
用于人体实例分割的卷积神经网络
2021-09-10 07:22鞠成国王国栋
青岛大学学报(自然科学版) 2021年1期
鞠成国 王国栋

摘要:针对当前的实例分割算法无法分割两个高度重叠的人体对象,且量化的Mask实例与其ground truth之间的IoU的Mask质量通常与分类分数相关性不强等问题,利用人体骨骼和姿态来对人体进行分割,增加一个全新的Evaluation模块,利用预测Mask与ground truth之间的IoU来描述实例分割质量,提出了一种直接学习IoU的网络,能够提高实例分割的质量。为了获得更加丰富的特征信息,采用ResNet和FPN网络进行特征提取,融合多层特征的信息,使分割结果更加准确。实验结果表明,提出的网络框架对人体分割的结果更加准确,具有更加优越的鲁棒性。
关键词:卷积神经网络;FPN;Evaluation模块
中图分类号:TP291
文献标志码:A
文章编号:1006-1037(2021)01-0034-06
基金项目:国家自然科学基金(批准号:61901240)资助;山东自然科学基金(批准号:ZR2019MF050, ZR2019BF042)资助。
通信作者:王国栋,男,博士,副教授,主要研究方向是人工智能、深度学习。E-mail:doctorwgd@gmail.com
近年来,由于对现实生活中应用的大量需求,计算机视觉领域中有关“人”的研究越来越受到关注,例如:人脸识别[1-6],行人检测[7-9]和跟踪,异常行为检测等。其中许多已经在现实生活中产生了实用价值。在此之前,已经有许多实例分割的算法[10-11],目前比较流行的主流的方法是基于深度学习的分割方法[12-14],例如:ResNet、Fast R-CNN、Faster R-CNN、Mask R-CNN、PANet[15-19]等网络结构,对实例分割的算法基本类似:首先生成图像中的多个候选区域,然后在生成的候选区域中,用非极大值抑制算法(NMS)从中删除不符合要求的候选区域。但是,当图像中存在两个高度重叠的对象时,NMS会将其中的一个边界框视为重复的候选区域并将其删除,表示这些算法无法区分高度重叠的两个对象。而人在生活中普遍会出现紧密相连的画面,所以用上述基于候选框的方法存在某个人不能被分割出来从而造成实验结果的不准确。除此之外,在当前的网络框架中,检测的分数(即假设由分类得分中最大的元素决定)由于背景杂波、遮挡等问题,分类分数可能较高,但Mask质量较低,利用候选框得到的实例Mask的分数通常与box分类置信度有关,使用分类置信度来度量Mask质量是不合适的,因为只用于区分proposal的语义类别,而不知道实例Mask的实际质量和完整性。通过对上述问题的研究,本文发现利用人体骨骼的特殊性能够更好的把图片中的人精准的分割出来,从而避免了候选框所带来的漏检情况,所以本文利用人体骨骼对人体分割,通过人体的关键点将人体骨骼连接起来,利用人体姿态[20-23]对人进行准确的分割;提出了一个全新的模块Evaluation模块,该模块的作用是使IoU在预测的Mask及其ground truth的Mask进行回归,该模块解决了Mask得分情况与其Mask质量不匹配的情况。
