
基于随机游走的网络表示学习推荐算法
2021-09-15 07:35:56王宝亮邹荣宇赵浩淳
计算机工程 2021年9期
刘 峰,王宝亮,邹荣宇,赵浩淳
(1.天津大学 信息与网络中心,天津 300072;2.天津大学 电气自动化与信息工程学院,天津 300072;3.天津大学 国际工程师学院,天津 300072)
0 概述
随着互联网和人工智能等信息技术的快速发展,信息量呈指数级的增长,信息过载问题日益突出。为解决这一问题,个性化推荐系统应运而生[1]。个性化推荐系统根据用户历史行为数据进行建模分析用户偏好,进而为其提供个性化的信息推荐,方便用户获取自身需求的信息[2-4]。推荐系统在给每位用户提供有针对性的商品信息推荐服务的同时过滤掉了那些用户并不感兴趣的信息,有效地节约了人们的信息筛选时间。个性化推荐系统由于在信息推荐方面的优秀表现,已成为热点研究方向。
随着各类互联网业务的快速发展,各种辅助信息的获取越来越容易,而将这些辅助信息应用于推荐算法中,将提升推荐性能,但这也对推荐算法的建模能力提出新的挑战。基于图模型的推荐算法是当前的热点方向,但是不易融合辅助信息,而网络表示学习(Network Representation Learning,NRL)强大的网络提取能力与基于图模型的推荐算法相结合,能提升算法的可扩展性。总体而言,网络表示学习是以稠密、低维的向量形式表示网络中的各个节点,并使这些低维向量具有表示和推理能力,从而将这些向量作为输入应用于节点分类、链接预测和推荐系统中。
基于上述设计思路,研究人员将网络表示学习技术应用于推荐算法中以提高其建模能力。ZHANG 等[5]利用TransR 提取物品的结构化信息,并融合物品的结构化信息、文本信息与视觉信息进行推荐。BARKAN 等[6]借 鉴Google 提 出的Word2vec方法,实现基于物品的协同过滤推荐。ZHOU 等[7]提出一种针对非对称结构的基于随机游走的网络表示学习方法。本文对经典DeepWalk[8]算法进行改进,面向推荐目标与被推荐对象为相同类型的应用场景,提出一种基于随机游走的网络表示学习推荐算法RANE。
1 相关工作
NRL 技术在早期主要是对稀疏高维的节点进行降维表示,包括主成分分析(Principal Component Analysis,PCA)、局部线 性嵌入(Locally Linear Embedding,LLE)[9]、拉普拉斯特征映射[10]等,但算法复杂度较高且应用条件较严苛,因此很难在大规模的网络中部署应用。随着NRL 技术的发展,研究人员致力于将其与推荐算法相结合,因此Word2vec模型[11]、DeepCrossing 模型[12]等应用于推荐系统的算法模型由此被提出。
Word2vec[11]模型可以较好地计算词与词之间的相似度,SkipGram 模型是其中的词向量训练模型。对于中心词而言,该网络模型在提高上下文单词出现概率的同时降低其他无关单词的出现概率。由于训练网络所使用的词汇表通常很大,如果每次预测上下文之后更新全部词汇表,则会导致过大的计算量,因此需要优化模型加速训练过程。在基于Negative Sampling 的SkipGram 模型中,对于中心词w规定上下文单词均为正样本,其余单词均为负样本,设由随机游走采样得到的上下文集合为Context(w),那么对于一组采样

其中:对于w上下文中每一个单词u都要进行负采样,Neg(u)表示对u的负采样集合。在n个单词中,wi出现的频率为f(wi),则其被采样到的概率如下:

引入标志位Lu(x),对于正采样x∊{u},令Lu(x)=1,对于负采样x∊Neg(u),令Lu(x)=0,则式(1)中的条件概率表示如下:
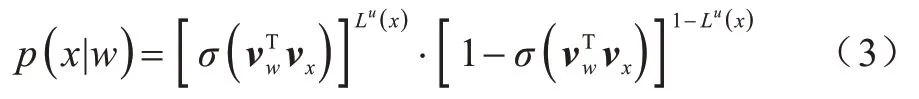
其中:σ为Sigmoid 函数;vw表示的是输入词向量与隐藏层权重矩阵乘积的结果;vx表示的是输出层权重矩阵中单词x对应某一列,称vx为单词x的辅助词向量。扩展到总语料库C,最大化目标函数如下:

为方便计算,取对数后可得最终的目标函数:

DeepWalk[8]将自然语言处理(Natural Language Processing,NLP)应用于NRL 中。DeepWalk 将网络中通过随机游走得到固定长度的节点序列看作是NLP 中的语句,将序列中的节点看作NLP 中的单词,通过实验表明由随机游走得到的节点序列组成的语料库与NLP 的语料库具有相似的幂律分布特性[8],对应真实网络的小世界特性说明该节点序列能有效描述网络结构信息,进而使用Word2vec 中的SkipGram 模型进行网络中节点的表示学习,并通过Hierarchical Softmax 模型加速训练过程。
Node2vec[13]算法在DeepWalk 基础上进行改进,在DeepWalk 中随机游走是从当前节点的邻居节点中随机均匀地选取下一个节点,而Node2vec 设计了两个参数p和q,p控制跳向上一个节点的概率,q控制跳向非上一个节点的邻居节点的概率,并以此控制随机游走的倾向。若p<1 &q>1,则游走偏广度优先遍历,着重刻画局部信息;若p>1 &q<1,则游走偏深度优先遍历,着重刻画全局信息。偏置参数的添加虽增加了算法的计算量,但使算法具有更强的可扩展性。
上述基于随机游走的算法主要考虑的是网络的一阶距离(两节点有直接连边),而LINE[14]算法中提出了网络的二阶距离(两节点有共同的邻居节点)的概念,用更多的邻域来丰富节点的表示。GraRep[15]算法则将一阶、二阶距离推广到了n阶,定义网络的n阶距离矩阵,使用SVD 算法对网络的1 到n阶矩阵进行分解,每个节点的特征由1 到n阶组合表示。
TADW[16]算法证明了DeepWalk 本质上与 矩阵分解是相同的,并在已经较为成熟的矩阵分解框架下,将文本特征引入网络表示学习。设节点的邻接矩阵为M,算法将M分解为3 个矩阵的乘积,其中矩阵T是固定的文本特征向量,另外2 个矩阵W与H为参数矩阵,使用共轭梯度下降法更新W与H矩阵求解参数,如图1 所示。
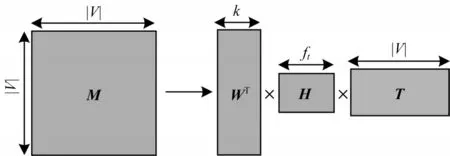
图1 TADW 矩阵分解模型示意图Fig.1 Schematic diagram of TADW matrix decomposition model
上述均为网络表示学习技术的热门算法,这些算法在推荐系统领域表现出较好的性能。本文受DeepWalk 算法的启发,提出RANE 算法,针对随机游走和网络表示两部分分别进行改进,修正游走序列数和游走长度,网络学习中融合属性信息,最终将输出用于推荐系统中,有效地提高了推荐性能。
2 本文算法
在原始的DeepWalk 算法中,各节点在网络中进行均匀的随机游走,进而得到固定长度、固定数量的游走序列,然后通过SkipGram 模型学习节点的向量表示。本文在DeepWalk 算法的基础上进行改进,RANE 算法具体步骤如下:
算法1RANE 算法
输入图G(V,E)、随机游走停止概率P、每个节点的最大游走数量maxT、每个节点的最小游走数量minT、上下文窗口大小k、嵌入维度d、负样本数量nns、顶点属性矩阵A
输出节点向量矩阵W、节点向量辅助矩阵W*、权重参数向量β

