
多方计算特定应用场景的匿名化认定与建议
2021-09-29 07:59:32庄媛媛何昊青
信息安全研究 2021年10期
庄媛媛 靳 晨 何昊青
1(华控清交信息科技(北京)有限公司 北京 100084)
2(清华大学五道口金融学院 北京 100084)
1 匿名化相关规定对数据流通的意义
新一代信息技术的迅速发展,使得数据控制者(controller)对于数据主体(data subject)个人信息的收集、处理、利用的深度与广度不断加大.随着数据控制者越发强势,数据主体的权利显得微不足道.为了消弭数据控制者与数据主体之间的权责失衡,保障个人信息能够合理利用,各国纷纷出台了建立在“告知同意”框架下的个人信息保护相关法律法规,定义了匿名化等概念,并给出了相应的管理规定.
各国对匿名化等相关术语的定义多有出入,宽严不一,但主要皆聚焦于信息能否“识别出特定个人”,其根本目的在于通过将特定个人“埋没”于群体中,在“统计学意义上”保障个人隐私.在我国,“匿名化”“去标识化”“假名化”等原属于技术概念的范畴,2021年出台的《中华人民共和国个人信息保护法》(以下简称《个保法》),定义了“去标识化”与“匿名化”,并将匿名化处理后的信息排除在《个保法》规制的范畴之外,至此“去标识化”与“匿名化”在我国已经成为法律概念.对于匿名化处理后的数据的豁免规定,欧盟的《通用数据保护条例》(General Data Protection Regulation, GDPR)将匿名化数据排除GDPR规制范畴;美国《加利福尼亚州消费者隐私保护法案》(California Consumer Privacy Act, CCPA)将去标识化后且无法合理识别出特定个人的信息排除CCPA规制范畴,以上规定皆旨在平衡个人信息隐私保护与个人信息流通所能带来利益之间的关系.
从匿名化数据消除了数据集中个体颗粒度的角度来看,该方式确实能够在一定程度上保障个人隐私,但还有以下问题亟待厘清:
1) 匿名化既是法律概念也是技术问题,是网络安全、信息安全与数据保护的关键一环,需要考虑涉及数据上下游产业链对数据的利用情况,辅之以政策、法律法规、标准、内部管理制度;
2) 匿名化不是孤立的,数据链条上相关方的数据处理与保护能力各不相同,对于数据的颗粒度需求也不同,故需结合数据的实际使用场景和目的去探讨;
3) 匿名化是一种对数据“状态”的评估,但数据处理是一个动态的过程,需充分衡量整个动态过程的评估与管理;
4) 合理利用数据是匿名化的目的,但匿名化不是唯一的起点或者手段,新技术的出现将会改变合理利用数据的方式.
在目前的研究过程中,上述问题并未受到充分关注.因此,本文将以欧美对匿名化的相关规定为起点,阐释上述观点并结合具体应用场景辨析匿名化相关规定在合规实践上的难点,于文末提出相关的政策建议.
2 欧美匿名化相关规定及其发展
2.1 欧盟匿名化规定解读
2.1.1 欧盟匿名化概念及发展历程
在技术领域,匿名化模型的起点可以追溯至1997年美国的Samarati和Sweeney提出的k匿名模型,目前也发展出许多其他的技术与解决方案.在法律领域,欧盟1995年的《数据保护指令》提及“匿名化”的概念.随着技术的进步,各产业对数据挖掘、共享、交换的需求越来越高,为保护个人隐私,各界纷纷对匿名化及其技术投入了更多关注,在与个人信息有关的法律法规中都有迹可循.例如,2014年欧盟第29条数据保护工作组起草的《关于匿名技术的意见》,对匿名化的场景因素、判断标准、常用匿名化技术等,结合1995年的《数据保护指令》与2002年的《电子隐私指令》作了详尽的介绍.2020年欧盟《电子隐私条例》延续了匿名化的相关规定,规定用于研究的元数据必须匿名化或假名化、电子通信服务商必须对其元数据删除或匿名化处理(如图1所示).
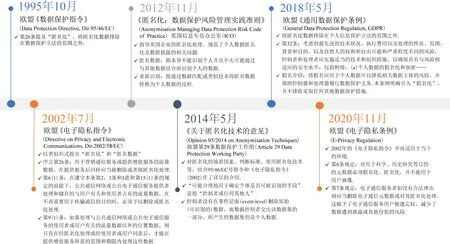
图1 欧盟匿名化相关概念的发展
2.1.2 欧盟匿名化和假名化的区别
欧盟在对于个人数据匿名化方面提出了“假名化”与“匿名化”这2个概念.假名化(pseudonymisation)是一种处理数据的方式,使其在不结合额外信息的情况下,无法再度识别到特定数据主体,前提是这些额外信息必须单独保存,采取相应技术和组织措施,确保个人数据不再被用于识别特定自然人(如图2所示).
