
基于残差注意力网络模型的浮游植物识别
2021-10-09 01:41项和雨陈维国饶凯锋
生态学报 2021年17期
项和雨,邹 斌,唐 亮,陈维国,饶凯锋,刘 勇,马 梅,杨 艳
1 湖北大学,数学与统计学学院,应用数学湖北省重点实验室,武汉 430062 2 无锡中科水质环境技术有限公司,无锡 214024 3 北京工业大学,北京现代制造业发展基地,北京 100124 4 中国科学院生态环境研究中心,环境模拟与污染控制国家重点联合实验室,北京 100085 5 中国科学院生态环境研究中心,中国科学院饮用水科学与技术重点实验室,北京 100085 6 中国科学院大学,资源与环境学院,北京 101407 7 武汉晴川学院,计算机学院,武汉 430204
浮游植物的定性定量检测是水环境检测的重要内容之一,对浮游植物进行快速准确识别将有助于对水域环境的监测、评价、开发和利用[1- 3]。特别地,当水体富营养化引发浮游植物大量繁殖[4-6]尤其是蓝藻水华泛滥[7-8],造成公共饮水威胁和巨大经济损失时[9],浮游植物的快速准确识别愈渐凸显其重要性。2017年无锡“供水危机”之后[10-11],国家、省市投入了大量的财力进行太湖综合整治。在蓝藻打捞、控源截污、生态清撤、引江济太等一系列措施下,太湖营养盐的控制取得了显著的成效,水质出现明显的改善[12]。尽管太湖水质的不断持续改善,但是太湖蓝藻水华每年仍然如期而至,个别年份暴发的面积和频次甚至出现反复。2019年2月20日生态环境部,就重点湖库水质及蓝藻水华监测发文《关于做好2019年重点湖库蓝藻水华防控工作的通知》,提出2019年1月至5月全国大部分地区气温较常年同期偏高,要求保障饮用水安全,各地应积极采取相关措施防控湖库蓝藻水华灾害。因此,浮游植物监测是一项非常重要而紧迫的工作。长期、有效的浮游植物监测数据积累是揭示富营养化机理和蓝藻水华暴发机制的基础工作,也是防控藻类水华的重要数据支撑。浮游植物生长在复杂的水生环境中,种类繁多且形态不一,准确而高效地识别水体中的浮游植物是监测工作中的重大挑战。
当前浮游植物识别方法主要分为三类[13-14]:(1)人工分类,即专家借助显微镜对浮游植物样本进行识别。这种方法最基本最方便,但耗时耗力,识别者往往需要经过专门的训练。(2)分子标记,基于浮游植物特征性化学组成成分或DNA等遗传物质[15]进行分类,如分光光谱法、荧光光谱法、液相色谱法、流式细胞仪法[16]和分子探针技术等。这些方法较为可靠,但需要昂贵的仪器和精细的操作,难以推广。(3)利用图像处理与模式识别技术分类。尽管人工分类是基于形态学的经典方法,应用最为广泛,但是随着浮游植物监测要求的不断提高,尤其是监测频次的不断增加,这种“高要求”和“人力成本”之间的矛盾愈加凸显。因此,自动化监测作为人工监测的辅助手段被认为是未来浮游植物监测的一个重要研究方向。
