
基于CenterNet 目标检测算法的改进模型
2021-09-15 07:36:32石先让宋廷伦戴振泳
计算机工程 2021年9期
石先让,苏 洋,提 艳,宋廷伦,2,戴振泳
(1.南京航空航天大学 能源与动力学院,南京 210001;2.奇瑞前瞻与预研技术中心,安徽 芜湖 241006)
0 概述
基于深度卷积神经网络的物体检测方法已经在各种数据集[1-3]上取得了较好的成果,其中很多方法都有一个共同的、重要的组成结构——锚框(Anchor),锚框是各种大小的预选框。当单阶段(One-stage)方法[4-6]使用锚框后,可以实现与两阶段(Two-stage)目标检测方法[7-8]极具竞争力的结果,同时检测速度更快。One-stage 方法将锚框密集地放置在图像上,根据对锚框评分并通过回归方法修正坐标来生成最终的预测框。需要锚框的方法称之为Anchor-based 方法。One-stage 目标检测算法将可能的边界框(称为锚框)复杂地排列在图像上,并采用滑动窗口的方法直接对其进行分类,而无需指定框的内容。Two-stage 目标检测算法是为每个潜在的框重新计算图像特征,然后对这些特征进行分类。当检测方法对潜在的锚框进行检测和分类后,一般都需要进行非最大值抑制(NMS)[9]后处理才能得到最终的检测目标的各种属性。
虽然在近年来该方法取得了一定的成功,但是锚框还存在缺点。首先,在目前锚框的目标检测算法中,通常使用基于滑动窗口的方法,这就需要大量的锚框,如DSSD 算法[10]中超过4 万,而在RetinaNet算法[11]中超过10 万。当采用锚框时,只有小部分的锚框满足于标注的真实值重叠程度,这会造成正锚框与负锚框的失衡,往往都是负锚框的数量远多于正锚框,同时还会增加训练时间。其次,锚框的使用会引入很多超参数,以及增加如何选择这些超参数的难点,这些超参数的选择很大程度上是通过经验和启发式方法[5-8]得到的,当与多尺度目标检测结合使用时会变得更加复杂。
鉴于锚框存在的缺点,考虑设计一个不需要锚框同时可以取得良好的目标检测速度和准确度的目标检测方法显得很有必要,即Anchor-free 方法。
目前已经产生了许多不需要锚框的方法[12-14]。2019 年,ZHOU 等[15]提 出CenterNet 目标检测算法。该算法通过对一张图片进行全卷积操作,输出热值图,直接检测目标的中心和大小,不需要NMS 方法,减少了计算量。CenterNet 目标检测算法通过3 个网络构造来输出预测值,分别输出目标的类、中心点与大小,完全实现了Anchor-free。CenterNet 算法[15]采用了4 种Backbone,在不同的Backbone 下,其最终的目标检测性能有着明显的差异。因此,设计同时兼顾目标检测速度和准确度的Backbone,显得很有必要。在原CenterNet 目标检测方法中,只采用一个特征图进行目标检测,这样不可避免地会造成图像特征丢失。为充分利用深度卷积神经网络提取后的特征,采用特征图融合非常重要。
本文在Hour-glasss-104 模型的基础上,构建Hourglass-208 模型。该模型基于原CenterNet 算法减少参数量和计算量,在此基础上给出特征图融合方法,并设计一种新的Backbone,通过对损失函数进行改进,提出一种T_CenterNet 目标检测算法。
1 相关工作
1.1 Hourglass-208 模型
在Hourglass-104 模型[15]中,输入为原始图像大小的4 倍下采样,依次经过8 倍、16 倍、32 倍、64 倍、128 倍的下采样,然后再依次经过上采样,最后只输出一个特征图,大小为输入图像的4 倍下采样。
与CenterNet[15]相比,本文设 计的Hourglass-208模型最后进行特征图的输出数量和大小不同于原Hourglass-104。在Hourglas-208 模型中,输入图像的大小为416×416×3,在进行卷积预处理后,再输入Hourglass-208 模型。Hourglass-208 输入的张量的大小为208×208×128,经过全卷积[16]操作后输出4 个特征图,分别为P1、P2、P3、P4。对于特征图Pi,对应为原输入图像的2i倍下采样,即输出特征图的宽和高分别为输入图像的1/2i。最大特征图P1的宽和高的大小为208,相对于输入图像宽和高的大小416,只有2 倍的下采样,相比原Hourglass-104,保留了更多的特征图和特征图更高的分辨率。
在Hourglass-208 模型中,主要计算为卷积操作以及残差网络[17]的短接,由7 个残差块构成,只经过了2 倍、4 倍、8 倍和16 倍下采 样,和hourglass-104 相比,省去了32 倍、64 倍和128 倍的下采样。同时,基于Hourglass-208 模型,在旁路卷积中,直接采用短接连接,省去了卷积操作,减少了参数量和计算量。Hourglass-208 模型如图1 所示。

