
基于嵌入式设备的Anchor Free行人检测①
2021-10-11 06:47:48张立国孙胜春
计算机系统应用 2021年9期
张立国,刘 博,孙胜春,张 勇,金 梅
1(燕山大学 电气工程学院,秦皇岛 066004)
2(燕山大学 河北省测试计量技术与仪器重点实验室,秦皇岛 066004)
行人检测是计算机视觉和数字图像处理的一个方向,广泛用于安防、智能视频监控等领域,将计算机视觉检测目标用在减少人力的使用的同时提高检测精度、提高灵活性具有重要意义.目前已有的行人检测方法主要分为两大类,一类是基于传统视觉处理的方法,主要包括基于背景建模的算法、基于手工特征与机器学习的检测算法.另一类主要是以神经网络为主的目标检测算法.
对以上算法中第一类算法的背景建模方法而言,其主要是通过对背景进行建模,然后将当前图像与背景模型进行比较,确定前景,如ViBe 算法[1,2]、光流法[3,4]等,该类方法通常受环境光照变化、背景的多模态性、运动物体的阴影等多方面因素的影响,不具备较好的鲁棒性.相比于背景建模算法,基于手工特征与机器学习算法的方法主要通过特定的特征实现检测,如HOG+SVM[5,6]、HOG+DPM[7],但该类方法很难处理遮挡问题,人体姿势动作幅度过大或物体方向改变也不易检测.
在另一大类基于神经网络的算法中,主要是以特征网络提取特征然后组合头部网络回归定位具体位置的方法定位检测目标为主,近年来衍生出多种系列的检测算法,如YOLO 系列[8-11]、RCNN 系列[12-14]、Anchor Free 系列[15-17],在实际的嵌入式设备应用上,主要是以YOLO 系列的阉割版和Anchor Free 系列为主,相对而言,YOLO 系列的阉割版虽然能取得较高的模型推理速度,但是当出现部分遮挡,行人部分超出视野范围等情况,精度会严重降低.而既有的Anchor Free方法虽然整体结构较为简单适用于嵌入式设备的部署,但是如CenterNet[16]、FCOS[17]等特征提取网络结构特征提取层和参数量较多会严重导致推理速度变慢,所以本文通过优化特征网络结构进行特征提取,从而保证头部网络输入特征的有效性,此外针对行人间的相互遮挡情形,提出针对行人的高斯核分布改进方式,保证了模型的检测精度.
1 相关理论基础
1.1 CenterNet 算法原理
CenterNet是基于中心点的检测方法,使用图像作为输入,然后经过骨干网络提取特征,最后在头部网络经过3 个分支,一个分支预测中心点的位置(HeatMap),一个分支预测因下采样过程带来中心点位置误差的修正量(offset),最后一个分支预测检测框的大小(scale),其抽象结构见图1.一般而言,输入图像可用I∈RW×H×3表示,其中W表示图像的宽度,H表示图像的高度,3为图像的通道数,预测中心点的分支最后得到预测结果其中R代表下采样率,C代表类别数,表示与检测物体的中心点相关,=0则表示与背景相关,预测修正量的分支会得到大小的预测值来表示每个中心点的修正值,同样的预测修正量的分支会得到大小的预测值来表示每个中心点的修正值,预测检测框大小的分支会得到的预测值来表示检测物体的宽和高.而骨干网络一般采用Hourglass[18]、DLA[19]等多层特征融合的模型.