在算法1 中,首先基于网络重要性进行随机游走采样得到节点序列库,并设置停止概率控制序列长度;然后在表示学习过程中,融合属性信息进行学习;最后应用学习后的向量进行相似性表示,进而完成推荐任务。因为RANE 算法是在原始DeepWalk中添加随机游走相关参数以及融合属性信息,并未涉及其他函数的加入,所以时空复杂度基本不变。
2.1 基于节点重要性的随机游走
针对DeepWalk 算法中采样点过多的问题,重新设计随机游走策略。对于网络节点v,根据式(6)通过考虑重要性计算游走次数lv:
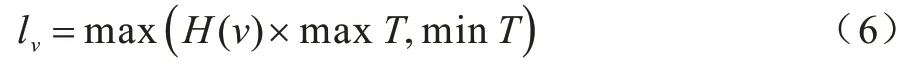
其中:maxT为随机游走的最大次数;minT为随机游走的最小次数;H(v)为节点的网络重要性。计算PageRank[17]值需要对H(v)进行数值量化,迭代公式如下:
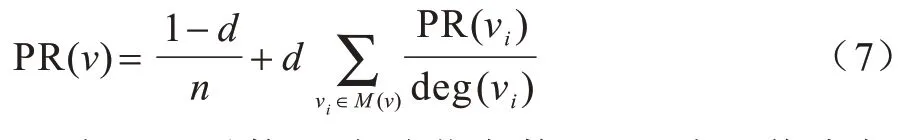
其中:d为阻尼系数;n为总节点数;M(v)为网络中与节点v关联的节点集合;deg(v)是节点v的度。通过式(7)不断进行迭代,最后趋于稳定的PR(v)值就是所需的H(v)。
另外,本文在游走过程中加入了停止概率P控制游走序列长度,即在节点每次向下一个节点游走时都有概率P结束本次游走,使得游走生成的节点序列不再是统一长度。
通过以上改进,使得重要的节点采样次数增加,可以更好地还原网络结构,并且序列长度不一,更接近真实情况。
2.2 融合属性信息的表示学习
在获得节点序列库后,本文在表示学习阶段提出利用属性信息学习节点向量表示的ASkipGram 模型。首先,应用自动编码器调整节点的属性维度[18-19],统一设置为d,所得属性矩阵为A∊R||V×d,其中,V为节点集,节点v的属性向量可以表示为Av。然后,将所得到的属性信息矩阵融入表示学习中。将属性信息和网络结构相结合得到两者的融合向量U(v):

其中:Wv为隐藏层的词向量;βv为节点v的属性权重。在式(8)中,在融合节点属性信息时,使用进行计算而没有直接使用权重βv,这样可以保证无论如何包含属性信息的部分均不可能为0,进而确保了节点的属性信息在模型训练中的参与度。在得到融合向量U(v)后,使用其代替原文中的词向量Wv与输出层的节点辅助词向量进行点积,计算得出节点v与x之间的相似度。
经过随机游走后,可采样得到节点v的上下文集合为Context(v)。对于节点v,Context(v)中的单词全为正样本,而其他单词全为负样本,因此对

其中:u为v上下文集合中的任一单词。对原模型中条件概率p(x|v)进行改进,计算公式如下:

其中:σ为Sigmoid 函数;Lu(x)为标志位,当正采样时Lu(x)=1,负采样时Lu(x)=0。由于原SkipGram 模型在训练时未考虑上下文节点与中心节点的距离,而对于推荐系统而言,较近的两节点之间应该具有更高的相似性,因此本文在式(10)中引入权重λx,v,定义该权重系数如下:

其中:D(x,v)为节点x与v之间的距离。当x与v直接相连时,D(x,v)=1;当两者之间有一个节点时,D(x,v)=2,以此类推。
将对单个节点v的计算结论扩展至总语料库C,则所有节点最大化目标函数如下:

将式(9)和式(10)代入式(12),为方便计算对式(12)取对数作为最终函数:

令L 对U(v)和分别求偏导:
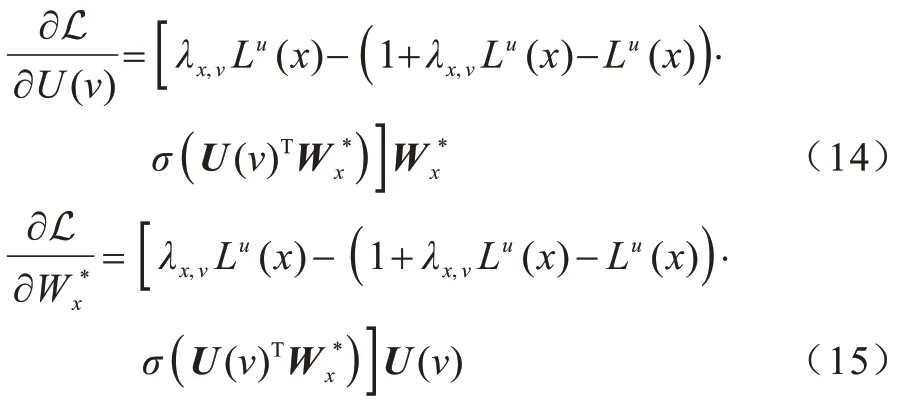
对于式(14),为在训练过程中针对每个节点进行属性权重的自适应调节,最终进行更新的参数为Wv和βv,因此分别对Wv和βv求偏导:
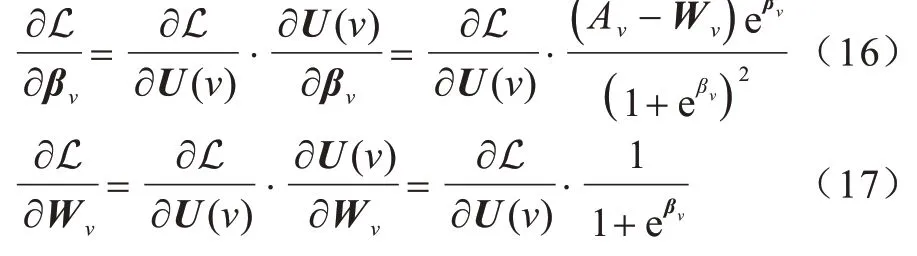
设梯度更新学习速率为η,则Wv、和βv的更新结果为:
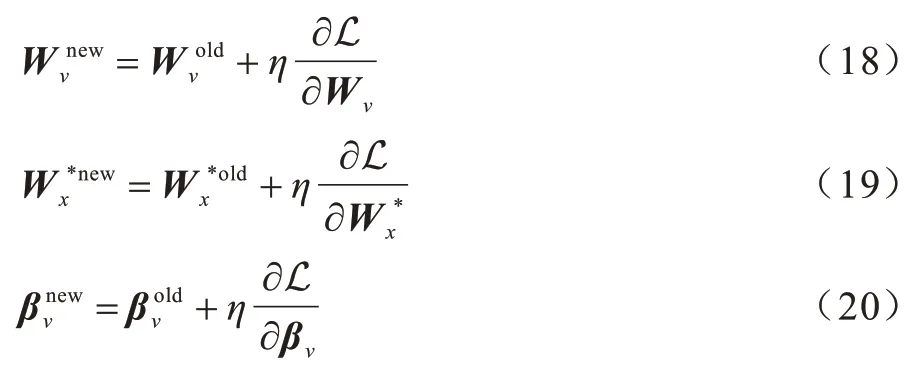
算法2ASkipGram(nns,A,k,Cv,W,W*,β)
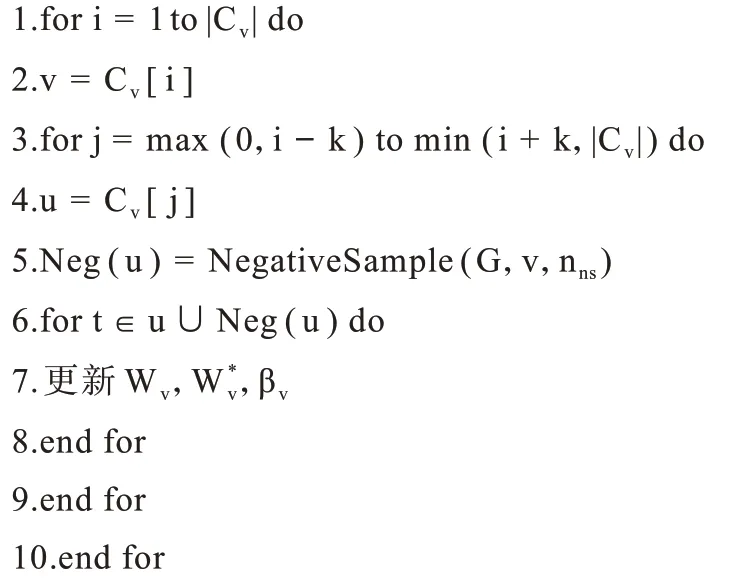
2.3 应用表示结果推荐
在同质图的推荐中,以节点相似性为依据进行推荐,而其中必然应用到以向量形式对节点进行表示。根据上文计算结果,可以得到任意节点v的向量表示:

