
人脸活体检测综述
2021-09-28 07:20蒋方玲刘鹏程周祥东
自动化学报 2021年8期
蒋方玲 刘鹏程 周祥东
人脸活体检测是指辨别当前获取的人脸图像是来自活体人脸还是假体人脸的过程,其中活体人脸指有生命的真实人脸,假体人脸指冒充真人身份的人脸仿冒品[1].随着人脸识别技术的广泛应用,人脸活体检测作为保障人脸识别技术安全性的关键环节,逐渐成为计算机视觉、模式识别、人脸识别领域非常活跃的研究方向.
人脸活体检测研究具有重要的应用价值.深度学习的发展使人脸识别技术的性能有了质的提升,人脸识别技术具有自然、直观、易用等优点,目前已广泛应用于智能安防、公安刑侦、金融社保、智能家居、电子商务、人脸娱乐、医疗教育等领域,应用场景丰富,应用市场潜力巨大.然而,人脸识别技术的广泛应用亦使得人脸识别技术的安全性问题日益凸显.传统的人脸识别研究专注于整体识别性能的提升,如图1 所示,整体处理流程一般包含人脸检测、人脸对齐、特征抽取、特征比对等环节,其并不判断当前获取的人脸图像是来自活体人脸还是假体人脸.随着智能手机和社交网络的蓬勃发展,不法分子收集合法用户的人脸图像,制作假体人脸的渠道广、成本低.文献[2] 利用合法用户在社交网络上发布的照片轻松地经过了6 个商业人脸识别系统Face Unlock,FacelockPro,Visidon,Veriface,Luxand Blink 以及FastAccess 的认证.目前人脸识别技术广泛应用于对安全性有较高要求的人员身份鉴定场景,若不法分子利用传统人脸识别技术的这个安全性隐患,使用假体人脸成功冒用合法用户身份,从短期来看,侵犯了合法用户的权益,较大可能造成生命财产损失;从长远来看,亦会影响人脸识别技术的进一步广泛深入应用.因此,如何准确识别活体人脸与假体人脸,保障人脸识别技术的安全性成为一个亟待解决的问题.

图1 传统人脸识别技术的安全性缺陷Fig.1 Vulnerability of conventional face recognition system
人脸活体检测研究具有重要的学术价值.近年来,国内外对人脸活体检测的研究活跃.瑞士Idiap研究所、密歇根州立大学、奥卢大学、南洋理工大学、中国科学院自动化所、清华大学、上海交通大学等都有团队从事人脸活体检测的研究.CVPR(IEEE Conference on Computer Vision and Pattern Recognition)、ECCV (Europe Conference on Computer Vision)、IEEE Transactions on Information Forensics and Security 等重要国际会议期刊上发表的人脸活体检测相关论文数量大幅度增长.人类的智慧是无穷的,假体人脸亦是各种各样,层出不穷.通过寻找活体人脸与假体人脸之间的可区分线索,研究出准确率高、通用性强的人脸活体检测算法,不仅能够服务于人脸识别技术,对于类似的纹理分类,皮肤检测,掌纹、静脉、虹膜等生物识别领域亦能够提供思路启发.
鉴于人脸活体检测的重要研究价值,相关研究者对人脸活体检测方法进行了综述.文献[3] 根据算法使用的技术对2014 年前的人脸活体检测方法进行了综述.文献[4-5] 对2017 年已有的人脸活体检测方法进行了综述.这些文献详细列举了目前存在的假体人脸类别,对于假体人脸的特性所造成的人脸活体检测问题没有更深入的分析,而问题的剖析更有利于后期有效方法的提出.因此,有必要对假体人脸特性所造成的人脸活体检测的难点进行深入剖析.除此之外,这些文献主要对基于手工特征的方法进行了分析综述,对于基于深度学习的方法少有涉及.随着深度学习方法的发展,不少研究者提出了基于深度学习的人脸活体检测方法.相对于2017 年前已有的人脸活体检测算法,近年来出现的基于深度学习的人脸活体检测算法很大程度上提升了人脸活体检测的性能.虽然目前基于深度学习的人脸活体检测算法也存在一定的问题,但是鉴于深度学习方法在人脸识别、物体分类等其他计算机视觉领域的应用经验,利用深度学习方法进行人脸活体检测的前景是可观的.因此,有必要对基于手工特征以及基于深度学习的人脸活体检测方法进行全面地综述和讨论,以期为进一步的人脸活体检测研究奠定一定的基础.
本文系统地综述了人脸活体检测相关研究进展,并对未来发展趋势进行了展望.本文首先从人脸活体检测的问题出发,从个体、类内、类间三个层面分析了假体人脸给人脸活体检测带来的难点和挑战,继而根据人脸活体检测算法的主要应用形式将主流算法分为交互式人脸活体检测与非交互式人脸活体检测两大类进行梳理和总结,详述了代表性方法的原理、优势与不足.之后,对人脸活体检测方面的主流数据库进行了整理,对数据库的特点、数据量、数据多样性方面进行了比较分析,对算法评估常用的性能评价指标进行了阐述,总结分析了代表性人脸活体检测方法在照片视频类数据集CASIA-MFSD、Replay-Attack、Oulu-NPU、SiW 以及面具类数据集3DMAD、SMAD、HKBU-MARsV2 上的性能数据,最后对人脸活体检测算法未来可能的发展方向进行了思考和探讨.
1 人脸活体检测的难点与挑战
人脸活体检测已经发展为保障人脸识别系统安全性的一个基本问题,逐渐成为了人脸识别整个处理流程中的一个重要环节,亦是一个非常具有挑战性的问题.目前常见的假体人脸有以下几种:
1) 照片类假体人脸
照片类假体人脸是指用照片纸、普通打印纸打印的黑白(如图2(a) 所示)、彩色人脸照片或者电子设备显示的电子照片.照片类假体人脸是二维人脸,有完整照片假体人脸(如图2(b) 和图2(c) 所示)和挖去部分脸部区域的照片假体人脸(如图2(d) 和图2(e) 所示) 两类,挖去的区域通常是眼部(如图2(d) 所示) 或者嘴部(如图2(e) 所示) 区域.照片类假体人脸可以平铺在摄像头前(如图2(b) 所示),亦可弯曲地放在摄像头前(如图2(c) 所示).社交网络的发展使得假体人脸的制造者能够快速、方便地收集他人的人脸图像,打印机的普及也使得打印照片方便且成本低廉.因此,照片类假体人脸是最常见的假体人脸.

图2 不同类别假体人脸示例Fig.2 Examples of spoofing faces
2) 视频类假体人脸
视频类假体人脸是指通过手机、平板电脑或者其他电子显示设备播放的预先录制好的人脸视频(如图2(f)所示).这些视频通常包含眨眼、点头、抬头、张嘴、唇部微运动等一些动作信息,用于迷惑人脸识别系统.
3) 面具类假体人脸
面具类假体人脸是指各类材质的三维人脸面具.此类假体人脸通常有塑料、乳胶、硅胶材质的人脸面具、人脸模具等.塑料硅胶人脸面具有根据商家设计的人脸制作的面具(如图2(h) 和图2(f) 所示),亦有根据用户提供的照片定制的人脸面具(如图2(j) 和图2(k) 所示),其中,图2(j) 的制作方是ThatsMyFace (thatsmyface.com),图2(h) 的制作方是REAL-F (real-f.jp).人脸模具指三维立体人头模块(如图2(l) 所示),一般不可以戴在脸上.
4) 合成的三维人脸模型类假体人脸
合成的三维人脸模型类假体人脸是指利用合法用户照片使用三维人脸软件合成的三维人脸模型(如图2(m) 所示).此类人脸模型通常以电子设备为媒介,通过电子设备显示后攻击人脸识别系统.
人脸活体检测的难点与挑战究其原因,主要是假体人脸以假乱真的高质量以及假体人脸的多种多样导致的,具体可以从个体、类内和类间三个层面来看.
a) 个体.人脸活体检测的任务是要识别当前获取的人脸图像是否来自有生命力的活体人脸.基本解决思路是抽取活体人脸图像与假体人脸图像的差异作为分类线索.目前很多假体人脸的制造工艺优良,制造出来的假体人脸质量高,经人脸检测对齐处理后的假体人脸图像与活体人脸图像看起来非常相似.如图3 所示,人眼几乎很难分辨出这些人脸图像不是采集于活体人脸而是照片类假体人脸.个体层次以假乱真的高质量使得人脸活体检测的难度大大增加.

图3 Replay-Attack 数据集中的假体人脸Fig.3 Spoofing faces of Replay-Attack
b) 类内.同一类别的假体人脸虽然有共同的本质特征,但是同一类别的不同假体人脸也存在着较大差异.假体材质、制造方式、制造者、外界环境的不同都会导致同类别的不同假体人脸的差异.比如说,照片类假体人脸的材质有打印纸、照片纸、电子显示屏等.面具的材质有塑料、乳胶、硅胶等.不同材质的同类别假体人脸成像时反射属性、纹理方面会存在较大差异.不同的打印机、不同的电子显示设备、不同的生成厂家及其制造方式都会导致同类别不同假体人脸在颜色分布、分辨率、外观质量等方面存在差异.同类别不同假体人脸的成像效果也会根据人脸识别系统的摄像头、外界环境的差异而多种多样.这些类内的差异给人脸活体检测算法带来了极大的困难.
c) 类间.假体人脸的种类多种多样,具体来说其品类有照片、视频、面具之分,其材质有纸质、电子显示屏、塑料、硅胶之分,其结构有二维和三维之分.目前大部分人脸活体检测算法都是根据具体的假体人脸类型设计具体的算法.假体人脸的类间差异使得抽取有效而通用的特征同时去准确识别各类假体人脸与活体人脸的难度大大增加,给人脸活体检测算法带来了极大的挑战.不仅目前常见的假体人脸多种多样,随着假体人脸制造技术的发展,未来的假体人脸更是可能多种多样.人脸活体检测算法如何对这多种多样的未知假体人脸有效而通用更是一个有挑战的问题.