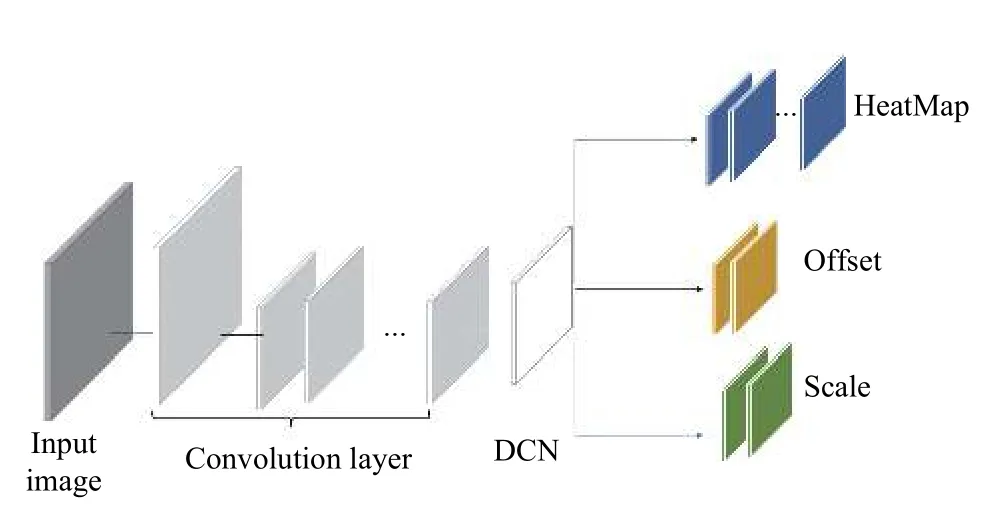
图1 CenterNet的网络结构图
在训练CenterNet 过程中,通常按以下方式设置ground truth和损失函数,记检测物体在原图上的中心点为p,计算图像经下采样后低分辨率的同一位置为对于HeatMap 分支设置ground truth为高斯核的分布形式:
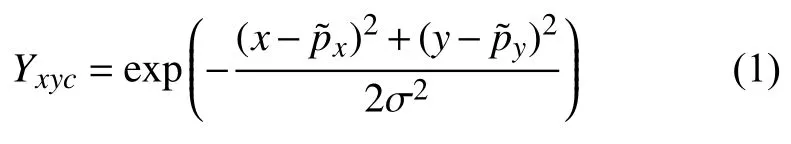
其中,σp是标准差,Yxyc依据标注的中心点生成的高斯分布,、表示在x、y方向上的分量,此分支训练过程通过focal loss[20]定义损失函数:
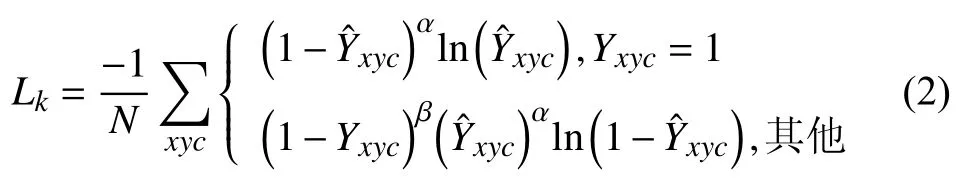
其中表示HeatMap 分支相对应的Yxyc的预测值,α、β是focal loss的参数,N代表中心点(检测到的目标物体)数量,一般设置α=2,β=4.在offset 分支,为了恢复因下采样造成的误差,ground truth 设置为使用L1 loss 进行回归:
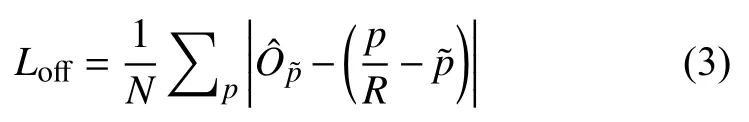
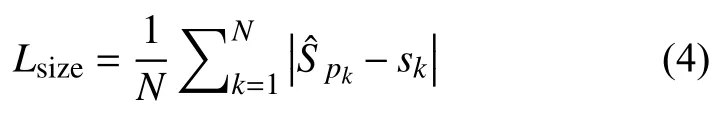
最后对以上3 个分支的损失进行平衡:
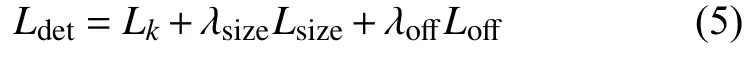
式中,一般在实验中设置λsize=0.1,λoff=1.
