
一种基于动态时间规整的闭环检测算法
2021-09-25 10:51彭之川张智腾朱泽敏谢勇波王文明
控制与信息技术 2021年4期
朱 田,彭之川,张智腾,朱泽敏,谢勇波,王文明
(长沙中车智驭新能源科技有限公司, 湖南 长沙 410000)
0 引言
机器人在未知环境中自主工作的第一步是环境感知和建立环境模型。同步定位与建图(simultaneous localization and mapping, SLAM)是研究此步骤的重要方法,即机器人在传感器数据基础上,自主移动建立环境模型并同时完成自身定位[1]。闭环检测是SLAM中的一个关键问题[2],其通过机器人的当前位置图像与先前位置图像进行配准来判断机器人是否曾经到达过先前位置,因此闭环检测也可以被视为是一类场景识别问题。正确的闭环检测可以为位姿图添加边约束,减小机器人运动估计的累计误差,并能构建一致性地图;而错误的闭环检测会对已有位姿图带来干扰,导致地图创建的失败。因此,闭环检测的研究意义重大,设计一个好的闭环检测算法,对于构图一致性乃至整个SLAM系统都是至关重要的。
目前主流的方法是基于单张图像特征进行匹配来检测闭环,比较经典的方法有基于词袋模型[3]的视觉闭环检测算法,其可以将场景图像中的视觉特征聚类成许多个“单词”,然后基于这些“单词”用向量的形式对整幅图像进行描述,进而将视觉闭环检测问题转化为两张图像的描述向量的相似度度量问题。由于机器人所在的工作环境是变化的,受光照变化、物体移动或者摄像头位置等因素的影响,即使来自同一个地方的两张图片,其绝对相似度很可能也不满足正确匹配的要求。另外,对于外表相似的一些地点,其图片的相似度可能很高,因而造成误匹配的现象。所以,在复杂环境下利用单张图像匹配进行闭环检测可能存在比较大的误差。由于在闭环检测问题中,图片数据集在时间上与空间上是关联的,基于这一特性,本文利用图片序列匹配取代单张图片匹配,提出了一种基于动态时间规整的闭环检测算法,其图像序列匹配不再是比较两张图片的绝对相似度,而是更看重图片在序列中的相对相似度。该方法首先通过深度神经网络来提取每张图像的高级抽象特征,然后构造出图像序列的相似度矩阵,最后基于动态时间规整算法(dynamic time warping, DTW)[4]计算出序列的相对相似度进行闭环检测。通过与词袋法进行实验对比,结果显示本文所提方法的准确率和召回率更高,算法性能更好。
1 基于动态时间规整闭环检测算法
动态时间规整算法包含4个关键组成部分:特征提取、余弦相似度矩阵的构建、基于DTW的序列相似度求解以及最终匹配结果报告。
1.1 特征提取
本文利用卷积神经网络模型VGGNet[5]的前5层完成对场景图像的特征提取。VGGNet网络的输入是像素大小为224×224、经过均值化处理的RGB图片。网络的前5层包含13个卷积层和5个最大池化层。卷积层中,卷积核的大小为3×3,步长为1。池化层中的池化窗口为2×2,步长为2,并且均采用最大池化的方式。同时,在所有隐含层后面均采用ReLU激活函数以加入非线性因素,提高神经网络对模型的表达能力。相较于其他卷积网络,例如AlexNet[6],VGGNet网络层数更多,并且所有卷积层使用同样大小的滤波器。更深的网络能够提升图像识别性能,学习更多图像的细微特征。VGGNet网络参数见表1。

表1 VGGNet前5层网络参数表Tab. 1 The first 5-network parameters of VGGNet
本文提取VGGNet的第5层输出作为图片的特征,由表1可知Maxpool2层提取到的特征的形式是维度为(1,7,7,512)的张量。
1.2 余弦相似度矩阵
将一张224×224×3的场景图像经过训练好的VGGNet模型提取特征之后,可以得到512个大小为7×7的特征图,这些特征图即为输入图像的抽象特征。为了计算两张图片的相似度,将7×7的特征图转为一维向量的表达形式:


两个向量的夹角余弦值越接近1,即两向量夹角越小,说明两张图片相似度越高。传统的基于单张图像进行闭环检测的原理就是利用两张图片的绝对相似度sij与设定的阈值进行比较来判断是否形成闭环。由于单张图片特征的地点识别无法应对复杂场景,因此本文采用图片序列来进行比对。
假设待检测的场景图像是Y1,目标图像帧为(X1,X2,X3, …,Xn),本文选取Y1后的(m-1)帧图像与该场景图像组成测试图像序列(Y1,Y2,Y3, …,Ym),记该待测序列为T,其中T的长度为m且可调。为了实现同等长度的序列匹配,本文在目标图像帧中随机提取连续的m帧图像构成作为一个候选序列,可以得到(n-m+1)段候选序列,记为(L1,L2,L3, …,Ln-m+1),如图1所示。

图1 候选序列的选取示意图Fig. 1 Schematic diagram of candidate sequence selection
在进行序列相似度计算之前,需要先构造待测序列与每个候选序列的余弦相似度矩阵,以待测序列T与候选序列L1为例:

1.3 基于DTW的序列相似度求解
动态时间规整DTW是一个典型的优化问题。在测试模板和参考模板时间关系基础上对优化目标求最优解,其中优化目标为两者的匹配距离。最开始该算法是运用在语言匹配当中,用来匹配两个长度不一致的语音序列的相似度,以识别测试语音对应参考语音中的哪个词。考虑到这种语言识别与闭环检测在匹配时的相似性,采用动态规整算法来识别测试图片序列对应参考图片序列的哪一段,以实现闭环检测。
本文在时间关系基础上寻找两个图像序列中对齐的图片,即在式(3)所示相似度矩阵中寻找一条通过对齐点的最优路径,路径通过的格点即为两个序列进行计算的对齐的点,如图2所示,黑色点线为最优路径。将该路径用W来表示。


图2 规整路径示例Fig. 2 An example of regular path
W的第k个元素定义为wk=(i,j)k,路径要满足以下的3个条件:
(1)边界条件。测试图像序列和参考图像序列是随机选择的,但是每个序列内部的时间关系是一致的,因此满足边界条件,目标左下角为起始点,右上角为终止点。
(2)连续性。每一个图像序列是按照时间排列,时间是连续关系,因此图像序列也将是连续关系,路径计算中可以包含图像序列中每一个节点。
(3)单调性。时间是单调递增关系,图像序列根据时间先后顺序排列,路径计算中沿着特定的3个方向,不会出现交叉等现象。
在连续性和单调性条件约束下,每一个点(i,j)的前进方向只有3个,即(i+1,j), (i,j+1), (i+1,j+1)。但是,满足这些约束条件的路径可以有指数个,优化目标是求得代价最小的路径,即满足以下条件:

式中:T——目标序列;Li——候选序列;wk——对应点距离;P——路径W的元素个数,其作用是对不同长度的规整路径做补偿。
本文算法是基于图像序列的相似度匹配,目标是寻找一条相似度最高的规整路径,因此定义一个累加距离为

其中,d(Xi,Yj)为当前格点相似度,为这3个方向中到此格点累加距离最大的格点。从(0, 0)点开始匹配这两个序列T和Li,到达终点(m,m)后,这个累积距离就是最后总的相似度。最佳路径是使得沿路径的累积距离达到最大值的路径,即此时序列T和Li的相似度最高。
1.4 匹配结果
为了得到最终的匹配结果,本文定义了一个序列相似度向量:

式(7)中,DTW(T,Li)是利用式(5)求解得到的两序列相似度,SVector代表序列相似度向量。将序列相似度向量中最大元素值与设定的阈值σ进行比较,判断待测场景是否形成了闭环:

其中,max(SVector)指序列相似度向量中最大的元素值,若该值不小于设定的相似度阈值,则说明待测序列可以在候选序列找到其匹配对象,即待测场景形成了闭环;若该值小于设定的相似度阈值,则说明待测场景不形成闭环。
2 实验结果分析
为了验证基于DTW的闭环检测算法的性能和有效性,本文将其与传统的利用单张图像进行匹配的FABMAP方法和基于图像序列匹配的SeqSLAM方法进行了比较,并且讨论了主要参数序列长度对算法造成的影响。
2.1 实验数据集
本文使用Gardens Point Walking闭环数据集对算法进行测试,该数据集被广泛应用于闭环检测算法性能的评测。Gardens Point Walking是针对澳大利亚布里斯班昆士兰科技大学Gardens Point校区的单一路线收集的视觉数据集。作者用前向手持摄像头收集视觉数据,且在此路线一共采集3组数据,分别为白天两组,夜晚一组。在路径的左侧遍历一天路线,并且在路径的右侧遍历另一天路线和夜间路线,用相机捕获不同时间、方向路线中环境的姿态和状况变化。图片帧之间的采集间隔取得较大,以避免在相同的时刻有大量重复图片。Gardens Point Walking数据集由3个部分组成,白天沿路线左侧拍摄的200张图像、白天沿路线右侧拍摄的200张图像以及晚上沿路线右侧拍摄的200张图像。图像按照名称顺序在空间位置上是一一对应的。图3给出了该闭环数据集的真实轨迹以及示例图像。