1 基本原理
本文提出一个全新的模块,用来计算Mask分支得到的Mask与ground truth对应的Mask之间的像素级别的IoU值(以下简称IoU),来衡量分割的精确程度。首先选用ResNet50网络作为特征提取网络,ResNet网络事实上是由多个浅的网络融合而成,避免了消失的梯度问题,所以能够加速网络的收敛。
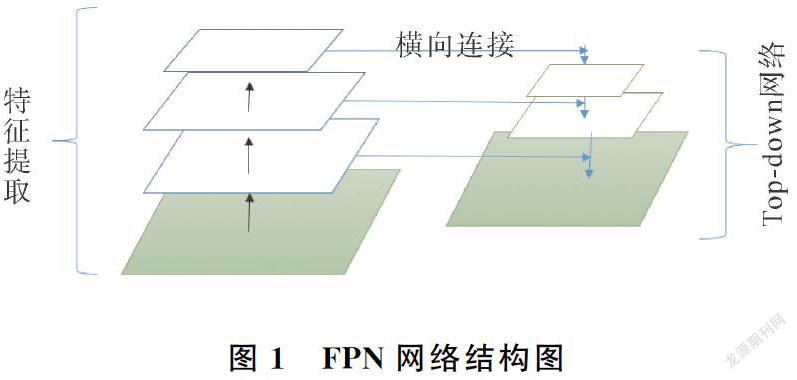
网络结构采用FPN网络[24]进行特性提取。把低分辨率、高语义信息的高层特征和高分辨率、低语义信息的低层特征进行自上而下的横向连接,使得所有尺度下的特征都有丰富的语义信息。FPN网络可以在增加较少计算量的前提下将处理过的低层特征和高层特征进行累加,因为低层特征可以提供更加准确的位置信息,高层特征能够提供比较细节的信息,利用深层特征可以将复杂的目标区分开来;利用比较深层次的网络来构造特征金字塔,可以增加鲁棒性[25-26]。FPN的大致内容包括:自底向上、自顶向下和横向连接。
自底向上(Bottom-top):也就是特征提取网络,即较低层反映较浅层次的特征图边缘信息等;较高的层则反映较深层次的特征图物体轮廓、乃至类别等。
自顶向下(Top-bottom):上层的特征输出特征图比较小,但却能表示更大维度的图片信息。此类高层信息对后续的目标检测、物体分类等任务发挥关键作用。因此在处理每一层信息时会参考上一层的高层信息做其输入,将上层特征图等比例放大后再与本层的特征图做横向连接。
卷积特征与每一级别输出之间的表达关联:使用1×1的卷积即可生成较好的输出特征,可有效降低中间层次的通道数目,使输出不同维度的各个特征图有相同的通道数目。网络结构如图1所示。
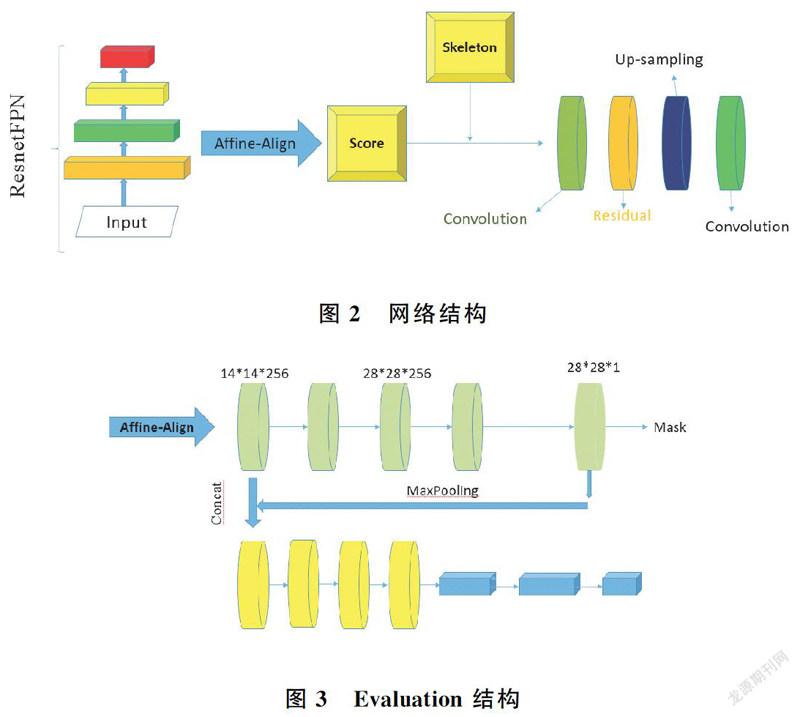
为了解决人体遮挡、重叠等不良因素,利用人体的骨骼特征来對人体进行分割。人类骨架更适合用来区分两个重合面积很大的人,相比边界框,可以提供更清晰的个人信息。实例分割中,大多数分割框架都采用实例的置信度作为Mask质量分数。然而,被量化为Mask实例与其ground truth之间的IoU的Mask质量通常与分类分数相关性不强,所以本文提出一个全新的模块,用来计算Mask分支得到的Mask与ground truth对应的Mask之间的像素级别的IoU值,来衡量分割的精确程度。整体网络框架如图2所示。
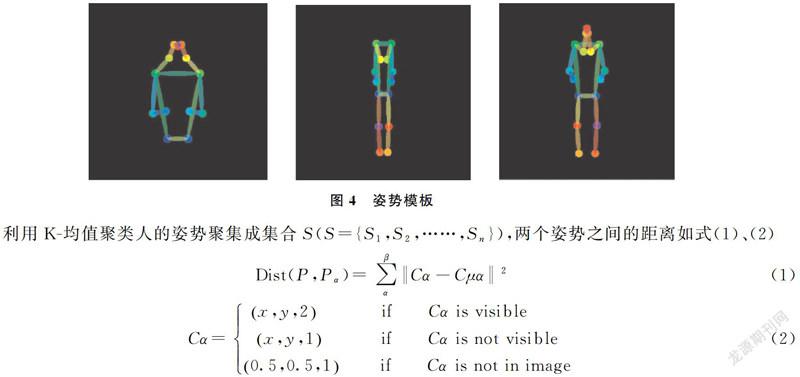
借鉴AP指标,实例分割利用预测的Mask与ground truth的Mask之间的像素级相交过并(IoU)来描述实例分割质量,提出了一种直接学习IoU的网络。在本文中,IoU表示为Evaluation。通过将预测的Mask分数来重新评估分割精准程度。