利用浮游植物图像进行自动化识别已有很多尝试[17],是实现浮游植物识别自动化的重要途径。经典的图像识别方法包含图像的预处理、图像分割、特征提取和图像分类四个步骤。例如,Stefan等[18]提取傅里叶描述子和矩不变量等47种特征,利用判别分析方法对蓝绿藻进行自动识别;Luo等[19]通过傅里叶频谱特征得到特征向量,利用BP神经网络对圆形硅藻进行自动分类;Mansoor等[20]利用图像处理技术和多重感知机前馈人工神经网络实现了四种蓝藻的自动识别;Walker等[21]应用贝叶斯决策函数和荧光辅助图像对湖中两种主要浮游植物进行分类。这些方法的弊端在于需要利用传统的图像分割算法来辅助浮游植物定位,并且需要手工设计特征。面对不同的图像识别任务,需要先设计不同的图像分割算法和特征提取算法,这难以满足现场快速自动测量的要求。深度学习方法克服了这些缺点,得益于精心设计的网络结构,深度卷积神经网络可以自动学习图像的表征,端到端的输出分类结果,兼顾准确率、效率且易于扩展。
目前,利用深度学习方法进行浮游植物识别的研究较少,万永清等[22]基于深度学习框架Caffe对三种藻类进行识别,虽达到100%的识别率,但识别种类较少,而且未详细描述数据集以及所用神经网络模型的结构和参数。本文以太湖的11种优势属为研究对象,基于深度学习中的残差注意力网络模型[23],提出一种新的深度卷积神经网络RAN- 11,并搭建出易推广的浮游植物自动化识别系统,对于提高浮游植物识别准确率和效率具有重要意义。该系统有助于自动化、快速识别水体中的常见浮游植物种类和数量,对于实现水体中浮游植物的自动化监测具有重要价值。
1 材料与方法
1.1 浮游植物图像获取
本研究组在太湖多个试点收集水样,然后利用自主研发的数字图像自动采集系统采集了多批浮游植物图像。最后,考虑到浮游植物种类的复杂性和样本数量的不均衡性,仅标注了太湖水体中的优势属,包括微囊藻,游丝藻,沟链藻,长孢藻,裸藻,盘星藻,转板藻,针杆藻,星杆藻,浮丝藻和栅藻共计11个属(图1)。
1.2 图像预处理和计算平台搭建
浮游植物的显微镜图像像素高、尺寸大,且在拍摄过程中气泡、杂质、相互遮挡等因素会造成图像清晰度和辨识度难以达到算法识别的标准。为了能够更好地对浮游植物进行标注及算法识别,本研究组开发了一套可以快速对超大图像进行切割的工具软件,该工具可将2cm×2cm区域中的72000×72000像素的超大图像切割为边长7200的矩形图像。专家对切割后的11种浮游植物交叉标注,截取边长在200- 260nm的浮游植物图像共计1036张,按照等比例缩放成分辨率为224×224的PNG格式图片,最后按3∶1∶1的比例将1036张图像随机分为训练集、验证集和测试集。