图3 数据集轨迹及闭环数据示例Fig. 3 Examples of trajectory and closed-loop data
2.2 准确率和召回率
与传统的基于单张图片进行匹配的方式不同,本文匹配的是一定长度的图片序列,并且通过DTW算法计算两段图片序列的相似度大小S,然后比较S和设定阈值σ的关系来判断两张图片是否属于闭环。当满足阈值要求时,则判定两张图片构成闭环。在实验中,得到的结果可以分为4种情况:真阳性TP、真阴性TN、假阳性FP和假阴性FN。其中,假阳性FP和假阴性FN为常见的两种错误的闭环。在闭环检测实验中,假阳性指识别两个不同地点为同一地点,假阴性指未识别出两个相同地点。为了综合评价闭环检测算法的质量,统计假阳性和假阴性数量,计算其准确率(precision,P)和召回率(recall,R)值,并作出一条准-召曲线precision-recall曲线(简称“P-R曲线”)。通过统计测试过程中TP,TN,FN和FP出现的次数,可以计算得到闭环检测算法的准确率P和召回率R:

通过设定不同的阈值,可以得到一组准确率和召回率的值。以R为横坐标,P为纵坐标,可以得到算法的P-R曲线。P-R曲线越偏向右上方,表明算法越好。与此同时,P=100%时的召回率大小和R=50%时的准确率大小都可以作为算法的评价指标。
将2.1节介绍的Gardens Point Walking数据集中白天沿路线右侧拍摄的200张图像作为目标图像序列。测试图像序列由作为闭环数据的50张晚上沿路线右侧拍摄的图像和150张非闭环图像组成。利用该测试数据得到的实验结果如图4所示。

图4 算法在测试数据集上的P-R曲线Fig. 4 P-R curve of the algorithm on the test data set
从图4可以看出,本文提出的基于DTW的闭环检测算法的P-R曲线偏向于右上方,具有较高的准确率和召回率。当R=50%时,FabMap方法的准确率只有28%,SeqSLAM算法的准确率为58%,而本文方法能达到100%。说明本文所提算法明显优于传统词袋法(FabMap)以及SeqSLAM算法。同时由于目标序列是白天拍摄的图片,而所选取的闭环数据选取的是同一地点晚上拍摄的图像,说明该方法在光照变化时鲁棒性较好。
2.3 真阳率与假阳率
除了对算法的准确率和召回率进行分析之外,本文还引入了接受者操作特征曲线(receiver operating characteristic, ROC)来对算法的性能进行评价。ROC曲线是另外一种常用的闭环检测算法的评估方式,它显示的是算法的真阳率(TPR)和假阳率(FPR)之间的关系。该方法简单、直观,观察者通过图示可分析方法的准确性,并可用肉眼作出判断。ROC曲线计算公式为

