
基于关键词注意力的细粒度面试评价方法
2021-09-13 01:54陈楚杰吕建明沈华伟
计算机研究与发展 2021年9期
陈楚杰 吕建明,2 沈华伟
1(华南理工大学计算机科学与工程学院 广州 510006) 2(大数据与智能机器人教育部重点实验室(华南理工大学) 广州 510006) 3(中国科学院计算技术研究所 北京 100190)
随着互联网技术不断发展,异步视频面试技术越来越成熟[1].面试者只需登录到特定的平台,回答出平台上事先设定好的问题.之后面试官们在平台上评估面试者的面试表现,从而判断面试者是否能进入下一轮的面试.这种方式和线下面试相比,大大缩短了招聘周期,面试者在任何地点和任何时间都可以回答问题[2].
然而,在招聘需求比较旺盛的季节,如针对大学校园招聘的春招和秋招季,异步视频的数量会急剧增加,并且由于全球疫情的蔓延,越来越多的公司采用了这种异步视频的面试形式,使得面试官需要耗费大量的精力处理视频.有研究表明,面试招聘标准越客观,该公司的绩效相对就越好[3-4],而在实际面试中,面试官通常是在一个连续、集中的时间内,根据一系列的标准对应聘者们的表现做出评价,这些评价会受到周围环境的影响.例如前面应聘者的评分结果可能会影响到面试官对后面应聘者的评分决策,这是面试官的记忆容量瓶颈所导致的.由于面试过程中,面试官需要在短时间内对应聘者的表现做出分析,因此面试官会重点关注与评分标准相关的信息,以此形成应聘者人格特性、沟通技能以及领导力等方面的画像评估,从而做出评分决策.在此过程中,面试官对前面应聘者的记忆会短暂存储下来,当应聘者数量过多时,面试官的工作记忆便会超负荷,因此长时间处理视频的状态下难以保证面试官评价的客观性[5-6].
作为缓解面试官人力瓶颈的自动化工具,自动面试评价旨在于针对面试者所做出的回答,自动分析出面试者的人格特性、沟通技能以及领导力等方面的特质,从而辅助面试官判断面试者的特质是否符合其岗位胜任要求,避免了面试官可能存在的主观性.其中的人格特性评估是公司间最广泛使用的一种评估方法[7],因为人格特性影响着人们的语言表达、人际交往等多个方面,比如人际敏感度过高的人在人际交往中会更加在意他人的评价,导致与他人相处时存在社会焦虑[8].因此本文将重点研究面试评价中的人格特性评价.然而,为了训练精准可用的自动化评价模型,往往需要大量专业人士的精标数据,构建代价昂贵.与此同时,已有的自动化评价模型可解释性较低,无法结合人力资源部门的先验专业知识.
基于上述挑战,文本提出了一种基于循环神经网络长短期记忆(long short term memory,LSTM)以及关键词-问题注意力机制的多层次(hierarchical keyword-question attention LSTM,HKQA-LSTM)细粒度面试评价方法.该模型是一种2阶段学习的分层注意力网络:第1阶段中,通过结合人力资源顾问的专业知识,我们将外部具有指导意义的关键词、问题作为输入,根据面试者在面试中表现出的社交信号[9-10],评价其不同人格特性的得分,例如针对面试题目“请分享一个实例说明您是如何带领团队成功完成某一个任务的?”,如果面试者的回答表述中蕴含沟通、合作、共赢、资源共享等类似含义,则面试官会倾向于认为该面试者的人格是较为宜人合群的;其次,考虑到面试官在面试中会对面试者的综合表现进行评估,即分析面试者的综合素质是否符合应聘岗位,从而决定是否录取[11].基于此,模型在第2阶段的训练中,通过融合不同人格特性特征向量,对面试者回答的问题进行了一个总体打分.实验结果表明,本文提出的方法能有效地评价面试者的不同人格特性得分与总体得分,在性能上明显超过基线方法.
1 相关工作
1.1 细粒度面试评价
结构化面试(structured interview)是面试中经常采用的一种面试形式,它根据特定职位的胜任能力要求,采用固定的一套设计题库,是一种标准化、公平性强的面试形式.心理学研究组织证明,结构化面试比非结构化面试更加有效地反映面试者能力[12-13].面试者要在有限时间内证明自己的就业资格.面试官根据面试者的回答,对其人格特性、沟通技能、领导力等方面进行评价,在对面试者有一个总体印象的基础上,面试官会进一步考虑目标岗位的实际需求,判断该面试者的特质是否适合其应聘的职位[14].其中人格特性评价是公司间广泛使用的面试评价方法[7],因为它有着持久、稳定的优点,并潜在影响着人们的社交表达,比如社交自信型的人往往会使用更多积极的情感用语,并且对他人会表现出更多的认同和称赞[15].
