
基于机器学习的VoLTE核心网KPI异常检测方法
2021-09-09 07:08任心怡戴筠迪蒋迅婕
江苏通信 2021年4期
任心怡 金 鑫 郑 圣 周 莹 戴筠迪 蒋迅婕
中国联合网络通信集团有限公司江苏省分公司
0 引言
VoLTE(Voice over LTE)是基于IMS网络的语音业务解决方案。VoLTE基于IP传输数据,其数据和语音业务全部承载于LTE网络,可以在给用户提供高速率数据业务的同时提供高质量语音和视频通话。
VoLTE网络架构一般可由业务平台、核心网、承载网、接入网和终端构成。其中,核心网结构复杂、网元众多,在整个网络中具有举足轻重的地位。VoLTE核心网可划分为PS域、CS域、信令层、分组域等,各部分的网元种类繁杂众多。如负责业务承载的EPC,主要包括策略与计费规则功能单元(PCRF)、移动管理实体(MME)、归属签约用户服务器(HSS)、域名系统(DNS)、路由代理节点(DRA)、SAE-GW(分组数据网关(P-GW)、业务网关(S-GW)和计费网关(CG)。PS域的IP多媒体子系统的网络组成主要包括:服务呼叫会话控制功能(S-CSCF)、代理呼叫会话控制功能(P-CSCF)、询问呼叫会话控制功能(I-CSCF)、IP多媒体网关(IM-MGW)。S-CSCF是IP多媒体子系统的核心,主要负责归属网络中UE的注册请求和会话控制;P-CSCF是IP多媒体子系统中手机终端的首个通信节点,负责进行请求验证,请求通过后将信息转交给下一目标,并做处理和转发响应操作;I-CSCF是运营商网络的内部接触点,主要负责查询HSS中用户地址等;IM-MGW负责IP多媒体子系统与固网及电路交换域之间的互联互通,提供了CS交换网络和IP多媒体子系统之间的用户平行链路。
在整个运营商网络中,一旦核心网发生故障,会对用户的网络感知造成很大影响。因此,需要快速发现核心网风险,在影响范围扩大之前及时消除故障。关键性能指标(Key Performance Indicator,KPI)反映了网络性能和质量,对KPI进行分析挖掘,能够在一定程度上及时发现网络质量劣化风险。传统的核心网KPI异常检测方法基于设备关键指标的固定阈值进行监控,不能基于业务进行全面、体系化的监控,无法及时发现现网故障风险和隐患。
本文基于中国联通江苏省VoLTE业务,构建了用于VoLTE核心网性能检测的KPI指标体系,并利用机器学习技术对KPI指标进行训练学习,构建多维度KPI异常检测模型,实现了业务性能实时异常检测和预警上报。
1 VoLTE核心网KPI异常检测原理
梳理VoLTE核心网KPI异常检测指标体系,通过各个KPI指标的数据特征匹配不同的模型算法,并学习得到各类指标的动态阈值,之后,设计业务过滤规则,对造成业务影响较小的情况进行过滤。主要构建逻辑如图1所示。

图1 异常检测构建逻辑
1.1 KPI异常检测指标体系构建
VoLTE核心网的指标主要可分为三类:注册、呼叫、切换。本文使用与业务相关的VoLTE核心网话务统计指标,在注册、呼叫、切换三大指标类别下,再按照网元类型进行划分,之后基于KPI指标特性进行指标分组,以适配不同的异常检测算法。
KPI指标根据其本身的数值特征可分为:无明显波动指标、有波动但无明显周期性指标、弱周期性指标以及强周期性指标。此外,考虑到VoLTE业务的逐步推广、用户数量逐渐增多,部分指标如注册请求数、试呼次数等可能呈现弱趋势性。
鉴于VoLTE核心网业务特性,大部分指标如接通率、请求数、注册成功率、响应成功率等呈现以24小时为周期的强周期性波动,可采用回归模型或时序分解模型对每个指标的周期性、趋势性进行单独建模分析。部分呼叫类SIP(Session Initiation Protocol,会话初始协议)响应码可呈现弱周期性波动、无规律性波动或无波动状态,网元的每类业务流程通常可对应多个响应码,在实际建模过程中,需要根据业务流程对响应码类的KPI指标进行拆解分组,对于各个分组内的响应码进行合并建模训练。
具体示例见表1,其中,S-CSCF为IMS的服务呼叫会话控制单元,ATS为IMS的应用服务单元,eSRVCC为增强的无线语音呼叫连续性。