通常,ROC曲线越偏向左上方,表明算法越好,将其量化为曲线下面积 (area under curve, AUC),则面积越大代表分类的性能越好,达到理想情况时AUC为1。利用2.1节所介绍的测试数据集分别对FabMap方法、SeqSLAM算法以及本文提出的闭环检测算法绘制ROC曲线,得到的结果如图5所示。
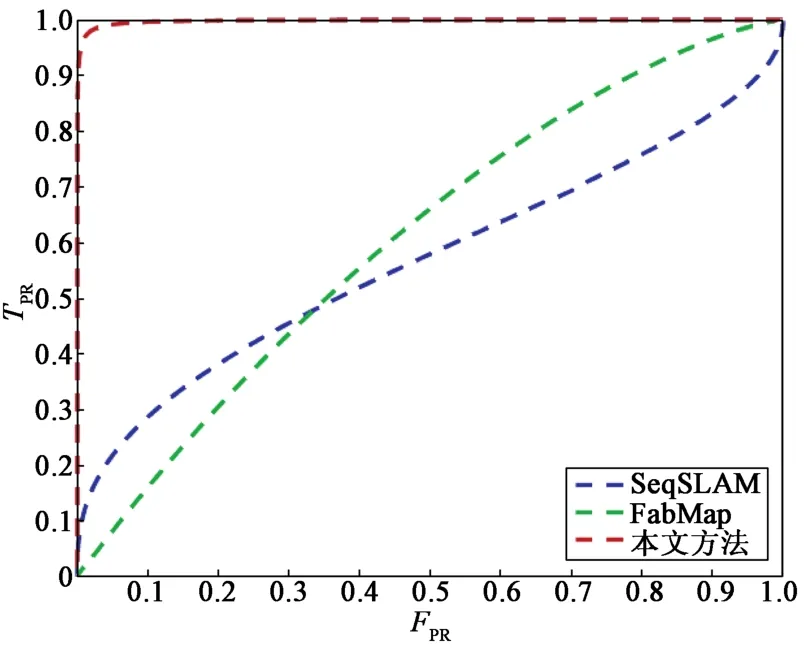
图5 算法在测试数据集上的ROC曲线Fig. 5 ROC curves of the algorithm on the test data set
从图5可以看出,本文提出的算法得到的ROC曲线最靠近左上方,真阳率的值始终比其他两种方法要高。通过计算3种方法的ROC曲线下面积,可以得到SeqSLAM的AUC值为0.56,FabMap的AUC值为0.61,而本文所提算法的AUC值为0.96,远远高于其他两种算法的,说明该方法检测闭环的精度更高,算法性能更好。
2.4 序列长度的不同对结果造成的影响
在利用动态时间规整算法求取两段序列的相似度时,实验发现序列长度的不同会影响到相似度的结果,并且对最终闭环检测的精度造成间接影响。因此,序列长度的选取是基于DTW的闭环检测算法的一个关键因素。为了验证相似度计算时序列长度调整对闭环检测造成的影响,本文将图片序列长度Length分别设置为5, 10, 15及20,通过式(1)计算对应序列长度的相似度,并且在第2.1节介绍的测试数据集下绘制出不同长度的P-R曲线以及ROC曲线来进行对比,实验结果如图6所示。

图6 不同序列长度的结果分析示意图Fig. 6 Result analysis in the condition of different sequence lengths
根据图6可以发现,将闭环检测匹配的方式设置为一定长度的序列匹配时,P-R曲线基本上都偏向于右上角,而ROC曲线基本上偏向于左上角,这说明了序列匹配性能的优越性。
同时,当R较高时,序列长度为10时的准确率比序列长度为5,15及20时的准确率要高。例如,在图6(a)中,当召回率为90%时,序列长度为10的准确率达到了98%,而序列长度为5,15和20的准确率分别为88%,94%和96%。在图6(b)中,计算得到序列长度为5时的AUC值为0.976;当序列长度增大到10时,得到的AUC值增长到了0.993;序列长度继续增大到15时,AUC值并没有增加,反而下降到了0.990;当序列长度为20时AUC的值继续下降,其值变成了0.988。结果证明,匹配序列长度会影响闭环检测的结果,序列长度被设置得过长或过短都会降低算法的性能,而选取合适的序列长度不仅可以提高视觉闭环检测算法的准确率和召回率,同时还可减少假阳性出现的概率,更有利于检测闭环。
3 结语
本文针对单张图像匹配的闭环检测算法存在的缺陷,利用单张图片的时间连续性的特点,提出一种基于DTW的闭环检测算法。此算法利用序列图片匹配可以提高闭环检测的动态环境适应能力。文中首先选择在ImageNet数据集上预训练好的深度神经网络VGGNet的前5个卷积层来提取每张图像的高级抽象特征,然后构造出图像序列的相似度矩阵,最后基于动态规整算法计算出序列的相对相似度进行闭环检测;同时,详细比较了不同序列长度下得到的P-R曲线以及ROC曲线以确定最合适的匹配序列长度。
从实验结果可以看到,本文所提方法具有较高的准确率和召回率,并且假阳性概率较低,相较于主流方法FabMap及SeqSLAM算法,其性能更好。同时,序列长度分析实验结果表明,虽然不同长度的序列精度稍有差别,但只要选取合适的序列长度就可以提高闭环检测性能。因此如何选取合适的序列长度是我们未来的研究方向。
猜你喜欢
军民两用技术与产品(2022年3期)2022-06-05
纺织服装周刊(2022年16期)2022-05-11
物流科技(2022年2期)2022-05-07
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
航天工业管理(2020年9期)2020-12-28
小学生学习指导(低年级)(2020年10期)2020-11-26
作文大王·低年级(2017年11期)2017-12-05