细粒度面试评价(特别是自动评估面试者的细粒度人格特性)是社交计算中一个有趣的问题.随着大数据热潮的到来以及计算机算力的提高,人工智能在图像识别与自然语言处理领域均得到了成功的应用,因此也被研究者用来解决面试评价中的人格特性分析问题.
过去的细粒度人格特性分析研究主要依赖于较为繁琐的特征工程,即通过人工定义的一些规则进行特征提取,再利用机器学习方法进行预测.Aydin等人[16]使用随机森林对视频中的人物性格进行预测;Sinha等人[17]收集企业的社交媒体帖子,利用词之间的相似度等统计特征分析员工的6种人格特质(诚实-谦恭性、情绪性、外向性、宜人性、尽职性、经验的开放性);Nambiar等人[18]利用音频和词汇特征,结合线性回归、隐含狄利克雷分布(latent Dirichlet allocation,LDA)主题生成模型以及支持向量机方法,对面试者的说话流畅度、自信心等特质做出预测;Muralidhar等人[19]通过场景模拟,收集了169个结构化面试数据集,使用支持向量机对面试者的积极性、热情性等人格特性进行预测;考虑到人们交流过程中经常会使用非正式文本,钟毓等人[20]利用基于主成分分析的方法,探究非正式词语与说话者人格特性之间的关系.
近年来,神经网络理论与应用不断发展,其中特定的网络结构,比如循环神经网络,可以很好地对文本进行表征建模[21-22].因此,针对自动面试评价的问题也涌现了不少使用神经网络的方法.Chen等人[23]应用神经网络为基础的Doc2Vec模型,对面试者的人格特质进行预测;Hemamou等人[24]专门收集了销售职业的结构化面试视频,使用循环神经网络模型对面试者的语言以及非语言行为(面部表情、语音)进行建模,预测面试者的可雇佣性;Suen等人[25]使用卷积神经网络,提取120位面试者的面部特征,预测他们的5种人格特性.
1.2 注意力机制
Bahdanau等人[26]首次在自然语言处理领域(natural language processing,NLP)中引入了注意力机制,并用在了以编码器-解码器为框架的机器翻译任务中,提高了翻译的准确率.经过实验证明,注意力机制能有效地筛选出重要的信息,并提高神经网络的可解释性[27].因此,在自动面试评价中引入注意力机制,可以使神经网络更多地关注面试者文本中包含的有效信息,忽略不重要的信息.
不少研究者针对不同NLP任务的具体特点,提出了不同的注意力计算方式.Lin等人[28]提出了一种基于自我注意力(self-attention)机制来提取句子的可解释性嵌入;Yang等人[29]根据文档中存在词语、句子、篇章这种层次结构特点,提出了一种基于层次注意力(hierarchical attention)机制的模型,用来捕获输入的层次结构信息.
总体上,基于注意力机制的循环神经网络能有效地对文本序列进行建模,但是仅仅依靠端到端的训练而没有融入人力资源的专业知识的方法往往依赖大量的数据训练,需要消耗人力资源顾问大量的时间进行样本标注,人力成本极高.此外,以往面试评价中注意力向量通常是由端到端的学习得来,面试官无法得知注意力权重所表达的含义.基于此,本文结合人力资源顾问的专业知识,将关键词与问题2种外部信息嵌入到模型中,提高了模型的可解释性,并且能在小样本上取得较好的预测效果.
2 基于关键词注意力的细粒度面试评价方法
2.1 任务定义及方法概述
总体任务结构如图1所示.本文将自动面试评价任务形式化描述为一个回归任务:给定一个面试者表述的文本内容W=(w1,w2,…,wn)和关键词词组Ki=(ki1,ki2,…,kim),预测对应的面试者不同人格特性得分yi以及对应的总体评分z.其中n是文本W的长度,i是人格特性项的下标,Ki是不同人格特性下的关键词词组,m是词组Ki的长度.任务定义中,模型除了在第1阶段对面试者的不同人格特性进行打分,还会在第2阶段根据第1阶段抽取出的人格特征向量,对面试者进行小题总分z的预测,人格特征向量的融合分为先融合与后融合2种模型.

