
大数据时代(铀)成矿预测技术方法变革
2021-10-02 09:18张士红林子瑜
铀矿地质 2021年5期
张士红,林子瑜
(1.河北工程大学 地球科学与工程学院,河北 邯郸 056038;2.东华理工大学,江西 抚州 344000)
矿产资源是社会经济可持续发展的重要物质基础。铀资源作为一种重要的战略资源,涉及到我国的国防安全和能源安全;发展核能亦是国际“温室气体”减排和能源可持续发展的有效途径。
在矿产勘查逐渐走向“绿地”、深部和“覆盖区”的大背景下[1],找矿目标已经或即将转向那些深部隐伏矿,而这意味着找矿难度的加大和找矿勘探成本的提高。我国铀资源勘查开发战略面向国内、国际两个战场,如何合理规划战略选区、精准定向重点靶区,迫切需要矿产资源预测新理论、新技术和新方法。
“成矿预测是实现科学找矿勘探的重要途径和方法。由于矿床类型的多样性,矿床成因的复杂性,控矿因素的隐蔽性和找矿信息的多解性,成矿预测结果具有不确定性并常常因人而异。探索成矿预测过程客观化、定量化和精确化一直是成矿预测学的前沿课题”[2]。
随着信息技术和互联网技术的飞速发展,大数据时代已然来临。大数据的核心就是预测,大数据的“相关性”思维为突破人类知识和思维的局限提供了可能,大数据正在成为科学发现的新引擎,驱动地球科学创新发展[3];而机器学习尤其是深度学习则是大数据分析和知识发现切实有效的工具。
地球科学属于数据密集型科学[4],地质大数据包括地-物-化-遥和探矿工程等数据[5]。对这些数据进行深层次找矿信息挖掘和集成融合,将有助于深入探讨地学规律,为覆盖区深部找矿带来机遇。
1 现状与发展动态
成矿预测是在不确定条件下制定最优决策的综合性研究工作,目的是提高找矿成效和预见性[2]。成矿预测的一般流程是在成矿动力学背景、成矿规律和矿床模型理论研究的指导下确定成矿-控矿要素;利用GIS 技术分析地-物-化-遥等多元地学数据,选择预测要素特征图层,识别提取成矿-示矿异常信息;定量统计预测要素和已知矿(床)点的相关关系,建立数学模型以集成融合多维特征;圈定不同级别的有利成矿区,估算未发现的矿床数和潜在资源量,并提出找矿工作部署建议[6-9]。
早期的成矿预测以定性的地质经验类比方法为主,通过分析成矿地质环境及其相似度,预测矿床存在与否及其规模[10-11]。现代意义上的矿产资源定量预测评价始于20 世纪50 年代,在阿尔及利亚撒哈拉地区,Allais(1957)[12]运用统计学方法开展矿产资源评价。随后,各国学者开始探索(多元)统计分析方法在成矿预测中的应用。
20 世纪80 年代,计算机技术与GIS 技术得到快速发展,使得成矿预测中综合利用矿产勘查工作积累的大量地-物-化-遥等空间数据变得可行。1976 年,国际地质对比计划“矿产资源评价中计算机应用标准”推荐了6种矿产定量预测方法[13],推动了矿产资源定量评价步入实用阶段。这一阶段的特点是GIS 技术被应用于矿产预测的全过程,包括利用定量方法进行多元异常信息挖掘,研究多元信息与矿产的相关关系,发展数据模型(算法)集成多预测要素证据图层,圈定成矿远景区,以实现未发现矿产资源的定位、定量预测评价。
随着对地质过程认识的加深和现代科学理论与技术方法的发展与交叉渗透,矿产预测已由单纯的定性预测发展为基于模型的定量预测;由单一地质信息预测发展为复杂多元地学数据挖掘和信息综合预测;由对矿床产出的定性预测发展为对不同规模尺度矿产资源体的综合定量化评价;由“随机采样”、“强调因果”的知识驱动模式向“全体数据”、“注重相关”的数据科学预测新模式发展[11,26]。
