
基于BERT+BiLSTM+CRF深度学习模型和多元组合数据增广的渔业标准命名实体识别
2021-09-17 10:31杨鹤于红刘巨升杨惠宁孙哲涛程名任媛张思佳
大连海洋大学学报 2021年4期
杨鹤,于红,2*,刘巨升,杨惠宁,孙哲涛,程名,任媛,张思佳,2
(1.大连海洋大学 信息工程学院,辽宁省海洋信息技术重点试验室,辽宁 大连 116023;2.设施渔业教育部重点试验室,辽宁 大连 116023)
渔业标准化是提高渔业生产效益、提升水产品质量和保障渔业生产安全的重要手段之一,渔业标准文本是渔业标准化的载体,也是渔业生产人员获取渔业标准知识的主要途径[1]。为高效地获取渔业标准知识,需对渔业标准文本中命名实体进行识别。渔业标准命名实体识别是从渔业标准文本中识别“渔业标准号”、“渔业标准指标”[2]及“水产品名称”等命名实体。早期的命名实体识别任务主要采用基于规则和词典的方法[3],这类方法需要由有经验的专家总结规则,识别效果依赖于专家的经验,在数据量较少且不同专家总结的规则一致性较高的情况下效果较好。随着数据量的不断增加,规则提取工作量增大,保持规则一致性难度加大,基于规则和词典方法的识别效果无法满足人们的进一步需求,学者们提出了基于词典与条件随机场的命名实体识别方法[4],该类方法采用统计学习的方法统计语料库中文本信息的分布情况并进行命名实体识别。与基于规则方法相比,统计学习方法的性能取得了较大提升,但是由于此类方法需要手工选择特征,算法性能依赖于特征模板的结构,缺乏泛化能力。随着深度学习的发展,深度学习被应用于命名实体识别领域[5]。孙娟娟等[6]提出了基于深度学习的渔业领域命名实体识别,取得了较好的效果,但由于对渔业领域命名实体对象类别定义较为宽泛,识别的实体类别较少,该算法不适用于具有较多类别、实体结构较为复杂的渔业标准命名实体识别。为解决上述问题,程名等[7]在分析渔业标准文本特点的基础上,提出了融合注意力机制的BiLSTM+CRF(BiLSTM+Attention+CRF)渔业标准命名实体识别方法,在渔业标准命名实体识别任务中取得了较好效果。然而,由于渔业标准文本中“水产品名称”等类别实体数量少、样本分布不均匀,导致识别效果不够好,人工扩充语料库存在效率低、成本高,以及易造成错误传播等问题,因此,需要研究语料库自动扩充方法。目前,少样本命名实体识别主要包括数据增广[8-12]、模型迁移[13]、特征变换[14]和知识链接等方法,分别从准确性、易用性和优缺点等方面对这些方法进行比较,4种方法各有优劣,其中,数据增广方法是最有效的小样本数据扩充方法,该方法通过优先挑选高质量样本参与训练,达到扩充语料库的目的,此方法在特定领域命名实体识别任务中能获得较高的准确率[15]。