2 人脸活体检测方法
现有的人脸活体检测方法从多种不同的角度致力于将活体人脸图像与假体人脸图像区分开来.关于人脸活体检测方法的分类,根据不同的分类依据可以得到不同的分类体系.如以信号源为依据,可以分为基于可见光的人脸活体检测、基于红外的人脸活体检测、基于多光谱的人脸活体检测、基于光场相机的人脸活体检测、基于深度摄像头的人脸活体检测、基于可见光图像与语音混合的人脸活体检测.以输入信息的模态为依据,可以分为基于单帧图像的人脸活体检测、基于视频的人脸活体检测、基于三维深度坐标点的人脸活体检测、基于视频语音混合的人脸活体检测.人脸活体检测方法一般将人脸活体检测问题作为一个活体人脸图像和假体人脸图像的二分类问题来处理.分类问题的性能很大程度上由算法是否使用了区分性足够强的特征以及是否使用了合适的分类策略.考虑到特征的重要性,本文拟以人脸活体检测方法所利用的特征种类为线索详述各类人脸活体检测算法.本文根据当前主流人脸活体检测方法的应用形式,将其分为交互式人脸活体检测与非交互式人脸活体检测两大类,针对每类方法,进而以特征种类为线索,具体阐述各类人脸活体检测算法[6-102].整体分类体系如图4 所示,表1对相应类别方法进行了概括性的对比分析.下面将对各类方法进行具体阐述.
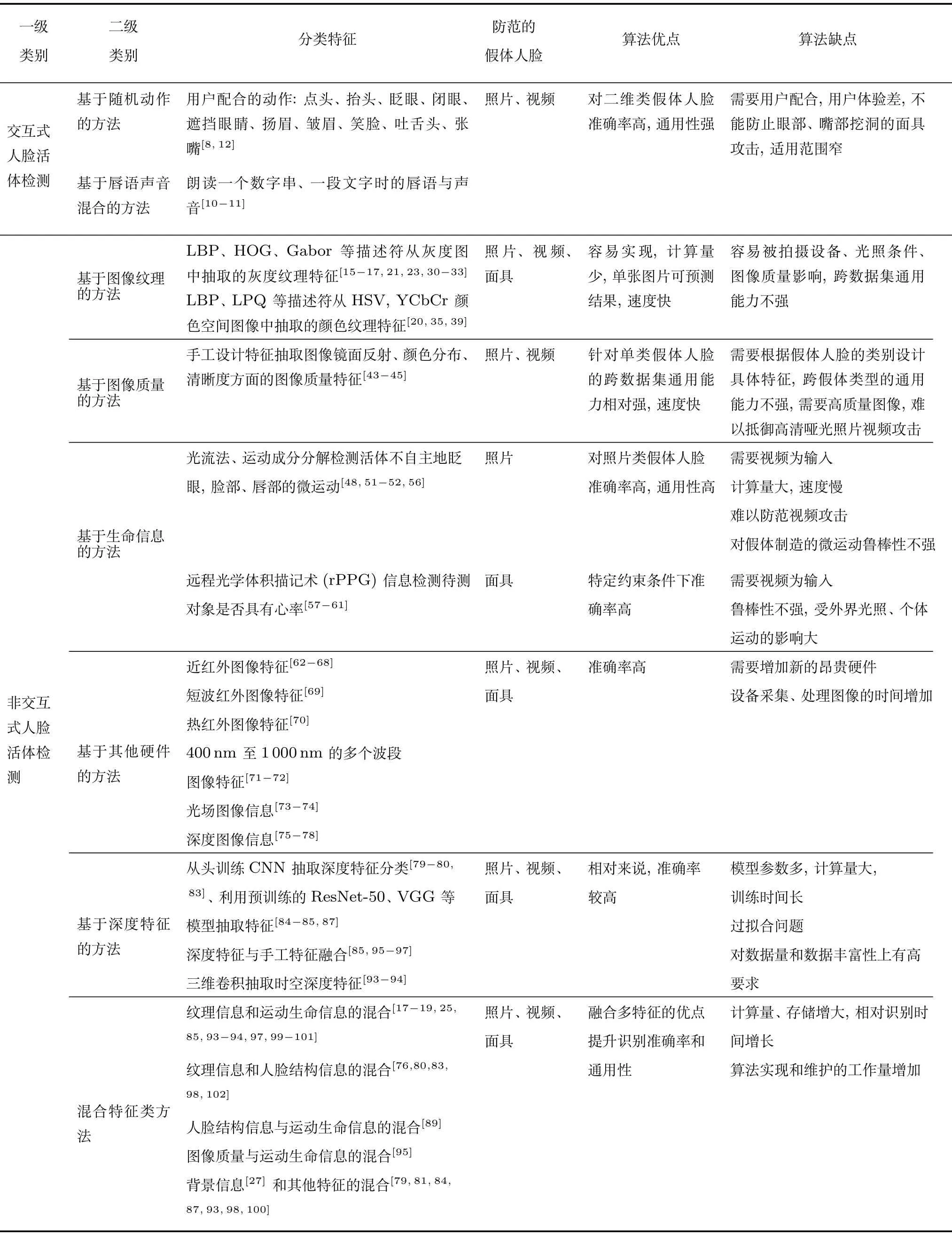
表1 主流人脸活体检测方法总览Table 1 Brief overview of face anti-spoofing methods

图4 人脸活体检测方法分类Fig.4 Classification of face anti-spoofing methods
2.1 交互式人脸活体检测
活体人脸的宿主是有生命力的人类.人类可以按照要求做出动作或者发出声音,但是假体人脸却难以做到.基于这个考虑,人们提出了交互式人脸活体检测方法.交互式人脸活体检测利用动作指令与用户交互,系统通过判断用户是否准确完成了指定动作来辨别摄像头前的人脸是活体人脸还是假体人脸[6-14].常见的动作指令有点头、抬头、眨眼、闭眼、遮挡眼睛、扬眉、皱眉、笑脸、吐舌头、张嘴、朗读一段文字等.
早期的交互式人脸活体检测动作指令的设计是固定的,这使得预先录制完成动作指令的视频就能攻破这类人脸活体检测算法.为了解决这个问题,基于随机动作指令的交互式人脸活体检测应运而生.动作指令的随机性使得攻击者难以预先录制视频来攻破活体检测算法.交互式人脸活体检测算法的性能如检测准确率、检测时间很大程度上依赖于动作指令识别算法的性能.动作指令的识别是交互式人脸活体检测算法的核心部分.文献[8] 对连续多帧人脸图像中的动作执行区域进行二值化处理,通过分析二值化图像的变化是否大于指定阈值来判断用户是否完成了随机指定的动作.文献[10] 通过检测人脸嘴部区域的变化幅度进行唇语识别,辅以语音识别获取用户响应的语音信息共同判断用户是否按要求朗读了系统随机给出的语句.文献[11] 抽取嘴部区域的光流特征继而用支持向量机(Support vector machine,SVM) 进行分类来识别用户是否朗读了系统给出的一串数字.文献[12] 指导用户完成随机表情动作,通过计算多帧图像的尺度不变特征变换(Scale-invariant feature transform,SIFT) 流能量值来判断用户是否完成了指定表情.
交互式人脸活体检测通过精心设计的交互动作,有效减弱了假体人脸类内类间差异对算法性能的影响,因此识别率高,通用性较好,目前广泛应用于金融、医疗等实际业务场景中.交互式人脸活体检测需
要从多帧图像中识别用户是否完成了动作,相对基于单帧的算法计算量大、所需时间长,而且其需要用户在指定区域内完成多个指定动作,检测过程繁琐,对用户的限制和要求较高,用户体验不佳,违背了人脸识别技术方便自然识别的优点.除此之外,交互式人脸活体检测需要用户配合的特点决定了其只能用于用户主动配合的业务场景,不适用于视频监控人脸分析之类的用户处于自然行为状态的业务,应用范围相对窄.
2.2 非交互式人脸活体检测
非交互式人脸活体检测在用户无主动感知条件下辨别活体人脸和假体人脸,无需与用户进行交互.非交互式人脸活体检测分析摄像头捕获的活体人脸图像和假体人脸图像间的差异来区分活体人脸和假体人脸.从利用的差异特征方面分析,非交互式人脸活体检测可以分为基于纹理的方法、基于图像质量的方法、基于生命信息的方法、基于其他硬件的方法、基于深度特征的方法和混合特征类方法.
2.2.1 基于纹理的方法
常见的基于纹理的方法主要关注照片、视频类攻击[15-35],也有少量文献处理面具类攻击[36-38].照片、视频中的人脸二次成像时面部的纹理会带有照片纸或者电子显示屏的纹理,与活体人脸皮肤的纹理有一定差异.照片类假体人脸不同的打印质量,视频类假体人脸显示设备不同的显示分辨率也会造成假体人脸的纹理与活体人脸不同.除此之外,活体人脸有复杂的三维立体结构,照片、视频类攻击是二维的平面结构,光在三维结构和二维结构表面不同的反射会形成脸部颜色明暗区域的差异.基于纹理的方法主要利用这些差异为线索进行活体人脸和假体人脸的分类.
