
结合目标检测与特征匹配的多目标跟踪算法
2021-09-26 09:44:02叶靓玲李伟达郑力新曾远跃黄凯
华侨大学学报(自然科学版) 2021年5期
叶靓玲, 李伟达, 郑力新, 曾远跃, 黄凯
(1. 华侨大学 工学院, 福建 泉州 362021; 2. 福建省特种设备检验研究院 泉州分院, 福建 泉州 36021)
多目标跟踪是计算机视觉和公共安全领域的热点研究问题[1-2],已被广泛应用于各行各业,如自动驾驶、行为分析和智能监控等.但在复杂场景下,多目标的实际应用仍面临许多挑战,如相似目标的区分、目标遮挡[3]、目标在镜头前的突然产生和消失等.为了解决这些问题,李星辰等[4]针对目标遮挡,提出目标轨迹修正的相应策略,在一定程度上能够缓解遮挡带来的目标身份切换问题.但这种依靠运动轨迹预测模型进行数据关联,在面对目标过多的复杂场景时,跟踪的准确性仍有待提高;Wang等[5]利用方向梯度直方图(histogram of oriented gradient,HOG)进行在线外观特征判断,只能保证局部的高效特征,对全局的轨迹关联仍有一定影响.针对上述的问题,本文基于深度学习,提出一种结合检测和特征匹配的多目标跟踪算法框架.
1 目标检测和特征匹配的多目标跟踪方法
多目标跟踪算法框架,如图 1所示.该框架主要由3个部分组成,即目标检测模型、特征匹配模型和跟踪模型.首先,将图像It+1输入到目标检测模型中,通过YOLOv5检测器获得每一帧中目标边界框的坐标信息Dt+1;其次,将It+1输入到预训练好的特征匹配模型中得到128维的特征向量Ft+1;最后,将Ft+1与特征空间Si中已保存的特征向量进行特征匹配(其中i代表特征空间中存储的图像帧数).若匹配值越大,代表二者为相同目标的可能性更大;反之,则为相同目标的可能性更小.预测It帧中所有目标在T+1帧中的位置,记为Pt+1,并将Pt+1和目标检测信息Dt+1与特征匹配的结果进行轨迹关联,从而得到完整的目标跟踪轨迹.
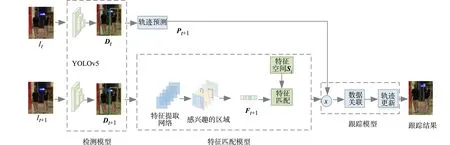
图1 多目标跟踪算法框架图 Fig.1 Structural framework of multiple object tracking
1.1 目标检测模型
Bewley等[6]提到检测算法的精度能直接影响多目标跟踪的准确性,因此将现阶段检测精度较高的YOLOv5引入多目标跟踪算法中.利用YOLOv5来准确定位并获取目标边界框的坐标信息D,以便作为后续跟踪模型的输入.首先将输入图像按照一定的尺度标准划分成单元格,该单元格负责预测目标边界框的坐标信息.
为了得到更多大小不一的尺度,使检测网络具有更好的鲁棒性,在输入端中使用Mosaic数据增强技术随机将4张图片进行缩放、裁剪和分布.同时,为了减少输入图像的冗余信息,在输入端加入自适应图片缩放技术来自动地添加最少的黑边,达到减少信息的目的.定义原始图像的尺寸为M×N,预计缩放的尺寸为P×P,具体的自适应图片缩放的计算式为
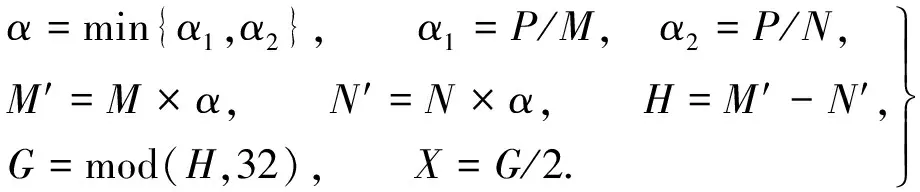
(1)
式(1)中:α是缩放系数;M′×N′是缩放后的图像尺寸;H是原始图像需要填充的高度;G是像素个数,通过H对32取余得到;X是图像两端需要填充的数值大小.
