
可见-近红外光谱的鸭梨黑心缺陷在线检测AdaBoost集成模型研究
2021-09-14 09:39王起明张书敏
光谱学与光谱分析 2021年9期
郝 勇, 王起明, 张书敏
1. 华东交通大学机电与车辆工程学院, 江西 南昌 330013 2. 南昌海关技术中心, 江西 南昌 330038
引 言
鸭梨在储藏过程中由于低温、 低氧和高二氧化碳浓度会出现内部褐变的现象[1]。 这与鸭梨组织内的多种酶类、 酚类以及膜脂过氧化等因素有关[2], 主要是多酚氧化酶与酚类物质在有氧的条件下反应生成复杂的醌类化合物[3], 醌类物质会与氨基酸、 蛋白质等发生反应产生褐色的高分子络合物。
可见-近红外光谱应用于鸭梨黑心病检测的主要原因是果实褐变过程中, 果实内部的C—H, N—H, O—H等含氢基团振动的倍频和合频在不同化学环境中对可见-近红外光的吸收波长都有明显差别。 Gabri⊇ls[4]等将可见-近红外光谱与芒果内部颜色分析获得的褐变指数值联系起来, 与人工神经网络结合可以对芒果内部褐变进行鉴别, 准确度超过 80%。 Sun[5]等使用近红外光谱结合偏最小二乘判别分析模型检测苹果内部褐变, 有21%的健康苹果被错误分类。 Mogollon[6]等针对苹果在冷藏期间容易出现内部褐变现象, 提出可见-近红外光谱结合偏最小二乘判别分析模型来预测存储开始时损坏的水果, 达到约87%的正确识别率。 Khatiwada[7]采用可见-短波近红外光谱法结合偏最小二乘对完整苹果内部果肉褐变进行静态评估, 并进行线性判别分析和支持向量机分类, 正确识别率为95%以上。 由文献报道分析可知, 在采用可见-近红外光谱分析方法对果品缺陷进行分析时, 静态分析效果较好, 而动态在线分选由于采用开放式的采集装置和较高分级效率的要求, 导致分析模型的精度较低。
针对可见-近红外光谱法在鸭梨黑心缺陷在线分选精度较低的不足, 提出了不同光谱预处理方法结合k近邻法(k-nearest neighbor, kNN)、 朴素贝叶斯法(naive Bayes classifier, NBC)、 支持向量机法(support vector machines, SVM)以及基于Adaboost的集成学习等方法对鸭梨黑心病进行在线判别, 以期得到一种高精度的果品病害在线判别模型的构建方法, 提升我国新鲜果品的质量分级水平。
1 实验部分
1.1 样品与仪器
样品: 选用河北鸭梨作为实验样品, 采用冷藏运送, 到达实验室后将鸭梨样品置于20 ℃恒温条件下保存, 实验前擦除鸭梨表面的污渍与水分。 鸭梨样品共计285个, 采用KS(Kennard-Stone)方法[8]对样品进行2∶1划分为训练集样本与测试集样本。 样品集信息如表1所示, 训练集共190个鸭梨样品, 包含正常鸭梨80个, 黑心鸭梨110个; 测试集共95个鸭梨样品, 包含正常鸭梨40个, 黑心鸭梨55个。

表1 样品集信息Table 1 Sample set information