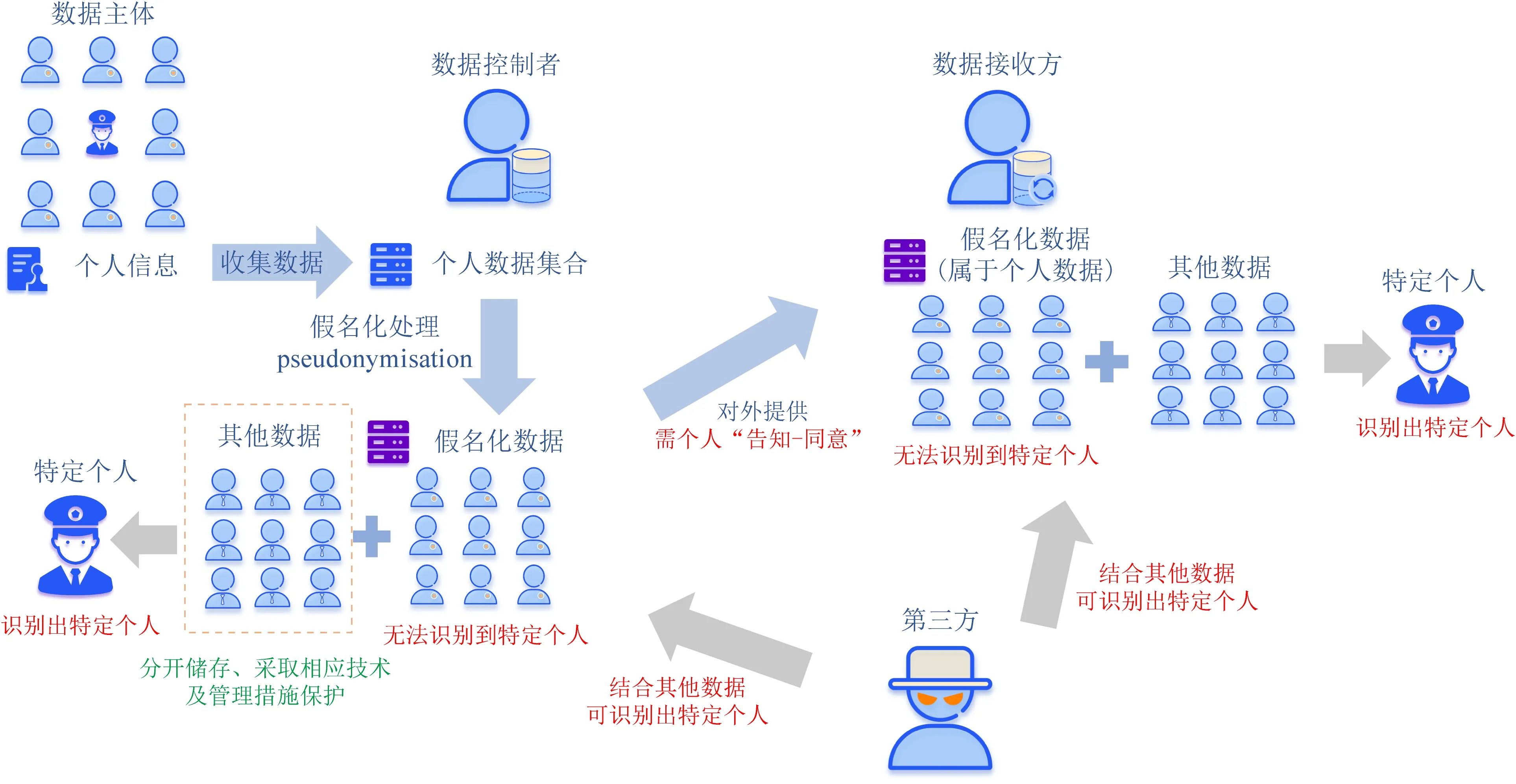
图2 欧盟匿名化概念图例
匿名数据(anonymous data)则是与已识别或可识别的自然人无关的数据,以及经过处理后无法或不再可识别到特定自然人的数据.在《关于匿名化技术的意见》中对其有更详尽的阐释,认为“只有当数据控制者将数据汇总到个别事件(event-level)不再可识别的水平时”该数据集才是匿名的数据集,即数据控制者应当在事件层面删除原始(可识别)的数据(如图3所示).