图1 Hourglass-208 模型Fig.1 Hourglass-208 model
在图1 中,Conv 表示卷积层,BN 表示BN层[18],Leaky relu表示Leaky relu 激活函数层,Upsample 表示上采样层,圆形为张量的相加操作,斜杠矩形表示由卷积层、BN 层和激活函数层构成的卷积块,为Hourglass-208 的主要组成结构。
1.2 加权特征图融合方法
在CenterNet 中,使用最大的特征图进行目标检测,不可避免地损失了图像的一些特征。为充分利用经过卷积操作后产生的特征图,本文将Hourglass-208 输出的4 个特征图进行融合。文献[19]提出特征金字塔网络(FPN)的特征图融合方法,随后FPN广泛运用于各种卷积网络中。
传统特征图融合方法都是平等对待各个特征图,未考虑不同特征图对最后目标检测性能的区别。但通过研究发现,各个特征图对最后融合输出特征图的贡献是不平等的,TAN 等[20]在EfficientDet 中提出一种对各个特征图的加权特征融合方法BiFPN。在对特征图进行融合时,对每个输入的特征图增加可以学习的权重,以便网络在学习时,通过学习改变各个特征图的融合权重,研究每个特征图的最后目标检测性能的重要性。
对每个特征图进行学习的权重融合,可采用快速归一化融合,计算公式为:

其中:ωi可用ReLU 函数保证其ωi≥0,同时设置一个极小值ε=0.000 1,避免分母为零的数值不稳定;Ii为输入的特征图;O为融合输出的特征图,每个归一化权重的值范围为0~1。
本文通过2 种方法进行特征图的加权融合:
1)双特征金字塔网络(TFPN)方法
TFPN 结构如图2 所示。在图2 中,圆形为卷积操作,点划线箭头代表上采样,虚线箭头表示跳层连接。

图2 双特征金字塔网络结构Fig.2 Structure of twin feature pyramid network
具体计算实例如式(2)所示:

在图2 所示的融合方法中,由高层到低层的特征图经过的卷积操作逐渐增加,整体呈三角形结构,所以对该融合方法命名为双特征金字塔网络(TFPN)。
TFPN 特征图融合不同于BiFPN[20],只有单向连接和跳层连接,因为最后是通过热值图来实现目标的检测和定位,考虑一张特征图实现,所以只采用了上采样操作,没有下采样。在TFPN 中,最后输出的只有一个融合后的特征图Pout。不同于CenterNet 只用了最后一层单个特征图进行目标检测,本文用于目标检测的特征图是通过更高层的特征图通过上采样以及可学习的权重融合得到的。
2)FPN_o1 方法
FPN_o1 结构如图3 所示。在图3 中,圆形为卷积操作,点划线箭头代表上采样。

图3 FPN_o1 结构Fig.3 FPN_o1 structure
具体计算实例如式(3)所示:

在图3 所示的融合方法中,由高层到低层的特征图是经过上采样后,然后通过相加得到,最后输出的只有一个融合后的特征图Pout,原理类似TFPN,但结构相对于TFPN 较简单,所以对该融合方法命名为FPN_o1。
1.3 Hourglass-208 输出特征图的融合
对输出的特征图进行权重融合时也采用快速归一融合法,计算公式如式(4)所示:

权重融合示意图如图4 所示。

图4 权重融合结构Fig.4 Structure of weight fusion
在图4 中,输出的特征图经过卷积,该卷积不改变特征图维度的大小,然后通过可学习的权重相加,其中:Pij代表第i个Hourglass-208 模型中第j个特征图;ωij代表第i个Hourglass-208 模型中第j个特征图的权重;Pij′为融合后的输出,即式(4)中的Pout;Add代表特征图的相加。
1.4 热值图
热值图(heatmap)主要通过颜色去表现数值的大小,热值图中的颜色越暖,表示值越大,颜色越冷,表示值越小,热值图示意图如图5 所示。