鸭梨可见-近红外光谱在线分选装置示意如图1所示, 装置包括输送模块、 光谱采集模块和控制模块。 输送模块是由变频器和异步电动机控制, 传输速度约为每秒过5个鸭梨(约0.2 s·个-1)。 光谱采集模块是由卤钨灯和光纤探头组成, 光纤探头安装在托盘的下方, 与输送线的距离约为120 mm; 光源布置方式如图2所示, 由20盏100 W卤钨灯组成, 每侧10盏等距排列。 控制模块由PLC控制电磁阀和光电接近传感器来触发光谱仪, 完成对鸭梨样品的可见-近红外光谱的采集。

图1 鸭梨的可见-近红外光谱在线分选装置示意图Fig.1 Schematic diagram of the vis-near infrared spectroscopyonline sorting device for ‘Yali’ pear
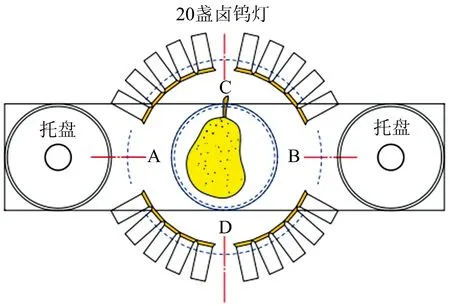
图2 卤钨灯的排列俯视图Fig.2 Arrangement top view of halogen lamp
光谱仪选用美国的QE65Pro型高精度光谱仪Ocean optics INC, 波长范围为372~1 154 nm。 开机前预热30 min, 以6.5 mm厚度的聚四氟乙烯白板作为标准参比, 校正光源能量谱; 鸭梨在输送线上的托盘里的放置方式要求果柄(C)和果蒂(D)的连线方向保持与传送带运行方向垂直。
1.2 黑心梨的破损判别
采集可见-近红外光谱后, 采用传统的人工切开识别法, 对黑心梨进行破损判别。 切开鸭梨时, 注意切开的部位是垂直于果柄与果蒂连线方向的中部, 即如图2所示的AB连线方向。 切开后观察鸭梨果核部位有无黑心症状, 对于出现褐色麻点、 整个果核褐变及果肉褐变的情况是否被认定为鸭梨患黑心病, 通过3位长期从事鸭梨种植和销售的从业者对鸭梨内部的黑心标准进行评价并综合得出结论。
1.3 判别模型构建方法
kNN算法[9]是通过计算训练集中的每个样本与测试集样本的距离, 通过对距离的排序, 取距离最近的k个点, 这k个样本中具有最多的那个类别就是测试集样本的类别。 kNN算法中k值的设定影响着模型的分类精确度,k值选择过大或过小, 都会降低分类精度, 同时也会造成噪声增加, 因此k值在选择时一般遵从低于训练样本数的平方根的原则。
NBC通过属性条件独立性假设, 假设所有属性相互独立[10]。 基于贝叶斯判定准则, 选择每个样本x中使后验概率P(c|x)最大的类别标记, 最优分类器为
式(1)中, c属于类别标记, d为属性值, xi为x在第i个属性上的取值。
SVM主要是通过找到最大间隔的划分超平面, 使得不同类别之间的间隔最大化, 在处理小样本、 非线性及高维数据等问题中具有一定的优势[11]。 通过间隔的概念, 确定模型的约束参数,SVM的优化目标为
式(2)中, n为训练样本数, xi为训练样本的支持向量, yi表示对应样本的类别, 取值为+1或-1, w为超平面的法向量, b为偏置向量, c为惩罚因子, ξi为松弛变量。
基于AdaBoost的集成学习可以通过训练多个独立的弱学习器来得到泛化性能优良的强学习器[12]。 集成学习不仅拥有更好的预测性能, 而且解决了单个学习器容易欠拟合及过拟合的问题。 算法的中心思想是通过改变样本的权值分布以得到更好的训练模型。
