
GRAPES-GEPS 环流集合预报的分类释用方法研究与检验*
2021-09-18 03:57:40罗月琳陈权亮蔡宏珂任宏利
气象学报 2021年4期
罗月琳 高 丽 陈权亮 蔡宏珂 任宏利
1.成都信息工程大学,大气科学学院,成都,610225
2.国家气象中心,中国气象局数值预报中心,北京,100081
3.国家气候中心,气候研究开放实验室,北京,100081
4.中国气象科学研究院,灾害天气国家重点实验室,北京,100081
1 引言
集合预报是为了减少由初值误差、模式误差和大气系统混沌特性引起的数值预报的不确定性,根据某种误差概率分布生成的数据集,制作出与之相对应的一组预报集合,这一方法就是集合预报方法(麻巨慧等,2011)。与传统的“单一”确定性数值预报不同,集合预报的初值不是“一个”,而是满足某一误差概率分布的初值数据集,因此其预报结果是“一组”(或“一集”)。这就为解决“单一”数值预报存在不确定性的问题提供了一条有效途径(李泽椿等,2002)。
在Epstein(1969)和Leith(1974)提出集合预报思想近20 年以后,20 世纪90 年代初,集合数值预报进入了实际业务应用阶段。世界上较为先进的国家陆续基于自己的模式发展了集合预报系统,随着美国国家环境预报中心(NCEP)和欧洲中期天气预报中心(ECMWF)于1992 年先后把集合预报系统投入业务运行,随后几年,欧美等发达国家的气象部门也相继建立了各自的业务集合预报系统(杜钧,2002;麻巨慧等,2011)。相比之下,中国开展集合预报研究和业务应用,尤其在产品的解释应用方面,略显滞后和技术薄弱(李泽椿等,2002;陈起英等,2004;关吉平等,2006)。中国学者陆续开展了有关集合预报扰动方法的研究(张涵斌等,2014a;Zhang,et al,2015;Xia,et al,2020),国家气象中心于1995 年安装了从美国进口的IBM/SP2 巨型并行计算机,为中国开展集合数值预报提供了硬件基础,并进一步于1996 年采用时间滞后平均法(LAF)(Hoffman,et al,1983;张兰等,2019)建立了基于T63L16 模式的第一代中期集合预报系统;在此基础上于1999 年以奇异向量法(SV)(Buizza,et al,1995;Winkler,et al,2020;叶璐等,2020)取代时间滞后法,建立了第二代中期集合预报系统,使用低分辨率的T21L16 生成奇异向量;1999 年底,基于国产神威巨型计算机平台建立了第三代中期集合预报系统,预报模式T106L19 投入准业务运行。随后采用增长模繁殖法(BGM)(Toth,et al,1997;闵锦忠等,2017)扰动初值生成技术,形成了中国新一代全球中期数值预报业务系统(T213L31),于2002 年3 月投入准业务运行,并于2002 年9 月正式业务化,成为中国新一代中期数值预报业务系统。2005 年底在T213L31 模式基础上建立了全球集合预报系统— GEPS-T213,并于2006 年12 月实现了准业务化运行。2010 年将GEPS-T213 模式成功升级为T639 全球模式,T639 全球集合预报系统(制作全球模式1—15 d 集合预报)于2014 年8 月正式投入业务运行(高丽等,2019)。中国气象局发展的新一代非静力数值预报模式—GRAPES,是中国面向天气预报业务应用的重要创新研究成果,其研发成功及业务应用标志着中国建立并形成了比较完善的数值天气预报业务体系。GRAPES 包含区域及全球两个版本,其中区域(GRAPES_Meso)版本已于2010 实现业务运行。王太微(2008)基于GRAPES 区域模式,采用集合变换卡尔曼滤波法(ETKF)(庄照荣等,2011;马旭林等,2015)和BGM 两种初值扰动方法进行集合预报试验,结果表明两种方案均具有一定的概率预报技巧,基于BGM 方法的集合预报离散度及降水预报效果略好于集合变换卡尔曼滤波法。目前GRAPES 全球集合预报系统已于2018 年底正式投入业务运行,集合成员增至31 个,为进一步开展集合预报应用提供了可能(张涵斌等,2014b;霍振华等,2020;高丽等,2020)。
