术语,包括彝文和哈尼文在翻译过程中我们大多采用音译的方式。根据这个特点,我们就扬长避短明确问题,即软件仅针对目前红河州“三种文字”标牌翻译工作,承担哈尼文、彝文、汉文三种文字标牌的翻译。由于少数民族语言独特的性质,其句子结构与汉语存在巨大差异,为简化和集中解决问题,软件暂不承担其他文章、古籍、对话等的翻译。这样我们在开发过程中就大大简化了问题。
3.由于我们平时需要的标牌有横向和竖向之分,所以“三种文字”标牌翻译软件需要输出横排和竖排两种情况,即要考虑三种文字在横向和竖向时的书写方式。其中汉字比较简洁,直接排版即可,彝文是传统的表意文字,在标牌翻译中可与汉字一一对应,而哈尼文是拼音文字,且在横向书写时,是以词为单位相连在一起,词与词之间用空格隔开,而在竖向标牌中,则要单个字分开,如下面的例子。为显正式与庄重,目前标牌翻译中哈尼文都采用大写字母书写。
横排:

蒙自市社会主义学院
竖排:

三“三种文字”翻译软件设计与实现
(一)软件设计思路
首先把要翻译的汉文内容根据横排和竖排的需要进行分词,在分词的过程中后台要通过分词算法给出正确的分词结果,然后进行翻译,即从词库中寻找到汉文匹配的哈尼文和彝文。词库需要收录日常使用的工具书《汉哈尼新词术语集》《汉哈尼词典》《汉彝大辞典》中的大部分词汇及其之相应的译文(哈尼文和彝文);还要收录之前翻译过的所有“三种文字”标牌词汇;并尽量收录红河州各县市、乡镇、社区、村委会、自然村的名称和有可能需要挂牌的词汇。词库是一个很重要的数据库,词库里面收录的词汇决定了翻译结果的正确性和完整性,如果词库里没有收录该词汇,则出不了相应结果,这就需要及时补充和完善,为此该软件还需设置词汇新增功能,若有重复收录词汇的情况,系统也能自动识别避免重复。找到了匹配的哈尼文和彝文,则根据需要排版成横排或竖排,以word文档形式,根据用户设置的路径输出到目标文件夹里,这里可设置单独输出横排或竖排,也可同时输出横竖排,最后用户只需对输出的结果进行核查和微调即可。
(二)软件总体架构
初步设想本系统提供以 B/S 架构(即浏览器和服务器架构模式)为主的 Web 应用,也提供可独立运行的 C/S 架构(即客户机/服务器模式)windows 客户端应用。系统大致分为四个部分,第一部分为用户交互层,提供 Web 网页和 windows客户端两种方式,其中 Web 网页支持电脑、Pad、手机浏览器通过互联网访问。Windows 客户端支持断网离线使用,也可以支持联网后自动更新最新数据使用。第二部分为服务层,此部分主要是依托于IIS(Internet Information Services互联网信息服务)提供服务,针对windows 客户端提供了WCF(Windows Communication Foundation是由微软开发的一系列支持数据通信的应用程序框架,可以翻译为Windows 通讯开发平台)服务进行数据更新。第三部分为标牌翻译软件核心模块翻译引擎,此部分主要是哈、彝、汉词库,根据词库自动生成中文分词词库,分词算法根据中文分词词库对需翻译的汉文进行词法解析,然后根据词法解析结果,对照词库进行翻译并输出结果。第四部分为数据存储区域,本系统采用轻量级的免费数据库,windows客户端也提供了本地数据存储。
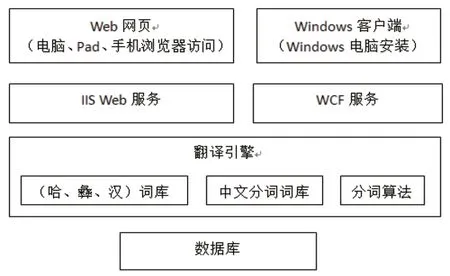
