
基于机器学习的气象网络数据安全研究
2021-09-28 10:16:30何恒宏韩春阳
计算机技术与发展 2021年9期
钟 磊,何恒宏,韩春阳,李 楠
(国家气象信息中心,北京 100081)
0 引 言
随着气象信息网络的快速发展,气象行业面临的信息安全威胁不断增加。通过对近三年国家级信息网络安全事件进行统计,各类APT(advanced persistent threat,高级可持续威胁攻击)和利用漏洞的渗透事件数量的年增长率均超过30%。安全事件不断增加的原因主要有以下三个方面:第一,业务系统在设计过程中没有将信息安全充分纳入考量,造成系统上线后暴露的安全问题难以彻底解决;第二,部分人员安全意识不足,在使用过程存在不安全操作;第三,安全监控和防护能力不足,无法做到所有终端数据流量的实时检测和分析。
近年来,机器学习的有关算法在网络空间安全方面取得了一些研究成果,有关技术也在不同行业进行了实践[1],以机器学习为基础的态势感知系统和以流量回溯为代表的分析系统能够及时发现正在进行的网络攻击,但对已存在的安全问题难以提供解决方案[2]。
现阶段国家级气象网络的安全防护存在一定不足:第一,各类安全监控系统和检测设备主要部署于互联网出口;第二,对内部网络的终端安全防护和检测手段相对较少,仅能通过探针等设备获取局域网内部分系统间数据交互的信息,当终端设备出现异常时,无法第一时间进行定位和溯源;第三,气象业务数据交互频繁,探针获取的有关日志信息数量较为庞大,传统的巡检方式无法高效地发现有关异常,亟待对日志信息进行筛选过滤。
文中以国家级业务数据交互的日志信息为基础,通过机器学习的有关算法还原出现异常终端的网络数据交互的拓扑,确定有关异常设备的位置和可能近一步受到影响的系统;再以有关系统的IP为检索条件,对有关日志信息进行过滤,通过训练有关模型对日志的核心信息进行提取,有利于深入分析异常终端的问题根源。以上述研究为基础,确定下一步的问题处理方案,从而在一定程度弥补原有安全防护体系结构的不足,对提高业务网络中各系统的安全性和可靠性有一定的帮助。
1 算法与设计
1.1 Louvain算法原理