从业务预报的角度出发,要让预报员在短时间内从大量集合预报结果提取所需信息是非常困难的(金荣花等,2007)。集合产品的释用就需要对预报结果进行处理、合成、压缩。目前,集合预报主要有3 类产品:集合平均预报、大气可预报性的预报(潘留杰等,2014;孙令东,2018)和概率预报(Stanski,et al,1989;Ji,et al,2019)。聚类分析法最初是用于集合预报产品分析的一种方法,把集合预报中相似的成员合并成一类,同时给出该类出现的相对频率,较为适合于经验不多的预报员。在实际预报中,环流形势预报对于预报员具有重要价值,而环流集合预报分类释用研究仍相对较少。为此,文中将对GRAPES-GEPS 环流集合成员开展聚类分析研究。ECMWF 先后采用Ward 聚类法(Ward,1963)和管子法(Atger,1999)对集合预报产品进行聚类;NCEP 采用距平相关系数分簇法对500 hPa 高度场进行分簇;法国气象局采用Diday提出的动力模糊法,初始划分时的重心由天气类型定义,划分用到的距离是位移和最大相关法(杨学胜等,2001,2002);瑞典气象局使用神经元聚类法,这种方法基于神经网络原理;日本气象厅利用中央聚类法进行聚类分析(金荣花等,2007)。中国已有学者利用聚类法对集合预报进行分类研究。杨学胜(2002)运用位移和最大相关距离法对ECMWF集合预报产品进行了分类,结果表明该系统对影响法国的平直型、热阻塞型、扰动型等500 hPa 天气形势预报效果比较好,而对波动型的天气形势预报效果稍差;金荣花等(2007)研究显示基于Ward 聚类法的T213 集合预报系统的分类产品,能够有效识别出最有可能发生的环流形势演变和调整,给预报员提供有价值的预报信息;王太微等(2015)利用最远距离法对ECMWF 集合预报产品进行分类,发现经过聚类分析后的集合预报较好地改善了降水落区和强度预报效果,降水预报评分均比业务预报的评分高,且集合离散度也较大。王太微等(2016)利用Ward 聚类分析法将50 个ECMWF全球集合预报成员分成4 组,分析了一次辽宁地区强降水过程,结果表明聚类分析在集合预报中的应用是可行的,可以提高预报员的效率。
目前,对于中国新一代业务集合预报系统,尚未开发和使用集合预报聚类产品。中国对于业务集合预报的应用一般采用集合平均作代表,对于集合聚类的研究工作较少,而后者对于集合产品的使用具有重要意义。通过对比分析,能够直观和定量体现出集合聚类结果相对于集合平均的优势。然而,中国目前的研究都是事先给定聚类数目,因此就有可能会导致聚类到后期时将两个不相似的类别合并在一起,并且没有给出定量化检验评分。因此,本研究利用GRAPES-GEPS 业务化以来实时输出集合成员数据开展500 hPa 位势高度场的集合预报产品的聚类分析,拟解决集合预报的动态聚类分析及检验评分。进一步针对中国新一代业务集合预报系统开展集合分类释用方法和检验评价研究。
2 资料及方法
2.1 模式和资料介绍
所用模式预报资料来自于中国气象局数值预报中心发展的GRAPES全球集合预报系统(GRAPESGEPS)。该系统是GRAPES 模式体系的重要组成部分,已于2018 年年底在中国气象局数值预报中心实现实时业务运行,其格点空间的水平分辨率为1°×1°,包含31 个成员(1 个对照预报和30 个集合成员),间隔24 h 预报一次,一共15 d 的预报。本研究采用GRAPES-GEPS 在2019 年1 月至2020 年6 月全国范围内的500 hPa 高度场资料,预报时效分别为24、48、72、96、120、144 h,共6 d。