Fig.1 The overall task structure图1 总体任务结构
鉴于注意力机制在神经网络模型中有着出色的表现以及可解释性,本文在自动面试评价中引入关键词以及面试问题2种外部信息作为注意力导向.其中关键词是通过对面试者的回答进行词频统计,接着人力资源顾问依据专业经验筛选出最能代表其人格特性的关键词,不同的人格特性关键词最终形成关键词表,本文实验部分给出了关键词表示例.由于模型训练过程中有了人的参与,该方法能有效提升模型的可解释性.
此外,考虑到面试者在面试中往往会分层次地表达自己的观点,本文使用句子-文档的层次网络来模拟面试者表述文本中的层次结构关系.在句子层次中,我们使用关键词注意力来对句子进行建模,筛选出句子中的重要单词.在文档层次中,我们使用问题注意力来对句子层次的输出进行建模,筛选出面试者表述中更贴切问题的回答,下面将对我们的方法做出详细介绍.
2.2 基于关键词注意力机制的双向LSTM模型
双向LSTM网络能有效编码上下文信息[30],本文为了使双向LSTM模型能关注到面试者表述中的不同重要信息,从而分析出面试者的不同人格特性,提出了一种基于关键词注意力机制的双向LSTM模型.不同于以往的方法,我们考虑到面试官往往会根据面试者表述中的文本内容来推断面试者的教育背景和人格特征,因此提出了关键词注意力以及关键词匹配2种机制,重现面试官在视频面试中采用的评价方法.
如图2所示,模型包含词向量层、双向LSTM层、关键词注意力层、关键词匹配层、多层感知机(multi-layer perceptron,MLP)层与sigmoid层,接下来对基于关键词注意力机制的双向LSTM模型进行介绍.

Fig.2 Keyword attention model图2 关键词注意力模型
1)词向量层.给定面试者表述的文本内容W=(w1,w2,…,wn)与人格特性关键词词组Ki=(ki1,ki2,…,kim),该模型首先使用由百度百科语料预训练的中文词向量[31],将基于词袋模型的one-hot向量转换成嵌入向量表示,我们将文本内容的嵌入矩阵记为X=(x1,x2,…,xn),作为双向LSTM层的输入.将关键词词组的嵌入矩阵记为Ei=(ei1,ei2,…,eim),作为关键词注意力层以及关键词匹配层的输入,设j为输入元素的下标,i为人格特性项的下标,We∈d×N为预训练词向量,其中d为词向量的长度,N为词表的大小,则
xj=Wewj,
(1)
eij=Wekij.
(2)
2)双向LSTM层.将嵌入矩阵X=(x1,x2,…,xn)输入到LSTM层,在获得前向LSTM与后向LSTM的编码输出后,对其进行拼接,得到双向LSTM层的输出H=(h1,h2,…,hn),设Γ为LSTM的基本单元,则
(3)
(4)
(5)
3)关键词注意力层.将关键词嵌入矩阵Ei=(ei1,ei2,…,eim)输入到MLP层做映射,形式为
(6)
其中Wk∈d×d,bk∈d,记映射后的矩阵为将矩阵作为注意力机制的导向,此时,不同的矩阵将会分配不同的注意力权重到双向LSTM的输出中.因此模型能够根据不同的人格特性,关注到面试者文本信息中的不同方面.注意力计算方式为
(7)
(8)
(9)
(10)
其中att为注意力函数.根据注意力函数计算ht的权重uit后,对uit进行归一化处理得到ait,最后根据ait对矩阵H=(h1,h2,…,hn)中的元素进行加权求和,得到特征向量si.
4)关键词匹配层.除了考虑经过上下文编码的隐含向量外,我们认为原始的嵌入向量表示同样重要,因此引入了关键词匹配机制.人力资源顾问形成的关键词表中,共包含卓越关键词词表、优秀关键词词表、普通关键词词表,我们将其嵌入后的矩阵分别记为Ei,Gi,Oi,其中i是关键词词组的下标.关键词匹配的计算方法为
vi=[match(Ei,X);match(Gi,X);
match(Oi,X)],
(11)
(12)
(13)

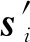
(14)
其中F为缩放因子,即实验中设定的总得分.
2.3 关键词-问题层次注意力网络
考虑到面试过程中面试者表述的内容是具有层次关系的长文本,且不同的句子表述的内容相对问题来说有侧重点,受Yang等人[29]工作的启发,我们将长文本分为句子层次以及文本层次,在引入关键词注意力的基础上,采用了一种关键词-问题的层次注意力网络,用来捕获文本信息中的层次结构信息.此外,模型使用2阶段的学习机制,在第1阶段中,模型针对文本信息输入,预测不同的人格特性得分;在第2阶段中,模型将对第1阶段输出的人格特征向量进行融合,得到面试者小题总得分.