为了达到下采样的同时不丢失信息,在图像输入主干网络前,对其进行切片操作.因此在主干部分,采用Focus结构来形成图像特征.具体Focus结构的关键操作,如图 2所示.
为了进一步加强检测网络特征融合的能力,在Neck部分[7]加入CSPNet网络设计的CSP2结构[8].CSP2将基础层的特征映射分成两部分,然后利用跨阶层次将二者合并.具体的CSP2结构,如图3所示.其中每个CBL模块分别由卷积、BN(batch normalization)和Leaky ReLu激活函数组成,最后输出端得到每帧中目标边界框的坐标信息D.在后续多目标跟踪中,对利用YOLOv5得到的目标信息进行跟踪.

图2 Foucs切片操作图 图3 CSP2结构 Fig.2 Foucs slice operation Fig.3 Structure of CPS2
1.2 特征匹配模型
多目标跟踪中目标特征的提取,可以看作是行人重识别网络(person re-identification,ReID)的具体实现[9].Wojke等[10]指出ReID能够有效缓解目标遮挡,提高关联的准确性,对关联轨迹可起到有效的辅助作用.因此,文中利用深度学习强大的表征输出能力,设计一个ReID网络作为多目标跟踪的特征匹配模型.该特征匹配模型以ResNet50[11]作为主干网络.
特别针对多目标跟踪场景,文中做如下3点改进.1) 为确保网络能捕捉更细致更全面的底层特征,在浅层网络中采用更宽的网络宽度和更大的卷积核(5×5).虽然采用更大的卷积核会增加少量计算开销,但相应将步长设置为2,步长较大,后续参与计算的图像会变小,这样可以有效减少模型的计算复杂度.2) 为有效减少特征的损失,再次采用步长为2的卷积操作代替网络中的最大池化操作.3) 为防止特征在传递过程中的损失,在特征匹配模型中不再使用ReLU激活函数,转而使用线性激活函数.
提取目标的特征过程,如图4所示.即先输入一张图像It,经过改进后的特征提取网络,得到输入图像的感兴趣区域,最后经过一个全局平均池化层将提取到的特征映射成一个128维的一维向量.

图4 目标特征的提取过程 Fig.4 Extracting process of object feature
由于多目标跟踪中目标特征差异性小,为了更好识别目标特征,判断前后两帧中的跟踪目标是否属于同一身份,使用Triplet损失[12]进行度量学习,选择Market 1501数据集[9]进行训练.Triplet 损失可以使具有相同标签的样本在嵌入空间里尽量接近,不同标签的样本在嵌入空间中尽量远离.具体地,将Triplet损失定义为:输入一个三元组〈a,p,n〉 ,其中a是anchor锚点[13],是从训练集中随机选取的一个样本,p是与a同类别的样本,n是与a不同类别的样本.即将anchor作为一个锚点,通过学习后,使得同类样本p更加接近a,而不同类样本n远离a.在嵌入空间中,这个三元组应该满足
L=max(d(a,p)-d(a,n)+margin,0).
(2)
式(2)中:阈值margin是衡量样本相似度的重要指标.较大的阈值可以增强模型对不同类样本的区分度,较小的阈值则不能有效区分同类样本.因此,在训练初期先选择一个较小的阈值,接着再针对测试的结果对阈值进行增大或缩小的调整.