为了保持与模式预报资料空间和时间分辨率的一致性,500 hPa 高度场的分析场采用的是同一时段由ECMWF 中ERA5 再分析资料给出的500 hPa高度场作为本研究的分析场资料进行模式气候与观测气候差异的对比分析。该资料分辨率1°×1°。
2.2 Ward 聚类计算方法
Ward 聚类分析法(昌霞等,2019)是利用离差平方和来计算距离的一种聚类分析方法。聚类时首先使k个样本各自成一类,然后样本之间离差平方和最小的两个样本合并成一类。该方法总是使得聚类导致的类内离差平方和增量最小,其思想源于方差分析,如果类分得好,同类样本的离差平方和应当小,类与类之间的离差平方和应当较大。因此,Ward 聚类法强调找出集合预报中的相似要素。该方法的主要计算公式如下:
第K个成员和第J个成员的距离(DK,J)为

第L个成员与K、J合并成一组的类之间的距离()为
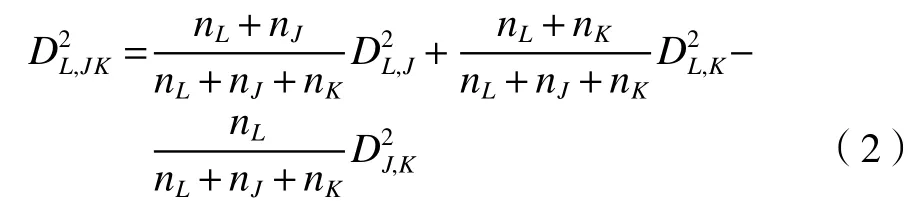
式中,Xi表示在第i簇类聚类点的数值,ni为第i簇类的样本数。
当集合预报分为n个类时的类间误差平方和(S)为

式中,Ci是第i个簇,p是Ci中的样本点,mi是Ci的质心(Ci中所有样本的均值),S是集合样本的误差平方和,代表了聚类效果的好坏。ΔS为当分为n个类及n−1 个类时的误差平方和的差值,S总为总的误差平方和。
Ward 聚类方法步骤:①首先利用式(1)求每个集合成员样本之间的距离,输入距离矩阵,将距离最小的两类归并为一类。此时,成员样本数减少至k−1。②再利用式(2)重新计算集合成员样本之间的距离,将距离最小的进行合并。③重复步骤②直到聚类数达到要求,停止循环。
2.3 引入动态聚类的分类释用方法
现有绝大部分聚类方法通常需要事先给定聚类数目,在实际工作中需要根据经验或相关领域背景知识来设定。由于聚类过程中,样本一旦被分配过,就不能再做类间的移动,这可能使初始错误的选择贯穿于整个聚类过程中,从而导致聚类结果的不可靠。那么,当聚类数目未知时,如何确定数据集的聚类数目是聚类分析研究的一项基础性难题。
基于现今最佳聚类数k值的研究(宋媛,2013;王建仁等,2019),利用“手肘法”判断最佳聚类数k值,该方法评价k值好坏的标准是误差平方和,即运用式(3)计算出不同k值对应的误差平方和。因为不同预报时效对应的总误差平方和取值范围不同,很难同时进行比较,因此引入一个判定系数R2,取值范围0—1。手肘法的核心思想是:随着聚类数k增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,R2自然会逐渐变小。当k处于最佳聚类数时,由于k的增大会大幅度增加每个簇的聚合程度,故R2下降幅度会很大,而当k到达最佳聚类数时,再增加k所得到的聚合程度回报会迅速变小,所以R2下降幅度会骤减,然后随着k值的继续增大而趋于平缓,即R2和k的关系图是一个手肘的形状,而这个肘部对应的k值就是数据的最佳聚类数。图1 给出了利用环流数据计算的R2随着k值变化的实例。
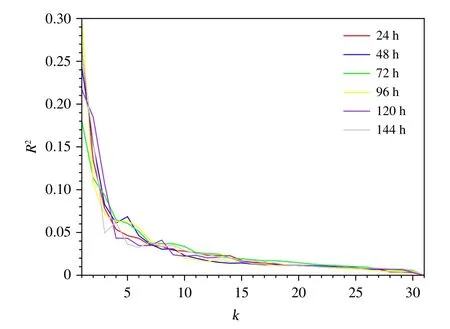
图1 2019 年5 月20 日00 时(世界时)环流数据计算的R2 随着不同k 取值的变化(不同颜色线代表各个预报时效)Fig.1 R2as a function of k using circulation data at 00:00 UTC 20 May 2019(Different color lines represent different forecast times)
