
基于BiLSTM-CNN模型的新闻文本分类
2021-09-23 07:20龚维印,韦旭勤
电脑知识与技术 2021年21期
关键词:文本分类
龚维印,韦旭勤
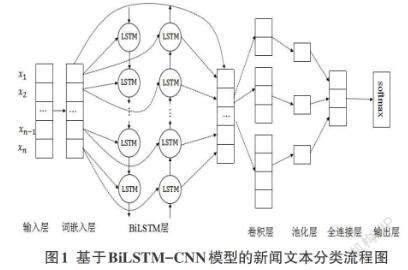
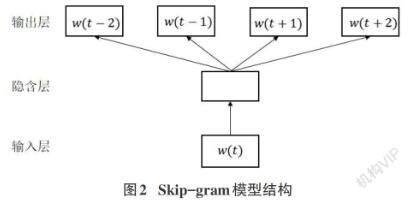
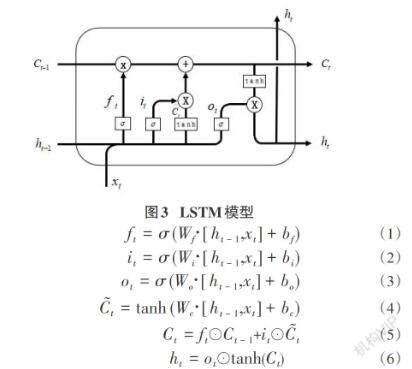
摘要:针对单一CNN网络在新闻文本分类中容易忽略上下文的语义信息,分类准确率低的问题,同时结合CNN和BiLSTM的优点,提出一种基于BiLSTM-CNN模型的新闻文本方法。该模型先使用Word2Vec中的Skip-gram模型对数据中的词进行映射处理,转换为固定维度的向量;再利用BiLSTM捕捉双向的语义信息;最后将BiLSTM模型提取的特征与词嵌入的特征进行拼接作为CNN的输入,使用大小为2,3,4的卷积核进行卷积。在THUCNews和SougouCS兩个公开的数据集上进行实验,实验结果表明,融合的BiLSTM-CNN模型在新闻文本分类效果上优于BiLSTM、CNN模型。
关键词:文本分类;CNN;BiLSTM;Word2Vec
中图分类号:TP391.1 文献标识码:A
文章编号:1009-3044(2021)21-0105-03
开放科学(资源服务)标识码(OSID):
News Text Classification Method Based on BiLSTM-CNN Model
GONG Wei-yin,WEI Xu-qin
(School of Mathematics and Computer Science, Liupanshui Normal University, Liupanshui 553004, China)
Abstract: To solve the problem that a single CNN network is easy to ignore the semantic information of context in news text classification and the classification accuracy is low. At the same time, combined with the advantages of CNN and BiLSTM, a news text method based on BiLSTM-CNN model is proposed. The model uses the Skip-gram model in the Word2Vec to map the words in the data and convert them into fixed dimension vectors, and then uses the BiLSTM to capture bidirectional semantic information. Finally, the features extracted from the BiLSTM model are spliced with the embedded features as the CNN input, and the convolution kernel is used. the experiment is carried out on two open data sets of THUCNews and SougouCS. the experimental results show that the fused BiLSTM-CNN model is superior to the BiLSTM、CNN model in the classification effect of news text.
Key words: Text Classification; Convolutional Neural Network; Bi-directional Long Short-Term Memory; Word2Vec
1 引言
在互联网及电子产品发展的同时,电子新闻也成为人们获取信息的重要来源。面对日益呈爆炸式增长的电子新闻文本数据,造成信息过量而知识匮乏的现象。因此,如何将海量杂乱无章的数据进行高效管理,从中快速挑选出具有价值的文本信息?这就凸显了文本分类技术的重要性。
文本分类即是指通过特定的学习机制,学习大规模分类样本数据的潜在规则,再根据该规则将新的样本分配到一个或多个类别里面。其主要流程有数据预处理,文本表示,特征提取和分类器的构建等。传统的文本分类通常是将词袋法(Bag-of-Word)与机器学习算法相结合,其词袋法则是把每篇文档看作由多个词组成,词与词之间相互独立,忽略其语法、语序和语义信息[1],但是基于词袋法的文本分类存在特征维数高,数据稀疏等问题,无法准确表示上下文语义信息。文本分类中常用于分类器构造的机器学习算法有:支持向量机(SVM)[2]、K-最近邻(KNN)[3]和朴素贝叶斯(NB)[4]等分类算法。
现今社会高速发展,大数据时代已稳步前进,其深度学习在图像处理、语音识别等复杂对象中取得的优异成绩。而众多研究者早已将深度学习应用到自然语言处理中。面对海量的文本数据,2013年谷歌提出Word2Vec词向量工具,能够将高维的词向量映射到固定维度的空间。Kim等人[5]于2014年通过Word2Vec训练词向量,使用词嵌入的方法将文本中的词转换为固定维度的词向量矩阵,然后将其作为卷积神经网络的输入,最后使用不同尺寸的卷积核进行局部特征提取,有效证明词向量的有效性。同年,Kalchbrenner等人[6]根据MaxPooling的原理设计了K-MaxPooling池化,即设置一定大小的滑动窗口,在每次滑动过程中提取特征值排名靠前的K个特征值,此方法逐渐应用到各个领域。Zhou等人[7]于2015年考虑上下文的语义信息,弥补了CNN上下文信息缺失的问题,结合CNN和LSTM的优点,将其应用到文本情感分析中,这一研究取得了较好的效果。
猜你喜欢
计算机应用(2016年12期)2017-01-13
电子技术与软件工程(2016年22期)2016-12-26
电脑知识与技术(2016年23期)2016-11-02
科教导刊·电子版(2016年23期)2016-10-31
科技视界(2016年24期)2016-10-11