1.3 跟踪模型
跟踪模块中进行前后两帧之间多个目标的轨迹关联,主要包括判断新目标的出现、处理旧目标的消失和匹配前后两帧间目标的ID.因此可以将前后两帧之间的轨迹关联看作是求最优解的过程.即将通过目标检测模型得到的目标检测信息D看作是一个图解空间,第T+1帧中的所有检测框记为Dt+1,第T帧中的所有预测框记为Pt+1.由于同帧不会存在相同目标,因此同帧中的目标不能进行轨迹关联,故匹配关联时只需要关注前后两帧间的目标.然而,由于每个目标的匹配地位不相同,需要对每个目标赋予相应的权重,为此引入KM算法[14]来求解前后两帧中目标的最优匹配轨迹.
文中利用KM算法进行轨迹的关联,采用通过目标检测模型得到的检测信息Dt+1与预测框Pt+1的交并比 (intersection over union,IoU) 作为不同目标的占比权重.IoU的计算式为
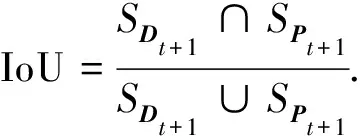
(3)
式(3)中:SDt+1是第T帧检测框的面积;SPt+1是第T+1帧预测框的面积.IoU的值越接近1,表明检测框与预测框的关联性越大,意味着二者是相同目标的可能性越大.当IoU大于一定阈值时,认为是相同目标.文中的阈值选为0.4.首先,对每个目标赋值,将Dt+1中的目标赋值为与其相邻目标的最大权重值;Pt+1中赋值为0.接着利用KM匹配原则对Dt+1中目标值与其相邻权重值相同的目标进行匹配.
2 实验结果与分析
为了验证文中算法具有良好的跟踪性能,在多目标跟踪数据集MOT16[15]上进行测试评估.实验平台为Linux服务器,python3.8和pytorch编程实现上述算法.在 NVIDIA GeForce GTX Titan GPU上进行特征匹配模型的训练和多目标跟踪算法的测试.
文中所提多目标跟踪算法属于SDE框架[16],即目标检测和特征匹配是两个独立的阶段.因此,在实验中,选择阶段式训练.首先,在多目标跟踪的检测模型中引入精度更高的YOLOv5.在特征匹配模型中,用Market1501数据集的行人身份标注训练文中所提的特征匹配模型.模型采用Adam优化器训练60个周期epoch,学习率为设置为0.001,batch_size设置为64.
2.1 实验数据集
MOT16(multiple object tracking 16)是在2016年被Milan[15]提出,主要用于衡量多目标跟踪算法性能的,也是多目标跟踪领域中最具有挑战的数据集之一,包括静态摄像机和动态摄像机拍摄的7个不同场景,共11 235张图像.标注的主要目标为行人和车辆.图 5为MOT16部分场景.从图5可知:每个场景都拥有丰富的画面信息,包含多个行人目标,目标间存在严重遮挡、光照变化和复杂天气等挑战.因此,利用MOT16数据集对文中提出的算法进行验证,可以进一步说明在复杂场景下该算法有较好的泛化能力和鲁棒性.

图5 MOT16部分场景 Fig.5 Some scenes in MOT16
2.2 检测模型对跟踪器性能的影响
采用多目标跟踪领域流行的评估标准对算法进行评估.对跟踪影响最大的四个指标分别为:多目标跟踪准确度(multiple object tracking accuracy,MOTA)、多目标跟踪精度(multiple object tracking precision,MOTP)、识别F1分数 (identification F-score,IDF1)和目标身份切换次数(identity switches,IDs).为了验证YOLOv5检测算法对跟踪器的有效性,文中挑选了3种当下检测效果较好的检测器(FasterR-CNN[17],YOLOv3[7],YOLOv5),并组合两种不同的特征匹配模型(WRN[18],ResNet50[11])在MOT16-05序列中对其进行评估,结果分别如表 1, 2所示.每一组评估中只设置一个变量,以保证算法的可信度.