为此,在传统Ward 聚类法中通过引入动态聚类的“手肘法”方案,发展了环流集合预报分类释用方法。利用Ward 聚类法对GRAPES-GEPS 业务集合预报产品进行分类,并计算出误差平方和,通过对大量样本不同个例不同预报时效的计算,在确定最佳聚类数时,发现k的最佳取值多在4—6,并且大多数情况k=5。然而通过对聚类结果的观察,当k=5 时,仍有部分类别比较相似,因此需要进一步合并。因为Ward 聚类分析法倾向于将一个成员分配到一个样本数较少的集群中,所以其结果是集群内部的方差相当。出于同样的原因,当聚类到后期的时候,表现出重要差异的成员往往会聚集在一起,即Ward 聚类方法的聚类效果是有限的,当聚类到后期,所使用的最小距离原则将不再适用。因此引入距平相关系数法进行最终判断k=5 时是否需要继续进行合并,此方法是5 个类别之间相互计算距平相关系数,将距平相关系数最大(大于0.95)的两类进行合并,然后再次计算类与类之间的距平相关系数,直到类与类之间的相关系数均小于0.95 时停止合并。
2.4 预报检验方法
目前已经发展了多种针对确定性预报的检验评价方法。一次或少数几次的单一确定性预报可以明确地针对某次天气过程的预报进行检验,但不能反映集合预报方法的整体预报效果,因此必须采用统计的方法,要有足够大的样本数才能反映整体的预报效果。为了全面分析预报方法的预报能力,针对500 hPa 位势高度场集合预报聚类结果中集合分类和集合平均的预报能力,采用常见的确定性预报检验的距平相关系数(ACC)和均方根误差(RMSE)进行效果检验,距平相关系数是用来衡量两个场的形态是否一致,其数值越大两个场的形态越相似;均方根误差是用来衡量两个变量之间平均差异的一个参数,表示的是两个变量的平均偏离程度,其值越小两个变量的偏离程度越小。
3 500 hPa 高度场的集合预报聚类应用个例
3.1 2019 年5 月26—29 日个例过程介绍
这里首先以一次典型过程为例来展示聚类分析结果。2019 年5 月26—29 日,中国长江以南地区出现大范围强降水天气过程,长江中下游,江南南部、华南和西南东部地区累计降水量普遍在50 mm 以上,其中湖北南部、安徽南部、浙江北部、广西西部、广东大部分地区为主要降水大值区,累计降水量超过100 mm,局地达到200 mm。区域强降水主要影响时段为26—27 日。图2 给出5 月26 日12 时(世界时,下同)至29 日00 时逐12 h 的500 hPa 分析场,为观察环流场形势配置变化在图中将5640 dagpm 等值线设置红色。可以看出,26 日12 时(图2a)中高纬度地区有一短波槽影响江淮东部和西南地区西部,随后高空冷涡控制中国东部沿海地区,切变线东移维持,低层水汽持续供给,继续影响整个江南和华南地区,增大累计降水量。从逐12 h 分析场环流形势演变来看,此次强降水过程,主要是高空冷涡东移入海造成的。短波槽从西北向逐渐转为南北向,槽后偏北气流增大,引导高纬度地区极地冷涡南下,28 日00 时(图2d)直抵东北地区形成高空冷涡。高空冷涡东移维持,低层水汽持续供给,继续影响整个江南和华南地区,增大累计降水量,直至29 日降水过程结束。通过对大量样本不同个例不同预报时效进行聚类分析发现,集合预报聚类结果中预报时效24 和48 h 的聚类分析结果大多数为一类或两类,分类效果并不明显,因为对于较短的预报时效来说,即初始误差微小增长不大的情况下,可以认为预报具有“确定性”,此时认为集合成员的预报质量相对较高,而集合离散度小,聚类效果不明显;在较长的预报时效中,预报轨迹可以发散到较大的区域,预报具有“随机性”(李小泉等,1997)。因此,接下来将分别展示预报时效为72、96 和120 h 的集合预报聚类结果。

图2 2019 年5 月26 日12 时至29 日00 时间隔12 h(a—f)的500 hPa 环流形势分析场Fig.2 500 hPa geopotential height analysis with an interval of 12 h from 12:00 UTC 26 May to 00:00 UTC 29 May 2019(a—f)
3.2 个例集合预报聚类分析结果