图5 热值图示意图Fig.5 Schematic diagram of heatmap
本文需要将卷积神经网络提取到的中心点的特征转化为热值图。在热值图中,颜色越暖,表示该处存在目标中心点的概率越大;颜色越冷,表示该处为背景的概率越大(彩图效果见《计算机工程》官网HTML 版)。
1.5 中继监督
本文通过端到端堆栈多个Hourglass-208 模型,将上一个Hourglass-208 模型的输出作为下一个Hourglass-208 模型的输入。这种方式为网络提供了一种重复的自下而上、自上而下推理的机制,从而允许重新评估整个输入图像的初始估计和特征。
每个Hourglass-208 模型的输出特征图融合后,都生成一个由关键点构成的热值图。在训练时,每个热值图都进行目标检测,生成损失函数。这种方法就可以对中间产生的热值图进行预测和监督,即中继监督[21-22]。中继监督可以减轻深度神经网络带来的梯度消失和梯度爆炸等[23-24]问题。因为通过对每个Hourglass-208 模型的输出都添加中继监督,所以可以保证底层的神经网络参数正常更新。
预测是通过每个Hourglass-208 模型在本地和全局环境下对输入图像或者特征图处理之后产生的。后续的Hourglass-208 模块再次处理上一个Hourglass-208 模块输出的特征图,以进一步评估和重新评估更高阶的特征信息。这种方法类似于一些人体姿势估计方法[21-22],在多个迭代阶段和中间监督下均表现出出色的性能。
在进行中继监督后,将中间产生的热值图映射到更大数量的通道(通过额外的1×1 卷积),然后重新集成到特征空间中,并将这些热值图从Hourglass-208 中添加到特征空间中,以及前一个Hourglass-208模型输出的特征图中,最后输出到下一个Hourglass-208 模块中,将该Hourglass-208 模块生成下一组热值图进行预测。
2 算法原理
2.1 基于锚框和中心点的区别
基于锚框与基于中心点目标检测都是将目标从背景中分离出来,但是采用的方法不同,区别如图6所示。
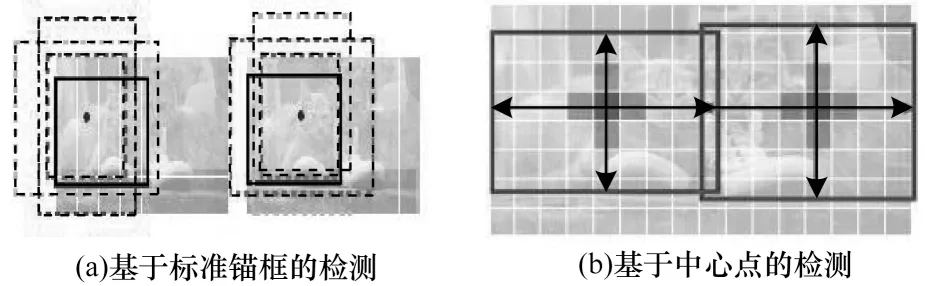
图6 基于标准锚框的检测与基于中心点的检测的区别Fig.6 Difference of standard anchor-based detection and center point-based detection
在图6(a)中,当锚框与标注的目标边界框的IoU>0.7 时,记该锚框包含的内容为前景;当IoU<0.3 时,记该锚框包含的内容为背景;否则忽略该锚框忽略[7-8]。在图6(b)中,将目标中心像素表示检测的目标对象,周围的像素点为背景,目标对象的大小回归得到。
2.2 目标中心点的预测
设输入图片为I∊RW×H×3,其中,W为图片的宽;H为图片的高。最后输出预测为图像关键点构成的热值图,该热值图的值为。这里图像的中心点为关键点。在关键点构成的热值图中,其热值图的值,其中:R为图像下采样倍数,在本文中R=2;C为关键点的类型,即目标的类型,在MS COCO 数据集[3]上C=80。当=1 时表示该点为目标中心点,当=0 时为该点为背景。
CenterNet 算法原理如图7 所示。

图7 CenterNet 算法原理Fig.7 Principle of CenterNet algorithm
目标的中心点如图7(a)所示。在训练时,每一个标注的真实点为p∊R2,根据输出的下采样倍数R,将真实点变换成,然后将真实值通过一个高斯核,如式(5)所示:

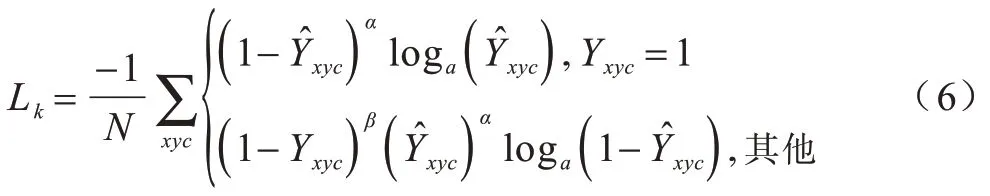
其中:α、β为Focal loss 损失函数的超参数;N为每张图片上关键点的数量,以进行归一化将所有损失值归一化为1。根据Cornernet[13]目标检测算法,取α=2,β=4。
2.3 目标中心点偏移预测
在最后输出热值图时,因为进行了下采样,所以输出的特征图不可避免地产生了偏移。为解决产生的偏移,可以通过对偏移进行预测,最后进行平衡,抵消输出偏移的影响。对所有的类C进行偏移预测,则设输出偏移为。如图7(b)所示。
在训练时,采用L1损失函数,如式(7)所示:
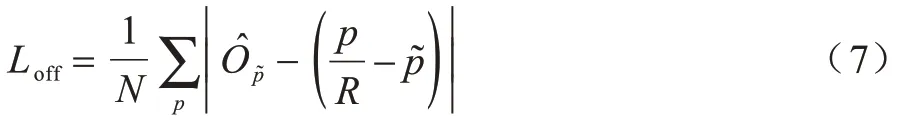
2.4 目标大小预测
为对目标大小进行预测,可通过增加预测输出分支,设输出的目标大小为,同时使 用smoothL1损失函数[7]进行目标大小学习和训练,smoothL1如式(8)所示:

目标大小的损失函数如式(9)所示:

2.5 总损失函数
由2.2 节~2.4 节可知,总损失函数包括中心点的损失函数、中心点的偏移损失函数和目标大小的损失函数。总损失函数表示如下:

在本文的算法模型中,设置λsize=0.1,λoff=1。
本文中的网络所有输出共享一个通用的全卷积Backbone 网络,使用该Backbone 网络来预测目标的关键 点、偏移和大小,每个特征图上的 点输出维度为C+4,C为目标类型数量。
2.6 目标检测
在进行目标检测时,首先提取每个类的热值图的峰值,选取所有值大于或等于其8 个连通邻居的响应,并保持前100 个峰值,通过3×3 的最大池化层实现。
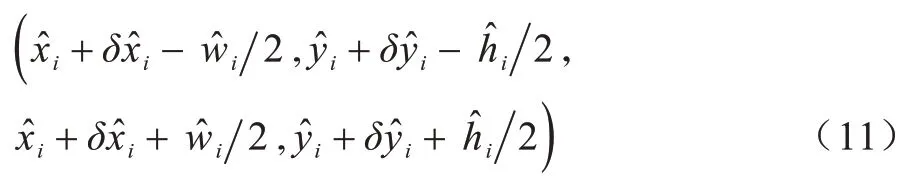
所有输出都是直接从关键点预测产生的,而无需基于IoU 的非最大值抑制(NMS)或其他后处理。因为峰值关键点提取可以作为NMS 的替代方案,并且可以使用3×3 最大池化操作实现。
3 目标检测算法模型架构
3.1 Hourglass-208 性能测试
在本文的实验中,实验条件均为:Ubuntu16.04系统,CPU 为Intel Core i7-8086K,GPU 采用英伟达的TITAN XP 12 GB 的独立显卡,安装CUDA8.0、CUDNN5.1、OpenCV3.2 等。
为了对新设计Hourglass-208 的性能进行测试,在这里对单个的Hourglass-208 模型进行图像的分类实验和测试并与原来的Hourglass 模型[15]进行比较。为了在ImageNet 数据集[1]上进行图像分类实验,在模型最后增加Softmax 全连接层。测试结果如表1所示。其中,Top-1 表示在ImageNet 数据集上的分类准确率,t表示模型对一张图片的识别时间。

