
生成对抗网络的银行不平衡客户流失预测研究
2021-09-14 02:46谢玖祚
重庆理工大学学报(自然科学) 2021年8期
李 波,谢玖祚
(重庆理工大学 计算机科学与工程学院, 重庆 400054)
不平衡数据分类在分类任务中是一个极具挑战性的领域[1]。在此类问题中往往最有价值的都是对少数类样本的识别。例如在商业银行领域中的客户流失问题中,银行与银行之间的竞争趋于白热化,以目前市场饱和的现状而言,保留现有客户需要付出的成本小于发展新的客户成本[2]。若不能精准知晓那些数量较小的已流失的客户,会对企业造成无法挽回的损失。但由于不均衡数据的分类特性,有很多传统的分类方法针对少数类别的预测效果很差,例如贝叶斯、支持向量机等,这些分类方法大都是为了使整体分类精度最大化而设计提出的,在分类的时候,预测多数类准确度比少数类的准确度高很多[3]。从这个角度而言,研究与探索分类策略对处理不平衡分类问题意义非常重大。
为了解决这个问题,近些年来,国内外诸多学者提出了许多方法[3]。其中一类常见方法是对不平衡数据本身进行数据处理。其关键思想是通过对训练集预处理,来减小不均衡类之间的差异。换言之,就是通过改变训练集中少数类和多数类的先验分布,以获得不同类之间更平衡的实例数量。数据生成就是一种通过复制合成少数类样本来增加少数群体比例的方法。SMOTE[4]就是一种经典的生成方法。SMOTE的主要思想是沿着线段生成少数类样本,该方法也提出了许多变体,并证明了它们的有效性,如Majumder等[5-6]提到的ADASYN和Borderline-SMOTE。其他方法更侧重于分类算法。其中集成学习方法一直是提高数据集分类器性能的常用方法[7]。在其他方法中,代价敏感学习[8]和单类别学习也已经被证明是解决不平衡数据问题的实用而有效的方法。
生成对抗网络(GAN)近年来得到了广泛的研究[9]。与传统的人工神经网络不同,生成对抗网络是一类生成模型,它通过2个网络组成的竞争过程学习:生成器(G)以随机变量作为输入学习生成可以欺骗鉴别器的虚假数据,而判别器(D)则试图将真实数据与生成的数据区分开来。如果对网络进行良好的训练,生成器就将生成与真实数据十分相似的假数据骗过鉴别器。自提出以来,GAN已成为一种广泛应用于不同机器学习领域的方法,尤其是在计算机视觉和图像处理领域[10-12]。