表1 不同检测算法组合相同的WRN特征匹配模型Tab.1 Different detection algorithms are combined with same WRN feature matching model

表2 不同检测算法组合相同的ResNet50特征匹配模型Tab.2 Different detection algorithms are combined with same ResNet50 feature matching model
MOTA是评估跟踪准确性的重要指标,而MOTP是衡量检测器的定位精度.从表 1可知:引入YOLOv5检测算法(YOLOv5s+WRN和YOLOv5x+WRN)时,MOTA,MOTP和IDF1的得分更高.这说明,检测器性能的好坏在一定程度上能够影响跟踪的鲁棒性;采用YOLOv5检测器进行跟踪时产生的目标身份切换次数(IDs)会略高于YOLOv3,但并不能单独利用IDs的得分来评估跟踪性能的优异.有时可能出现目标身份切换次数较少,但产生较多的轨迹片段,跟踪的稳定性也会受到影响.因此,需要结合IDF1,IDs和MOTA的得分来评估跟踪的鲁棒性才更具有说服力.
从表2可知:用与表1相同的3个检测器搭配ResNet50[11]为主干的特征匹配模型进行跟踪,结果表明使用YOLOv5的MOTA得分更高.这说明,将YOLOv5作为多目标跟踪的检测器引入到MOT中,能够有效地提高MOT的跟踪精度.
综合表1,2可知:通过比较WRN和ResNet50两个特征匹配模型在不同检测器上(FasterR-CNN,YOLOv3,YOLOv5s 和YOLOv5x)的影响,使用ResNet50的特征匹配模型在MOTA,MOTP,IDs等3个指标上的得分相对更高.特别是当检测器选择YOLOv5时,使用ResNet50(表2中YOLOv5s+ResNet50和YOLOv5x+ResNet50)相比较于使用WRN(表1中YOLOv5s+WRN和YOLOv5x+WRN)的特征匹配模型,IDs减少约20%和17%.这说明,当目标面对遮挡时,基于ResNet50的特征匹配模型能够正确关联到相应目标的可能性更高,跟踪稳定性相对更好.造成两个特征匹配模型有如此差异的原因,是因为ResNet50的网络层数更深,能够提取更细致更全面的目标外观特征,故当目标存在遮挡时,也能够有效减少目标间的身份切换问题.因此,将ResNet50作为特征匹配模型的主干网络能够在目标的数据关联上起到一定的辅助作用.
2.3 特征匹配模型的性能评估
特征匹配模型是基于ReID,通过分类网络来具体实现的.因此可以利用ReID中的性能指标mAP(mean average precision)和rank=1作为评估特征匹配模型的性能.利用WRN和ResNet50探究特征匹配模型对跟踪性能的影响,可以看出,在检测器相同的情况下,ResNet50在跟踪性能上取得的效果更好.为了进一步充分利用ResNet50强大的特征提取能力,文中提出改进的特征匹配模型.即在浅层网络中采用更宽的网络宽度和更大的卷积核(5×5),并将步长设置为2来减少卷积操作带来的计算开销.最后,在特征匹配模型中再次使用步长为2的卷积代替最大池化操作,利用线性激活函数来防止特征在传递过程中的损失.
改进的特征匹配模型在Market1501上训练60个周期epoch后得到的函数损失,如图 6所示.图6中:L代表的是Triplet损失函数在Market1501数据集上训练时的收敛过程;etop1代表的是top1的错误率.从图6可知:Triplet损失函数在训练开始后逐渐收敛.
进一步选用当下流行且性能优越的ReID算法(SPReID[19],BFE[20],Mancs[21])与文中改进的特征匹配模型进行评估,结果如图7所示.图7中:A为精度.从图7可知:文中通过ResNet50改进的特征匹配模型在mAP和rank1上的得分明显优于其他算法.这说明文中所提的特征匹配模型能够有效提取到目标的细致特征.