Louvain算法是一种基于多层次优化的算法,具有快速、准确的特点,被认为是性能最好的网络或图的发现算法之一[3-4]。Louvain算法中的Modularity函数是衡量发现算法结果质量的重要参数,能够刻画发现网络的紧密程度,Modularity函数的定义如下:
(1)
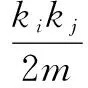
(2)
当ci=cj时节点i和节点j之间存在网络连接,此时函数的值为1,当ci≠cj时函数的值为0。
参数ΔQ为模块性改变量,其公式定义如下:
(3)
对以上公式化简可得如下结果:
(4)
当每次聚类完成时,都需要重新计算公式中的ΔQ,当Q的值不再变化,说明所有的顶点都被分组成了一个巨型聚类或者已有的类无法进一步合并,此时计算停止,输出此时的分组信息和Q的数值[4-5]。
1.2 Louvain算法应用设计
本次研究中,原始数据信息由序号、时间、日志类型、源IP、源端口、目的IP、目的端口和数据流量等几个部分组成。序号为事件信息编号,时间为采集事件的具体时间,日志类型为采集的传输形式,源IP、源端口、目的IP、目的端口是具体传输和接收设备信息,数据流量是本次源IP和目的IP数据交互的数据总量。本次研究数据为14天内不同系统相同时次的数据交互信息,本次算法中主要采用源IP、目的IP、源端口、数据流量为研究对象,算法具体步骤如下:
(1)对原始数据进行清洗,去除暂不使用的部分。研究中设定目的IP在恶意地址库中或单次源IP和目的IP交互数据流量超过30 GB视为高危行为,源端口和目的端口使用存在风险的端口则视为异常行为[6-8]。
(2)将原数据转换为N阶矩阵A,当源IP和目的IP有数据交互时,对应的aij为1,否则aij为0[9]。
(3)初始分配每个顶点到其自己的团体,随后计算整个网络的模块性Q。
(4)当每个点对至少被一条单边链接,如果有两个点融合到一起,则计算由此造成的模块性改变ΔQ。
(5)取ΔQ出现最大增长的改变量,然后融合。再为这个聚类计算新的模块性Q,并记录下来。
(6)当所有的顶点都被分组成一个巨型聚类或者被分成的类之间已无任何关系时,整个计算过程结束。随后检查这个过程中的记录,找到其中返回最高的聚类模式和此时的最大值Q。
(7)统计各系统与其他业务的链接情况,形成汇总表。