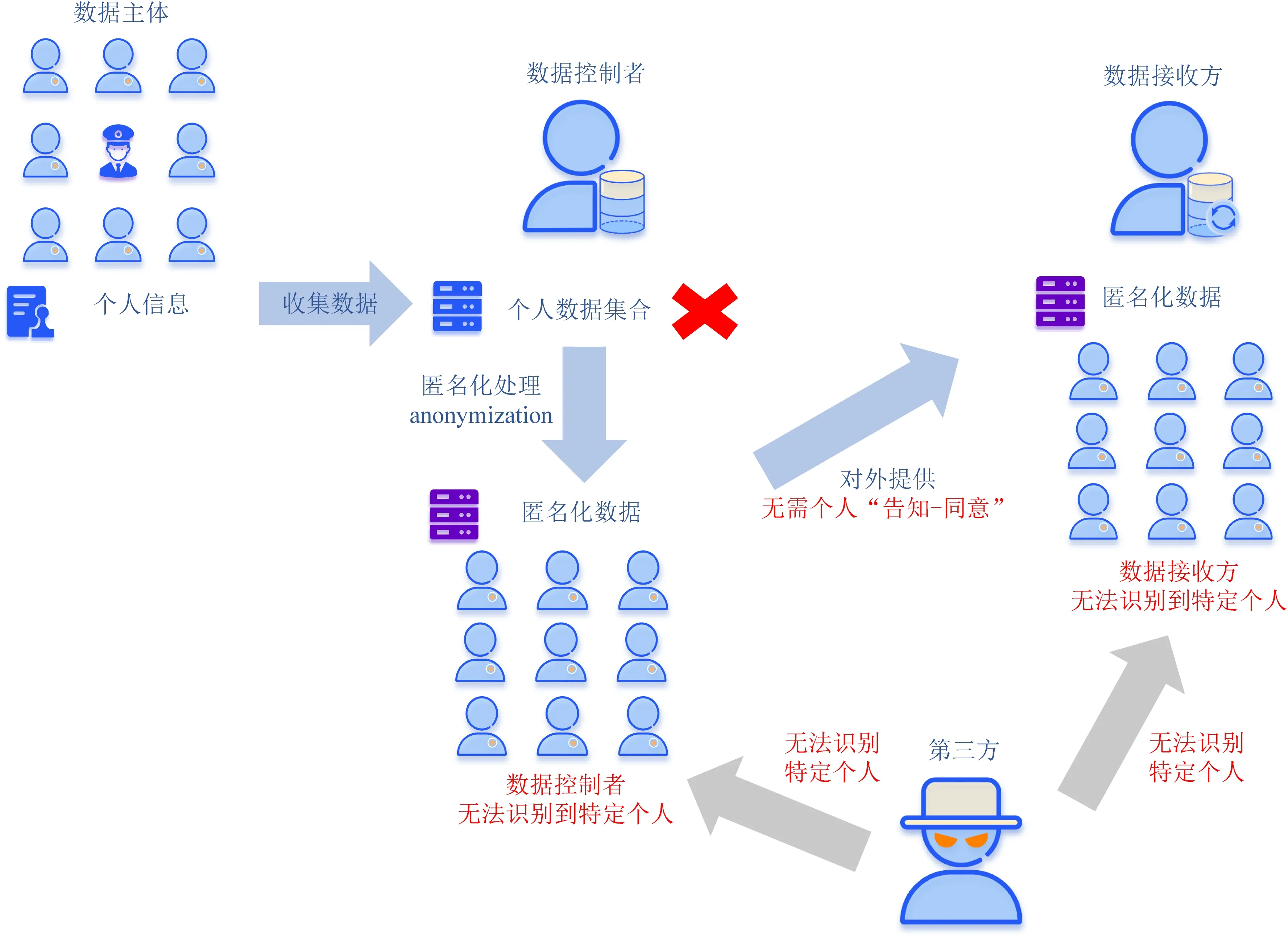
图3 欧盟去标识化概念图例
2.1.3 欧盟关于匿名化的技术评估
欧盟的《关于匿名技术的意见》主要从3个维度考虑匿名化技术的稳健(robustness)程度:
1) 筛选(singling out).将数据集中的所有或某些记录分离出来,从而识别出特定个人.
2) 关联(linkability).从1个数据集中的至少2条记录或者至少不同数据集中的2条记录关联到特定个人(单独的数据集中无法筛选出特定个人则不具有筛选风险).