本文采用深度学习框架Pytorch搭建网络,在一台Win10工作站上进行网络训练和测试。该工作站配备Intel(R) Xeon(R) Platinum 8268 CPU 和NVIDIA Quadro GV100 GPU,主频2.90GHz,显存32G。
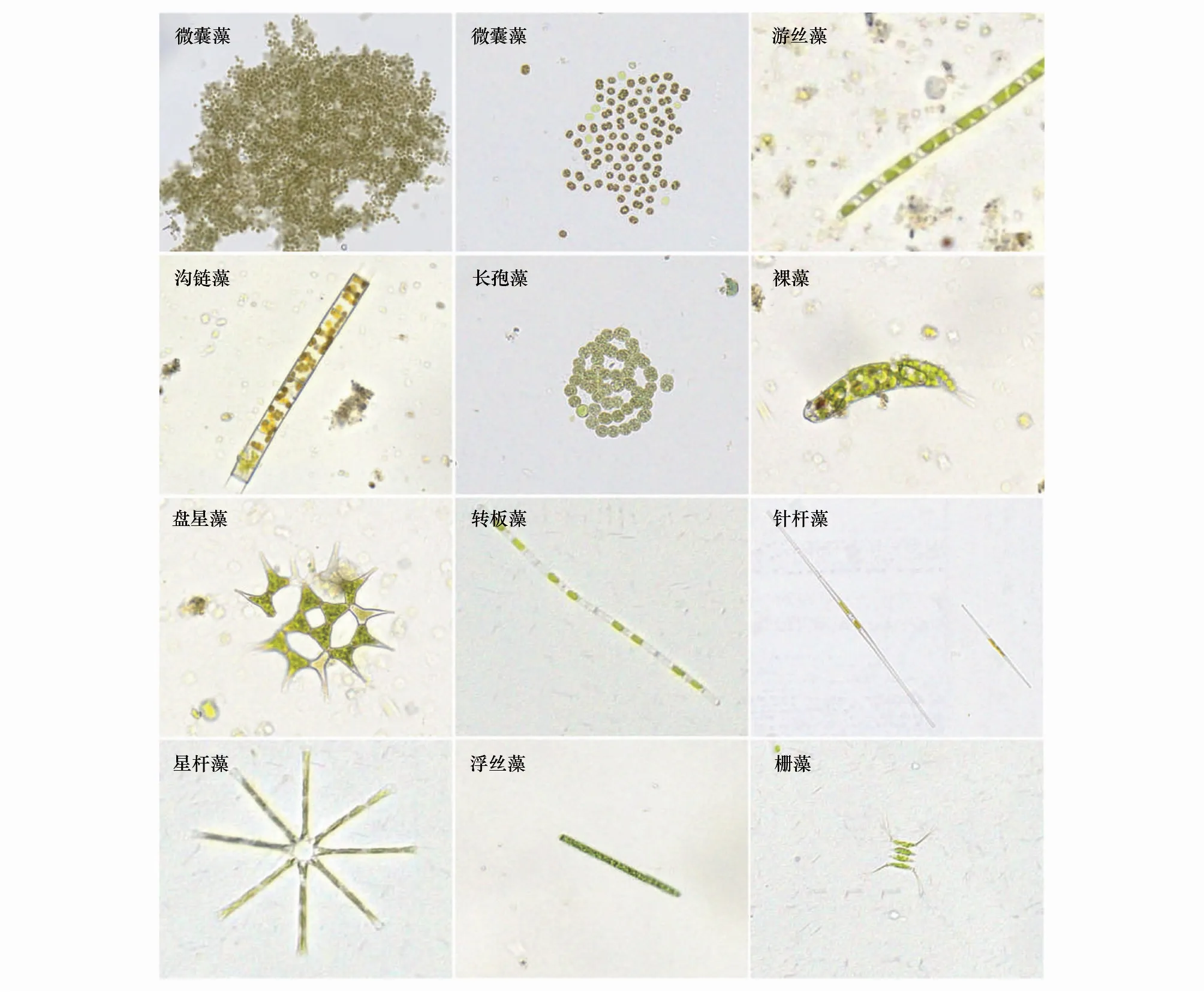
图1 浮游植物扫描图Fig.1 Microphotography of dominant phytoplankton in Lake Taihu (Automatic light scanning system)
1.3 经典图像分类模型概要
近年来,图像分类方法多侧重于学习特征表达[24],代表是词包模型(Bags of Words,BoW)[25]和深度学习模型。其中词包模型在2005- 2012年期间表现优异,多次斩获PASCAL VOC分类竞赛冠军。至2012年深度学习模型崛起,逐渐代替词包模型成为图像分类任务的主流方法,屡次刷新ImageNet大规模视觉识别竞赛(ImageNet Large Scale Visual Recognition Challenge, ILSVRC)的最高记录。
1.3.1词包模型
词包模型成熟于自然语言处理领域,主要通过计算文档中单词出现的频率来对文档进行表达和描述。在图像处理的分类问题中,词包模型将每个图像的局部特征看成一个视觉单词,形成词包进行分类,其基本流程如下:
(1)底层特征提取。对每一张图像提取特征,如SIFT特征或SURF特征;
(2)构建码本。使用K-means算法对提取的特征聚类,用聚类中心构建视觉码本;
(3)特征汇聚。利用视觉码本对图像特征编码,获取图像的词包作为新的特征描述;
(4)使用分类器对词包进行分类,如逻辑斯蒂回归分类器或支持向量机。
1.3.2残差注意力网络
He等[26]通过实验猜测,深的网络的求解器很难去利用多层网络拟合恒同映射g(x)=x,因而在网络层数加深时难以求解目标函数H(x)。为此,He开创性地在卷积层之间加入快捷连接(即在主分支外另起一个分支,两个分支的输入皆为x,输出相加),执行恒同映射,形成残差块。这样,原本求H(x)的问题,凭借快捷连接转化为求解另一个函数F(x)=H(x)-x的问题。可以发现,在恒同映射恰为目标函数H(x)的极端情形下,残差块完全避免了拟合恒同映射这一难题。由残差块堆积而成的深度残差网络(ResNet)[26]因为足够深并且容易优化,在ILSVRC 2015中获得了图像分类任务的冠军。