学习Evaluation不同于proposal classification或Mask prediction,需要将预测的Mask与object feature进行比较。本文提出了一个名为Evaluation head的Mask预测网络,以Mask分支的输出和由对齐模块Affine-Align处理的RoI特征作为输入,使用简单的回归损耗进行训练。大量的实验结果表明,本文的方法提供了一致和显著的性能改进,这归因于Mask质量和Score之间的一致性。网络结构如图3所示。
本文提出的利用人體骨骼来进行人体分割的打分机制的卷积神经网络主要有以下特点:通过FPN网络采用多尺度融合的方式,各个层级都有丰富的语义信息;提出打分机制, 加入Evaluation分支,直接学习IoU的网络,通过计算IoU值,来衡量分割的精确程度。
2 实验过程
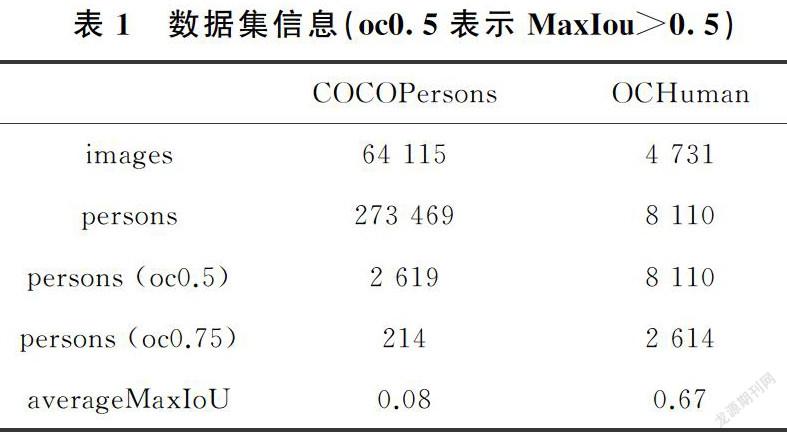
本文利用K-均值聚类生成的人体姿势模板,生成的姿势模板符合日常生活最普遍的姿势,半身和全身,其中全身分为前视图和后视图,如图4所示。
利用K-均值聚类人的姿势聚集成集合S(S={S1,S2,……,Sn}),两个姿势之间的距离如式(1)、(2)
其中,Pu是姿势集合中Sn的平均值,并将Pu>0.5关键点作为有效点,Cα表示人体关键点的坐标。用式(1)、(2)定义两个人之间的距离:(1)首先使用其边界框裁剪每个实例的正方形RoI,然后将目标及其姿势坐标放到RoI的中心;(2)将此平方RoI的大小调整为1×1,以便将姿势坐标都归一化为(0,1);(3)仅计算数据集中包含8个以上有效点的那些姿势,以达到姿势模板的要求。有效点太少的姿势无法提供有效的信息,并且会在K-均值聚类期间充当离群值舍弃。最普遍的两个姿势就是半身姿势和全身姿势(全身后视图和前视图,如图4所示),也符合日常生活,其他的姿势通过放射变换矩阵尽可能的向其转换。
数据集有两部分,COCO数据集和OCHuman数据集,COCO数据集是一个大型的、丰富的物体检测,分割和字幕数据集。但是在本文中COCO数据集使用仅含有人的图片来进行训练,由于公共数据集很少同时有人体姿势和人体实例分割标签,COCO数据集是同时满足这两个要求的最大数据集,因此所有模型都在COCOPersons训练集中进行,并带有姿势关键点和分割Mask的注释;OCHuman数据集包含4 731张图像中的8 110个人类实例, 每个人类实例都被一个或多个其他实例严重阻挡。使用MaxIoU来衡量被遮挡对象的严重性,MaxIoU> 0.5的那些实例称为重度遮挡,并被选择构成此数据集。OCHuman平均每个人的平均MaxIoU为0.67,是与人类实例相关的最具挑战性的数据集。见表1。
3 实验结果
在上述两个数据集上评估了本文提出的方法:(1)OCHuman是最大的验证数据集,主要适用于被严重遮挡的人;(2)COCOPersons(COCO的人员类别)[28],其中包含日常生活中最常见的情况。实验中,对OCHuman数据集进行测试,对人的遮挡和重叠进行了测试,而COCO数据集仅训练“人”这一类别。