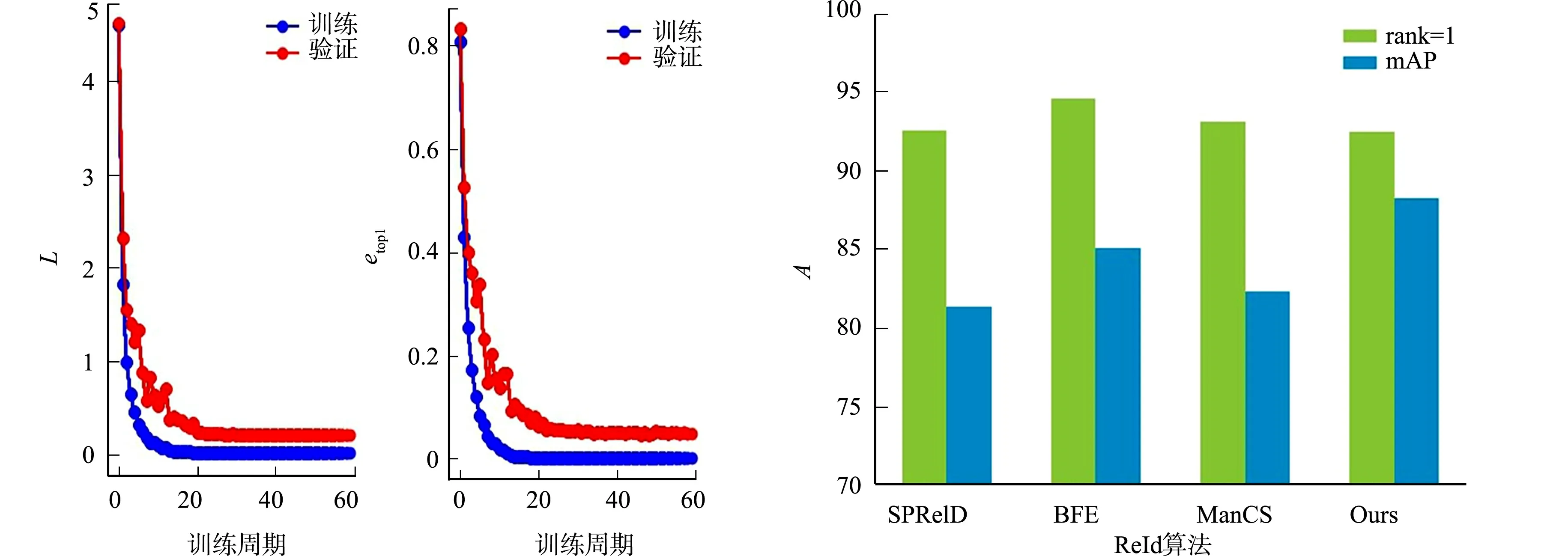
图6 特征匹配模型训练的损失函数图 图7 特征匹配模型与性能优异的ReID算法的比较 Fig.6 Loss function of feature ReID algorithm in excellent performance Fig.7 Comparison of feature matching model with matching model training
为了进一步验证引入的YOLOv5检测模型与改进的特征匹配模型对提高跟踪器的准确性具有一定的效果.文中所提算法在检测模型部分选择YOLOv5s模型,在特征匹配模型部分,以ResNet50为主干网络进行网络结构的调整并训练后得到特征匹配模型.将文中所提算法在MOT16-05序列上与上节中表现优异的组合相对比,得到的评估结果,如表 3所示.
从表3可知:文中所提算法在检测器上选择了精度更高的YOLOv5,相比较于FasterR-CNN+WRN,多目标跟踪的准确性MOTA提高了约20%,IDs减少了近24%.即引入YOLOv5能够提升一定的跟踪精度.更重要的是,面对频繁遮挡的场景,利用文中改进的特征匹配模型可以提取更为鲁棒的特征,有效减少目标间的身份切换次数和提高IDF1的得分.