人类的视觉注意力机制是通过向目标区域投入更多注意力资源,以获取更多所关注目标的细节信息而抑制其他无用信息。注意力机制可以通过加权来实现。Wang等[23]通过不同的注意力模块来学习针对其特性而专门化的注意力,即令Hi,c(x)=(1+Mi,c(x))×Fi,c(x),其中,Fi,c(x)代表图像的特征图的第i个位置第c个通道的特征值,Mi,c(x)∈[0,1]代表该特征值的权重,Hi,c(x)为纳入了注意力机制的特征输出。由此构建的残差注意力网络Attention- 56和Attention- 92[23]在三种基准数据集上取得了优异的识别效果。
1.4 构建新网络
Wang等[23]把自底向上、自上而下的前馈结构(软掩模分支)作为注意力模块的一部分,以改变特征上的权重,形成越来越精细的注意力。在该模型中先下采样再上采样确保了特征矩阵和权重矩阵的维度一致可以逐点相乘,改变快捷连接的个数和输出尺寸确保各个模块的注意力的精细程度不同,由此奠定了残差注意力网络的基础。
考虑到Leaky ReLU激活函数[27]在输入为负时仍旧可以产生非零的激活值,从而能促进反向传播过程中网络参数的更新,使网络收敛更快,因此本文使用Leaky ReLU激活函数代替ReLU激活函数。进一步地,为获取更好的图像表征,本文对浅层特征降采样后与深层特征按通道拼接,并用大步长卷积层代替池化层。但这些改变会增加网络的计算负担。因此,本文通过消融实验改变注意力模块和残差块的个数,并大幅调整相应的通道数以适应特征变换,由此形成卷积神经网络RAN- 11。RAN- 11为residual attention network- 11的缩写,其中“11”表示该网络主要由表1中的11种模块组成。

表1 RAN- 11的网络参数
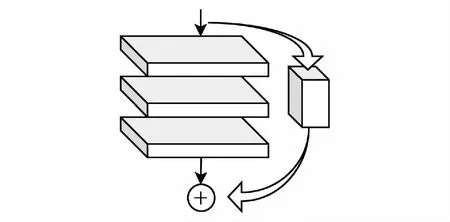
图2 残差块Fig.2 Residual block
1.4.1构建残差块
残差块由主分支和快捷连接组成,如图2。其中主分支由3层卷积层串联组成,每个卷积层都会配备一个批量归一化层和一个激活函数层,其顺序为:批量归一化层-Leaky ReLU激活函数层-卷积层。残差注意力网络模型与ResNet所采用的恒等映射不同,在残差注意力网络模型的快捷连接中包含额外的卷积块,该卷积块的输入与主分支的输入相同,其输出则与主分支的输出相加后前向传播。
1.4.2构建注意力模块
根据软掩模分支中快捷连接的个数差异可将注意力模块分为A1、A2和A3三类,如图3(网络层以大写英文字母标识,“I”代表上采样层,“S”代表Sigmoid激活层,“x”和“+”分别代表逐点相乘和逐点相加,其余缩写见表1)。以A1为例,输入之后的第一个模块和输出之前的最后一个模块均为残差块,二者中间是主分支和软掩模分支。主分支由两个残差块串联组成;软掩模分支主要包含三对“下采样层-上采样层”和两个快捷连接,快捷连接的起点前和终点后皆为残差块。A2、A3的结构与A1类似,两个分支的输出的乘积与主分支的输出之和作为最后一个残差块的输入向前传播。
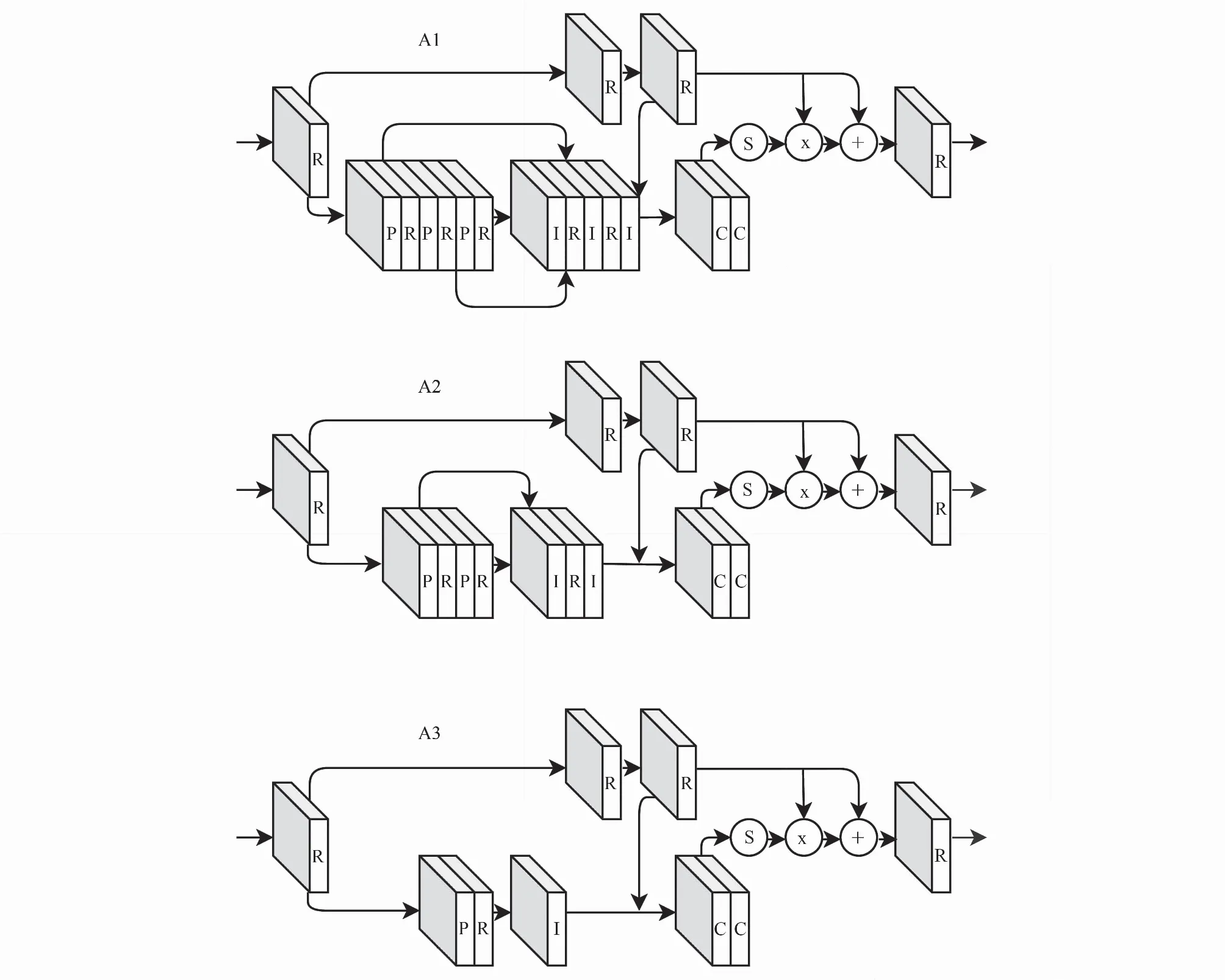
