
基于用户通话行为的金融类电信网络诈骗建模分析方法
2021-09-09 07:08时镇军
江苏通信 2021年4期
时镇军
中国移动通信集团江苏有限公司
0 引言
近年来,电信网络诈骗案件高发多发。电信网络诈骗是指通过电话、网络和短信等方式,编造虚假信息,设置骗局,对受害人实施远程、非接触式诈骗,诱使受害人转账的犯罪行为,通常以冒充他人及仿冒、伪造各种合法外衣和形式的方式达到欺骗的目的。其中,贷款、代办信用卡等金融类电信网络诈骗案件在全部电信网络诈骗案件中占比较高,且呈现高发态势。本文提出一种对金融类诈骗案件涉案号码的用户通话行为特征提取分析和建模的方法。该方法利用大数据挖掘技术、AI机器学习/训练、大数据关联分析等技术,深度抽象行为特征和算法,构建基于大数据分析的模型,并最终通过模型实现对用户通话话单的自动化比对分析,及时将涉嫌进行金融类电信网络诈骗号码检出和迅速处置,对降低用户受到电信网络诈骗的侵害、减少案发率有显著效果。该模型结合专家经验和对数据的深度分析,对通话特征进行多维度采集,模型检出效果更准确,同时降低误判率。通过使用机器学习算法提升异常样本的适应性,模型生命周期更长,以应对诈骗分子手段多变的特性。
1 建模数据来源
所有电话通信诈骗都会产生相应的通话话单,因此从通话话单着手,对涉案号码进行通话特征的提取分析是一种准确有效的建模分析方法。本文数据源主要包括信令话单(O域话单)、计费话单(B域话单)、B域用户基本信息、其他数据(12321举报平台不良号码信息、公安涉案不良号码信息等)。
本文通过提取用户话单中的关键字段信息,结合金融类电信网络诈骗涉案号码话单的通话行为特征进行建模分析,并通过模型实现对疑似涉诈号码的自动化检出。同时结合12321平台和公安方面接收到的新举报金融类涉案号码,不断对模型进行迭代训练和调整,使得模型检出效果不断提升。
2 建模分析方法
2.1 模型构建方法
2.1.1 模型构建流程
电信网络诈骗检测模型从诈骗对抗的角度出发,围绕涉案诈骗分子的通话行为建立诈骗事件分析模型。建模采用机器学习和大数据分析方法,基于知识库数据如黑白号码、可疑号码、可信号码等特征数据,对通话行为如号码行为特征、号码活跃特征、通话行为事件流特征、通话地域特征等进行分析,从而在海量通话话单中找出其中的疑似电信网络诈骗号码。
模型构建流程如下:
(1)根据金融类电信网络诈骗涉案举报数据,提取举报当天及历史多天内的涉案号码话单数据,并对话单进行数据清洗;
(2)从主对端占比、平均通话时长、拨打区域离散度、集中时间点、重复通话占比等维度统计涉案诈骗号码的通话行为特征,排除诈骗样本中表现行为与绝大部分样本不一致的异常号码;
(3)对比分析正常用户及涉案诈骗号码的通话行为特征,并建立初筛条件;
(4)基于已知的正常用户及涉案诈骗样本进行建模,并对模型在训练集和测试集的效果进行评估,测试模型在实际运行中对全量通过初筛的疑似号码的检测效果;
(5)结合反馈结果,对模型误判情况复盘分析,并结合新的涉案诈骗样本进行模型调整和优化。
2.1.2 模型分析算法选择
电信网络诈骗事件分析算法主要采用适用性优良、精确度高、理论基础佳、学术成果前沿的机器学习算法对通信行为模式挖掘和准确识别,常见的算法如逻辑回归、随机森林、支持向量机、朴素贝叶斯、梯度提升决策树等。结合金融类电信网络诈骗场景,本文选择基于LightGBM(Light Gradient Boosting Machine)框架的梯度提升决策树算法,用于金融类涉诈号码的特征分析。LightGBM是一个实现GBDT算法的框架,该框架是一个梯度Boosting框架,使用基于学习算法的决策树,具备更快的训练效率、低内存使用、更高的准确率、支持并行化学习、可处理大规模数据等优势。
基于LightGBM框架的梯度提升决策树算法的实现流程:
说明:d,通话号码;f,通话特征;v,通话号码和对应通话特征的值;b,进行归一化后的值;λ,梯度值;k,离散后的特征区间;h:累计值。
(1)对所有特征进行分桶归一化并计算初始梯度值,如图1和图2所示。