本文中提出了一种基于生成对抗网络的数据不平衡分类策略。将该模型应用于少数类样本的生成,并使用机器学习对原数据集和补全数据集进行分类实验,通过对比实验验证了该模型的有效性。
1 相关工作
1.1 常用不平衡数据分类方法
通常情况下,可以采用2种方法处理不平衡分类问题,一种是基于数据层面,另一种是算法层面[3]。其中数据层面有2类方法,分别是数据删除和数据生成。常用的删除方法有2种。随机欠采样(RUS)排除了来自多数类的随机样本,而聚焦欠采样(FUS)排除了存在于2个类之间边界上的多数类样本。ROS是最传统的一种过采样方法,可以随机生成少数类样本,而SMOTE则是一种更为常用且有效的方法。
在SMOTE[13]方法中,通过取每个少数类样本并沿着连接所有选定的K个少数类最近邻的线段引入合成的例子对少数类进行生成。根据所需的生成样本量,从K个最近的邻居中随机选择邻居。
SMOTE算法过程描述如图1所示。首先,对于少数类的每个观测x,识别其K近邻,如图中红色方形样本所示。然后随机选择K个邻居(这个数字取决于不平衡比率)。最后,沿着连接原始观测样本x与其最近邻居的直线生成新的数据。
上述2类方法的弊端是显而易见的。删除数据可能会导致原始数据集中包含的信息丢失,而原始数据的简单复制可能不会提高少数类的有效性。
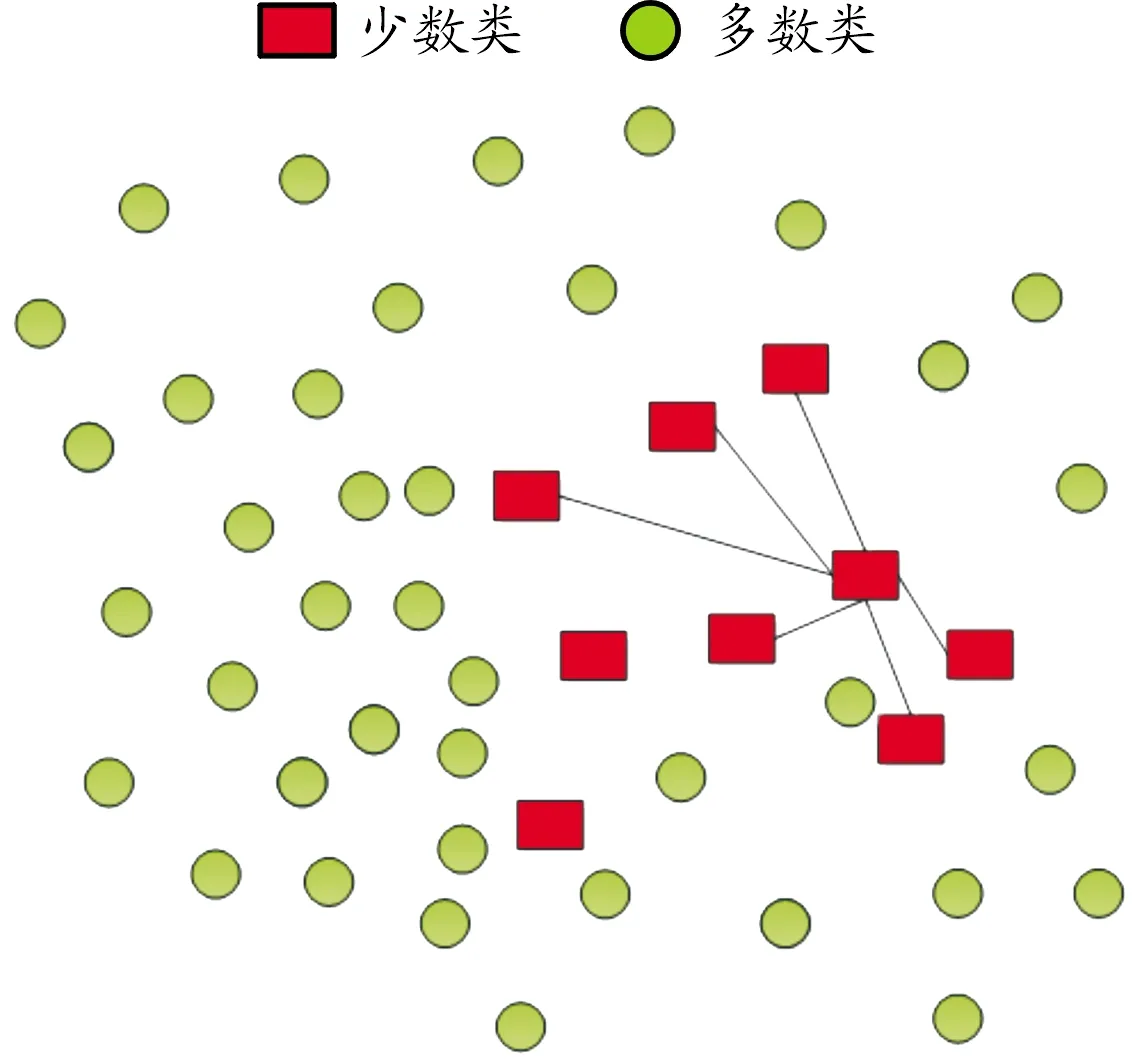
注:方块是少数类 圆型是多数类
1.2 生成式对抗网络
生成式对抗网络(GAN)是受博弈论启发和影响的一种生成模型,该模型由生成器以及判别器组成[14]。G(z)是由D(x)产生的模拟真实样本伪样本。其中:z指的是随机噪声,x指的是真实样本。GAN的优化可以看成是如何极小化、极大化[9]。其损失函数是:
Ez~p(z)[log(1-D(G(z)))]
(1)
式中:p(x)表示真实的样本分布;p(z)表示噪声分布,E(*)表示期望。其中,GAN模型既包括判别器的优化过程式(2)也包括生成器的优化过程式(3)。
Ez~p(z)[log(1-D(G(z)))]
(2)
(3)
生成对抗网络是一种通过训练样本而得出新样本的网络结构[9]。生成对抗网络的核心是通过训练集来预估它的样本是如何分布,然后再利用得出的样本分布生成另一个和训练集相似的样本。图2为GAN模型结构框图。
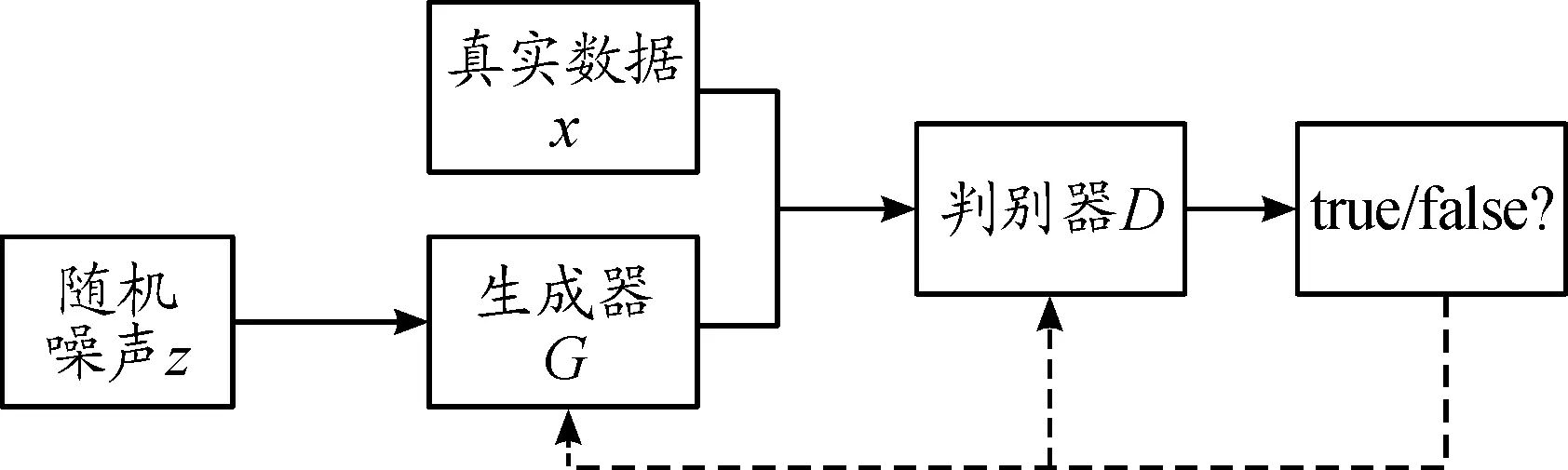
图2 GAN模型结构框图