图3 注意力模块Fig.3 Attention modules
1.4.3构建RAN- 11
RAN- 11包含1个A1模块、1个A2模块和2个A3模块,注意力模块个数多于Attention- 56但少于Attention- 92,其网络结构见图4。RAN- 11主要借助调整残差块参数对特征图进行维度变换。此外,对恰好位于注意力模块之后的残差块,其输出会与恰好位于注意力模块之前的残差块的输出,按通道拼接后再前向传播。

图4 RAN- 11的网络结构Fig.4 Network structure of RAN- 11
2 结果
对RAN- 11、Attention- 56[23]、Attention- 92[23]、DenseNet- 161[28]、BoW[25]五种模型在相同的计算环境下进行对比实验,实验结果见表2。表2中的评价指标分为三部分:(1)模型对单一浮游植物类别的查准率[29];(2)浮游植物的随机测试Top-k准确率。模型评价中常用的准确率指标即指Top- 1准确率,表示预测正确的样本数量在总样本数量中的占比。Top-k准确率相较于Top- 1准确率扩大了误差容忍程度,对某一样本,只要在预测概率为Top-k的类别中包含样本的正确类别,就认为该样本预测正确;(3)模型的推理速率,即该模型平均每秒可以处理多少帧图像。
由表2知,本文提出的算法RAN- 11在除星杆藻外其余种类的查准率都在90%以上,而在其他模型中,查准率在90%以下的类别的数目均不少于两类。同时,RAN- 11是取得100%查准率的类别的数目最多的算法,为5种。从总体来看,RAN- 11的Top- 1、Top- 2和Top- 3准确率均是五种算法中最高的,分别为95.67%、98.56%和100%。最后从推理速率来评估,由于深度神经网络普遍具有海量参数,尽管使用GPU加速,其速率还是慢于经典的词包模型。以此为代价,深度神经网络的Top-k准确率远高于词包模型,Top- 1准确率普遍比词包模型高10个百分点以上。同时,RAN- 11的推理速率为41.5 fps,是几种深度学习模型中表现最好的。仅从残差注意力网络模型的角度来看,Attention- 92通过增加注意力模块的个数在取得优于Attention- 56的准确率的同时,却牺牲了推理速率,帧速从41.2 fps下降到23.6 fps。RAN- 11在适当增加注意力模块个数的同时引入多尺度特征和Leaky ReLU激活函数,使得准确率和推理速率都获得提升,特别是准确率相较于Attention- 56提升近一个百分点。

表2 RAN- 11和其他模型的对比实验