3) 推断(inference).从1组其他属性显著可能地推断出其他属性.
当数据集有可能出现筛选、关联、推断情况时,数据集就不是匿名化的数据集,需受GDPR的约束.《关于匿名技术的意见》中将对标签进行加密的一类密码学相关技术归类为假名化的技术,认为该类技术在不结合其他技术的情况下,无法实现匿名化(如图4所示).在评估稳健性要求时,采取“合理可能”(reasonably likely)的标准,即综合考虑了采取重识别的技术手段需付出的成本(所需时间与资源)和技术,并且考虑了技术随时间发展的变化.

图4 欧盟关于匿名化的判断
2.2 美国不采用匿名化,而采用假名化和去标识化
美国采用去标识化(de-identification)与假名化(pseudonymization)的概念,而未有匿名化的概念,即将个人信息中的直接或者间接标识符删除.1996年出台的《健康保险责任流通法案》(Health Insurance Portability and Accountability Act, HIPAA)是最早有关个人信息去身份化的法律规定.HIPPA指出去标识化处理后的健康信息,使用和公开不再受限,其认定标准采取“专家标准”与“安全港标准”.2015年美国国家标准与技术协会发表了《个人信息去标识化》,将去标识化定义为从数据库删除身份信息,使其不能再链接到特定个人,处理后的数据不再受到隐私保护的限制.美国关于去标识化的方法较为简单,将标识符分为直接标识符与准标识符(间接标识符),对于与特定个人高度关联的直接标识符,应采取“删除”或者“置换”的方式.准标识符无法直接识别到特定个人,但结合其他信息后则可连接到特定个人,对其可选择抑制(suppression)、泛化(generalization)、干扰(perturbation)、交换(swapping)、子抽样(sub-sampling)的处理方式.2018年的《加利福尼亚州消费者隐私法案》(The California Consumer Privacy Act, CCPA)将去标识化的消费者信息或聚合消费者信息排除在个人信息的范围之外.“假名化”则是一种个人信息的处理方式,在附加信息单独保存并受技术合组织管理的前提下,通过该方式处理后的数据若不附加其他信息则不再被用于识别到特定个人.2020年的《加利福尼亚隐私权法案》(Consumer Privacy Bill of Right Act, CPRA)对去标识化与假名化的相关规定与CCPA一致,同时还认为去标识化后的数据仍有残存的安全风险,规定信息处理者有禁止重新识别的义务,从管理的角度上保障个人信息安全(如图5所示).

图5 美国匿名化相关概念发展
可以看出,相较于欧盟的规定,美国对于去标识化的标准作了较为宽松的规定,提出的技术手段操作上更加简易,对于去标识化结果也没有提出定量或定性的评估方式.美国更倾向于通过合同约束数据的转让者与接收者,并且在法律当中规定其具有禁止重新识别的义务(如图6所示).

图6 欧美匿名化、假名化、去标识化相关概念对比
3 国内对去标识化、匿名化的定义及发展
2016年出台的《网络安全法》是我国法律领域与“匿名化”相关概念的起点.其中第42条规定,不得向他人提供个人信息,但经处理无法识别特定个人且不能复原的除外.2017年《信息安全技术 个人信息安全规范》是我国首次对“匿名化”“去标识化”定义的标准.匿名化为通过对个人信息的技术处理,使得个人信息主体无法被识别或者关联,且处理后的信息不能被复原的过程.个人信息经匿名化处理后所得的信息不属于个人信息.去标识化指的是通过个人信息的技术处理,使其在不借助额外信息的情况下,无法识别或者关联个人信息主体的过程.2019年《信息安全技术 个人信息去标识化指南》(以下简称《去标识化指南》)提出了常用去标识化技术,并且对技术的去标识化效果进行了评价.需要提及的是,该评价并非从“匿名化”的角度出发,而是将所有技术都置于“去标识化”的框架下,最后将去标识化后的效果进行重标识风险评估(如图7所示).与欧盟的《关于匿名化技术的意见》类似,《去标识化指南》列举了3类重标识的方法即隔离、关联、推断,并提出了重标识概率的定量分析方法,即先计算每行的重标识概率,从而得出数据集重标识的概率,再结合环境风险计算整个数据集重标识的概率.2021年4月,《信息安全技术 个人信息去标识化效果分级评估规范(征求意见稿)》(以下简称《分级评估规范》)给出了定量的去标识化评估方式,如图8所示,这与欧美的技术意见相比增加了可供评价的依据.