2.3.1 第1阶段训练:单项人格特性项训练
(15)
(16)
(17)

Fig.3 Keyword-question attention model图3 关键词-问题注意力模型
在结构化面试过程中,面试者需要围绕问题内容进行回答,因此我们在文档层次上融入了问题注意力机制,该机制会将面试者回答文本中更加贴合问题的语句赋予更高的权重,设问题为Q=(q1,q2,…,qv),其中v为问题长度,将问题输入到LSTM中进行编码,形式为
(18)
(19)
将LSTM层中最后一个时间步输出的隐含向量作为问题编码向量u′,问题注意力计算方式为
(20)
(21)
(22)
经过问题注意力机制加权处理后,获得人格特征向量ci,ci在通过MLP层与sigmoid层的计算后获得面试者该项的分数预测:
yi=F×sigmoid(Woci+bo).
(23)
任务的目标函数为均方误差(mean-square error,MSE),给定N对回答记录-人格特性关键词-问题对(Wi,Ki,Qi),MSE损失的计算方式为
(24)
其中,p(Wi,Ki,Qi)为模型预测得分,y(Wi,Ki,Qi)为面试官打的真实得分,λ为L2正则化惩罚项的因子,θ为模型参数.
由于在模型训练的过程中,面试问题和面试者作答共同作为输入信号进行编码和参与训练,模型所学习到的是面试问题和面试者作答之间的匹配程度,因此模型不依赖于特定的问题,具有较好的泛化能力.在实际的应用中,可通过提高面试问题的多样性,进一步提升问题适配能力.
2.3.2 第2阶段训练:人格特性特征融合
将第1阶段训练得到的基础模型进行迁移,设输入的文本信息为W,基础模型输出的第i项人格特性的特征向量为ci,i∈[1,k],k为人格特性项个数,如图4所示:
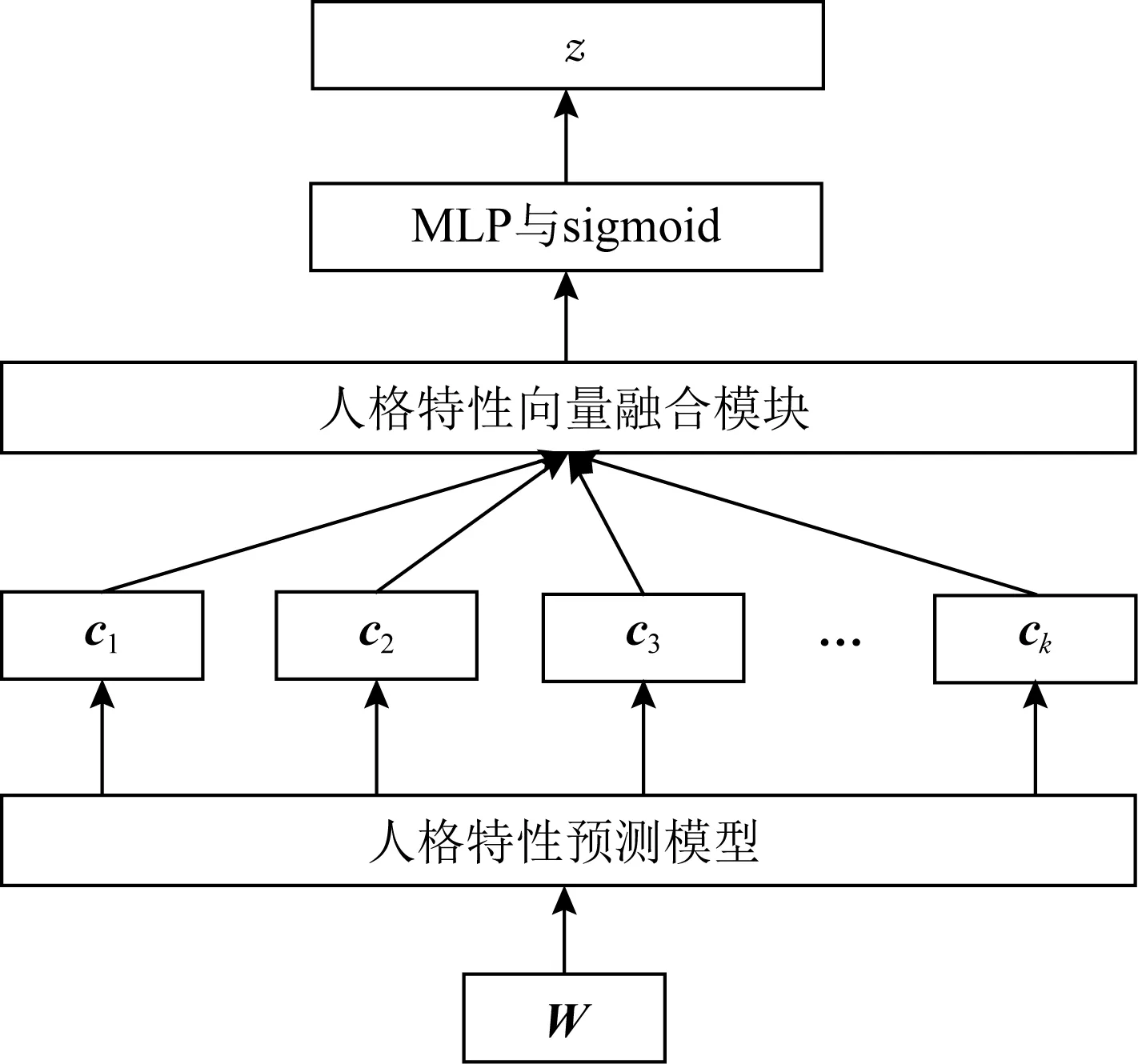
Fig.4 Personality traits vector fusion图4 人格特性特征向量融合
我们将不同人格特性的特征向量进行融合,分别使用先融合和后融合2种模式,计算方式为
(25)
zlast=F×sigmoid(Wr[c1;c2;…;ck]+br).