在评估算法结果的同时,本文对表2中4种深度学习算法的训练过程进行可视化分析。深度学习实验中常用回合(Epoch)表示训练集中全部样本完成一次前向传播和一次反向传播的过程,用批量尺寸(Batch size)表示神经网络每次梯度更新所处理的样本数,称神经网络每处理完一个批量的样本为一次迭代(Iteration)。回合数和批量通常决定了一个网络要训练多久。本文将所有网络的批量均设置为16,训练200个回合,并利用可视化工具TensorBoard记录训练过程中训练集损失随迭代次数、验证集准确率随回合数的变化情况,以确保深度学习算法正常运行。特别地,由于记录的损失数据波动较大不利于观察比较,本文先用三次样条插值来填充离散数据点,再利用移动平均滤波器对训练损失数据进行平滑后处理。可视化结果见图5和图6。

图5 损失变化曲线Fig.5 Variation of loss

图6 准确率变化曲线Fig.6 Variation of accuracy
由图5和图6知,训练损失在第3000—4000次迭代之间便已趋于稳定,验证集准确率在第75—100个回合之间便已达到最高,这与现有参数设置下一个回合包含约40次迭代相一致。综合损失和准确率变化可知,模型在训练达100个回合时便可以停止更新,此时模型的准确率趋于稳定,而训练时间可以压缩掉1/2,这有利于进行网络调参和模型快速迭代。此外,我们观察到图5中蓝色曲线基本位于其他曲线下侧,图6中蓝色曲线基本位于其他曲线上侧。这表明RAN- 11损失下降速率最快、准确率上升速率最快,即算法收敛性好,这得益于我们采用了更好的激活函数Leaky ReLU来代替ReLU,使得即使激活函数的输入值为负时神经元仍然可以更新参数。
3 讨论
对于大规模的浮游植物图像识别任务而言,在模型的推理速率相差不是很大的情况下,识别准确率即使提高1%也会带来更大实际使用价值,因此RAN- 11对Attention56和Attention92的提升是非常有益的,但仍存在改进空间。为进一步提高识别效果,我们可以考虑从以下几方面对现有算法进行改进。
表2中算法对星杆藻的最高查准率为86.96%,其中RAN- 11算法对星杆藻的查准率仅有82.61%。查看混淆矩阵[30]发现,星杆藻查准率低主要源于相对多的钩链藻被误识别。在部分训练集图像中,破碎的星杆藻不再呈星状,而是和钩链藻一样都呈现黄色和白色交错的链状,后者确实存在较大的被误识别为星杆藻的可能性。在后续工作中,我们将针对性地引入图像的颜色增强以丰富训练集的颜色变化,避免神经网络对这种黄白交错的形态过度学习,从而提升识别查准率和总体准确率。
相对于大型图像识别任务而言,目前浮游植物的有标注数据量还有待增加。浮游植物的显微镜图像中存在大量的相互重叠、遮挡、模糊、物种数量不均匀等现象,导致参与训练的标注图片中某些浮游植物的可鉴别的数量特别稀少,不足以支撑深度学习的训练过程。另外,目前的模型是在有监督的条件下进行的,人工标注的过程非常耗时耗力,因此后续可以考虑引入半监督或者无监督的深度学习方法,将大量的未标注图片中的有用信息加入到训练模型中,丰富样本的种类和数量。