程名[16]提出了基于改进EDA(easy data augmentation)的数据增广方法用于解决样本数量较少等问题,取得了较好的效果,但进行数据增广后实体上下文特征并未得到保护,造成实体特征缺失,影响了命名实体识别任务的识别效果。为了解决上述问题,需要研究有效的数据增广方法,确保在不丢失语义信息的基础上,进一步扩充语料数量,提升语料质量,增加样本多样性,提高命名实体识别的准确性和鲁棒性[17]。
为此,本研究中针对渔业标准命名实体识别任务的特点,以及部分目标实体样本数量较少、效果不好等问题,提出了多元组合数据增广的渔业标准命名实体识别方法,即在传统的同义词替换算法(synonym substitution)、随机删除算法(randomly delete)和随机插入算法(randomly insert)基础上进行改进,提出了基于领域词典的联合替换算法(joint replacement algorithm based on domain dictionary,DDR)、基于槽点保护的随机删除算法(random deletion algorithm based on slot protection,SPD)和基于槽点保护的随机插入算法(random insertion algorithm based on slot protection,SPI),将这3种算法进行多元组合,并使用基于融合注意力机制的BERT-BiLSTM-CRF网络模型对渔业标准文本进行命名实体识别,以提高识别的准确率。
1 基于多元组合数据的增广算法
在对渔业标准文本处理过程中,通过采样统计了渔业标准文本中各类实体的数量分布(表1),结果表明,“水产品名称”样本较少且特征不明显,模型无法学习较多特征,识别效果较差,仅有71%。
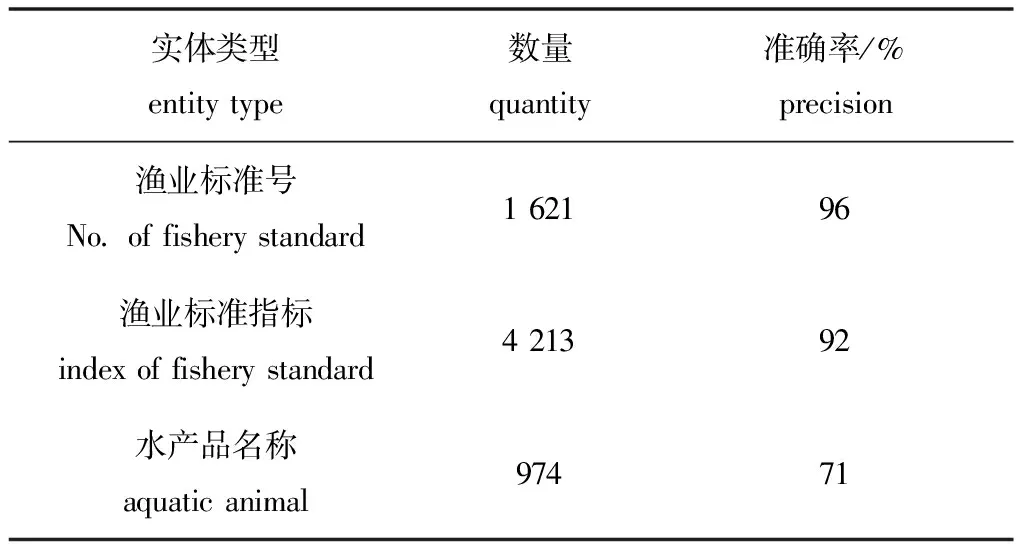
表1 实体数量情况
为了增加“水产品名称”实体的数量,采用数据增广的方法对“水产品名称”进行扩充。EDA方法是目前广泛使用的一类数据增广方法,主要包括4种方法,即对文本进行同义词替换、随机插入、随机交换、随机删除操作。使用基于同义词替换算法对渔业标准文本中的“水产品名称”进行数据增广,虽然提高了样本的多样性,但同义词替换未增加目标实体的数量,不能从根本上解决实体样本稀疏的问题。使用随机删除、随机插入方法虽然改变了句子结构、提升了模型泛化能力,但随机删除和插入会破坏句子中的目标实体和上下文特征,影响命名实体识别效果,因此,直接采用EDA方法进行渔业标准命名实体识别虽然可在一定程度上增加样本数量,但存在破坏语义信息等问题,导致识别效果不够好。针对以上问题,本研究中提出了基于多元组合数据的增广算法,同时采用基于领域词典的联合替换算法、基于槽点保护的随机删除算法和基于槽点保护的随机插入算法进行数据增广。