图7 我国去标识化、匿名化相关概念发展
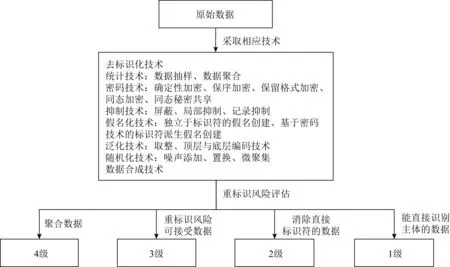
图8 我国匿名化相关的判断
相较去标识化,我国关于匿名化的提法不多.2020年《民法典 人格权篇》将散见于相关法律法规当中的人格权统一其中,人格权、隐私权、个人信息有了新的内涵.对匿名化信息有关的规定可见于第1038条,未经自然人同意不得向他人非法提供其个人信息,但是经过加工无法识别特定个人且不能复原的除外.2021年《个保法》定义了匿名化与去标识化,其由标准中的技术概念,上升为法律概念.具体地,《个保法》指出匿名化为个人信息经过处理无法识别特定自然人且不能复原的过程,个人信息不包括匿名化处理后的信息,隐含了数据控制者可不经数据主体同意对数据进行处理的意涵;而经过去标识化的个人信息,借助额外信息还能识别到特定自然人,需遵循《个保法》的各项规定.
4 对我国个人信息保护的法律思考
从上可知,我国《个保法》对匿名化、去标识化的阐释较为笼统,在实践中结合不同的场景可能有不同的解释,故需要具备更广泛的适用性.在技术上,去标识化可结合《去标识化指南》对具体数据集作出相应操作,并参照其中风险评估方法考核去标识化的具体效果,落地可操作性较强.但对于匿名化而言,我国目前尚未有匿名化相关的技术指南、评估标准,实践中亦未有人能明确自身处理后的数据为匿名化数据,若未能很好地结合实际,规范恐将沦为一个空洞且无意义的概念.故将现有的法律法规、标准结合欧美对于匿名化一类概念的相关规定以及实践中可能遇到的问题,提出如下观点,以兹参考.
4.1 定级方面
《分级评估规范》将去标识化的效果分为4级,但未明确说明哪一个级别或者达到何种程度效果的数据为匿名化数据,或者可在哪个范围使用的去标识化数据,从规范到实践有一定的跨度.例如:《分级评估规范》中的4级聚合数据仅具有统计概念上的意义,符合《个保法》对匿名化定义的内涵.
4.2 定量分析方面
《分级评估规范》是以“重标识概率”来定义风险,但必须明确的是“重标识”只是数据风险的其中一个维度,通过定量分析出来重标识概率高的数据集并不能完全代表数据集的其他风险就高.比如:完全公开共享数据,除非数据集足够大、等价类足够多,否则在该计算方法下总体风险值为1(数值越大风险越高).但从数据敏感程度的角度来看,被完全公开的数据集(合法合规的前提下),一般是风险极低的非敏感数据.故《分级评估规范》评估出的重标识风险与数据实质上面临的风险考虑上应当有所区别.
4.3 对于密码学技术去标识化的认识
无论是在欧盟《关于匿名技术的意见》中还是在我国的《去标识化指南》中都有提及密码学相关技术,对于密码学技术的考虑局限于用其对标识符进行加密处理,只要密钥没删除,个人信息就可以被“重新识别”.《去标识化指南》认为其不可能降低隔离风险、关联风险、推导风险与可辨别风险.上述认识具有一定局限性,因为在密码学技术中,在安全性假设成立的前提下其安全性具有严谨的数学证明.只要符合基于其安全性假设建立的安全模型,隔离、关联与推断风险对于密码技术来说在所有“合理可能”(攻击者的能力,如有效时间和计算能力)的情况下是可忽略的,除非攻击者付出“不合理的努力”(违法攻击服务器)才会发生,即在“合理可能”的情况下该风险近乎于0,符合匿名化的要求.
4.4 关于“合理可能”的考虑
欧盟认为匿名化应当考虑重识别所需的具体手段,特别是实施这些手段的成本和技术,评估对匿名化付出的努力和成本.我国的相关规定则不具备这方面的考虑,是一种较为绝对的规定方式.
4.5 关于“可操作性”的考虑
美国的相关规定则是将规定中的标识符删除或置换即可达到相应标准,从技术上看是一种较为“简单粗暴”的保障方式,但是操作方式较为简便,评估也具备可行性,其关键在于对管理的要求较高,包括对于违反规则所导致个人或群体利益受损时的追责机制健全.