虽然文中所提算法在MOT中引入特征匹配模型来关联目标轨迹,但并没有引入额外的计算开销.针对ResNet50改进的特征匹配模型,文中算法在模型参数量Params和浮点运算次数(floating point of operations,FLOPs)上都优于其余算法.其中,FLOPs可以衡量多目标跟踪算法复杂度.计算目标检测模型和特征匹配模型复杂度时,输入图像的大小分别为680 px×680 px和224 px×224 px.可见,文中所提算法在没有引入额外开销的同时还能有效缓解遮挡时的身份切换问题并实现稳定跟踪.这主要得益于文中检测算法引入参数量较小,但检测精度相对较高的YOLOv5s.在特征匹配模型中虽然加大了卷积核来提取更细致的特征,但同时可对网络结构采用步长为2的设置,来减少参与计算图像的大小.与YOLOv5x+ResNet50相比,文中所提算法虽然会牺牲小部分MOTA和MOTP的精度,但其参数量和复杂度远比YOLOv5x+ResNet50小得多,并且在跟踪稳定性IDs和IDF1两个指标上也优于YOLOv5x+ResNet50.综合来看,文中所提算法在减少推理时间的同时,还能实现稳定的跟踪.

表3 总体跟踪性能评估(MOT16-05)Tab.3 Overall tracking performance evaluation(MOT16-05)
2.4 与当下同类跟踪算法进行评估
为了进一步体现文中所提算法具有良好的跟踪性能,利用MOT16数据集中的7个测试序列进行全面评估,并将其与当下MHT-bLSTM[22],CDA_DDALv2[23],MTDF[24],AM_ADM[25]和OVBT[26]等同类型算法进行对比,结果如表 4所示.
从表4可知:文中所提算法的MOTP在所有方法中得分最高,说明文中引入的YOLOv5检测器对定位目标的位置起到一定效果;其次,文中所提算法在IDs和IDF1两个指标上的表现性能也最好,这表明所提出的特征匹配模型能够有效减少目标间身份切换的次数,有利于稳定跟踪.MHT-bLSTM[22],CDA_DDALv2[23]算法的思想与文中所提算法的思想相似,都对目标的特征进行了建模.由此可知,在所有算法中,这三者算法的IDs和 IDF1性能表现最好,特别是文中所提算法,在三者中指标得分最高.这说明,在MOT上引入目标特征的建模中,文中所提出特征匹配算法的性能最优,对关联轨迹和维持跟踪的稳定性有一定效果.

表4 不同方法在MOT16测试集上的结果对比Tab.4 Comparison of different methods on MOT16 test set
文中所提算法在MOTA上得分不如MTDF[24],这是因为MOT是一项复杂的任务,特别是针对SDE框架下设计的跟踪算法[16],往往会受到检测模型、时空信息等因素的影响.MTDF加入了时空信息,可以在目标相互接近时消除模糊的轨迹关联,因此跟踪的准确性会略高.但该算法在IDs和IDF1这两个指标上表现不佳,导致跟踪的稳定性不如文中所提算法.它在面对遮挡时依然能够正确关联大部分轨迹,维持稳定鲁棒的跟踪.文中重点关注的是检测器和特征匹配模型对跟踪性能的影响,忽略了时空信息对轨迹关联的影响,后续将进一步加入时空信息来提高多目标跟踪的准确性.
2.5 行人多目标跟踪
为了进一步验证文中所提算法在复杂场景下的行人跟踪效果,利用文中所提算法对MOT16测试集中的序列进行跟踪,对得到的跟踪结果随机截取图像帧,如图 8所示.从图8可知:文中所提算法对MOT16测试集场景中出现的目标都成功关联到身份ID,做到了有效的跟踪.

图8 行人多目标跟踪结果图 Fig.8 Pedestrian multiple object tracking results
为了进一步说明文中所提算法在遮挡频繁场景下能够有效识别目标的产生和消失,选择MOT16中移动相机拍摄的视频序列进行重点说明,如图9所示.在图9(a)中,利用文中方法有效跟踪到当前场景下出现的目标,并赋予目标相应的ID编号,重点分析编号为8的目标;在图9(b)中,8号的目标框发生丢失,经过一段时间后,8号目标的ID在图9(c)中被重新正确关联上;在图9(d)中,8号目标被完全遮挡,消失在镜头中,经过若干帧后,当8号目标重新出现在镜头下时,利用特征匹配模型辅助关联,成功将其外观特征与特征空间中的特征进行匹配计算;在图9(f)中,利用相同目标的匹配关联值最大的特点,将8号目标重新关联,得到8号目标完整的行人轨迹.这说明文中结合YOLOv5检测与特征匹配模型的多目标跟踪算法,经过数次遮挡,依然能够稳定维持目标编号,实现稳定的跟踪.