1.1 对传统同义词替换算法的改进
传统的同义词替换算法是在句子中随机抽取n个词,然后从同义词词典中随机抽取同义词进行替换。但使用传统的同义词替换方法会存在以下问题:
1)目前的分词方法存在一定的错误率,句子中的实体可能被错误切割,再经过同义词替换会造成错误传播,影响同义词替换的效果甚至消除语料库中原本的目标实体。
2)同义词替换后虽然能改变一定的句式结构,但未增加目标实体的数量,不能从根本上解决实体不足、语料稀疏的问题。
针对上述问题,提出了基于领域词典联合替换的数据增广方法。首先,根据领域词典构建“水产品名称”同类词词典和同义词词典;参照同类词词典和增广系数(N)对“水产品名称”类实体进行同类词替换;同时根据同义词词典对除目标实体外的随机词进行同义词替换,其中同类词替换只对目标实体进行替换,有效增加了目标实体的数量。对句子中的随机词进行同义词替换增加了句子的多样性,但未改变渔业标准的句子结构,符合渔业标准文本的行文规范。在不改变目标实体上下文特征和语义信息的情况下,使用基于领域词典的联合替换算法,增加了目标实体的数量和句子的多样性,有效解决了渔业标准命名实体识别样本稀疏问题。
同类词词典和同义词词典的结构如表2所示。基于领域词典的联合替换算法流程如图1所示。基于领域词典的联合替换算法示例如图2所示(设增广系数N=3)。
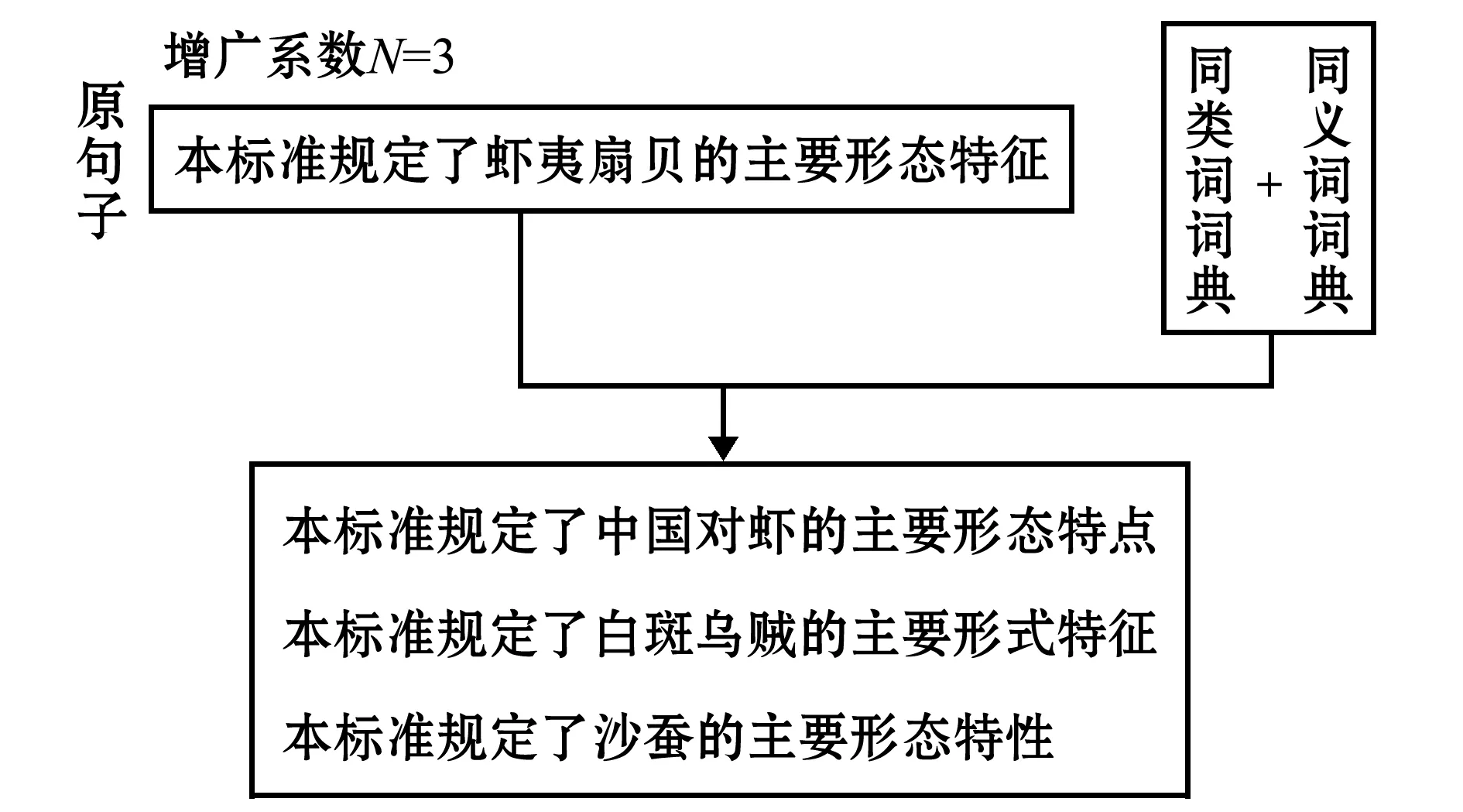
图2 基于领域词典的联合替换算法实例

表2 两个领域词典实例
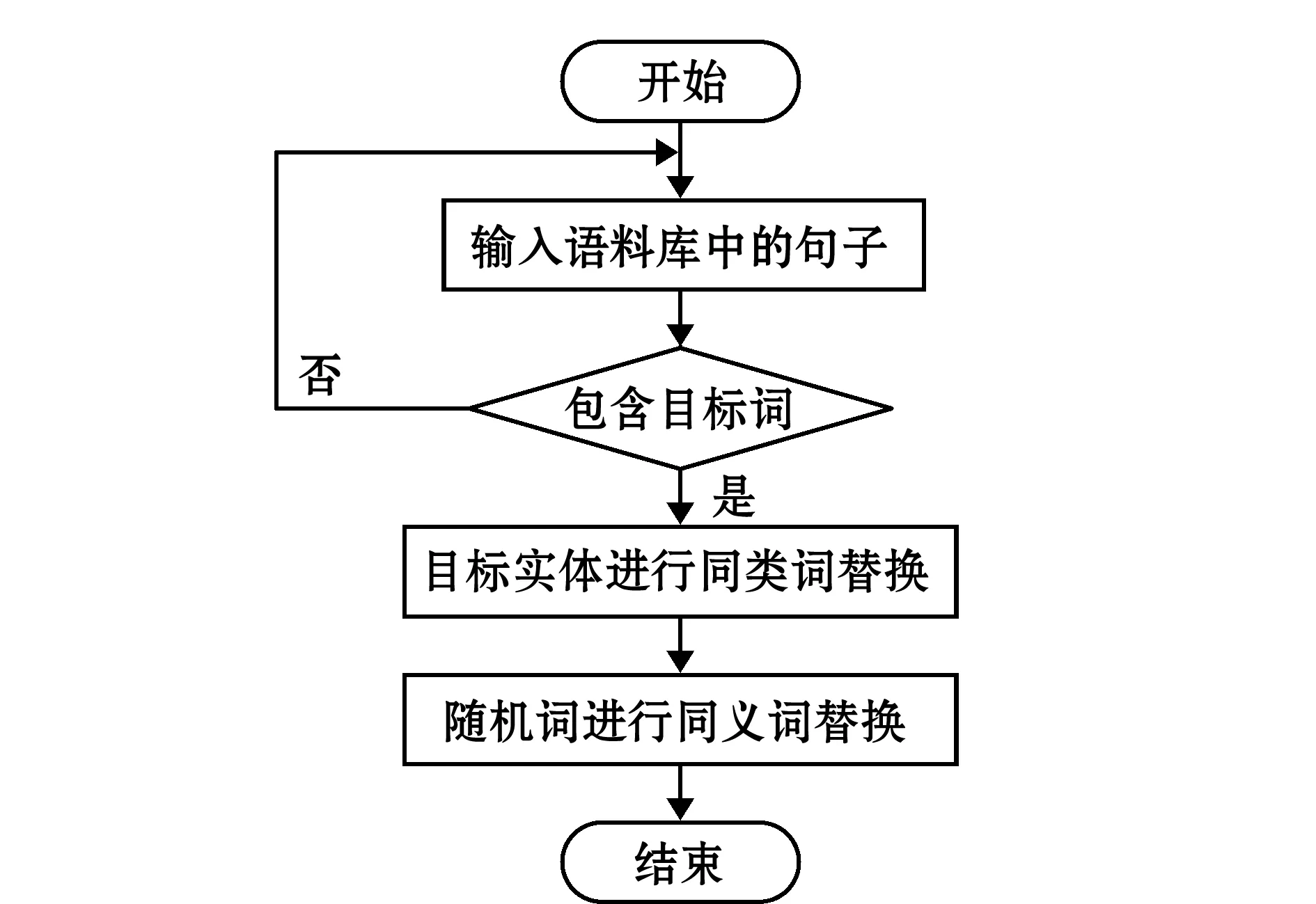
图1 基于领域词典的联合替换算法(DDR)
1.2 对传统随机删除算法的改进
1.2.1 基于槽点保护的随机删除算法 EDA数据增广方法中的随机删除算法是对句子中的每个词,以概率P随机删除,删除句子中字符可以提升样本的多样性,提升模型的泛化能力。但随机删除方法用到渔业标准命名实体识别任务中效果不够理想,因为它会随机删除标准文本中的一些实体,使模型无法学习到实体特征,影响了命名实体识别效果。使用传统的随机删除算法会造成如下问题:
1)渔业标准命名实体识别的目标是识别有意义的专有名词,但是随机删除方法会大量删除需要识别的目标实体,严重影响语料的质量。
2)由于传统的随机删除方法中,每个字符有固定的删除概率,这会造成语义缺失或无效删除,当概率P较大时会对短序列产生较大影响,甚至影响句子原本语义,当概率P较小时则无法对长序列产生影响,使随机删除变得毫无意义。
本研究中,结合渔业标准文本的特点和命名实体识别任务的目标,对随机删除方法进行了两点改进并提出了基于槽点保护的随机删除算法:
1)提出“槽点”保护机制,槽点包含实体本身及上下文特征词语,在保护槽点后再进行随机删除,可改变句子结构以增加多样性。
2)将固定概率改成动态概率,针对不同长度的语句进行动态调整,避免随机删除概率过大或过小产生的不适配问题。
假定随机删除概率为P,句子长度为S,动态概率倍率T,则动态随机删除概率P1=P×T,图3为动态概率倍率T随句子长度S的变化程度,其中,当句子长度小于10时动态概率倍率取0.2,句子长度大于100时动态概率倍率恒定为2。
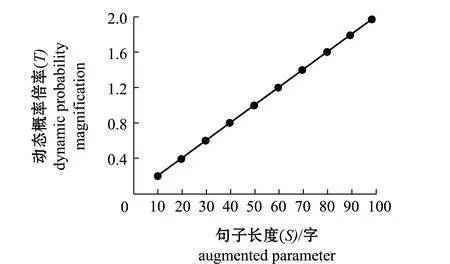
图3 动态删除概率
1.2.2 槽点的保护机制 在自然语言中,判断一个实体是否为目标实体,除了要看实体本身以外,还要参考上下文语义环境。语义特征一般存在于目标实体上下文一定范围内。在渔业标准命名实体识别任务中,将句子序列转化成向量输入到长短时记忆(LSTM)网络模型[18]中,LSTM网络模型会对实体及其上下文特征进行特征提取,得到渔业标准命名实体识别模型。传统的随机删除算法会对句子中的实体及其上下文信息进行随机删除,为了避免实体及其上下文特征被删除,提出了基于槽点保护的概念,槽点包含目标实体及其上下文语义信息,槽点保护包含实体本身保护和实体上下文的语义特征保护,实体上下文特征保护机制是设定一个上下文范围槽点[19],即以目标实体的首字符和末字符为两个点,首字符向前ɑ个字符与末字符向后ɑ个字符区间内的所有字符设为上下文特征槽点,与实体槽点一样,不参与随机删除。通过对实体槽点和上下文特征槽点的保护,使得句子在进行随机删除时目标实体不会被删除,并且保护了目标实体的上下文语义信息,让模型在进行随机删除生成的新句子中,最大化地学习到完整的实体特征。
1.2.3 上下文特征槽点保护长度 对渔业标准语料库中所有包含“水产品名称”目标实体句子进行统计分析,如“本标准适用于我省凡纳滨对虾的苗种培育和养殖”、“要使乌鳢通过驯食后能摄食偏植物性为主的饵料”、“根据中国冻海水鱼片加工的实际情况编制的”。通过部分例句可以看出,句子中目标实体上下文2~3个词语可以涵盖句子大部分的语义特征,由此可以得出结论:对目标实体上下文语义信息影响最大的是前后4~6个字符(2~3个词语)。为了让模型更好地学习到“水产品名称”的上下文特征,最大化保留句子的语义结构,上下文槽点的长度设置非常重要,槽点长度过大会导致随机删除没有意义,本研究中上下文槽点长度若设置为6,虽然保留了较多的目标实体上下文特征,但是句子结构和实体上下文特征基本未发生改变,违背了随机删除的目的。而若将上下文槽点长度设置为4,则既可以适当改变实体的上下文特征,又保留了目标词最主要的上下文特征,可以更好地完成随机删除任务,实现语料的有效扩充,因此,本研究中上下文槽点长度α=4,算法流程如图4所示,算法实例如图5所示。