表1 Hourglass 性能测试Table 1 Hourglass performance test
从表1 可以看出,虽然Hourglass-208 的准确率降低了19.9%,但是运算速度却提高了47.8%,这对于提高目标检测的实时性具有很大的优势。因此,为提高目标检测的速度,本文采用Hourglass-208 模型。
3.2 架构设计
为得到最佳的网络架构设计,本文设计了一系列实验进行测试和验证。在验证测试时,采用PASCAL VOC 数据集[2]进行实验,该数据集远小于MS COCO 数据集[3],为了能更快地得到实验结果,选择PASCAL VOC 数据集进行训练和测试,根据结果对算法的架构进行评估,并选择最优的架构结果。本文实验将对是否考虑中继监督、特征图融合、综合考虑2 个Hourglass-208 模型输出特征图的归一化融合以及采用soomthL1损失函数来选择最优的网络架构。
在PASCAL VOC 数据集上进行目标检测实验。训练时在训练图像集上进行算法模型训练,采用数据增强技术,对训练集的图像进行随机翻转、随机缩放、裁剪和色彩抖动等方法,算法模型的优化器选择Adam[25]优化,批量大小(Batch size)为32,学习率设置为指数衰减,初始值设置为1.0e-3,每经过5epoch,学习率下降0.96 倍。以416像素×416像素的分辨率进行输入训练,在进行2 倍下采样后输入到Hourglass-208 模型中,最后模型的输出分辨率为208像素×208像素。
本文实验将从中继监督、Hourglass-208 输出特征图的选择、FPN_o1、TFPN 及smoothL1损失函数等方面选择出最优的构件,设计了12 种不同的算法架构,进而筛选出目标检测算法的最优架构。本文设计的12 种架构,都使用了2 个Hourglass-208,其中对第1 个Hourglass-208 模型进行了外部短接,2 个Hourglass-208 模块之间没有共享权重,对每个Hourglass-208 模型输出的特征图进行权重融合、FPN_o1 及TFPN 融合等操作,然后通过1×1 卷积层生成热值图。在进行模型的训练时,每个中继监督都使用相同的目标真实值计算损失函数,其中目标大小的损失函数采用L1或者smoothL1损失函数。在模型的测试时,只需要将热值图进行目标中心点以及大小的预测即可。如果使用中继监督,则需将2 个热值图进行相加求平均值,重新生成一个热值图进行目标检测。
本文设计的12 种目标检测算法架构如图8 所示。
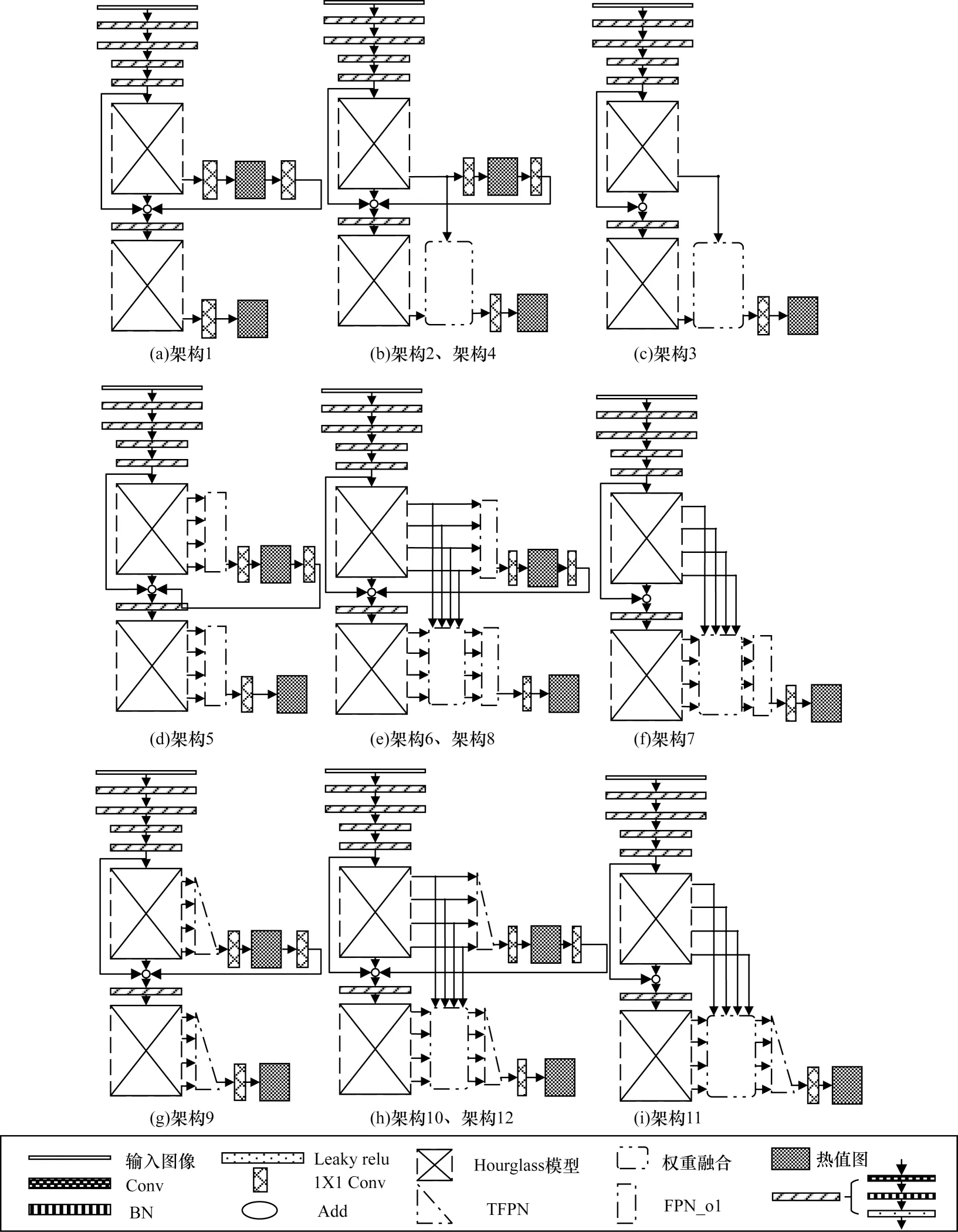
图8 目标检测算法架构Fig.8 Architecture of target detection algorithm
在图8 中,空白矩形表示输入图像;Conv 表示卷积层;BN 表示BN 层;Leaky relu 表示Leaky relu 激活函数层;1×1Conv 表示1×1 卷积层;Add 表示张量的相加;热值图表示预测生成的热值图;斜杠矩形表示由卷积层、BN 层和激活函数层构成的卷积块;交叉矩形表示Hourglass-208 模块;TFPN 表示TFPN 特征图融合方法;FPN_o1 表示FPN_o1 特征图融合方法;圆角双点划线矩形表示权重融合。
测试结果如表2 所示,其中:√表示采用。在表2中,中继监督表示是否采用中继监督方法;P1 表示只采用Hourglass-208 输出的分辨率最高的特征图进行目标检测,即P1 特征图,如图8 架构1~架构4 所示;FPN_o1 表示采用FPN_o1 特征图融合方法,如架构5~架构8 所示;TFPN 表示采用TFPN 特征图融合方法,如图8 架构9~架构12 所示;加权融合表示是否考虑将2 个Hourglass-208 模型输出的特征图进行归一化融合;SmoothL1表示是否采用smoothL1损失函数。