1.2 BiFPN 结构
在Backbone的研究中,模型有效性是一个重要的概念,在目标检测网络中都需要一个特征提取层提取深度特征,一般的做法是对高层的语义特征和低层的细节特征进行融合,即FPN[21]结构,这样用在检测过程中可以提高位置检测和分类的精度,但同时也会极大的增加参数量,致使检测的速度降低,所以越来越多的FPN 结构尝试在尽可能少的增加参数量的同时能保证一定的检测精度,以满足在嵌入式设备上的实时性要求.其中EffcientDet[22]提出加权融合的BiFPN 结构就可以有效的对下采样或上采样后的不同分辨率的特征图进行有效的融合,其结构如图2所示.图中假设P3、P4、P5、P6、P7为经过在初始输入图像上逐级下采样后得到的不同分辨率的特征图,然后通过跳跃连接使双向网络层结构(top-down和bottom-up)提取的特征进行特征融合.此外在融合的过程中,为了区分不同特征层对最后输出特征的不同贡献和提高特征提取结构的有效性,可以通过对不同层级的特征进行加权实现:
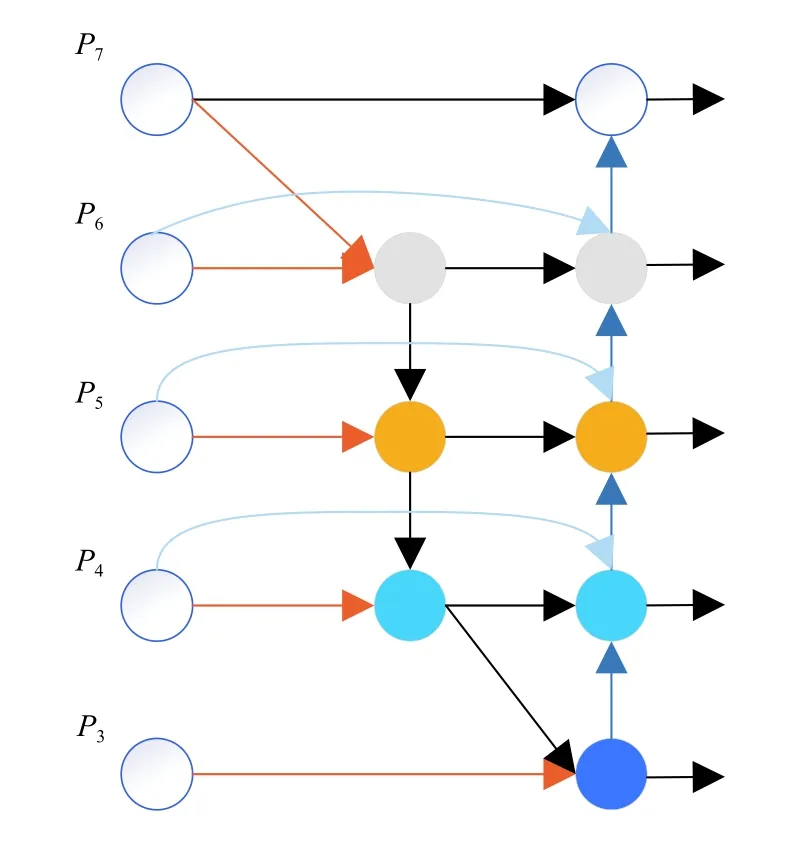
图2 BiFPN 结构示意图
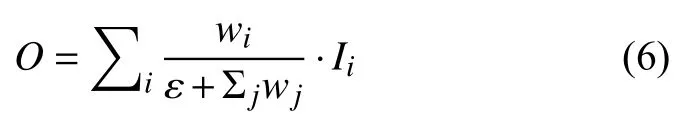
其中,Ii表示融合过程中的所有被融合前的特征图,wi为其对应的权值,是一个可训练的参数,Σjwj表示所有的权值之和,O表示融合后结果特征图的输出.以P6和P7融合的过程为例,设输入的特征层为和,第6 层中间的特征设为,输出特征设为,同理第6 层的输出特征为,计算第6 层的输出如下:
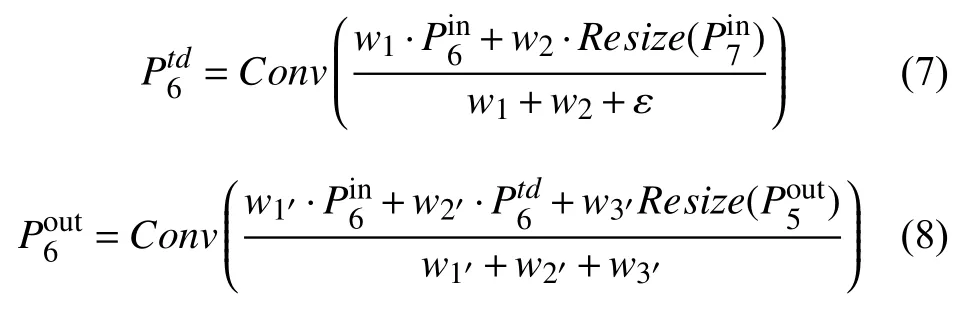
经过以上计算就能更加有效的提取到低层细节特征和高层语义特征的混合特征,用于头部网络的检测和分类任务.
