
生物数据分析平台中的大文件多线程传输方案①
2021-10-11 06:47:50史若曦马俊才田园静张荐辕
计算机系统应用 2021年9期
史若曦,马俊才,田园静,张荐辕
1(中国科学院 计算机网络信息中心,北京 100190)
2(中国科学院 微生物研究所,北京 100101)
3(中国科学院大学,北京 100049)
随着微生物数据的快速增长,研究者越来越重视微生物大数据的高效管理和分析.国家科学微生物数据中心建立了以云计算为基础的生物信息分析的数据平台[1],用户可以登陆网站,根据需求在线使用生物信息分析工具.由于网站面向所有用户开放,一般生物文件较大,HTTP 协议下云服务器端对文件接收大小也有一定的限制,用传统的插件技术、表单直传等方法进行文件上传时效率过低,网络波动或浏览器异常等突发情况导致上传中断时也需要对整体文件进行重复上传[2].所以,本文设计了一个与分片传输技术相结合的多线程传输方案,保证用户数据可以安全、快速的传递至云平台.
1 现状分析
1.1 相关技术
传统的基于Web 文件上传的方法有Form 表单上传,该方法要求表单里包含一个类型为file的输入文件框,与JavaScript 等技术结合,实现文件的上传操作.插件技术是另一种实现Web 端文件上传的方法,主要利用ActiveX、Huploader 等一系列插件实现文件上传,但是该技术容易因浏览器的设置导致插件运行失败,因此只适合在内网此类安全的内部环境使用[3].
除此之外,文献[4]提出了一种断点续传方案,大文件在Web 端分片后,通过计算出每片的MD5 值来做为其唯一标识符.当网络异常发生传输中断时,由唯一标识符来确定断点续传从分片相应部分开始.文献[5]提出了一种多线程控制的方式.该方法在传输多个不同文件时,为每个文件开启一个线程来控制内容文件和配置文件,虽然在传输多个文件时有明显优点,但针对单个文件时效率不高.文献[6,7]采用双线程分别记录文件内容和内容偏移量的方法,该方法在实现断点续传的情况下牺牲了传输效率.文献[8]在线程选择上采取逐步增加的方式,虽然提高了传输效率,但是逐步增加试探,在网络承载率大的情况下仍然有一定程度的资源浪费.
1.2 存在的问题
尽管上述技术已经对断点续传、重复文件上传等问题进行了一定程度的解决,但针对如何提升大文件传输速率这一问题仍存在不足.部分技术为了实现断点续传,采用多线程来记录文件传输时产生的相关配置文件,造成了带宽资源的浪费.一些技术虽然提出利用多线程来实现文件并发传输,但并没有具体提出如何选择并发线程数来保证尽可能高效的利用网络带宽.
因此本文提出了一种根据带宽时延积(BDP)来选择并发线程数的文件传输方案,与分片上传、断点续传技术相结合,满足生物数据分析平台用户的需要,实现生物数据的稳定上传.
2 基于BDP的多线程方案设计
2.1 理论分析
在实际的传输过程中,数据每份发送后无法立即得到确认,这些在信道中传输但还未被确认的数据量通过用带宽时延积(BDP)来表示,它是衡量网络链路能力和承载能力的关键指标.窗口机制就是防止数据量超过接收端确认处理能力的一种措施,它通过限定窗口大小的方式来进行TCP的流量控制和拥塞控制.滑动窗口和固定窗口是常用的两种窗口机制,但是由于TCP 报文头中窗口字段大小只有16 位,无论哪种方式,TCP 窗口最大值都为64 KB.在理想的宽带利用率下,带宽时延积应与TCP 窗口大小一致.在1000 Mb/s的网络带宽下,只有往返时延在小于0.448 ms 时,BDP才会小于64 KB,此时能够有效利用带宽.但是在实际的网络情况下,要想达到这么小的往返时延几乎是不可能的.因此,对于并发TCP 连接,通过同时建立多条连接,并发n条连接就相当于将窗口大小扩大了n倍,从而能有效的提高传输速率[9].
2.2 理论分析
根据前文对TCP 窗口机制与带宽时延积的理论分析可知,为了实现高效的利用网络带宽,减少数据等待确认时的资源浪费,TCP 发送窗口大小应与带宽时延积一致.然而受到报文头字段大小限制,要想在生物数据分析平台用户的网络条件下提高文件传输效率,应采用多线程的方法建立多条TCP 连接,扩大传输窗口.