表2 12 种架构的测试结果Table 2 Test results of twelve architecture
通过表2,在类似结构下可得到如下结论:
1)通过对比实验架构11、12 可知,采用中继监督后,mAP 值最高可以提高18.2 个百分点。
2)通过对比实验架构4、12 可知,采用特征图融合方法相比只采用P1 特征图,mAP 值最高可以提高17.1 个百分点。
3)通过对比实验架构8、12 可知,采用TFPN 特征图融合方法相比采用FPN_o1 特征图融合方法,mAP 值最高可以提高2.9 个百分点。
4)通过对比实验架构10 和12 可知,采用smoothL1损失函数代替L1损失函数时,mAP 值最高可以提高1.1 个百分点。
综上所述,考虑中继监督、TFPN、加权融合和smoothL1时,架构12 在VOC 数据集上得到了最优的结果,mAP 值达到了85.4%。
3.3 实验结果
根据实验结果,架构12 为最优的架构,即在最终选择的网络架构计中,使用了2 个Hourglass-208,其中对第3 个Hourglass-208 模型进行了外部短接,2 个Hourglass-208 模块之间没有共享权重,对每个Hourglass-208 模型输出的特征图进行权重融合以及TFPN 融合,然后通过1×1 卷积层生成热值图。在进行模型的训练时,每个中继监督都使用相同的目标真实值计算损失函数,其中目标大小的损失函数采用smoothL1损失函数。
因为该算法架构采用了本文设计的TFPN 特征图融合方法,所以命名为T_CenterNet。架构模型如图9 所示(图例含义同图8)。

图9 T_CenterNet 架构模型Fig.9 T_CenterNet architectural model
下文将在MSCOCO 数据集上对该架构目标检测的速度和准确度进行评估,并与知名的目标检测算法进行比较。
4 实验
4.1 实验条件
本文实验在Ubuntu16.04 系统下进行,CPU 为Intel Core i7-8086K,GPU 采用英伟达的TITAN XP 12 GB 的独立显卡,安装CUDA8.0、CUDNN5.1、OpenCV3.2 等。数据集采用更大的ImageNet 图像分类数据集[1]和MS COCO 目标检测数据集[3]。
4.2 Hourglass-208 的预训练
为提高Hourglass-208 特征提取能力,本次实验在ImageNet 数据集上进行图像分类的预训练。在预训练时,由于ImageNet 数据集的目标种类远多于MS COCO 数据集,因此选取和MS COCO 具有相同的物体类型进行预训练,从ImageNet 数据集中选取约80 种和MS COCO 数据集具有相同物体的图片集。对于预训练,需要将原T_CenterNet 目标检测模型进行改进。对于每一个Hourglass-208 的输出,经过TFPN 处理后,只需将2 个TFPN 的输出Pout特征图进行拼接(Concat)处理,然后经过一个卷积块的处理,再经过平均池化层(Avgpool),最后通过Softmax 全连接层进行分类输出,共输出80 个类别,如图10 所示。其中:空白矩形表示输入图像;Conv表示卷积层;BN 表示BN层;Leaky relu 表示Leaky relu 激活函数层;Add 表示张量的相加;Concat 表示张量的拼接操作,Avgpool 表示平均池化层;Softmax表示Softmax 全连接层;Hourglass 模型表示Hourglass-208 模块;TFPN 表示TFPN 特征图融合方法;双点划线圆角矩形表示权重融合;斜杠矩形表示由卷积层、BN层和激活函数层构成的卷积块。
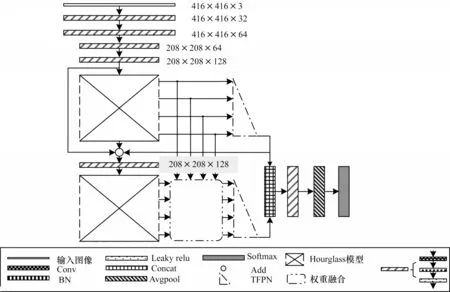
图10 Hourglass-208 特征提取预训练模型Fig.10 Hourglass-208 feature extraction pre-training model
在ImageNet 数据集上训练完成后,去掉拼接层、池化层和全连接层,添加热值图和中继监督,然后在MS COCO 数据集上进行目标检测训练和测试。
4.3 目标检测训练
在MS COCO 数据集上进行训练和测试,该数据集包含118k 训练图像(train201-7)、5k 验证图像(val2017)和20k 支持测试图像(test-dev)。
在训练图像集(train2017)上进行算法模型训练,以416像素×416像素的分辨率进行输入训练,模型的输出分辨率为208像素×208像素。采用数据增强技术,对训练集的图像进行随机翻转、随机缩放、裁剪、色彩抖动等方法,算法模型的优化器选择Adam。学习率设置为指数衰减,初始值设置为1.0e-3,每经过5epoch,学习率下降0.96 倍,批量大小(Batch size)设置为32。
损失函数的收敛趋势如图11 所示。从图11 可以看出,其损失函数L(size)、L(off)、L(k)和L(det)分别在迭代数(Iteration)为1.35×107、1.24×107、2.4×107和2.5×107时趋于收敛,其损失函数值分别收敛于0.2、0.1、0.78 和0.9。另一方面可以得出L(off)的收敛速度最快,L(size)其次,最后是L(k),总损失函数L(det)最后在迭代数为2.5×107时最后收敛。其总损失函数的值最终稳定在0.9 左右,即T_CenterNet 模型达到稳定和最优。