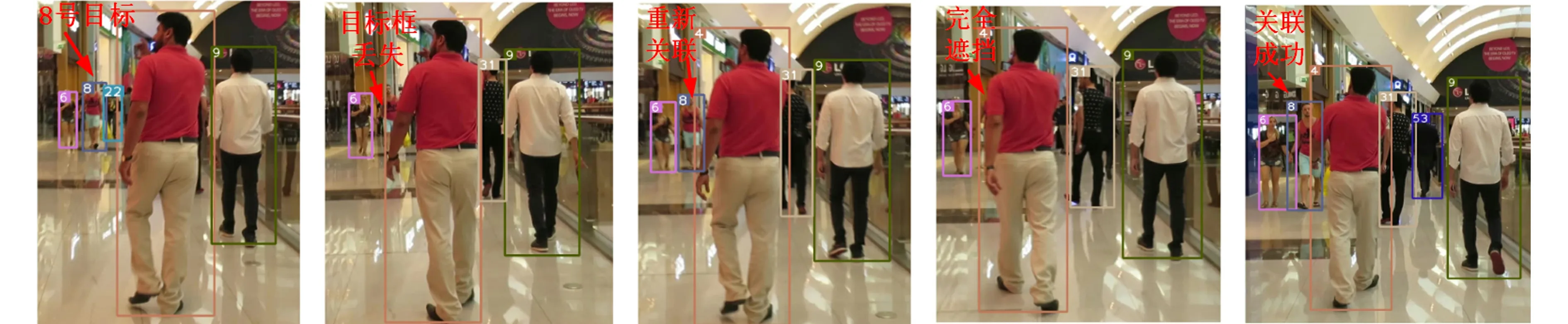
(a) 关注目标 (b) 目标丢失 (c) 重新关联 (d) 完全遮挡 (f) 关联成功图9 移动场景下的行人多目标跟踪 Fig.9 Pedestrian multiple object tracking in moving scenarios
3 结论
为了解决多目标跟踪在目标检测精度低和多目标遮挡时存在轨迹匹配难的问题,通过一系列实验探究表明YOLOv5检测器对提高跟踪的准确性有一定效果,因此将YOLOv5引入到多目标跟踪中作为跟踪的检测器.为了提取更全面更鲁棒的特征,提出改进的特征匹配模型,来解决目标间由于遮挡导致的身份切换问题.在MOT16数据集上的评估也表明,文中所提算法在处理遮挡能力和关联轨迹方面都有优异表现,并且能够在维持稳定跟踪的前提下减少相应的推理时间,这为多目标跟踪在实际设备中的应用提供了更大的可能性.
然而,该算法也存在一些问题,如文中所提算法属于SDE算法框架[16],即检测和跟踪分成两个阶段训练,这会对实时性产生一定的影响.下一阶段的研究目标是联合检测和跟踪,并进行多任务训练得到端到端的多目标跟踪网络,从而进一步提高多目标跟踪的实时推理速度.
猜你喜欢
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
当代陕西(2019年15期)2019-09-02 01:52:00
现代装饰(2018年5期)2018-05-26 09:09:39
学苑创造·A版(2018年11期)2018-02-01 06:29:20
中国三峡(2017年2期)2017-06-09 08:15:29
中国交通信息化(2017年9期)2017-06-06 07:14:57
读者(2017年5期)2017-02-15 18:04:18
工业设计(2016年11期)2016-04-16 02:49:43
河南科技(2014年22期)2014-02-27 14:18:12