局部二值模式 (Local binary patterns,LBP)[103]考虑了像素及其相邻像素间的关系,作为一种局部纹理描述符,能够抽取高判别力的纹理特征且理论简单、计算复杂度低,已广泛应用于基于纹理的人脸活体检测方法.鉴于LBP 描述符在人脸活体检测领域的基础地位,这里对LBP 描述符简单地进行介绍.原始的LBP 算子定义了一个3×3的矩阵邻域,以中心点像素值为阈值将邻域像素值二值化,邻域的像素值大于或者等于中心点像素则设为1,邻域的像素值小于中心点像素则设为0,之后以逆时针方向遍历邻域一周得到一个表示中心点的像素值二进制模式.图像中的每一个像素点按照此计算方法得到一个表示局部纹理信息的二进制模式.统计各个二进制模式出现的频率得到LBP 直方图作为特征向量用于分类.3×3 的邻域设计使得原始的LBP 描述符不能获取其他尺度的纹理信息,Ojala 等[103]采用圆形邻域扩充了3×3 的矩阵邻域,使得其能够自定义使用指定半径圆上的指定个邻域点的信息.如此改进后却依然存在问题:同一尺度下的LBPP,R的各个模式出现的频率不均匀致使抽取的纹理特征效果不能让人满意,同时会产生2P种不同的二进制模式,对计算和存储带来了挑战.为了解决这个问题,Ojala 等[103]提出了均匀LBP.均匀LBP 模式是指二进制串里从0 到1 或者从1 到0 的变化不超过U次.每一个均匀LBP 模式分为独立的一类,非均匀的LBP 模式全部归为一类.均匀LBP 起到了降维的作用,改进计算效率的同时提升了特征抽取的效果.
文献[15-17] 将采集的图像转化为灰度图之后抽取图像的灰度纹理信息用于活体人脸和假体人脸的分类,屏蔽了颜色光照因素的影响.文献[15] 利用多个不同尺度的均匀LBP 算子从灰度图的局部块以及全局图像中抽取纹理特征直方图,之后将所有特征直方图连接形成一个531 维的特征直方图送入以径向基函数(Radial basis function,RBF) 为内核的SVM 分类器中进行活体人脸和假体人脸分类的训练和测试.基于灰度图的纹理分析算法对于高分辨率、纹理清晰的假体人脸图像比较有效,但是对于一些低分辨率的假体人脸图像,则很难分辨准确.一般用于制造照片视频假体人脸的打印机或者电子设备的色域是人眼可视色域的子集,其颜色没有人眼能感知的颜色丰富.因此,打印机或者电子设备制造的照片、视频类假体人脸在颜色分布上与活体人脸有一定差异.考虑到这个因素,文献[20] 将图像从RGB 颜色空间转化为YCbCr 颜色空间,从亮度、色度通道抽取LBP 纹理特征,结合颜色、纹理两方面的差异线索进行人脸活体检测.除了LBP 特征,LBP 的一些变种,如tLBP[16],dLBP[16],mLBP[16],CLBP[21],CSLBP[21],LBPV[22]等也被用于抽取图像中的纹理信息.
除了LBP 及其变种,研究者们也提出了诸多其他的特征描述符用于人脸活体检测纹理特征的抽取.文献[23] 将人脸分成12 个小块,利用局部相位量化(Local phase quantization,LPQ) 抽取纹理特征.文献[21,24] 利用二值化统计图像特征(Binarized statistical image features,BSIF) 抽取脸部局部块和脸部全局的纹理特征送入SVM 用于分类.方向梯度直方图(Histogram of oriented gradient,HOG) 计算局部区域的梯度方向直方图构成特征被用于分类[23,26-29].文献[28,31-32] 使用灰度共生矩阵(Gray-level co-occurrence matrix,GLCM)[104]统计像素间灰度值的分布规律抽取纹理特征.文献[33-34] 利用高斯差分函数(Difference of Gaussian,DOG) 抽取纹理特征识别差光照条件下的活体人脸和假体人脸.文献[15,26,32] 利用Gabor 滤波器提取不同尺度不同方向上的纹理特征.文献[39] 利用加速稳健特征(Speeded-up robust features,SURF) 从HSV、YCbCr 颜色空间的图像中抽取颜色纹理特征.文献[40] 利用一个附加的闪光灯以便拍摄的图像纹理更清晰,活体人脸图像和假体人脸的纹理差异更明显.不少研究者们混合使用多种特征描述符从图形中抽取特征,继而连接不同描述符的特征送入分类器SVM 进行训练和测试,如LPQ 与LBP 混合[23,41],BSIF 与LBP 混合[24],HOG 与LPQ 混合[42],Gabor、LBP、GLCM的混合[32].不同特征的混合有利于人脸活体检测性能的提升,但是同时也增加了计算复杂度.
总体来说,基于纹理的方法计算量少,计算复杂度低,容易实现.基于纹理的方法着重利用纹理颜色方面的差异进行分类,要求输入图像的分辨率高,能够保存清晰的颜色纹理细节信息,对采集设备有高要求.采集条件如光照、摄像头质量的差异,假体人脸制造设备的差异造成的假体人脸类内差异皆会导致同类别假体人脸抽取的纹理模式不同,因此,基于纹理的方法普遍存在跨数据集通用性不够强的问题.文献[35] 也利用丰富的实验验证了采集条件差异和假体人脸类间差异对于基于纹理的人脸活体检测算法的跨数据集通用性存在明显的削弱.
2.2.2 基于图像质量的方法
假体人脸的呈现需要一定的媒介,无论是照片纸、打印纸、电子设备、硅胶、塑料等各类媒介的材料属性与活体人脸的五官、皮肤材质都有差异.材质的差异会导致反射属性的差异,如照片纸、手机显示屏会有一些镜面反射而活体人脸基本不会存在这种现象.假体人脸的制造工艺虽然优良,但是大部分假体人脸二次成像后的图像质量与活体人脸还是存在一定距离,如颜色分布的失真、假体人脸图像的模糊感等.基于图像质量的方法主要利用图像失真、反射属性方面的差异分辨真假人脸.
文献[43] 设计了25 种图像质量评估指标用于评估假体人脸的失真程度.文献[44] 针对人脸活体检测设计了14 种通用特征用于抽取图像质量方面的差异.文献[45] 利用镜面反射、图像模糊、颜色分布等图像失真方面的分析提取了针对照片假体人脸的特征.图像的质量很大程度上依赖拍摄设备以及外界条件.低质量的拍摄设备以及差的光照等外界条件亦会使得活体人脸的图像存在失真的问题.文献[46] 考虑了不同质量拍摄设备的影响,首先利用聚类的方法将图像以图像质量维度聚类,然后针对每一种质量等级的图像预训练一个基于图像质量特征的活体人脸和假体人脸分类指导模型,对于测试图像,首先判断其图像质量等级,利用回归的方法映射图像到其对应图像质量等级的分类指导模型,之后利用映射得到的分类指导模型进行活体人脸和假体人脸分类.文献[47] 选取图像质量差异明显的人脸块用于人脸活体检测,他们首先将检测到的人脸图像分成小块,利用图像质量评价、图像强度分析等方法将小块人脸图像根据其判别能力进行排序,最后从判别能力强的小块人脸图像中抽取特征,送入SVM、二次判别分析(Quadratic discriminant analysis,QDA) 等分类模型中进行活体人脸和假体人脸分类.
基于图像质量的方法计算复杂度低,检测速度较快,有利于在线实时检测.此类方法使用了一些通用的图像质量评估特征,能够较好地应对假体人脸的类内差异问题,对于单类假体人脸的跨数据通用能力相对较强.目前基于图像质量的方法主要关注于照片、视频类假体人脸的识别,对面具类假体人脸的研究较少.此类方法不能很好地应对假体人脸的类间差异,需要针对每一类假体人脸的特点设计其图像质量方面的特征,识别照片、视频类假体人脸的图像质量特征不能简单地迁移使用到面具类假体人脸的识别.算法虽然对于打印照片、手机显示的照片视频假体人脸比较鲁棒,但是难以准确识别一些高清哑光的照片、视频攻击[44].从基于图像质量的方法的本质来看,其需要高质量的活体人脸和假体人脸图像作为输入以便能够抽取足够好的图像质量特征,对人脸图像采集设备要求高.
2.2.3 基于生命信息的方法
活体人脸和假体人脸之间一个明显的区别是活体有心跳、血液流动、眨眼、脸部肌肉不自主地微运动等生命特征,而大部分类别的假体人脸难以完美模仿此类生命特征.基于生命信息的方法主要利用这些生命特征方面的差异来进行活体人脸和假体人脸的分类.
文献[48-49] 利用条件随机场检测输入图像序列中的人眼是否存在睁眼闭眼的切换来判断是否是活体人脸.文献[50] 分析眼部区域多个尺度、多个方向的Gabor 响应信号来判断是否存在眨眼行为.文献[51] 分析活体人脸唇部不自主地微动作进行活体检测.此类利用眼睛和唇部信息的方法能够比较好地识别照片类假体人脸,但是不能很好地识别视频、面具类假体人脸.活体人脸具有三维立体结构,其运动模式和照片、视频类二维假体人脸存在差异.文献[52-54]利用光流线(Optical flow of lines,OFL) 从水平方向和垂直方向两个维度计算人脸图像的时空差异,获取人脸的运动信息来检测照片、视频之类的平面假体人脸攻击.文献[55] 利用欧几里得运动放大的方法增强人脸不自觉的微运动信息并用HOOF(Histogram of oriented optical flow)算子抽取运动特征.文献[56] 利用运动成分分解的方法从图形中分解出眨眼、唇部动作、脸部肌肉动作等运动信息用于活体检测.基于运动信息的检测方法利用了假体人脸难以模拟的生命特征,对于活体人脸和假体人脸来说差异大.同时,假体人脸的类内类间差异对于此类方法有效特征的抽取影响较少.在约束条件下,特征能够稳定抽取时此类方法检测准确率高,但是其需要人脸视频作为输入,计算量相对大,假体人脸的一些模拟微运动能够迷惑此类算法.