2 行人检测算法设计
2.1 行人检测模型
原CenterNet 使用的backbone是多层特征融合的DLA34和Hourglass101,这类模型参数量大,前向传播速度较慢,不适合使用在嵌入式这类计算能力有限的设备上,所以根据BiFPN 结构提出一种新的特征提取结构,其参数量在嵌入式设备上可以满足实时性的同时,保证了精度不会出现大幅降低,改进后的网络结构如图3所示,从网络结构的图中可以看出输入图像首先经过一个Conv1(卷积)→Bn1(批标准化)→ReLU(激活层)→maxpool(最大池化)的结构得到一个64 维的特征图,然后使用ResBlock(残差块)进一步提取特征,分别将残差块下采样输出的特征相对应的按式(7),式(8)进行分辨率调整,并且按图中BiFPN 结构进行融合,经过BiFPN 结构之后得到对应输入的不同层融合之后的特征,将这些特征经过Conv (卷积),DeConv[23](可变形卷积)送入到头部分支,最后再在不同的分支分别进行卷积,得到各个头部检测分支的对应结果,综合3 个分支的结果即可得到最终的检测结果.
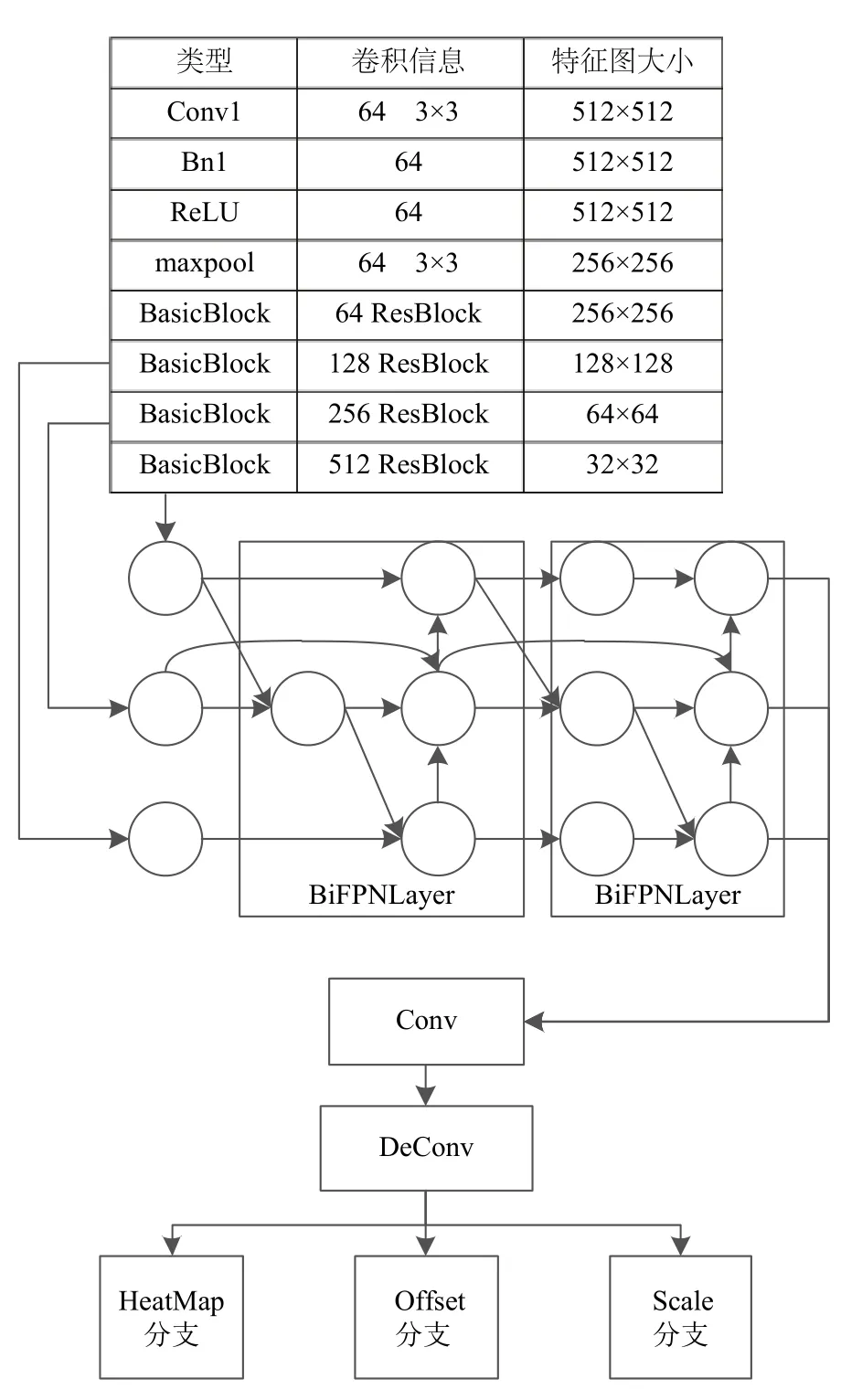
图3 基于CenterNet 改进的网络结构
2.2 检测网络训练及损失
本文所提方法训练时的输入量和原CenterNet 网络的输入量相同,不过因行人这一检测类别的特殊性进行微调,并改进其相应的损失函数.