(8)将研究结果与已知恶意IP、高风险端口列表进行对比,当具体业务访问恶意IP或流量异常时,则相关终端标记为红色;当源IP通信端口为高风险端口,则相应终端标记为蓝色;其余正常终端标记为绿色。
(9)根据步骤(7)和步骤(8)的结果生成最终数据交互图。
1.3 TF-IDF算法原理
TF-IDF(term frequency-inverse document frequency,词频-逆向文件频率)算法是一种用于检索与探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一个字词在一个文件集或一组文字库中的重要程度[10]。字词的重要性一般随着它在文件中出现的次数成正比,同时随着它在语义库中出现的频率成反比。对于某一特定词语的逆向文件频率,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到最终结果。
TF-IDF的基本原理是当某个词或短语在一段文字中出现的频率较高,并且在其他文章中很少出现,那么就认为这个词或短语具有很好的类别区分能力,适合用来做分类[11]。IDF的主要思想是当包含词条t的文档越少,权重越小,当IDF变大时说明词条t具有很好的类别区分能力。实际的文字信息中,当一个词条在一个类的文档中频繁出现,说明该词条能够很好地代表这个类的文本的特征,这样的词条将被赋予较高的权重,可作为该类文本的特征词以区别于其他类文档[12-14]。在算法方面,TF-IDF算法采取如下方式进行计算:
首先,对于特定的词语ti,其在文本中的重要性可以表示为:
(5)
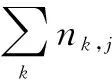
然后,逆向文件频率idfi可由公式(6)计算取得:
(6)
其中,|D|为文件中文字的总数,|{j:ti∈dj}|为包含ti的文件数目。
最后,计算最终结果tfidfi,j,由公式(7)求得最终结果。
tfidfi,j=tfi,j×idfi
(7)
1.4 TF-IDF算法应用设计
本次研究中,采用anaconda作为集成开发环境,jieba作为中文分词工具,TfidfVectorizer作为词频逆文档频率向量化模型,Logistic回归分析作为权重调节的参考依据[15]。