远程光学体积描记术(Remote photoplethysmography,rPPG)[105]是一种利用普通摄像头拍摄的人脸视频计算人体心率的方法.活体人脸面部有丰富的毛细血管,活体心脏跳动会导致血管中血液流量和流速的变化,而血流的变化又影响面部光线的吸收和反射情况,最后这种血液的变化就导致了人脸颜色的变化.通过抽取人脸毛细血管丰富区域的颜色变化即可得到心率的变化.活体人脸的宿主有心率,而假体人脸没有心率,利用这个线索,文献[57-60] 利用rPPG 信号检测待测对象是否具有心率并以此判断待测对象是否是活体人脸.文献[61]从图像的R 和G 通道中抽取血流信息来进行活体检测.此类抽取心率、血流信息的方法多用于三维面具类假体人脸的检测上,在良好不变光照条件下,待测对象保持姿态、表情不动的情况下方法准确率较高,但是它们的计算过程需要足够长的高清人脸视频以便能够抽取到足够好的rPPG 信号,同时rPPG 信号受外界环境光照、待测对象运动的影响大,方法鲁棒性不强.
2.2.4 基于其他硬件的方法
除了利用传统的可见光摄像头捕获人脸图像,研究者们也利用了其他多元化的硬件如红外摄像头、多光谱摄像头、光场相机、深度摄像头等捕获相应类型的人脸图像进行活体检测.
1) 红外摄像头、多光谱摄像头
红外摄像头、多光谱摄像头是最常用的一种.不同波段的红外如近红外、短波红外、热红外都有相关研究工作.假体人脸的材质与活体人脸的皮肤、眼睛、嘴唇、眉毛等部位的材质不同,而材质的不同就会造成反射属性有差异.虽然假体人脸在可见光条件下看起来和活体人脸非常相似,但是在红外光谱下,活体人脸的皮肤、眼睛、鼻子等区域看起来和假体人脸都有较大差异.一些研究者利用Gabor、HOG、朗伯模型等抽取近红外摄像头图像中活体人脸和假体人脸的反射差异进行活体检测[62-68].在近红外光谱下,照片和视频攻击与活体人脸的差异较大,此类方法准确率高,跨数据通用能力强,但是制作精良的面具却与活体人脸的差异较少.为了识别面具攻击,文献[69] 利用短波红外来区分人脸皮肤和面具.热红外图像中包含了受测对象散发的热辐射信息.活体人脸有一定温度能够散发热辐射,但是照片、视频等假体人脸却不能散发此类信息.文献[70] 利用热红外图像进行活体人脸以及照片、视频类假体人脸的分类.文献[71-72] 利用了400 nm~1 000 nm 的多个波段图像来抽取反射特征区分活体人脸和照片攻击.
2) 光场相机
光场相机能够记录光在空间中的方向与位置等信息[106],文献[21,73-74] 利用光场相机拍摄光场照片用于人脸活体检测.原始的光场照片是由很多个小的微透镜图像组成的.随着焦距的不一样,微透镜图像表示不同的光分布.这些不同光分布的图像能够用于估计输入图像中深度的存在.文献[73] 利用LBP 从光场照片的两种可视化图像:微透镜图像和光场子孔径图像中抽取人脸边缘特征以及射线差异特征用于假体人脸与活体人脸的分类.
3) 深度摄像头
活体人脸有复杂的三维立体结构,照片、视频类假体人脸却是二维平面结构.深度摄像头拍摄的深度图像能够记录下物体间的深度信息,三维活体人脸和二维假体人脸结构的差异导致人脸离深度摄像头的深度信息会存在较大差异.文献[75-76] 利用Kinect 与可见光摄像头录制人脸深度图和可见光图像,继而从人脸可见光图像和深度图中抽取纹理特征以及人脸结构特征进行活体人脸和照片、视频类假体人脸的分类.活体的三维人脸结构有明显变化的表面曲率,但是二维的假体人脸却没有.文献[77]利用三维扫描仪获取待测对象的三维模型,通过分析待测对象的表面曲率来判断三维活体人脸和二维假体人脸.面具类假体人脸虽然也有三维立体结构,但是因为工艺原因,大部分面具类假体人脸的三维结构还是没有活体人脸精细.基于几何属性的三维形状分析能够很好地刻画人脸的表面结构与形状.常用的几何属性包括主曲率、高斯曲率、平均曲率及其方差.文献[78] 利用主曲率测量以及meshSIFT特征描述符从待测对象的三维人脸模型中抽取活体人脸和面具间的几何形状差异来进行活体人脸和面具假体人脸的分类.
基于其他硬件的方法利用的特征区分度大,假体人脸的类内差异对方法的影响较少,整体识别准确率高,但是其需要增加新的硬件,这不仅意味着新的昂贵的硬件投入,而且也意味着人脸识别系统的硬件改造,费时费力.新增硬件在一定程度上也会限制算法的使用范围,如智能手机之类的移动端人脸活体检测可能会因为新增其他摄像头不方便而舍弃这种解决方案.
2.2.5 基于深度特征的方法
早期的人脸活体检测算法一般抽取手工设计的特征,继而利用SVM、线性判别分析(Linear discriminant analysis,LDA) 等分类器训练分类模型进行活体人脸和假体人脸的分类.手工设计特征作为浅层特征,表达能力一般,不能有效表征活体人脸和假体人脸之间的差异.深度学习方法能够抽取高层语义的特征表达,近年来大大提升了人脸识别、物体分类等计算机视觉任务的性能.随着深度学习方法的发展,人们也逐渐利用深度学习的方法来处理人脸活体检测的问题.基于深度特征的人脸活体检测方法一般融合考虑了多方面的信息进行活体人脸与假体人脸的分类,如颜色纹理、图像质量、背景边框信息、时序变化信息等.针对深度学习技术,数据和网络模型训练至关重要,本节将从网络输入数据源和深度特征学习两个方面来分析基于深度特征的人脸活体检测方法.
1) 网络输入数据源
最初人们借鉴深度学习方法在其他领域的应用方法,使用端到端的深度学习方法进行活体人脸和假体人脸分类.文献[79] 利用5 个卷积层、5 个池化层、3 个全连接层组成的卷积神经网络从包含不同尺度背景信息的可见光RGB 人脸图像中抽取深度特征,并使用Softmax 进行活体人脸和假体人脸的预测.由于假体人脸的类内类间差异大以及假体人脸的造价昂贵导致的人脸活体检测数据集中个体数量少、数据总量少、数据间的多样性不如常规的人脸识别数据集丰富的问题,方法的识别准确性和跨数据集通用性仍有待提高.
为了提取区分度更大的特征,研究者们对传统的RGB 人脸图像进行各类处理,使得要利用的特征更加明显,之后再利用卷积神经网络抽取分类特征[80-82].文献[80] 将人脸图像从RGB 颜色空间转换成HSV,YCbCr 颜色空间并分割成小块,利用端到端的卷积神经网络从分割的小块图像中抽取特征进行分类.颜色空间转换让活体人脸和假体人脸的颜色纹理差异更明显.小块的分割一方面让卷积神经网络更专注于局部块的信息抽取,另一方面也从数据增强的角度提升了方法的性能.文献[81] 将非线性扩散[107]和卷积神经网络进行了结合.考虑到二维的假体人脸经非线性扩散后人脸五官的边界会退化而活体人脸则会保留边界信息,他们首先使用非线性扩散处理活体人脸和假体人脸图像,继而利用卷积神经网络从扩散后的图中抽取深度特征.文献[82] 采取类似rPPG 的思路,以心脏跳动会带来活体面部颜色的变化为差异线索,为图像中的每一个像素点进行频率分析,得到能够表征生命信息的相对高低能量值,之后利用卷积神经网络从人脸图像的这种能量表示图抽取分类特征进行分类.除了对RGB 图像进行各类处理,研究者们也综合利用了其他硬件设备录制的图像.文献[83] 利用卷积神经网络从常规的可见光人脸图像以及Kinect 录制的人脸深度图中抽取特征用于活体人脸和假体人脸分类.深度图中包含的人脸结构信息对于三维活体人脸和二维假体人脸的高区分性有利于提升算法的准确率与通用性.
2) 深度特征学习
深度学习的方法能否学习到有效而通用的特征很大程度上依赖数据量是否足够大,数据多样性是否丰富.人脸活体检测的小数据集问题导致基于深度学习的人脸活体检测方法容易陷入过拟合的困境.很多研究者们利用在其他数据更丰富的数据集上预训练深度神经网络模型的思路来解决过拟合的问题[84-87].文献[84] 首先在ImageNet 上预训练ResNet50 模型[108],利用得到的模型从连续多帧人脸图像中抽取空间深度特征,之后将抽取的特征送入长短期记忆网络(Long short-term memory,LSTM)[109]中抽取帧间的时序变化信息用于活体人脸和假体人脸的分类.LSTM 与卷积神经网络(Convolutional neural network,CNN) 的结合综合了双方从连续多帧人脸图像中抽取空间信息、时序信息的能力,利用预训练的残差网络模型减少了人脸活体检测数据集上过拟合的影响.文献[87]在MSU-MFSD(Michigan State University mobile face spoofing database)[45]数据集上通过大量实验对比了Inception-v3、ResNet50,ResNet152 用于人脸活体检测的性能.实验中考虑了模型的深度、微调预训练模型或者从头训练、不同学习速率等方面的对比因素.