针对行人之间容易出现遮挡的情况,如图4所示,通过改进训练过程中HeatMap的高斯核分布形式,来提高准确度,即将(1)式修改为:

图4 行人之间的相互遮挡
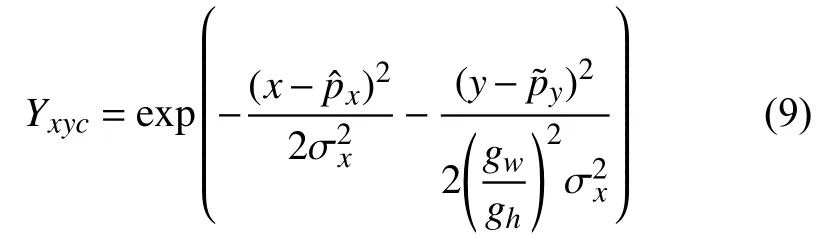
其中,σx为原方差 σp,gw和gh为标注框ground truth对应的宽和高,HeatMap的变化如图5所示,图5(a)中采用的是式(1)中的分布形式,如果以这种形式表达行人中心点的分布,在预测过程中当行人的距离较近时,很容易在预测过程中导致两个响应峰值距离较近,导致最后使用最大池化或soft-NMS[24]等过滤手段时将其过滤,即响应更为强烈的预测中心点将另一个中心点“吞并”,而如果按式(5)的形式绘制HeatMap,则会在响应图5(b)上产生一条明显的界限,避免因行人相互遮挡或距离较近产生漏检.相应的在HeatMap 分支设置损失函数:

图5 改进前后的高斯核分布形式
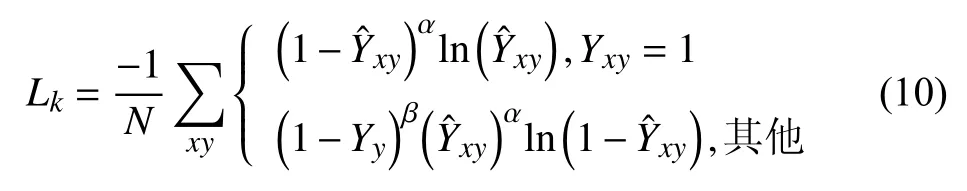
式(10)与(2)的不同之处在于,首先因为应用的是针对于行人这一个单类别的检测,所以HeatMap的结构没有类别对应的维度,仅在x、y方向是有效的,其次针对于HeatMap 上Yxy≠1的情况,由于改进后高斯核在两个方向上的分布形式不同,所以仅在y方向上对focal loss 损失进行衰减,这有利于检测行人时生成更加符合其长宽比的检测框,提高模型的精度.
3 实验结果及分析
3.1 实验数据、环境及评价指标
实验过程中使用CityPerson[25]数据集首先进行30 个epoch的预训练,然后使用CrowdHuman 行人数据集进行130 个epoch 训练和评测.CrowdHuman 数据集是密度较高的行人检测数据集,平均每张图片有22.64 个行人检测框,在训练过程中使用15 000 张训练集图像和4370 张验证集图像进行训练,使用5000 张测试集图像进行评测.