4.6 对于“识别主体”的考虑
目前《个保法》对匿名化与去标识化的定义中未有对“无法识别到特定个人”的“识别主体”作出相应规定,但在实际业务场景中,对个人信息的保护考虑可能是“第三人”不可识别出特定个人,而对数据发送和接收方则是利用管理的手段保障个人信息安全.
4.7 对于数据处理全流程活动的考虑
去标识化考虑的模式是单方采集、享有、处理的数据,要对外发送时,用去除可识别出特定自然人标签的方式来保障个人信息不被泄露.但目前市场上对数据多方融合的需求已经进入深水区,对于数据中存在的个人信息保护已经可以贯穿数据处理的全流程活动,而无需将其限定在数据处理的起点.
5 基于多方计算数据交易所场景下的匿名化认定
在厘清我国匿名化、去标识化相关概念与实践中,近年来我国隐私计算技术的发展也为数据流通创造了新的可能性.本文在自主可控的多方计算(multi-party computation, MPC)应用可能存在问题的基础上,选取大数据交易所为例,对在采用MPC的特定场景下匿名化的认定进行分析.MPC是一种基于多方数据协同完成计算目标,实现除计算结果及其可推导出的信息之外不泄露各方隐私数据的密码技术.计算因子是基于多方计算输入数据产生的数据,包括输入因子、输出因子和中间因子.输入因子是指数据提供方执行数据输入过程后可供计算方执行后续计算的数据;输出因子是指计算方执行计算后,返回给结果适用房用以恢复最终计算结果的数据;中间因子指计算方中间计算过程中产生的数据.数据交易所基于MPC的数据交易平台,可实现数据的安全交易,降低因数据交易造成的个人信息泄露的风险.
5.1 数据交易的参与主体
1) 每个需要作数据共享的部门或单位都是数据提供方,如图9的数据提供方1与数据提供方2.在每个数据提供方部署数据接入模块,对应图中的“MPC数据输入处理”,用于实现数据的密文接入.
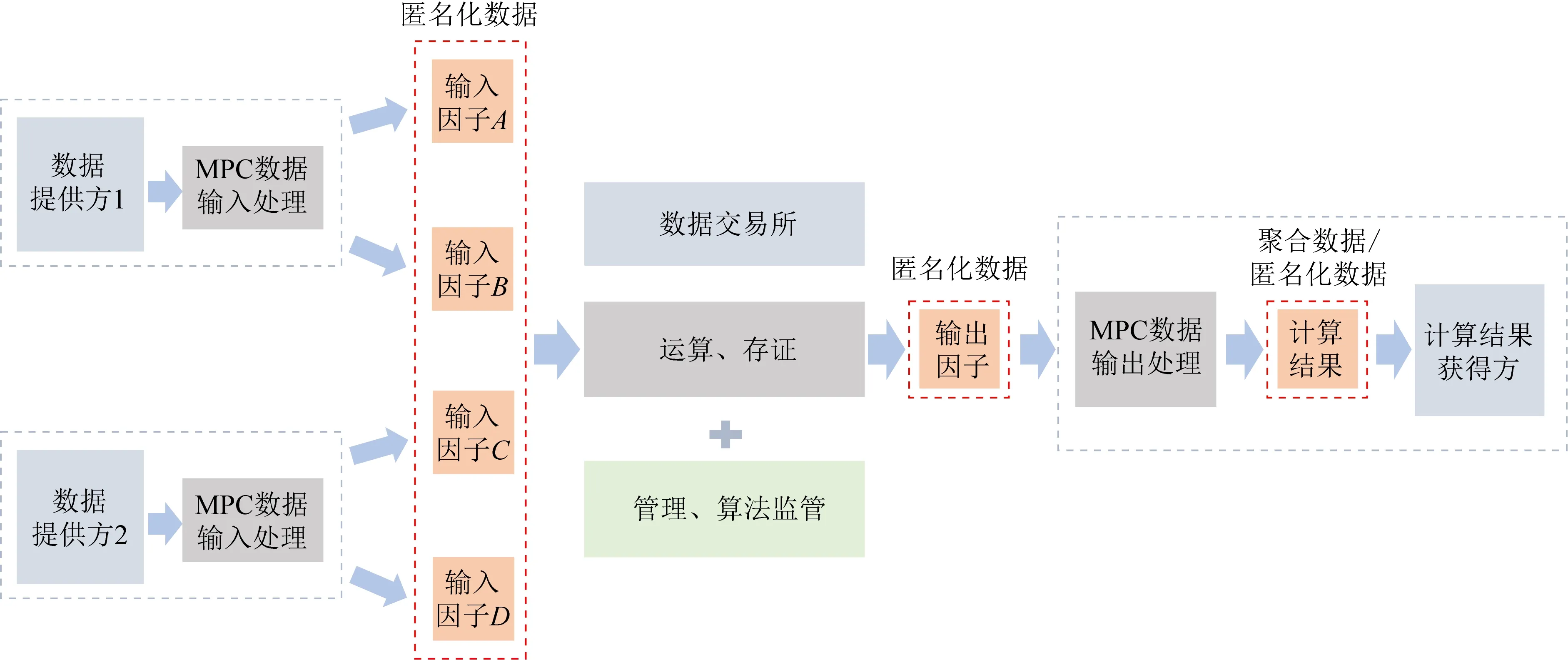
图9 基于MPC的数据交易平台匿名化的认定
2) 数据交易平台是计算方,主要提供算力,监督数据交易过程.