图11 损失函数的收敛曲线Fig.11 Convergence curve of loss function
4.4 目标检测测试
对于测试,同样是在MS COCO 数据集上评估了目标检测的性能。最后的测试结果的指标为FPS(Frame Per Second),表示每秒检测图像的帧数,是实时性的衡量参数。AP、AP50、AP75、APs、APM、APL为对MS COCO 数据集图像上目标检测准确性的评价指标,如表3 所示。其中:AP(Average Precision)为目标检测的平均精度:APs为小目标的检测精度;APM为中等大小目标的检测精度:APL为大目标的检测精度。具体请参考MS COCO 数据集官网(http://cocodataset.org/#detections-eval)。在表3 中:加粗数字代表排名第1;加粗斜体数字代表排名第2;斜体数字代表排名第3;R_T_CenterNet 为未对T_CenterNet目标检测算法预训练;T_CenterNet/off 为不考虑对目标中心点的偏移的预测,即去掉T_CenterNet 中对目标中心点预测的分支(经过预训练);T_CenterNet为本文设计的目标检测算法。
通过表3 可以得知:
1)T_CenterNet 算法模型的AP50达到63.6%,APS达到31.6%,APM达到45.8%,在表2 中的目标检测算法中排名第1。
2)虽 然T_CenterNet 算法模型的FPS 值低于EfficientDet-D0 的47,但是也达到了36%,排名第3,具有实时性。
3)T_CenterNet 算法模型的目标检测各项指标均高于EfficientDet-D2,虽然AP、AP75和APL指标低于 EfficientDet-D3,但是FPS值却远高于EfficientDet-D3 的28 frame/s。
4)T_CenterNet 算法模型的目标检测各项指标均高于原CenterNet 算法模型。这个结果与改进的Hourglass-208 和采用了加权特征图融合方法有关。
5)从T_CenterNet/off 的检测结果可以看出,去掉中心点偏移的预测后,对目标的检测速度影响不大,只有1 帧的速率的提升。各个检测精度的指标均有降低,其中AP 值降低了5.49 个百分点,特别是对大目标和中等大小的目标影响很大,分别降低了11.3、7.86 个百分点,但对小目标的检测准确度影响很小,只降低了0.1个百分点。总体来讲,增加对目标中心点偏移的预测有利于增加目标检测的准确性。
通过实验可知,本文提出的T_CenterNet 算法模型在进行目标检测之前先在ImageNet 数据集上对Hourglass-208 进行了预训练,通过预训练的方法,可以很好地提高目标检测的性能。从表3 可以看出,T_CenterNet 目标检测算法最后的测试结果超过了原CenterNet 算法模型,也优于最新的EfficientDet 目标检测算法,总体上达到了理想的结果。但是在目标检测的准确度上,T_CenterNet 算法模型的部分指标稍落后于EfficientDet-D3 算法模型,由于EfficientDet 算法模型综合考虑了复合模型缩放方法[20]。