图3—5 分别给出的是预报时刻均为5 月28 日00 时但起报时刻不同的集合预报聚类结果的对比:集合预报起报时刻分别为2019 年5 月25 日00 时的72 h 预报、24 日00 时的96 h 预报和23 日00 时的120 h 预报,选取聚类区域为(30°—60°N,100°—150°E)。如图3 所示,72 h 预报的集合聚类结果分成两类,分别代表着不同的大气环流形势配置。与5 月28 日00 时的分析场(图2d)对比,预报发生概率最高的称为集合大类(图3a,发生概率为0.903),其代表的环流形势配置和主要系统形态与分析场可能更为相似,环流形势配置短波槽呈南北走向,呈小倒“Ω”形,盘旋在中国东部沿海上空,引导槽后暖湿气流往南发展,造成此次强降水天气过程。发生概率次之的集合第二类(图3b,发生概率为0.097),其代表的短波槽呈偏西南走向,但短波槽的深度和位置远不及集合大类与分析场的相似程度。最后,图3c 所代表的集合平均预报场,环流形势配置与图3a 的集合大类高度相似,两者与分析场相比难以分辨哪个预报效果更好,需要给出定量化检验评分。

图3 2019 年 5 月 25 日 00:00 UTC 起报的 72 h集合预报的聚类分析(a、b,分别代表聚类分析的第 1、2 类;右上角为每一类的发生概率)和集合平均(c)结果Fig.3 Cluster analysis(a,b,1−2 categories of cluster analysis,respectively;the upper right corner is the probability of each category)and ensemble mean(c)results of 72 h ensemble forecast at 00:00 UTC 25 May 2019
图4 给出96 h 预报的聚类结果是最终分成5 类,分别代表不同的环流形势配置。对比分析场(图2d)来看,聚类中预报发生概率最高的集合大类(图4a,发生概率为0.581)所代表的环流形势配置和主要系统的形态与分析场更相似,高空冷涡配置呈较明显的倒“Ω”型,位置较分析场略偏北,短波槽呈南北向,深度不及分析场(图2d)。发生概率次之的第2 类(图4b),短波槽呈偏东南走向、且明显弱于分析场。在第3 类(图4c)中高空冷涡配置虽呈倒小“Ω”型,但范围明显小于分析场、且短波槽呈西南走向。而在图4d 的第四类中,其短波槽位置偏北、且明显弱于分析场。发生概率最小的图4e高空冷涡配置呈倒“Ω”型,但位置明显较分析场偏西。所以,整体上,集合大类与分析场的短波槽深度最为接近。集合平均(图4f)的环流形势配置与图4a 集合大类(图4a)相比,前者的高空槽强度不及后者。
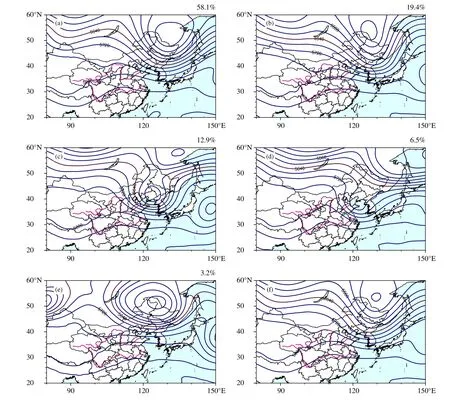
图4 2019 年5 月24 日00 时起报的96 h 集合预报的聚类分析(a—e,分别代表聚类分析的第1—5 类;右上角为每一类的发生概率)和集合平均(f)结果Fig.4 Cluster analysis(a—e,1—5 categories of cluster analysis,respectively;the upper right corner is the probability of each category)and ensemble mean(f)results of 96 h ensemble forecast at 00:00 UTC 24 May 2019
图5 给出的120 h 预报的集合聚类结果分成4 类,分别对应不同的环流形势配置。如图5a 所示的集合大类发生概率为0.581,作为集合大类可能具有更高的信度,高空槽强度与分析场(图2d)较为接近,位置稍偏北,跨越的纬度与分析场一致,但强度不及分析场。相比之下,作为集合第2 类(图5b),高空槽呈西南走向,强度不及集合大类与分析场相似,第3 类(图5c)高空槽的位置比分析场更偏西,呈西南走向,主体形状与分析场表现出明显差异。发生概率最小的第4 类(图5d),无论是高空槽的位置还是主体形状,均与分析场差别明显。在集合平均(图5e)中,环流形势配置与第1 类较为相似,但高空槽相对较弱,这显然与集合平均对振幅的削弱作用有关。