1.4 模型的评价
F-measue和Accuracy作为分类模型的评价指标,F-measue和Accuracy的结果越接近1, 表明分类模型越好。 其中F-measue是由P(查准率或者准确率,Precision)和R(查全率或者召回率,Recall)加权调和平均得出[13]。 混淆矩阵如表2所示。
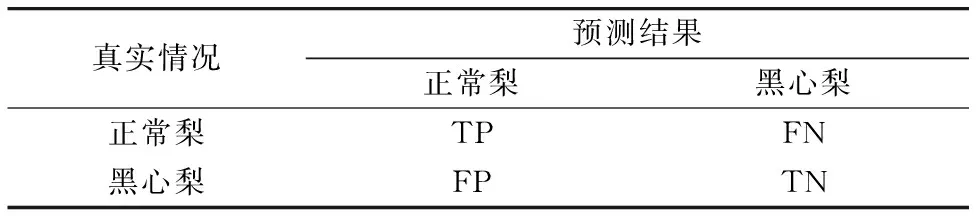
表2 分类结果混淆矩阵Table 2 confusion matrix for classification result
Precision与 Recall的计算公式如式(3)
对于鸭梨进出口贸易, 希望既要将正常梨尽可能多的挑选出来又要使得挑选出来的鸭梨中正常梨的比例尽可能的高, 即查准率和查全率都需要得到提高。F-measue公式如式(4)
Accuracy指的是正确预测的样本数占总预测样本数的比值, 公式如式(5)
2 结果与讨论
2.1 鸭梨可见-近红外光谱分析
鸭梨的可见-近红外光谱如图3所示, 从光谱的全波段来看, 正常梨与黑心梨的光谱在695和797 nm左右范围内, 都存在明显的吸收峰, 正常梨的能量谱总体上是高于黑心梨的光谱能量, 但也存在部分正常梨的光谱能量低于黑心梨, 而且光谱存在重叠, 没有一个准确的阈值分割线, 因此不能直接从光谱图中区分鸭梨是否黑心。 为了消除可见-近红外光谱存在的光散射、 基线漂移等问题, 实验分别采用平滑(Smoothing)、 标准正态变量变换(standard normal variate, SNV)、 多元散射校正(multiplicative scatter correction, MSC)、 SG一阶导数(savitzky golay first-derivative, SG 1st-Der)和小波变换(wavelet transform, WT)等预处理方法增强光谱的特异性, 以便更好地建模分析。

图3 正常梨与黑心梨的能量谱曲线Fig.3 Energy spectra curve of normal pearand black heart pear
2.2 正常和黑心病鸭梨光谱的PCA分析
采用主成分分析法(principal components analysis, PCA)对两种鸭梨样品光谱的空间分布情况进行分析。 建模集含有120个正常梨, 165个黑心梨, 对其进行主成分分析, 前三个主成分累计贡献率占99.70%, 表示这3个主成分能够解释原始波长变量的99.70%[14]。 图4所示(PC1, PC2, PC3)为正常鸭梨与黑心鸭梨样品的前三个主成分分布图。 图中黑心梨与正常梨的光谱点相互交叉在一起, 无法区分, 表明采用可见-近红外光谱结合PCA方法对鸭梨是否黑心进行定性鉴别具有一定难度, 需要进一步探讨区分黑心梨与正常梨的判别方法。
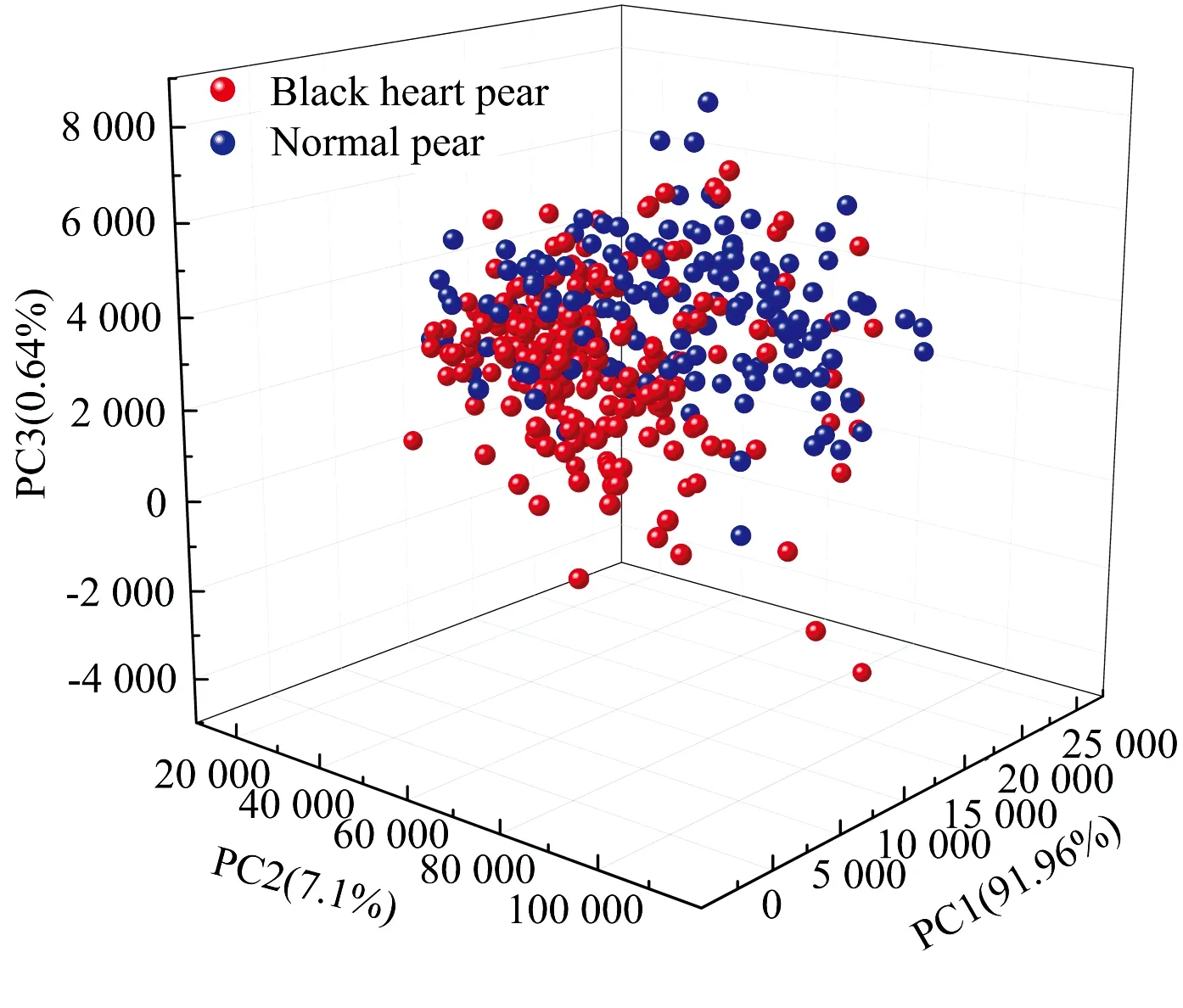
图4 正常梨与黑心梨的前三主成分分布图Fig.4 Distribution of the first three principal components of normal pears and black heart pears