(26)
先融合模式中,我们把不同的特征向量取平均;后融合模式中,把不同的特征向量进行拼接;获得融合的特征向量后,将其输入到MLP层与sigmoid层,得出面试者的小题总分预测.
与2.3.1节相同,任务的目标函数为MSE,设给定基础模型M以及N个回答记录Wi,设p(Wi,M)为模型预测的小题总得分,z(Wi)为面试官对该问题的真实打分,则损失的计算方式为
(27)
3 实验与分析
3.1 实验数据
我们通过与人力资源公司进行合作,搭建了异步在线面试平台,模拟了真实场景下的结构化面试过程.面试共分为3道题,每道题设定5min答题时间.首先,我们邀请面试者登录平台,针对事先设定好的题目进行回答录制,接着3位专业的人力资源顾问依据评分标准,将对面试者进行人格特性打分(包括乐于说服他人、乐于改变、考虑周详等18项人格特性)以及小题总分打分,打分范围为0~5分.最终3位能力资源顾问所打的分值取平均,作为面试者的最终得分.打分过程中根据面试者回答记录做出词频统计,人力资源顾问分别选出最能代表人格特性的关键词形成卓越、优秀、普通关键词表.我们最终共收集了96位面试者的面试数据.表1给出了数据集的详细说明,表2给出了人力资源顾问形成的关键词词表中的其中一项示例.

Table 1 Statistics of Interview Datasets表1 面试数据集统计信息
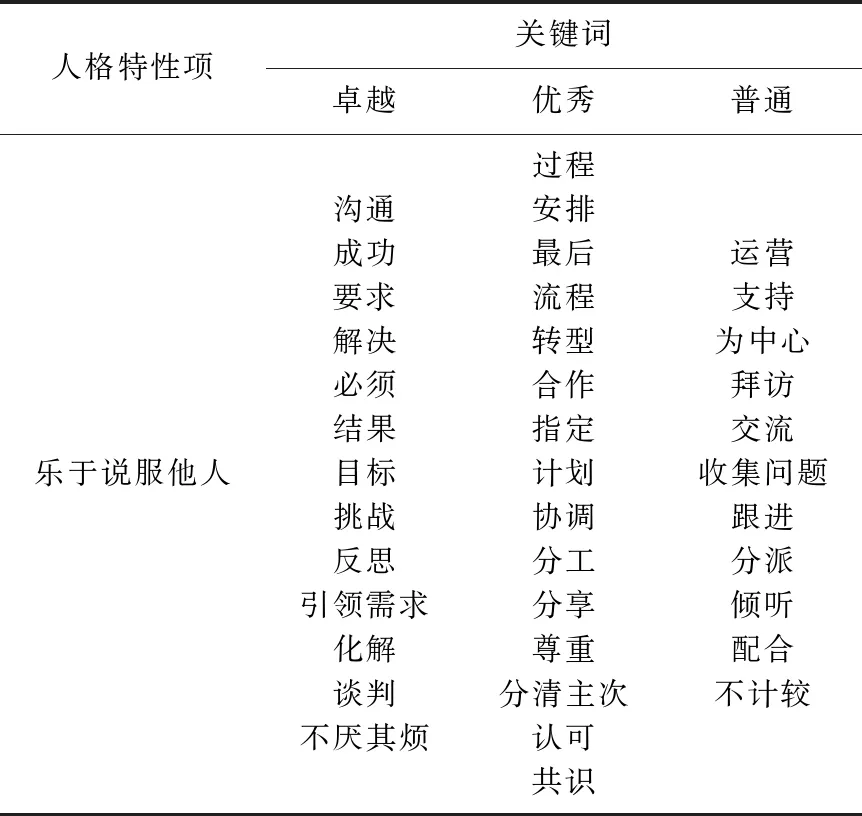
Table 2 Examples of Keywords表2 关键词示例
3.2 评价指标
评价指标除了模型训练阶段使用的MSE之外,本文还采用皮尔逊相关系数(Pearson correlation coefficient,PCC)、斯皮尔曼秩相关系数(Spearman’s rank correlation coefficient,SCC)来表示模型预测结果与人力资源顾问打分的相关程度.此外,二次加权Kappa(quadratic weighted Kappa,QWK)也常作为分数预测类任务的评价指标.QWK会对预测分数与真实分数差值较大的项做出更大的惩罚,计算方式为