3) 结果获得方一般也是数据的实际需求方.
5.2 数据交易的流程
1) 数据提供方提供数据目录;
2) 数据需求方查看数据目录,根据自身需求与数据交易所订立合约;
3) 数据提供方审核所需数据及算法后,将数据通过MPC数据输入处理后形成计算因子,将计算因子传输至数据交易平台;
4) 数据交易平台对接入的计算因子根据合约中的算法进行计算;
5) 数据交易平台将计算后的结果发送至数据需求方(结果获得方).
5.3 数据交易的管理
数据提供方对算法进行审核,只有审核通过后,数据需求方才能正常使用该算法.数据交易平台基于区块链等技术搭建的应用,负责数据资源目录管理、数据合约订立和执行以及数据安全融合流程存证等功能,建立多方可见且不可篡改的存证体系,支持问题溯源和审计需求.
5.4 数据交易中匿名化数据的认定
1) 输入因子,不降低数据的可用性,其他方只有在获得所有输入因子时才可能恢复、识别出原始数据集中的特定自然人,可以说每个独立的输入因子完全符合匿名化的相关规定;
2) 输入因子在数据交易平台集中计算,可能被视为“加密数据与密钥结合”,导致不再被视为“匿名化”,但计算场所是一个可监管的环境,通过严格的管理约束,按照计算合约限制的范围完成计算,基本不存在泄露特定个人数据的风险;
3) 数据交易平台输出的输出因子依然是加密数据,符合匿名化的相关规定;
4) 输出因子传输至计算结果获得方,通过MPC数据输出处理(解密),从而获得“计算结果”,其一般为一个不具备任何可识别出特定自然人可能性的“模型”或者符合“聚合数据”特征的数据.“聚合数据”在《分级评估规范》被定为第4级,虽然目前该级别数据尚未被认定为匿名化数据,但根据其“不可重识别出特定个人”的特性,可认为其符合匿名化的相关规定.
5.5 数据交易需考虑的风险点
1) 计算因子仅在符合安全性假设的前提下,可视为完全清除“隔离”“关联”“推断”风险,即不存在被识别出的可能性;
2) 计算因子的“匿名化”保证,需结合管理上的措施,对算法用途的审核,保证数据有限的用途,且不可用于识别出特定个人.
6 结论与建议
6.1 法律法规与标准的制定应当考虑技术进步及其应用场景
去标识化是一种通过对标识符处理来达到不可识别具体个人效果的技术,较少考虑数据在具体场景应用上的问题,也忽略了技术进步在法律法规中的融合实践.因为信息技术的快速发展,如果对相关法令的运用解释过度制式化、僵化,亦可能造成产业创新的阻碍.应当考虑具体化、匿名化与加工信息流程的关系,并保持弹性以应对各种可能场景的个案问题.
6.2 对于匿名化的“合理保证”与“重新被识别”的标准
匿名化应当是一种“合理保证”而不是“绝对保证”,法律法规与标准的制定应当考虑可操作性,以在实践中更好地应用.应适当考虑“重新被识别”的标准是一种合理的可能性,并建立数据责任人自证其管理完备且已尽到合理可能范围内最大努力的机制.目前对于匿名化的效果未有相应的标准,《分级评估规范》建立了去标识化后的数据集的评价机制,但对应级别是什么样类型的数据却未有明示.