2.3 鸭梨黑心病在线判别模型构建
2.3.1 独立判别模型的构建
采用kNN方法进行建模时, 其核心思想是利用训练集数据训练一个kNN分类器, 其中k(预测变量中最近邻的数量)为5。 计算训练集中的每个样本与测试集的欧氏距离, 取距离最近的5个点, 选择这5个样本中出现最多的类别标记作为预测结果。 从表3中可知, 经过小波变换预处理的kNN模型训练集的F-measure和Accuracy最高, 分别为78.98%和82.62%。

表3 不同预处理方法的鸭梨定性识别kNN模型判别结果Table 3 kNN model results of qualitative identification of ‘Yali’ pears with different pretreatment methods
NBC分类方法建模的主要原理是使用具有一定平均值和标准偏差的高斯分布对正常鸭梨与黑心鸭梨两个类别内的预测变量分布进行建模。 利用训练集的数据, 估算出基于贝叶斯分布的概率分布参数, 测试集数据根据NBC模型估计出的分布概率参数, 计算出测试集样本属于正常梨或黑心梨的先验概率。 从表4中可知, 鸭梨光谱经过SG一阶导数预处理后的NBC模型可达到最好的识别效果, 训练集的F-measure为80.90%, Accuracy为82.11%。
SVM分类是利用训练二进制支持向量机分类器建立二分类SVM模型。 使用训练集和对应的类别标签训练的SVM分类器进行二分类, 使用径向基核训练SVM分类器, 找到内核函数的比例值。 从表5中可知, 鸭梨光谱经过小波变换预处理后的SVM模型可达到最好的识别效果, 训练集的F-measure为90.24%, Accuracy为91.58%。

表5 不同预处理方法的鸭梨定性识别SVM模型判别结果Table 5 SVM model results of qualitative identification of ‘Yali’ pears with different pretreatment methods
2.3.2 AdaBoost集成模型的构建
AdaBoost分类方法集成kNN、 NBC和SVM三种分类方法, 设独立学习器数目为3。 AdaBoost模型的原理如图5所示, 通过训练集(黑心梨样品集的2/3与正常梨样品集的2/3组成)来训练kNN学习器, 根据kNN学习器对鸭梨黑心病的判别表现来调整样本权重, kNN学习器错误分类的鸭梨样本的权重得到提高, 正确分类的鸭梨样本的权值将被降低[15]; 同理, 基于调整后的鸭梨样本分布来训练NBC学习器, 鸭梨样本权值根据分类结果再一次得到重新分布; 最后, 将调整后的鸭梨样本作为SVM模型的训练集。 完成独立学习器的模型建立后, 通过加权投票法(weighted voting)得到最终的强学习器。

图5 AdaBoost算法原理Fig.5 AdaBoost algorithm principle