目前,该模型广泛应用于图像视觉[10]、异常检测[11]、信用卡欺诈等领域[12]。与传统的生成模型对比,GAN模型不需要基于真实数据就可以生成逼近真实数据的合成数据[9]。
2 基于GAN的少类数据生成模型构建
2.1 特征工程
特征工程(feature engineering,FE)对于模型的性能提升起着非常重要的作用[15]。它的输入是原始数据,而输出是模型训练所需的数据集,FE能够筛选出效果更好的属性用于训练,让模型的训练效果得到改善与提高。特征处理、特征分析、特征选择是特征工程的3个主要步骤,其中最关键的是选择特征。本文中选择的方案是基于RF(random forest),是一种学习算法,其基于决策树,并且实现简单,开销较小,而且在分类问题上也有着优异的性能[15]。用RF算法来做特征选择,不仅能解决特征过多导致的过拟合问题,还能通过改善特征,加快训练速度,改善模型效果。

(4)
式中:K表示有K个类别,pnk指的是在节点n中类别k的比值。从客观层面上而言,指的是从任意节点n中随机选择2个样本,他们标记不同的几率。节点n分枝前后GI指数变化量是
(5)
式中:GI1指的是分枝后1节点的GI指数,GIr同理。假如在决策树i中,特征Xj出现的节点在M中,则在第i颗树中,Xj重要性为:
(6)
假设RF中共有m颗树,那么
(7)
最后,将全部所得的重要性评分集中归一化处理。
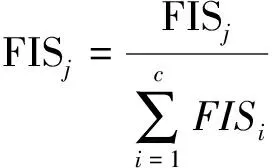
(8)
2.2 激活函数
通常情况下,神经网络模型的神经元激活函数是Sigmoid。但是,Sigmoid函数存在梯度消失造成模型训练收敛缓慢的问题。一般以ReLU函数(修正线性单元)将其替代[10]。ReLU与Sigmoid相比,有着易于优化的优势,并且由于它的定义域的一半范围输出为0,使得网络结构变得更加稀疏,对过拟合起着缓解作用;而定义域的另一半范围输出的梯度保持为1,这便意味着对于学习来说它的梯度将会有更好的效果。然而在训练时ReLU这个函数也有着“脆弱”的缺陷,即当网络进行第一次训练时若权重为0以下,按照ReLU函数的计算公式,之后的训练将一直为0。为解决这种现象,使用LeakyReLU函数。LeakyReLU作为ReLU函数的一种特殊形式,在神经元出现不激活现象时仍会有一个小梯度的非0值输出,从而规避了可能的神经元的“消逝”。式(9)(10)分别是ReLU、LeakyReLU的函数公式。ReLU的作用是把负值刷新为零,LeakyReLU的作用是把负值刷新为非零斜率。