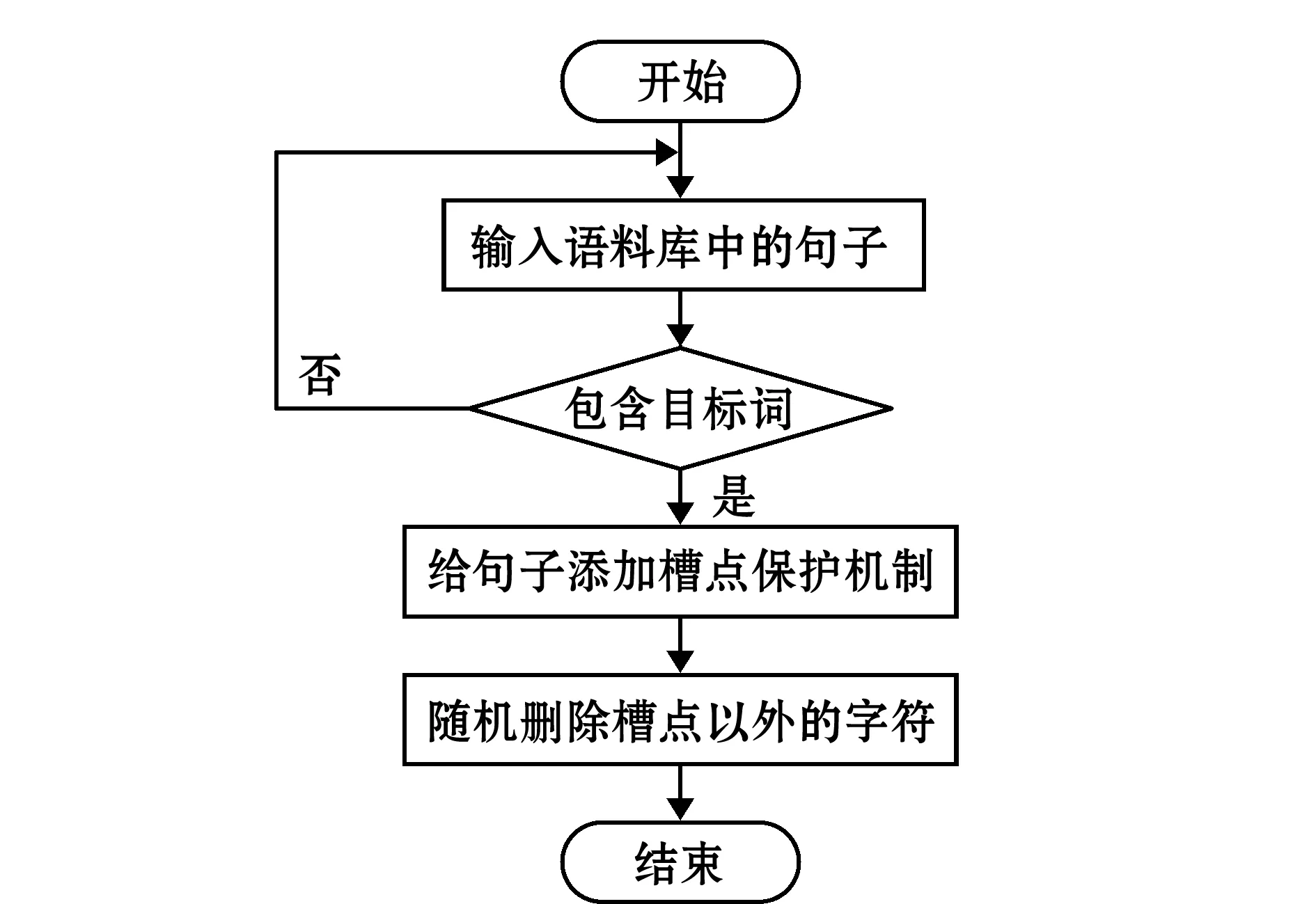
图4 基于槽点保护的随机删除算法(SPD)
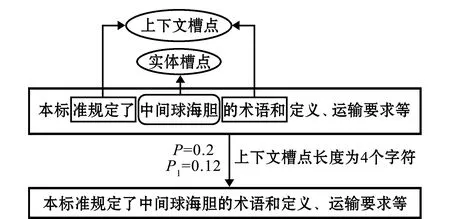
图5 基于槽点保护的随机删除算法实例
1.3 对传统随机插入算法的改进
EDA数据增广方法中的随机插入算法是在句子中随机抽取一个词,然后在该词的同义词集合中随机选择一个同义词,插入原句子中的随机位置。将该方法用于渔业标准文本数据增广时,同随机删除一样,会随机将同义词插入到实体间或者实体上下文间,进而造成模型无法学习到完整的实体特征,影响命名实体识别任务的效果。在使用随机插入算法进行数据增广时,随机插入次数应与句子长度线性相关,避免长句子只进行一次随机插入后句子结构几乎无改变,无法达到语料多样性的目的。
本研究中结合渔业标准文本的特点和命名实体识别的任务目标,对传统的随机插入方法进行了两方面改进,并提出了基于槽点保护的随机插入算法:
1)沿用上文中的槽点保护机制,即实体槽点和上下文槽点间不进行插入操作,在基于槽点保护的情况下进行随机插入,既能保护实体特征,又能改变句子结构,增加样本多样性,提高模型泛化能力。
2)渔业标准文本中句子长度范围大致为20~200个字符,以最短句子长度为单位,每20个字符进行一次随机插入,这使在长句子中的随机插入变得有意义,可在更大程度上改变句子结构。
基于槽点保护的随机插入算法流程如图6所示。
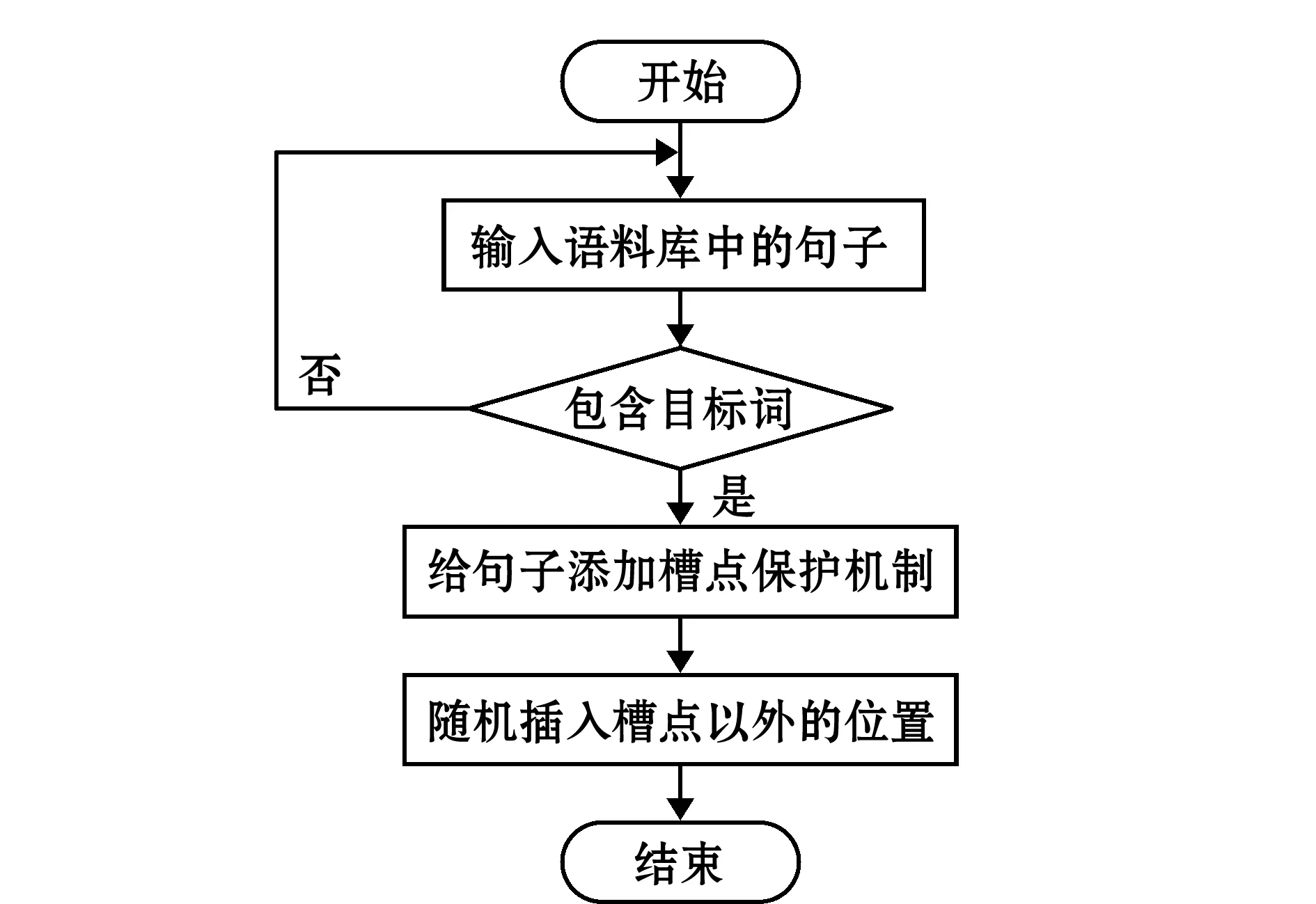
图6 基于槽点保护的随机插入算法(SPI)
1.4 3种增广算法的比较和组合
基于领域词典的联合替换算法、基于槽点保护的随机删除算法和基于槽点保护的随机插入算法等3种方法同样也存在各自的优点和不足(表3)。从表3可见,3种算法中任何一种都会有一定的局限性,为了进一步提高数据增广算法的效果,将这3种算法融合在一起可以弥补各种算法的缺点,因此,本研究中提出了基于多元组合的数据增广方法。

表3 3种增广方法的优缺点对比
2 试验
2.1 试验环境
试验的硬件环境为intel xeon E5-2630 v3 2.4 GHZ 处理器,6 GB 内存,操作系统为 Ubuntu 16.04 LTS 64 bit,GPU为GTX2080Ti,试验平台是PyCharm(2018版)。所用的深度学习框架为Pytorch。
2.2 BERT+BiLSTM+Attention+CRF网络模型
