
基于教育大数据的学生用户画像研究
2021-09-26 13:12廉颖
电脑知识与技术 2021年20期
廉颖

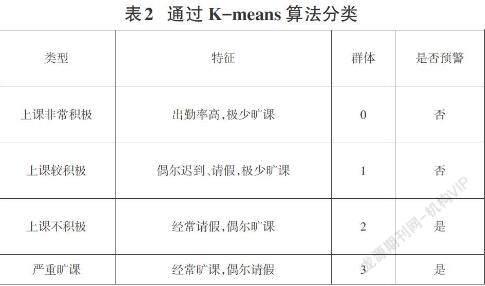
摘要:近年来有关学生用户画像的研究较多,但是关于研究成果应用到具体学生管理的相关成果相对较少,而且学生管理复杂性高难以照搬通用。所以,在用户行为画像的理论方面和应用方面都有很大研究空间,而本文选用智慧校园进行学生用户数据的搜集,通过大数据相关挖掘算法进行学生行为画像研究,对学生的消费习惯、兴趣偏好和学习习惯进行综合分析,为学校不同管理者提供数据,方便进行辅助教学管理。
关键词:数据挖掘;用户画像;教学管理
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2021)20-0038-03
1 研究背景与意义
目前用户画像有了一定研究,在国外Giuseppe Amato[1]等人通过研究图书馆用户的数据,挖掘分析其阅读习惯,进而构建画像,为读者推荐图书的目的。现在随着技术的发展,用户画像被定义为指根据用户的关键特征、网络活动、网络社交等行为给用户建立一个抽象标签。本文通过构建大数据平台对学生数据进行挖掘,构建学生食堂消费画像,上网浏览画像,自习室使用的画像帮助学生管理者决策。
2 学生采集
当前,我校可利用不同的系统对教育大数据进行采集和分析,这些系统涉及到教务管理、财务管理、图书管理、一卡通管理等方面。另外,教育大数据之中还含有其他软件提供的数据,比如超星学习通,钉钉学习的数据。由于数据结构复杂,在正式形成学生用户画像之前,需要解决两个重要问题:一是数据如何存储分析;二是怎样确定标准化的数据。一般来说,用户画像由三个基本要素构成[2],用户特征是其中之一,另外两者为用户标签与用户属性。属性数据给出了学生的基本信息,如籍贯、性别、姓名、学号、年级等。用户的特征数据比较繁杂,我们抽取关联性较高的一些的数据进行研究。对于校园教育大数据来说,其突出特征主要有两个,首先是数据总量庞大,难以准确地进行计量;其次是数据结构表现出明显的复杂性。考虑到由于数据的结构性或非结构性之间也存在误差,因而需要对数据进行ETL转换,为防止出现信息孤岛问题,还应当构建科学而合理的数据模型。
3 大数据平台系统架构
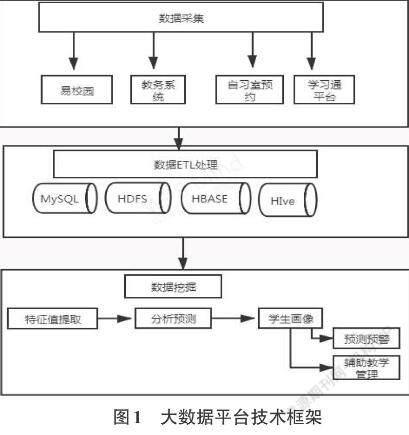
具有数据采集功能的ETL工具库是我校大数据平台系统的关键构成部分,该工具库不仅支持数据访问权限的分配,而且具有工作效率高、集中度高等优点,其采集的数据主要来自于以下几个方面:一是互联网环境中具有分散特性的海量数据;二是软、硬件的运行日志与设备数据;三是数据中心内外的所有数据,其中也包括新增数据源。大数据平台从我校信息系统中采集到相关的数据信息之后,首先选择Hadoop分布式大数据存储方式,然后再使数据得到分类存储,执行此项操作时可利用三种分布式存储技术,即HIVE、HBASE与HDFS。对于部分仅仅需要预测趋势而不需要具有较高计算实时性的学生用户数据,应当选用HIVE这一存储技术。SPARK与HBASE这两种存储技术对互联网、一卡通等数据具有良好的适用性,这类数据往往提出了较高的实时性要求。另外,当数据来自于表格或文本时,所选用的分布式存储技术应当是HDFS。对数据存储以后进行下一步的数据分析挖掘,例如以我校学生的用餐数据进行用户画像,首先选取用餐有关的相关数据,抽取相应的数据特征,基于Python编程语言选择对应的算法进行分析预测,然后将多用户的标签进行用户画像的生成,最后根据用户画像进行辅助教学管理。如图1是我校大数据平台技术框架图。