除了利用预训练的模型外,研究者们也从训练方法方面进行了研究.文献[75-83] 利用深度卷积神经网络抽取特征,之后利用SVM 进行分类,在一定程度上可以降低过拟合的影响,提升算法性能.文献[88] 针对人脸活体检测数据集数据量少的问题,提出了一种训练策略提高算法的通用能力.常规的深度学习模型训练方法是将训练集随机化排序一次后划分小批量数据集用于训练,文献[88] 在模型的训练阶段每一次迭代都从整个训练集中随机地选取一个小批量数据用于训练,通过这种随机的选取小批量训练数据的方法减少过拟合的影响.一般的基于深度学习的人脸活体检测方法利用活体人脸和假体人脸的类别为标签,文献[89] 认为简单的类别标签包含的信息过于简单,研究者们利用活体人脸和假体人脸的深度信息图以及rPPG 信号为指导标签训练深度神经网络进行分类预测.深度信息图中蕴含了三维活体人脸和二维假体人脸的结构差异,rPPG 信号蕴含了活体人脸与假体人脸的生命信息差异,两种信息皆对活体人脸与假体人脸的区分度大.使用这两种信息明确地作为指导信息,有利于提升方法的通用性.假体人脸的种类多且类间差异大,为了减少类间差异对活体检测算法性能的影响,文献[90] 针对照片和视频类攻击分别训练对应类别的ResNet50 分类模型,然后利用堆栈泛化[110-111]的方法训练一个模型组合不同类别假体人脸的分类模型.单类假体人脸分类模型减少了不同假体人脸间的差异对分类性能的影响,使模型专注于某一类假体人脸的分类,有利于模型性能的提高.使用堆栈泛化组合模型一方面能够进一步提高分类准确率,另一方面也使得一个模型能够处理多种假体人脸,提升模型的通用性.
针对目前人脸活体检测算法跨数据集通用性不强的问题,文献[91] 引入领域自适应的方法进行活体人脸与假体人脸分类,提升深度模型的跨数据集通用性.文献[92] 将贪婪深层字典学习用到了人脸活体检测.一般基于深度学习的方法利用二维的卷积神经网络抽取图像层面的信息,并没有利用到连续多帧人脸活体检测图像中的时序信息.文献[93-94] 利用三维卷积神经网络[112]从连续多帧人脸图像中抽取时空深度特征,相对于基于二维卷积神经网络的人脸活体检测方法,增加了时间维度的差异信息,更有利于提高算法的识别性能与通用性.
很多研究者将深度学习的方法和手工设计特征的方法进行了融合[85,95-97],以结合两种方法的优点,减少过拟合的影响,提升算法性能.文献[95] 将神经网络、Shearlet、光流法进行了结合,设计了一个分层神经网络,融合学习图像质量以及运动信息用于人脸活体检测.他们首先利用Shearlet 抽取图像质量方面的特征,利用光流法从裁剪后的人脸以及包含背景的人脸图像中抽取光流幅度运动特征,然后将抽取的运动特征送入一个两层的神经网络中抽取分类特征进行分类.文献[85] 将CNN 与LBP结合起来,利用人脸活体检测数据集微调预训练好的VGG-face 模型[113],之后从微调的VGG-face 模型抽取的卷积特征图中抽取LBP 特征并送入SVM进行活体人脸和假体人脸的预测.文献[96]将CNN与LBP-TOP (Local binary patterns from three orthogonal planes)[114]结合起来,利用LBP-TOP从卷积特征图中抽取时空特征,在减少过拟合情况的发生的同时,为活体检测算法增加了时间维度的分类线索.文献[97] 将CNN 与光流法进行了结合,学习连续多帧人脸图像中的动态纹理信息.他们首先利用一个预训练的VGG (Visual geometry group) 网络从每一帧图像中抽取卷积特征图,然后利用光流法计算每一个卷积特征图的微运动特征,最后在通道可分辨性约束下,从所有卷积通道的微运动特征中提取深层卷积动态纹理特征并送入SVM 进行分类.文献[98] 将微纹理描述符与SSD(Single shot multibox detector)[115]结合,首先在人脸检测的过程中同时进行活体人脸和假体人脸的分类,然后对于SSD 给出的预测结果置信度高的人脸图像,取SSD 的预测结果,对于SSD 给出的预测结果置信度低的人脸图像,利用设计的微纹理描述符抽取纹理特征并送入SVM 进行分类,取得SVM的预测结果.利用深度学习方法与手工设计特征的方法组成的层级结构,融合了两类方法的判别能力提升活体人脸与假体人脸的识别性能.
总体来说,越来越多的研究者倾向于利用基于深度特征的人脸活体检测方法去解决人脸活体检测面临的问题.一些端到端的基于深度特征的方法相对于基于手工特征的方法实现起来更方便.基于深度特征的方法针对假体人脸个体以假乱真的高质量、类内类间差异、数据量少的问题从网络输入数据源和深度特征学习等方面做了相关研究,抽取的深度特征相对来说有效性和通用性较好,在公开数据集上,目前基于深度特征方法也取得了最好的性能,但是其模型参数多、训练时间长、计算量大,对数据量和数据丰富性上有较高要求.
2.2.6 混合特征类方法
基于单一差异线索进行活体人脸与假体人脸分类,可能会面临识别准确率以及算法通用性方面的瓶颈.为了提高人脸活体检测方法的性能,人们提出了融合多个差异线索进行人脸活体检测的方法,也就是混合特征类方法.常见的混合有纹理信息和运动生命信息的混合[17-19,25,85,93-94,97,99-101]、纹理信息和人脸结构信息的混合[76,80,83,98,102]、人脸结构信息与运动生命信息的混合[89]、图像质量与运动生命信息的混合[95]、背景信息[27]和其他特征的混合[79,81,84,87,93,98,100]等.照片、视频类假体人脸存在的边框等背景信息能够提供有效的分类线索,经常被融合利用到各类方法中.
为了利用时序上的微运动生命特征差异,文献[17-19] 利用LBP-TOP 从时空两个维度抽取动态纹理信息进行活体人脸与假体人脸的分类.LBP主要抽取空间上的局部纹理信息,LBP-TOP 从时间维度扩充了传统的LBP,从而可以抽取时空两方面的纹理信息.LBP-TOP 考虑了三个正交平面,即传统LBP 处理的xy平面、图像每一行沿时间轴形成的xt平面以及图像每一列沿时间轴形成的yt平面.三个平面以中心点正交.xy平面记录着空间纹理,xt平面、yt平面记录着动态纹理.计算每一个平面的LBP 特征,然后连接三个平面的LBP 特征形成LBP-TOP 特征.文献[17-19]考虑了不同长度的时间窗口,抽取LBP-TOP 动态纹理信息,继而利用以RBF 为内核的SVM 进行分类.类似于LBP-TOP,研究者们也从时间维度扩充了MLPQ (Multiscale local phase quantization) 为MLPQ-TOP,MLPQ (Multiscale local phase quantization) 为MBSIF-TOP,抽取动态纹理进行人脸活体检测[25].文献[99] 融合了深度神经网络抽取的深度纹理特征以及眨眼等运动生命信息.文献[76] 利用BSIF 描述符从图像全局以及眼睛等局部小块抽取了纹理和人脸结构造成的深度差异信息.
很多基于深度特征的人脸活体算法混合使用了多种分类特征[80,83,85,89,93-95,97-98].文献[98] 融合利用了颜色纹理信息、背景信息、人脸结构信息进行人脸活体检测.他们将人脸活体检测与人脸检测融合到一个步骤完成,利用上下文背景信息在给出人脸所在位置的矩形框时也进行活体人脸和假体人脸的判断.他们还设计了两个描述符:SPMT (Spatial pyramid coding micro-texture) 抽取微纹理方面特征,TFBD (Template face matched binocular depth) 抽取人脸结构方面的特征.将SPMT 和SSD 结合起来,对于SSD 预测结果置信度低的人脸图像抽取SPMT 特征并利用SVM 进行分类.除此之外,他们还将SPMT 与TFBD 结合起来,综合利用纹理与人脸结构方面的差异.从文献[98] 的实验结果可以看出,混合了各类特征的人脸活体检测算法有利于算法识别率的提升.
总的来说,混合特征类方法可以综合各类特征的优势,减少高质量假体人脸以及假体人脸的类内类间差异的影响,抽取高判别力的特征,提高算法的准确率和通用性,但是正因为其综合了多个不同的特征,算法实现和维护的成本增加,计算量也将增多,算法的处理时间相对会变长.
3 人脸活体检测数据集
数据集中数据的总量、数据类型的丰富程度、数据的采集设备、采集环境等都会影响人脸活体检测方法的性能.随着深度学习方法的发展,数据的重要性日益凸显.对于人脸活体检测,相关研究者们利用的分类特征多种多样,使用的数据集也都有自身的特点,从数据集的发展也能窥测出主流人脸活体检测方法使用的特征、防范的攻击类型、影响算法性能因素的处理等方面的发展.鉴于数据的重要性以及人脸活体检测数据集的多样性,本节对人脸活体检测方面的主流数据集分假体人脸类型进行阐述:照片视频类假体人脸活体检测数据集、面具类人脸活体检测数据集.综述的数据集大部分是公开数据集,少部分是不公开的数据集.在介绍不同的数据集时,主要从数据集的特点,数据集建设年份,数据集包含的活体人脸和假体人脸的个体数,图像大小,各类别样本数量,假体人脸类型,录制时考虑的光照、姿态、假体人脸材质等方面的影响因素等方面进行阐述,表2 对主流人脸活体检测数据集进行了总览对比分析.