(9)
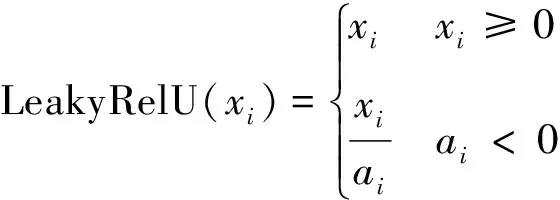
(10)
式中:ai指的是位于(1,+∞)区间中的固定值,基于LeakyReLU的角度而言,若斜率较小,则它和ReLU区别非常小,反之,效果更佳。
2.3 批标准化(Batch Normalization)
深度学习训练较为复杂。如果某一层数据出现了较小的变化,那么层变化会逐渐增大,此时就必须调整网络参数来适应新数据的分布。批标准化则是解决这一问题的有效方法。
批标准化可以说是一个重参数化的算法,它能够自适应。为了有效避免由于网络层数的逐步增加,梯度出现消失或者爆炸的问题,引入了批标准化来对各个层的输入进行规范,从而固定各层输入信号的方差以及均值。通常情况下,用于在非线性映射以前规范x=Wu+b,使得它的结果全部为0,方差为1。让每一层的输入有一个稳定的分布会有利于网络的训练。
上述批标准化的单位是随机梯度下降批量样本,对数据做统一处理,使得概率分布在每一个维度都趋于稳定,他的均值是0,标准差是1。同时,为了使经过归一化学习到的特征免受破坏,γ、β2个参数需要被引入,然后利用2个参数变换重构数据。若某层的输入是x=(x(1),…,x(a)),而且有a维,同时将batch-size置成n,那么一批的样本集合为B={x1,…,xn},则批标准化如下:

(11)
(12)
(13)
y(k)=γ(k)x′(k)+β(k)
(14)

2.4 生成网络
使用全连接层作为本文网络的生成模型。该网络生成器与鉴别器的结构借鉴了Sethia等[10]提出的关于信用卡欺诈检测的GAN模型的思想,该网络相比于图像领域常用的WGAN、f-GAN、DCGAN 等网络,在面对银行领域的结构化数据的时候更加适用,本文的网络在改善了VGAN网络结构的同时,在生成器的输入层和隐藏层中使用了上文提到的批标准化(Batch Normalization)策略,从而减少了网络对各个参数的敏感程度,训练过拟合风险越来越小,网络收敛越来越快,而且还可以防范梯度消失或者爆炸、协变量移位等问题。