图1 软件总体架构
(三)系统结构和各部分功能模块
本系统设计功能结构模块分为基础功能、业务功能、系统管理、翻译引擎四部分,如图2。各模块的详细功能介绍如下:
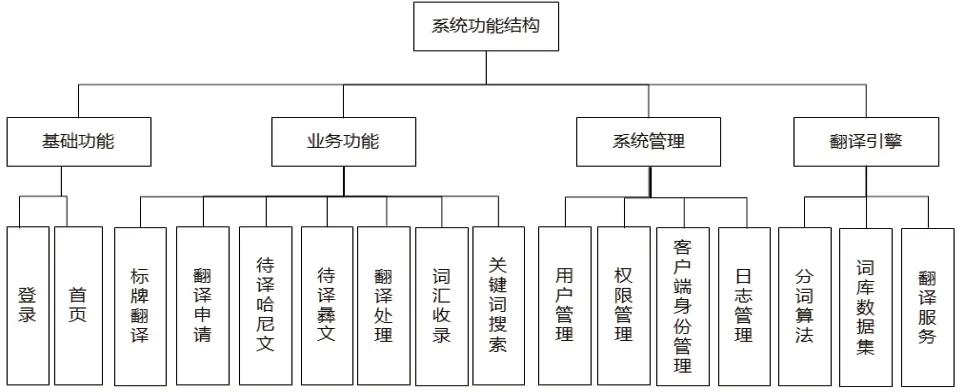
图2 系统功能结构图
1.基础功能主要是完成系统的登录认证,进入系统首页后能看到系统整体的使用概况,包括词汇收录情况,待译数据情况等直观图表展示。
2.业务功能为本系统的重要组成部分,涵盖了待译词汇的申请、翻译处理、词汇收录、标牌翻译以及收录语料的搜索查询。翻译申请,考虑到哈尼文和彝文的不同翻译以及对应不同的使用者,为协调进行翻译工作的进行,在进行翻译申请时,分别自动生成待译哈尼文和待译彝文清单。当哈尼文和彝文工作者翻译完成时,系统将自动收录汉文、及对应的哈尼文和彝文词汇。翻译处理,哈尼文和彝文工作者分别处理待译清单内容。词汇收录,可以直接收录汉文、哈尼文、彝文词汇,并且可以对收录词汇进行增加、删除、修改、查询。标牌翻译,此功能也是本系统最终的应用核心。该功能提供友好的输入界面,输入待翻译的中文信息,点击翻译,系统将经过分词算法对待译中文进行分词和翻译,并将分词结果和对应的哈尼文和彝文返回界面。系统提供将翻译结果导出至 word(横排、竖排)文档,与此同时可以将翻译结果收录至语料库以便后续进行查询。
3.系统管理主要包括用户管理,权限管理,客户端身份管理,日志管理等功能。用户管理包括新增、删除和修改用户密码。权限管理,用于给用户授权不同的系统使用功能,可以进行增删改查。客户端身份管理,主要用于windows 客户端访问者的身份验证,以确保数据访问的安全性。日志管理,主要进行系统操作的日常记录,以便审计和排查问题。
4.翻译引擎是系统的关键模块,它通过分词算法的运算和与词库内词汇的匹配,提供翻译服务。如下为此系统采用的翻译规则和算法,如不满足算法规则则不能出结果。
基本翻译规则:汉文语句分词取决于收录词汇,未收录词汇只能被解析为单个字;汉文分词算法:双向最大匹配(详见下方算法资料);汉文语句能够按照算法进行分词,然后再根据分词结果进行翻译;针对词汇,翻译成哈尼文时横排中间没有空格,竖排是哈尼文单词与汉文单词对齐即可;汉文与彝文字符一对一翻译,不考虑一对多或者多对多的翻译;考虑到标牌翻译多为名词组合,为简化问题,不考虑语法语序问题,按照汉文的先后顺序一一对应。
算法包括正向最大匹配算法和逆向最大匹配算法,详细解析如下:
(1)正向最大匹配算法:第一步,从左向右取待切分汉语句的 m 个字符作为匹配字段,m 为翻译引擎词库中最长词条个数。第二步,查找翻译引擎词库进行匹配。若匹配成功,则将这个匹配字段作为一个词切分出来。若匹配不成功,则将这个匹配字段的最后一个字去掉。剩下的字符串作为新的匹配字段,进行再次匹配,重复以上过程,直到切分出所有词为止。
(2)逆向最大匹配算法:该算法是正向最大匹配的逆向思维,匹配不成功,将匹配字段的最前一个字去掉。实验表明,逆向最大匹配算法要优于正向最大匹配算法。
(3)双向最大匹配法:是将正向最大匹配法得到的分词结果和逆向最大匹配法得到的结果进行比较,从而决定正确的分词方法。如果正反向分词结果词数不同,则取分词数量较少的那个。如果分词结果词数相同,就说明没有歧义,可返回任意一个。