进入21 世纪,随着信息技术的发展,地质矿产勘查已经积累了大量的地-物-化-遥资料,地质科学进入了地质大数据时代[4],矿产预测也进入到基于数据科学为主的新阶段[5]。
2 技术方法
铀成矿是多层次复杂地质作用的综合结果,铀矿分布与成矿要素及其呈现的多元地学异常信息之间具有时空上复杂的非线性关系。
将大数据思维引入地学领域,利用数学工具进行数据清理和挖掘,将有助于矿产资源预测评价。大数据时代,借助机器学习(尤其是深度学习)算法,开展地-物-化-遥多元信息特征的有效提取与集成研究,挖掘、识别隐性的深层次找矿信息,进行隐伏矿产资源定量预测评价,这是当前成矿预测研究的重要方向[27]。
2.1 成矿理论-地质模型指导确定成矿-控矿要素
成矿理论-地质模型的研究内容包括区域地质构造背景、矿床模型、成矿作用,目的是深入理解成矿过程,建立地质理论模型/模式,开展成矿预测。成矿理论-地质模型是矿产资源评价的基石。陈毓川和朱裕生(1993)[28]提出成矿模式概念,其核心内容是对矿床成因、成矿机理和矿床特征进行概括性的描述和解释,对矿床普适性特征、规律进行研究总结,指导分析矿床成矿-控矿要素。以美国为代表的西方国家,主要通过构造环境与容矿岩石进行模型分类,建立矿床模型资源评价方法;Erickson 总结了48 个全球矿床模型[29],Cox 和Singer 在此基础上总结了85 个矿床模型和65 个品位-吨位模型,用于美国地质调查局开展的“全球矿产资源评价”项目(The Globe Mineral Resource Assessment Project)[30]。
基于地球系统科学提出的成矿系统理论方法,主张从影响矿床形成的所有地质要素和作用过程的角度来认识成矿全过程[31-33],弥补了区域成矿理论与矿床模式研究之间的空档。成矿系统从物理学、化学和动力学角度,理解和揭示成矿作用的全过程,为深部和覆盖区勘探提供理论基础;而成矿系统三要素——“源区”、“通道”和“场所”具有可探测性,这为多尺度成矿预测确定了探测与勘查目标,即同时定位与解决矿床“为什么存在于此”和“怎么发现他”。如何将成矿系统转化为勘查系统,从实际地质、地球物理、地球化学数据中分析提取成矿系统多级组成要素,开展基于成矿系统的多尺度成矿预测,这是当前矿产资源定量预测领域的热点研究问题[34]。
2.2 数学模型/算法定量分析提取特征和集成融合多元信息
在矿产资源定量预测中,发展数学模型/算法主要有两个应用目标:第一,多元地学数据挖掘和异常信息特征提取,其代表性研究如成秋明等人提出的多重分形和奇异性分析方法[18,20],主要用于地球勘探数据背景与异常的分解和弱异常信息的提取。第二,多元信息的集成融合,根据证据权重确定方式,可以分为知识驱动和数据驱动两类[35];前者主要根据专家知识对地质变量直接赋权值,完成信息综合和预测远景区的圈定[7];后者则是在地质模型基础上,利用数学模型或机器学习算法定量分析证据图层和已知矿床的相关关系,对证据图层权重赋值,实现矿产资源的定量预测[36-39]。
随着时代的进步,近现代音乐视唱作品一定会越来越多的融入到视唱练耳教学当中,可以看出传统视唱与近现代视唱有着千丝万缕的关系。尽管视唱素材的写作手法越来越新奇,尽管视唱作品的风格越来越丰富,视唱的难度不断增加。只要我们能够了解音与音之间的联系。不断地总结并完善传统视唱与近现代视唱相融合的教学方法。就能够使两者相互并存、共同发展。