(28)
(29)
其中,O是观察分数矩阵,E是预期分数矩阵,i和j分别指实际分数和预测分数,R是分数能取得的最大值.矩阵O和矩阵E需要进行归一化.归一化前的Oi,j的值表示实际标签为i分、模型预测为j分的数量;归一化前的矩阵E通过实际标签值、模型预测值2个向量做外积得到.
3.3 参数设置
我们对训练集、验证集、测试集按8∶1∶1的比例划分.使用预训练的中文词向量[31],维度设置为300,对于词表中不存在的词,词向量进行随机采样,采样范围为[-0.01,0.01].优化器选择Adam-optimizer,学习率设置为0.001.LSTM的隐藏层维度设置为200.第1阶段训练的batch_size设置为128,第2阶段训练的batch_size设置为16.对于最大句子长度与句子中的最大单词数长度,我们使用网格搜索,在句子最大长度设置为15,句子中单词数最大长度设置为20的条件下实验结果最佳,因此实验中统一采用此参数.此外,为了防止过拟合,实验中加入了dropout机制与L2正则化机制,并在训练过程中采用了early stopping技巧.为了避免实验的随机性,本文在实验上采取10折交叉验证,以产生不同的训练集、验证集和测试集,选择在10折交叉验证中的测试数据集上结果的平均值作为模型最终表现.
3.4 实验对比与结果分析
本文采用3个基线模型用于对文本信息进行编码,并将编码向量输入MLP层与sigmoid层进行预测,用来与我们的模型作比较:
1)BiLSTM.该模型利用一个双向的LSTM来对文本信息进行编码,考虑了上下文关系.模型中的记忆门缓解了序列模型容易发生梯度消失、爆炸的问题,使模型可以学习到长文本中远距离的依赖关系.
2)HA-LSTM(hierarchical attention LSTM)[29].该模型考虑了文本的层次结构并融入了注意力机制,将文本信息中不同的句子输入到LSTM中获得句子向量表示后,再将不同的句子向量表示输入到另一个LSTM中获得输出.
3)KA-LSTM(keyword attention LSTM).该模型为2.2节介绍的基于关键词注意力的双向LSTM模型.