为方便进行统一的度量,先对向量进行L2 范数归一化处理,然后使用向量内积的方式表示两节点的相似度,最终相似度计算结果如下:

对某一节点而言,利用式(22)计算出该节点与其他节点的相似度,排序后根据预先设定的阈值取出相似度高的节点进行推荐。
3 实验与结果分析
3.1 实验数据集
实验选取3 个数据集进行验证,分别为Cora、Citeseer 和BlogCatalog,其中,Cora 和Citeseer 数据集来源于科学出版物网络,BlogCatalog 来源于社交网络。具体统计信息如表1 所示。

表1 实验数据集信息Table 1 Experimental dataset information
3.2 对比算法
本文选定以下4 种算法与RANE 算法进行对比:
1)DeepWalk[8]。该算法 是本文 算法的 思想基础,采用均匀随机游走生成节点序列,并通过SkipGram 模型进行网络表示学习。
2)Node2vec[13]。该算法针对DeepWalk 的随机游走部分进行改进,控制随机游走偏向。
3)GraRep[15]。该算法是对LINE 算法的扩展,定义了网络的n阶距离矩阵并使用SVD 算法对网络的1 到n阶矩阵进行分解,每个节点的特征由1 到n阶的特征拼接表示。
4)TADW[16]。该算法是DeepWalk 算法的 扩展算法,将节点的文本信息特征矩阵融入到矩阵分解过程中,最终将得到的两个分解后的矩阵中的对应向量进行拼接,作为节点的最终嵌入表示。
3.3 评价指标
采用ROC 曲线下方面积(Area Under Curve,AUC)来评测推荐系统性能。在计算过程中,采用下式降低计算复杂度[20]:
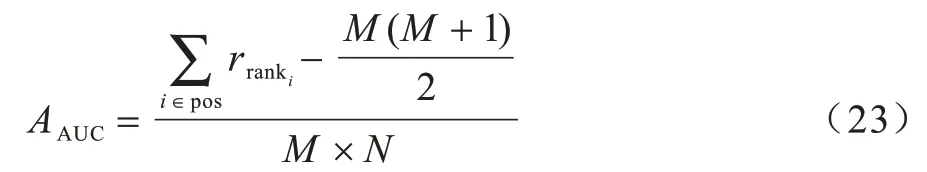
3.4 实验环境
实验环境为Ubuntu 16.04,应用Python 3.6.5 进行算法开发。为了控制实验中输出结果的可比较性,设定所有算法输出节点向量的维度均为128 维,使用余弦相似度进行节点间的相似度计算。对于使用均匀随机游走的算法,规定任一节点游走的次数为20,序列长度为40,其余参数根据实验选择最优设定。RANE 算法中maxT设为40,minT设为10,随机游走终止概率P设为0.15。在节点嵌入学习部分,DeepWalk、Node2vec 与RANE 算法的上下文窗口大小设为5,学习率设为0.01,负样本个数设为4。对于GraRep 算法设定融合1 至4 阶邻居信息组成节点向量,其余参数均沿用原论文设定。对于TADW 算法,除节点嵌入维度外其他参数依照原论文设定,取迭代至稳定的节点嵌入向量作为结果。
在实验过程中,选取数据集的10%作为测试集,其是在保证训练集中无孤立节点的情况下随机选取的,并且保证测试集中正采样与负采样数量相同。
3.5 结果分析
3.5.1 推荐性能分析
改变训练集的数量比率(R),使其占数据集的40%~90%,测试集不变,均为上文设置。对不同数量训练集,每种算法进行10 次独立测试,取平均值后作为该次实验的最终结果。
在Citeseer 数据集上,5 种算法的准确度对比结果如表2 所示。可以看出,RANE 算法在不同的训练集比率下所得结果均优于其他算法,而在训练集比率为40%的情况下,优势最明显。