对于并发TCP 来说,理想的并发数N可以用式(1)计算.
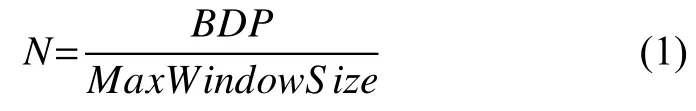
其中,BDP为带宽时延积,由网络带宽与传输时延(RTT)共同确定,其计算方式为BDP=带宽 ×RTT,MaxWindowSize为最大窗口数.
3 方案设计及实现步骤
本文综合分片传输和断点续传等技术,提出一种根据用户网络带宽时延积选择最佳并发线程数的传输方案.该方案采用部分功能函数,实现Web 端的文件分片传输,并根据MD5的计算原理,采用分片计算后整合的方式,最终得到原文件的MD5 值.在解决相同文件上传时,使用MD5 校验来检测服务器端是否已经存储该文件[10],提高传输效率.本文的关键在于设计了一个多线程创建方式,在用户打开网站时获得此时的网络状态,根据此参数得到当前网络状态下用户进行上传操作时可使用的最大线程数,进而提升了文件的上传效率.文件发送流程如图1所示.

图1 客户端文件发送流程
3.1 确定线程数
线程数的选择主要依据网络带宽和传输时延,该参数可以在用户与服务器建立连接时测定,通过BpsDataPerInterval 方法,获取连接服务器时的带宽传输时延RTT,根据上文公式,确定并发数poolSize=(RTT×带宽)/(64×1024),存储在poolSize函数中,在进行上传时,启动与服务器的线程连接.
3.2 分片
因为服务器端会限制每次上传文件的大小,所以需要在前端指定每片文件的值.如果分片较小,则分片数大,会导致多次建立传输请求,增大开销;如果分片较大,则会降低灵活度[11].综合数据分析平台服务器端的设置要求,本文设置每片的大小为2 MB,即chunkSize=1024×1024×2,此外还需要的参数有,chunkNumber 表示分片序数,chunks 表示分片总数,用于服务器端的文件合成.其合并流程如图2所示.

图2 服务器端文件合并流程
3.3 MD5 值计算
生物信息分析平台中的分析工具所需生物数据文件大都在600 MB 以上,甚至大到十几GB,如果采用整体计算文件MD5 值的方式,容易导致内存占用过大,Web 端异常崩溃等情况,计算效率也相对较低.
由于MD5的计算特性,分片计算每部分的MD5值后,再进行合并不改变原文件的MD5 值[12],因此本文采用新的计算方式.将文件分片后逐个传入spark.appendBinary()方法来计算、最后通过spark.end()方法输出MD5.这种方法节约内存开销,在计算大文件MD5 值效果更好.根据前文设置,分片大小为2 MB,综合文件大小得出总片数,然后设置file.cmd5=true,即文件状态改为MD5 计算.接着逐片读取分片信息,并计算MD5 值,由spark.end()得出所有值后,将总文件的MD5 值赋给file.5;,作为该文件唯一标识,为秒传和断点续传操作提供方便.最后取消计算状态,并开始上传文件.其相关代码如下:
//计算MD5
computeMD5(file) {
chunkSize=2 097 152,//2 MB
chunks=Math.ceil(file.size/chunkSize),
currentChunk=0,
spark=new SparkMD5.ArrayBuffer(),
fileReader=new FileReader();
let time=new Date().getTime();
file.cmd5=true;//文件状态为“计算md5…”
fileReader.onload=(e)=> {
spark.append(e.target.result);
currentChunk++;
if (currentChunk< chunks) {
loadNext();
} else {
console.log('finished loading');
let md5=spark.end();//得到md5
file.uniqueIdentifier=md5;//将文件md5 赋值给文件唯一标识
file.cmd5=false;//取消计算md5 状态
file.resume();//开始上传
}
loadNext();
}
3.4 续传实现
受异常情况中断后,整体文件重传需要很大的代价,本文利用已经计算得出的文件MD5 值作为文件的特殊标识符,在进行文件重传时,通过MD5 校验判断文件是否已经上传[12],然后再进行传输操作.本文采用checkChunkUploadedByResponse()函数响应后台返回的信息,并检测分片信息是否上传完整.分片上传前,前端会向后端发送一个携带文件信息的get 请求.如果文件已经在服务器端存储,则返回obj.isExist,后续上传操作不需要继续执行.如果返回的是文件分片信息,则表示该部分已经上传,执行续传操作.其相关代码如下:
//续传实现
checkChunkUploadedByResponse:(chunk,message)=> {
let obj=JSON.parse(message);
if (obj.isExist) {
this.statusTextMap.success='秒传文件';
return true;
}