在算法方面,算法和应用的步骤如下:
(1)采集原有各系统同时段的日志信息。
(2)使用jieba作为中文分词工具,对监控信息做分词处理。
(3)采用TF-IDF算法进行判断[16]。
(4)通过Logistic回归分析对权重进行调节[17]。
(5)重复步骤3和步骤4中的过程。
(6)分别用90%的数据进行训练,10%的数据进行验证。
(7)用训练结果对日志信息进行分析验证,对有关结果进行分析。
2 实验结果与分析
2.1 终端数据交互研究结果与分析
研究中采用1.2节的设计并进行实验验证,基于某气象业务系统的部分实验结果如图1所示。
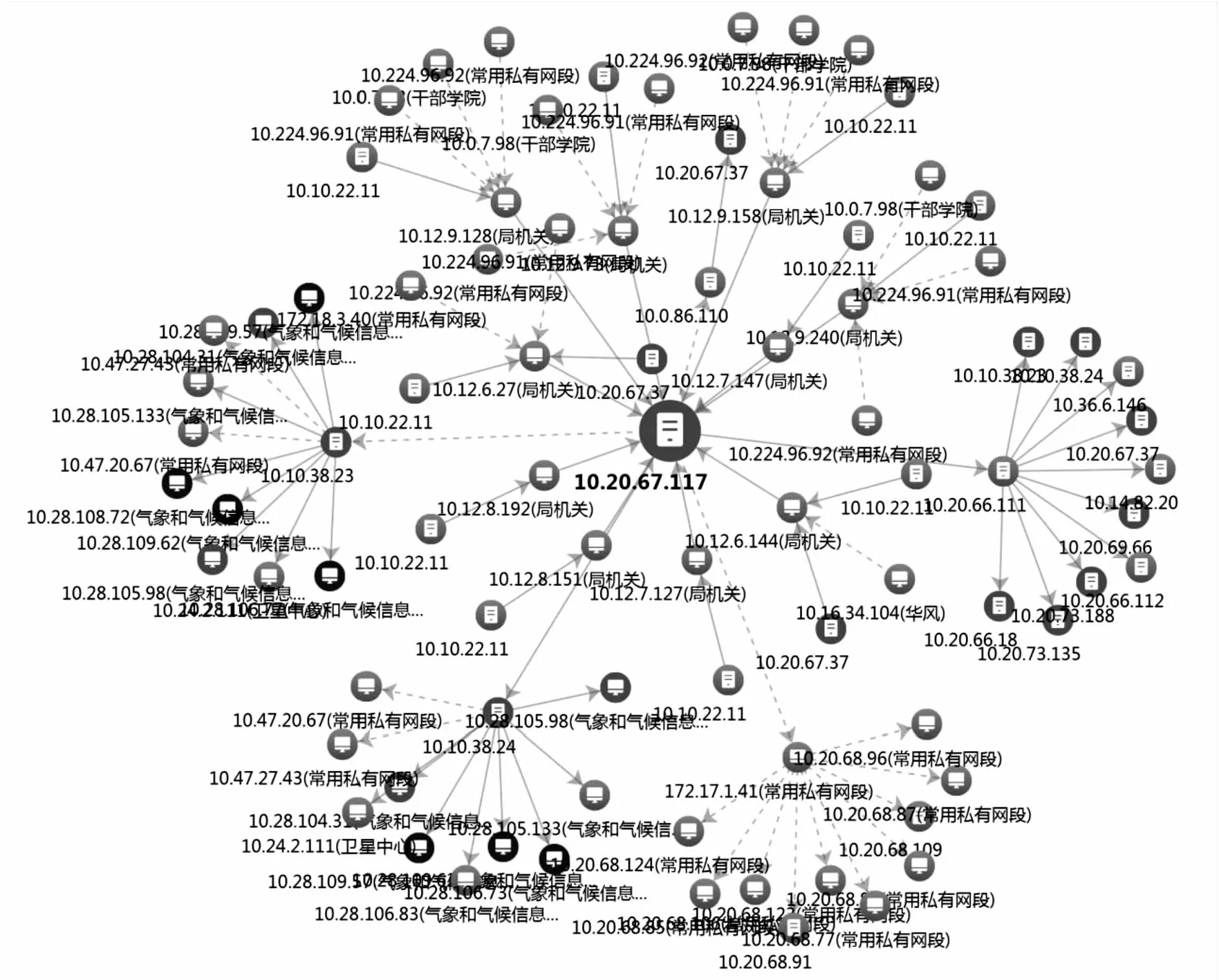
图1 数据业务交互实验结果
由实验结果可知,和该业务存在数据交互的系统中有7台终端存在高危异常,与其进行通信的网络结构能够清晰地进行表示,对于及时发现安全问题有很好的帮助作用。通过对其中存在高危的终端,以该终端的IP作为过滤条件生成对应数据交互拓扑,某高危异常终端的数据交互如图2所示。通过图2可以清晰地发现其他存在安全风险的主机,分析该IP的终端日志等可以逐步进行溯源,确定风险来源,同时消除对应风险。

图2 基于Louvain算法生成的某高危终端数据交互图
2.2 告警信息数据分析结果与分析
本次实验中,以90%的原始数据进行训练,10%的数据进行验证,部分训练结果如图3所示。由于标题重要性较高,因此不做任何分词处理,日志详细内容中能够提取到关键短句“WannaCry攻击”、445端口攻击“”,地址信息中提取到关键词语“10.28.107.*”,同时给出有关分词提取的可信度数值。由于日志告警形式较为统一,当重复出现告警并经过大量训练后,相关告警的可信性得到增加,可信度数值有一定的提高[18]。对该高危IP地址主机的行为进行分析和梳理后的结果进行汇总后,可得到如图4所示的行为画像[19]。
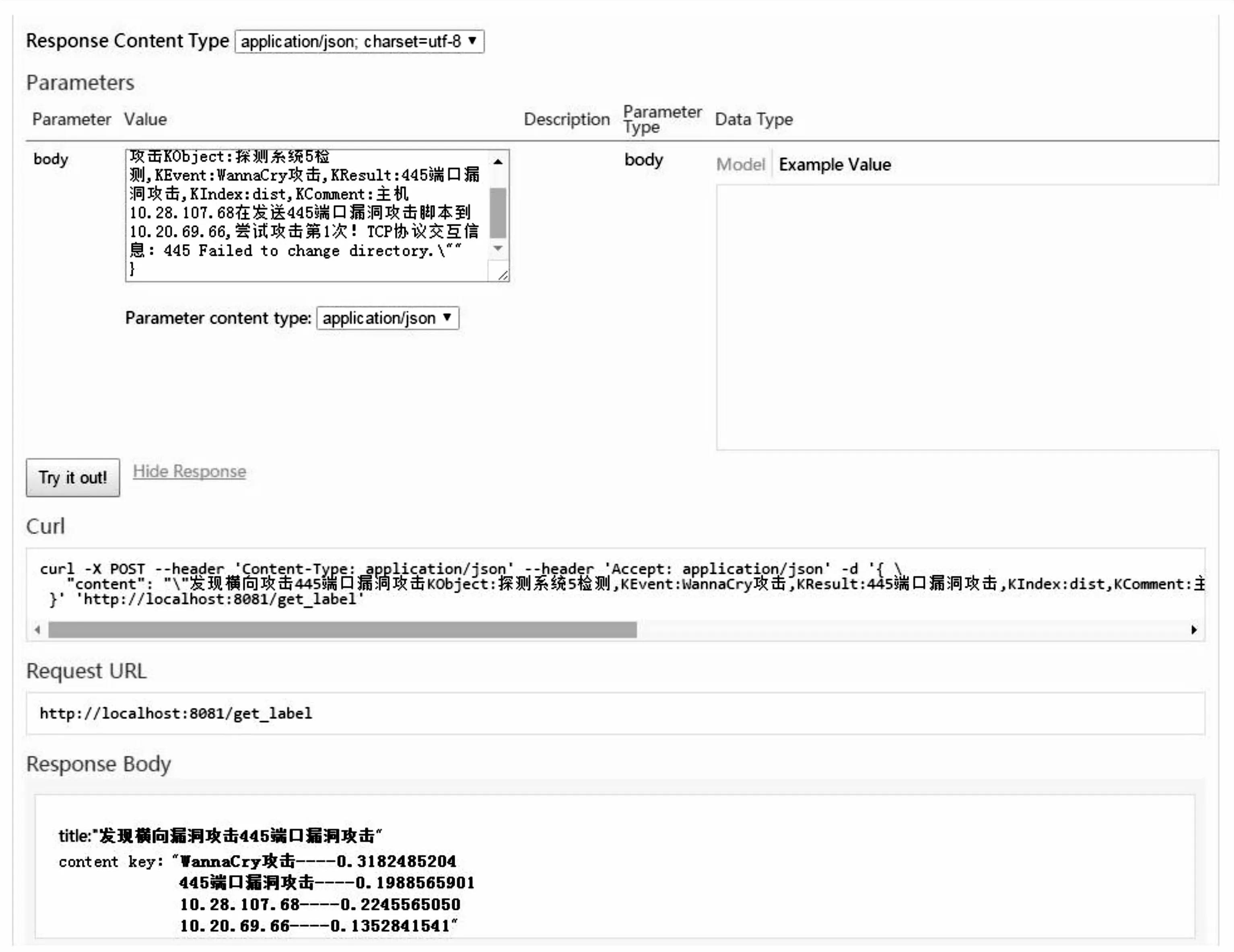
图3 训练结果示意图

图4 某高危用户网络行为画像分析图