表2 5 种算法在Citeseer 数据集上的准确度对比结果Table 2 Comparison results of the accuracy of five algorithms on the Citeseer dataset
在Cora 数据集上,5 种算法的准确度对比结果如表3 所示,可以看出整体趋势和Citeseer 数据集相同,RANE 算法仍然具有最优的性能表现,且在训练集比率较低的情况下优势更明显。
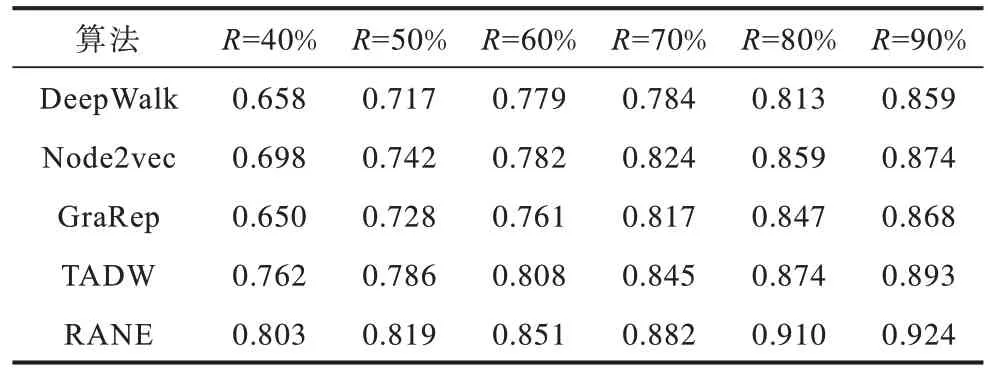
表3 5 种算法在Cora 数据集上的准确度对比结果Table 3 Comparison results of the accuracy of five algorithms on the Cora dataset
在BlogCatalog 数据集上,5 种算法的准确度对比结果如表4 所示。综合3 个数据集上所得结果可以看出,RANE 算法相比其他算法具有更好的推荐效果,并且在训练集比率较小时优势更明显,主要原因笔者认为是该算法可以更好地解决冷启动问题。

表4 5 种算法在BlogCatalog 数据集上的准确度对比结果Table 4 Comparison results of the accuracy of five algorithms on the BlogCatalog dataset
3.5.2 随机游走与表示学习模块消融实验
由于本文算法在DeepWalk 算法上对随机游走和节点表示学习两部分均进行改进,为了测试每一部分的改进对最终结果的影响情况,本文对两部分进行了消融实验。RRANE 算法表示仅改进随机游走部分,ARANE 算法表示仅改进节点表示学习部分,在BlogCatalog 数据集上进行消融实验,准确度结果如表5 所示。可以看出,两部分均对最终结果有一定的性能提升,但节点表示学习部分对整体算法的性能影响更大。

表5 RANE 随机游走与节点表示学习模块的消融实验结果Table 5 Results of ablation experiments of random walk and node representation learning module of RANE
3.5.3 随机游走模块采样效果验证
为验证改进后的随机游走策略对采样序列的修正效果,选取BlogCatalog 数据集进行实验,结果如图2 所示。设置maxT为40,minT为10,随机游走终止概率为0.15。可以看出,改进后的随机游走策略更好地保留了网络结构特性。

图2 RANE 随机游走序列节点分布Fig.2 Node distribution of random walk sequence of RANE
3.5.4 参数敏感性分析
在BlogCatalog 数据集上对算法进行参数敏感性分析。本文分析maxT与minT参数,在分别固定minT或maxT的同时调节另一个参数进行实验。如图3 所示,minT对AUC值的影响更大。