传统的基于知识驱动和数据驱动的定量预测方法(包括证据权重方法和浅层机器学习方法),主体是在地质模型假设的前提下,由(数学)地质专家人工设计规则来构造特征,识别提取与成矿相关的证据图层,进行综合信息成矿预测[40]。在以地质模型为先验前提的综合信息找矿预测主导思想下,致矿异常信息特征提取是决定预测准确性的关键因素[41]。但是,面对极其复杂的地质过程、成矿作用,仅从地质概念模型出发指导找矿预测的正演模型存在着诸多主观认识上的局限(片面)性和客观信息的不确定性;传统的地统计学、浅层学习利用有限样本和有限参数生成的特征也很难充分有效地表征复杂成矿作用的内在结构和规律,针对复杂的非线性分类或预测问题其泛化能力受到一定程度的制约[42]。
大数据时代,深度学习强大的特征表示能力,有助于从时空背景中获得对地球系统科学问题和成矿作用过程的进一步理解。
2.3 基于数据科学的成矿预测
大数据时代,数据科学从“随机采样”、“精确求解”和“强调因果”的传统模式转变为注重“全体数据”、“近似求解”和“注重关联”的新模式[3]。大数据“重相关、轻因果”的数据密集型科学发现新思维范式为找矿预测开拓了一条新的路径。从数据出发,分析复杂多元数据的相关关系,挖掘、洞察数据中隐藏的知识,是发现新矿床、获取新地质认知的最佳途径,是实现“智慧找矿”的关键技术[43]。
机器学习尤其是深度学习作为人工智能的核心,具有优秀的对复杂、非线性问题的处理能力[44]。研究表明,机器学习方法能够更好地模拟和处理复杂的地质作用过程,识别致矿地质异常信息,刻画预测要素和矿床(点)之间的复杂非线性关系[45]。
深度学习以原始数据作为输入,包含模型学习和特征学习双重任务,最终实现特征到任务目标的映射[46]。深度学习更依赖于数据本身,克服了专业领域手工设计特征的困难,降低了由于客观目标复杂性和主观认知局限性而造成的预测结果的不确定性。在成矿预测领域,深度学习模型可直接从原始数据中进行特征提取和信息集成融合,不需要依据地质模型识别和提取证据图层[47-48]。深度学习技术的引入正在推动矿产预测从传统的知识驱动、数据驱动进入基于数据科学为主的新阶段。基于数据科学的(铀)成矿预测技术路线可直观反映研究方向和内容(图1)。
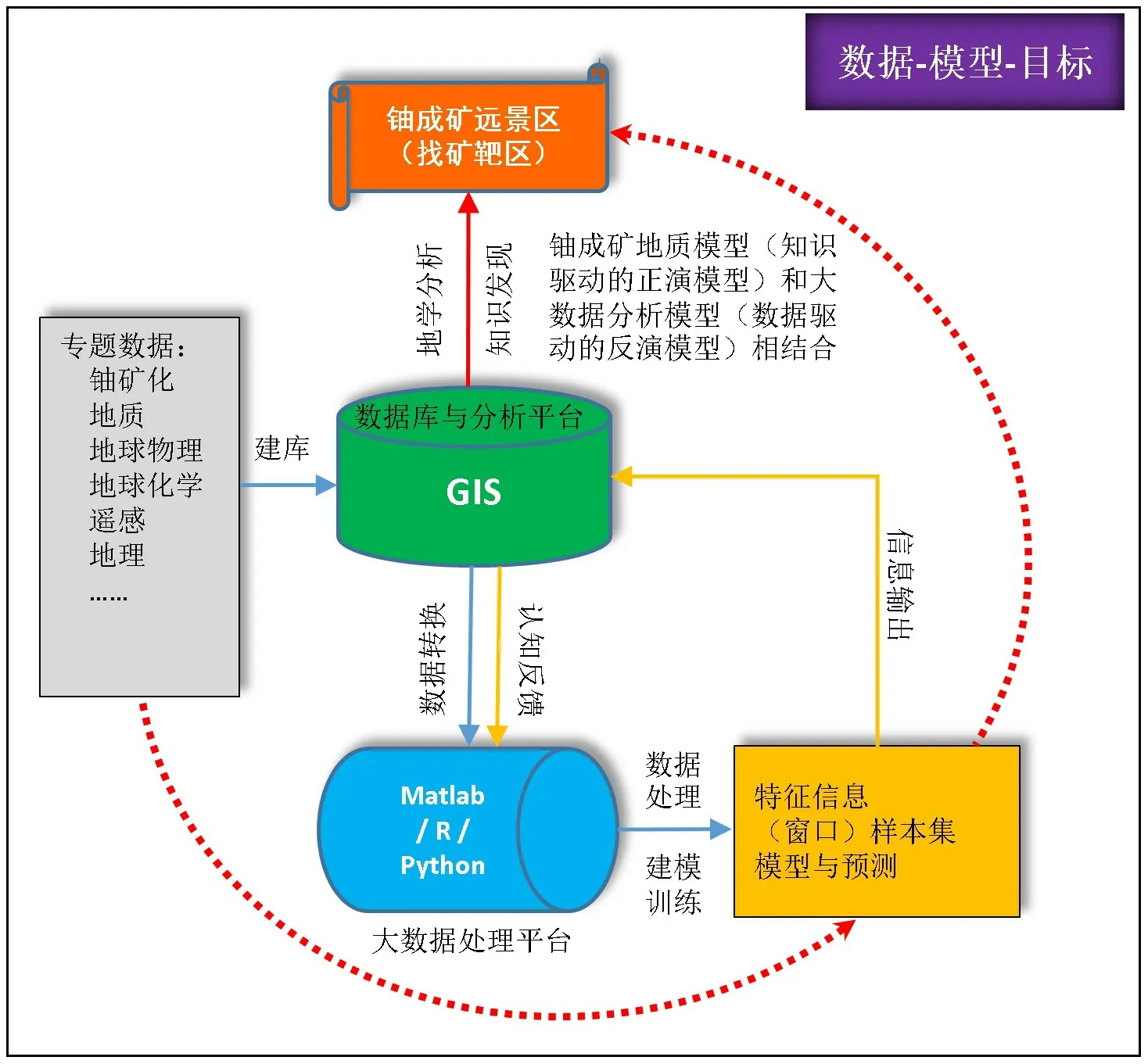
图1 基于数据科学的(铀)成矿预测技术路线框图Fig.1 Technical roadmap of(uranium)metallogenic prediction based on data science
基于数据科学的矿产资源定量预测,可以通过数据统计、数据挖掘、数据洞察与预测等对地质大数据进行清洗、分析,识别出与地质作用过程相关的空间异常信息,挖掘并集成融合与成矿系统相关的源、运、储、变、保等知识,进而圈定找矿远景区,为进一步找矿提供决策支持[5]。
3 问题与展望
基于数据科学的矿产资源定量预测是连接知识驱动正演模型与数据驱动反演模型的桥梁。然而深度学习的“黑盒效应”使得人们对模型的学习行为无法进行直观的地质解释,距离被地质学家完全接受、认可还有一段路要走,这需要数据科学专家与地质学家相向而行。数据科学侧重“相关性”,地球科学强调“因果性”,两种思维的交互融合是将深度学习引入成矿预测领域面临的挑战之一。