实验结果如表2、表3、图 5、图6所示,本文提出的模型优于Pose2seg模型,具有更好的稳定性。首先,在OCHuman上的实验结果有比较明显的提升,比Pose2seg提高了1.9AP,对于AP@0.5和AP@0.75也有不同程度的提升[29]。其次,由COCOPerson数据集中的实验结果可以看出,在一般情况下,本文提出的算法是可行的,对人体分割的精度有所提升。
4 结论
本文通过人体骨骼和Evaluation模块(计算Mask分支得到的Mask与ground truth对应的Mask之间的像素级别的IoU值,来衡量分割的精确程度)对人体进行分割,提出的打分机制可以很好地预测Mask的质量,利用FPN网络很好的能够融合多层特征图的语义信息和人体特有的骨骼信息,能够很好的对人体进行分割。通过测试OCHuman数据集,结果表明,本文提出的Evaluation模块对人体分割有明显的提升。
参考文献
[1]LIU S, ZHANG Y Q, YANG X S, et al. Robust facial landmark detection and tracking across poses and expressions for in-the-wild monocular video[J]. Computational Visual Media, 2017, 3(1):33-47.
[2]MA X, LI Y L. Robust sparse representation based face recognition in an adaptive weighted spatial pyramid structure[J]. 2018, 61(1):101-103.
[3]PENG O Y, YIN S Y, DENG C C, et al. A fast face detection architecture for auto-focus in smart-phones and digital cameras[J]. 2016, 59(12):1-13.
[4]WANG J, ZHANG J Y, LUO C W, et al. Joint head pose and facial landmark regression from depth images[J]. Computational Visual Media, 2017, 2(3):1-13.
[5]ZHANG Z P, LUO P, TANG X O, et al. Facial Landmark Detection by Deep Multi-task Learning[C]// European Conference on Computer Vision. Springer, Cham, 2014:633-647.