生成网络由6层神经网络组成,包括输入层,隐含层和输出层。其中生成器的输入为200维的随机噪声,激活函数采用上述LeakyReLU函数。网络包含4层隐含层,节点数分别为64、128、256、512,激活函数仍都采用了LeakyReLU。最后生成网路输出层节点数是25,元素区间是[0,1],故输出层激活函数选择tanh。
2.5 判别网络
判别网络同样为6层神经网络,包括输入层、隐含层和输出层。为了“压平”输入,在判别器模型全连接之前加入了另一个层,那就是Flatten层,从而实现了多维输入的一维化。输入的一部分数据来自于真实数据,而其他的来自于网络生成的数据。其中判别器输入层节点数是25,网络包含4层隐含层,节点数分别为512、256、128、64,激活函数使用上文所述的LeakyRelU函数。输出层的节点数为2,且激活函数选择了Sigmoid,通过对数据源的判断,采用Binarycrossentropy(二元交叉熵损失函数)来减小损失误差,提高分类精度。综上,生成模型整体结构如图3所示。
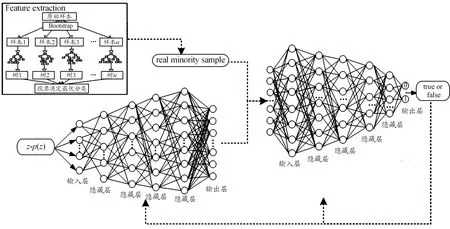
图3 本文的模型整体结构示意图
3 实验评估与结果分析
3.1 评估指标
分类问题常采用准确率(accuracy)作为衡量分类效果的标准,但是对于不均衡数据问题,仅使用accuracy作为度量指标是不够的。因为在不均衡数据中,正负类样本的数量差异会很大,那么就会出现多数类预测精确度非常高,然而少数类预测准确度非常低。对于这种情况,在使用准确率的同时使用了Precision、Recall、F-mean作为评估指标,既能客观地评价数据集的性能,也能兼顾各类别的分类精度。表1表述了二分类中的混淆矩阵种类。其中FN、FP指的是错误分类正负样本数量,TP、TN则指的是正确分类正负样本数量。

表1 二分类中的混淆矩阵种类
根据表1的矩阵种类得到以下评估指标,其中查准率(precsion)和查全率(recall)的公式如式(15)(16)所示。
(15)
(16)
通常情况下,Precision、Recall的相对重要度由β值来调和,一般值是1。若少数类Precision、Recall两者的值都比较大的时候,F-mean值才会更大,因此F-mean能够更精确地反映出少类分类性能,公式如下。
(17)
3.2 实验数据集与实验设计