表3给出了我们的方法(hierarchical keyword-question attention LSTM,HKQA-LSTM)与其他不同的基线模型的性能对比,分别比较了面试数据集中人格特性项以及小题总分的预测情况.从表3可以发现:
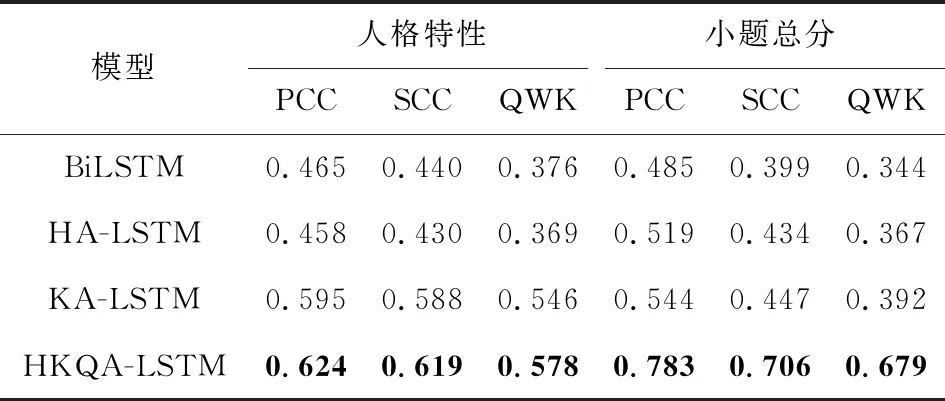
Table 3 Performance Comparison of Different Models表3 不同模型性能对比
1)HA-LSTM模型在小题总分的预测上效果比BiLSTM模型效果有一定的提升,其中PCC高出0.034,SCC高出0.035,QWK高出0.023.说明在面试过程中,面试官从整体上看更注重面试者表述文本信息的层次结构.即对于面试官来说,他会被面试者回答记录中的某几句话着重吸引,这也符合现实场景,证明了层次建模的重要性.
2)KA-LSTM模型在人格特性以及小题总分的预测上效果比BiLSTM模型、HA-LSTM模型有优势,说明在文本信息编码的过程中,关键词注意力机制发挥了作用,我们将关键词作为注意力的外部导向,可以有效地对重要的信息进行保存,对不重要的信息进行过滤,并且提高了模型的可解释性.
3)从整体上看,HKQA-LSTM模型取得的效果均高于基线方法,说明关键词注意力机制以及问题注意力机制能有效地关注到更精确的局部信息,从而帮助模型提升预测的准确性.层次结构也使得模型能够捕获更长序列的依赖关系.
4)对于小题总分的预测,HKQA-LSTM模型比KA-LSTM模型有了较大的提升,PCC高出0.239,SCC高出0.259,QWK高出0.287.这种现象的原因在于HKQA-LSTM模型使用了2阶段学习的训练方式,模型在第2阶段的训练中,对第1阶段抽取出的人格特性向量进行融合,使得文本表征更加丰富.
表4列出了我们的方法(HKQA-LSTM)与基线方法在测试集上的预测值与真实值的对比,使用MSE来评估不同模型的表现.可以看出,在人格特性和小题总分2种预测上,本文方法的预测值相比于基线方法都更加接近真值.与HA-LSTM相比,人格特性预测值与真实值的MSE误差由1.764降低到了1.376,小题总分MSE 误差由0.695降低到了0.314.
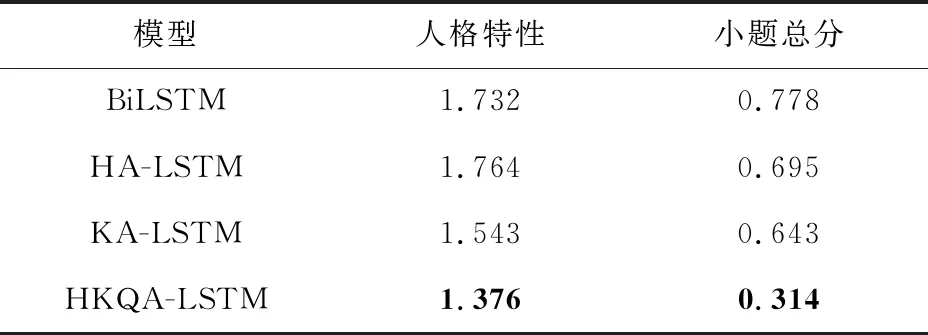
Table 4 MSE Results of Different Models表4 不同模型预测结果的均方误差
为了验证本文提出的方法对细粒度评分预测的准确程度,我们对18项不同人格特性的预测做出比较分析,使用PCC来评估不同方法的表现.实验结果如图5所示:
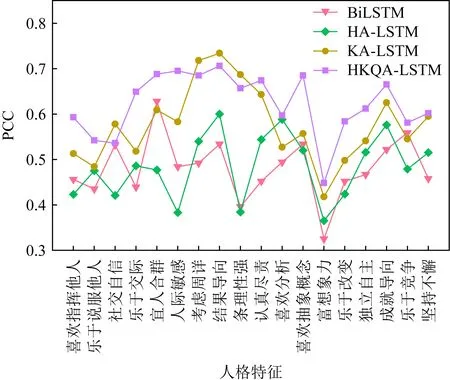
Fig.5 Comparison of fine-grained ratings of different models图5 不同模型细粒度评分对比
从图5中可以看出,相比与基线方法,本文提出的2种基于关键词注意力的方法在不同人格特性预测的表现上都更为优秀,主要原因在于面试者的口语表述是相对较长的文本,我们的方法拥有关键词注意力机制,可以更有质量地捕捉到不同人格特性下所侧重关注的不同词语和句子,从而使得模型预测效果得到提升.