return(obj.uploaded||[]).indexOf(chunk.offset + 1)>=0
},
//检测断点和MD5
public function checkFile()
{
//检测文件MD5是否已经存在
$rs=$this->checkMd5($identifier,
$this->fileInfo['totalSize']);
if ($rs['isExist']===true) {
return $rs;
}
//检查分片是否存在
$chunkExists=[];
for ($index=1;$index <=$totalChunks;$index++){
if (file_exists("{$filePath}_{$index}")) {
array_push($chunkExists,$index);
}
}
3.5 文件合并
本文采用的是多线程传输,为了保证传输的准确性,需等待所有分片传输成功再进行合并.当传输的分片数等于总分片数chunks 时,会向后台发送合并请求.onFileSuccess()方法接收从后台返回的response 包含了是否需要合并的指令merge,如果resp.merge===true,则向后端发送合并请求.前端将文件的唯一 ID和拆分总数(或要传递的更多参数)发送到合并文件的后端.后端受到合并指令后开始进行文件合并其相关代码如下:
//文件合并
public function merge()
{
$filePath=self::$tmpDir.DIRECTORY_SEPARATOR.$this->fileInfo['identifier'];
$totalChunks=$this->fileInfo['totalChunks'];//总分片数
$filename=$this->fileInfo['filename];//文件名
$done=true;
//检查所有分片是否都存在
for ($index=1;$index <=$totalChunks;$index++){
if(!file_exists("{$filePath}_{$index}")) { $done=false;
break;
}
}
if ($done===false) {
return $this->message(1005,'分片信息错误');
}
//如果所有文件分片都上传完毕,开始合并
$timeStart=$this->getmicrotime();//合并开始时间
$saveDir=self::$saveDir.
DIRECTORY_SEPARATOR.date('Y-m-d');
if (!is_dir($saveDir)) {
@mkdir($saveDir);
}
$uploadPath=$saveDir.DIRECTORY_SEPARATO R.$filename;
if (!$out=@fopen($uploadPath,"wb")) {
return $this->message(1004,'文件不可写');
}
if (flock($out,LOCK_EX)) {// 进行排他型锁定
for($index=1;$index<=$totalChunks;$index++) {
if(!$in=@fopen("{$filePath}_{$index}","rb")) {
break;
}
while ($buff=fread($in,4096)) {
fwrite($out,$buff);
}
@fclose($in);
@unlink("{$filePath}_{$index}");//删除分片
}
flock($out,LOCK_UN);// 释放锁定
}
@fclose($out);
return $res;
}
4 实验结果分析
根据实际网络情况,本文进行了带宽时延积BDP为75 KB和135 KB 两种情况下的文件传输测试.
如表1所示,当BDP大于64 KB 时,该网络情况可以进行多线程传输,其效率相较单线程传输有一定的提高.

表1 不同BDP 下传输耗时的测试结果
5 结论
本文提出利用带宽时延积和最大窗口数计算得到网络最大承载率,来决定并发线程数的文件上传方法,充分利用网络带宽资源,采用MD5 值标识已经上传过的文件,实现生物数据分析平台用户的文件高速上传,节约了时间成本.该方法解决了一般分片上传过程中,无法确定并发线程数的问题,能够提高大文件的上传效率,增强传输稳定性.
猜你喜欢
词学(2022年1期)2022-10-27 08:06:12
数学物理学报(2020年5期)2020-11-26 06:06:48
广东通信技术(2020年10期)2020-10-26 06:36:52
火控雷达技术(2018年4期)2019-01-15 05:07:22
成功(2018年10期)2018-03-26 02:56:14
科技传播(2017年14期)2017-08-22 02:39:36
电脑知识与技术(2016年25期)2016-11-16 12:49:46
电脑知识与技术(2016年21期)2016-10-18 21:27:13
电脑知识与技术(2016年7期)2016-05-19 14:00:19
网络安全和信息化(2015年7期)2015-12-03 06:35:30