实验数据是某商业银行的客户数据。该数据具有很高的不平衡比率,多类和少类的比例达到了20∶1,其中数据样本量多达8万,数据维数高达600。在使用GAN模型训练前,首先需用上文提到的RF算法进行特征选择,再使用PCA算法进行特征降维,最终保留25,各特征进行后续的训练。之后,为了充分展示不平衡数据的分类特性,选用了少类和多类的比值为1∶1到1∶20之间的数据(如表2所示),来进行部分预测实验。

表2 少类和多类的不同比值的数据
同时为了验证GAN模型对银行少类样本的生成效果,实验将使用平衡处理后的数据作为训练集,不平衡数据作为测试集,对少类进行预测实验。并与BSMOTE(BS)、ROS、ADASYN(AS)、SMOTE等不平衡处理算法进行对比。实验流程如图4所示。
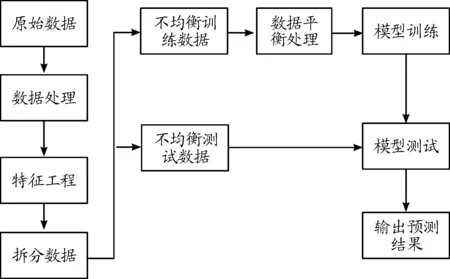
图4 实验流程框图
3.3 实验结果分析
图5为GAN模型判别器的损失下降曲线,损失值在迭代次数1 000次左右时趋于稳定。
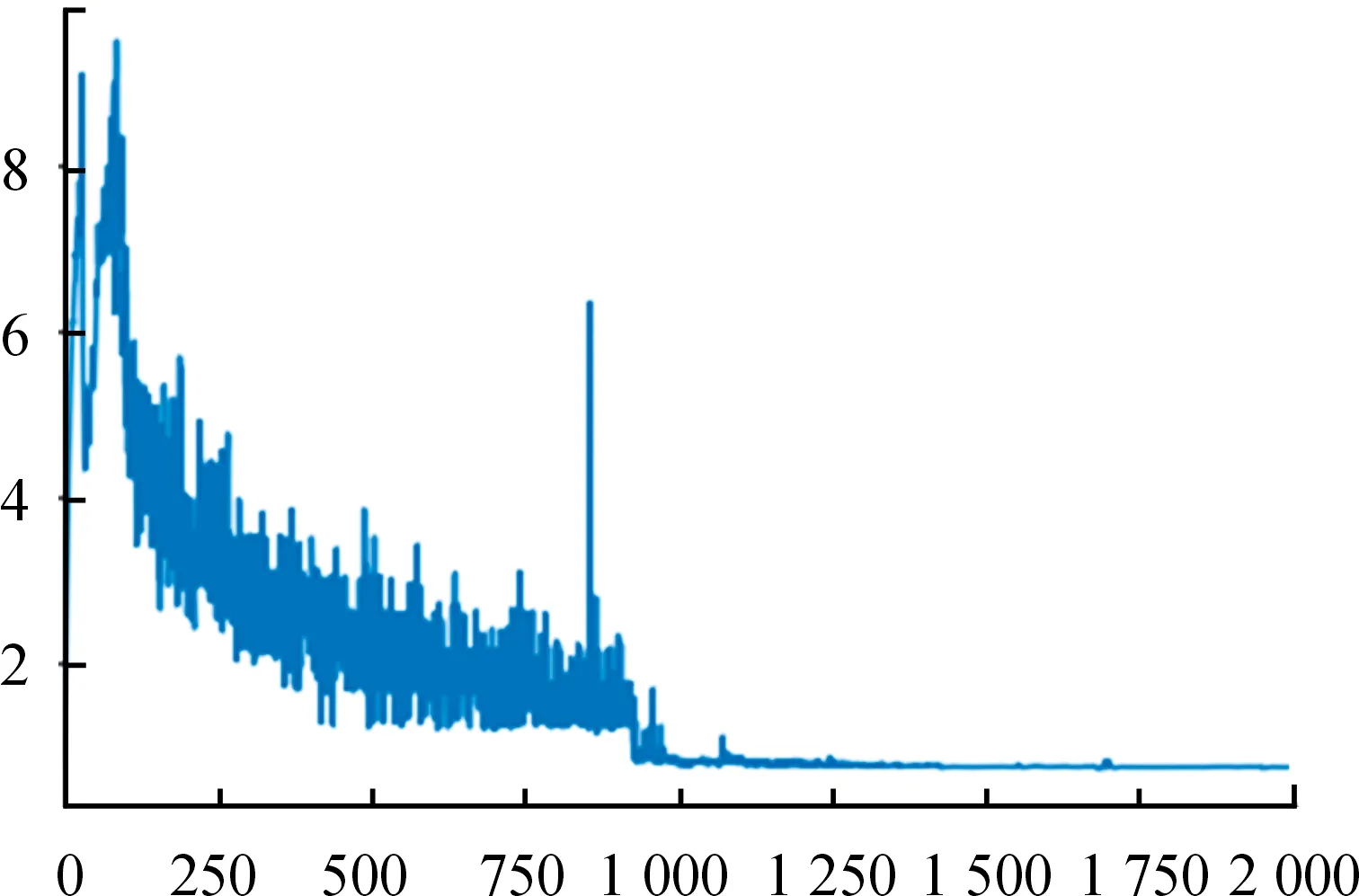
图5 判别器损失函数曲线
使用LightGBM(LGB)、随机森林(RF)验证不平衡分类的倾向问题。实验先预测多类样本准确率,其结果如图6所示。
从图6结果可以看出,LGB与RF在不同比例的非均衡数据上对多数类预测稳定性较好,具有倾向性。其次,分别使用这2种机器学习算法与GAN模型组合,并与上文中提到的SMOTE、AS等多种不平衡处理算法进行实验对比。实验结果如图7、8所示。
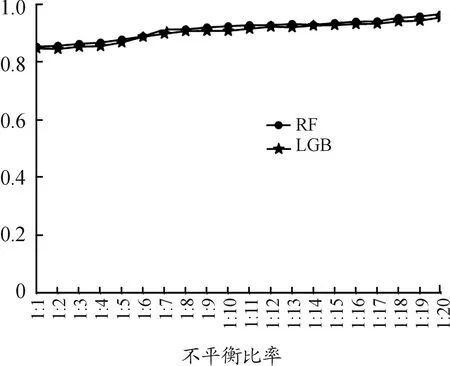
图6 多类预测准确率曲线
图7、8中,分别采用RF、LGB算法测试各不平衡处理算法和GAN模型在测试集上的分类预测效果。从图7、8中均可以看出,LGB与RF算法在本文GAN模型处理过的数据上的准确率要优于其他不平衡处理算法。
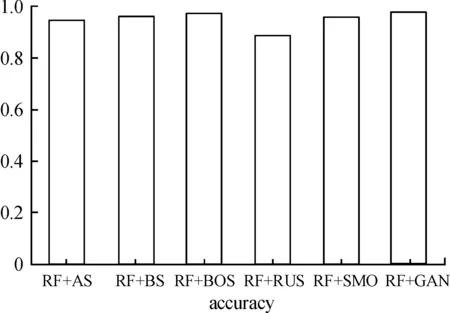
图7 RF在数据集上的准确率直方图

图8 LightGBM在数据集上的准确率直方图
上述实验,尽管证明了经本文中提出的GAN模型处理后的数据在整体预测准确率上的效果,但在反映类别不均衡数据分类效果的提升上仍不够全面。因此,还需要使用上文提到的Precision、F-mean度量指标,上文提到的各种不平衡处理算法的结果如图9所示。

图9 各算法在数据集上的Precison值直方图