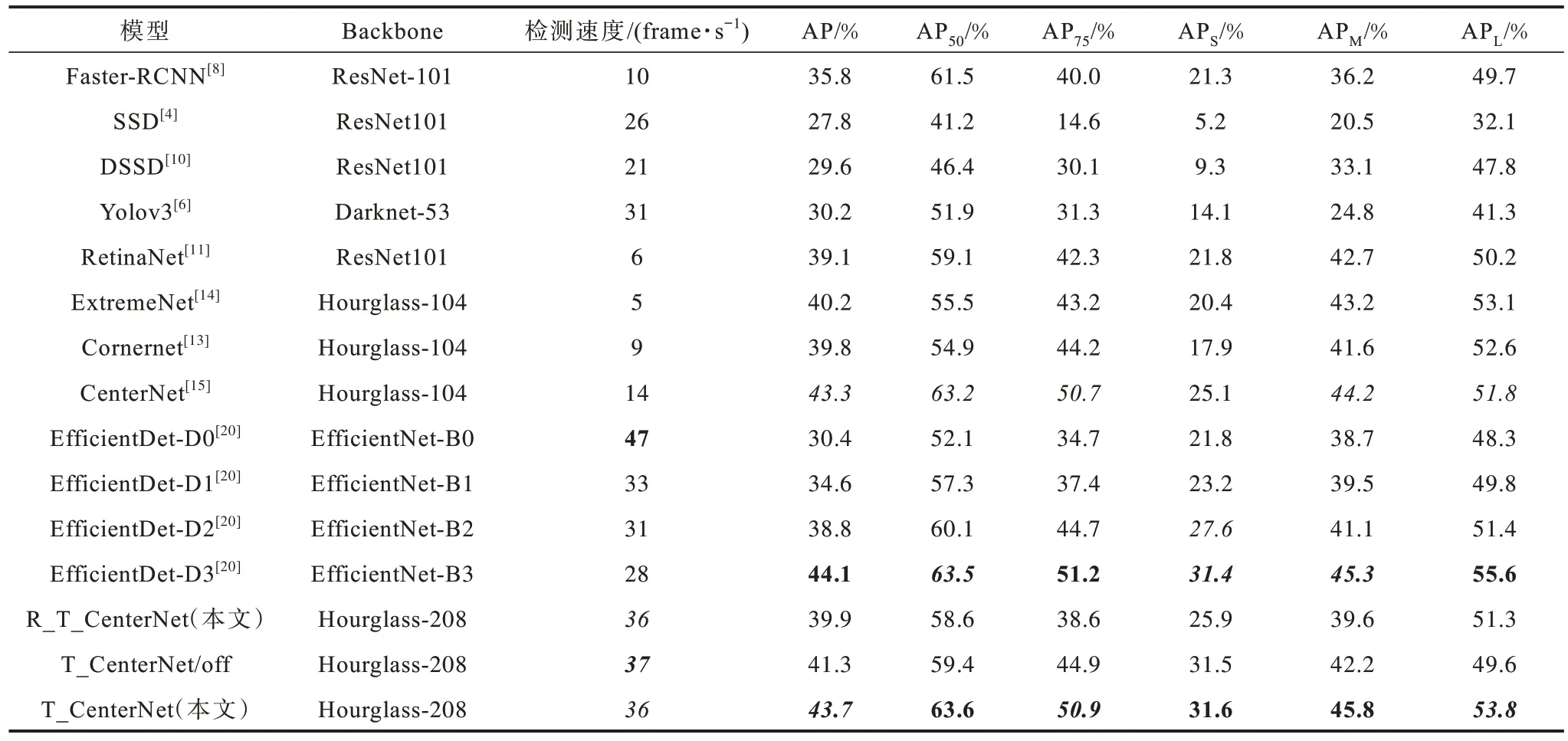
表3 在MS COCO 数据集测试图像上的目标检测结果Table 3 Object detection results on test images of MS COCO dataset
该算法模型采用TFPN 特征图融合策略后,对于原CenterNet 中多个中心点在同一位置的目标检测效果不是很理想,改善不明显,这是因为最后的目标检测还是在一个特征图上进行的(TFPN 的目标检测并不是严格意义上的用特征金字塔网络(FPN)进行目标检测)。关于该问题解决,还要考虑使用多个分辨率不同的特征图进行目标检测。同时发现,当不考虑在ImageNet 数据集上进行预训练时,T_CenterNet 算法模型在目标检测准确度的各项指标均有5%~20%的降低。因此,该算法模型经过预训练后,可以取得更好的效果。另一方面也可以得到,当模型考虑对目标中心点偏移的预测时,有利于增加该模型进行目标检测的准确率。
5 结束语
本文针对CenterNet 算法中以Hourglass 为Backbone 的目标检测模型检测速度慢的问题,提出改进的T_CenterNet 算法。在原CenterNet 算法的基础上对Hourglass 以及特征图融合等方法进行改进,将目标大小的损失函数改进为smoothL1。在MS COCO 数据集上的实验结果表明,本文提出的T_CenterNet 算法与One-stage 和Two-stage 算法相比具有竞争优势,综合性能优于EfficientDet 系列目标检测算法。下一步将对本文所提模型进行轻量化设计,以应用于嵌入式设备与移动设备。
猜你喜欢
信号处理(2022年11期)2022-12-26 13:22:06
计算机与生活(2022年11期)2022-11-15 16:17:48
计算机工程与科学(2022年8期)2022-08-20 01:39:22
昆钢科技(2022年2期)2022-07-08 06:36:38
中南民族大学学报(自然科学版)(2022年3期)2022-05-08 03:51:12
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
环境卫生工程(2021年1期)2021-03-19 05:22:28
竹子学报(2019年4期)2019-09-30 06:50:18
建材发展导向(2019年10期)2019-08-24 06:24:38
电子制作(2019年11期)2019-07-04 00:34:38