实验训练过程中所用硬件环境Inter Core i7 9400,GPU2080Ti,操作系统为Ubuntu 16.04,训练深度学习框架为MXNet 1.5.0,最终应用的嵌入式平台为Jetson TX2,在模型移植过程中采用TensorRT 加速,训练和推理过程图片采用512的大小作为输入.
在评价指标上主要采用平均精度(Average Precision,AP)作为主要的评价依据,其计算过程如式(11):

其中,P表示精确度,R表示召回率.精确度是指正确检测到的物体在所有目标中所占的比例,而召回率是指正确检测到的物体在所有检测到的目标中所占的比例,式(12)表示精确度的计算,式(13)表示召回率的计算,两式中TP(IoU不小于阈值)为正确检测出目标,FP(IoU 小于阈值)为错误检测目标,FN为没有被检测出目标.本文IoU 阈值设置为0.3,当IoU ≥0.3 时,则认为检测正确,否则为错误.
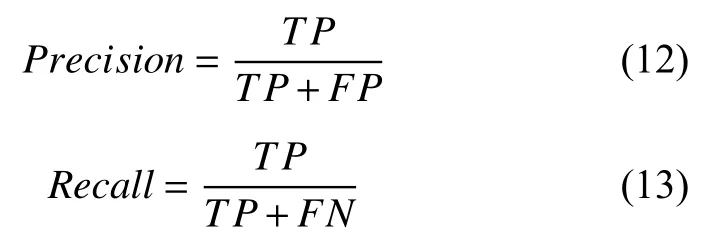
参数量和检测速度的评测采用固定大小图片512×512 作为输入,分别计算模型前向传播过程的权重参数的总量及传播时间来实现.
3.2 实验设置和结果
为了更好的对改进后的模型及输入进行评估,分别设置了不同的对比实验,首先针对模型结构的适应性进行评估,对其Backbone 分别使用DLA34、ResNet34、MobileNet_v2[26]及本文改进后的结构进行对比,训练过程的损失曲线和精度曲线分别如图6和图7所示,几个Backbone的参数量如表1所示,由于MobileNet_v2的参数量较少,所以很快训练权重就完成拟合,但最后的损失也略大,所以精度较低,相比于ResNet34,DLA34 融合了更多高级语义信息和低层细节信息,所以DLA34在整个训练过程中以比ResNet34更少的参数量达到更优的效果.最后从本文算法的损失曲线和精度曲线来看,虽然相比于DLA34、和ResNet34的精度略低,但从表1可以看出其参数量相较于其他两个Backbone 分别少了34.4%和56.2%,充分说明了本文所用方法提取特征的有效性.
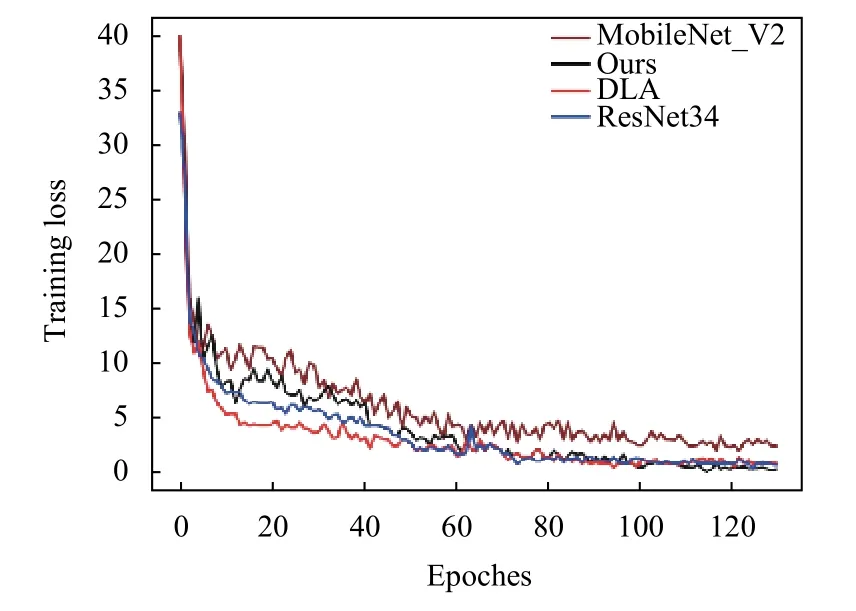
图6 训练损失变化曲线
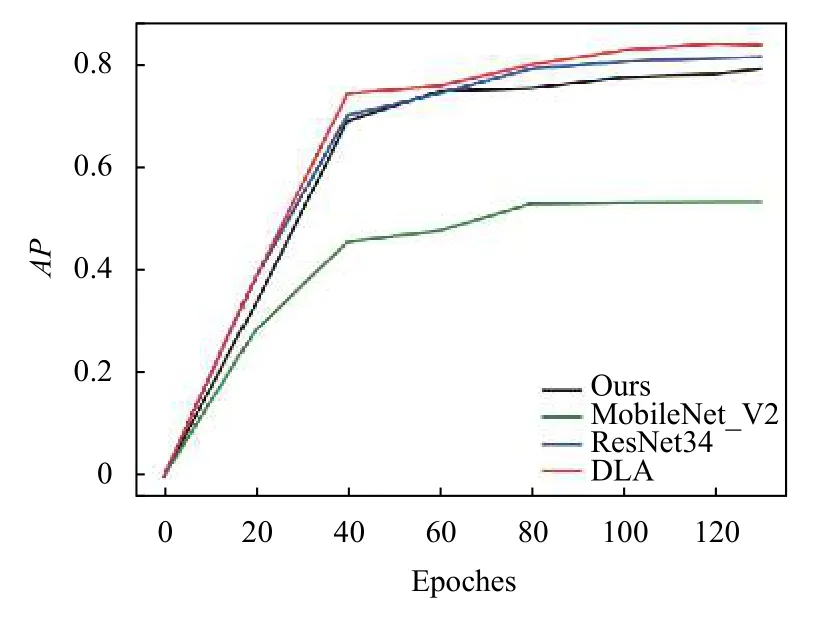
图7 训练精度变化曲线

表1 不同Backbone的参数量