机器学习致力于让计算机从已知样本(正样本类和负样本类)中认识数据中蕴含的规则(即产生模型),并对未知数据进行识别/预测。然而,由于矿床的形成属于稀有地质事件,很难获取足够的正样本类——有矿样本。尽管深度学习具有强大特征表示和分类预测能力,但在训练数据有限的条件下,深度神经网络模型也容易受到随机错误或噪声的干扰,出现过拟合问题,导致其泛化能力降低。正如李飞飞(2017)[49]在ImageNet Workshop 上讲到的:“人们已经意识到,ImageNet改变了人工智能领域,数据集是AI 研究的核心之一;在研究中,数据集与算法同样重要”。因此,如何构建一套规范化的、客观详实的样本数据集是深度神经网络模型能否得到有效训练的关键问题。针对成矿预测中训练样本不足的问题,相关学者尝试将半监督和非监督的机器学习算法引入到成矿预测中,其核心思想是利用数据分布上的假设,建立带标签样本和无标签样本间的关系,对无标签数据进行分类预测,然后将无标签样本的异常值点作为新的标记样本加入到训练数据中重新对模型进行训练,以达到较好的预测效果[50]。
在以往大部分研究中,样本均为点状数据,并未考虑到其空间特征。对于矿产勘查而言,除特征变量场值的变化趋势以外,场的局部变化性和空间结构信息的识别对成矿预测亦非常重要,因为这种局部变化性和空间结构信息往往反映一定的地质控制因素[51]。
本文作者提出了利用已知勘探矿体范围及其合适的缓冲区网格化单元和随机分布的非矿单元作为样点中心,构建窗口样本;在这些样本中,内涵了致矿地质异常多元信息空间属性与结构特征。通过一系列线性变换处理,扩展样本集,实现了深度卷积神经网络的有效训练。以窗口样本为基础和纽带,将深度学习技术与集成决策思想相结合,提出并实现了一套新的大数据成矿预测方法——随机样本集成卷积神经网络(Random Sample Integrating CNN,RsICNN)成矿预测方法。该方法实现了致矿地质异常信息多层次空间属性与结构特征的自动识别提取、逐层次归纳与聚合,并兼顾了这些特征的广义自相似性;使预测在原理上符合人们对致矿地质异常信息特征的基本认知,在方法上避免了通过人工设计特征来寻找决策规则的困难与片面性,在决策策略上兼顾了矿化异常的主体相似性与个体多样性。先后在四川省拉拉铜矿集区、南澳高勒地盾北东缘IOCG 型矿集区和弗罗姆湖盆地ISL 型铀矿集区使用该方法进行成矿预测,取得了良好的效果,证明了该方法可行和稳定[27,52]。
综上所述,积极探寻大数据成矿预测新技术方法,实现从地学大数据到单元成矿有利度的映射,定量圈绘成矿边界,有利于提高成矿预测的客观性和智能化水平,促进成矿新认知与找矿新发现,是实现铀矿“智慧找矿”的必由之路。
大数据时代,(铀)成矿预测技术方法之变革已经到来!
致谢:本文是在大量阅读前人研究成果的基础上思考与综合而成,在此对所引用文献的作者致以敬意。第一作者在读博期间,得到了肖克炎导师、朱裕生先生等前辈在成矿预测领域的诸多指导和帮助;所研制的大数据成矿预测新方法在南澳州的应用和改进则得益于中国核工业地质局“铀资源大数据分析与找矿战略”项目的支持,在此一并致谢!
猜你喜欢
矿产勘查(2021年3期)2021-07-20
矿产勘查(2021年3期)2021-07-20
矿产勘查(2020年2期)2020-12-28
矿产勘查(2020年6期)2020-12-25
矿产勘查(2020年5期)2020-12-19
学术论坛(2018年4期)2018-11-12
中国矿山工程(2018年6期)2018-01-24
自然资源情报(2017年2期)2017-11-26
新疆地质(2016年4期)2016-02-28
地质与资源(2016年5期)2016-02-27