图3 min T 与max T 的参数敏感性实验Fig.3 Experiment on parameters sensitivity of min T and max T
对随机游走部分的终止概率P进行敏感性测试,设置P为0.05、0.10、0.15、0.20、0.25、0.30。如图4所示,终止概率越小,AUC 值越大,但此时游走长度更长,相应的计算量就会增大,因此实验过程中应综合考虑推荐效果与计算成本。
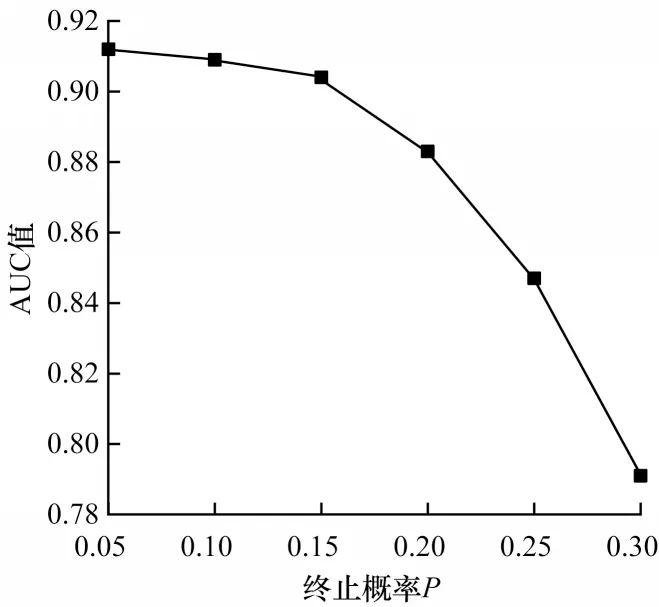
图4 游走终止概率的参数敏感性实验Fig.4 Experiment on parameter sensitivity of walk termination probability
由于RANE 算法在计算节点相似性时引入了有关上下文节点与中心点距离的权重,因此需要对ASkipGram 模型的窗口大小k进行参数敏感性分析,窗口大小依次设置为1、3、5、7、9、11、13、15。如图5所示,随着窗口的不断增大,AUC 值呈先增大后减小的变化趋势,说明窗口取得过大或过小都会影响节点网络特征的表征效果。
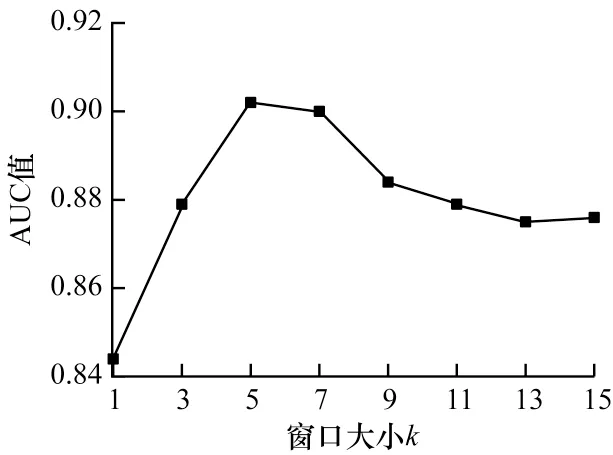
图5 ASkipGram 模型窗口大小的参数敏感性实验Fig.5 Experiment on parameter sensitivity of window size of ASkipGram model
测试节点嵌入维度d分别为16、32、64、128 和256 时的RANE 算法AUC 值,其他参数均为上文设置,在BlogCatalog 数据集上的实验结果如图6 所示,可以看出在嵌入维度为128 时AUC 取得最优值。

图6 节点嵌入维度的参数敏感性实验Fig.6 Experiment on parameter sensitivity of node embedded dimension
4 结束语
本文在DeepWalk 算法的基础上,提出基于随机游走的网络表示学习推荐算法。根据节点重要性决定游走序列数,设置终止概率使得游走序列的长度不完全相同,从而更接近真实情况。同时,在节点表示学习过程中,融合节点的属性信息,自适应调整节点属性信息权重,并考虑上下文节点离中心节点的距离,以获得更准确的推荐结果。在3 个数据集上的实验结果表明,该算法具有较好的推荐性能,并且有效解决了冷启动问题。但由于该算法随机游走部分设置的截止概率为随机生成,因此后续可将其与游走长度相关联,进一步提高推荐准确度。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
新高考·高一数学(2022年3期)2022-04-28 07:02:46
国际眼科杂志(2021年9期)2021-09-15 03:24:42
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
装备制造技术(2020年2期)2020-12-14 03:09:16
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
中国卫生(2015年12期)2015-11-10 05:13:34
南都周刊(2015年4期)2015-09-10 07:22:44