表1 VoLTE核心网KPI异常检测指标体系示例
1.2 指标预处理
建模前需要对KPI指标进行预处理,主要包括时间戳的补齐、缺省值的填充、异常值的剔除及数据的平滑去噪。其中,时间戳补齐和缺省值填充可采用多项式插值法;异常值剔除可采用统计学方法如箱线图法、3-Sigma法等;数据平滑可采用局部线性回归等方法。
此外,针对强周期性波动的指标,为了更好地让模型学习到其数值规律,本文采取基于等长有重叠的时间滑窗对时序KPI数据进行分段。该分段方法不仅能够保证将持续时间较长的数据模式完整地分割出来,还能够保持原有时序数据在时间上的先后依赖性。本文采用的等长有重叠的时间滑窗数据分段方法具体为:设时序样本记为X=(x1,x2,x3,…,xt,…,xn),其中xt表示X在t时刻的取值。现将时序样本X以长度为w的滑窗、s为步长进行截取,得到样本集Y。具体的划分表示如下:

实际应用中,滑窗长度w一般以24小时为基准,结合数据的时间颗粒度进行取值;步长s一般取1小时。
1.3 算法实现
根据KPI异常检测指标分组,在完成指标预处理后,匹配不同的检测算法,并融合统计学方法得到最终的异常判断阈值。
1.3.1 基于极端梯度提升树的KPI异常检测
针对具有强周期性波动的单一指标,如各网元的接通率、请求数、注册成功率、响应成功率等,鉴于其本身的指标特征,本文选取极端梯度提升树(eXtreme Gradient Boosting,XGBoost)模型来进行训练及预测。XGBoost是一种集成学习算法,在传统的梯度提升决策树(Gradient Boosting Decision Tree,GBDT)算法上进行了改进。GBDT在优化时仅使用一阶导数信息,而XGBoost则对损失函数进行二阶泰勒展开,同时用到一阶和二阶导数。XGBoost还在损失函数中加入了正则项,控制模型的复杂度,正则化可以降低模型的方差,使模型更简单且避免过拟合。XGBoost模型可以较好地学习到数据的周期性及趋势性特征,且需要的训练样本相对少,训练及预测速度快。具体的实现流程如下:
Step1:取7天 以上 的KPI时 序 样 本 记 为X=(x1,x2,x3,…,xt,…,xn),其中xt表示X在t时刻的取值。采用基于滑窗的分段方法,滑动地以长度为w的滑窗、s为步长截取时序数据作为训练数据的输入Y,以每段滑窗数据的下一个点作为预测的目标值Z。
Step2:将Step1中得到的训练数据Y作为模型的输入,预测目标值Z作为模型的输出,训练XGBoost回归模型,完成模型的构建。
Step3:预测时,输入一段新的滑窗数据,依据训练好的XGBoost回归模型得到该段滑窗下一个点的预测值。
因模型训练前进行了异常值剔除的预处理操作,故XGBoost学习到的是每个KPI时序数据的平稳周期性特征。当异常出现时,某一时刻的真实值可能与XGBoost预测值出现较大偏差,因此需要确定一个阈值区间来判断该时刻的真实值是否为异常。在训练XGBoost模型得到每个时刻的预测值之后,计算每个预测值与该时刻真实值之间的偏差,得到偏差序列,之后,利用箱线图法得到偏差序列的阈值区间,用于异常判断。箱线图法利用数据中的五个统计量,即最小值、第一四分位数、中位数、第三四分位数、最大值来描述数据,IQR为第三四分位数Q3与第一四分位数Q1的差值,实际应用中,一般认为大于Q3+3*IQR或小于Q1-3*IQR的值为异常。
完整的伪代码如下:

?