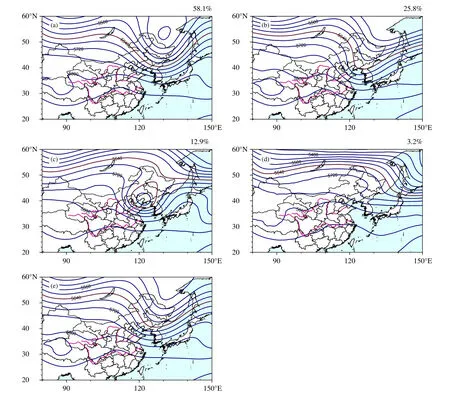
图5 2019 年 5 月 23 日 00:00 UTC 起报的 120 h集合预报的聚类分析(a—d,分别代表聚类分析的第 1—4 类;右上角为每一类的发生概率)和集合平均(e)结果Fig.5 Cluster analysis(a−d,1−4 categories of cluster analysis,respectively;the upper right corner is the probability of each category)and ensemble mean(e)results of 120 h ensemble forecast at 00:00 UTC 23 May 2019
总体来看,就这个被选取的典型个例而言,集合预报聚类结果在给出比重最大的类别和其他比较小类别的情况下,集合大类的预报效果比其他类别更好,且集合大类和集合平均预报效果相当,但其他聚类次大类在实际预报中也不可忽视,小概率类别也有可能对应极端事件的发生。由此可见,集合预报信息中的集合大类相比于其他类与观测场更为相似,少数情况下,所占比重更小的类别预报更准确,所以在实际应用中发生概率最高的第1 类通常具有高于其他类别的预报技巧,但相较于集合平均而言仍需给出定量化的检验评分。
4 集合聚类预报的综合检验分析
在个例分析基础上,为了验证集合大类相比于集合平均具有更高的预报技巧,综合对比不同个例在不同预报时效的效果,选取该模式系统业务化以来2019—2020 年期间10 个个例(具体个例过程的描述参见表1),每个个例选取两个起报时刻,这两个预报时刻高空槽都正好位于中国中东部地区,预报区域均为(30°—60°N,100°—150°E),对选取的两个时刻运用不同集合预报起始时间做聚类分析,并将集合大类与集合平均预报分别进行确定性评分ACC 和RMSE 检验,最后将这10 个个例的各自检验结果取算术平均得到综合检验分析结果。
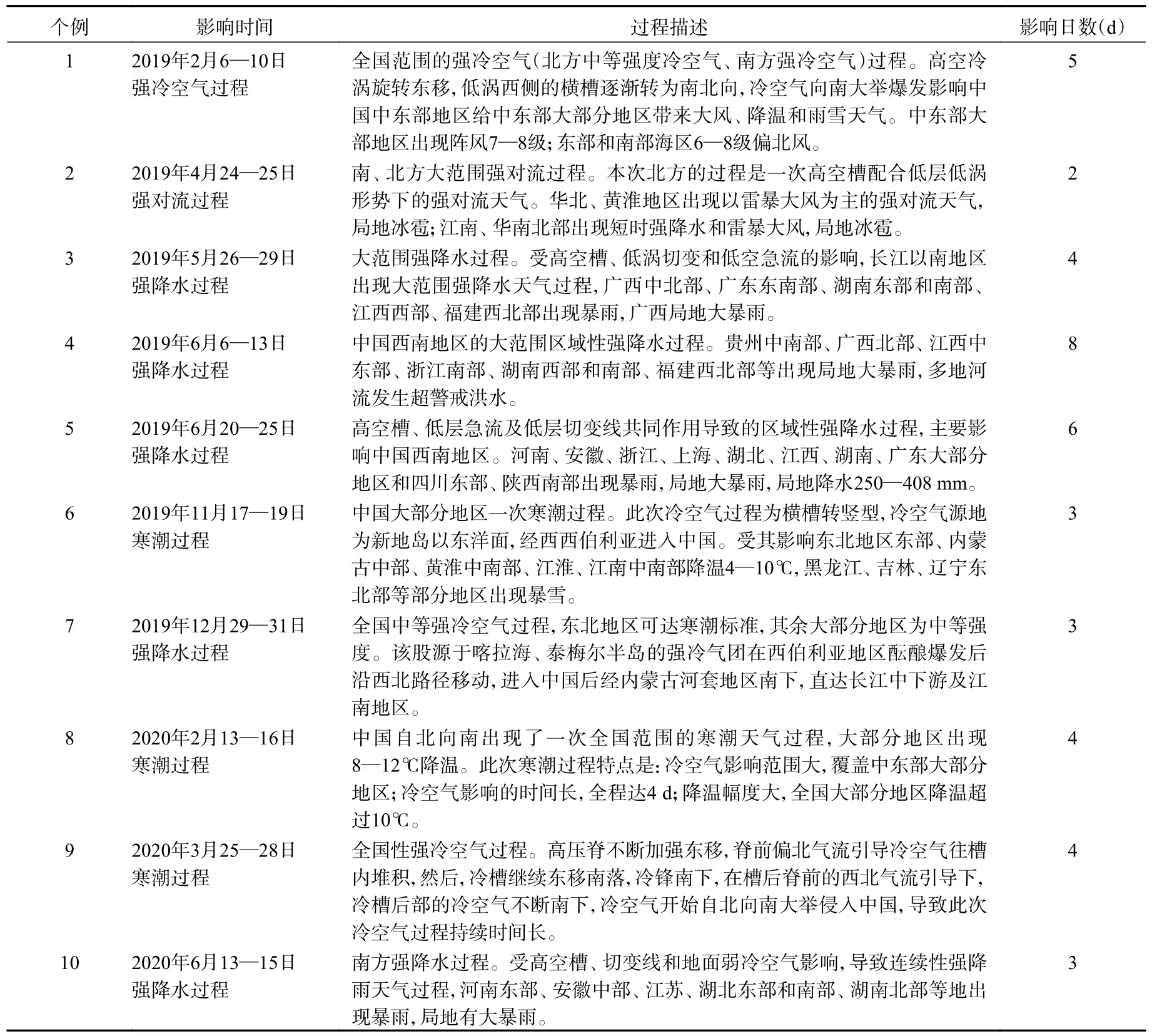
表1 10 次个例的影响时间及过程描述Table 1 Influence time and process description of 10 cases
4.1 距平相关系数检验结果
图6 给出了不同预报时效的集合大类和集合平均预报与分析场的距平相关系数。相关系数越大,说明预报和实况的空间型相似度越高,预报技巧越高。从图6可以看出,距平相关系数随着预报时效的延长呈现自然下降趋势,这反映出集合预报的确定性预报效果随着预报时效延长而下降。但很明显,集合大类预报技巧的下降要比集合平均缓慢得多。在24及48 h 的预报中,集合预报成员之间仍然较为聚集、发散度较小,在预报时效较短的情况下,预报具有“确定性”,预报质量相对较高,可能导致聚类后的最终分类数较少,大多数情况下集合大类与集合平均非常接近,因此二者预报的距平相关系数差异较小,只是集合大类预报技巧略高一些。相比之下,当预报时效达到72—144 h 时,集合预报成员已经充分发散,此时集合聚类倾向于离散成若干个有差别的类。从图中可以看到,在72 h 预报时效以后,集合大类预报与实况的距平相关系数明显比集合平均预报的更大,即发生概率最高的集合大类具有明显高于集合平均的预报技巧。

图6 集合大类(红线)和集合平均(蓝线)预报分别与实况场的距平相关系数Fig.6 ACC of the analysis and forecasts for the primary cluster(red line)and ensemble mean(blue line)forecast,respectively