从图9可以看出:RUS(随即欠采样)效果最差。LGB和RF算法与GAN模型的组合在指标Precision上效果最好,其中LGB+GAN的组合相比传统方法中综合效果较好的ROS和SMOTE算法分别提高了0.338和0.405。而RF+GAN模型的组合则分别提高了0.179和0.359。图9只是实验对少类样本预测性能的分析,但这还并不能综合反映GAN模型对少数类样本的分类能力。因此,还要利用F-mean指标对数据生成后的样本做分类效果评估,实验结果如图10所示,LGB+GAN模型的组合在F-mean指标上,相比LGB算法与RUS、ROS、SMOTE、AS、BS的组合分别提高了0.369、0.137、0.171、0.165、和0.258。而RF+GAN在F-mean指标则分别提高了0.307、0.136、0.097、0.154和0.062。

图10 各算法在数据集上F-mean值对比
综上,从数据处理着手,提出的GAN模型在准确率、F-mean等指标上好于其他不平衡处理算法。因此,其对于商业银行客户数据不均衡的分类问题有着较好的适用性,其中LGB+GAN的模型组合得到了最好的指标效果。
4 结论
将图像领域常用的生成对抗网络应用到商业银行客户流失问题中,提出了一种基于GAN网络的结构化数据生成模型,改善了银行客户流失问题中少数类的生成以及预测问题。
与ROS、SMOTE等多种常用不平衡处理方法进行了比较。实验结果表明:该方法能较好地避免SMOTE等算法合成样本的盲目性,提高了合成样本的质量,让数据生成更具针对性,进而使分类结果有较好的准确率、F-mean及Precision值,其应用在银行客户流失不平衡分类问题上具有可行性和适用性。但本次实验只是在数据层面上进行了改进,如何在算法层面上进行改进与优化,将是以后研究的重点和难点。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
中学生数理化·中考版(2021年3期)2021-07-22
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·高一版(2021年2期)2021-03-19
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
知识经济·中国直销(2018年8期)2018-08-23
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