表2 主流人脸活体检测数据集总览Table 2 Brief overview of face anti-spoofing datasets
3.1 照片视频类人脸活体检测数据集
3.1.1 可见光照片视频类人脸活体检测数据集
NUAA[116]数据集是第一个面向学术界免费公开的人脸活体检测数据集.NUAA 利用普通的网络摄像头在三个不同的环境下录制了15 个个体的活体人脸与照片类假体人脸的图像.为了让活体人脸与假体人脸更相似,录制过程中要求活体人脸做到人脸正向面对摄像头,保持自然表情,不出现眨眼、头部微运动等情况.制作的假体人脸一共有三种:6.8 cm×10.2 cm 与8.9 cm×12.7 cm 两种大小的照片纸上打印的彩色照片,普通A4 打印纸上打印的彩色照片.数据集录制了正面平展照片,同时还对照片弯曲、沿水平轴旋转、垂直轴旋转等情况进行了录制.
Yale-Recaptured[33]数据集为LCD 屏幕显示的照片类假体人脸录制了一批多种光照条件下的数据.Yale Face Database B[14]包含了1 个录制个体64 种不同光照条件下的活体人脸数据.Yale-Recaptured 数据集利用三种LCD 显示屏显示Yale Face Database B 中1 个个体64 种光照条件下的640 张人脸照片.整个数据集从假体人脸光照差异方面考验算法的有效性和通用性.
Print-Attack[117]数据集是瑞士Idiap 研究中心发布的关于打印照片类假体人脸的人脸活体检测数据集.Idiap 研究中心在人脸活体检测领域研究活跃,针对照片、视频、面具等不同类型的假体人脸发布了不同的数据集.Print-Attack 数据集在两种不同的光照条件下分别录制了手持照片、固定照片两种不同照片攻击模式的数据,其中照片是打印在A4打印纸上的彩色照片.
CASIA-MFSD[34]数据集为活体人脸和照片、视频类假体人脸录制了低、中、高三种不同质量的视频数据.假体人脸包括完整的彩色照片假体人脸,挖去颜色的彩色照片假体人脸以及视频类假体人脸.照片类假体人脸在录制的过程中也录制了正面平展照片以及弯曲照片的情况.根据收集的数据,CASIA-MFSD 从图像成像质量、假体人脸类型方面设计了7 种不同的测试协议用于验证人脸活体检测算法的性能.
Replay-Attack[16]数据集的录制方式类似于Print-Attack 数据集.相对于Print-Attack 数据集,假体人脸新增了iPhone 3GS 手机以及iPad 显示的视频类假体人脸.
MSU-MFSD[45]数据集考虑了人脸活体检测在移动端的应用场景,采用智能手机录制活体人脸和假体人脸的图像信息.采用佳能550D 单反相机以及iPhone 5S 后置摄像头拍摄高像素照片和视频作为假体人脸.视频类假体人脸采用了两种像素进行显示,iPad Air 显示的是2 048×1 536 像素的视频,iPhone 5S 显示的是1 136×640 像素的视频.打印类照片假体人脸以1 200×600 像素的分辨率打印在A3 纸上.相比于之前的数据集中的假体人脸,MSU-MFSD 的假体人脸质量更高.
UVAD(Unicamp video-attack data set)[31]数据集采用了6 种不同的摄像头拍摄人脸视频用做假体人脸录制数据,之后利用7 种不同的设备显示视频假体人脸用于攻击人脸识别系统.UVAD 从制作视频假体人脸的设备以及假体人脸的显示设备方面丰富了人脸活体检测数据集.
REPLAY-MOBILE[118]数据集同样考虑到智能移动设备如智能手机和平板电脑的发展,利用Nikon Coolpix P520 相机以及LG-g4 智能手机后置摄像头拍摄高分辨率照片或者视频作为假体人脸.考虑到人脸活体检测在移动端的应用,数据集的录制也采用IOS 和Android 智能移动设备进行数据录制.假体人脸的显示也尽量屏蔽镜面反光的影响,采用了哑光电子显示屏和纸张显示视频或者照片.为了验证方法的通用性,REPLAY-MOBILE 数据集录制了5 种不同的光照条件下的数据.
MSU-USSA[119]数据集也是一个模拟假体人脸攻击智能手机中的人脸识别系统的数据集.MSUUSSA 的采集过程中考虑了背景环境、图像质量、图像采集设备、个体方面的多样性.MSU-USSA 从Weakly labeled face 数据集选取了100 个个体的图像用于数据集的录制,从个体、个体所在背景环境方面增加了人脸活体检测数据集的多样性.100 个活体人脸图像来自于互联网,所以其拍摄设备多种多样,从图像采集设备方面丰富了数据集.假体人脸类似于其他数据集,采用笔记本、平板电脑、智能手机、哑光照片纸显示.MSU-USSA 利用Google Nexus 5 的前置摄像头与后置摄像头为假体人脸拍摄两种不同分辨率的图像,从图形质量、假体类别、假体质量方面丰富了数据集.
Oulu-NPU[120]数据集在3 个不同光照不同背景的场景下利用6 种移动设备的前置摄像头录制了活体人脸和假体人脸的图像信息.打印照片类假体人脸由两个不同的打印机彩色打印而成.视频类假体人脸由两种不同的显示设备显示.Oulu-NPU 数据集录制过程中考虑了更多的变化因素用于验证人脸活体检测方法的有效性和通用性.
SiW[89]收集了165 个个体的活体人脸与假体人脸图像信息.活体人脸在录制的时候考虑了人脸与摄像头的距离、姿态、表情、光照方面的变化.打印照片类假体人脸考虑了高分辨率和低分辨率两种照片.视频类假体人脸采用了平板电脑、苹果手机、PC 机显示器、三星手机四种不同的设备显示.SiW 数据集在个体数以及活体人脸的变化方面增加了数据集的丰富性.
3.1.2 基于其他硬件的照片视频类人脸活体检测数据集
GUC-LiFFAD[21]数据集是一个利用光场相机录制了不同焦距的光场图像的数据集,为利用光场图像差异的人脸活体检测算法提供数据支持.数据集利用喷墨打印机、激光打印机、第四代iPad 平板电脑制作了高质量的打印照片与显示的电子照片.数据集收集了80 个不同个体的活体人脸和假体人脸数据,个体差异方面相对来说更丰富.
Msspoof[121]数据集录制了活体人脸和照片类假体人脸的可见光与近红外光谱图像数据.数据集使用的近红外波段是800 nm.对于活体人脸,Msspoof 数据集在7 个不同的环境下录制了5 张可见光与5 张近红外光谱图像.对于假体人脸,Msspoof 数据集从之前录制的活体人脸的5 张可见光与5 张近红外光谱图像选取了看起来成像比较好的3 张可见光与3 张近红外光谱图像用于制造假体人脸.选取出来的6 张图像均被打印成黑白照片.Msspoof 数据集分别为这6 张照片录制了三种不同光照条件下的可见光与近红外光谱图像.
EMSPAD (Extended multispectral presentation attack face database)[122]数据集利用多光谱摄像头录制了425 nm,475 nm,525 nm,570 nm,625 nm,680 nm,930 nm 7 个波段的图像.数据集录制的过程中考虑了距离的影响,选取了1.52 m 的录制对象与摄像头间距,以便能够收集高质量的多光谱图像.
3.2 面具类人脸活体检测数据集
3DMAD[37]是最早录制的三维人脸面具类假体人脸数据的人脸活体检测数据集.数据集使用的面具是由ThatsMyFace.com 根据用户的一张正面人脸图像以及两张侧面人脸图像定制的三维塑料面具.考虑到假体人脸与活体人脸三维结构方面的差异,3DMAD 数据集不仅利用可见光摄像头录制了活体人脸与假体人脸的可见光图像,还利用了微软Kinect 深度摄像头录制活体人脸与假体人脸的深度图像信息.
HKBU-MARsV2 (HKBU mask attack with real world variations dataset version 2)[123]数据集也是一个三维人脸面具类假体人脸数据集.相比较于3DMAD,HKBU-MARsV2 在假体人脸质量、录制数据的摄像头、外界光照条件等方面增加了数据多样性.假体人脸方面,数据集选取了两个公司的假体人脸:ThatsMyFace 制作的脸部表观质量稍低的三维面具以及Real-F 制作的脸部表观质量高的三维人脸面具.录制数据的摄像头方面,数据集考虑了传统人脸识别系统以及智能移动设备上人脸活体检测的应用,选取了3 种传统摄像头以及4 种移动设备的摄像头录制活体人脸和假体人脸的数据.光照方面,数据集设计了6 种不同的室内光照环境用于数据录制.
SMAD (Silicone mask attack)[92]数据集是一个为活体人脸以及三维硅胶人脸面具录制了图像信息的数据集.硅胶人脸面具能更好地与人脸的眼睛、鼻子、嘴巴部位贴合,戴起来看起来更加真实.硅胶人脸面具更接近现实应用中不法分子可能会使用的面具,从这个角度上看,SMAD 数据集更贴近现实情况.数据集在录制的过程中也考虑了不同的外界光照、背景等外界影响条件.
MLFP(Multispectral latex mask based video face presentation attack)[124]数据集在可见光、近红外、热红外光谱下录制了多光谱的活体人脸和面具假体人脸数据.面具假体人脸使用了挖去眼部区域的二维照片以及三维的乳胶人脸面具.录制过程中选取了不同时段、室内室外不同地方的多个场景录制数据,在外界环境方面丰富了数据集.
从表2 中可以看出,早期人们关注照片视频类假体人脸的处理,逐渐发展为也关注面具类假体人脸的处理.早期人们关注PC 端人脸活体检测,逐渐发展为关注PC 端以及移动端的人脸活体检测,利用网络摄像头以及移动端多元化摄像头捕获人脸图像.人脸识别、物体分类等其他领域的大规模数据集多是从网络上收集不同人、不同摄像头、不同环境下拍摄的图像,而目前人脸活体检测的数据集都是约束状态下人工录制的,其数据集个体数、数据多样性远远不及人脸识别、物体分类等其他领域的数据集.