图1 对所有特征进行分桶归一化

图2 计算初始梯度值
(2)在训练决策树计算切分点的增益时,LightGBM通过计算将样本离散化为直方图切割位置的增益即可,时间复杂度较低,因此在运算时间效率上有很大提升。如图3所示。

图3 计算直方图
从直方图获得分裂增益,选取最佳分裂特征并计算分裂阈值。
(3)建立根节点,根据最佳分裂特征、分裂阈值将样本切分。如图4所示。

图4 分裂阈值样本切分
(4)直方图做差进一步提高效率,计算某一节点的叶节点的直方图,可以通过将该节点的直方图与另一子节点的直方图做差得到,所以每次分裂只需计算分裂后样本数较少的子节点的直方图通过做差的方式获得另一个子节点的直方图,进一步提高效率。然后选取最佳分裂叶子、分裂特征、分裂阈值、切分样本,直到达到叶子数目限制或者所有叶子不能分割,并最终更新当前每个样本的输出值。
通过上述算法对正负样本的特征进行学习训练,从而在面对海量特征时,有效将正常号码和异常号码特征进行区分,筛选出针对金融类诈骗的重要特征进行建模及模型优化。经过特征筛选最终可用于模型创建的较为重要的特征有61个,其中显著特征有如下6个:某号码在8天内的对端号码归属地的平均对端号码数、当天通话总时长和历史7天日均时长的差异倍数、当天主叫通话总时长、当天主叫小时的时均主叫时长、8天中有通话行为的最早那天的通话总时长、当天主叫号码数在8天对端号码数中的占比。
2.2 金融类电信网络诈骗模型显著特征
本次建模正样本取自2021年1-3月集团下发的金融诈骗类公安举报号码,共计133个正样本,负样本来源为江苏移动正常用户号码。通过提取正负样本关联号码话单,对其通信特征进行归纳分析。金融类电信网络诈骗号码具备如下显著通信行为特征,可以作为模型训练和金融类涉诈号码检出的重要依据。
(1)某号码在8天内的对端号码归属地的平均对端号码数(normal:正常号码,fraud:诈骗号码)
图5展示了涉案号码和正常用户号码在8天中的对端归属地的平均对端号码数这一特征上的分布。涉案号码在8天中的对端归属地的平均对端号码数大部分是小于正常用户号码的,部分正常用户8天里对端归属地的平均对端号码数高达100,而涉案号码8天里对端归属地的平均对端号码数在5个左右。

图5 某号码在8天内的对端号码归属地的平均对端号码数
(2)当天通话总时长和历史7天日均时长的差异倍数
图6展示了涉案号码和正常用户号码在当天通话总时长和历史7天日均通话时长的差异倍数这一特征上的分布。涉案号码的当天呼叫总时长和历史7天日均通话时长的差异倍数呈两级分化状态,且涉案号码的差异倍数是大于绝大部分正常用户号码的。

图6 当天通话总时长和历史7天日均时长的差异倍数
(3)当天主叫通话的总时长
图7展示了涉案号码和正常用户号码在当天作为主叫进行通话的总时长这一特征上的分布。涉案号码的当天主叫通话总时长高于绝大部分正常用户号码,而正常用户号码的通话时长较短,并没有那么活跃。