为了判断模型是否能真的分辨出面试中综合表现较为卓越的面试者,我们将模型对小题总分的预测结果分为2类,即卓越(小题总分≥2.5)与一般(小题总分<2.5),评价标准采用准确率(Precision)、召回率(Recall)和Macro-F1.
我们分别尝试了先融合模式(HKQA-LSTM-Early)和后融合模式(HKQA-LSTM-Late),对第1阶段抽取出的人格特征向量进行融合.表5展示了2种模式的实验对比.

Table 5 Accuracy of Total Score in Different Modes表5 不同模式下小题总分的预测精度
从表5可以看出,后融合模式比先融合模式有更好的效果,其中Macro-F1值提高了2.9%.造成这种现象的原因是,在实际面试过程中,由于题目的不同,面试官所关注的面试者的人格特性侧重点也不同.而后融合模式的计算方法可以动态地调整不同人格特性的权重,更符合实际的面试情况,因此对于模型的准确率、召回率都有一定的提升.
3.5 案例分析
为了分析关键词注意力机制预测不同人格特性的有效性,我们进行了样例分析.图6包含了2个可视化的例子,我们对文本信息编码过程中单词、句子注意力的权重进行了高亮显示,其中颜色越深说明该单词或句子的注意力权重越大.

Fig.6 Attention weight visualization of interview texts图6 面试文本注意力权重可视化
从图6的可视化例子中可以看出,我们的模型可以有效地关注文本信息中重要的单词,忽略掉不重要的单词.并且针对不同的人格特性,关键词注意力机制使得模型可以关注到同一文本的不同方面.如图6(a)中,为了判断面试者的“乐于改变”人格特性,模型更加关注“打破”“梳理”“挑战”等词.而图6(b)中,由于考虑的是面试者的“考虑周详”人格特性,模型则将注意力更多地放在“用户”“客户”“调试”等词,因此该模型可以有效地帮助面试官进行决策.
图7展示了模型预测误差较大的一项人格特性项“富想象力”.在该例子中,模型对不同句子的注意力比较平均,并将单词注意力更多地放在了重复率较高的一些名词上.这是由于关键词表中,人力资源顾问给出的该人格特性项的关键词为“提出”“战略布局”“新思路”等,与面试者所表述的出入较大,导致最后模型对各个句子的注意力较为分散.此外,从图5的细粒度评分比较中可以看出,模型对于人格特性项“富想象力”的预测与面试官打分的相关程度较低.一个可能的原因是“富想象力”本身是一项较为抽象的人格特性,因此面试官在打分的过程中会受到面试者的声音、表情动作等其他方面的影响.

Fig.7 Example of negative samples图7 负例举例
4 结 语
本文提出了一种基于关键词注意力机制的细粒度面试评价方法,模型利用外部的关键词以及问题作为模型不同层次上的注意力导向,对面试者面试过程中所展现出来的不同人格特性进行预测.模型对第1阶段训练得到的人格特性表征尝试了不同的融合方式,得到第2阶段的最终模型.在数据集上的实验结果表明,本文提出的模型能有效地对面试者的不同人格特性进行细粒度评价,对于不同的人格特性,模型能筛选出同一文本中不同的重要词句,有效帮助面试官做出决策.
在未来的工作中,我们将考虑进一步探索面试中的语音、视觉模态特征并融合进模型中,并在模型增量学习过程中产生新的人格特性关键词,让人力资源顾问参与完善关键词表,考虑基于图谱的方法挖掘关键词词语之间的同义、上下位等更丰富的语义关系.结合其他半监督的学习方法,通过利用更多面试过程产生的无标签数据来进一步提升细粒度评分的性能.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
茶道(2022年3期)2022-04-27
作文中学版(2021年9期)2021-11-21
作文·初中版(2021年9期)2021-10-11
中学生数理化·高一版(2021年11期)2021-09-05
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
情感读本·道德篇(2019年2期)2019-05-09
CHIP新电脑(2017年6期)2017-06-19
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