渔业标准命名实体识别网络模型由BERT层[20]、BiLSTM层、Attention层[21]、CRF层4部分组成。BERT是预训练模型,可以更好地训练出位置向量和字向量;BiLSTM层学习到BERT层预训练输出的向量信息,更好地捕捉到较长距离的依赖关系和上下文语义特征;Attention层可以在有限的资源下快速、准确地处理信息,分配权重;CRF层将Attention层的输出添加约束计算得到最优结果,转化成序列标签输出最后的预测结果。
BERT+BiLSTM+Attention+CRF网络模型结构如图7所示。
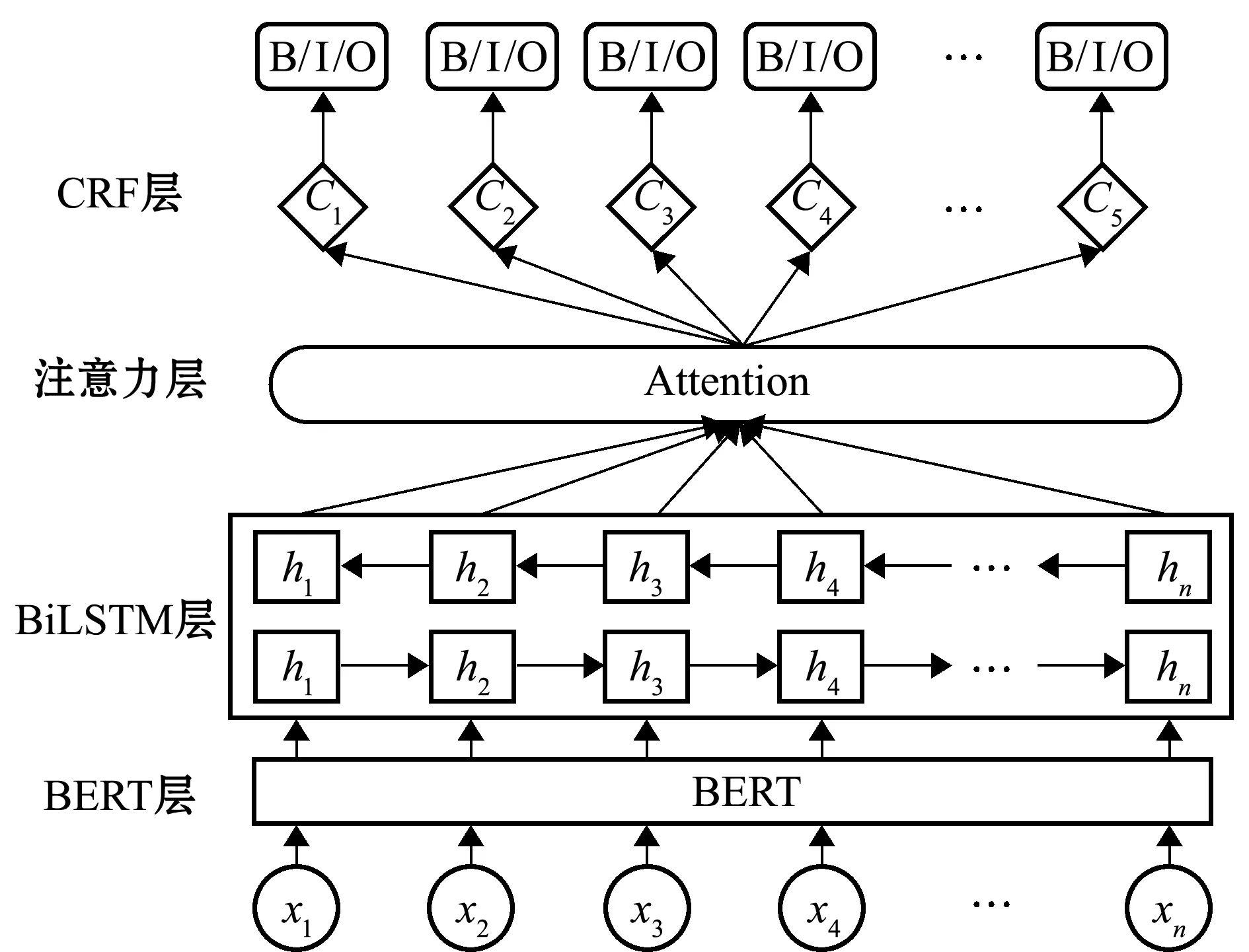
图7 BERT+BiLSTM+Attention+CRF网络模型结构
2.3 基于领域词典的联合替换算法对比试验
为验证基于领域词典的联合替换算法的有效性,对“水产品名称”进行单目标训练,使用不同数据增广方法进行了对比试验。
试验1:BERT+BiLSTM+Attention+CRF网络模型训练“水产品名称”类别的目标实体。经过多次对不同增广系数N进行对比测试,结果显示,当增广系数N=16时的数据增广效果最佳,表4给出了N=16时,原语料库、经过同义词替换后和基于领域词典联合替换后的语料库对“水产品名称”识别效果的比较。
使用同义词进行数据增广后能改变一定的句式结构,提高命名实体识别结果,但是没有增加目标实体的数量,不能从根本上解决目标实体不足的问题。基于领域词典的联合替换算法对渔业标准中的“水产品名称”进行数据增广,有效增加了目标实体的数量,使模型更容易学习到目标实体特征,提高了泛化能力。比传统的同义词替换算法准确率提升了5.37%,召回率提升了8.77%,F1值提升了7.09%(表4)。

表4 基于领域词典的联合替换对比试验
2.4 基于槽点保护的随机删除算法对比试验
为验证基于槽点保护的随机删除算法的有效性,本试验中对“水产品名称”进行单目标训练,使用不同数据增广方法进行了对比试验,上下文槽点长度为4个字符。
试验2:BERT+BiLSTM+Attention+CRF网络模型训练“水产品名称”类别的目标实体。经过多次对选用不同的删除系数进行对比测试,当删除系数为0.02时,数据增广效果最好。表5给出了当删除系数为0.02时,原语料库、经过随机删除后和基于槽点保护的随机删除后的语料库对“水产品名称”识别效果的比较。
使用随机删除算法进行数据增广后能改变句子的句式结构,但没有对目标实体及其上下文信息进行保护,这会造成语义缺失的情况,而本研究中提出基于槽点保护的随机删除算法取得了较好的效果,在保护目标实体和上下文信息后进行随机删除,相比于随机删除算法准确率提升了6.1%,召回率提升了4.19%,F1值提升了4.97%(表5)。这表明,使用上下文槽点的保护机制后有效地提升了样本的多样性,提高了模型的泛化能力,验证了本研究中提出的基于槽点保护的随机删除方法的有效性。