在通过Louvain算法进行拓扑生成和告警信息关键信息提取后可知,图4中的终端因未及时修补MS17-010漏洞同时未关闭445端口而被其他被控主机攻陷,攻陷后主机被植入后门并尝试连接已知恶意网站并对局域网内其他终端进行恶意扫描。重复利用Louvain算法和TF-IDF算法进一步分析可进行攻击溯源并发现其他存在安全风险的终端存在的安全问题并确定解决方案。
3 研究应用与对比
通过机器学习算法分析和对终端安全问题进行处理,对2018年和2019年同期安全事件告警数量进行对比,安全事件数量出现较为明显的下降,业务终端的安全性得到大幅提高。应用前后安全事件数据对比如图5所示。
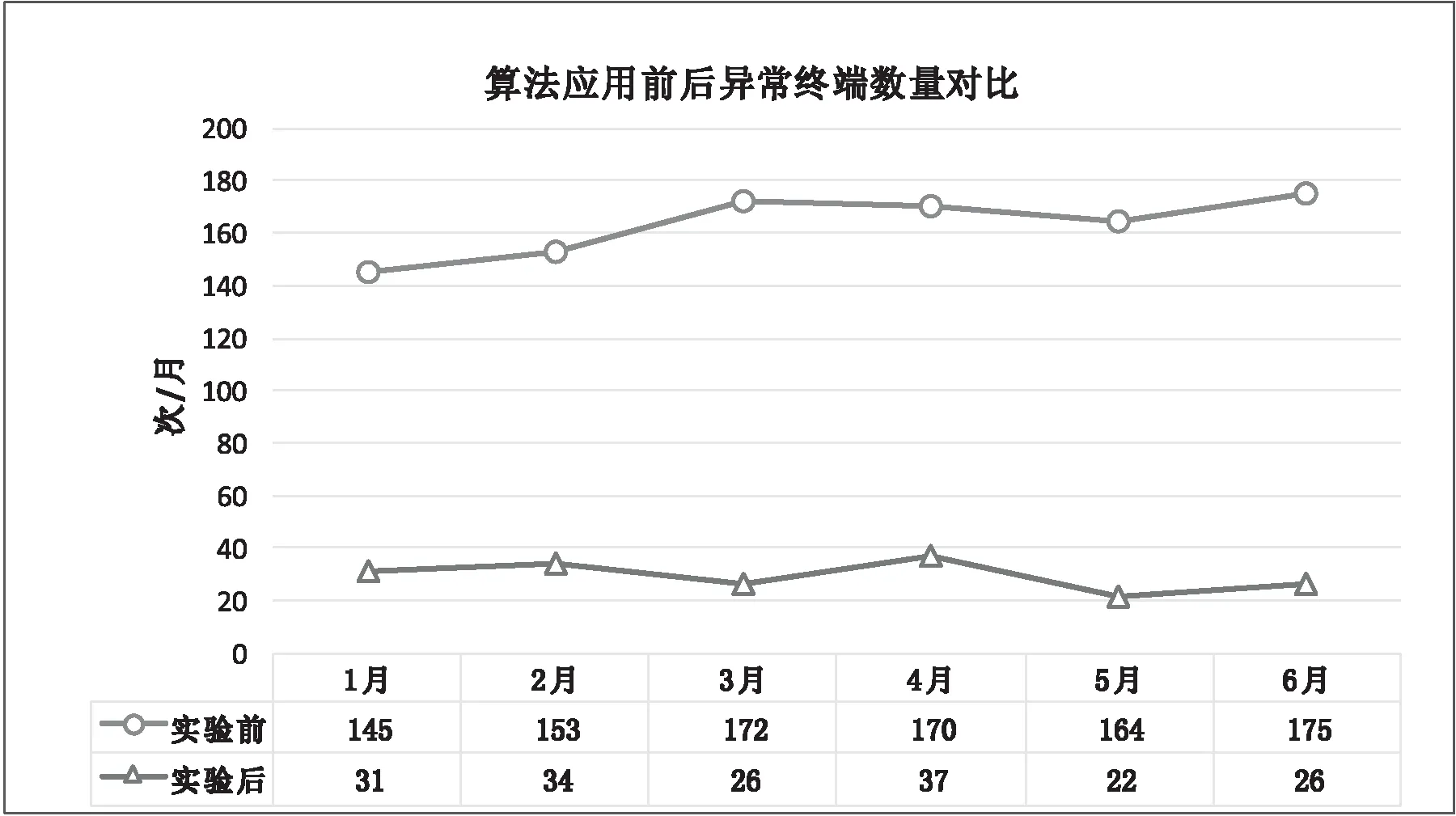
图5 算法应用前后异常终端数量对比
4 结束语
该研究通过机器学习的有关算法对气象网络安全数据进行了分析,实现了对气象网络存在安全隐患的终端进行定位和日志信息关键短句的提取,进而对有关终端安全问题进行修复,一定程度上解决了对业务终端安全监控不足的问题,提高了气象网络和业务终端的安全性。
该研究对国内气象系统安全数据分析具有一定的参考价值和借鉴意义。
同时,该研究还存在一些不足:整体分析过程中还无法做到全自动化地完成,部分步骤需要人工干预;个别安全信息重要内容较多,通过现有算法无法做到全部提取,未来的研究将针对以上的不足继续进行探究与完善。
猜你喜欢
作文周刊·小学一年级版(2022年24期)2022-06-18 13:11:03
华人时刊(2021年13期)2021-11-27 09:19:02
内蒙古气象(2021年2期)2021-07-01 06:19:58
科学家(2021年24期)2021-04-25 13:25:34
心声歌刊(2020年4期)2020-09-07 06:37:14
心声歌刊(2019年5期)2020-01-19 01:52:52
领导决策信息(2018年46期)2018-04-20 04:00:42
网络安全和信息化(2017年6期)2017-11-23 08:36:18
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
电脑迷(2015年6期)2015-05-30 08:52:42