4.2 均方根误差检验结果
图7 进一步给出集合大类和集合平均预报与实况场的均方根误差随预报时效的变化情况。均方根误差越大,两者相似度越低。可以看到,均方根误差随着预报时效延长呈现增大趋势,这表明集合预报整体的预报效果是随着预报时间的延长而趋于变差的。总体来看,在最初的24 及48 h,由于集合成员尚未充分离散开,导致最终分类数少,集合聚类中的大类预报与集合平均预报差别微小;而在72—144 h 的预报中,集合大类预报的优势愈发显著,其与实况场的均方根误差增长幅度比集合平均预报的小很多,即在500 hPa 位势高度场集合预报聚类结果中集合大类的均方根误差要比集合平均明显减小,这与距平相关系数的检验结论一致,集合大类预报比集合平均具有更好的预报效果。
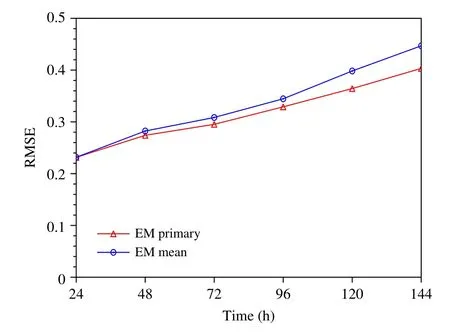
图7 集合大类(红线)和集合平均(蓝线)预报分别与实况场的均方根误差Fig.7 RMSE of the analysis and forecasts for the primary cluster(red line)and ensemble mean(blue line)forecasts,respectively
综上,两种确定性预报检验评分(距平相关系数和均方根误差)所体现的集合聚类预报效果总体结论较为一致,即对于中国中东部地区500 hPa 位势高度场而言,集合大类预报综合检验效果优于集合平均,且能给出与之相对应的发生概率,这是后者所不具备的。图8 展示了10 个例在72—144 h时效平均的距平相关系数和均方根误差评分情况,并对集合大类与集合平均进行了对比。可以看到,绝大多数个例的集合聚类大类预报相比于简单的集合平均具有更高的距平相关系数和更小的均方根误差,显示出集合分类释用方法具有较为稳定的预报性能。当然,某些个例仍可能出现集合平均比集合大类预报技巧更高的情况,例如图8a 第9 个例及图8b 第7 和第9 个例。但整体上集合大类预报与实况场的相似度要比集合平均更高,即在实际中发生概率最高的第1 类通常具有高于集合平均的预报技巧。
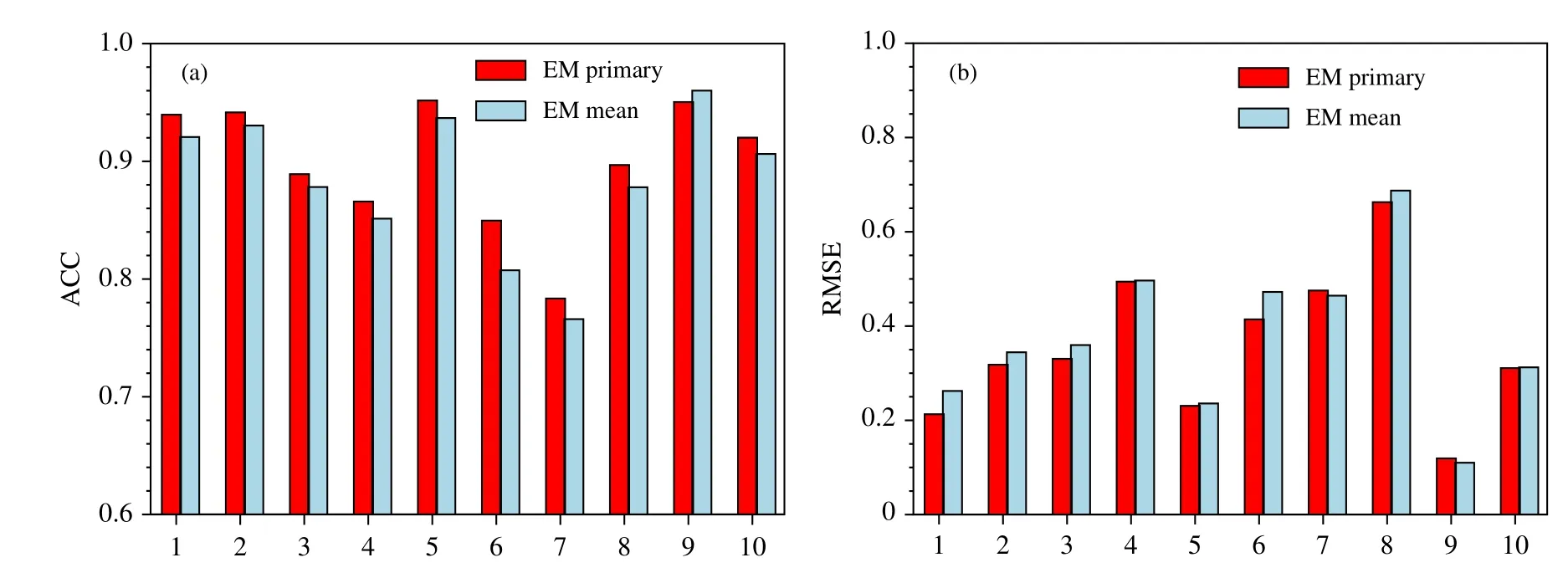
图8 10 个例在72—144 h 时效平均的距平相关系数和均方根误差(a.距平相关系数,b.均方根误差)Fig.8 Average ACC and RMSE scores of 10 cases at 72—144 h forecast lead time(a.ACC,b.RMSE)
4.3 距平相关系数和均方根误差连续时间检验结果
为了验证文中提出的聚类分析方法是否能在连续时间的检验评估结果上与个例分析结果保持一致,图9 分别给出了2019 年1 月—2020 年6 月连续时间的平均距平相关系数和均方根误差的检验结果。从图9 看,距平相关系数随着预报时效的延长呈现减小趋势,这反映出集合预报的确定性预报效果随着预报时效延长而下降,且随着预报时效延长集合大类与分析场的距平相关系数预报技巧相对于集合平均预报更具有优势。均方根误差所体现的集合聚类预报效果总体结论与距平相关系数较为一致,即发生概率最高的集合大类具有高于集合平均的预报技巧。连续性时间检验相较于典型个例的检验结果改进没有那么显著,这一方面与参与计算评分的样本数大量增加有关,而且也反映出,聚类分析对于有明显天气过程发生时更有显著优势。

图9 2019 年1 月至2020 年6 月逐日输出的集合大类(红线)和集合平均(蓝线)预报分别与实况场的距平相关系数和均方根误差Fig.9 ACC and RMSE of the analysis and forecasts for the primary cluster(red line)and ensemble mean(blue line)forecasts based on daily outputs from January 2019 to June 2020