(四)系统安装和使用
1.系统安装包括系统环境和系统部署。系统环境目前普通办公电脑即可,电脑系统要求windows7及其以上。系统部署主要是外网服务器和内部网络部署,由专业人员安排部署。
2.系统使用:分为普通用户界面和高级用户界面。高级用户的权限要比普通用户的权限大。
(1)统一使用同一个登录界面,用户权限根据后台分配的账号类别而定,用户在登录时选择自己的账号和密码登录即可。
(2)普通用户界面主要是针对县市民宗局和其他需要翻译的各单位部门工作人员提供的操作界面,有翻译标牌、翻译申请、关键词搜索几个功能。翻译标牌即直接输入汉字,点击翻译,即可输出相应的“三种文字”标牌,同时可选择横竖排。翻译申请是在遇到翻译结果有误,或部分汉字未翻译出来的时候,向翻译老师提交申请的渠道,在此处提交申请,专门负责补充词库的哈尼文、彝文老师就会在高级用户界面的待译哈尼文、待译彝文模块查看到需要翻译的内容,并予以处理,处理后的词汇将自动收录进词库,提交申请的用户也将收到反馈信息。
(3)高级用户界面主要是针对专业人员,如专门负责审查补充词库的哈尼文、彝文老师,目前主要是指州民研所的翻译人员。除了拥有普通用户的权限外,高级用户界面还可以新增收录词汇、修改和删除词汇、对普通用户提供的翻译申请进行处理和反馈。另外可以对用户进行简单的管理和维护。
3.系统评测,即对其功能性、稳定性和实用性等方面进行考察。
为验证技术原理的可行性,目前我们初步做了一个测试版的“三种文字”标牌翻译软件,翻译结果显示,常用的标牌标语都能翻译出来,若词库未收录所需翻译的汉字信息相对应的译文(哈尼文和彝文),则能输出横排,而不能输出竖排,横排所缺的汉字对应的译文用空格显示。根据目前的测试结果来看,需要开展专门的词汇补充工作,使得输出结果得到全面改善。软件正式开发完成以后,也是需要一段时间的积累和优化才能最终投入使用。
四 结论与讨论
纵览中国发展史,可以说,得益于包括民族语言翻译在内的国家翻译机制,中华文明形态得以发展和改观,尤其是在和平年代,各国政府为了国境安定、行政畅通,专门设置负责民族语言翻译的机构、机制和官职[5]。创建少数民族文字的初心:一是改变少数民族地区文化事业落后的状况,使其尽快适应社会主义的建设和发展。二是尽快提高少数民族地区人民的教育水平和文化素质。三是更好地发展和传承少数民族的语言文化[6]。红河州哈尼文、彝文、汉文“三种文字”标牌作为我州创建全国民族团结进步示范州宣传工作的载体之一,开发“三种文字”标牌翻译实操性软件,不仅可以提高工作效率,也将为红河州进一步巩固提升全国民族团结进步示范州创建成果助力。
猜你喜欢
小读者(2021年20期)2021-11-24
小读者·爱读写(2021年10期)2021-11-05
小天使·四年级语数英综合(2021年10期)2021-10-20
动漫界·幼教365(大班)(2020年7期)2020-06-26
动漫界·幼教365(中班)(2020年3期)2020-04-20
现代计算机(2019年30期)2019-12-11
活力(2019年17期)2019-11-26
幼儿教育·父母孩子版(2018年4期)2018-09-13
电脑爱好者(2017年5期)2017-05-04
现代企业文化·综合版(2016年11期)2016-12-21