图7 当天主叫通话的总时长
(4)当天主叫小时的时均主叫时长
图8展示了涉案号码和正常用户号码在当天主叫小时的时均主叫时长这一特征上的分布。涉案号码的主叫的时段相对更集中,每小时的总时长均值高于正常用户号码。
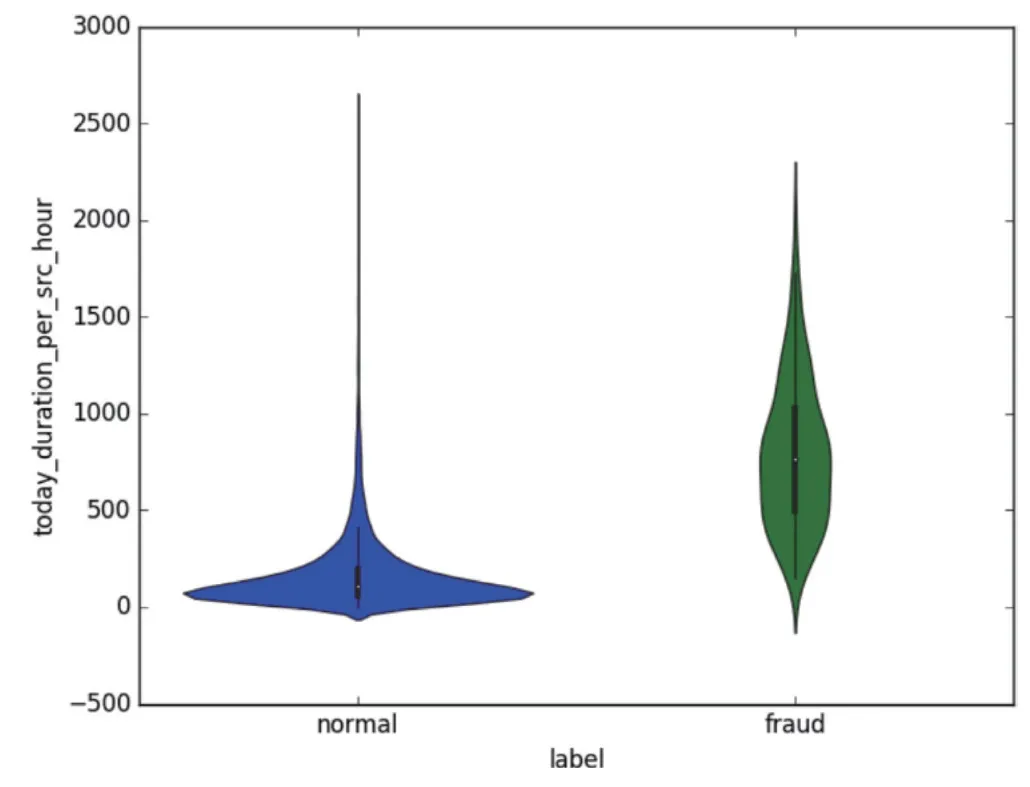
图8 当天主叫小时的时均主叫时长
(5)8天中有通话行为的最早那天通话总时长
图9展示了涉案号码和正常用户号码在8天中有通话行为的最早那天的通话总时长这一特征上的分布。涉案号码8天中有通话行为的最早那天的通话总时长高于正常用户号码。

图9 8天中有通话行为的最早那天的通话总时长
(6)当天主叫号码数在8天对端号码数中的占比
图10展示了涉案号码和正常用户号码在当天主叫号码数在8天对端号码数中的占比这一特征上的分布。在该特征上,涉案号码和正常用户号码刚好相反,涉案号码当天主叫过的号码占历史8天内对端号码的比例较高,而正常用户号码的分布相对比较平均。