此外,对比分析了聚类效果不理想个例以说明集合预报聚类应用的不足。2019 年4 月24—26 日受高空东移的短波槽影响,中国北方和南方同时发生较大范围的强对流天气过程,主要影响时段在24—25 日。从分析场看,本次过程由一次高空槽配合低层低涡形势而发生。自24 日起,短波槽在东移过程中逐渐加强,与南支槽相连。随着高空槽的东移,至25 日白天,此次过程趋于结束。选取这次过程集合预报起始时刻为2019 年4 月21 日12 时,分析72 和96 h 的集合预报聚类。对比同时次集合预报的聚类结果与分析场发现,集合平均预报能够较好描述大尺度环流形势的演变特征,但对此次过程预报的强度偏弱,冷空气移动的路径偏北、偏东。预报效果最好的类别并不是聚类分析的第1 类或者第2 类,说明在集合预报聚类结果中对于影响时间短、强度较弱的对流性天气预报可能仍然具有一定局限性,需要进一步针对此类降水开展研究。
5 结论
系统性介绍了中外集合预报业务系统中所使用的集合预报聚类分析方法,借鉴中外已有的技术和经验以及进行实际对比试验,在传统Ward 聚类分析中引入了动态聚类判别方案,发展了适用于中国GRAPES-GEPS 环流集合预报的分类释用方法,进一步利用实时业务集合预报数据检验了集合预报聚类结果在2019—2020 年中东部地区重要天气过程个例中的预报效果,目的是通过对集合业务预报进行聚类和释用研究,寻求客观识别最有可能发生的环流形势方法,提升集合预报信息利用率和预报准确度,为实际预报提供参考。
基于GRAPES-GEPS 实时集合预报的检验结果表明,经过聚类分析后的集合预报聚类分型能较好地识别出500 hPa 环流场最有可能发生的环流形势类型,并提供相对应的发生概率。通过比较集合大类和集合平均与实况场的相似度,以及经过定量化的距平相关系数和均方根误差确定性预报检验,结果表明,对于中国中东部地区,随着预报时效延长,经过聚类分析后得到的集合大类相比于集合平均的预报技巧有显著提高,即实际预报中集合大类比集合平均具有明显的优势。当然,在实际预报中次大类等其他类的作用仍不可忽视,例如在某些突发性的极端天气过程中可能会出现集合大类失去优势的情况。
目前国际上很多气象部门已将聚类分析法应用到实际业务中,随着中国自主集合预报系统和产品的业务化程度不断提升,开发基于集合预报聚类分析并开展相关的分类释用,成为一个很有前景的研究方向。由于聚类分析方法和集合预报系统本身仍可能存在的不足,使得分类释用方法在实际应用试验中还存在一些不够理想的地方,需要通过更多试验尝试对方法进行发展完善,并开展更为全面的检验评估。此外,由于天气形势和区域选择的不同,文中所用的Ward 聚类法不一定全部适用,还需要探索利用和改进其他类型的聚类分析方法,以满足中国在集合预报应用产品研究方面的发展需求,更好服务防灾、减灾工作。
猜你喜欢
中学生数理化·七年级数学人教版(2023年3期)2023-03-21 00:44:56
农业灾害研究(2022年8期)2022-10-01 08:25:38
中华养生保健(2020年7期)2020-11-16 01:14:30
西藏科技(2018年9期)2018-10-17 05:51:30
成都信息工程大学学报(2017年2期)2017-11-09 02:29:41
自动化学报(2017年2期)2017-04-04 05:14:28
高原山地气象研究(2016年2期)2016-11-10 06:06:43
现代农业科技(2016年5期)2016-10-20 00:35:00
西藏科技(2016年8期)2016-09-26 09:00:53
中学生数理化·七年级数学人教版(2016年2期)2016-05-30 21:20:57