?
1.3.2 基于核主成分分析的KPI异常检测
针对具有业务相关性的KPI指标组,如各个业务流程下的SIP响应码组,为了挖掘指标与指标之间存在的隐形关联,本文选取带核方法的主成分分析(Kernel Principal Component Analysis,KPCA)算法来进行训练及预测。主成分分析(Principal Component Analysis,PCA)是一种统计方法,将多个可能存在相关性的变量通过正交变换转换为一组线性不相关的主成分,是数学上用来降维的一种方法。而KPCA是PCA的一种改进版,它引入核函数的概念,将原始空间映射到高维的特征空间,在高维空间进行PCA分析,使输入数据具有很好的可分性。本文利用KPCA将具有业务相关性的KPI指标组进行重构,通常情况下,重构后的第一主成分通常能够包含95%重构特征的方差比,即第一主成分在很大程度上反映了原始数据中的重要信息,而剩余的主成分则可能包含噪声。实际应用中,一般选取高斯核作为KPCA的核函数,在完成对原始KPI指标组数据的重构后,将重构后的第一主成分映射回原始数据空间。具体步骤如下:
Step1:取7天以上的KPI指标组时序样本集记为X=(X1,X2,X3,…,Xt,…,Xn),其中Xt表示t时刻指标组内某一指标的取值。
Step2:将Step1中的时序样本集输入KPCA模型进行重构,之后选取第一主成分映射回原始数据空间,得到新的数据集Y=(Y1,Y2,Y3,…,Yt,…,Yn)。
Step3:以24小时为周期,计算step2中得到的新数据集Y在24小时当中每个时间点上的平均值,得到预测集Z=(Z1,Z2,Z3,…,Zm)。
因模型训练前进行了异常值剔除的预处理操作,故KPCA学习到的是无异常状态下的数据特征。当异常出现时,某一时刻的真实值可能与重构后映射回原始数据空间的预测值出现较大偏差,此时可以参考单指标模型中的箱线图法来确定指标组内每一个KPI指标在24小时内每一个时间点上的阈值范围。
完整的异常检测伪代码如下:

?
1.3.3 基于高斯混合模型的KPI异常检测
针对无明显规律性但数据形态较为稳定的单一指标,可采用高斯混合模型(Gaussian Mixture Model,GMM)对其进行训练及预测。
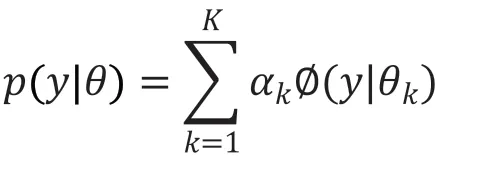
GMM是指具有如下形式的概率分布模型:

检测时,通过计算数据在整体分布中的概率,来判断其是否为异常点。具体流程如下:
Step1:取7天以 上 的KPI时 序 样 本 记 为X=(x1,x2,x3,…,xt,…,xn),其中xt表示X在时刻t的取值。
Step2:将Step1中的时序样本X输入高斯混合模型进行训练,得到高斯混合模型参数。
Step3:将Step1中的时序样本X输入训练好的高斯混合模型并计算得到逐样本点的整体概率,利用箱线图法得到概率的上下阈值。
Step4:异常检测时,针对每个时间点的数据,输入Step2中训练好的高斯混合模型,结合Step3中的概率上下阈值,判断是否为异常。
实际应用中,VoLTE核心网各网元的KPI指标基本都具有一定周期性,基于XGBoost的异常检测和基于KPCA的异常检测可以涵盖绝大多数异常检测场景,因此,本文暂未启用基于GMM的异常检测。
1.4 业务过滤规则
在经上述模型判断出异常后,需要通过业务过滤规则对异常进行进一步的筛选。通常情况下模型对异常的识别相对灵敏,业务过滤规则的设计是为了去除核心网KPI的一些合理抖动,从而更专注于真实异常的发现。
本文中的业务过滤规则融入核心网运维专家经验,考虑到不同时段核心网业务量的差异及夜间割接情况,将模型学习出的阈值在合理区间内进行小范围调整,并引入多时间点监控机制,在确保真实异常能够被检测出的前提下,过滤掉因KPI正常抖动造成的模型误检,提升检测准确度。具体流程如图2所示。

图2 业务过滤规则
2 VoLTE核心网KPI异常检测应用实例
2.1 突变类异常检测应用实例
本实例选取了VoLTE核心网S-CSCF网元LTE接入被叫侧的SIP响应数据。该KPI指标组内包含多个KPI指标,即S-CSCF网元LTE接入被叫侧的各类SIP响应。采用KPCA对该KPI指标组内的指标进行重构,并选取第一主成分映射回原始数据空间。可以观察到该指标组内的“S-CSCF LTE接入被叫408请求超时次数”于9月9日15:00左右产生了一个异常突变,如图3中蓝色曲线所示。
图3中蓝色曲线为该KPI指标的观测值,灰色曲线为经异常检测模型及业务过滤规则预测得到的指标阈值,该异常可以被捕捉。同时,“S-CSCF LTE接入主叫408请求超时次数”也捕获到相似的异常情况。后期经核心网运维专家验证,9月9日下午VoLTE核心网发现故障,间接说明了本文基于多指标模型的KPI异常检测的可行性。

图3 突变类异常检测实例
2.2 渐变类异常检测应用实例
本实例选取了VoLTE核心网S-CSCF网元MT接通率指标的数据。该指标为单指标,我们使用相应的单指标模型进行训练和预测,预测结果如图4所示。图中蓝色曲线为真实接通率,灰色曲线为XGBoost算法预测出的下阈值边界。图中可见,我们检测出在5月29日 01:40到5月29日 07:05之间发生了渐变类的接通率过低异常。在真实现网环境中,及时发现渐变类异常是非常有意义的,因为我们一旦发现异常就可以及时预警,并采取补救措施,避免性能指标持续劣化,从而避免对运营商的网络服务质量造成更大的影响。
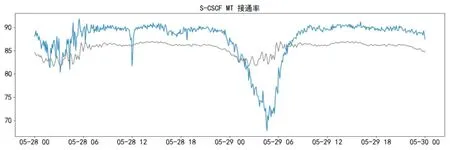
图4 渐变类异常检测实例
3 结束语
核心网KPI能够实时反映网络运行情况及质量,KPI异常检测对于及时发现现网故障及隐患有着十分重要的意义。本文以VoLTE核心网为例,基于业务流程梳理KPI指标体系,并采用多种机器学习算法,对核心网KPI异常检测的检测流程、算法逻辑及模型选型进行了研究探索,提出了一套VoLTE核心网KPI异常检测方案,打破了传统基于设备关键指标的固定阈值进行监测的方式,使监控更全面、故障发现更及时,具有较大的应用前景。
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-28
铁道建筑技术(2020年11期)2020-05-22
铁道通信信号(2019年6期)2019-10-08
数字通信世界(2019年2期)2019-03-11
通信电源技术(2018年3期)2018-06-26
电子制作(2017年13期)2017-12-15
互联网天地(2016年2期)2016-05-04
自动化学报(2016年5期)2016-04-16
电信工程技术与标准化(2015年10期)2015-12-22
电子设计工程(2014年17期)2014-02-27