表5 基于槽点保护的随机删除对比试验
试验3:使用槽点保护的随机删除算法对语料进行相同随机删除概率下选取不同长度的上下文槽点对比试验。选取删除系数为0.02条件下进行试验,上下文槽点保护长度分别为2、4、6、8个字符单位,结果如表6所示。在相同的随机删除概率下进行不同长度的上下文槽点保护试验,根据试验结果可知,当上下文槽点长度为4个字符单位时效果最佳,准确率最高为82.94%,完全可以概括实体的大部分特征。这表明,基于上下文槽点保护的随机删除算法,当槽点长度选择4个字符时模型效果达到最好。

表6 上下文槽点保护长度
2.5 基于槽点保护的随机插入算法对比试验
为验证本研究中提出的基于槽点保护的随机插入算法对“水产品名称”进行单目标训练的效果,使用不同数据增广方法进行了对比试验,本试验中上下文槽点长度为4个字符。
试验4:BERT+BiLSTM+Attention+CRF网络模型训练“水产品名称”类别的目标实体。上下文槽点长度为4个字符,表7给出了原语料库、经过随机插入后的语料库和基于槽点保护的随机插入后的语料库对“水产品名称”识别效果的比较。由表7可知,与随机插入算法相比,基于槽点保护的随机插入算法的识别效果更加优异,其准确率达到了82.34%,能够更好地保留目标实体的特征,提高识别准确率。

表7 基于槽点保护的随机插入对比试验
2.6 基于多元组合数据增广算法与其他单一算法识别效果的对比试验
为验证本研究中提出的多元组合的数据增广方法,对“水产品名称”进行单目标实体训练。
试验5:使用基于领域词典的联合替换算法(方法A)、基于槽点保护的随机删除算法(方法B)、基于槽点保护的随机插入算法(方法C)、基于多元组合数据增广算法(方法A+B+C),以及程名[16]基于BiLSTM+CRF的渔业标准术语识别研究中的数据增广方法(方法D)进行对比试验。其中,基于领域词典的联合替换算法增广系数N=16,基于槽点保护的随机删除算法随机删除概率为0.02,且所有试验中上下文槽点长度为4个字符。试验结果如表8所示,将3种算法融合的多元组合数据增广算法的识别效果要优于单独使用1种算法的识别效果,且较程名[16]提出的数据增广算法识别效果有较大提升,准确率达到了91.73%。

表8 3种方法结合使用对比试验
3 讨论