图10 当天主叫号码数在8天对端号码数中的占比
3 用户数据筛选规则
3.1 用户数据清洗
为了确保分析数据的准确性,需要对原始话单数据进行加工处理,包括数据清洗、数据转换、数据关联,不规则数据需要进行数据补齐,满足数据的完整性和一致性。数据清洗过程需要用到数据采集组件、数据预处理组件和大数据处理组件等。
(1)数据采集组件采用分布式部署方式,能够采集来自不同数据源的数据,并传输至后续模块或直接写入分布式存储。
(2)数据预处理组件可实现按照一定的规则,对已采集的数据进行清洗,对无用的“脏数据”进行过滤;将不合理或者不满足数据结构要求的数据,进行字段取值、字段类型等转换,以满足实际数据结构要求。
(3)大数据处理组件主要是对接大数据全域数据汇聚中心,完成数据清洗、转换、过滤、压缩、筛选、加密等处理与数据存储等功能。
3.2 基于基本通话行为特征数据筛选
通过对金融类电信网络诈骗涉案号码历史及当日通话话单进行提取分析,总结发现金融类电信网络诈骗涉案号码通话行为所具备的基本特征如下:(1)涉案号码均有主动发起通话的行为;(2)涉案号码前30天内有通话记录天数的比例小于45%;(3)涉案号码开户天数小于425天;(4)涉案号码历史7天内每天通话总时长的均值小于等于1885秒;(5)涉案号码当天通话漫游记录在全天通话行为中的占比大于80%。
由于全省每天都会产生亿级通话话单,面对如此海量通话话单,必须要对采集的当日全部用户话单通过大数据处理组件进行过滤筛选,将不符合上述基本特征的通话话单做过滤处理,从而缩小检测范围,提高检出效率。
3.3 基于异常通话特征数据筛选
通过将金融类电信网络诈骗涉案号码通话行为特征和正常用户通话行为特征进行比对分析,筛选出涉案号码的异常通话行为特征。本文对异常通话特征提取采用四分位分析法。
通过使用四分位分析法,研究发现金融类电信网络诈骗涉案号码的通话行为具有如下异常特征:
(1)涉案号码历史8天通话中的对端号码数异常
通过对比涉案号码和正常用户号码在8天内通话中的对端号码个数特征的四分位数值和极值,可以得出涉案号码和正常用户号码在该特征上具有一定差异,即涉案号码在8天内通话中的对端号码个数略高于正常用户。
(2)涉案号码当日发起主叫的对端号码个数异常
通过对比涉案号码和正常用户号码在当天发起主叫的对端号码个数特征的四分位数值和极值,可以得出涉案号码和正常用户号码在该特征上具有一定差异,即涉案号码在当天发起主叫的对端号码个数高于正常用户。
3.4 检出号码筛查过滤
为了使模型在实际应用中真正发挥作用,在完成金融类电信网络诈骗模型建立后,需要在生产环境中进行部署。针对经模型检出的涉案号码数据,需要进行再次筛查过滤,以降低模型误判的风险。检出号码筛查过滤将遵循以下原则:(1)用户所选套餐价格小于等于99元/月;(2)当天主叫归属于本端归属地和归属于本端所在地的占比均值小于0.1;(3)当天作为主叫发起通话的次数大于2;(4)多天内均有所联系的号码数量的占比小于0.1;(5)若当天作为主叫发起通话的次数小于8,则当天作为主叫发起通话的连续时间占比要大于0.5;(6)若仅当天有话单,则当天通话涉及到的号码数量(不区分主对端)大于等于8个。仅保留同时满足上述条件的号码作为疑似诈骗号码作为最终检出号码。
4 结束语
本文利用大数据挖掘技术、AI机器学习技术、大数据关联分析等技术,深度抽象电信网络诈骗涉案号码通话行为特征和算法,建立基于大数据的分析机制,实现基于O域信令、B域话单和用户信息等多数据源数据的清洗、整合、预处理,构建基于用户话单的金融类电信网络诈骗疑似诈骗号码筛选模型,并对模型持续校验和迭代,从用户行为、身份、卡号属性等多个维度进行疑似诈骗的筛选,实现对金融类电信涉诈号码及时预警和处置。模型经部署实践后,日均检出疑似诈骗号码约1500个,再经人工核查处置,江苏移动涉案号码举报率持续降低,由模型部署前的日均10个降至现今的日均3.6个,降幅明显,效果良好,有效保障了用户的经济财产免受电信网络诈骗分子的侵害。后期将对模型持续迭代优化,通过比较少的硬规则条件排除绝大多数正常用户,通过单变量异常值进一步排除正常用户,提高模型的泛化性与适应性。
猜你喜欢
邯郸学院学报(2020年2期)2020-08-11
小学生学习指导(低年级)(2020年6期)2020-07-25
故事会(蓝版)(2020年1期)2020-01-19
奥秘(创新大赛)(2019年10期)2019-10-24
中华诗词(2018年5期)2018-11-22
电信工程技术与标准化(2015年5期)2015-07-03
电子设计工程(2015年8期)2015-02-27
电信科学(2014年1期)2014-09-29
小说月刊(2014年1期)2014-04-23
铁道通信信号(2013年3期)2013-09-06