4 算法性能比较
4.1 性能评价指标
人脸活体检测算法的性能主要从单数据集测试以及跨数据集测试两方面进行衡量.单数据集测试是指训练集和测试集同属于一个数据集时算法的性能.跨数据集测试是指训练集和测试集不是同一个数据集时算法的性能.人脸活体检测算法的性能评价同时考虑活体人脸与假体人脸的识别率.常用的性能评价指标主要有两大类:一类是错误接受率(False acceptance rate,FAR)、错误拒绝率(False rejection rate,FRR)、等错误率(Equal error rate,EER) 以及半错误率(Half total error rate,HTER) 指标[16];另一类是生物识别防假体攻击方面的标准文件ISO/IEC 30107-3[125]提出的APCER (Attack presentation classification error rate)、BPCER (Bona fide presentation classification error rate)以及ACER(Average classification error rate) 指标.
错误接受率(FAR) 指算法把假体人脸判断成活体人脸的比率.错误拒绝率(FRR) 指算法把活体人脸判断成假体人脸的比率.FAR 与FRR 的定义如式(1) 和式(2) 所示,其中Ns2l表示假体人脸判断为活体人脸的次数,Ns表示假体人脸攻击总次数,Nl2s表示活体人脸判断为假体人脸的次数,Nl表示活体人脸检测总次数.不同的阈值可以得到不同的FRR 以及FAR 对,分别以FRR、FAR 为横轴与纵轴,即可绘制ROC (Receiver operating characteristic curve) 曲线.利用开发集数据进行测试得到的ROC 曲线上FRR 等于FAR 时,FRR 与FAR 的均值即为等错误率(EER).以开发集上FRR 等于FAR 时的阈值为测试集上的阈值计算测试集FRR与FAR 的均值,即为半错误率(HTER).

APCER (Attack presentation classification error rate) 指假体人脸分类错误率.BPCER (Bona fide presentation classification error rate) 指活体人脸分类错误率.ACER(Average classification error rate) 指平均分类错误率,其定义如式(3)~(5)所示.

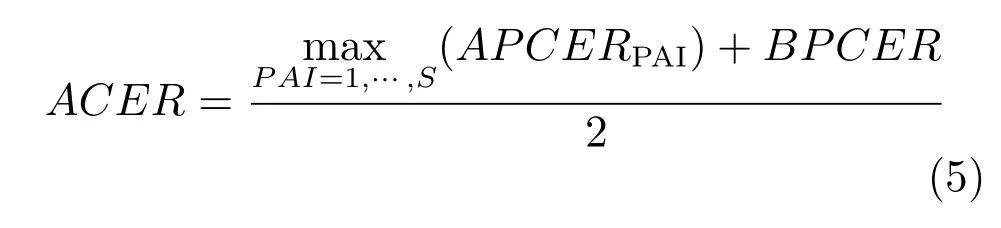
其中,NPAI是某一类别假体总的攻击次数.NBF是指活体人脸检测次数.若第i次检测判断为假体人脸则Resi置为1,若判断为活体人脸则置为0.APCER 与BPCER 与第一类评价指标中的FAR与FRR 类似,但是FAR 和FRR 把所有类别的假体人脸混合在一起计算性能,APCERPAI是为每一种类别的假体人脸计算APCER,如照片类假体人脸、视频类假体人脸,最后活体检测算法总的APCER是所有类别假体人脸中最大的APCERPAI,也就是说识别率最差的那类假体人脸.EER 是指开发集上APCER 与BPCER 相等时APCER 与BPCER的均值.ACER 是以等错误率对应的阈值为测试集的阈值计算的APCER 与BPCER 的均值.
单数据集的测试能够在一定程度上反映算法的性能,但文献[126] 通过实验验证了很多在单数据集上性能优良的算法,在其他数据集上测试时,性能会急剧下降,算法的通用性不强.为了验证算法的通用性,研究者们提出了跨数据集测试的方法:以一个数据集的数据为训练集训练活体检测算法模型,以另一个数据集的数据为测试集测试活体检测算法模型的性能.目前大部分的跨数据集测试还都是集中在同类别假体人脸跨数据集测试的形式,对于跨数据集、跨假体人脸类别的测试还比较少.这也从侧面反映出目前人脸活体检测算法的通用性还有待提高.
4.2 主流算法性能比较
照片视频类数据集CASIA-MFSD、Replay-Attack、Oulu-NPU、SiW 以及面具类数据集3DMAD、SMAD、HKBU-MARsV2 是目前比较常用的基准数据集.表3~8 以文献发表的年份为顺序总结了代表性的人脸活体检测方法在CASIA-MFSD、Replay-Attack、Oulu-NPU、SiW、3DMAD、SMAD、HKBU-MARsV2 上报道的单数据集以及跨数据集测试性能数据.为了比较的公平性,表3~7 中总结的方法在每个数据集上使用的是相同的官方给出的评价协议.3DMAD、SMAD、HKBU-MARsV2 面具类数据集中的个体数比较少,方法性能的评价通常采用交叉验证.

表3 CASIA-MFSD 与Replay-Attack 数据集单数据集测试性能数据(%)Table 3 The performance of intra-test on CASIA-MFSD and Replay-Attack datasets (%)

表4 Oulu 数据集单数据集测试性能数据(%)Table 4 The performance of intra-test on Oulu dataset (%)

表5 SiW 数据集单数据集测试性能数据(%)Table 5 The performance of intra-test on SiW dataset (%)
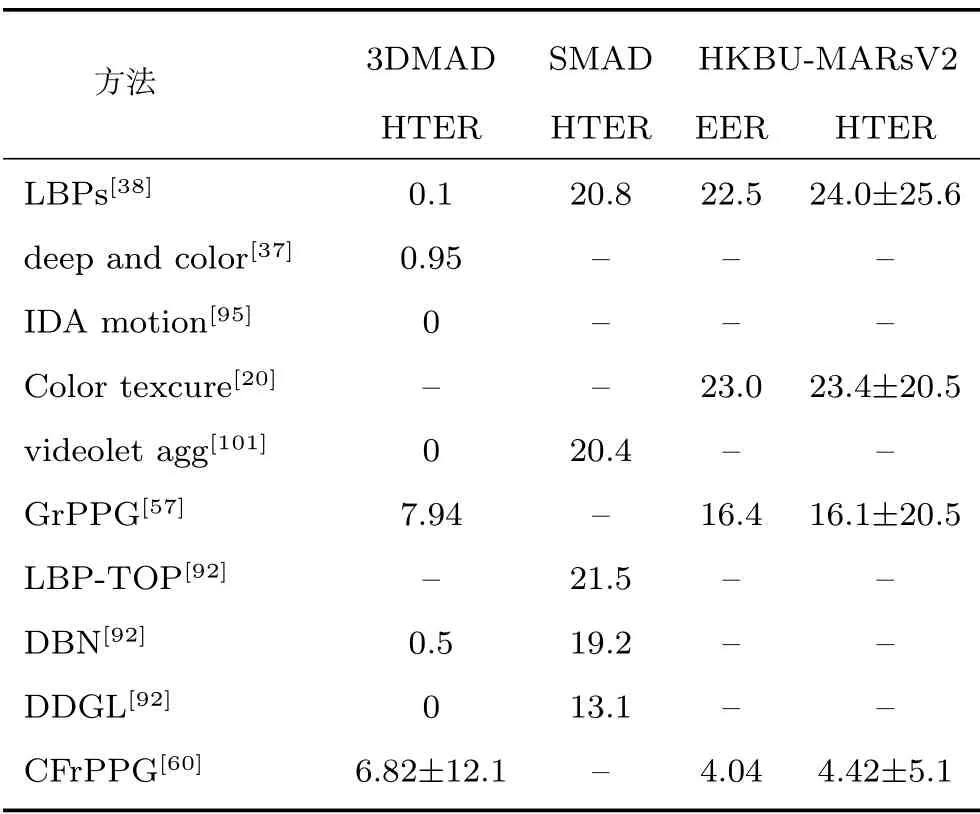
表6 3DMAD、SMAD 与HKBU-MARsV2 数据集单数据集测试性能数据(%)Table 6 The performance of intra-test on 3DMAD,SMAD and HKBU-MARsV2 datasets (%)

表7 CASIA-MFSD 与Replay-Attack 数据集间跨数据集测试性能数据HTER (%)Table 7 The performance of inter-test between CASIA-MFSD and Replay-Attack (%)
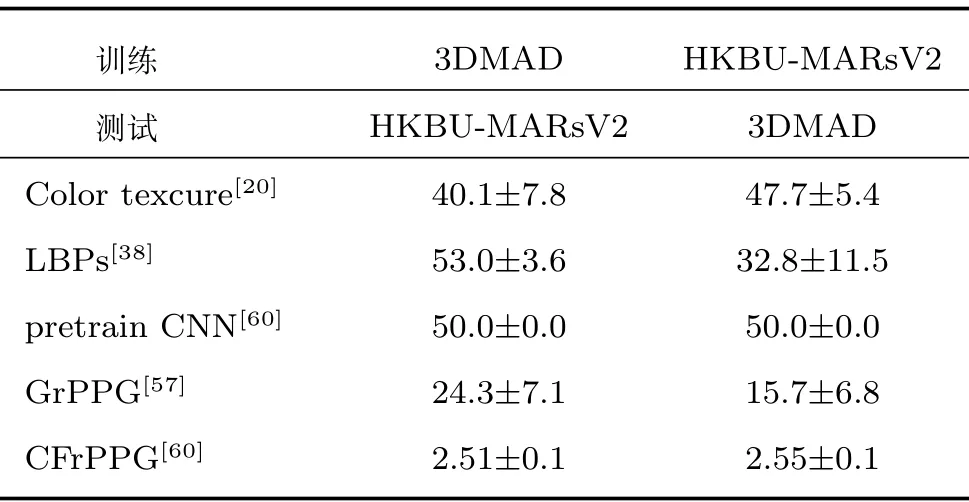
表8 3DMAD 与HKBU-MARsV2 数据集间跨数据集测试性能数据HTER (%)Table 8 The performance of inter-test between 3DMAD and HKBU-MARsV2 (%)
表6 中3DMAD 数据集上的不同方法在进行交叉验证时训练集与测试集的数据比例稍有差异.表6中SMAD 与HKBU-MARsV2 数据集上的方法分别采用文献[92] 和文献[60] 中的测试协议.表8 中3DMAD 与HKBU-MARsV2 数据集间跨数据集测试采用文献[60] 中的测试协议.从表3 中可以看出,许多方法在Replay-Attack 数据集上性能较好,但是在CASIA-MFSD 数据集上却不能得到类似Replay-Attack 数据集上的性能.CASIA-MFSD、Replay-Attack 的假体人脸类别都是照片类假体人脸和视频类假体人脸.这种性能差异也表明假体人脸类内差异大,对算法的性能有较大影响.随着深度学习方法的应用,同一种人脸活体检测方法抽取的特征更加通用,两个数据集间的性能差异逐渐减少.从表4 Oulu-NPU 数据集上的性能测试数据中可以看出,协议4 的指标值明显高于其他三个协议,这表明不同的数据集录制设备造成的类内差异对于方法的性能影响较大.表7 和表8 列出的皆是同类别假体人脸数据集间的跨数据集测试性能数据,较高的半错误率也告诉我们类内差异对人脸活体检测方法性能有较大影响.人脸活体检测方法的通用性仍有很大的提升空间.