6.3 关于数据处理的全流程活动与重新识别的主体
目前所有去标识化的技术都是“单方”“本地处理”,新的技术应用方式“多方融合”与数据处理的全流程活动却没有被考虑.去标识化与匿名化考虑的是单方采集、享有、处理的数据,要对外发送时,用去除可识别出特定自然人标识符的方式来保障个人信息不被泄露,是一种静态的、基于数据接收方取得的是明文数据集的思路.采用类似MPC的技术已经可以对数据中存在的个人信息保护贯穿数据处理的全流程活动,通过对数据使用的限制做到数据接收方不能滥用个人信息.同时,可由6.2节对数据交易所的场景示例得知,在数据交易的关键节点,数据符合“匿名化”相关规定;有被“重新识别”可能性的数据交易节点,被严格监管.
6.4 管理机制对于个人信息保护的重要性
匿名化不能只考虑技术,随着法律法规的逐步完善,数据处理的管理机制对于个人信息保护至关重要.借鉴美国的规定,认识管理手段对个人信息保护的重要性,制定技术保护措施与管理规定,禁止重新识别到特定自然人.需充分认识到:
1) 数据泄露或滥用造成风险的本质是数据控制者对数据的“用途”与“用量”失去控制,而在基于MPC的数据交易平台是对数据“用途”与“用量”的交易,是一种从源头上控制风险的手段.
2) 在基于MPC的数据交易平台的数据交易中,应当防范的是利用多次计算重新识别出特定个人及其相关信息的行为.因此对数据的监管应重点关注对计算用途的监管,而不能仅停留在对数据集标识符去标识化处理的效果及其度量本身.在基于MPC的数据交易平台中,平台监督数据交易的全过程、审核计算合约中的算法、对交易过程进行存证,是一种事前审核+事中存证+事后审计的管理模式.
6.5 保障畅通的维权渠道保护个人信息
去标识化与匿名化的规定是一种风险防范的思维,为了更好地保障个人信息主体的各项权益,还应当完善侵权责任的相关规定,并且通畅个人维护自身权益的渠道.以数据交易所的场景为例,参与数据交易的主体与交易所应积极地、谨慎地采取有效措施确保信息安全,防止个人信息泄露与滥用.除了《数据安全法》中对数据交易中介所需遵循的相关规定外,若数据交易引起有关个人信息泄露、滥用等问题,应当采取过错责任推定,即参与数据交易的主体、交易所不能自证无过错的情况下,推定其对个人信息的泄露、滥用有过错,应承担赔偿损害的民事责任,以更好地保护个人的权益,平衡数据交易参与各方的权益.
6.6 对于特定行业应用的考虑
日本的《次世代医疗基盘法》立法移除了现行个人信息保护法对利用医疗大数据造成的障碍,让各医院、医疗机关的个人医疗信息相互串联流通,有助于医疗领域能更灵活利用医疗数据作多目的研究与创新.我国《刑法修正案九》提出非法出售和提供个人信息罪,绝对禁止个人信息的交易行为.但必须明确,排除一切个人信息有关数据的商业化应用,对于数字经济而言将会是毁灭性的打击.同样以数据交易为例,交易的“价值”所在是数据“用途”与“用量”,并不是含有个人隐私的“个人信息”本身,出于促进数据流通的考虑,建议探讨对特定行业应用个人信息制定相关豁免条款的可行性.
6.7 结 语
2021年8月20日《个保法》正式通过,其中匿名化处理后的信息不再是个人信息,此概念备受数据相关从业人士关注.从《个保法》条文看来,可理解为匿名信息由数据控制者(企业)原始取得,但处理后的效果与边界仍有待进一步厘清,以更好地划分数据流通过程中的“权责利”.当前基于大数据分析、人工智能的发展,推动了海量数据的汇聚融合,考虑到法律落地与未来执法的可操作性,“匿名化”的实现路径应当是法律、标准、技术、管理与效果评估的结合.本文借鉴欧美匿名化相关规定、技术可操作性,结合基于多方计算的数据交易所的场景,旨在提出一种可行的匿名化认定方式,对《个保法》中匿名化落地提出相关建议.
猜你喜欢
工会博览(2022年16期)2022-07-16 05:53:54
今日农业(2022年1期)2022-06-01 06:17:42
数学物理学报(2021年4期)2021-08-30 08:27:50
中等数学(2020年1期)2020-08-24 07:57:42
疯狂英语·爱英语(2020年9期)2020-01-07 00:52:42
文化创新比较研究(2020年14期)2020-01-02 19:25:56
文化创新比较研究(2020年8期)2020-01-02 04:45:23
绿色中国(2019年14期)2019-11-26 07:11:44
特别健康(2018年3期)2018-07-04 00:40:08
长春大学学报(2014年8期)2014-12-05 05:17:00