为了体现对行人检测框训练时HeatMap的改进及相应的损失函数的修改带来的效果增益,首先用未改进HeatMap 输入的方法进行检测,从中挑选出128 处因遮挡导致漏检的结果,如图8(a)所示,然后使用改进后的训练方式及损失函数进行重新训练,得到的结果如图8(b),改进前后在精度和因遮挡造成的评测如表2所示.
结合图8和表2可以看出,经过对HeatMap 训练的高斯核分布改进后,不仅能够提高检测精度和减少因遮挡造成的漏检,而且因为新的高斯核分布形式与行人这一类别更加匹配,所以也会提高新人检测的置信度.

图8 高斯核改进前后检测效果

表2 改进HeatMap 上高斯核的分布方式对行人遮挡效果的提升效果
最后为了准确的评估模型在传播速度(FPS)来综合比较经TensorRT 加速后在Jetson TX2 上的表现,其中在移植时,权重参数全部量化为float8,结果如表3所示.

表3 Jetson TX2 移植后的效果
从表3可以看出,相比于其他几种Backbone在Jetson TX2 上的表现,本文所提方法精度仅略微降低,但68 ms的推理速度足以保证模型在嵌入式平台Jetson TX2 上的实时性.
4 结论与展望
本文主要是针对原CenterNet 检测网络在嵌入式设备上检测速度较慢,提出了一种满足实时要求又不大幅降低检测精度的网络模型.然后针对于行人这一检测类别通过改进头部网络HeatMap 分支的高斯核分布进一步降低因遮挡带来漏检的方法.实验结果表明,本文所提方法在嵌入式设备上与其他方法相比具有一定的优势,在保证检测精度的同时,通过有效的检测模型极大的减少了参数量并提高了检测速度,同时在行人检测的相互遮挡问题上进行了研究.如何进一步在现有部署框架上尽可能少的使精度下降,是下一阶段的研究方向.
猜你喜欢
意林(2021年5期)2021-04-18 12:21:17
电脑报(2020年12期)2020-06-30 19:56:42
电脑报(2019年4期)2019-09-10 07:22:44
学生天地(2019年28期)2019-08-25 08:50:54
扬子江(2019年1期)2019-03-08 02:52:34
数学物理学报(2018年1期)2018-03-26 08:16:36
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
少儿美术·书法版(2016年1期)2016-02-06 00:59:39
大众摄影(2015年9期)2015-09-06 17:05:41
山西大同大学学报(自然科学版)(2014年3期)2014-01-23 01:56:30