图5 针对表3 与表7 中人脸活体检测方法的EER 或HTER 性能数据分类别进行了展示.从图5中可以大致看出,目前常见的各类方法的性能发展水平.相对于其他类别的方法,基于纹理的方法、基于深度特征的方法、混合特征类方法的研究相对较多.无论是单数据集测试还是跨数据集测试,基于深度特征的方法以及混合特征类方法的性能是最好的.我们相信这两类方法的研究也将是未来的发展趋势.

图5 各类人脸活体检测方法性能分布图Fig.5 Performance comparison of different category of face anti-spoofing methods
5 未来可能的发展方向
人脸活体检测方法的研究已经取得了一系列的进展,研究重心从交互式人脸活体检测方法逐渐转移到非交互式人脸活体检测方法,从手工设计特征的方法逐渐转移到基于深度学习的方法,从基于可见光图像的方法也逐渐发展为基于多元化图像的方法.从目前人脸活体检测方法的不足以及人脸活体检测业务的发展需要来看,人脸活体检测研究未来可能的发展方向主要有以下几个方面.
5.1 面具类假体人脸的识别
照片、视频类假体人脸制作起来方便简单,也是最常见的假体人脸,目前大部分的活体检测方法主要防范照片、视频类假体人脸的攻击.而目前针对面具类假体人脸的活体检测方法研究还不是很多.三维人脸面具的制造工艺复杂、成本高,但是三维人脸面具相对于二维的照片、视频类假体人脸,无论从颜色纹理还是人脸结构上都与活体人脸更为相似.常规的基于颜色纹理、图像质量、微运动、人脸结构等方面分类线索的方法处理面具类假体人脸的时候,性能都会大打折扣.对于智能安防、通关安检类的公共场合,不法分子一般不会选择使用照片、视频攻击人脸识别系统,而是更倾向于使用面具进行伪装来攻击人脸识别系统.因此,研究如何有效地分辨活体人脸和面具类假体人脸对于人脸活体检测多场景的实际应用具有重要意义.
5.2 通用性问题研究
目前活体检测方法抽取的特征泛化能力不强,算法也不能很好地处理与训练数据不是同一个数据集的测试数据,无论是训练集中见过的假体人脸类别还是训练集中没有见过的假体人脸类别.究其原因是假体人脸的类内类间差异大.不同的假体人脸制造工艺,不同的数据集录制设备,不同的外界环境都会影响算法的性能.这些差异信息是人脸活体检测应用环境中确切存在的,也是人脸活体检测算法实际应用中无法回避的问题.如何提取泛化能力强的特征,灵活应对这些现实差异,提高活体检测算法单类别假体人脸的跨数据集通用性以及跨假体人脸类别、跨数据集的通用性都是值得研究的问题.
5.3 未见过假体人脸的自适应处理
目前主流的人脸活体检测算法都是观察活体人脸和假体人脸的分类线索,抽取分类特征,之后利用分类模型进行活体人脸与假体人脸的分类.大部分方法只对训练数据中见过的假体人脸有效.对于训练数据中没有见过的假体人脸,其性能则会下降.然而对于人类来说,即使之前只见过照片类假体人脸,第一次见到面具类假体人脸的时候也可以判断出面具类假体人脸不是活体人脸.人类大脑可能掌握了活体人脸的一些本质属性,对于未见过的假体人脸类别能够自适应识别.人类的智慧是无穷的,人脸活体检测的研究者们难以完全预测他人即将制造出什么样式的新的假体人脸.对于新出现的假体人脸,类似于打补丁似的完善活体检测方法则永远会慢人一步,给不法分子留下攻破人脸识别系统的机会.研究类似于人类大脑,对于未见过的新型假体人脸快速自适应识别的人脸活体检测算法具有重要的价值.
5.4 更大更全面数据集的建立
从十元左右制造成本的照片纸打印的彩色照片到成本上万的定制人脸面具,各类假体人脸的高成本使得人脸活体检测的数据集基本都存在个体少、样本少、数据的多样性不够丰富的问题.目前大部分常见的活体检测数据集要么是专门针对照片、视频类二维假体人脸的,要么是专门针对面具类三维假体人脸.数据集中包含的假体类别比较单一.计算机视觉领域的人脸识别、物体识别等子领域的数据集都远比人脸活体检测的数据集数据量大、数据多样性更丰富.随着深度学习方法的发展,数据在算法研究中的地位越来越重要.数据量大、数据多样性更丰富有利于基于深度学习的方法能够抽取有效而通用的分类特征.如何集结资源,以最少的成本建立一个数据量更大、个体数更多、假体人脸类型更全面,影响算法性能的姿态、表情、光照、录制设备等因素更多的数据集是值得思考和挑战的问题.
目前大部分的人脸活体检测数据集都是约束状态下,如正面人脸、自然表情录制的,而非约束条件下人脸活体检测研究需要的非约束状态下的活体人脸和假体人脸数据集也急需建立.
5.5 适应人脸活体检测的深度学习方法研究
深度学习方法的使用让人脸活体检测算法的性能有了一定的提升,但是人脸活体检测数据集的问题导致深度学习方法在人脸活体检测领域使用的过程中经常会出现过拟合,抽取的特征通用性不够强的问题.目前人们提出了微调在其他大数据集上预训练的模型,设计特定的训练方法,深度特征与手工特征融合等方法来减少过拟合问题的影响,提高基于深度学习方法的准确率和通用性.根据现有的数据现状,研究适合人脸活体检测的深度学习方法是一个重要的研究方向.
5.6 非约束状态下的人脸活体检测研究
目前人脸活体检测研究集中在约束状态下的人脸活体检测.交互式人脸活体检测方法要求用户在指定距离内按照提示完成指定交互动作.目前主流的非交互式人脸活体检测方法虽然不需要用户交互,但是检测的整个过程基本要求人脸是正面脸,脸部不出现表情变化、姿态变化,人脸在规定距离内以便能够采集到足够好的待分析图像.约束状态下的人脸活体检测只能在特定的业务场景中使用,比如手机解锁、用户登录之类的用户能够处于约束状态的场景,应用范围窄,不能满足视频监控人脸活体检测之类用户处于自然状态的应用场景的需求.研究用户处于自然状态,可能存在姿态变化、部分遮挡、光照变化等影响的情况下的有效人脸活体检测方法具有非常重要的意义.有效而鲁棒的非约束状态下的人脸活体检测方法更有利于人脸活体检测方法大规模的实际应用,提高人脸识别技术的安全性.
6 结论
人脸活体检测在生物识别研究中具有重要的学术价值与实际应用价值.目前人脸活体检测的研究活跃,但同时也存在不少困难与挑战.本文从假体人脸的特性出发,分析了目前人脸活体检测的难点,以人脸活体检测算法利用的分类特征为主线,详细阐述了人脸活体检测领域的主流算法,探讨了各类方法主要利用的特征、防范的假体人脸类型、优缺点,就领域内常用的各个数据集的特点、数据量、数据多样性等方面进行了对比分析,阐述了常用的算法性能评价指标并总结分析了代表性人脸活体检测方法在照片视频类数据集CASIAMFSD、Replay-Attack、Oulu-NPU、SiW 以及面具类数据集3DMAD、SMAD、HKBU-MARsV2 上的性能数据.以此为基础,本文对人脸活体检测未来可能的研究方向进行了分析与展望.我们相信人脸活体检测所面临的问题必将能在理论上与实践上得到更好的解决,人脸活体检测的应用也将推动人脸识别技术、生物识别技术更广泛、更深入的应用.
猜你喜欢
疯狂英语·新读写(2023年1期)2023-04-06
基层中医药(2022年1期)2022-07-22
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
肝博士(2021年1期)2021-03-29
华人时刊(2020年21期)2021-01-14
保健医苑(2020年1期)2020-07-27
动漫星空(2018年9期)2018-10-26
中华骨与关节外科杂志(2016年6期)2016-05-17
百科探秘·航空航天(2015年10期)2015-11-07