4 数据分析挖掘
4.1 特征值提取
当原始数据采集完成过后,由于有的数据存在一些问题,比如特征编号不一致,字段表意不清,标签特征不明显等等这种不完整的数据,为了提高数据集的搜集效率和结果的准确性,给后面的研究提供统一标签。标签的提取思路如下,我们定义大的标签所占的权重较大,小的标签所占权重较小,所以画像上面的每个标签大小不同,由此可以确定画像的重要特征。说明并存储用户特征是针对学生用户建立画像模型的出发点,为了构建可计算并支持读取的用户画像模型,应当以用户的行为日志、消费偏好、兴趣、个人基本信息等为依据。实际上,使用户特征得到向量化与标签化处理是用户画像建模的真正意图,这样做不仅可以获取到便于计算的数据,还可使语义信息更为精确,从而为后期处理算法创造了良好的条件。需要强调的是,在向量化处理用户属性时,不应当忽略数值的连续性与离散性。
4.1.1 特征值维度
在获取到数据之后,怎么从大量的数据中选取有助于刻画用户画像的数据,对数据挖掘过程有非常大的影响。如果数据特征值维度较少,用户画像的准确性将大打折扣;否则,不仅会增加时间成本还需要系统提供更大的存储空间。总之,最适宜的数据特征值维度应同时兼顾效率与精度。为保证所获取数据的有效性,除了要深入剖析其每个属性以外,有时还需要数据特征通過Python的一些工具统计后进行可视化。
4.1.2 特征值关联性
特征值与画像之间的关联性分析,如何用较少的特征较准确的刻画用户画像,有必要对二者的关联度展开分析,并在此基础上通过算法加以预测。以分析学生的某科目考试成绩为例,首先应当明确性别、年龄、思维模式等属性,然后再探究这些属性与成绩之间的关系。在获取属性数据的过程中,需要搜索和查看有关联性的多种表。比如:为了明确用户上网地点,既需要查看设备地点设置表,也需要调取用户登录日志。再如,若要将ISBN顺利添加到图书借阅信息表中,应使该表与图书基本信息表相关联。对于其他属性,应当利用Python或Web API到网上进行采集。以某种图书为例,可通过豆瓣API与ISBN相关联来获知其内容简介、关键词与读者评价状况。
4.2 特征值标签化
语义化和短文本是数据特征标签的两个基本特性,前者是指标签的实际含义易于理解,该特性既可使业务需求得到满足,又增强了用户画像模型的真实性。后者是指标签比较简约,可以较为直观是学生的特征,一般不需要再分即可描绘用户画像,同时也能为数据分析提供方便,还可使软件更为高效率地提取标准化信息。值得一提的是,单纯的打标签不能等同于用户画像,这是因为后者需要依托计算机来处理属性与标签向量化。从本质上来说,文字标签是对用户画像进行可视化处理的一种手段,通过读取其展示的信息即可了解用户的偏好与行为趋势。不同标签之间建立了一个关系网,但是只强调了权重大小与属性关系,并没有表达非继承关系以及包含与被包含关系。基于此,标签比分类更具有灵活性。不过,由于参与的用户基本不受限制,因而标签的权威性得到了弱化。
猜你喜欢
大学(2021年2期)2021-06-11
电力与能源(2017年6期)2017-05-14
现代情报(2016年10期)2016-12-15
现代经济信息(2016年24期)2016-11-09
电脑知识与技术(2016年7期)2016-05-19
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
体育师友(2011年2期)2011-03-20