最后,在实际应用中如何将识别过程系统化是一项重要的挑战。实验表明RAN- 11在浮游植物识别中取得具有竞争力的识别效果,因此可以基于RAN- 11构建出一种浮游植物自动化识别系统,如图7。

图7 浮游植物自动化识别系统Fig.7 Automatic phytoplankton identification system
该系统由三大模块组成:(1)图像获取模块。主要负责抽取试点收集水样,并通过显微镜及图像获取装置,获取浮游植物显微镜图像;(2)图像预处理模块。主要借助计算机软件完成浮游植物图像的切割、标注等,形成可供网络训练或测试的数据集。其中,如果目的是预测浮游植物类别则不需要标注图像。如果没有权重则需要先标注图像并输入RAN- 11训练;(3)图像识别模块。加载已训练的权重,对预处理的浮游植物图像进行快速自动分类。该系统不依赖于水域环境,不需要手工设计特征,加载已有权重文件和待测试的浮游植物样本,便可以端到端的输出识别结果,具有很好的推广性。鉴于图像预处理模块的工作耗时占比大,尤其是图像标注,需要为每张图片建立标签,在后续工作中,可利用模型推断结果对数据集进行预标注后再进行人工修正,提高浮游植物图像的标注效率,逐步完善该系统。
4 结论
本文以太湖浮游植物的11个优势属为数据来源,提出了一种新的的残差注意力网络模型RAN- 11,可以以高准确率快速识别浮游植物,并构建了一种具有竞争力的浮游植物自动化识别系统,得到以下结论:
(1)RAN- 11因其精心设计的网络结构可以取得比原残差注意力网络Attention- 56和Attention- 92更好的识别结果,在准确率和速度上均优于原算法。
(2)深度学习方法的识别效果远优于传统的以手工设计特征为主的图像识别方法。虽然传统方法如BoW计算量小、速度快,但难以弥补识别效果上的不足。
(3)基于深度学习的浮游植物识别方法,可以准确而高效地对所关注的水体中的浮游植物进行分类,极大地提高了水质检测的可靠性和易操作性,可有力促进水质监测和保护。
(4)当前深度学习方法在浮游植物识别领域的应用较少,但具有广阔的应用前景。本文构建的浮游植物图像识别系统,易于在实际应用中推广,对于实现水体中浮游植物的自动化监测具有重要意义。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
北京航空航天大学学报(2020年10期)2020-11-14
甘肃教育(2020年22期)2020-04-13
自动化学报(2019年6期)2019-07-23
中国交通信息化(2018年5期)2018-08-21
第二课堂(课外活动版)(2016年2期)2016-10-21