表6所示为不同预处理方法下的AdaBoost模型的训练集样品的查准率/查全率的调和平均和正确识别率结果。 从表中可知, 不同的处理方法其分类结果不尽相同, 鸭梨光谱经过小波变换预处理后的AdaBoost模型可达到最好的识别效果, 训练集的F-measure为91.46%, Accuracy为92.63%。
2.3.3 最优分类模型分析
通过模型查准率/查全率的调和平均和正确识别率, 综合比较kNN模型、 NBC模型、 SVM模型和AdaBoost模型。 表7可以得出, 鸭梨黑心病鉴别最优模型是WT-AdaBoost模型, 其测试集分类结果的F-measure为90.91%, Accuracy为92.63%, 模型对测试集样品预测时的计算时间约为0.12 s, 满足在线分选要求。 WT-AdaBoost的训练集(a)与测试集(b)的预测类别(红色三角形)与实际类别(黑色三角形)比较如图6 所示, 其中1代表正常梨, -1代表黑心梨, 红色三角形与黑色三角形重合代表预测正确, 否则预测错误(红色三角形+垂线)。

图6 鸭梨样品实际类别与WT-AdaBoost模型 预测类别比较图Fig.6 Comparison of actual categories and predicted categories in WT-AdaBoost model for ‘Yali’ pear samples
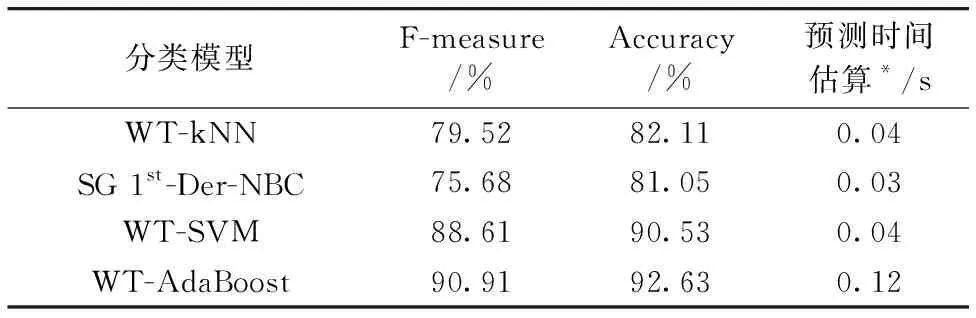
表7 kNN, NBC, SVM和AdaBoost模型测试集预测结果Table 7 KNN, NBC, SVM and AdaBoost modeltest set prediction results
3 结 论
可见-近红外光谱结合PCA, kNN, NBC, SVM和基于Adaboost的集成学习法建模对鸭梨黑心病进行判别研究, 原始光谱和5 种预处理光谱结合kNN, NBC, SVM和Adaboost方法用于鸭梨黑心病判别模型的建立和优化。 实验结果表明: PCA方法无法在主成分空间将黑心鸭梨与正常鸭梨区分开来; 小波变换预处理方法结合由kNN, NBC和SVM集成的AdaBoost分类方法建立的分类模型最优, 训练集与测试集的F-measure分别为91.46%和90.91%, Accuracy分别为92.63%和92.63%, 且模型对测试集样品预测时间约为0.12 s, 满足在线分选要求。 可见-近红外光谱结合WT-AdaBoost分类方法, 可以实现对鸭梨黑心病的在线检测。
猜你喜欢
小学生优秀作文(高年级)(2022年4期)2022-04-25
青少年法治教育(2020年12期)2020-06-08
作文大王·低年级(2020年5期)2020-05-25
快乐语文(2018年33期)2018-03-06
数学大王·中高年级(2018年1期)2018-01-30
制导与引信(2017年3期)2017-11-02
中老年健康(2016年11期)2017-02-05
工业设计(2016年11期)2016-04-16
环境科技(2015年6期)2015-11-08
电网与清洁能源(2015年2期)2015-02-28