[6]BRUNELLI R, POGGIO T. Face recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1993, 15(10): 1042-1052.
[7]MAO J, XIAO T, JING Y N, et al. What can help pedestrian detection? [C]// 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, 2017: 6034-6043.
[8]ZHANG L L, LIN L, LIANG X D, et al. Is faster R-CNN doing well for pedestrian detection?[C]// 14th European Conference on Computer Vision (ECCV). Amsterdam, 2016: 443-457.
[9]ZHANG S, YANG J, SCHIELE B. Occluded pedestrian detection through guided attention in CNNs[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, 2018:6995-7003.
[10] CHEN H, SUN K, TIAN Z, et al. BlendMask: Top-down meets bottom-up for instance segmentation[C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2020:112-126.
[11] LI Y, QI H, DAI J, et al. Fully Convolutional instance-aware semantic segmentation[C]// 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, 2017: 4438-4446.
[12] BOLYA D, ZHOU C, XIAO F Y, et al. YOLACT++: Better real-time instance segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, (99): DOI:10.1109/TPAMI.2020.3014297.
[13] HARIHARAN B, ARBELáEZ P, GIRSHICK R, et al. Hypercolumns for object segmentation and fine-grained localization[C]// IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, 2015: 447-456.
[14] DAI J, HE K, LI Y, et al. Instance-sensitive fully convolutional networks[C]// 14th European Conference on Computer Vision (ECCV). Amsterdam, 2016: 534-549.
[15] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, 2016:770-778.
[16] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6):1137-1149.
[17] HE K M, GEORGIA G, PIOTR D, et al. Mask R-CNN[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 36(2):1-1.
[18] LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2018: 536-544.
[19] HUANG Z, HUANG L, GONG Y, et al. Mask scoring R-CNN[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2020:127-136.
[20] CHEN Y, WANG Z, PENG Y, et al. Cascaded pyramid network for multi-person pose estimation[C]// Conference on Computer Vision and Pattern recognition(CVPR). 2017:733-747.
[21] FANG H S, XIE S Q, TAI Y M, et al. RMPE: Regional multi-person pose estimation[C]//16th IEEE International Conference on Computer Vision(ICCV).Venice, 2016:2353-2362.
[22] LIFKOOEE M Z, LIU C L, LIANG Y Q, et al. Real-time avatar pose transfer and motion generation using locally encoded laplacian offsets[J]. Journal of Computer Science and Technology, 2019, 34(2):256-271.
[23] XIA S H, GAO L, LAI Y K, et al. A survey on human performance capture and animation[J]. Journal of Computer Science and Technology, 2017(32):536-554.
[24] LIN T, DOLLAR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]// Conference on Computer Vision and Pattern Recognition (CVPR).2017:304-311.
[25] CHEN L C, PAPANDREOU G, KOKKINOS I, et al. Deeplab: Semantic image segmentation with deep convolutional Nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4):834-848.
[26] LI M, ZHANG Z, HUANG K, et al. Estimating the number of people in crowded scenes by MID based foreground segmentation and head-shoulder detection[C]// 19th International Conference on Pattern Recognition (ICPR 2008), Tampa, 2009:447-456.
[27] CAO Z, SIMON T, WEI S, et al. Realtime multi-person 2D pose estimation using part affinity fields[C]// 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, 2016: 1302-1310.
[28] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common objects in Context[C]//Europearn Corcference on Computer Vision. Springer, 2014:740-755.
[29] ZHANG S H, LI R L, DONG X, et al. Pose2Seg: Detection free human instance segmentation[C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, 2019: 889-898.
猜你喜欢
时代英语·高二(2021年4期)2021-07-29
时代英语·高二(2021年4期)2021-07-29
作文大王·中高年级(2020年8期)2020-08-14
学校教育研究(2017年30期)2017-08-13
中学生数理化·高一版(2016年6期)2016-05-14
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
读者·校园版(2013年3期)2013-05-14