在命名实体识别任务中,存在部分目标实体样本稀疏问题,此问题常导致该类实体识别效果较差,影响命名实体识别任务的整体结果。目前,解决样本稀疏的方法[13-14]较多,通过对渔业标准文本特性分析,本研究中选取数据增广的方法来解决渔业标准文本中“水产品名称”类实体样本稀疏问题。由试验1、试验2、试验4可知,本研究中提出的3种数据增广方法均优于传统方法,识别精度均有较大提升,其中,基于领域词典的联合替换算法较同义词替换算法有效地增加了“水产品名称”类实体的数量,准确率提升了5.37%,基于槽点保护的随机删除算法和基于槽点保护的随机插入算法有效提高了样本的多样性,提升了模型的泛化能力,准确率分别较传统的随机删除和随机插入算法提升了6.10%和6.55%。为了更好地融合3种算法的优势,提高识别效果,本研究中将3种数据增广算法进行了多元组合,由试验5可知,本研究中提出的多元组合数据增广的命名实体识别方法在渔业标准文本命名实体识别任务中效果提升更加明显,准确率、召回率、F1值分别达到了91.73%、88.64%、90.16%。该方法较程名[16]提出的渔业标准术语识别方法具有更高的识别精度。这种多元组合的数据增广方法也为其他领域的命名实体识别任务提供了新的思路。
4 结论
本研究中针对渔业标准命名实体识别任务中“水产品名称”等实体类别样本分布稀疏,使模型无法准确学习到目标实体的特征,导致这类实体识别效果较差的问题,在传统的同义词替换、随机删除算法和随机插入算法的基础上进行改进,并使用融合注意力机制的BERT-BiLSTM-CRF网络模型进行多组对比试验,得出以下结论:
1)通过改进3种传统的数据增广算法,提出了基于领域词典的联合替换算法、基于槽点保护的随机删除算法和基于槽点保护的随机插入算法,使用这3种数据增广算法后的语料库进行命名实体识别任务的准确率、召回率、F1值均有较大提高,有效提升了渔业标准命名实体识别的整体效果。
2)本研究中将所提出的3种数据增广算法进行多元组合,在命名实体识别任务上取得了较好的效果,在保护实体和上下文特征的情况下,既可有效增加目标实体数量又可丰富样本多样性,从而提高了模型的泛化能力和识别精度。
3)使用本研究中提出的融合注意力机制的BERT-BiLSTM-CRF网络模型进行渔业标准命名实体识别任务,相较BiLSTM-CRF网络模型取得了更好的效果,准确率、召回率、F1值分别提升了2.27%、1.43%、1.84%,证明了该模型的有效性,下一步可通过改进该模型完成渔业标准实体关系抽取工作,为构建渔业标准知识图谱奠定基础。
猜你喜欢
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
世界农药(2019年4期)2019-12-30
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
中国水产(2017年2期)2017-02-25
中国水产(2017年2期)2017-02-25
湖南畜牧兽医(2016年3期)2016-06-05
中关村(2014年5期)2014-05-15
